
已在GitHub开源与本博客同步的YOLOv8_RDKX5_object_detect项目,地址:https://github.com/A7bert777/YOLOv8_RDKX5_object_detect
详细使用教程,可参考README.md或参考本博客第八章 模型部署
注:本文是以sunrise5 SoC进行示例,旭日其他系列SoC的部署流程也基本一致,如需帮助,可通过Github仓库的 README.md 沟通。
文章目录
- 一、项目回顾
- 二、文件梳理
- 三、模型训练
- 四、PT转ONNX
- 五、ONNX转bin-Dokcer容器配置
- 六、ONNX转bin-OE工具链配置
- 七、容器内ONNX量化bin
- [八、RDK X5边缘模型部署](#八、RDK X5边缘模型部署)
一、项目回顾
博主之前主要使用瑞芯微、昇腾系列的SoC及对应生态,现在逐渐转向地平线/地瓜系列,博主本人使用的是RDK X5开发套件,如下图所示,SoC为sunrise5,但发现CSDN上目前没有什么比较详细的免费文章与开源项目供大家入手,因此自己尝试进行完整流程的部署,遂以此文分享,供大家一起学习。

博主之前有写过在华为Ascend、瑞芯微RK系列SoC上的YOLOv8目标检测&图像分割、YOLOv10目标检测、MoblieNetv2图像分类的模型训练、转换、部署文章,感兴趣的小伙伴可以了解下:
【YOLOv8部署至Ascend 310B】模型训练→转换om→310B部署
【YOLO11-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLO11部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv10部署RK3588】模型训练→转换rknn→部署流程
【YOLOv8-obb部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8-pose部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv8seg部署RK3588】模型训练→转换rknn→部署全流程
【YOLOv8部署至RK3588】模型训练→转换rknn→部署全流程
【YOLOv7部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv6部署至RK3588】模型训练→转换RKNN→开发板部署
【YOLOv5部署至RK3588】模型训练→转换RKNN→开发板部署
【MobileNetv2图像分类部署至RK3588】模型训练→转换rknn→部署流程
【ResNet50图像分类部署至RK3588】模型训练→转换RKNN→开发板部署
YOLOv8n部署RK3588开发板全流程(pt→onnx→rknn模型转换、板端后处理检测)
二、文件梳理
之前博主发布过YOLOv8转RKNN模型并在开发板上部署的流程,现在尝试在地瓜的RDK X5 开发板上,使用旭日sunrise5进行YOLOv8目标检测模型的部署。
OK,进入正题,模型转换需要以下工具:
第一个文件:github上ultralytics的yolov8项目
第二个文件:github上地瓜的rdk_model_zoo仓库
第三个文件:博主个人Github仓库:YOLOv8_RDKX5_object_detect
三、模型训练
YOLOv8的模型训练环境配置、训练步骤,网上的很多相关教程很多,基础不多叙述,大家可以直接参考其他文章
python
from ultralytics import YOLO
