《博主简介》
小伙伴们好,我是阿旭。
专注于计算机视觉领域,包括目标检测、图像分类、图像分割和目标跟踪等项目开发,提供模型对比实验、答疑辅导等。
《------往期经典推荐------》
二、机器学习实战专栏【链接】 ,已更新31期,欢迎关注,持续更新中~~
三、深度学习【Pytorch】专栏【链接】
四、【Stable Diffusion绘画系列】专栏【链接】
五、YOLOv8改进专栏【链接】,持续更新中~~
六、YOLO性能对比专栏【链接】,持续更新中~
《------正文------》
目录
- 引言
- 一、为什么自动化数据标注是必选项?
- 二、第一步:搭建稳定的AI开发环境
- 为什么必须用独立Conda环境?
- 三、第二步:视频抽帧,生成高质量训练样本
- 四、第三步:AI自动标注
- 五、第四步:可视化验证,确保标注质量
- 六、第五步:训练YOLO11模型
- 七、第六步:实战验证
- 八、常见问题解答
- 总结
引言
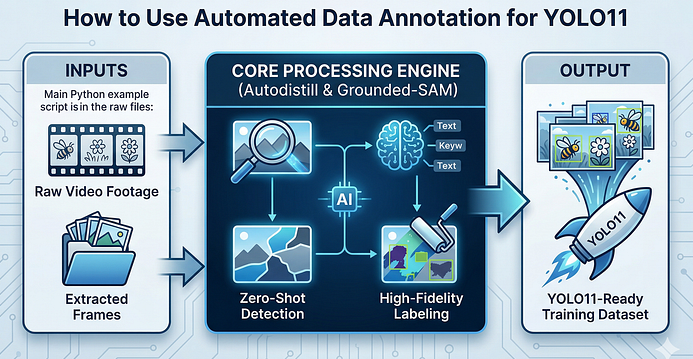
在2026年的计算机视觉(CV)开发中,打造高性能检测模型不该再是"手动标数据"的体力活。传统CV项目里,开发者往往要耗费数百小时手动框选目标、标注数据,很多雄心勃勃的项目都折在了这个"数据瓶颈"上。

而今天要分享的这套流程,能把原本数周的手动标注工作压缩到几分钟------通过Grounded-SAM和Autodistill搭建"教师-学生"模型架构,让AI自动识别并精准标注目标(比如蜜蜂、花朵),最终训练出可落地的YOLO11模型。无论你是做生物多样性研究、毕业设计,还是工业级检测应用,这套自动化数据标注流程都能让你把精力聚焦在模型优化和落地,而非重复劳动。
一、为什么自动化数据标注是必选项?
现代AI开发的核心瓶颈早已不是神经网络本身,而是高质量训练数据的生成。手动标注不仅效率低,还容易因疲劳、主观判断导致标注不一致;而自动化数据标注则依托预训练大模型(Grounded-SAM)的"零样本检测"能力,通过简单的文本指令就能批量生成高精度的边界框和分割掩码,既保证标注质量,又能处理远超人工规模的数据集。
整个流程的核心是"模型蒸馏":用大而强的Grounded-SAM(教师模型)自动标注数据,再把这些标注数据喂给轻量、高速的YOLO11(学生模型)训练,最终得到既精准又易部署的检测模型。
二、第一步:搭建稳定的AI开发环境
自动化标注依赖CUDA、PyTorch、Ultralytics等工具的特定版本,环境冲突是最容易踩的坑。因此第一步要搭建独立的Conda环境,避免全局库冲突,保证流程可复现。
为什么必须用独立Conda环境?
