主页:https://ff3d-survey.github.io

Feedforwad系的三维重建方法思想起源于MVS-net(神经网络构建代价体以实现精致的深度估计),2023年DUSt3R开创了这个框架的基底,2025年上旬VGGT规范了此框架(以DINO2特征作为输入),再到当前基于该框架加入多种方法在点云重建、高斯重建、SLAM任务、4D动态重建各个领域的Feedforwad框架大放异彩,这个框架逐渐有了统一趋势,本文中,作者们总结了相关的395篇论文!让我们跟随他们独特的视角回溯与学习前馈3D重建的精华,展望三维视觉大模型的未来。
abstract
从二维输入重建三维表示是计算机视觉与图形学中的一项基础任务,是理解和交互物理世界的基石。传统方法虽能实现高保真度,但受限于逐场景优化速度慢或需按类别训练,阻碍了其实际部署与可扩展性。
因此,近年来可泛化的前馈式三维重建技术发展迅速。这类方法通过训练一个模型,使其在单次前向传递中直接将图像映射为三维表示,从而实现了高效重建和跨场景的鲁棒泛化。本综述的动机源于一项关键观察:尽管输出的几何表示形式多样(从隐式场到显式图元),现有前馈方法在高层架构模式上具有相似性,例如图像特征提取主干网络、多视角信息融合机制以及几何感知设计原则。
基于此,我们跳出表示形式的差异,聚焦于模型设计,提出了一种新颖的、与输出格式无关的、以模型设计策略为核心的分类体系。 该分类体系将研究方向归纳为驱动近期发展的五个关键问题:**1)面向鲁棒二维到三维提升的特征增强;2)融合稀疏输入先验的几何感知;3)降低计算与内存需求的模型效率;4)利用生成模型的增强策略;5)面向动态四维重建的时序感知模型。**为了给这一分类体系提供实证基础和标准化评估,我们进一步全面回顾了相关基准和数据集,并基于前馈三维模型对其实际应用进行了广泛的讨论与分类。最后,我们展望了未来方向,以应对可扩展性、评估标准及世界建模等开放挑战。更多内容请参见我们的GitHub代码库和项目页面。
Keywords
Feed-forward 3D, Mesh, SDF, Occupancy, 3DGS, NeRF, Pointmaps, Survey
1 Introduction
基于前馈式三维重建的快速发展,本综述旨在系统性地梳理近期进展,特别是阐明关键挑战。以往的综合性综述 20 主要依据三维表示形式对现有方法进行分类。我们的工作采用问题驱动的视角,如图1所示,提供了一个结构化、端到端的领域全景图。涵盖了三维表示、五大研究方向(详细分类见图2)、数据集与基准、广泛的实际应用以及未来方向。
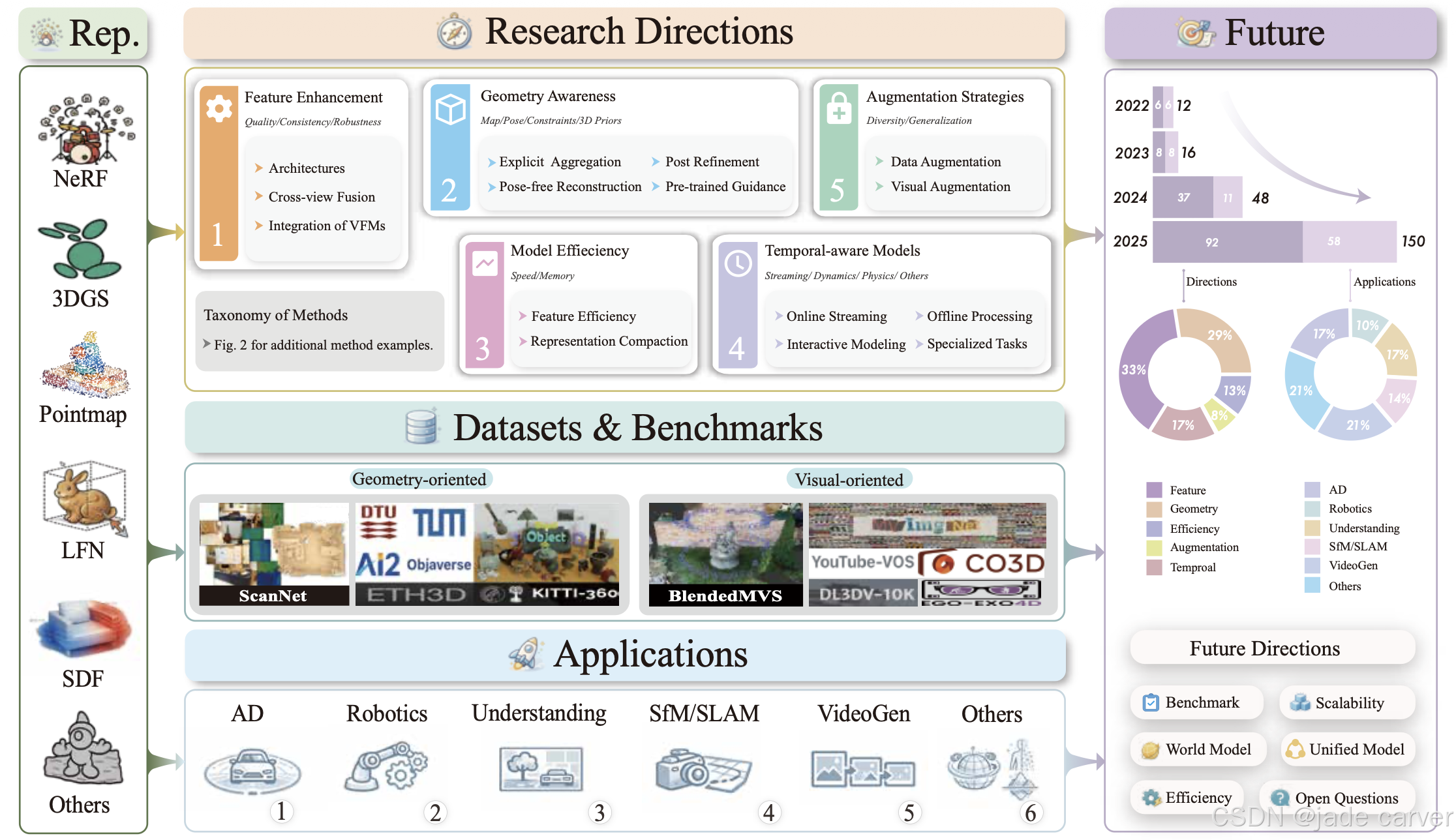