# 加载模型
model = YOLO("/xxx/Algorithm/YOLOv8/ultralytics-main/yaml/yolov8n.yaml") # 从头开始构建新模型
#model = YOLO("yolov8n.pt") # 加载预训练模型(推荐用于训练)
# Use the yaml
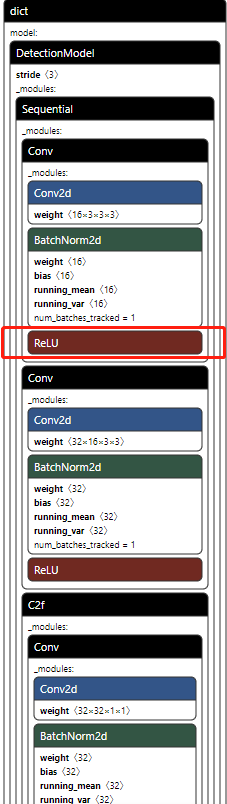
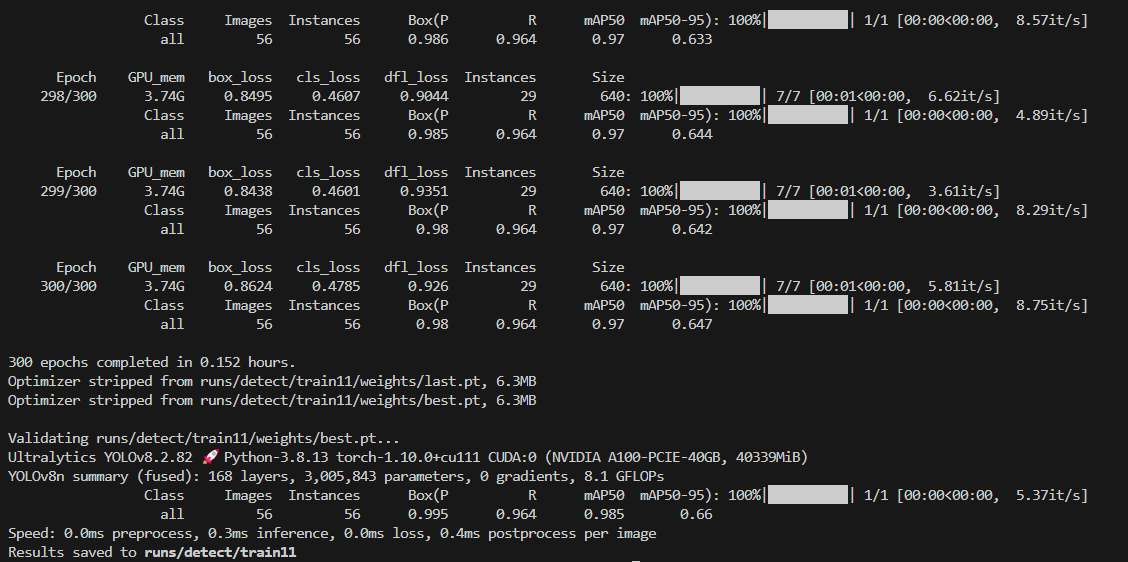
results = model.train(data="/xxx/Algorithm/YOLOv8/ultralytics-main/yaml/bird.yaml", epochs=300, batch=32) # 训练模型训练完成后,在当前路径下的runs/detect下生成我们的best.pt,我将其重命名为birds_yolov8_best.pt,博主比较喜欢实用ReLU激活函数,因此netron打开模型后如下所示:
这是模型训练结果:
将best.pt重命名为birds_yolov8_best.pt,如下所示:
四、PT转ONNX
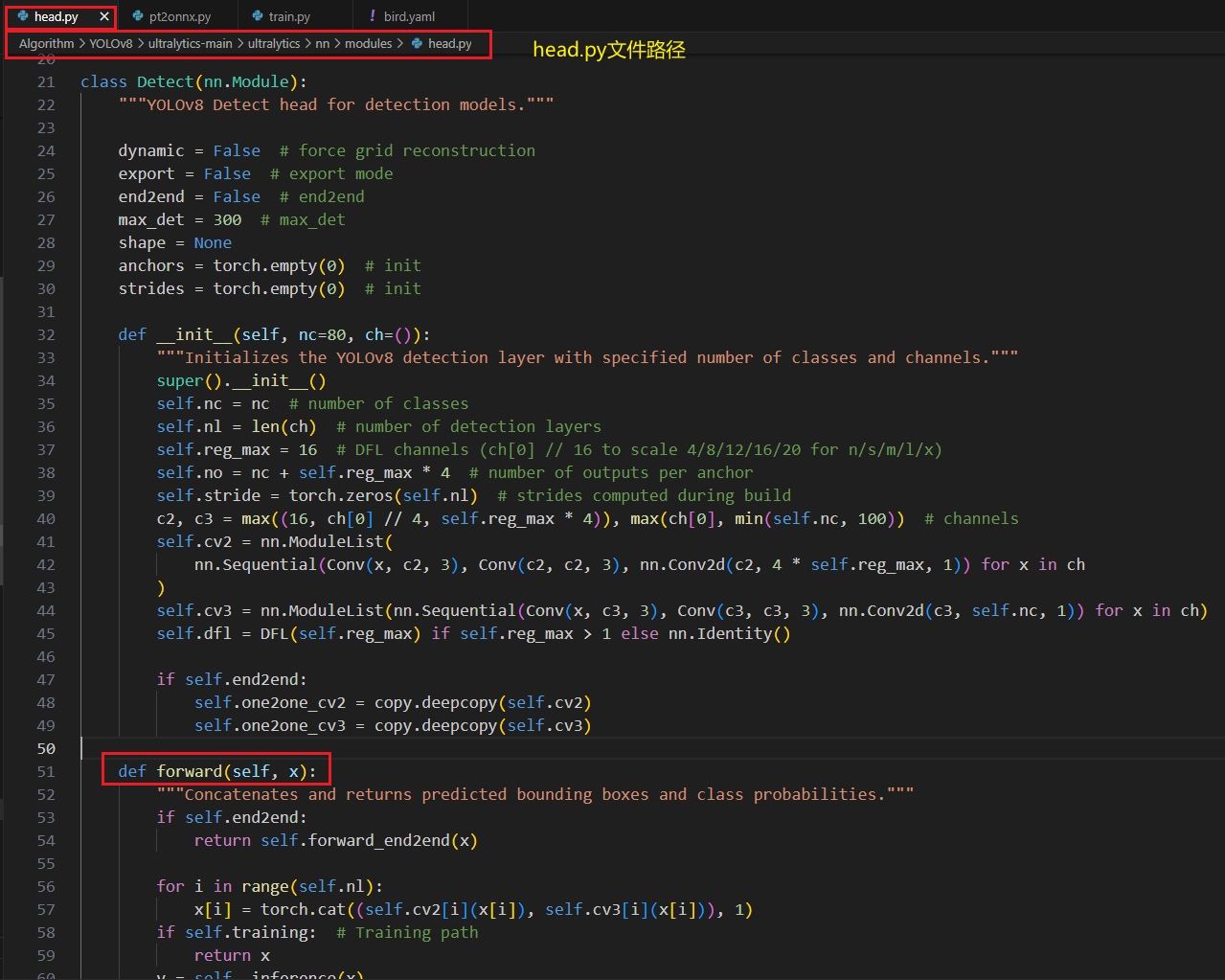
pt转onnx时,需要修改自己的head.py的Detect类forward函数,目的是修改Detect 的输出头,直接将三个特征层的BoundingBox信息和Classify信息分开输出,一共6个输出头原
head.py原内容如下所示:
修改成如下所示:
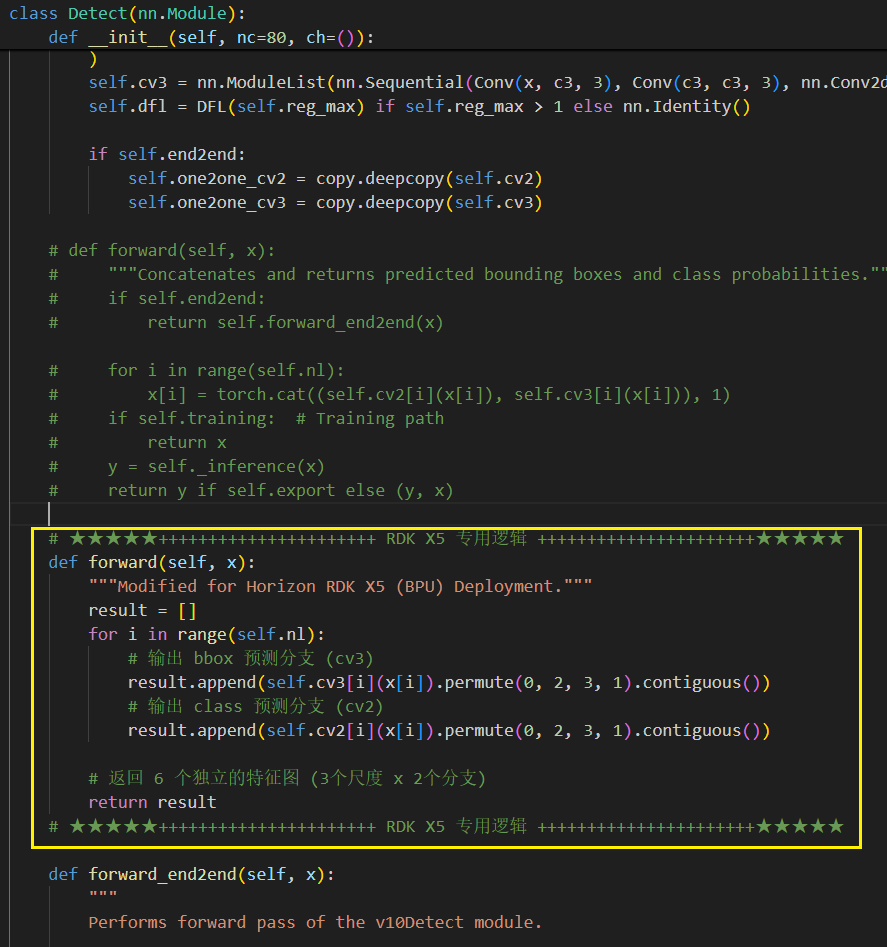
修改完成后的完整Detect类如下所示,不会改的可以直接复制,但要记得在寻俩你的时候要把这个专用的 RDKX5 的forward注掉,改用原来的forward训练:
python
class Detect(nn.Module):
"""YOLOv8 Detect head for detection models."""
dynamic = False # force grid reconstruction
export = False # export mode
end2end = False # end2end
max_det = 300 # max_det
shape = None
anchors = torch.empty(0) # init
strides = torch.empty(0) # init
def __init__(self, nc=80, ch=()):
"""Initializes the YOLOv8 detection layer with specified number of classes and channels."""
super().__init__()
self.nc = nc # number of classes
self.nl = len(ch) # number of detection layers
self.reg_max = 16 # DFL channels (ch[0] // 16 to scale 4/8/12/16/20 for n/s/m/l/x)
self.no = nc + self.reg_max * 4 # number of outputs per anchor
self.stride = torch.zeros(self.nl) # strides computed during build
c2, c3 = max((16, ch[0] // 4, self.reg_max * 4)), max(ch[0], min(self.nc, 100)) # channels
