【论文总结】MobileSAM 是一个面向移动设备的轻量级分割模型,通过解耦蒸馏策略解决 SAM 模型在资源受限设备上的部署难题。将图像编码器和掩码解码器的耦合优化问题分解为两个独立步骤:(1)首先通过知识蒸馏将原始 SAM 的重量级图像编码器(ViT-H,632M 参数)的知识迁移到轻量级编码器(如 ViT-Tiny,5M 参数),让学生模型学习模仿教师模型的特征表示;(2)可选地微调掩码解码器以更好地适配新编码器。这种解耦策略避免了从头联合训练两个模块的优化困难,使得训练可以在单个 GPU 上一天内完成。最终模型比原始 SAM 小 60 多倍,推理速度达到每张图像 10ms(编码器 8ms + 解码器 4ms),比同期 FastSAM 快 5 倍且小 7 倍,同时保持了与原始 SAM 相当的分割性能,可在 CPU 上流畅运行,非常适合移动端应用场景。
ABSTRACT
Segment Anything Model (SAM) has attracted significant attention due to its impressive zero-shot transfer performance and high versatility for numerous vision applications (like image editing with fine-grained control). Many of such applications need to be run on resource-constraint edge devices, like mobile phones. In this work, we aim to make SAM mobile-friendly by replacing the heavyweight image encoder with a lightweight one. A naive way to train such a new SAM as in the original SAM paper leads to unsatisfactory performance, especially when limited training sources are available. We find that this is mainly caused by the coupled optimization of the image encoder and mask decoder, motivated by which we propose decoupled distillation. Concretely, we distill the knowledge from the heavy image encoder (ViT-H in the original SAM) to a lightweight image encoder, which can be automatically compatible with the mask decoder in the original SAM. The training can be completed on a single GPU within less than one day, and the resulting lightweight SAM is termed MobileSAM which is more than 60 times smaller yet performs on par with the original SAM. For inference speed, With a single GPU, MobileSAM runs around 10ms per image: 8ms on the image encoder and 4ms on the mask decoder. With superior performance, our MobileSAM is around 5 times faster than the concurrent FastSAM and 7 times smaller, making it more suitable for mobile applications. Moreover, we show that MobileSAM can run relatively smoothly on CPU. The code for our project is provided at MobileSAM, with a demo showing that MobileSAM can run relatively smoothly on CPU.
【翻译】Segment Anything Model(SAM)因其令人印象深刻的零样本迁移性能和对众多视觉应用(如具有细粒度控制的图像编辑)的高度通用性而受到广泛关注。许多此类应用需要在资源受限的边缘设备(如移动手机)上运行。在这项工作中,我们旨在通过用轻量级图像编码器替换重量级图像编码器来使 SAM 适配移动设备。按照原始 SAM 论文中的方法训练这样一个新 SAM 的简单方式会导致不令人满意的性能,特别是在可用训练资源有限的情况下。我们发现这主要是由图像编码器和掩码解码器的耦合优化引起的,受此启发,我们提出了解耦蒸馏。具体来说,我们将知识从重量级图像编码器(原始 SAM 中的 ViT-H)蒸馏到轻量级图像编码器,该编码器可以自动与原始 SAM 中的掩码解码器兼容。训练可以在单个 GPU 上在不到一天的时间内完成,由此产生的轻量级 SAM 被称为 MobileSAM,它比原始 SAM 小 60 多倍,但性能与原始 SAM 相当。在推理速度方面,使用单个 GPU,MobileSAM 每张图像运行约 10ms:图像编码器 8ms,掩码解码器 4ms。凭借卓越的性能,我们的 MobileSAM 比同期的 FastSAM 快约 5 倍,小约 7 倍,使其更适合移动应用。此外,我们展示了 MobileSAM 可以在 CPU 上相对流畅地运行。我们项目的代码在 MobileSAM 提供,并附有演示显示 MobileSAM 可以在 CPU 上相对流畅地运行。
1 Introduction
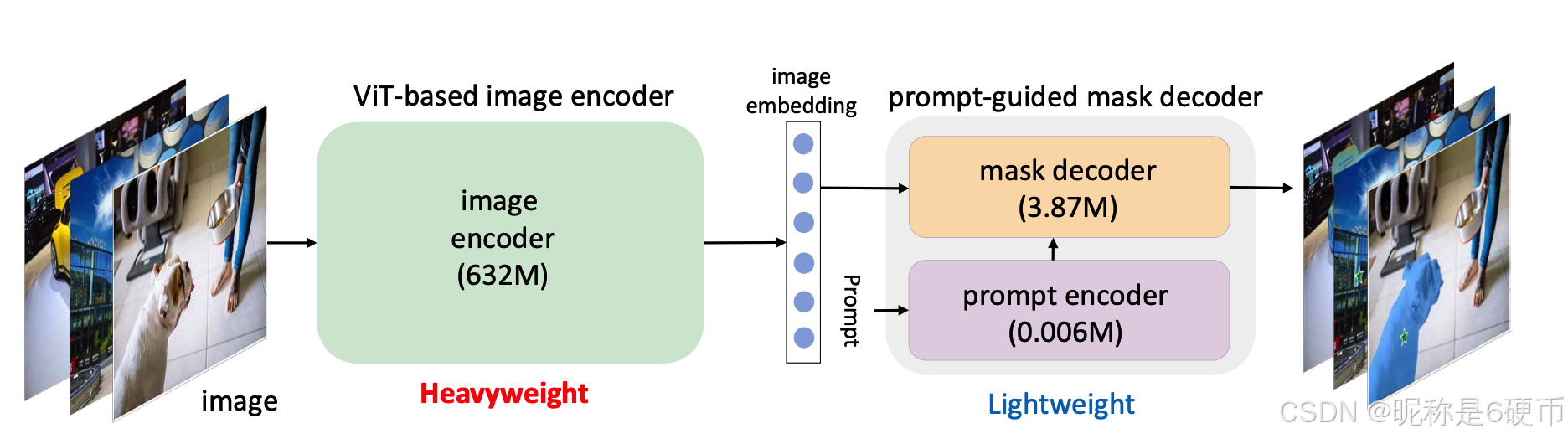
ChatGPT Zhang et al. 2023a has revolutionized the NLP field, marking a breakthrough in generative AI (AIGC, a.k.a Artificial intelligence generated content) Zhang et al. 2023b. What has made this possible lies in GPT-series models Brown et al. 2020, Radford et al. 2018, 2019, which are foundation models Bommasani et al. 2021 trained on web-scale text datasets. Following the success of foundation models in NLP, multiple works He et al. 2020, Qiao et al. 2023a, Zhang et al. 2022a have learned an image encoder together with a text encoder via contrastive learning He et al. 2020, Zhang et al. 2022b. Very recently, Meta Research team has released the "Segment Anything" project Kirillov et al. 2023, where a prompt-guided vision foundation termed SAM has been proposed and is believed to be a GPT moment for vision. SAM consists of two components: ViT-based image encoder and prompt-guided mask decoder, which work in sequence (see Figure 1).
