Segment anything model (SAM) addresses two practical yet challenging segmentation tasks: segment anything (SegAny), which utilizes a certain point to predict the mask for a single object of interest, and segment everything (SegEvery), which predicts the masks for all objects on the image. What makes SegAny slow for SAM is its heavyweight image encoder, which has been addressed by MobileSAM via decoupled knowledge distillation. The efficiency bottleneck of SegEvery with SAM, however, lies in its mask decoder because it needs to first generate numerous masks with redundant grid-search prompts and then perform filtering to obtain the final valid masks. We propose to improve its efficiency by directly generating the final masks with only valid prompts, which can be obtained through object discovery. Our proposed approach not only helps reduce the total time on the mask decoder by at least 16 times but also achieves superior performance. Specifically, our approach yields an average performance boost of 3.6 % 3.6\% 3.6% ( 42.5 % 42.5\% 42.5% v.s. 38.9 % 38.9\% 38.9% ) for zero-shot object proposal on the LVIS dataset with the mask AR@K metric. Qualitative results show that our approach generates fine-grained masks while avoiding oversegmenting things. This project targeting faster SegEvery than the original SAM is termed MobileSAMv2 to differentiate from MobileSAM which targets faster SegAny. Moreover, we demonstrate that our new prompt sampling is also compatible with the distilled image encoders in MobileSAM, contributing to a unified framework for efficient SegAny and SegEvery. The code is available at the same link as MobileSAM Project https://github.com/ChaoningZhang/MobileSAM.
The NLP field has been revolutionalized by ChatGPT 36, which constitutes a milestone in the development of generative AI (AIGC, a.k.a artificial intelligence generated content) 37. GPT-series models 3, 23, 24 trained on web-scale text datasets play a major role for its development. Following the success of foundation models 2 in NLP, vision foundation models like CLIP 25 have been developed by co-learning a text encoder via contrastive learning 8, 33. More recently, a vision foundation model termed SAM 14, short for segment anything model, was released to solve two practical image segmentation tasks: segment anything (SegAny) and segment everything (SegEvery). Both two tasks perform class-agnostic mask segmentation, with the difference in what to segment. SegAny utilizes a certain prompt (like a point or box) to segment a single thing of interest in the image. By contrast, SegEvery aims to segment all things in the image. SAM has been widely used in a wide range of applications 38 due to its impressive performance on these two tasks.
SAM works in sequence with two modules: ViT-based image encoder and prompt-guided mask decoder (see Figure 1). They are simply referred to image encoder and mask decoder in the remainder of this work when it does not confuse. The lightweight mask decoder adopts two-way attention to enable efficient interaction between image embedding and promt token for generating fine-grained masks 14. What makes SegAny slow is the image encoder which is 100 + 100+ 100+ more heavyweight than the mask decoder. This issue has been addressed by MobileSAM by distilling a lightweight image encoder in a decoupled manner. To segment all things, SegEvery requires first repeatedly running the mask decoder to generate numerous proposal masks and then selecting the high-quality and non-overlapping ones. This shifts the computation bottleneck from the image encoding to the mask generation and filtering. In essence, SegEvery is not a promptable segmentation task and thus the masks might be generated directly without using prompts 34. Such a prompt-free approach has been attempted in 41, which generates masks with less satisfactory boundaries (see analysis in Sec. 6.1). The mask decoder with two-way attention solves this problem but at the cost of making SegEvery much slower 14. To this end, we follow the practice of SegEvery in 14 to prompt the mask decoder to guarantee the quality of the generated masks but address its low-speed issue by reducing the number of prompts.
Figure 1. SAM architecture and efficiency. The computation bottleneck for SegAny lies in its image encoder, while that for SegEvery mainly lies in its mask decoder when a high grid-search density is required (zero-shot object proposal in 14 adopts 64 × 64 64\times64 64×64 points).