self.cv2 = nn.ModuleList(
nn.Sequential(Conv(x, c2, 3), Conv(c2, c2, 3), nn.Conv2d(c2, 4 * self.reg_max, 1)) for x in ch
)
self.cv3 = nn.ModuleList(nn.Sequential(Conv(x, c3, 3), Conv(c3, c3, 3), nn.Conv2d(c3, self.nc, 1)) for x in ch)
self.dfl = DFL(self.reg_max) if self.reg_max > 1 else nn.Identity()
if self.end2end:
self.one2one_cv2 = copy.deepcopy(self.cv2)
self.one2one_cv3 = copy.deepcopy(self.cv3)
# def forward(self, x):
# """Concatenates and returns predicted bounding boxes and class probabilities."""
# if self.end2end:
# return self.forward_end2end(x)
# for i in range(self.nl):
# x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
# if self.training: # Training path
# return x
# y = self._inference(x)
# return y if self.export else (y, x)
# ★★★★★++++++++++++++++++++++ RDK X5 专用逻辑 ++++++++++++++++++++++★★★★★
def forward(self, x):
"""Modified for Horizon RDK X5 (BPU) Deployment."""
result = []
for i in range(self.nl):
# 输出 bbox 预测分支 (cv3)
result.append(self.cv3[i](x[i]).permute(0, 2, 3, 1).contiguous())
# 输出 class 预测分支 (cv2)
result.append(self.cv2[i](x[i]).permute(0, 2, 3, 1).contiguous())
# 返回 6 个独立的特征图 (3个尺度 x 2个分支)
return result
# ★★★★★++++++++++++++++++++++ RDK X5 专用逻辑 ++++++++++++++++++++++★★★★★
def forward_end2end(self, x):
"""
Performs forward pass of the v10Detect module.
Args:
x (tensor): Input tensor.
Returns:
(dict, tensor): If not in training mode, returns a dictionary containing the outputs of both one2many and one2one detections.
If in training mode, returns a dictionary containing the outputs of one2many and one2one detections separately.