Since its advent, SAM has attracted significant attention for multiple reasons. First, it is the first to show that vision can follow NLP to pursue a path that combines foundation model with prompt engineering. Second, it is the first to perform label-free segmentation, a fundamental vision task that is in parallel to label prediction Zhang et al. 2023c. Moreover, this fundamental task makes SAM compatible with other models to realize advanced vision applications, like text-guided segmentation and image editing with fine-grained control. Many of such use cases, however, need to be run on resource-constrained edge-devices, like mobile apps. As shown in the official demo, with a processed image embedding, the SAM can work on resource-constrained devices because the mask decoder is lightweight. What makes the SAM pipeline computation heavy lies in the huge image encoder. In this work, we investigate how to obtain a lightweight SAM suitable for resource-constrained mobile devices, which is therefore termed MobileSAM.
【翻译】自问世以来,SAM 因多种原因引起了广泛关注。首先,它是第一个展示视觉可以遵循 NLP 的路径,将基础模型与提示工程相结合的模型。其次,它是第一个执行无标签分割的模型,这是一个与标签预测并行的基础视觉任务 Zhang 等人 2023c。此外,这个基础任务使 SAM 能够与其他模型兼容,以实现高级视觉应用,如文本引导分割和具有细粒度控制的图像编辑。然而,许多此类用例需要在资源受限的边缘设备(如移动应用)上运行。如官方演示所示,有了处理过的图像嵌入,SAM 可以在资源受限的设备上工作,因为掩码解码器是轻量级的。使 SAM 流程计算量大的原因在于巨大的图像编码器。在这项工作中,我们研究如何获得适合资源受限移动设备的轻量级 SAM,因此称为 MobileSAM。
【解析】无标签分割(label-free segmentation)是 SAM 的创新,传统的分割模型需要预定义类别(如"猫"、"狗"),只能分割训练时见过的类别,而 SAM 不需要知道物体是什么类别,只需要根据提示就能将其从背景中分割出来。SAM实际部署时面临挑战,图像编码器基于 ViT-H,有超过 600M 参数,需要大量计算资源。一旦图像编码完成,后续的交互式分割(用户点击不同位置生成不同掩码)都很快,因为只需要运行轻量的解码器。因此,本文的核心目标就是用轻量级编码器替换 ViT-H,同时保持分割性能。
Figure 1: The overview of Segment Anything Model.
【翻译】图 1:Segment Anything Model 的概览。
Given that the default image encoder in the SAM is based on ViT-H, a straightforward way to obtain MobileSAM is to follow the official pipeline in Kirillov et al. 2023 to retrain a new SAM with a smaller image encoder like replacing the ViT-H with a smaller ViT-L or even smaller ViT-B.
【解析】这里提出了最直接决方案,保持 SAM 的整体架构和训练流程不变,只是把图像编码器换成更小的版本,然后在相同的数据集上重新训练整个模型。简单直接,不需要设计新的训练策略。但问题在于,原始 SAM 的训练需要 256 个 A100 GPU 运行 68 小时,即使换成 ViT-L 或 ViT-B 也需要 128 个 GPU,这是难以承受的计算成本,此外,重新训练的方式存在优化困难,因为图像编码器和掩码解码器需要同时从头学习如何协同工作,这是一个耦合优化问题。当两个模块都处于未训练好的状态时,它们相互依赖又相互制约,训练过程容易陷入局部最优或收敛缓慢。
Table 1: Parameters SAM with different image encoders.
【翻译】表 1:使用不同图像编码器的 SAM 参数。
The parameters of SAM with different variants of image encoder are summarized in Table 1. As stated in Kirillov et al. 2023, training a new SAM with ViT-L or ViT-B as the image encoder requires 128 GPUs for multiple days. Such resource-intensive retraining can be a non-trivial burden to reproduce or improve their results. This optimization difficulty mainly comes from the coupled optimization of the image encoder and mask decoder. Motivated by this understanding, we propose to decouple the optimization of the image encoder and mask decoder. Concretely, we first distill the knowledge from the default image encoder ViT-H to a tiny ViT. After that, we can finetune the mask decoder in the original SAM to better align with the distilled image encoder. It is worth highlighting that the alignment optimization is optional because the fact that the lightweight image encoder is distilled from the default image encoder guarantees its inherent alignment with the default mask decoder.
【翻译】使用不同图像编码器变体的 SAM 参数总结在表 1 中。如 Kirillov 等人 2023 所述,使用 ViT-L 或 ViT-B 作为图像编码器训练新的 SAM 需要 128 个 GPU 运行多天。这种资源密集型的重新训练对于复现或改进他们的结果来说是一个不小的负担。这种优化困难主要来自图像编码器和掩码解码器的耦合优化。受此理解的启发,我们提出解耦图像编码器和掩码解码器的优化。具体来说,我们首先将知识从默认的图像编码器 ViT-H 蒸馏到一个微型 ViT。之后,我们可以微调原始 SAM 中的掩码解码器,以更好地与蒸馏后的图像编码器对齐。值得强调的是,对齐优化是可选的,因为轻量级图像编码器是从默认图像编码器蒸馏而来的事实保证了它与默认掩码解码器的固有对齐。
【解析】提出了本文的核心创新点------解耦蒸馏策略。首先需要理解什么是耦合优化问题。在原始 SAM 的训练中,图像编码器和掩码解码器是同时训练的,它们之间存在强依赖关系:编码器生成的特征质量直接影响解码器的学习效果,而解码器的梯度反向传播又会影响编码器的参数更新。当两个模块都处于未优化状态时,这种相互依赖会导致训练不稳定,容易陷入次优解,需要大量的计算资源和精心的超参数调整才能收敛。
By turning the problem of seeking a new SAM pipeline into a decoupled distillation, our approach has the advantage of being simple, and effective, while being reproducible at a low cost (on a single GPU with less than a day). The resulting MobileSAM reduces the encoder parameters by 100 times and total parameters by 60 times yet. Surprisingly, such a lightweight MobileSAM performs on par with the original heavyweight SAMs, which constitutes a significant step for pushing SAM for mobile applications. For the inference with MobileSAM, a single image takes runs only around 10 m s 10\mathrm{ms} 10ms : 8ms on the image encoder and 4ms on the mask decoder. It is worth highlighting that our MobileSAM is around 5 times faster and 7 times smaller than the concurrent FastSAM Zhao et al. 2023, while achieving superior performance.