本文首先概述了核心3D表示(NeRF1、3D高斯溅射2、点图3等4-8)以及前馈网络如何生成它们。然后,它沿着五个挑战驱动的轴线分析方法:特征增强、几何意识、模型效率、数据或视觉增强和时间建模,然后审查数据集和基准、实际应用(例如,自动驾驶和机器人技术)。最后,根据调查作品的统计总结,我们概述了最近的趋势,并讨论了前馈3D场景建模的未来方向。
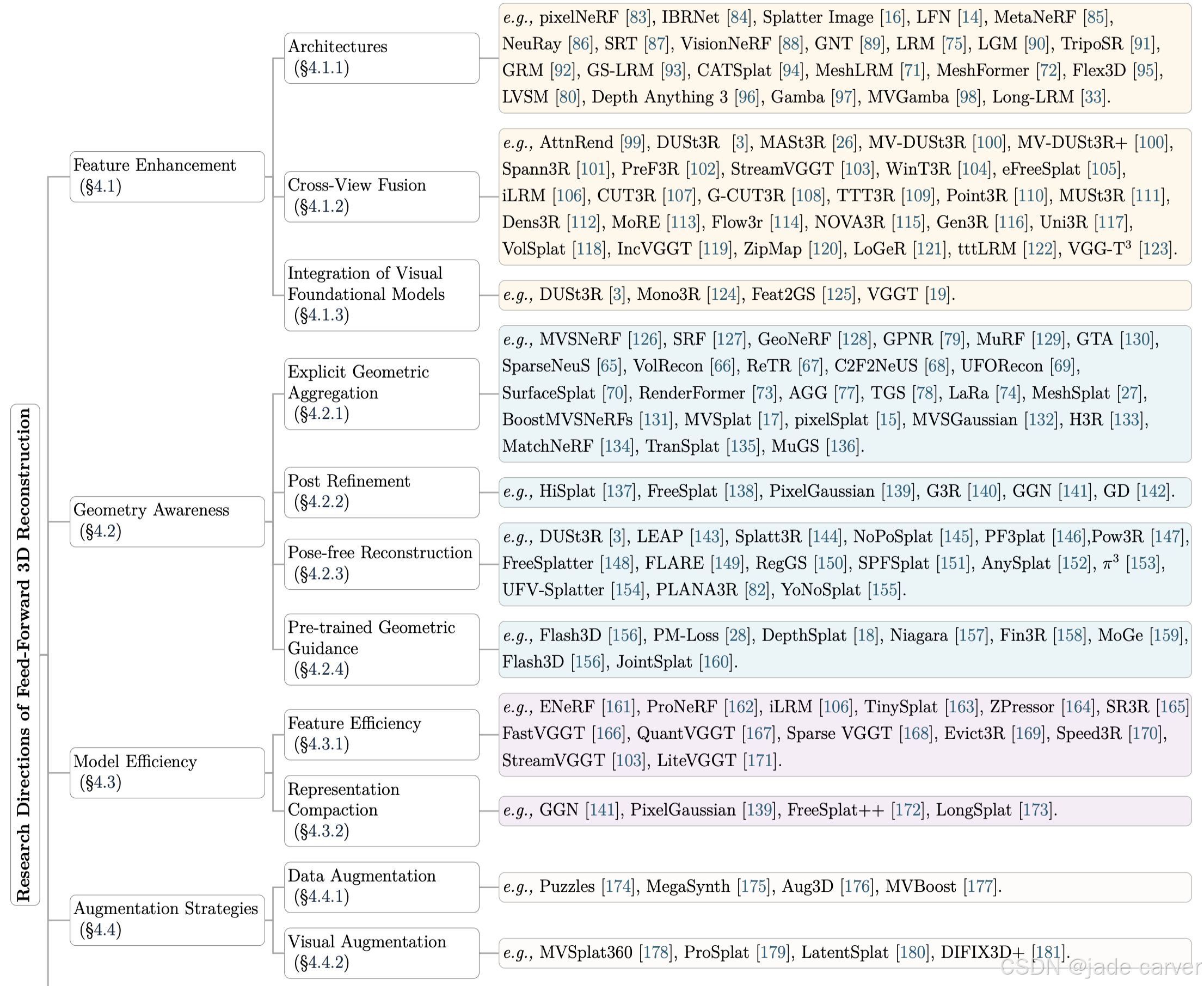

1.1 分类规则
本文的目的是能同时反映技术进展与内在挑战的方式来梳理该领域 ,所以分类方向的时候,并不是根据3D场景的表征方式(比如mesh、nerf、sdf、3dgs)来分类,因为基于相同表示的方法可能针对根本不同的问题(如特征鲁棒性、几何模糊性或计算效率),而应对相似挑战的方法则可能采用不同的表示。所以,**我们采用了一种问题驱动的分类法,根据方法旨在解决的核心挑战对其进行分类(见图1和图2)。**这一视角能够更好地反映现有方法的功能角色、设计权衡与发展趋势,并为理解前馈式三维重建的当前进展和未来方向提供更清晰的路线图。
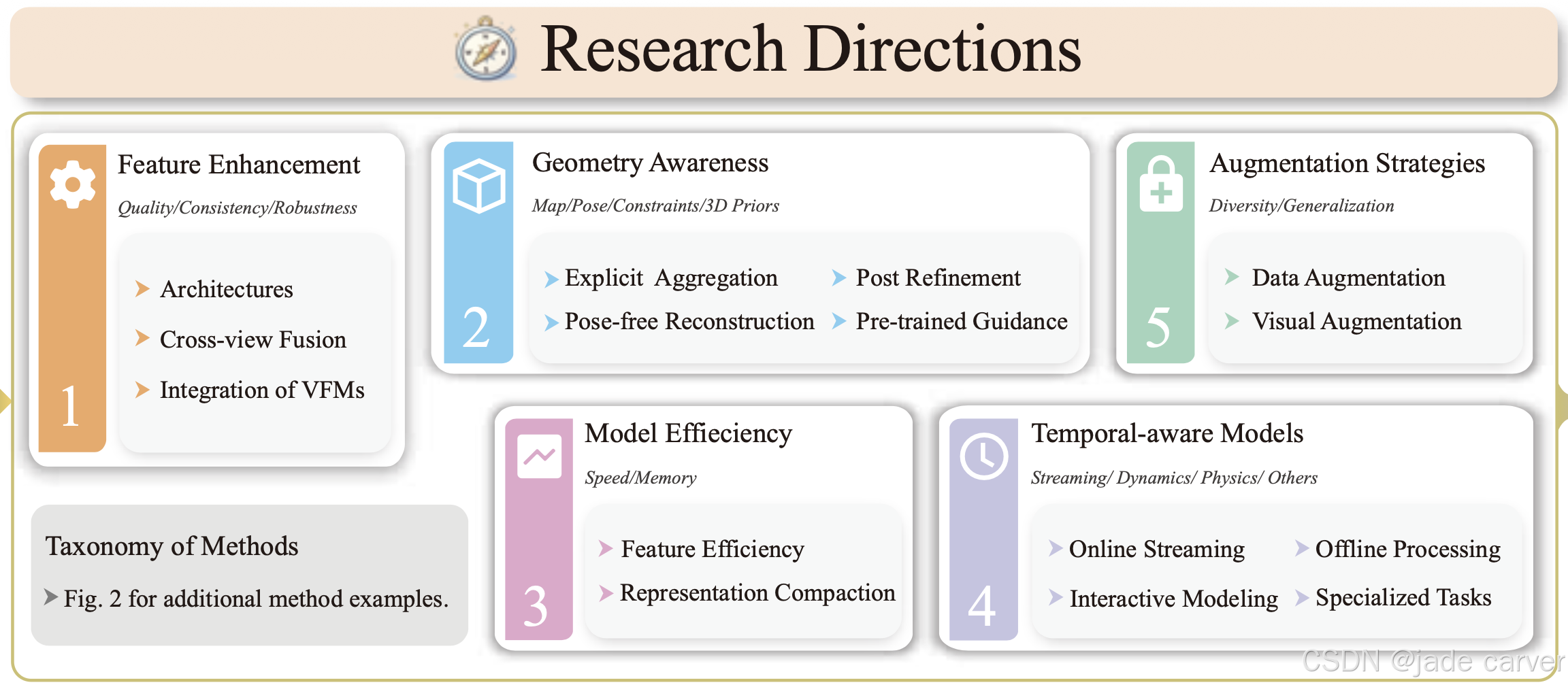
我们确定了五个关键研究方向:(1)特征增强 (第4.1节),旨在提升隐式特征表示的质量,从而更准确地解码三维场景;(2)几何感知 (第4.2节),目标是实现鲁棒且精确的底层场景几何推断;(3)模型效率 (第4.3节),应对实时计算和资源受限环境中的计算与内存瓶颈;(4)增强策略 (第4.4节),通过丰富数据分布和视觉表示来克服稀疏输入和训练多样性有限的问题;(5)时序感知模型(第4.5节),捕捉跨帧的几何与运动一致性,用于低延迟的四维场景建模。
1.2 Datasets & Benchmarks
因此,我们也重新评估了数据集与基准。根据其核心关注点对数据集进行分类:几何导向数据集 (例如DTU 21、ScanNet 22、Replica 23),侧重于点云、深度和相机位姿;以及视觉导向数据集(例如NeRF-Synthetic 1、RealEstate10K 24、DL3DV 25),优先考虑照片级真实的视图合成。
为了进一步说明基准选择如何影响研究进展,我们系统地整理了代表性方法在关键数据集上的报告性能,揭示了不同类别之间的显著趋势。我们得出了若干重要的数据驱动结论,例如需要建立场景复杂度的标准化量化方法,以及更清晰地报告几何多样性 24, 25。这些发现将在我们关于未来方向(第7节)的讨论中深入探讨。

1.3 下游应用
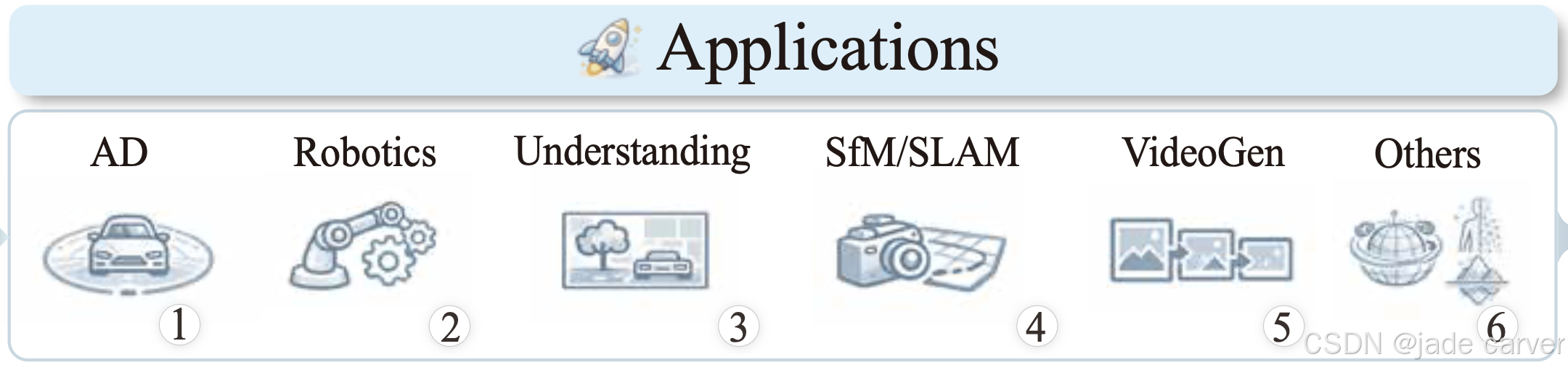
前馈式三维重建范式已从研究概念演变为实用技术,目前正推动着包括自动驾驶 (第6.1节)、机器人 (第6.2节)、场景理解 (第6.3节)、运动恢复结构与即时定位与地图构建 (第6.4节)、视频生成(第6.5节)以及其他场景(如视觉定位,第6.6节)等领域的进步。