"""
x_detach = [xi.detach() for xi in x]
one2one = [
torch.cat((self.one2one_cv2[i](x_detach[i]), self.one2one_cv3[i](x_detach[i])), 1) for i in range(self.nl)
]
for i in range(self.nl):
x[i] = torch.cat((self.cv2[i](x[i]), self.cv3[i](x[i])), 1)
if self.training: # Training path
return {"one2many": x, "one2one": one2one}
y = self._inference(one2one)
y = self.postprocess(y.permute(0, 2, 1), self.max_det, self.nc)
return y if self.export else (y, {"one2many": x, "one2one": one2one})
def _inference(self, x):
"""Decode predicted bounding boxes and class probabilities based on multiple-level feature maps."""
# Inference path
shape = x[0].shape # BCHW
x_cat = torch.cat([xi.view(shape[0], self.no, -1) for xi in x], 2)
if self.dynamic or self.shape != shape:
self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))
self.shape = shape
if self.export and self.format in {"saved_model", "pb", "tflite", "edgetpu", "tfjs"}: # avoid TF FlexSplitV ops
box = x_cat[:, : self.reg_max * 4]
cls = x_cat[:, self.reg_max * 4 :]
else:
box, cls = x_cat.split((self.reg_max * 4, self.nc), 1)
if self.export and self.format in {"tflite", "edgetpu"}:
# Precompute normalization factor to increase numerical stability
# See https://github.com/ultralytics/ultralytics/issues/7371
grid_h = shape[2]
grid_w = shape[3]
grid_size = torch.tensor([grid_w, grid_h, grid_w, grid_h], device=box.device).reshape(1, 4, 1)
norm = self.strides / (self.stride[0] * grid_size)
dbox = self.decode_bboxes(self.dfl(box) * norm, self.anchors.unsqueeze(0) * norm[:, :2])
else:
dbox = self.decode_bboxes(self.dfl(box), self.anchors.unsqueeze(0)) * self.strides
return torch.cat((dbox, cls.sigmoid()), 1)
def bias_init(self):
"""Initialize Detect() biases, WARNING: requires stride availability."""
m = self # self.model[-1] # Detect() module
# cf = torch.bincount(torch.tensor(np.concatenate(dataset.labels, 0)[:, 0]).long(), minlength=nc) + 1
# ncf = math.log(0.6 / (m.nc - 0.999999)) if cf is None else torch.log(cf / cf.sum()) # nominal class frequency
for a, b, s in zip(m.cv2, m.cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
if self.end2end:
for a, b, s in zip(m.one2one_cv2, m.one2one_cv3, m.stride): # from
a[-1].bias.data[:] = 1.0 # box
b[-1].bias.data[: m.nc] = math.log(5 / m.nc / (640 / s) ** 2) # cls (.01 objects, 80 classes, 640 img)
def decode_bboxes(self, bboxes, anchors):
"""Decode bounding boxes."""
return dist2bbox(bboxes, anchors, xywh=not self.end2end, dim=1)
@staticmethod
def postprocess(preds: torch.Tensor, max_det: int, nc: int = 80):
"""
Post-processes YOLO model predictions.
Args:
preds (torch.Tensor): Raw predictions with shape (batch_size, num_anchors, 4 + nc) with last dimension
format [x, y, w, h, class_probs].
max_det (int): Maximum detections per image.
nc (int, optional): Number of classes. Default: 80.