【翻译】通过将寻求新 SAM 流程的问题转化为解耦蒸馏,我们的方法具有简单、有效的优势,同时可以以低成本复现(在单个 GPU 上不到一天)。由此产生的 MobileSAM 将编码器参数减少了 100 倍,总参数减少了 60 倍。令人惊讶的是,这样一个轻量级的 MobileSAM 的性能与原始的重量级 SAM 相当,这为推动 SAM 在移动应用中的应用迈出了重要一步。对于 MobileSAM 的推理,单张图像仅需约 10 m s 10\mathrm{ms} 10ms:图像编码器 8ms,掩码解码器 4ms。值得强调的是,我们的 MobileSAM 比同期的 FastSAM Zhao 等人 2023 快约 5 倍,小约 7 倍,同时实现了更优越的性能。
SAM: generalization and versatility. Since its advent in early April of this year, numerous projects and papers have emerged to investigate SAM from different perspectives. Given that SAM claims to segment anything, a line of works has reported its performance in real-world situations, including medical images Ma and Wang 2023, Zhang et al. 2023d, camouflaged objects Tang et al. 2023, and transparent objects Han et al. 2023. The findings consistently show that SAM works well in general setups, but not in the above challenging setups. Another significant research direction has focused on enhancing SAM to improve its practicality. Attack-SAM Zhang et al. 2023e has shown that the output masks of SAM can be easily manipulated by adversarial attacks through maliciously generated adversarial perturbations. Another work Qiao et al. 2023b further conducts a comprehensive robustness evaluation of SAM, ranging from style transfer and common corruptions to local occlusion and adversarial perturbation. It is found in Qiao et al. 2023b SAM has high robustness but not for adversarial perturbation, which aligns well with the finding in Zhang et al. 2023e. Another line of work focuses on demonstrating the versatility of SAM. Grounded SAM IDEA-Research 2023 is the pioneering work to combine Grounding DINO Liu et al. 2023a with SAM for segmenting anything with text inputs. Specifically, it relies on Grounding DINO to generate a bounding box from text and then the generated box can be used as a prompt to segment the mask. SAM predicts masks without labels and multiple works Chen et al. 2023, Park 2023 combine SAM with other models such as CLIP Radford et al. 2021 to semantically segment anything. Beyond object segmentation, multiple works have also shown its versatility in other fields, including image editing Rombach et al. 2022, as well as inpainting tasks Yu et al. 2023, object tracking within videos Yang et al. 2023, Zxyang 2023. Beyond 2D vision, the investigation of SAM has also been extended to 3D object reconstruction Shen et al. 2023, Kang et al. 2022, demonstrating its capabilities in assisting 3D model generation from a single image. For a complete survey of SAM, the readers are suggested to refer to Zhang et al. 2023c.
【翻译】SAM:泛化性和多功能性。自今年 4 月初问世以来,已经出现了大量项目和论文从不同角度研究 SAM。鉴于 SAM 声称可以分割任何东西,一系列工作报告了其在现实世界情况下的性能,包括医学图像 Ma 和 Wang 2023,Zhang 等人 2023d,伪装物体 Tang 等人 2023,以及透明物体 Han 等人 2023。研究结果一致表明,SAM 在一般设置中表现良好,但在上述具有挑战性的设置中表现不佳。另一个重要的研究方向集中在增强 SAM 以提高其实用性。Attack-SAM Zhang 等人 2023e 表明,SAM 的输出掩码可以通过恶意生成的对抗性扰动轻易被对抗性攻击操纵。另一项工作 Qiao 等人 2023b 进一步对 SAM 进行了全面的鲁棒性评估,范围从风格迁移和常见损坏到局部遮挡和对抗性扰动。Qiao 等人 2023b 发现 SAM 具有高鲁棒性,但对对抗性扰动不具有鲁棒性,这与 Zhang 等人 2023e 的发现非常一致。另一条工作线专注于展示 SAM 的多功能性。Grounded SAM IDEA-Research 2023 是将 Grounding DINO Liu 等人 2023a 与 SAM 结合以使用文本输入分割任何东西的开创性工作。具体来说,它依赖 Grounding DINO 从文本生成边界框,然后生成的框可以用作提示来分割掩码。SAM 在没有标签的情况下预测掩码,多项工作 Chen 等人 2023,Park 2023 将 SAM 与其他模型(如 CLIP Radford 等人 2021)结合以语义分割任何东西。除了物体分割,多项工作还展示了其在其他领域的多功能性,包括图像编辑 Rombach 等人 2022,以及修复任务 Yu 等人 2023,视频中的物体跟踪 Yang 等人 2023,Zxyang 2023。除了 2D 视觉,SAM 的研究还扩展到 3D 物体重建 Shen 等人 2023,Kang 等人 2022,展示了其在从单张图像辅助生成 3D 模型方面的能力。有关 SAM 的完整综述,建议读者参考 Zhang 等人 2023c。
【解析】讲述 SAM 发布后学术界的研究方向。首先是泛化性测试,SAM训练数据主要来自自然图像,对特定领域的适应能力有限。第二个方向是鲁棒性评估。对抗性攻击通过在输入图像中添加人眼难以察觉的微小扰动,就能让模型产生完全错误的输出。Attack-SAM 的研究表明 SAM 对这类攻击很脆弱,攻击者可以通过精心设计的扰动让 SAM 生成错误的分割掩码。Qiao 等人的工作更全面,测试了风格迁移(如将照片转为油画风格)、常见损坏(如模糊、噪声)、局部遮挡(部分物体被遮挡)等情况。结果显示 SAM 对自然变化有较强的抵抗力,但对精心设计的对抗性扰动仍然脆弱,这是深度学习模型的普遍问题。第三个方向是功能扩展。Grounded SAM 是重要突破,它解决了 SAM 的一个关键限制:SAM 需要人工提供提示(点击或框选),无法直接理解文本描述。Grounding DINO 是一个能够根据文本描述在图像中定位物体的模型,它输出边界框,这个框正好可以作为 SAM 的提示输入。两者结合实现了"用文字描述想要分割的物体"的功能。另一个扩展是语义分割,SAM 只能分割出物体形状,不知道物体是什么类别。通过结合 CLIP(一个理解图像和文本对应关系的模型),可以给分割出的区域打上语义标签,实现"既知道在哪里,也知道是什么"。
ViT: lightweight and efficient. Early mobile vision applications have been mainly powered by lightweight CNNs, such as MobileNet Howard et al. 2017 and its improved varinats Sandler et al. 2018, Howard et al. 2019. The core idea of MobileNet lies in separating a normal convolution block into depth-wise convolution and point-wise convolution, which significantly reduces the mode parameters and computation time. Since the advent of ViT Dosovitskiy et al. 2021, numerous works have attempted to make it lightweight and efficient. Complementary to ViT-Huge (ViT-H), ViT-Large (ViT-L), ViT-Base (ViT-B) in the original ViT paper Dosovitskiy et al. 2021, smaller ViTs are introduced in Touvron et al. 2020 and are denoted as Deit-Small (Deit-S) and Deit-Tiny (Deit-T) ViT-Small and ViT-Tiny. MobileViT Mehta and Rastegari 2021 is a pioneering work to combine ViT with standard convolutions for improving its performance, which outperforms MobileNet v2 Sandler et al. 2018. The main motivation is to exploit the local representation capability of CNN, and this practice is followed by multiple follow-up works which aim to enhance the model speed, including EfficientFormer Li et al. 2022a, EfficientViT Liu et al. 2023b, Next-ViT Li et al. 2022b and Tiny-ViT Wu et al. 2022. The recent progress in lightweight and faster ViT is complementary to our proposed decoupled distillation towards making the next-generation SAM suitable for resource-constrained mobile devices.