1.4 未来方向
尽管已取得显著进展,前馈式三维重建仍然是一个活跃的前沿领域,面临着诸多开放性的挑战和机遇。最后,我们概述了几个有前景的未来方向,涵盖基准严谨性 (第7.1节)、模型效率 (第7.2节)、可扩展的场景表示 (第7.3节)、世界模型 (第7.4节)、统一的感知与重建(第7.5节)以及其他关键的开放问题(第7.6节)。

2 问题的数学设定
2.1 通用前馈式3D模型设定
通用前馈式3D模型的目标是:在单次前向传递中,根据一组输入图像重建3D场景,无需任何逐场景优化。现有方法通常包含编码器、解码器以及用于新视角合成的可选渲染器 。编码器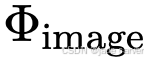 将输入图像编码为隐式特征,解码器
将输入图像编码为隐式特征,解码器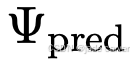 将隐式特征解码为3D场景的表示。若需要,渲染器R则根据预测的3D场景合成图像。
将隐式特征解码为3D场景的表示。若需要,渲染器R则根据预测的3D场景合成图像。
给定K张输入图像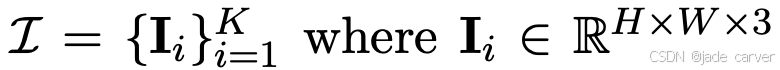 ,及其(可选的)对应相机位姿
,及其(可选的)对应相机位姿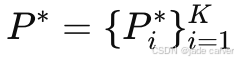 ,编码器会提取一组隐式特征图
,编码器会提取一组隐式特征图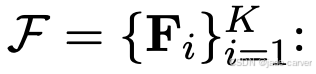 :
:
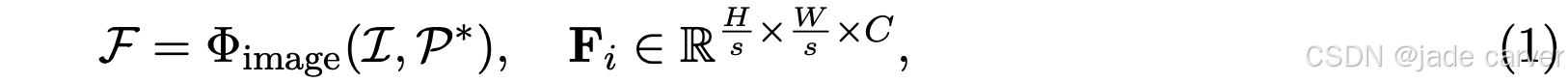
其中:
- s 是空间下采样因子
- C 是特征维度
这些特征还可以通过额外的特征增强模块进行优化,得到增强后的特征 。
。
随后,将增强后的特征输入解码器,得到3D场景表示 :
:

其中:
- 是解码器
- 是最终的3D表示
例如,在使用3DGS时:

其中每个高斯包含:

2.2 大规模数据训练
前馈式3D方法在大规模场景数据集上训练一次 ,并在测试时直接推理,设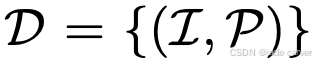 表示训练场景数据集。对于每个场景也就是每一个
表示训练场景数据集。对于每个场景也就是每一个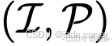 ,编码器和解码器会生成一个3D表示 ,可能的类型例如:
,编码器和解码器会生成一个3D表示 ,可能的类型例如:
- 深度图(depth maps)
- 体素(voxel)
- 有符号距离场(SDF)
- 网格(mesh)
- 点图(pointmaps)
- NeRF
- 3D Gaussian Splatting(3DGS)
具体形式取决于方法设计。如果模型包含渲染器 ,则:
,则:
- 输入:3D表示 GG 和新视角相机位姿

- 输出:合成图像

编码器 、解码器 以及(若可学习)渲染器,通过最小化以下损失进行联合优化:
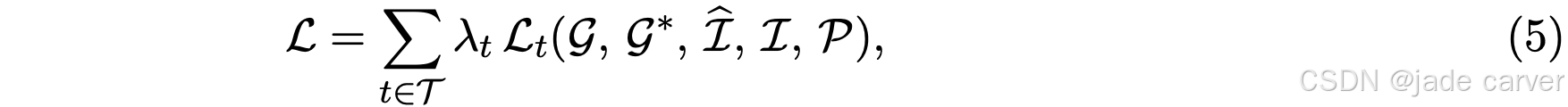
其中:
- T:损失项集合
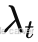 :损失
:损失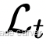 权重
权重 :ground-truth(如深度图、点图、法向等)
:ground-truth(如深度图、点图、法向等)
实际中,总损失 L 通常包括三类:
第一类,几何监督(Geometric Supervision) ,直接约束预测的3D结构 ,最后不渲染。包含的约束有点图回归(pointmap regression)、深度监督(depth supervision)、法向一致性(normal consistency),这一类是基于pointmap的方法。
第二类,光度 / 感知损失(Photometric / Perceptual Loss) ,在渲染图像和真实图像之间计算像素误差(MSE)、感知损失(LPIPS),这一类只在使用可微渲染器 R 时才存在。
第三类,结构正则(Regularization),约束3D表征本身的结构,例如:
- 对于 3DGS:
- opacity 稀疏性
- scale 限制
- 对于 NeRF:
- distortion loss
- depth smoothness
这种跨多场景的大规模训练 是关键,因为它实现了**将"重建能力"从"每个场景优化"转变为"模型参数中学习"**也就是所谓的 amortized reconstruction(摊销式重建)
2.3 Feed-forward inference
在推理时,前馈式系统通过式(1)和式(2)对新的输入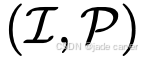 进行单次前向传递,即可重建一个新场景,无需任何基于梯度的逐场景优化或测试时微调。可以应用一些轻量级的后处理,例如基于置信度的剪枝与合并 33,以进一步降低内存消耗并提高渲染稳定性。
进行单次前向传递,即可重建一个新场景,无需任何基于梯度的逐场景优化或测试时微调。可以应用一些轻量级的后处理,例如基于置信度的剪枝与合并 33,以进一步降低内存消耗并提高渲染稳定性。
3 当前的几种3D表征以及相关改进
在本节中,我们将探索几个突出的表示,包括NeRF、3DGS、Pointmap等,研究前馈方法如何改进这些表示,以更好地满足现代3D重建任务的需求。
3.1 NeRF
NeRF是把空间3D点以及渲染视角作为输入,颜色与密度作为输出,以MLP来隐式表达一个3D场景的方式。