SegEvery in 14 prompts the image encoder with a grid search of foreground points. When the grid search is sparse, many small things or meaningful object parts might miss from being detected. Therefore, SegEvery in 14 adopts a high grid density, like 64 × 64 64\times64 64×64 points for zero-shot object proposal, which tends to have redundant prompts for large objects. In essence, it adopts a strategy to first generate many masks, most of which are redundant, and then filter the redundant ones. Intuitively, this process can be simplified by only generating valid masks, which saves time for mask generation and removes the need for mask filtering. Motivated by this intuition, we propose an efficient prompt sampling that seeks object-aware prompts. Fortunately, this is a well-solved issue in modern object detection. In this work, we adopt YOLOv8 which is a SOTA architecture for efficient detection with bounding boxes. To avoid over-fitting to any specific dataset, the model should be trained on an open-world dataset, for which a subset of SA-1B dataset is chosen. With the generated box, we can either use its center as an object-aware point prompt or directly adopt the box itself as the prompt. An issue with the point prompt is that it requires predicting three output masks per prompt to address the ambiguity issue. The bounding box is more informative with less ambiguity and thus is more suitable to be adopted in efficient SegEvery. Overall, this project is designed to make SegEvery in 14 faster while achieving competitive performance. We term this project MobileSAMv2 to differentiate MobileSAM 34 that makes SegAny faster. Overall, the contributions of this work are summarized as follows.
• We identify what makes SegEvery in SAM slow and propose object-aware box prompts to replace the default grid-search point prompts, which significantly increases its speed while achieving overall superior performance.
• We demonstrate that the our proposed object-ware prompt sampling strategy is compatible with the distilled image encoders in MobileSAM, which further contributes to a unified framework for efficient SegAny and SegEvery.
Progress on SAM. Since its advent in April 2023, SAM has been extensively studied in numerous GitHub projects and research articles. Its performance of SegAny, has been studied in various challenging setups, including medical images 18, 40, camouflaged objects 28, and transparent objects 7. Overall, SAM shows strong generalization performance but can be improved when the setup gets more challenging. Its generalization in the adversarial setup has been studied in Attack-SAM 35 which shows that the output masks of SAM can be easily manipulated by maliciously generated perturbations. Follow-up works further study the performance of adversarial perturbation generated on SAM in cross-model transferability 7 and cross-sample transferability 42. A comprehensive robustness evaluation of SAM has been studied in follow-up work 22 which shows that SAM is robust against style transfer, common corruptions, local occlusion but not adversarial perturbation. The versatility of SAM has been demonstrated in another line of work. Even though SAM is shown to be compatible with text prompts in the original paper 14 as a proof-of-concept, this functionality is not included in its official code. Grounded SAM 9 project combines Grounding DINO 17 with SAM for text-guided promptable segmentation. Specifically, Grounding DINO utilizes a box to generate a bounding box which can be used as a prompt for the SAM to predict a mask. Semantic segment anything project 4 introduces CLIP 25 to assign labels to the predicted masks of SAM. SAM has also been shown to be versatile for image editing 26, inpainting tasks 32 and object tracking in videos 31, 43. Beyond 2D, SAM can also be used for 3D object reconstruction 11, 27, i.e. assisting 3D model generation from a single image. PersoanlizeSAM 39 personalizes the SAM with one shot for the customized SAM. High-quality tokens have been introduced in 12 to improve the quality of predicted masks. The readers are suggested to refer to 38 for a survey of SAM for its recent progress.
Class-agnostic segmentation. Detection is a fundamental computer vision task that localize the objects of interest on an image 16. Detection roughly localizes the object by a box, while segmentation performs a more fine-grained localization by assigning a pixel-wise mask 20. It is straightforward to deduce a box from a given mask, but not vice versa, which indicates that the segmentation task is more complex than detection. Except for assigning masks, image segmentation (like semantic segmentation) often involves predicting their corresponding semantic labels from a predefined class set 5. However, it is far from practical applications because there can be unlimited classes in the real world. To this end, a line of work has attempted to extend them to the open world by not considering their semantic labels. Class-agnostic object detection has been first formally proposed in 10 with the average recall established as the metric to evaluate its performance and then be used as a new pretraining technique 1. Multimodal transformer has been shown in 19 to demonstrate satisfactory performance. Open-world instance segmentation has been extensively in 13, 29, 30 for realizing class-agnostic detection and segmentation. In contrast to them treating the object as a whole, a follow-up work 21 has investigated open-world object part segmentation. More recently, SAM 14 has solved the SegEvery task that segments all things including all objects and their meaningful parts. It has been shown in multiple Github projects (CLIP-SAM, Segment-Anything-CLIP, segmentanything-with-clip) that class-agnostic segmentation masks obtained from SegEvery with SAM 14 can be combined with CLIP 25 to produce semantic-aware segmentation in the open world.