【翻译】ViT:轻量化和高效化。早期的移动视觉应用主要由轻量级 CNN 驱动,如 MobileNet Howard 等人 2017 及其改进变体 Sandler 等人 2018,Howard 等人 2019。MobileNet 的核心思想在于将普通卷积块分离为深度卷积和逐点卷积,这显著减少了模型参数和计算时间。自 ViT Dosovitskiy 等人 2021 问世以来,许多工作试图使其轻量化和高效化。作为原始 ViT 论文 Dosovitskiy 等人 2021 中 ViT-Huge (ViT-H)、ViT-Large (ViT-L)、ViT-Base (ViT-B) 的补充,Touvron 等人 2020 引入了更小的 ViT,记为 Deit-Small (Deit-S) 和 Deit-Tiny (Deit-T) ViT-Small 和 ViT-Tiny。MobileViT Mehta 和 Rastegari 2021 是将 ViT 与标准卷积结合以提高其性能的开创性工作,其性能优于 MobileNet v2 Sandler 等人 2018。主要动机是利用 CNN 的局部表示能力,这一做法被多个后续工作所遵循,这些工作旨在提高模型速度,包括 EfficientFormer Li 等人 2022a,EfficientViT Liu 等人 2023b,Next-ViT Li 等人 2022b 和 Tiny-ViT Wu 等人 2022。轻量化和更快的 ViT 的最新进展与我们提出的解耦蒸馏相辅相成,旨在使下一代 SAM 适用于资源受限的移动设备。
Background on SAM. Here, we first summarize the structure of SAM and how it works. SAM consists of a ViT-based image encoder and a prompt-guided mask decoder. The image encoder takes the image as the input and generates an embedding, which is then fed to the mask decoder. The mask decoder generates a mask to cut out any object from the background based on a prompt like a point (or box). Moreover, SAM allows generating multiple masks for the same prompt for addressing the ambiguity issue, which provides valuable flexibility. Considering this, this work maintains the pipeline of SAM to first adopt a ViT-based encoder to generate image embedding and then to adopt a prompt-guided decoder to generate the desired mask. This pipeline is optimally designed for the "segment anything", which can be used for the downstream task of "segment everything" (see Sec. 4.3 for more discussion).
【翻译】SAM 的背景。首先,我们总结 SAM 的结构及其工作原理。SAM 由基于 ViT 的图像编码器和提示引导的掩码解码器组成。图像编码器将图像作为输入并生成嵌入,然后将其馈送到掩码解码器。掩码解码器根据提示(如点或框)生成掩码,从背景中分割出任何物体。此外,SAM 允许为同一提示生成多个掩码以解决歧义问题,这提供了宝贵的灵活性。考虑到这一点,本工作保持 SAM 的流程,首先采用基于 ViT 的编码器生成图像嵌入,然后采用提示引导的解码器生成所需的掩码。该流程针对"分割任何东西"进行了优化设计,可用于"分割所有东西"的下游任务(更多讨论见第 4.3 节)。
Project goal. The goal of this project is to generate a mobile-friendly SAM (MobileSAM) that achieves satisfactory performance in a lightweight manner and is much faster than the original SAM. The prompt-guided mask decoder in the original SAM has less than 4M parameters and is thus considered lightweight. Given an image embedding processed by the encoder, as shown in their public demo, SAM can work in resource-constrained devices since the mask decoder is lightweight. However, the default image encoder in the original SAM is based on ViT-H with more than 600M parameters, which is very heavyweight and makes the whole SAM pipeline incompatible with mobile devices. Therefore, the key to obtaining a mobile-friendly SAM lies in replacing the heavyweight image encoder with a lightweight one, which also automatically keeps all its functions and characteristics of the original SAM. In the following, we elaborate on our proposed method for achieving this project goal.