Conda环境能隔离项目依赖,确保CUDA 12.8、PyTorch 2.9.1等核心库的版本适配,让自动化标注脚本在不同机器上都能稳定运行。
环境配置代码
shell
# 1. 创建名为GroundedSam的虚拟环境(Python 3.11)
conda create --name GroundedSam python=3.11
# 2. 激活环境
conda activate GroundedSam
# 3. 检查NVIDIA编译器版本(确认CUDA 12.8)
nvcc --version
# 4. 安装适配CUDA 12.8的PyTorch套件
pip install torch==2.9.1 torchvision==0.24.1 torchaudio==2.9.1 --index-url https://download.pytorch.org/whl/cu128
# 5. 安装YOLO11核心库
pip install ultralytics==8.3.50
# 6. 安装自动化标注相关库
pip install autodistill==0.1.29 # Autodistill核心(模型蒸馏)
pip install autodistill-grounded-sam==0.1.0 # Grounded-SAM插件
pip install autodistill-yolov11==0.1.4 # YOLO11插件
pip install scikit-learn==1.6.1 # 数据分割与评估
pip install roboflow==1.1.50 # 数据集管理
pip install Transformers==4.29.2 # 模型权重管理
pip install opencv-python==4.11.0.86 # 图像处理(无头版本)三、第二步:视频抽帧,生成高质量训练样本
原始视频无法直接用于训练,需要先提取关键帧作为标注素材。用Supervision库抽帧比手动截图更高效:可自定义"帧间隔",既保证样本多样性,又避免冗余。
关键概念:帧间隔(FRAME_STRIDE)
帧间隔指每跳过多少帧保存一张图片,比如设为5,就是每5帧保存1张。合理的帧间隔能避免数据集全是相似画面,让模型学到更多视角,同时提升后续自动化标注的效率。

视频抽帧代码
python
import os
import supervision as sv
from tqdm import tqdm
# 配置路径(根据自己的文件位置修改)
VIDEO_DIR_PATH = "Trainvideos" # 原始视频路径
IMAGE_DIR_PATH = "D:/Data-Sets-Object-Detection/Bees/images" # 抽帧后图片保存路径
FRAME_STRIDE = 5 # 每5帧保存1张
# 筛选视频文件(仅处理mov/mp4)
video_paths = sv.list_files_with_extensions(
directory=VIDEO_DIR_PATH,
extensions=["mov","mp4"] )
print("找到的视频文件:", video_paths)
# 批量抽帧
for video_path in tqdm(video_paths) :
video_name = video_path.stem # 获取视频名(不含后缀)
image_name_pattern = video_name + "-{:05d}.png" # 生成图片命名规则
# 抽帧并保存
with sv.ImageSink(target_dir_path=IMAGE_DIR_PATH, image_name_pattern=image_name_pattern) as sink :
for image in sv.get_video_frames_generator(source_path=str(video_path), stride=FRAME_STRIDE) :
sink.save_image(image=image)
# 验证抽帧结果
image_paths = sv.list_files_with_extensions(
directory=IMAGE_DIR_PATH,
extensions=["png", "jpg", "jpeg"] )
print("抽帧完成!共提取图片数量:", len(image_paths))四、第三步:AI自动标注
这是自动化标注的核心步骤------用CaptionOntology(描述性本体)通过自然语言告诉AI要标注的目标。比如告诉它"a bee"对应标签"bee",Grounded-SAM就能基于预训练的语义理解能力,自动识别图片中的蜜蜂并标注,无需手动框选。
灵活适配任意目标
这套逻辑不局限于蜜蜂/花朵:只需修改文本指令(比如把"a bee"改成"一辆汽车""一个零件"),AI就能适配任意检测场景,堪称通用的自动化标注模板。
自动标注代码
python
from autodistill.detection import CaptionOntology
from autodistill_grounded_sam import GroundedSAM
# 1. 定义标注规则:自然语言描述 → 数据集标签
ontology = CaptionOntology({
"a bee" : "bee", # 识别蜜蜂,标注为bee
"a flower" : "flower" # 识别花朵,标注为flower
})
# 2. 配置路径(根据自身情况修改)
IMAGE_DIR_PATH = "D:/Data-Sets-Object-Detection/Bees/images" # 抽帧后的图片路径
DATASET_DIR_PATH = "D:/Data-Sets-Object-Detection/Bees/dataset" # 标注后数据集保存路径
# 3. 初始化Grounded-SAM模型,执行自动标注
base_model = GroundedSAM(ontology=ontology)