Task Definition. Conventional image segmentation predicts pixel-wise masks together with their corresponding class labels. However, the classes can be ambiguous across different datasets. For example, CIFAR10 dataset has a dog class, while ImageNet-1K has several hundred classes to indicate various breeds of dogs. Another setup might divide them into puppy or adult dogs instead of their breed. This makes open-world image segmentation not tractable when considering the semantics. When decoupled from label prediction, open-world image segmentation becomes relatively easier but remains a challenging issue. Without semantic information, whether a region in the image is considered an object or a thing denoted by a mask can be subjective. This ill-posed nature is, at least partly, connected to the ambiguity of granularity 15. For example, when the granularity is too large, it might only detect a large object but ignore its meaningful object parts. When the granularity is too small, every pixel can be independently segmented, which is trivial and meaningless. In other words, open-world image segmentation requires segmenting all things including the whole objects and their meaningful parts, i.e. everything. In essence, it is a class-agnostic segmentation task that performs zero-shot object proposal generation in the open world. This task is termed segment everything (SegEvery) in 14, and we follow 14 to adopt the same name to avoid confusion.
Prompt-aware Solution. SAM is a pioneering work to solve the task of promptable segmentation 14. Specifically, it segments any object of interest with a certain prompt, which is named segment anything (SegAny) in 14. Based on this, SAM provides a straightforward solution to the SegEvery task by prompting the SAM decoder with a search grid of foreground points. An underlying issue of this approach is that the performance is highly dependent on the grid density. Intuitively, a higher grid density tends to yield higher performance but at a cost of significantly increasing the computation overhead. Orthogonal to MobileSAM 34 distilling the heavyweight image encoder for faster SegAny, this project, named MobileSAMv2 for term differentiation, aims to make SegEvery faster by proposing a new sampling strategy to reduce the number of sampled prompts. Our solution significantly improves its efficiency while achieving overall superior performance. In the following section, we will illustrate the motivation behind our solution and its detailed implementation.
The prompt-aware solution proposed in 14 has demonstrated impressive performance for the challenging SegEvery task. It adopts a strategy of first generating redundant masks and then filtering them to obtain the final valid masks. Intuitively, this process might be unnecessarily cumbersome and can be simplified by prompting the mask decoder with only valid prompts, which saves time for mask generation and has no need to perform any filtering. The core of our method lies in replacing the default gird-search prompt sampling with object-aware prompt sampling. This strategy boils down to determining whether there is an object in a certain region on the image. Modern object detection task already solves this by localizing the objects with bounding boxes. Most of the generated bounding boxes overlap with each other, which thus requires pre-filtering before being used as valid prompts. Without additional prior knowledge, we deduce the filter-left bounding box center as the foreground point with a moderate assumption that the box center point is on the object. Moreover, the mask decoder of SAM also accepts a box as the prompt. Therefore, we also experiment with directly using the remaining box as the prompt. Overall, our proposed SegEvery framework consists of two stages: object-aware prompt sampling and prompt-guided mask decoding. The first stage samples the prompts by relying on a modern object detection network, and the second stage follows SAM 14 to perform a prompt-guided mask decoding.
Object discovery has been widely used in some cases (like visual-language tasks) as a preprocessing technique for avoiding exhaustive sliding window search. Inspired by their practice, we propose to exploit object discovery for sampling prompts. In essence, object discovery is to localize the objects with a bounding box, which can be realized by modern object detection models but excluding its classification head. The past decade has witnessed a huge advancement in the development of object detection models, YOLO family models have become de facto standard choice for its advantages in real-time performance. To prevent over-fitting to any specific domain, the chosen YOLOv8 model needs to be trained on an open-world dataset, for which a small subset of SA-1B dataset 14, 34 is chosen. The model is trained with the supervision of both the bounding box and masks and then finetuned with only the bounding box loss. Such a training approach also facilitates comparison with the prompt-free approach (see Sec. 6.1). This generates numerous overlapping boxes, which need to be filtered before being used as prompts. Following the standard practice, we adopt NMS to filter the overlapping boxes. With the filtered bounding boxes, we can either use its center as an object-aware point prompt or directly adopt the box itself as the prompt. In practice, we choose the latter strategy for multiple reasons. Even though the center point is object-aware, it is based on an assumption that the object inside the bounding box covers the center point. This holds in most cases but not in all cases. Another issue with the point prompt is that it needs to predict three output masks to address the ambiguity issue, which requires additional mask filtering. By contrast, the box prompt is more informative and generates high-quality masks with less ambiguity, which mitigates the need to predict three masks and is thus more beneficial for efficient SegEvery.