【翻译】项目目标。本项目的目标是生成一个移动友好的 SAM(MobileSAM),以轻量级方式实现令人满意的性能,并且比原始 SAM 快得多。原始 SAM 中的提示引导掩码解码器参数少于 4M,因此被认为是轻量级的。如其公开演示所示,给定编码器处理的图像嵌入,SAM 可以在资源受限的设备上工作,因为掩码解码器是轻量级的。然而,原始 SAM 中的默认图像编码器基于 ViT-H,参数超过 600M,非常重量级,使得整个 SAM 流程与移动设备不兼容。因此,获得移动友好 SAM 的关键在于用轻量级编码器替换重量级图像编码器,同时自动保留原始 SAM 的所有功能和特性。接下来,我们详细阐述实现这一项目目标的方法。
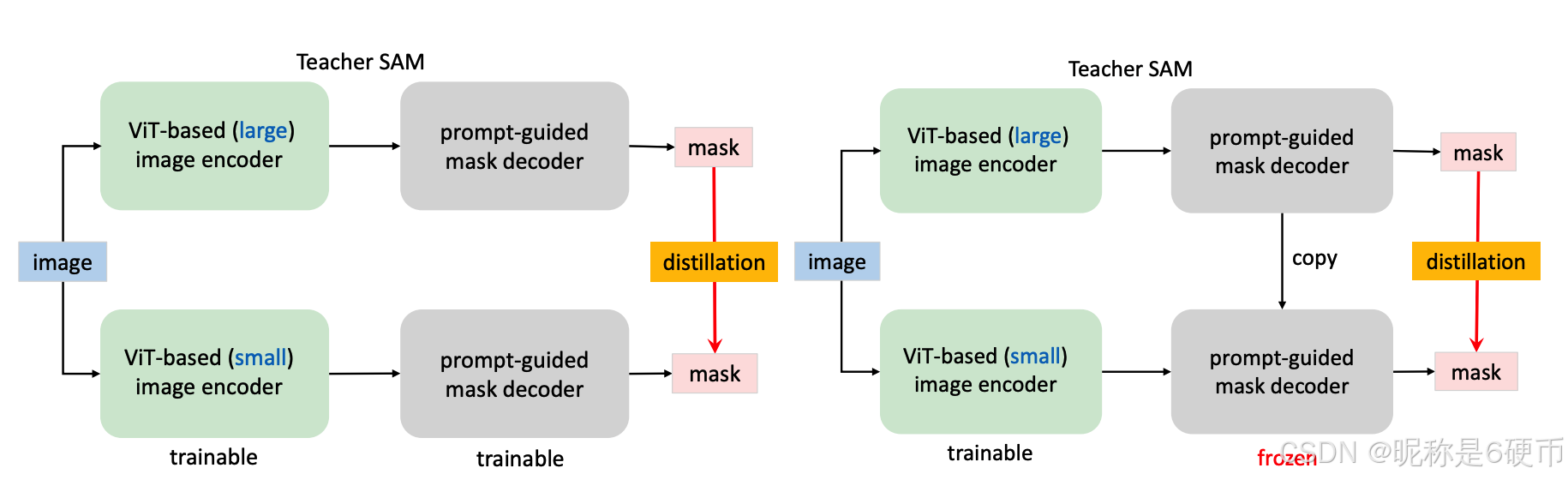
Coupled distillation. A straightforward way to realize our project goal is to follow the official pipeline in Kirillov et al. 2023 to retrain a new SAM with a smaller image encoder. As stated in Kirillov et al. 2023, training a SAM with ViT-H image encoder requires takes 68 hours on 256 A100 GPUs. Replacing the ViT-H with ViT-L or ViT-B reduces the required GPUs to 128, which is still a non-trivial burden for many researchers in the community to reproduce or improve their results. Following their approach, we can further adopt an even smaller image encoder and retrain a new SAM with their provided segmentation dataset which is 11-T. Note that the masks in the provided dataset are given by the pretrained SAM (with the ViT image encoder). In essence, this retraining process is knowledge distillation Hinton et al. 2015, which transfers the knowledge from a ViT-H-based SAM to a SAM with a smaller image encoder (see Figure 2 left).
Figure 2: Coupled knowledge distillation of SAM. The left subfigure denotes the fully-coupled distillation, while the right one represents the semi-coupled distillation.
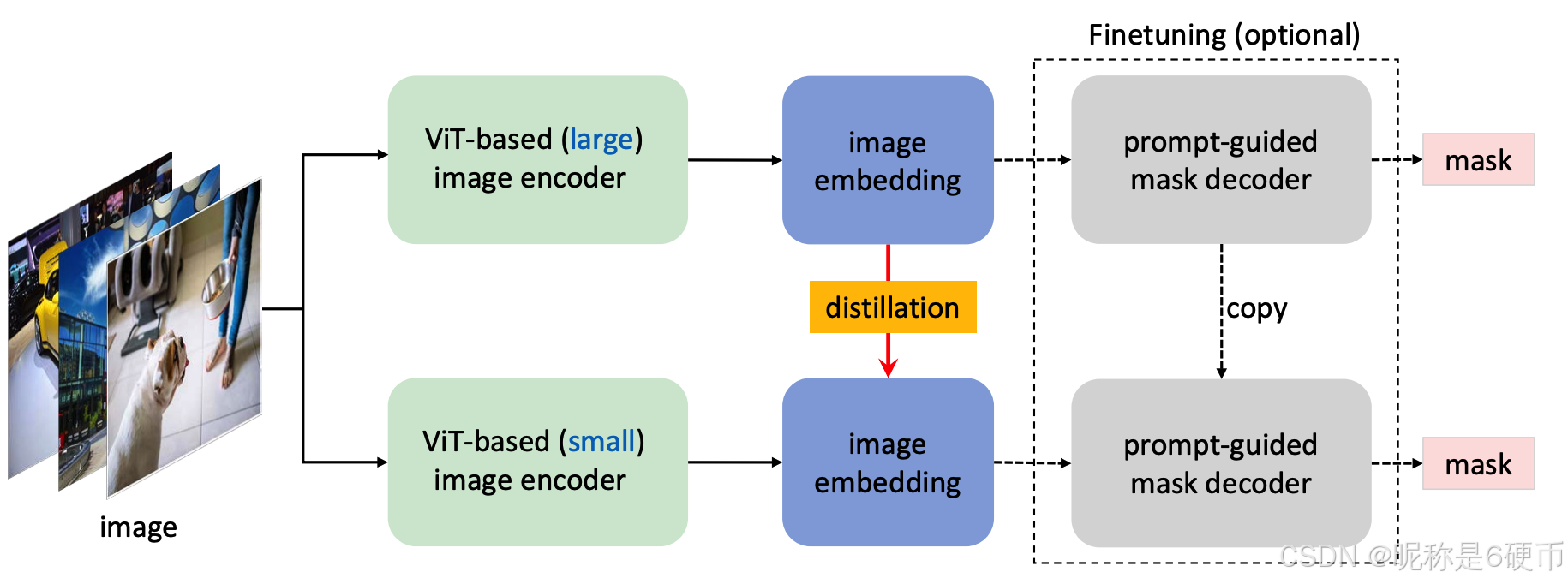
From semi-coupled to decoupled distillation. When performing a KD from the original SAM to that with a smaller image encoder, the difficulty mainly lies in a coupled optimization of the image encoder and combined decoder. Intuitively, the optimization of the image encoder depends on the quality of the image decoder, and vice versa. When the two modules in the SAM are both in a bad state, it is more challenging to train them both to a good state. Inspired by the divide-and-conquer algorithm Zhang et al. 2022c, we propose to divide the KD task into two sub-tasks: image encoder distillation and mask decoder finetuning. Concretely, we first perform the KD on the image encoder by transferring the knowledge from ViT-H to a smaller encoder. Since the mask decoder in the original SAM is already lightweight, we plan to keep its architecture. This brings a benefit of a readily used combined decoder for finetuning instead of training it from scratch. To alleviate the optimization issue of coupled distillation, a straightforward way is to optimize the image encoder with a copied and frozen mask decoder (see Figure 2 right). The freezing operation can help prevent the quality of the mask decoder from being deteriorated by a poor image encoder. We call this distillation semi-coupled because the optimization of the image encoder is still not fully decoupled from the mask decoder. Empirically, we find that this optimization is still challenging because the choice of a prompt is random, which makes the mask decoder variable and thus increases the optimization difficulty. Therefore, we propose to distill the small image encoder directly from the ViT-H in the original SAM without resorting to the combined decoder, which is termed decoupled distillation (see Figure 3). Another advantage of performing distillation on the image embedding is that we can adopt a simple MSE loss instead of using a combination of focal loss Lin et al. 2017 and dice loss Milletari et al. 2016 for making the mask prediction as in Kirillov et al. 2023.