dataset = base_model.label(
input_folder=IMAGE_DIR_PATH,
output_folder=DATASET_DIR_PATH,
extension='.png'
)运行后,AI会自动生成YOLO格式的标注文件,甚至会帮你创建data.yaml配置文件(告诉YOLO数据集路径和类别),直接用于后续训练。
五、第四步:可视化验证,确保标注质量
虽然Grounded-SAM标注精度极高,但仍需抽样验证,避免因文本指令模糊导致标注错误。我们可以随机抽取16张标注后的图片,叠加边界框、分割掩码和标签,直观检查标注效果。
标注验证代码
python
import supervision as sv
from pathlib import Path
import random
# 配置路径
ANNOTATIONS_DIRECTORY_PATH = "D:/Data-Sets-Object-Detection/Bees/dataset/train/labels" # 标注文件路径
IMAGES_DIRECTORY_PATH = "D:/Data-Sets-Object-Detection/Bees/dataset/train/images" # 图片路径
DATA_YAML_PATH = "D:/Data-Sets-Object-Detection/Bees/dataset/data.yaml" # 配置文件路径
# 加载数据集
dataset = sv.DetectionDataset.from_yolo(
images_directory_path=IMAGES_DIRECTORY_PATH,
annotations_directory_path=ANNOTATIONS_DIRECTORY_PATH,
data_yaml_path=DATA_YAML_PATH)
print("标注数据集大小:", len(dataset))
# 配置可视化参数
SAMPLE_SIZE = 16 # 抽样数量
SAMPLE_GRID_SIZE = (4,4) # 展示网格(4×4)
SAMPLE_PLOT_SIZE = (16,10)# 展示尺寸
# 初始化标注可视化工具
mask_annotator = sv.MaskAnnotator() # 分割掩码标注器
box_annotator = sv.BoxAnnotator() # 边界框标注器
label_annotator = sv.LabelAnnotator() # 标签标注器
# 随机抽样
dataset_indices = list(range(len(dataset)))
random.shuffle(dataset_indices)
# 批量生成可视化图片
images = []
images_names = []
for i in dataset_indices[:SAMPLE_SIZE] :
image_path , image , annotation = dataset[i]
annotated_image = image.copy()
# 叠加分割掩码
annotated_image = mask_annotator.annotate(
scene=annotated_image,
detections=annotation)
# 叠加边界框
annotated_image = box_annotator.annotate(
scene=annotated_image,
detections=annotation)
# 叠加标签
annotated_image = label_annotator.annotate(
scene=annotated_image,
detections=annotation)
images_names.append(Path(image_path).name)
images.append(annotated_image)
# 展示可视化结果
sv.plot_images_grid(
images=images,
titles=images_names,
grid_size=SAMPLE_GRID_SIZE,
size=SAMPLE_PLOT_SIZE)六、第五步:训练YOLO11模型
有了高质量的自动化标注数据,训练YOLO11就成了"水到渠成"的事。这一步的核心是"模型蒸馏":把Grounded-SAM的"知识"浓缩到轻量的YOLO11中,得到既精准又高速的检测模型。
关键参数解释
- 轮次(Epoch):整个数据集完整过一遍神经网络算1个轮次,300轮能让模型充分学习目标特征,保证精度;
- 批次大小(Batch Size):32是兼顾GPU显存和训练效率的取值,显存不足可改为16;
- Patience:若40轮内模型精度无提升,自动停止训练,避免过拟合。
YOLO11训练代码
python
from ultralytics import YOLO
def main():
# 1. 加载预训练YOLO11小模型(yolo11s.pt)
model = YOLO("yolo11s.pt")
# 2. 配置数据集配置文件路径
config_file_path = "D:/Data-Sets-Object-Detection/Bees/dataset/data.yaml"
# 3. 配置训练结果保存路径
project = "d:/temp/model/Bees-model" # 项目根路径
experiment = "Bees-small" # 实验名称
# 4. 训练参数配置
batch_size = 32 # 批次大小(显存不足改16)
# 5. 执行训练
results = model.train(
data=config_file_path,
epochs = 300, # 训练轮次
project=project , # 结果保存根路径
name = experiment, # 实验名称
batch = batch_size , # 批次大小