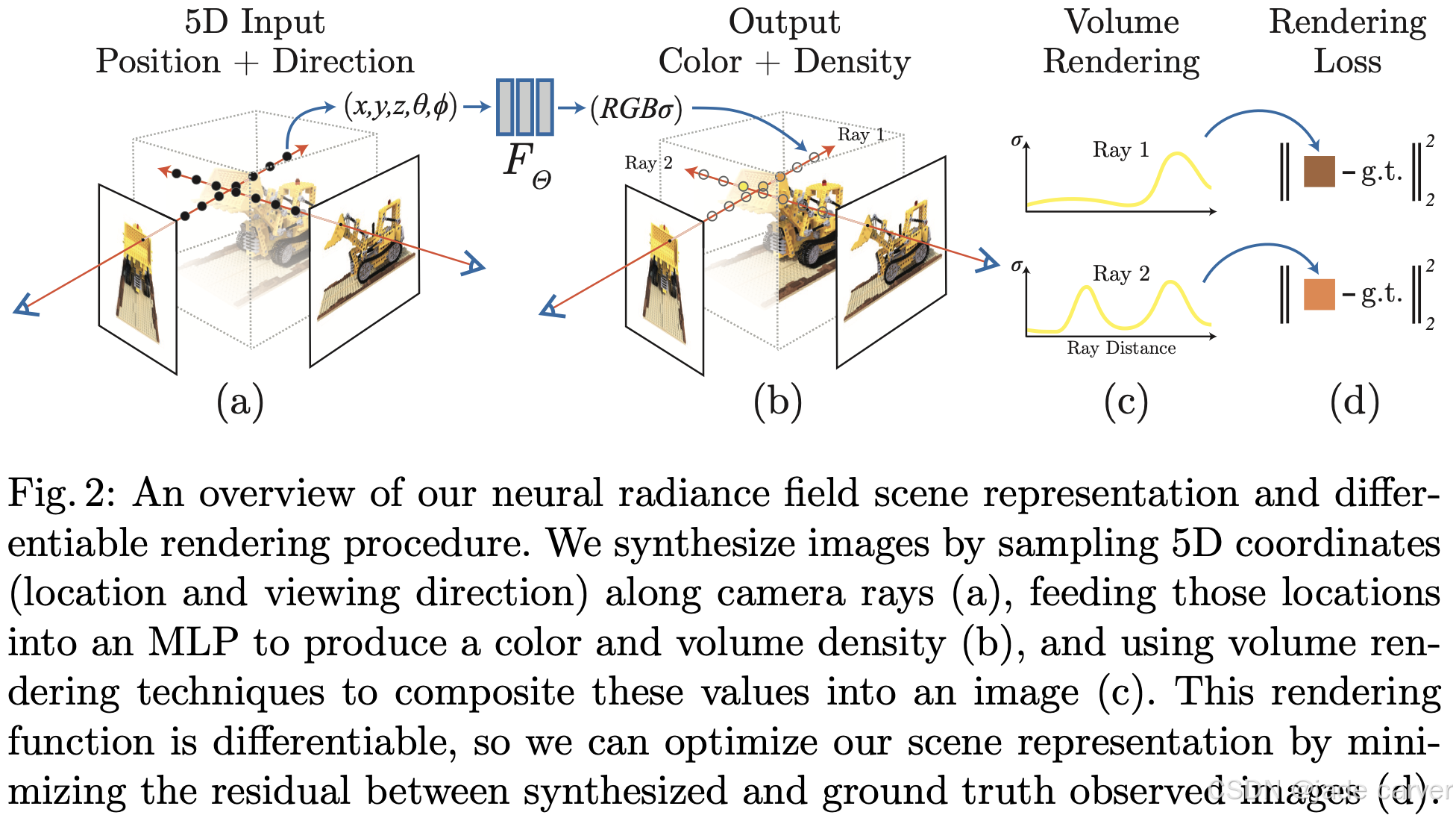
NeRF 的优势在于它能够生成高保真、逼真的新视角图像,并且能够很好地处理复杂遮挡以及视角相关效应(例如镜面反射)。然而,原始的 NeRF 框架也存在一些明显的局限性,例如需要针对每个场景进行长时间的优化、在渲染时需要进行大量的 MLP 查询,以及对相机视角的精确标定要求较高。
后续的一系列工作在质量和鲁棒性方面对 NeRF 进行了显著改进。例如,Mip-NeRF 和 Mip-NeRF 360 通过多尺度表示和更先进的正则化方法,解决了混叠问题,并将 NeRF 扩展到了无界场景。Ref-NeRF 对体渲染模型进行了调整,使其更好地表达反射表面。DS-NeRF 和 NerfingMVS 引入了几何先验,从而在监督较稀疏的情况下也能加速收敛并提升重建精度。在效率方面,Instant-NGP 通过基于哈希的编码,大幅提升了训练和推理速度。
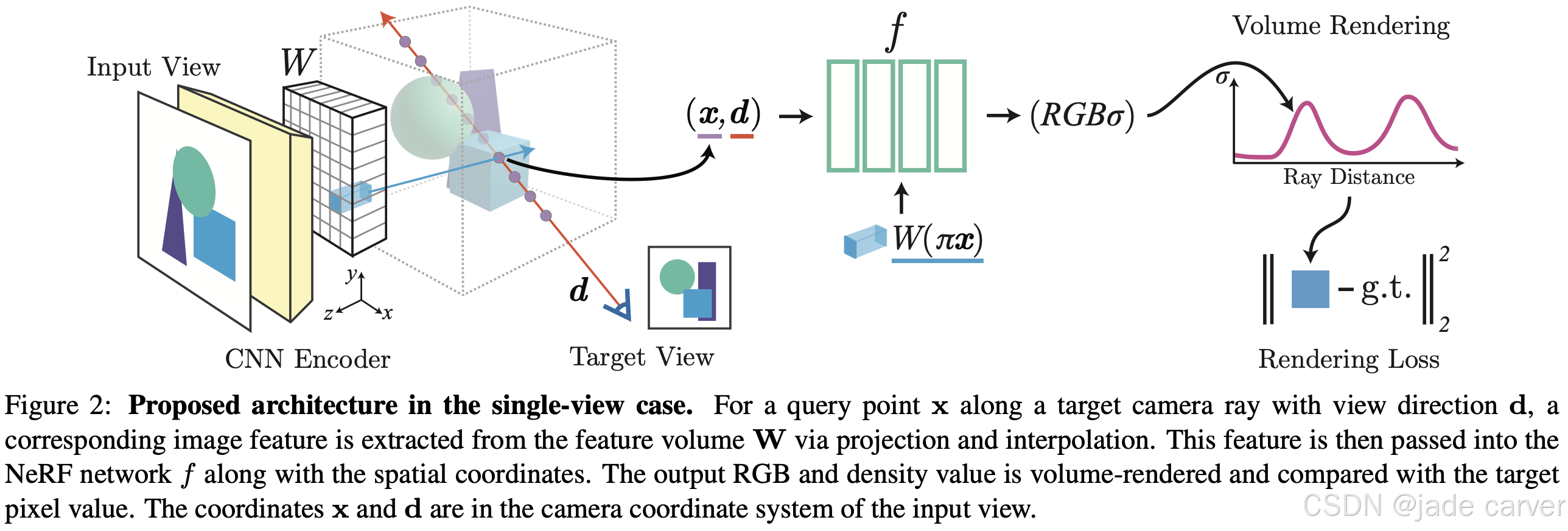
前馈式的 NeRF 重建方法试图实现跨场景泛化,而无需在测试时重新训练 。PixelNeRF 是其中较早的代表方法,它将辐射场建模为依赖输入图像特征的函数。具体来说,
假设你要渲染一个3D点 x,,首先用编码器提取输入图像的特征feature map ,然后把 x 投影到图像位置上,再在图像 feature map 上取对应特征,也就是输入(3D位置 x, 视角 d, 图像特征 f),用还是和NeRF一样用MLP输出颜色和密度,不同于单个场景单独训练与推理,这个MLP是用很多数据集训练提前好的,渲染时推理。
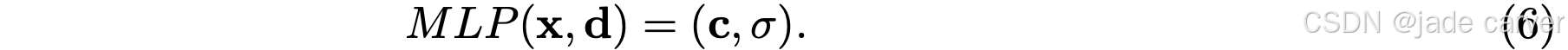
PixelNeRF是神经辐射场具有开创意义的前馈式方法。
3.2 3D Gaussian Splatting
3DGS是利用一个高斯球集合来显式表达一个3D场景的方式,每个高斯球带有位置、尺度、协方差、不透明度、球谐函数颜色参数,在渲染时,依据输入的位姿,在图像平面上高斯球进行splatting,通过此方式来影响图元的颜色完成渲染,由于NeRF的隐式表达在渲染时需要进行采样光线、MLP计算等过程,无法避免复杂计算,而3DGS这套框架可以完成实时渲染。
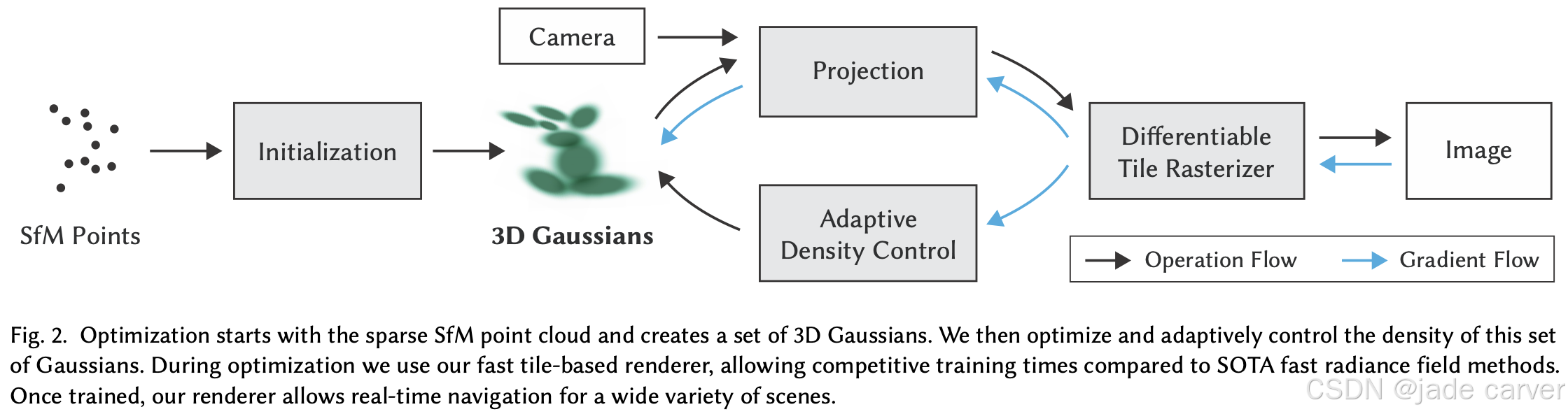
然而,这些优势也伴随着代价。标准的3DGS流程高度依赖于精确的相机位姿以及由运动恢复结构(SfM)生成的稀疏点云来进行初始化。此外,要实现高质量重建往往需要数百万个高斯球,导致巨大的内存占用和带宽需求,有时甚至超过NeRF中的多层感知机(MLP)。