We follow SAM 14 to perform a prompt-guided mask decoding in a batch manner. In contrast to the image encoder setting the number of image samples as batch, here, the batch concept is the number of prompts. It is worth noting that the promptguided mask decoder in SAM also accepts a box as the input. Therefore, it is technically feasible to directly prompt the mask decoder with a set of boxes that save the process of deriving the center points. Even though it is not our original motivation, without causing any additional cost, we find that this practice yields a non-trivial performance boost. In other words, it can be seen as a free trick to improve the task performance. Prompt-aware solution in 14 requires mask filtering. Empirically, we find that this process can be very slow because the mask is high-dimensional. This is different from efficient box filtering because a box only has four dimensions. This cumbersome mask filtering is optional in our proposed SegEvery framework because we can avoid it by prompting the mask decoder with only valid prompts. In other words, we keep all the generated masks since the prompts are sampled in an object-aware manner.
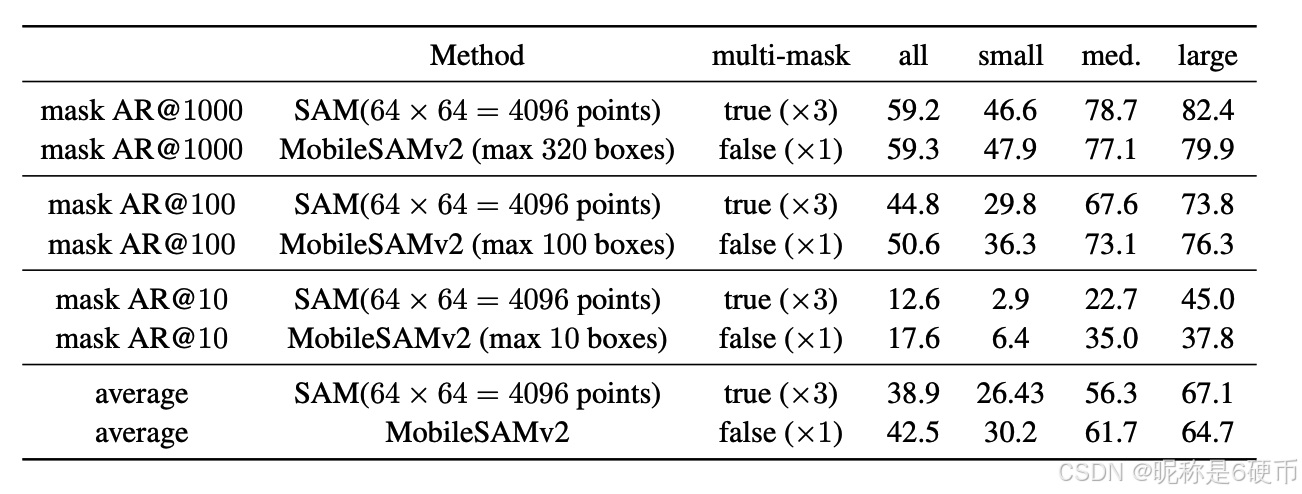
SegEvery has been perceived in 14 as a zero-shot object proposal task with standard average recall (AR) as the metric for performance evaluation. We follow the practice in 14 to adopt AR for masks at K K K proposals (mask AR @ K ) \operatorname{AR}{@K}) AR@K) , where K K K is the maximum allowable number of masks. With the definition of AR, AR @ K \operatorname{AR}@K AR@K gets higher when K K K is allowed to set to a larger value, which constitutes a less strict metric. Only A R @ 1000 \mathrm{AR}@1000 AR@1000 is reported in 14, but we choose to report AR @ K \operatorname{AR}@K AR@K for K K K ranging from 10 to 1000. To not lose generality yet save computation resources, we choose to report the results on 100 images randomly sampled from the large vocabulary instance segmentaiton (LVIS) dataset 6.
【翻译】SegEvery在14中被视为一个零样本对象提议任务,采用标准平均召回率(AR)作为性能评估指标。我们遵循14中的做法,采用K个提议的掩码平均召回率(mask AR @ K \operatorname{AR}{@K} AR@K),其中 K K K是允许的最大掩码数量。根据AR的定义,当 K K K被允许设置为更大的值时, AR @ K \operatorname{AR}@K AR@K会更高,这构成了一个不太严格的指标。14中仅报告了 A R @ 1000 \mathrm{AR}@1000 AR@1000,但我们选择报告 K K K从10到1000范围内的 AR @ K \operatorname{AR}@K AR@K。为了不失一般性同时节省计算资源,我们选择在从大词汇量实例分割(LVIS)数据集6中随机采样的100张图像上报告结果。
5.1. Main Results
What makes SegEvery much more computation-intensive than SegAny lies in the need to run the mask decoder with numerous sampled prompts 14. Our proposed object-aware prompt sampling improves its efficiency by reducing the number of total prompts. In the following, we detail their difference in terms of required computation time by roughly dividing the prompt-guided mask decoding pipeline into two stages: prompt encoding (including pre-sampling) and mask decoding (including post-filtering). Mask decoding is much more heavy than simple prompt encoding. Except for the redundant sampled prompts, the default grid-search sampling in 14 also requires filtering the generated masks, which is also time-consuming. By contrast, our object-aware prompt sampling strategy does not need to filter the generated masks because the prompts are sampled in an object-aware manner. This saves the time for mask filtering. In the following, we compare the efficiency of the two sampling strategies in terms of the time spent on the prompt encoding and mask decoding stages.