device = 0 , # 使用第0块GPU(CPU训练可删此参数)
patience = 40 , # 早停阈值
imgsz=640 , # 输入图片尺寸
verbose = True, # 打印详细日志
val= True # 训练时同步验证
)
if __name__ == "__main__":
main()训练完成后,会生成best.pt权重文件------这就是可直接部署的YOLO11模型。
七、第六步:实战验证
最后一步是用未见过的测试视频验证模型效果,看看自动化标注训练出的模型能否在真实场景中精准检测目标。
视频推理代码
python
import cv2
import os
import matplotlib.pyplot as plt
from matplotlib.animation import FuncAnimation
from ultralytics import YOLO
# 1. 加载训练好的模型权重
WEIGHTS_PATH = "d:/temp/model/Bees-model/Bees-small/weights/best.pt"
model = YOLO(WEIGHTS_PATH)
# 2. 配置测试视频路径(修改为自己的测试视频)
INPUT_VIDEO_PATH = "Best-Object-Detection-models/Yolo-V11/GroundedSAM-Auto-Annotation - Bees/Videos/Test videos/test_video.mp4"
# 3. 配置输出视频路径
input_folder = os.path.dirname(INPUT_VIDEO_PATH)
input_filename = os.path.basename(INPUT_VIDEO_PATH)
output_video_path = os.path.join(input_folder , f"annotated_{input_filename}")
# 4. 打开测试视频
cap = cv2.VideoCapture(INPUT_VIDEO_PATH)
# 获取视频属性(分辨率、帧率)
frame_width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
frame_height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
fourcc = cv2.VideoWriter_fourcc(*"mp4v")
# 5. 初始化视频写入器(保存标注后的视频)
out = cv2.VideoWriter(output_video_path , fourcc , fps , (frame_width , frame_height))
# 6. 初始化Matplotlib可视化窗口
fig , ax = plt.subplots(figsize=(12,8))
frame_display = None
# 7. 定义帧处理函数(逐帧推理+标注)
def update_frame(_):
global frame_display
# 读取单帧
success , frame = cap.read()
if not success :
return
# YOLO11推理
results = model(frame)
# 叠加检测结果(边界框+标签)
annotated_frame = results[0].plot()
# 保存标注帧到输出视频
out.write(annotated_frame)
# 转换色彩空间(适配Matplotlib显示)
annotated_frame = cv2.cvtColor(annotated_frame , cv2.COLOR_BGR2RGB)
# 更新可视化窗口
if frame_display is None :
frame_display = ax.imshow(annotated_frame)
else :
frame_display.set_data(annotated_frame)
# 8. 配置可视化样式
plt.axis("off")
ani = FuncAnimation(fig , update_frame , interval=100 // fps)
# 9. 展示实时推理结果
plt.show()
# 10. 释放资源
cap.release()
out.release()
print(f"标注后的视频已保存至:{output_video_path}")八、常见问题解答
Q:自动化数据标注到底是什么?
A:依托预训练大模型,通过文本指令自动识别并标注图片中的目标,替代人工框选,大幅提升数据生成效率。
Q:Autodistill是免费的吗?
A:是的!Autodistill是Roboflow开发的开源框架,可免费使用大模型训练轻量检测模型。
Q:多少张图片能训练出好用的模型?
A:取决于场景复杂度,通常几百张自动化标注的高质量图片,就能训练出效果优秀的YOLO11模型。
Q:data.yaml文件有什么用?
A:YOLO的核心配置文件,定义了数据集路径、类别名称等关键信息,Autodistill会自动生成。
Q:Grounded-SAM标注比人工好吗?
A:速度上远超人工;精度上,对于有机形状(如蜜蜂、花朵)的标注一致性,往往优于人工。
总结
从原始视频到可落地的YOLO11模型,这套流程彻底绕开了"手动标注"的痛点。依托Grounded-SAM的零样本能力和Autodistill的模型蒸馏逻辑,我们把CV开发的核心从"体力活"拉回"创造力"------不用再纠结标注是否准确、数据是否足够,而是聚焦模型优化和业务落地。
2026年的CV开发,早已不是"谁标数据更快",而是"谁能更快把想法变成可用的模型"。这套自动化标注流程,就是你提升开发效率、构建竞争力的核心工具。

好了,这篇文章就介绍到这里,喜欢的小伙伴感谢给点个赞和关注,更多精彩内容持续更新~~
关于本篇文章大家有任何建议或意见,欢迎在评论区留言交流!