为了解决这些问题,近期的研究主要从两个方面展开挑战。首先,一系列面向质量的方法 ,如Fregs 41、Scaffold-GS 42 和 Gaussian Opacity Fields 43,引入了新的正则化策略和高级着色模型,以进一步提高稳定性、减少伪影并提升渲染场景的整体视觉保真度。其他专门技术,包括针对反射 44--46 和运动模糊 47, 48 的技术,进一步扩展了3DGS在极具挑战性场景中的表达能力。其次,面向效率的方法试图通过使3DGS的形式化表示更加紧凑,来解决其表示和操作中存在的问题。像Compact-3DGS 30、Reducing-3DGS 49 和 LightGaussian 29 等方法直接减少了高斯基元的数量,而 Compressed-3DGS 50 和 HAC 51 等工作则专注于压缩每个高斯函数的属性,使得大规模场景的存储和流式传输变得更加实用。
尽管取得了这些进展,但原始的3DGS及大多数扩展方法仍然遵循从SfM初始化的逐场景优化范式。前馈式3DGS方法旨在绕过这一要求,直接从图像中预测高斯基元 。例如,pixelSplat 15 采用了一种编码器-解码器架构:从一个或多个输入视图中提取多尺度特征,并在单次前向传递中将其解码为与像素对齐的3D高斯参数。这类方法将3DGS向前馈机制推进,实现了更快速、更具泛化能力且更易于部署的基于高斯的3D重建。

3.3 Pointmap
点图(Pointmap)利用3D点及其关联特征来表示一个场景。在前馈式方法(如DUSt3R 3)中,点图被定义为一个稠密的2D平面上的3D点场,记作 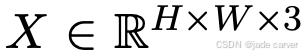 。当与其对应分辨率 H×W 的RGB图像 I 相关联时,点图在图像像素与3D场景点之间建立了一种直接的一一对应关系。当网络处理一对图像
。当与其对应分辨率 H×W 的RGB图像 I 相关联时,点图在图像像素与3D场景点之间建立了一种直接的一一对应关系。当网络处理一对图像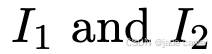 时,它会输出两个对应的点图
时,它会输出两个对应的点图 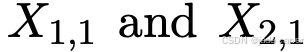 。这里,Xn,m 表示相机 n 的点图
。这里,Xn,m 表示相机 n 的点图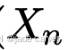 在相机 m 的坐标系中的表达:
在相机 m 的坐标系中的表达:
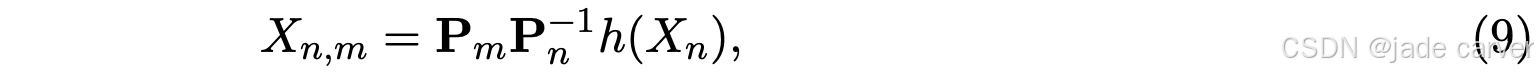
其中 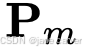 和
和  分别是相机 m 和 n 的w2c矩阵,h: (x,y,z) → (x,y,z,1) 为齐次映射。这个