Efficiency comparison. SegEvery with our proposed sampling strategy needs to run an object discovery algorithm to obtain object-aware prompts, which requires more time for prompt sampling than the default grid-search sampling in 14 but needs to encode much fewer prompts. For the mask generation, the time spent on the mask decoder is somewhat proportional to the number of sampled prompts. We find that the performance saturates when the number of prompts is approaching 320, which is set to the maximum number of detection boxes (See Sec.6.2). Less computation is needed when the object discovery generates masks that are fewer than 320, which occurs in many cases. Nonetheless, when performing an efficiency analysis, we compare our most computation-intensive scenario (max 320 prompts) with the grid-search strategy. The results in Table 2 show that our proposed prompt sampling strategy significantly improves the efficiency of SegEvery. Specifically, our proposed prompt sampling strategy reduces the time spent on the mask decoder by more than 10 times (from 1200ms to 100ms) while achieving overall superior performance.
Table 2. Efficiency comparison of the (prompt-guided) mask decoder between grid-search sampling and object-aware sampling. Note that the prompt encoding includes the prompt pre-sampling time, while the mask decoding includes the mask post-filtering time.
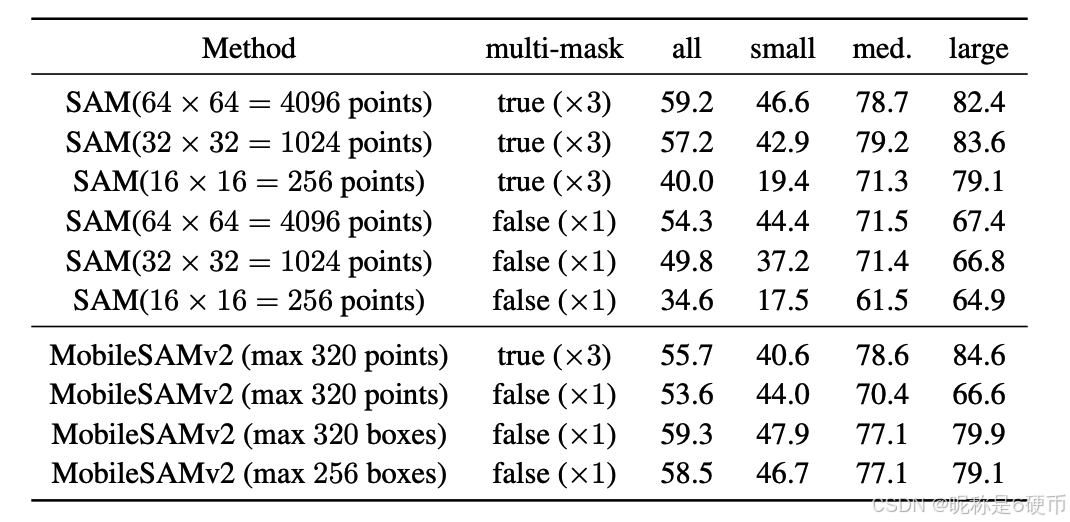
Performance comparison. We carefully follow the implementation practice recommended in 14 for zero-shot object proposal. By default, it is suggested to set the grid density to 64 × 64 64\times64 64×64 and generate a total of 12288 ( 64 × 64 × 3 ) (64\times64\times3) (64×64×3) masks, out of which a maximum of 1000 masks are then selected given the mask A R @ 1000 \mathrm{AR}@1000 AR@1000 metric. We have experimented with decreasing the grid density and/or setting the multi-mask option to false (single-mask mode). The results in Table 3 show that generating fewer masks by either one of the above two practices leads to a performance drop, suggesting that the default grid-search sampling strategy highly relies on generating redundant masks for selecting the final needed ones. Moreover, we have multiple major observations by comparing SAM (the default grid-search prompt sampling) and MobileSAMv2 (our proposed object-aware prompt sampling). First, under the condition of prompting with the same type of prompt (points) and setting multi-mask to false, we find that MobileSAMv2 (max 320 points) achieves comparable performance as SAM using 4096 points, suggesting that the object-aware property of our prompt sampling strategy significantly avoids redundancy. Boosted with the multitask option set to true, the default 64 × 64 64\times64 64×64 grid density yields a higher performance ( 59.2 % ) (59.2\%) (59.2%) , which constitutes the best setup for the grid-search