Returns:
(torch.Tensor): Processed predictions with shape (batch_size, min(max_det, num_anchors), 6) and last
dimension format [x, y, w, h, max_class_prob, class_index].
"""
batch_size, anchors, predictions = preds.shape # i.e. shape(16,8400,84)
boxes, scores = preds.split([4, nc], dim=-1)
index = scores.amax(dim=-1).topk(min(max_det, anchors))[1].unsqueeze(-1)
boxes = boxes.gather(dim=1, index=index.repeat(1, 1, 4))
scores = scores.gather(dim=1, index=index.repeat(1, 1, nc))
scores, index = scores.flatten(1).topk(max_det)
i = torch.arange(batch_size)[..., None] # batch indices
return torch.cat([boxes[i, index // nc], scores[..., None], (index % nc)[..., None].float()], dim=-1)在之前第三步的路径下使用pt2onnx.py将自己的pt模型转成onnx格式,博主的pt2onnx.py如下所示:
python
from ultralytics import YOLO
# 加载训练好的模型
model = YOLO("birds_yolov8_best.pt") #相对路径
# 导出为 ONNX 格式
model.export(
format="onnx",
imgsz=640, # 输入尺寸(与训练一致)
opset=11, # ONNX 算子集版本(建议12+)
dynamic=False, # 是否启用动态维度(True 适用于可变输入尺寸)
simplify=False, # 启用 ONNX Simplifier 优化模型
task="detect", # 指定任务类型(目标检测)
)执行转换命令:
bash
python pt2onnx.py终端结果如下所示:

作为对比,这是使用head.py中原forward函数转换的结果:
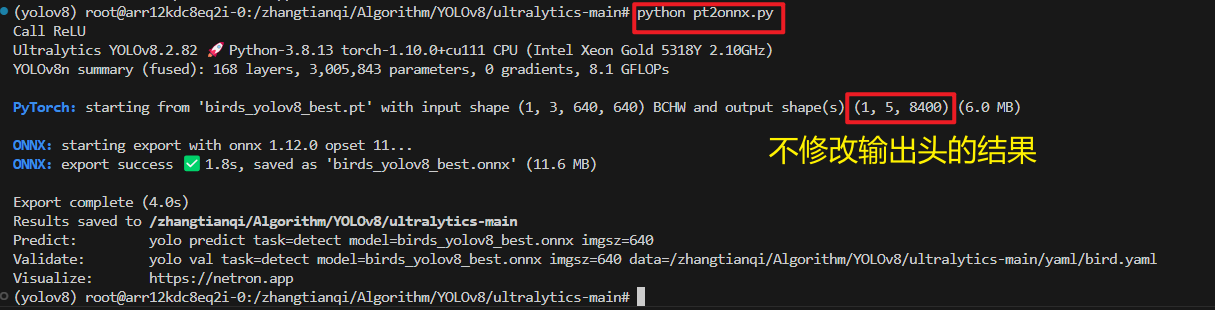
可以看到,不修改输出头的话,所有的信息全部都在一个输出tensor里,不利于后续的模型量化和板端推理。
执行完pt2onnx.py后,在当前路径下生成的onnx:
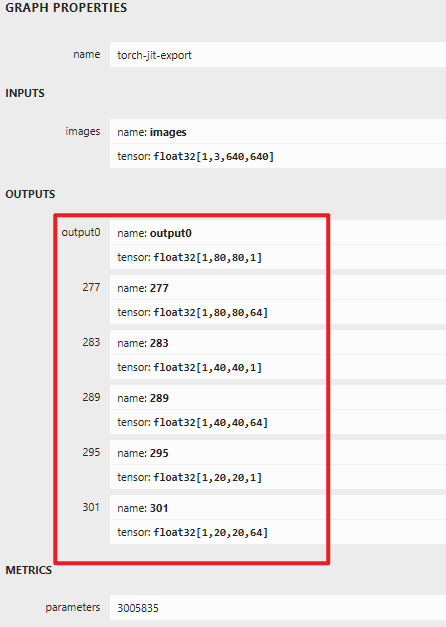
此时再可视化对比下修改了head.py和未修改head.py生成的onnx的二者区别对比:
拆分后ONNX的netron可视化效果:
未拆分后ONNX的netron可视化效果:
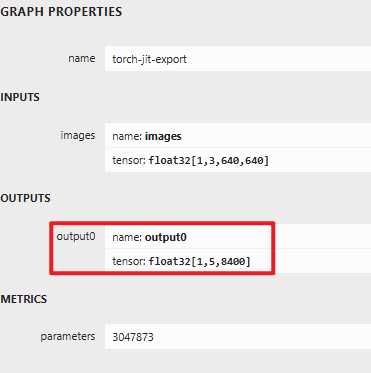
和终端中显示的输出tensor一致。
五、ONNX转bin-Dokcer容器配置
--------------------------------这一步骤全部在PC端的虚拟机中完成--------------------------------
①:docker镜像文件下载:
bash
wget -c ftp://x5ftp@vrftp.horizon.ai/OpenExplorer/v1.2.8_release/docker_openexplorer_ubuntu_20_x5_cpu_v1.2.8.tar.gz --ftp-password=x5ftp@123$%如下所示:

②:加载docke镜像:
bash
sudo docker load -i docker_openexplorer_ubuntu_20_x5_cpu_v1.2.8.tar.gz如下所示:

③:查看确定镜像已加载:
bash
docker images
六、ONNX转bin-OE工具链配置
--------------------------------这一步骤同样全部在PC端的虚拟机中完成--------------------------------
①:下载地瓜所需的OE工具链
bash
wget -c ftp://x5ftp@vrftp.horizon.ai/OpenExplorer/v1.2.8_release/horizon_x5_open_explorer_v1.2.8-py310_20240926.tar.gz --ftp-password=x5ftp@123$%如下所示:

下载完成后解压,文件夹内容如下所示,其中run_docker.sh是我们的启动容器的脚本:

②:打开run_docker.sh,在version参数后加-py310,如下所示:
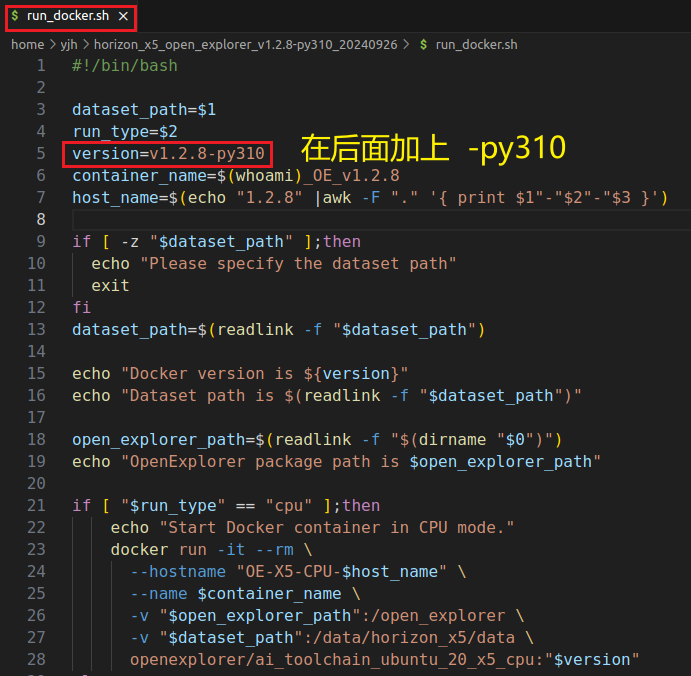
修改后完整的run_docker.sh如下所示:
bash
#!/bin/bash
dataset_path=$1
run_type=$2
version=v1.2.8-py310
container_name=$(whoami)_OE_v1.2.8
host_name=$(echo "1.2.8" |awk -F "." '{ print $1"-"$2"-"$3 }')
if [ -z "$dataset_path" ];then
echo "Please specify the dataset path"
exit
fi
dataset_path=$(readlink -f "$dataset_path")
echo "Docker version is ${version}"
echo "Dataset path is $(readlink -f "$dataset_path")"
open_explorer_path=$(readlink -f "$(dirname "$0")")
echo "OpenExplorer package path is $open_explorer_path"
if [ "$run_type" == "cpu" ];then
echo "Start Docker container in CPU mode."