分别是相机 m 和 n 的w2c矩阵,h: (x,y,z) → (x,y,z,1) 为齐次映射。这个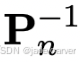 为相机n的c2w矩阵,把从相机坐标系转到世界坐标系,然后左乘,转到相机m的坐标系下,这是一般的相机n到m的坐标变换。
为相机n的c2w矩阵,把从相机坐标系转到世界坐标系,然后左乘,转到相机m的坐标系下,这是一般的相机n到m的坐标变换。
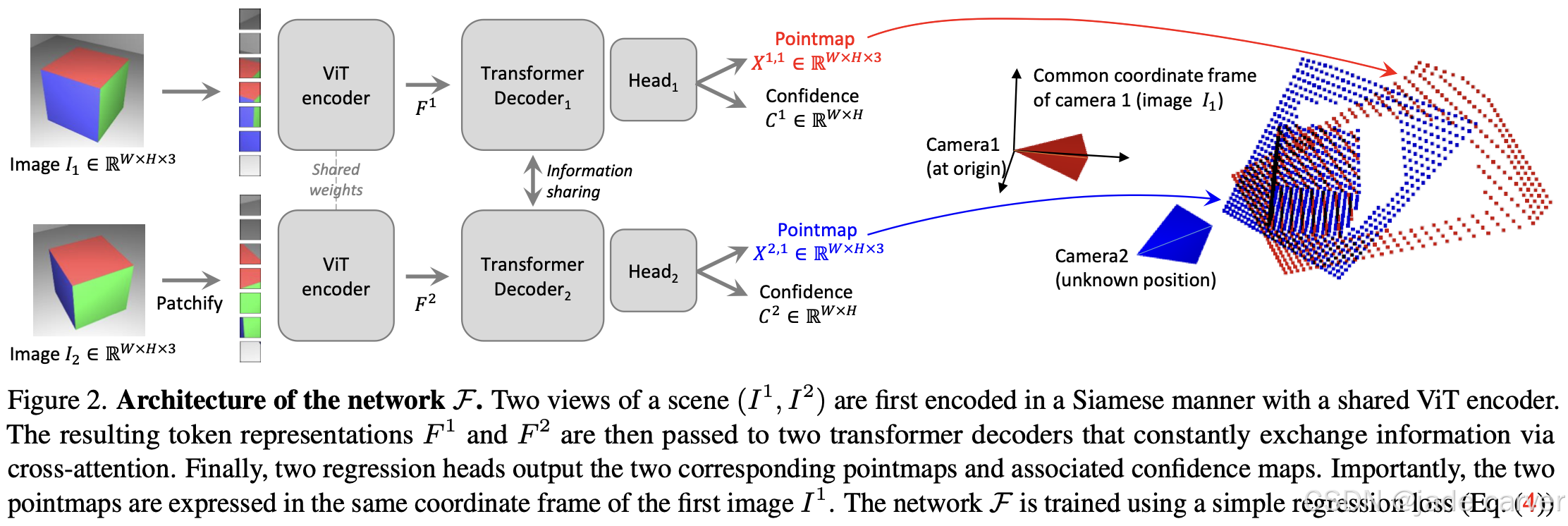
**DUSt3R 3 是前馈式点图重建的典范。该方法使用基于Transformer的ViT 62 来处理多张输入图像,模型在单次前向传递中直接回归出每个输入视图的点图。在处理一对图像时,它能同时预测它们的相对相机位姿和一致的点图,其中来自一个视图的3D点在另一个视图的坐标系中表达。**其核心操作是学习将像素对齐的图像特征直接映射到3D坐标,从而有效地统一了深度估计和相机位姿推断。
点图在视觉定位应用中已被证明极具价值。无论是scene-dependent的优化方法 52--54,还是能够跨场景泛化(scene-agnostic)的与场景无关的推理方法 55--57,都已成功采用了这种表示。该概念的应用范围已超越定位------通过2D视图存储3D几何已成为单图像3D重建 58--60 和视图合成 61 领域的基础 。通过在图像空间中操作并利用透视相机几何进行渲染,这些方法能够有效地处理和操纵底层的3D结构。
3.4 其他表达
前馈范式下还探索了多种替代性的3D表示方法。其中许多方法出现于神经渲染时代之前,并且它们是最早展示如何从学习到的表示中进行前馈式3D重建的方法。这些表示方法可以大致分为两类:一类仅对几何进行建模(例如占用表示、有符号距离函数SDF、网格),另一类则同时对几何和外观进行联合建模(例如光场、纹理场、基于三平面的辐射场)。
1. Neural implicit representations for geometry
这类方法专注于恢复几何结构,并不对视角相关的外观进行建模。占用网络(Occupancy Networks)5 将3D形状表示为深度分类器的连续决策边界,通过学习隐式占用函数,将3D坐标映射到二值占用概率,从而能够实现高分辨率的形状重建,且不会产生离散化伪影。
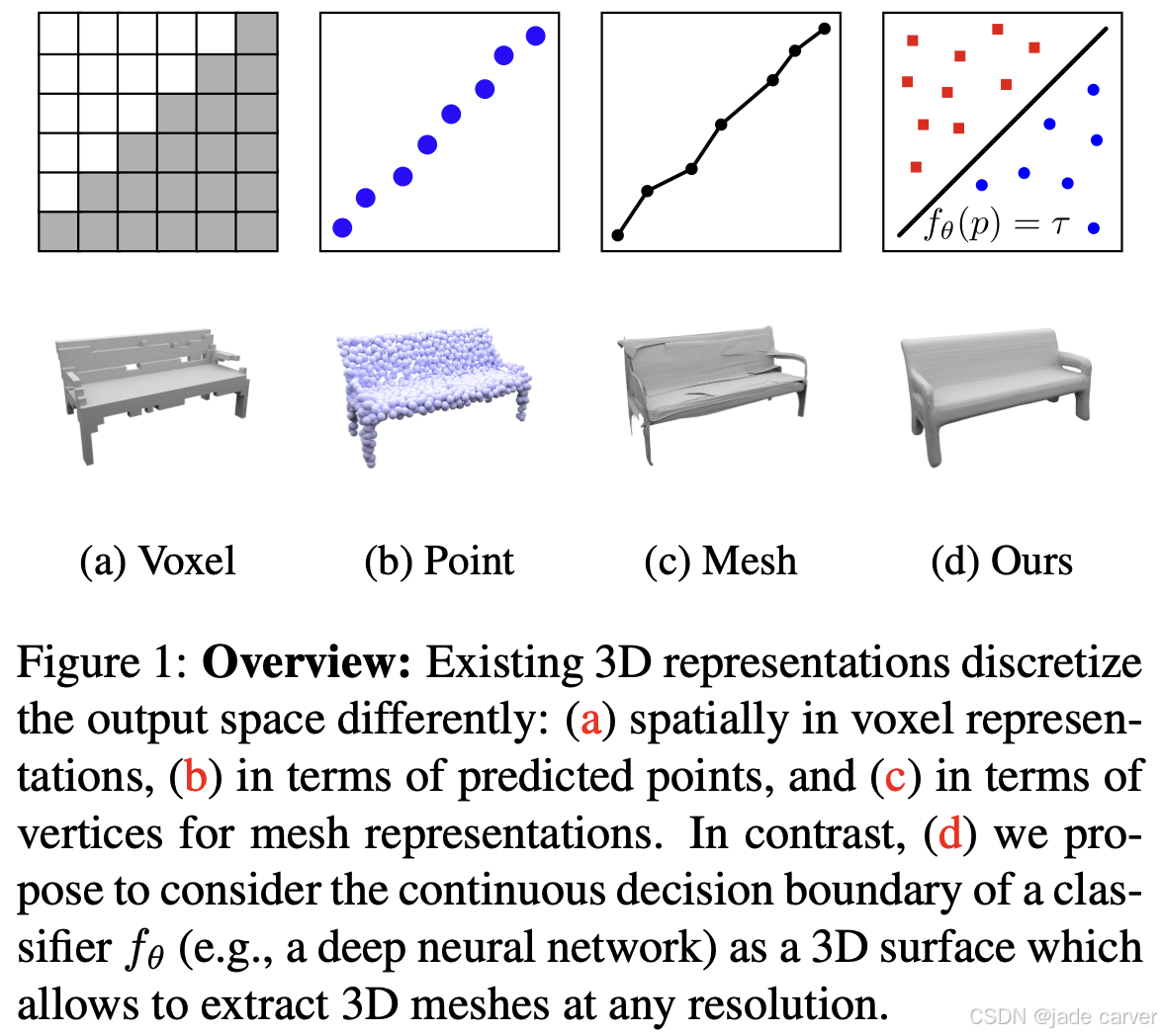
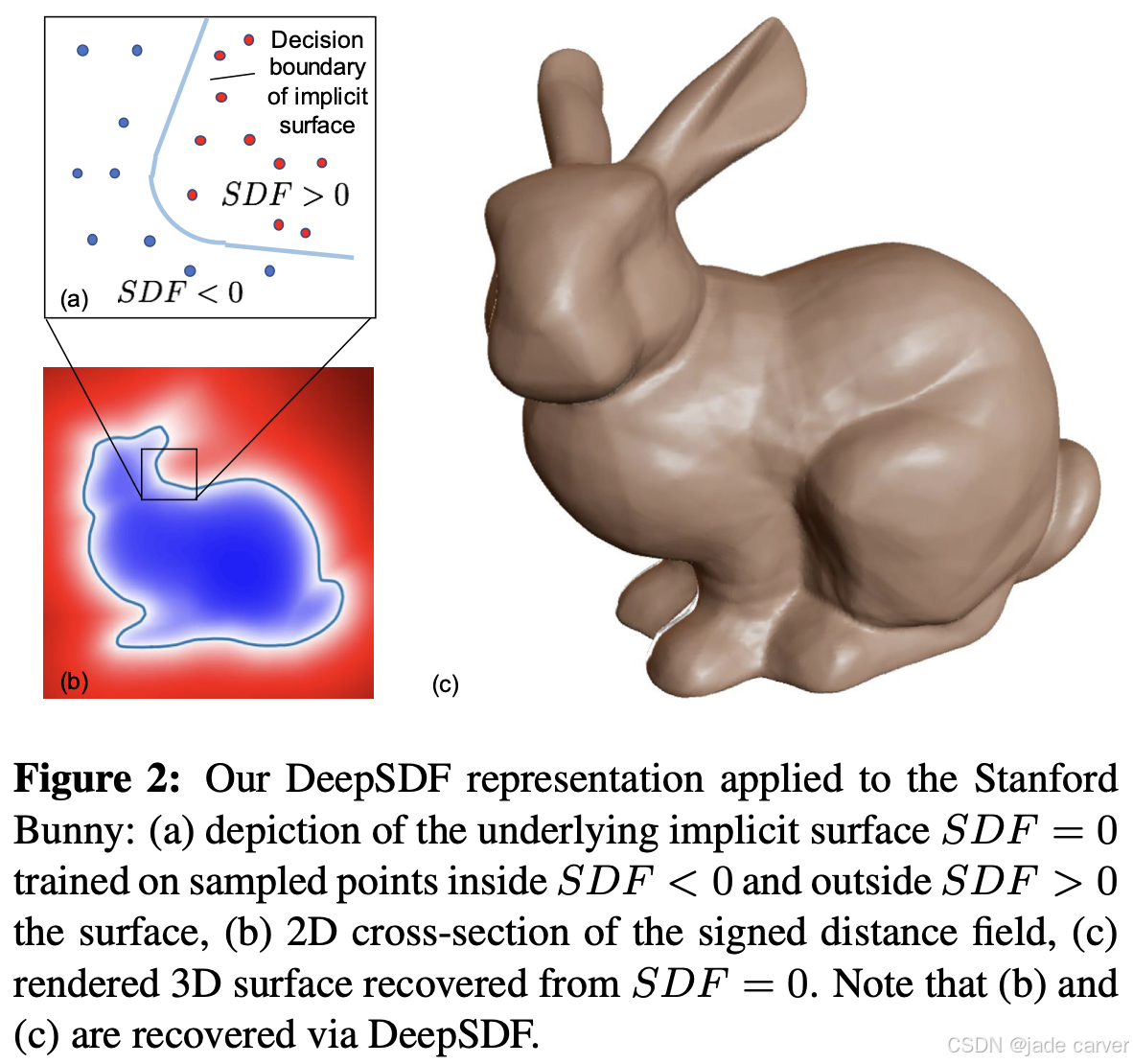
同期的工作,如回归连续有符号距离函数的DeepSDF 4,以及学习以形状嵌入为条件的隐式场解码器的IM-NET 63,各自独立地确立了相同的核心思想。这些工作共同为通过神经隐函数进行前馈式3D重建奠定了概念基础,其影响力延伸至本综述中几乎所有的后续方法。