【翻译】从半耦合到解耦蒸馏。当从原始 SAM 对具有更小图像编码器的 SAM 进行知识蒸馏时,主要困难在于图像编码器和组合解码器的耦合优化。直观地说,图像编码器的优化依赖于图像解码器的质量,反之亦然。当 SAM 中的两个模块都处于不良状态时,将它们都训练到良好状态更具挑战性。受分治算法 Zhang 等人 2022c 的启发,我们提出将知识蒸馏任务分为两个子任务:图像编码器蒸馏和掩码解码器微调。具体来说,我们首先通过将知识从 ViT-H 转移到更小的编码器来对图像编码器进行知识蒸馏。由于原始 SAM 中的掩码解码器已经是轻量级的,我们计划保持其架构。这带来了一个好处,即可以直接使用现成的组合解码器进行微调,而不是从头开始训练它。为了缓解耦合蒸馏的优化问题,一个直接的方法是使用复制的冻结掩码解码器来优化图像编码器(见图 2 右侧)。冻结操作可以帮助防止掩码解码器的质量因较差的图像编码器而恶化。我们称这种蒸馏为半耦合,因为图像编码器的优化仍然没有完全与掩码解码器解耦。经验上,我们发现这种优化仍然具有挑战性,因为提示的选择是随机的,这使得掩码解码器可变,从而增加了优化难度。因此,我们提出直接从原始 SAM 中的 ViT-H 蒸馏小型图像编码器,而不依赖于组合解码器,这被称为解耦蒸馏(见图 3)。在图像嵌入上执行蒸馏的另一个优势是,我们可以采用简单的 MSE 损失,而不是像 Kirillov 等人 2023 中那样使用焦点损失 Lin 等人 2017 和 Dice 损失 Milletari 等人 2016 的组合来进行掩码预测。
Figure 3: Decoupled distillation for SAM.
【翻译】图 3:SAM 的解耦蒸馏。
On the necessity of mask decoder finetuning. Unlike the semi-coupled distillation, the above decoupled distillation yields a lightweight image encoder that might not align well with the original frozen mask decoder. Empirically, we find that this is not true because the generated image encoding from the student image encoder can be sufficiently close to that of the original teacher encoder, which renders finetuning on the combined decoder in the second stage optional.
It is expected that finetuning the mask decoder on the frozen lightweight image encoder or jointly finetuning them together might further improve the performance.
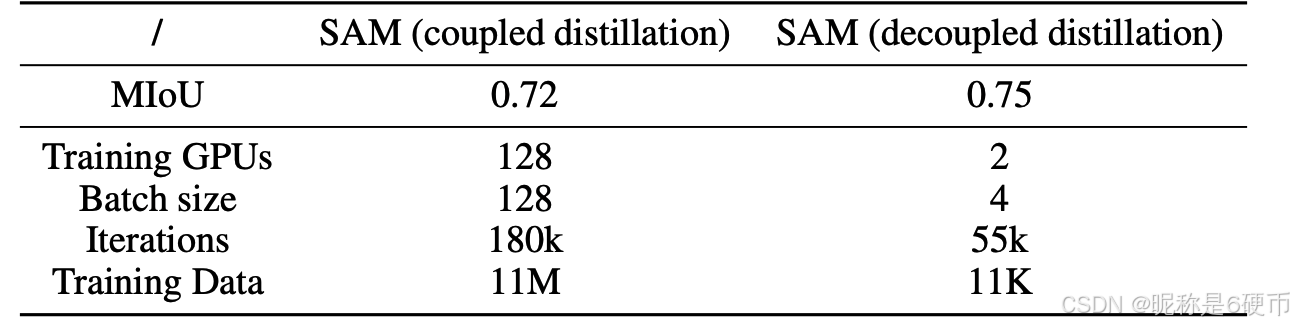
Preliminary evaluation. Here, we conduct a preliminary investigation to compare coupled distillation and decoupled distillation. Here, for performance evaluation, we compute the mIoU between the two masks generated by the teacher SAM and student SAM on the same prompt point. Intuitively, a higher mIoU indicates a higher mask prediction performance by assuming that the mask generated by ViT-H is ground-truth. For the coupled distillation, we adopt the SAM with ViT-B provided in the original SAM Kirillov et al. 2023. It was trained on SA-1B (11M images) on 128 GPUs (1 sample per GPU) for 180 k 180\mathrm{k} 180k iterations. By contrast, in our decoupled distillation setup, we train the model on 2 GPUs (two samples per GPU to save computation resources) on 0.1 % 0.1\% 0.1% samples of SA-1B dataset (11k) images for 55 k 55\mathrm{k} 55k iterations. Overall, decoupled distillation takes less than 1 % 1\% 1% of the computation resources than coupled distillation, while achieving a superior performance of mIoU of 0.75 vs 0.72 for the coupled sit (averaged on 200 samples). Since ViT-B is still a non-trivial burden for mobile devices, therefore in the following we experiment with a TinyViT (with 5M parameters) Wu et al. 2022 based on our proposed decoupled distillation.
Table 2: Comparison of coupled distillation and decoupled distillation fro SAM with ViT-B as the image encoder. Decoupled distillation performs better and requires less than 1 % 1\% 1% computation resources than coupled distillation.