docker run -it --rm \
--hostname "OE-X5-CPU-$host_name" \
--name $container_name \
-v "$open_explorer_path":/open_explorer \
-v "$dataset_path":/data/horizon_x5/data \
openexplorer/ai_toolchain_ubuntu_20_x5_cpu:"$version"
else
echo "Start Docker container in GPU mode."
docker run -it --rm \
--hostname "OE-X5-GPU-$host_name" \
--name $container_name \
--gpus all \
--shm-size="15g" \
-v "$open_explorer_path":/open_explorer \
-v "$dataset_path":/data/horizon_x5/data \
openexplorer/ai_toolchain_ubuntu_20_x5_gpu:"$version"
fi③:在home下创建一个容器挂载时的文件夹:RDK_X5_related
④:把你转换得到的onnx模型放到 RDK_X5_related 文件夹中
⑤:在 RDK_X5_related 文件夹下再创建一个 cal_data 文件夹,用于存放量化校正数据集
⑥:在数据集中挑选一部分图片,大概50张,放到 cal_data 文件夹下,如下所示:
⑦:在 RDK_X5_related 文件夹下再创建一个 yolov8_config.yaml 文件:
⑧:修改 yolov8_config.yaml 内容,设置好你的onnx模型名以及bin模型名前缀,尽量保持一致,如下所示: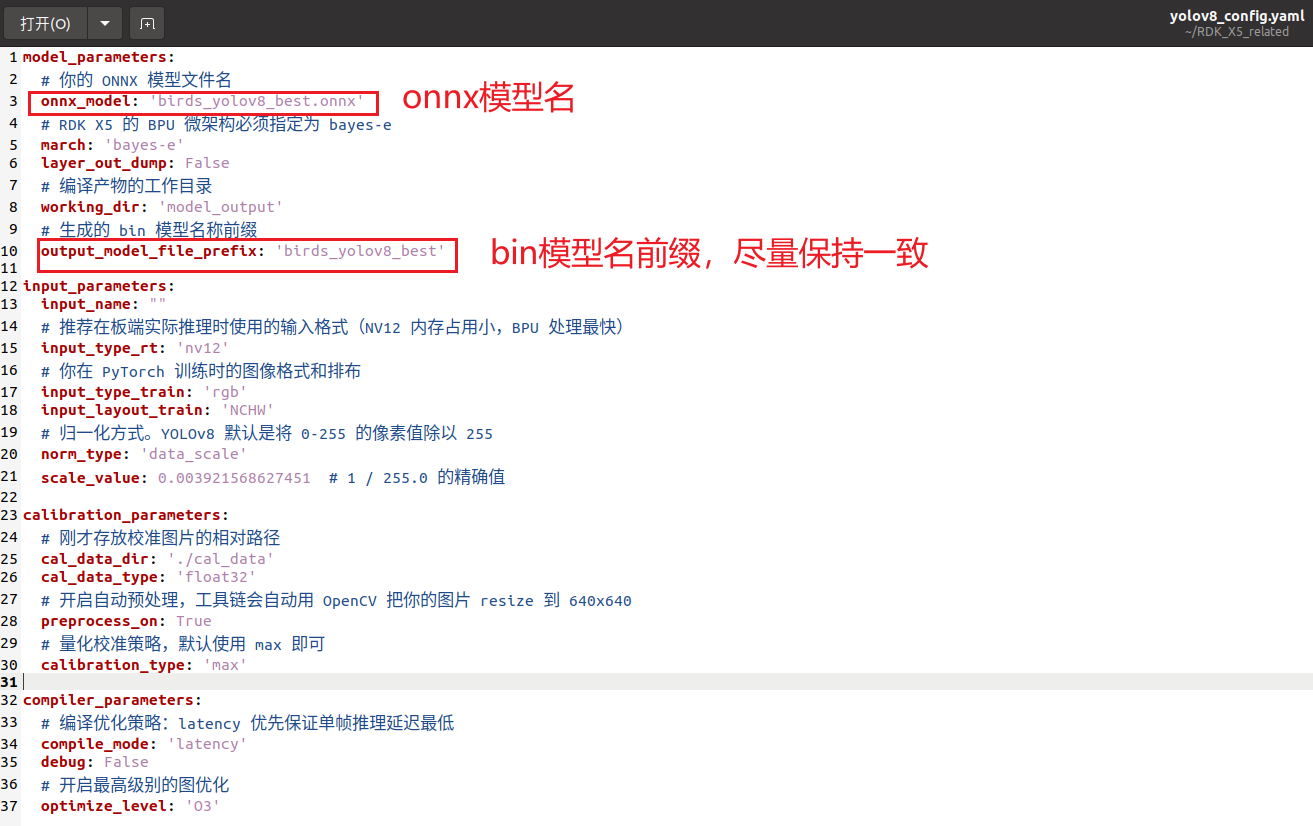