strategy. Similarly, we can also increase the performance of our object-aware point sampling by setting the multi-mask to true. Note that the motivation for predicting three output masks of different granularities 14 is to address the ambiguity issue of a point prompt. A single point has limited prompt information and thus causing ambiguity (the readers can check Figure 4 in 14 for more details). By contrast, a box prompt is much more informative and reduces ambiguity to a very large extent. This is supported by our results in Table 3 that box prompts yield a significant performance boost at single mask mode. Last, it is worth mentioning that, compared with the best result of the grid-search sampling strategy (with 64 × 64 64\times64 64×64 points at multi-mask mode), our proposed sampling strategy (with max 320 box prompts) achieves comparable performance ( 59.3 % ν . s .59.2 % ) (59.3\%\nu.s.59.2\%) (59.3%ν.s.59.2%) . Limiting the max number of prompts to 256, our strategy still yields competitive performance ( 58.5 % ) (58.5\%) (58.5%) compared with that of the grid-search strategy ( 34.6 % ) (34.6\%) (34.6%) under the same condition. We also report AR @ K \operatorname{AR}@K AR@K for other K K K values in Table 4. When K K K is set to a relatively small value, we find that our proposed object-aware sampling strategy with much fewer prompts leads to a performance boost by a large margin. Overall, our proposed approach achieves an average performance boost of 3.6 % 3.6\% 3.6% ( 42.5 % 42.5\% 42.5% v.s. 38.9 % 38.9\% 38.9% ).
【翻译】性能比较。我们仔细遵循14中推荐的零样本对象提议的实现实践。默认情况下,建议将网格密度设置为 64 × 64 64\times64 64×64并生成总共12288个 ( 64 × 64 × 3 ) (64\times64\times3) (64×64×3)掩码,然后根据掩码 A R @ 1000 \mathrm{AR}@1000 AR@1000指标从中选择最多1000个掩码。我们尝试了降低网格密度和/或将多掩码选项设置为false(单掩码模式)。表3中的结果表明,通过上述两种做法中的任何一种生成更少的掩码都会导致性能下降,这表明默认的网格搜索采样策略高度依赖于生成冗余掩码来选择最终需要的掩码。此外,通过比较SAM(默认的网格搜索提示采样)和MobileSAMv2(我们提出的对象感知提示采样),我们有多个主要观察结果。首先,在使用相同类型的提示(点)进行提示并将多掩码设置为false的条件下,我们发现MobileSAMv2(最多320个点)实现了与使用4096个点的SAM相当的性能,这表明我们提示采样策略的对象感知特性显著避免了冗余。在多任务选项设置为true的情况下,默认的 64 × 64 64\times64 64×64网格密度产生了更高的性能 ( 59.2 % ) (59.2\%) (59.2%),这构成了网格搜索策略的最佳设置。同样,我们也可以通过将多掩码设置为true来提高对象感知点采样的性能。请注意,预测三个不同粒度的输出掩码14的动机是为了解决点提示的歧义问题。单个点的提示信息有限,因此会造成歧义(读者可以查看14中的图4了解更多细节)。相比之下,边界框提示信息量更大,在很大程度上减少了歧义。我们在表3中的结果支持了这一点,即边界框提示在单掩码模式下产生了显著的性能提升。最后,值得一提的是,与网格搜索采样策略的最佳结果(在多掩码模式下使用 64 × 64 64\times64 64×64个点)相比,我们提出的采样策略(最多320个边界框提示)实现了相当的性能 ( 59.3 % ν . s .59.2 % ) (59.3\%\nu.s.59.2\%) (59.3%ν.s.59.2%)。将提示的最大数量限制为256,我们的策略在相同条件下仍然产生了有竞争力的性能 ( 58.5 % ) (58.5\%) (58.5%),而网格搜索策略为 ( 34.6 % ) (34.6\%) (34.6%)。我们还在表4中报告了其他 K K K值的 AR @ K \operatorname{AR}@K AR@K。当 K K K设置为相对较小的值时,我们发现我们提出的对象感知采样策略使用更少的提示就能带来大幅度的性能提升。总体而言,我们提出的方法实现了平均 3.6 % 3.6\% 3.6%的性能提升( 42.5 % 42.5\% 42.5%对比 38.9 % 38.9\% 38.9%)。
Table 3. Zero-shot object proposal comparison between grid-search sampling and object-aware sampling (mask @ @ @ 1000 as the metric).