【翻译】表 2:以 ViT-B 作为图像编码器的 SAM 的耦合蒸馏和解耦蒸馏的比较。解耦蒸馏性能更好,所需的计算资源不到耦合蒸馏的 1 % 1\% 1%。
4 Experiments
4.1 Experimental Setup
Table 3: Comparison of the parameters and speed for the image encoder in original SAM and MobileSAM. The inference speed is measured on a single GPU.
【翻译】表 3:原始 SAM 和 MobileSAM 中图像编码器的参数和速度比较。推理速度在单个 GPU 上测量。
Lightweight Image Encoder. The goal of our project is to obtain an efficient SAM by replacing the default ViT-H with a lightweight image encoder for mobile devices. As a ViT-based backbone, ViT-Tiny has similar parameters as Deit-Tiny but performs better. For example, on ImageNet-1K, Deit-Yiny achieves an accuracy of 72.2 % 72.2\% 72.2% , while ViT-Tiny achieves 79.1 % 79.1\% 79.1% . Therefore, we adopt ViT-Tiny for the proof of concept to demonstrate the effectiveness of our proposed decoupled distillation for training a lightweight MobileSAM that can be much faster than the original SAM. The adopted lightweight image encoder consists of four stages which gradually reduce the resolution. The first stage is constructed by convolution blocks with inverted residuals Sandler et al. 2018, while the remaining three stages consist of transformer blocks. At the beginning of the model, there are 2 convolutions blocks with a stride of 2 for downsampling the resolution. The downsampling operation between different stages is processed by convolution blocks with the stride of 2. Different from Wu et al. 2022, we set the stride of 2 in the last downsampling convolution to 1 for making the final resolution match that of the ViT-H image encoder of the original SAM. The parameters inference speed of MobileSAM are summarized in Table 3. Note that other efficient image encoders discussed in Section 2 can also be adopted as the image encoder.
Training and evaluation details. For the decoupled KD on the image encoder, we train the lightweight encoder with 1 % 1\% 1% of the SA-1B dataset Kirillov et al. 2023 for 8 epochs on a single GPU. We observe that more computation is spent on the forward process on the teacher image encoder considering that it is significantly more heavy than our adopted student image encoder (see above). To make the distillation faster, we follow the practice in Wu et al. 2022 to save the image embeddings beforehand so that we only need to run the forward process once. With a single GPU, we can obtain our MobileSAM in less than a day. Training our MobileSAM with more GPUs for a longer time is expected to yield better performance. The initial investigation of performing mask decoder finetuning further improves the performance of MobileSAM, however, we omit this step in this version of our paper for simplicity. For quantitative evaluation of the distilled SAM, we compute the mIoU between the masks predicted by the original SAM and our MobileSAM.
Figure 4: Mask prediction with a single point as the prompt.
【翻译】图 4:使用单个点作为提示的掩码预测。
4.2 MobileSAM 的性能与原始 SAM 相当
For the main results, we report the predicted masks with two types of prompts: point and box. We do not report the results with text prompt because the official github project of SAM does not provide pretrained models for text-guided mask decoder. The results with point as the prompt are shown in Figure 4, and those with box as the prompt are shown in Figure 5. We observe that MobileSAM makes a satisfactory mask prediction similar to that of the original SAM.
【翻译】对于主要结果,我们报告了使用两种类型提示的预测掩码:点和框。我们没有报告使用文本提示的结果,因为 SAM 的官方 GitHub 项目没有提供用于文本引导掩码解码器的预训练模型。使用点作为提示的结果如图 4 所示,使用框作为提示的结果如图 5 所示。我们观察到 MobileSAM 做出了令人满意的掩码预测,与原始 SAM 相似。
Figure 5: Mask prediction with a box as the prompt.
【翻译】图 5:使用框作为提示的掩码预测。
Ablation study. Here, we conduct an ablation study on the influence of the training computation on the performance of SAM. The results in Table 4 show that, under the same number of iterations, increasing the batch size increases the model performance. Moreover, under the batch size, the performance also benefits from more update iterations by increasing the training epochs. Note that all the experiments are conducted on a single GPU. We expect that increasing the number of GPUs for allowing a larger batch size or further increasing the iterations can further improve the performance.
Table 4: Ablation study on the influence of training computation on the MobileSAM performance.
【翻译】表 4:训练计算量对 MobileSAM 性能影响的消融研究。
4.3 MobileSAM 优于 FastSAM
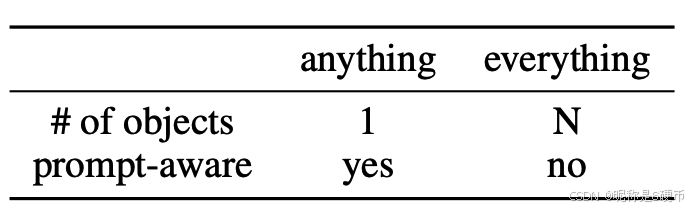
Segment anything v.s. segment everything . Note that the title of the original SAM paper Kirillov et al. 2023 is "segment anything" instead of "segment everything". As highlighted in Kirillov et al. 2023, SAM performs the task of promptable segmentation which "returns a valid segmentation mask given any segmentation prompt" (quote from Kirillov et al. 2023). The role of the prompt is to specify what to segment in the image. In theory, any object can be segmented as long as the prompt is set properly, therefore, it is called "segment anything". By contrast, "segment everything" is in essence object proposal generation Kirillov et al. 2023, for which the prompt is not necessary. In Kirillov et al. 2023, "segment everything" (object proposal generation) is chosen as one of the downstream tasks for demonstrating its zero-shot transfer performance. To summarize, "segment anything" solves the foundation task of promptable segmentation for any object, while "segment everything" solves the downstream task of mask proposal generation for all objects. Since "segment everything" does not necessarily require a prompt, FastSAM directly generates the mask proposal with YOLO v8 in a prompt-free manner. To enable promptable segmentation, a mapping algorithm is designed to select the mask from the proposal mask sets. It is worth highlighting that the follow-up works that evaluate its generalization/robustness or investigate its versatility mainly focus on the anything instead of everything mode because the former addresses the foundation task. Therefore, the comparison with FastSAM mainly focuses on "segment anything", but we also provide a comparison regarding "segment everything" for completeness.
Table 5: Comparison between segment anything and segment everything.