在占用网络 5 的基础上,卷积占用网络(Convolutional Occupancy Networks)64 通过卷积编码器和局部隐式解码器引入了结构化的几何推理,在提升对大型场景可扩展性的同时,保持了对含噪输入的鲁棒重建能力。
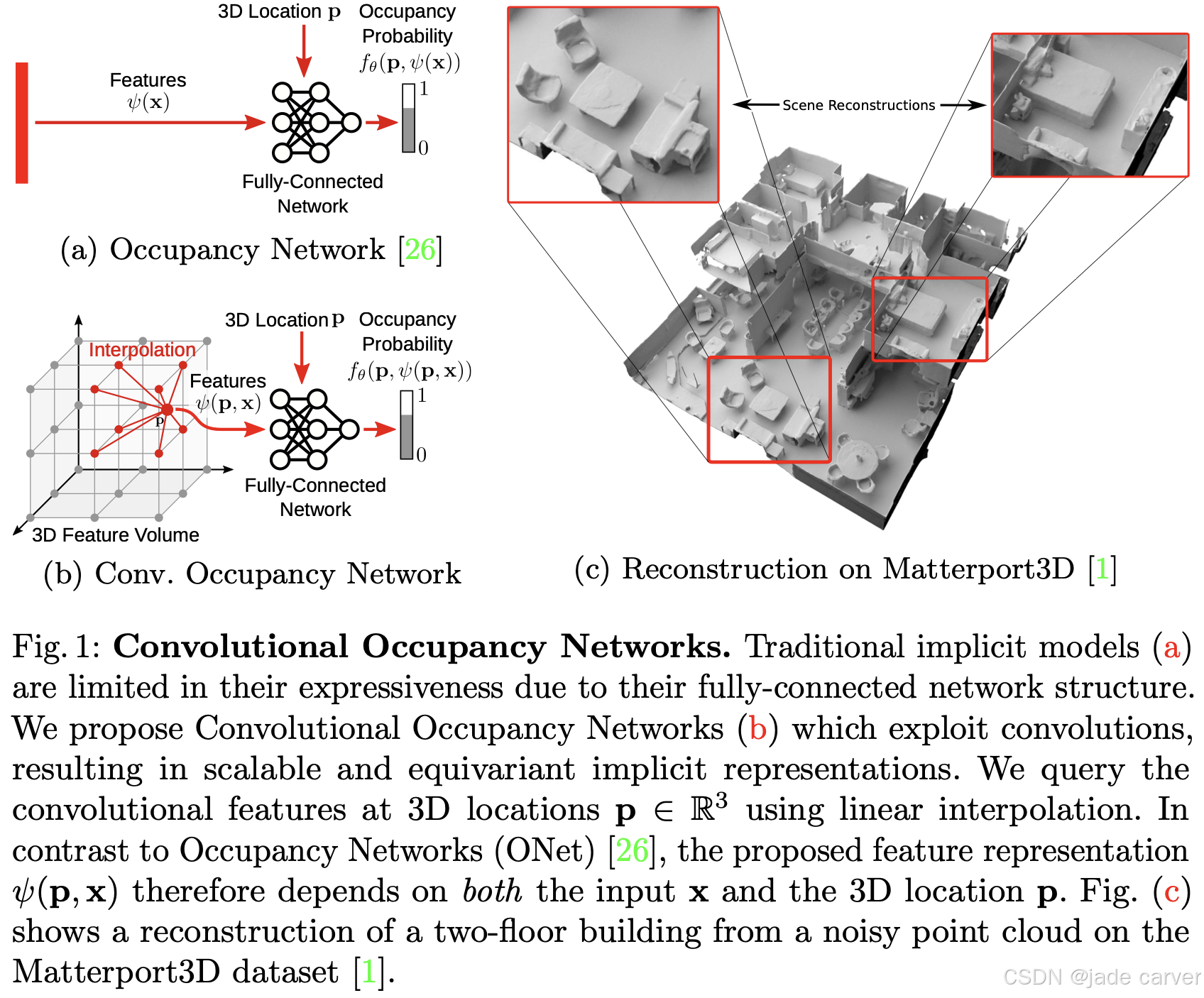
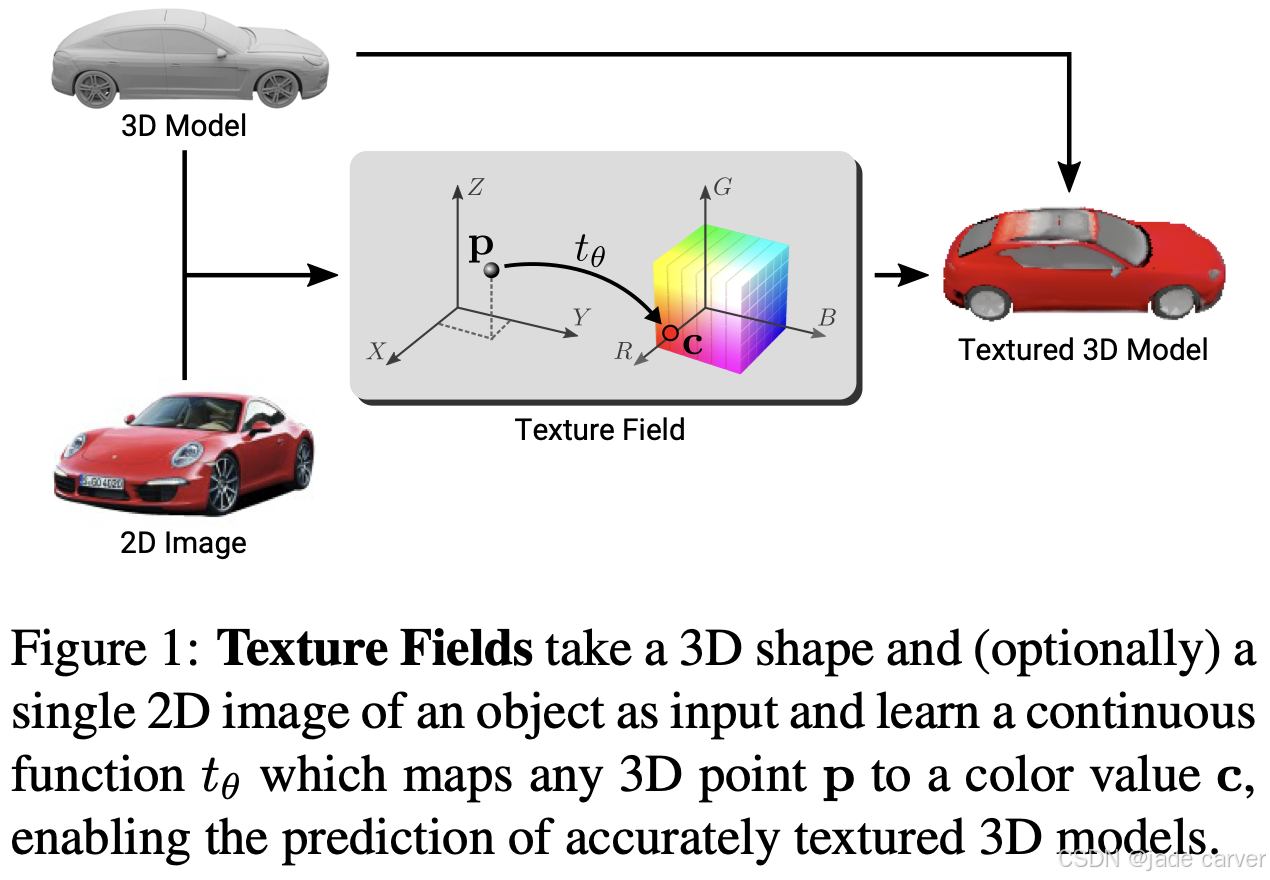
2.Joint geometry and appearance
将神经隐式表示从纯几何扩展出去,纹理场(Texture Fields)6 将学习到的纹理函数附着到隐式曲面上,实现了以前馈方式联合预测形状和外观。
隐式表面光场(Implicit Surface Light Fields)7 进一步统一了表面表示和辐射度表示。可微分体积渲染(Differentiable Volumetric Rendering)8 将隐式表面表示与可微分渲染连接起来,使得能够从图像中以前馈方式同时预测几何和新视角------弥合了重建与合成之间的差距,而这一方向后来通过体积密度场被NeRF所推广。这些工作是当前主流的基于NeRF和基于3DGS的流程的直接先驱。
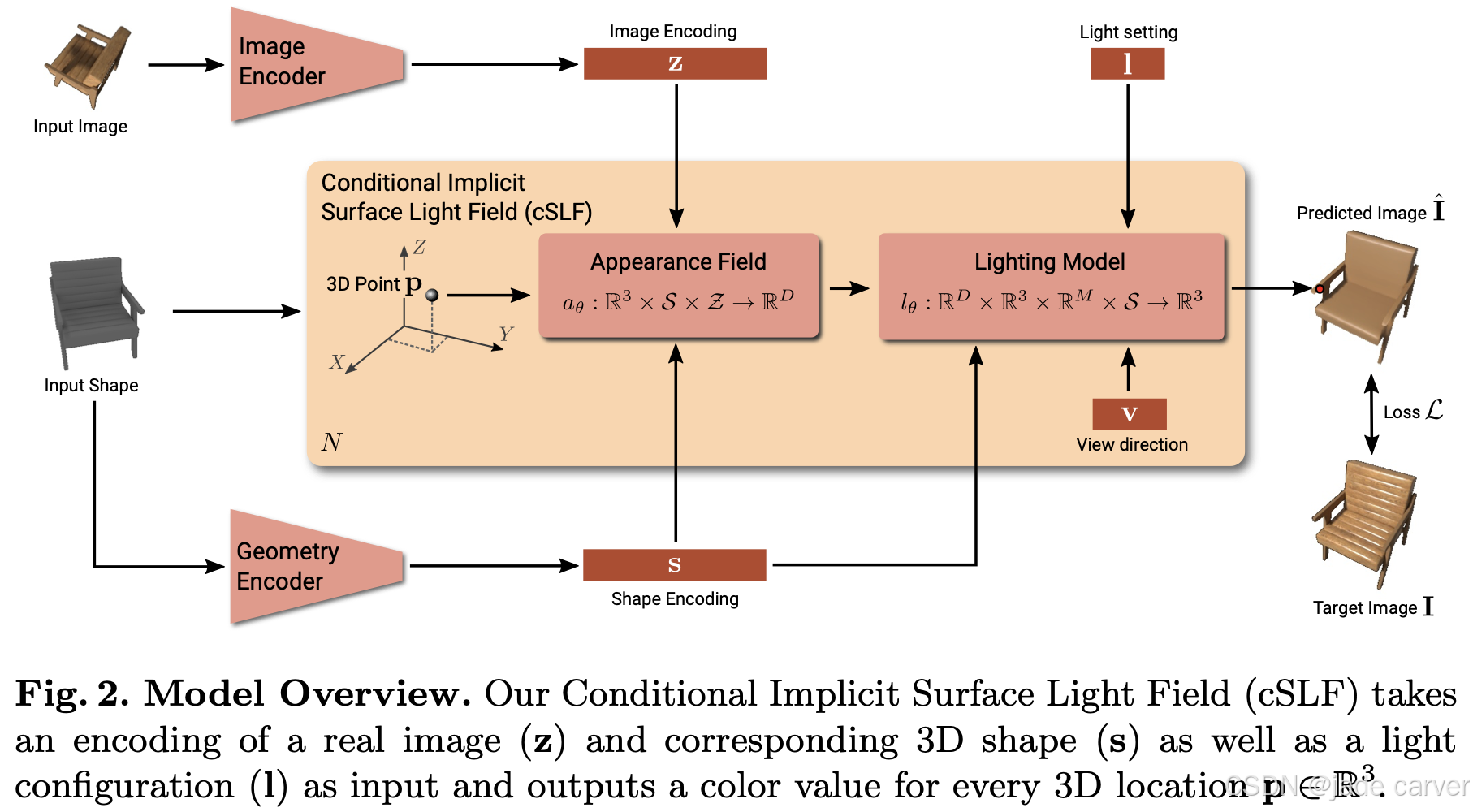
3.Light fields and SDF-based methods
光场网络 14 将场景表示为4D光场,无需体积光线行进即可实现实时渲染,其代价是在观测光线之外的 extrapolation 能力有限,且难以显式提取表面。基于有符号距离函数(SDF)的方法 65-70 擅长生成干净、无漏洞的表面,适用于下游几何处理,但其固有的平滑性先验可能导致对精细细节和薄结构的重建不足。
4.Explicit and hybrid representations
基于mesh的模型 71-73 能够与标准图形学和仿真流程直接兼容,但它们在表示拓扑复杂或半透明场景时面临困难。2DGS 27, 74 用带方向的2D圆盘取代体积高斯函数,以实现更紧密的表面耦合和更具几何一致性的重建,但其代价是牺牲了表示雾、透明度等体积现象的能力。
三平面表示 75-78 提供了一种紧凑且内存高效的中间形式,便于进行2D卷积处理,然而,对于与规范平面对齐不佳的几何结构,这种轴对齐分解方式可能会引入各向异性伪影。
5.Other specialized representations
无3D(3D-free)方法 79, 80 完全绕过显式的3D建模,采用纯数据驱动的架构,其优点是架构简单,但可能面临大视角变化下的几何不一致问题,并且无法恢复显式的3D结构。一些专用表示,如普吕克线场(Plücker line fields)81 和平面基元(planar primitives)82 表明,针对特定任务的几何先验可以在薄结构恢复、室内重建等目标领域中带来显著的性能提升。