Table 4. Zero-shot object proposal comparison between grid-search sampling and object-aware sampling.
【翻译】表4. 网格搜索采样和对象感知采样之间的零样本对象提议比较。
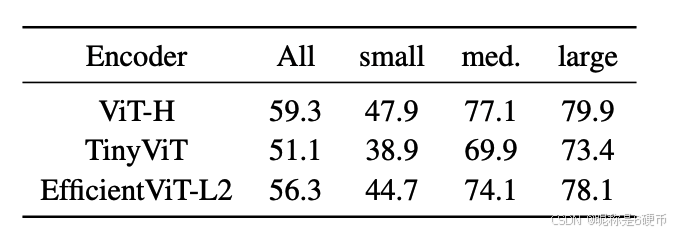
Table 5. Influence of the image encoders on MobileSAMv2 for zero-shot object proposal (mask@1000).
【翻译】表5. 图像编码器对MobileSAMv2零样本对象提议的影响(mask@1000)。
5.2. 关于与蒸馏图像编码器的兼容性
In the above, we only consider the prompt-guided mask decoder, however, the whole pipeline needs to run the image encoder once before running the mask decoder. As shown in Figure 1, the time spent on the image encoder is relatively small for SegEvery with the grid-search point sampling. However, this is no longer the case when adopting our object-aware prompt sampling strategy, which reduces the time on the mask decoder to around 100 m s 100\mathrm{ms} 100ms . Therefore, we consider reducing the time spent on the image encoder by replacing the original one (ViT-H) in the SAM with a distilled one in the MobileSAM project 34. The results with different distilled image encoders are shown in Table 5. We observe a moderate performance drop (from 59.2 % 59.2\% 59.2% to 56.3 % 56.3\% 56.3% ) when EfficientViT-L2 is used. Given that EfficientViT-l2 runs around 20 m s 20\mathrm{ms} 20ms which is significantly faster than that of ViT-H (more than 400 m s , 400\mathrm{ms}, 400ms, ), it is worthwhile to replace the image encoder. Due to the simplicity and effectiveness of decoupled knowledge distillation introduced in MobileSAM 34, a more powerful distilled image encoder is expected to emerge soon to further alleviate the performance drop. It is worth highlighting that MobileSAM and MobileSAMv2 solve two orthogonal issues: faster SegAny and faster SegEvery. Combing them together constitutes a unified framework for efficient SegAny and SegEvery.
【翻译】在上文中,我们只考虑了提示引导的掩码解码器,然而,整个流程需要在运行掩码解码器之前先运行一次图像编码器。如图1所示,对于使用网格搜索点采样的SegEvery,图像编码器花费的时间相对较小。然而,当采用我们的对象感知提示采样策略时,情况就不再如此了,该策略将掩码解码器的时间减少到约 100 m s 100\mathrm{ms} 100ms。因此,我们考虑通过用MobileSAM项目34中的蒸馏编码器替换SAM中的原始编码器(ViT-H)来减少图像编码器花费的时间。表5显示了使用不同蒸馏图像编码器的结果。我们观察到当使用EfficientViT-L2时性能有适度下降(从 59.2 % 59.2\% 59.2%降至 56.3 % 56.3\% 56.3%)。鉴于EfficientViT-l2运行时间约为 20 m s 20\mathrm{ms} 20ms,这比ViT-H(超过 400 m s 400\mathrm{ms} 400ms)快得多,因此替换图像编码器是值得的。由于MobileSAM34中引入的解耦知识蒸馏的简单性和有效性,预计很快会出现更强大的蒸馏图像编码器,以进一步缓解性能下降。值得强调的是,MobileSAM和MobileSAMv2解决了两个正交的问题:更快的SegAny和更快的SegEvery。将它们结合在一起构成了一个高效SegAny和SegEvery的统一框架。
6. 额外比较和消融研究
6.1. 与无提示方法的比较
As discussed in 34, the SegEvery is in essence not a promptable segmentation task and thus can be realized in promptfree manner. Such an approach has been attempted in 41 with YOLOv8-seg, which mainly augments YOLOv8-det with a protonet module to generate mask prototype. The intance mask is obtained by convolving the mask prototype with a mask coefficient that has the same length as the prototype dimension (32 by default), which is mathematically a dot product. Here, we point out that the mask decoder of SAM 14 also generates the mask by making a dot product between a mask coefficient (called mask token in 14) and a mask prototype (called image embedding in 14), which have the same (32) dimensions so that the dot product can be computed. Intuitively, the quality of generated mask relies on how well the