【翻译】表 5:"分割任何物体"和"分割所有物体"之间的比较。
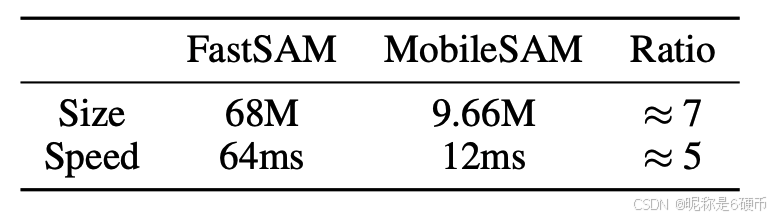
MobileSAM is faster and smaller. FastSAM consists of a YOLOv8-based detection branch and a YOLACT-based segmentation branch to perform a prompt-free mask proposal generation. It has 68M parameters and takes 40 m s 40\mathrm{ms} 40ms to process an image. By contrast, MobileSAM has less 10M parameters, which is significantly smaller. For the inference speed, on a single GPU, it takes 40 m s 40\mathrm{ms} 40ms to process an image while ours only takes 10 m s 10\mathrm{ms} 10ms , which is 4 times faster than FastSAM (see Table 6).
【翻译】MobileSAM 更快更小。FastSAM 由基于 YOLOv8 的检测分支和基于 YOLACT 的分割分支组成,以执行无提示掩码提议生成。它有 6800 万个参数,处理一张图像需要 40 m s 40\mathrm{ms} 40ms。相比之下,MobileSAM 的参数少于 1000 万,明显更小。对于推理速度,在单个 GPU 上,FastSAM 处理一张图像需要 40 m s 40\mathrm{ms} 40ms,而我们的只需要 10 m s 10\mathrm{ms} 10ms,比 FastSAM 快 4 倍(见表 6)。
Table 6: Comparison between FastSAM and MobileSAM.
【翻译】表 6:FastSAM 和 MobileSAM 之间的比较。
mIoU comparison under segment anything mode. We further compare the mIoU between the predicted masks with that of the original SAM. FastSAM is suggested to predict the mask with multiple points, for which we choose one for the foreground and the other for the background. The results in Table 7 show the mIoU for FastSAM is much smaller than that for MobileSAM, suggesting that the mask prediction of FastSAM is very different from that of the original SAM. Moreover, the mIoU for the FastSAM decreases very fast when the distance between the two prompt points. This is mainly caused by the fact that FastSAM often fails to predict the object when the foreground prompt point is set too close to the background prompt point.
Table 7: mIoU comparison. With the assumption that the predicted mask from the original SAM is ground-truth, a higher mIoU indicates a better performance.
【翻译】表 7:mIoU 比较。假设原始 SAM 的预测掩码是真实值,更高的 mIoU 表示更好的性能。
Results for segment everything. The results for "segment everything" are shown in Figure 6. For completeness, we also report the results of the original SAM, which generates a pleasing object proposal. We have two major observations. First, the results of our MobileSAM align surprisingly well with that of the original SAM. By contrast, the results of FastSAM are often less satisfactory. For example, FastSAM often fails to predict some objects, like the roof in the first image. Moreover, the mask proposal is sometimes difficult to interpret (see the mask for the stage in the first image and that for the sky in the second image). Second, FastSAM often generates masks that have non-smooth boundaries, for which we suggest the reader zoom in to check the details in Figure 6. For example, the pillars in the third image have non-smooth boundaries, while the original SAM and our MobileSAM do not have this issue.
【翻译】"分割所有物体"的结果。"分割所有物体"的结果如图 6 所示。为了完整性,我们还报告了原始 SAM 的结果,它生成了令人满意的物体提议。我们有两个主要观察结果。首先,我们的 MobileSAM 的结果与原始 SAM 的结果惊人地一致。相比之下,FastSAM 的结果通常不太令人满意。例如,FastSAM 经常无法预测某些物体,如第一张图像中的屋顶。此外,掩码提议有时难以解释(参见第一张图像中舞台的掩码和第二张图像中天空的掩码)。其次,FastSAM 经常生成具有非平滑边界的掩码,我们建议读者放大查看图 6 中的细节。例如,第三张图像中的柱子具有非平滑边界,而原始 SAM 和我们的 MobileSAM 没有这个问题。
Figure 6: Comparison of segment everything results.
【翻译】图 6:"分割所有物体"结果的比较。
5 Conclusion
In this work, we aim to make SAM mobile-friendly by replacing the heavyweight image encoder with a lightweight one. We find that the naive way to train such a new SAM as in the original SAM paper leads to unsatisfactory performance, especially under a setup of limited training sources. The coupled optimization of the image encoder and mask decoder is the reason, and thus we propose decoupled distillation, whhere the knowledge is distilled from the image encoder ViT-H in the original SAM to a lightweight image encoder. We show that the resulting lightweight image encoder can be automatically compatible with the mask decoder in the original SAM. Our MobileSAM is more than 60 times smaller yet performs on par with the original SAM. Moreover, we conduct a comparison with the concurrent FastSAM and show that MobileSAM achieve superior performance. Our MobileSAM is also 4 times faster and 7 times smaller than the concurrent FastSAM, making it more suitable for mobile applications. Since our MobileSAM keeps all the pipeline of the original SAM and just replaces the image encoder, it can be plug-and-play for the existing SAM-based projects to move from a heavyweight SAM to a lightweight one with almost zero effort.
【翻译】在这项工作中,我们旨在通过用轻量级图像编码器替换重量级图像编码器来使 SAM 适合移动设备。我们发现,按照原始 SAM 论文中的朴素方式训练这样一个新的 SAM 会导致不令人满意的性能,特别是在训练资源有限的情况下。图像编码器和掩码解码器的耦合优化是原因所在,因此我们提出了解耦蒸馏,将知识从原始 SAM 中的图像编码器 ViT-H 蒸馏到轻量级图像编码器。我们表明,生成的轻量级图像编码器可以自动与原始 SAM 中的掩码解码器兼容。我们的 MobileSAM 比原始 SAM 小 60 多倍,但性能与原始 SAM 相当。此外,我们与同期的 FastSAM 进行了比较,结果表明 MobileSAM 实现了更优越的性能。我们的 MobileSAM 也比同期的 FastSAM 快 4 倍、小 7 倍,使其更适合移动应用。由于我们的 MobileSAM 保留了原始 SAM 的所有流程,只是替换了图像编码器,因此对于现有的基于 SAM 的项目来说,它可以即插即用,几乎无需任何努力就能从重量级 SAM 迁移到轻量级 SAM。