mask coefficent and mask prototype interact with each other. The mask decoder in 14 adopts two-way attention to enable the interaction between the mask prototype and mask coeffcient before performing the final product. Such an interaction is the key foundation for guaranteeing the high-quality mask in SAM. By contrast, there is no explicit interaction between the mask coefficients and mask prototypes in the prompt-free approach. With a single shared mask prototype, it often predicts multiple objects at different regions of the image and thus relies on a bounding box to crop the mask. This can help remove the irrelevant masks outside the box but still fails in yielding high-quality masks as 14, at least partly, due to lack of the interaction between mask coefficient and mask prototype. Even though the prompt-free approach realizes the fastest speed, it results in a nontrivial performance drop (see Table 6). The less satisfactory performance of the prompt-free approach is mainly attributed to the poor mask boundary (see Figure 2). Compared with prompt-free approach, the two prompt-aware approaches (SAM and MobileSAMv2) generate masks with much more fine-grained boundaries. SAM tends to over-segment things while our MobileSAMv2 alleviates this tendency by utilizing its object-aware property.
Table 6. Zero-shot object proposal comparison between prompt-free and prompt-aware approaches (mask @ @ @ 1000).
【翻译】表6. 无提示和提示感知方法之间的零样本对象提议比较(mask @ @ @ 1000)。
Figure 2. Comparison between prompt-free and prompt-aware mask predictions. Prompt-free tends to predict the mask with a non-smooth boundary compared with prompt-aware approaches. For the two prompt-aware approaches, SAM tends to over-segment things while our MobileSAMv2 addresses it due to its object-aware property. Best view in color and zoom in.
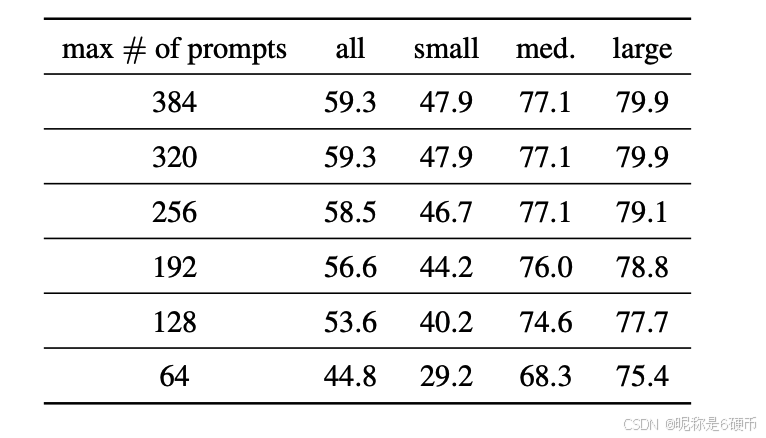
With the mask AR@1000 as the metric, we find that our proposed sampling strategy often yields fewer prompts than 1000, which motivates us to explore the influence of the maximum number of (box) prompts in our proposed prompt sampling strategy. The results in Table 7 show that increasing the number of box prompts is beneficial for a higher mask AR, however, it saturates after it approaches 320. Therefore, by default, we set the maximum number of prompts in MobileSAMv2 to 320.
Table 7. Influence of the maximum number of prompts on MobileSAMv2 for zero-shot object proposal (mask@1000).
【翻译】表7. 提示的最大数量对MobileSAMv2零样本对象提议的影响(mask@1000)。
7. Conclusion and Future work
Orthogonal to the MobileSAM project making SegAny faster by distilling a lightweight image encoder, this project termed MobileSAMv2 makes SegEvery faster by proposing a new prompt sampling strategy in the prompt-guided mask decoder. Replacing the grid-search with our object-aware prompt sampling, we significantly improve the efficiency of SegEvery while achieving overall superior performance. We also demonstrate that our object-aware prompt sampling is compatible with the distilled image encoders in the MobileSAM project. Overall, our work constitutes a step towards a unified framework for efficient SegAny and SegEvery. Future work is needed to seek superior image encoder(s) and object discovery models(s).