yolov8_config.yaml 代码内容如下所示:
yaml
model_parameters:
# 你的 ONNX 模型文件名
onnx_model: 'birds_yolov8_best.onnx'
# RDK X5 的 BPU 微架构必须指定为 bayes-e
march: 'bayes-e'
layer_out_dump: False
# 编译产物的工作目录
working_dir: 'model_output'
# 生成的 bin 模型名称前缀
output_model_file_prefix: 'birds_yolov8_best'
input_parameters:
input_name: ""
# 推荐在板端实际推理时使用的输入格式(NV12 内存占用小,BPU 处理最快)
input_type_rt: 'nv12'
# 你在 PyTorch 训练时的图像格式和排布
input_type_train: 'rgb'
input_layout_train: 'NCHW'
# 归一化方式。YOLOv8 默认是将 0-255 的像素值除以 255
norm_type: 'data_scale'
scale_value: 0.003921568627451 # 1 / 255.0 的精确值
calibration_parameters:
# 刚才存放校准图片的相对路径
cal_data_dir: './cal_data'
cal_data_type: 'float32'
# 开启自动预处理,工具链会自动用 OpenCV 把你的图片 resize 到 640x640
preprocess_on: True
# 量化校准策略,默认使用 max 即可
calibration_type: 'max'
compiler_parameters:
# 编译优化策略:latency 优先保证单帧推理延迟最低
compile_mode: 'latency'
debug: False
# 开启最高级别的图优化
optimize_level: 'O3'⑨:在horizon_x5_open_explorer_v1.2.8-py310_20240926路径下执行容器运行脚本:
bash
sudo bash run_docker.sh /home/yjh/RDK_X5_related cpu如下所示:
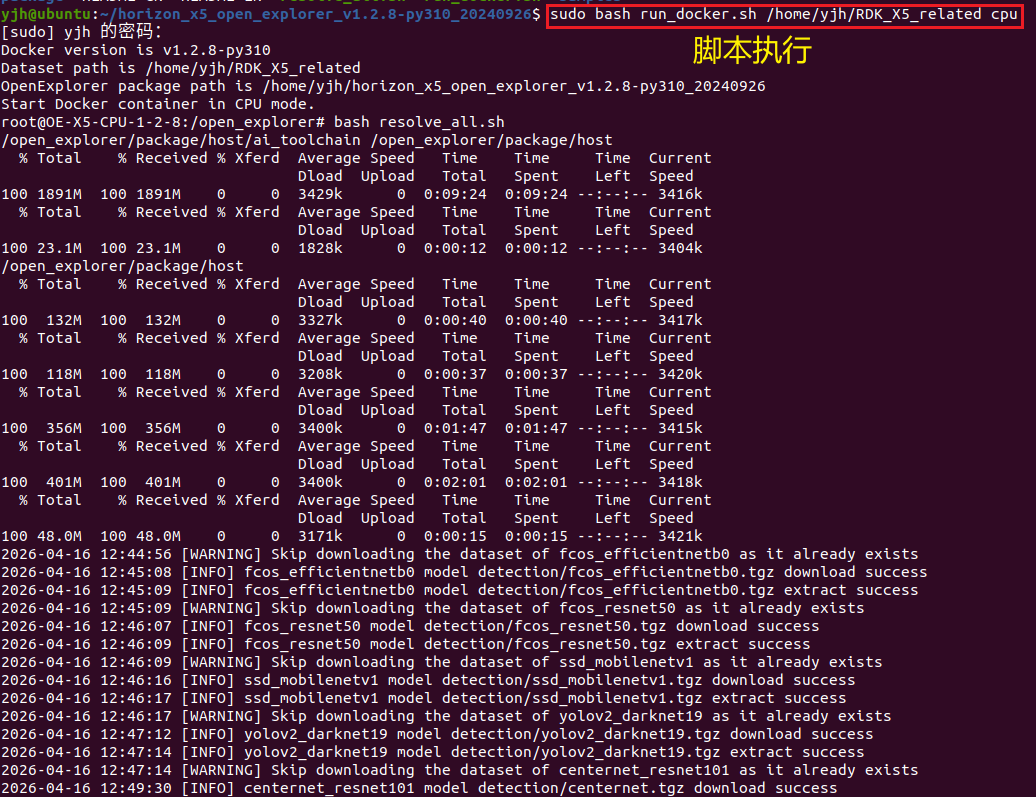
虚拟机内执行完脚本后进入容器了,ls结果:

进入容器后进入挂载路径 /data/horizon_x5/data :

可以看到挂载路径下的内容和我们home下的 rdk_x5_related 文件夹下的内容是一模一样的:

七、容器内ONNX量化bin
①:在完成第六章的最后一步后,直接在容器内的 /data/horizon_x5/data 路径下,调用OE工具链检查onnx模型格式是否正确,注意复制代码时候要改成自己的模型名,如下所示:
bash
hb_mapper checker --model-type onnx --march bayes-e --model birds_yolov8_best.onnx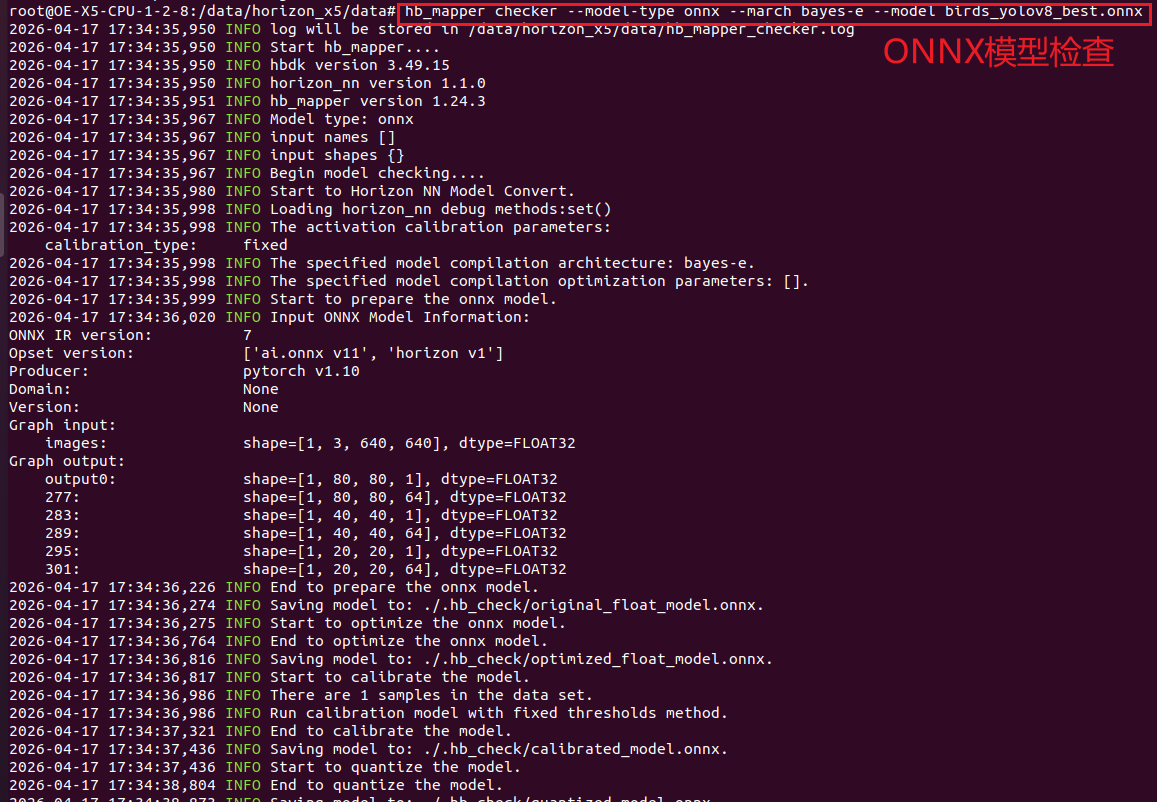
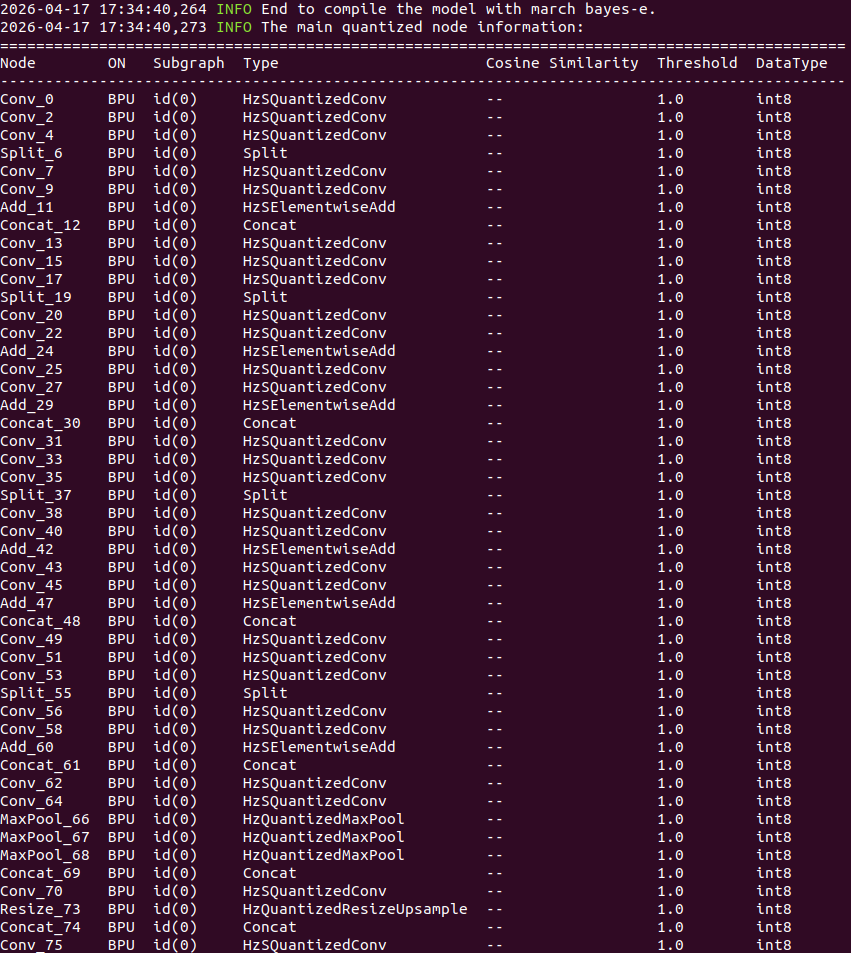
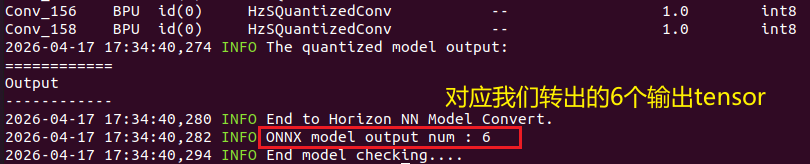
②:开始执行模型量化:
bash
hb_mapper makertbin --model-type onnx --config yolov8_config.yaml如下所示:
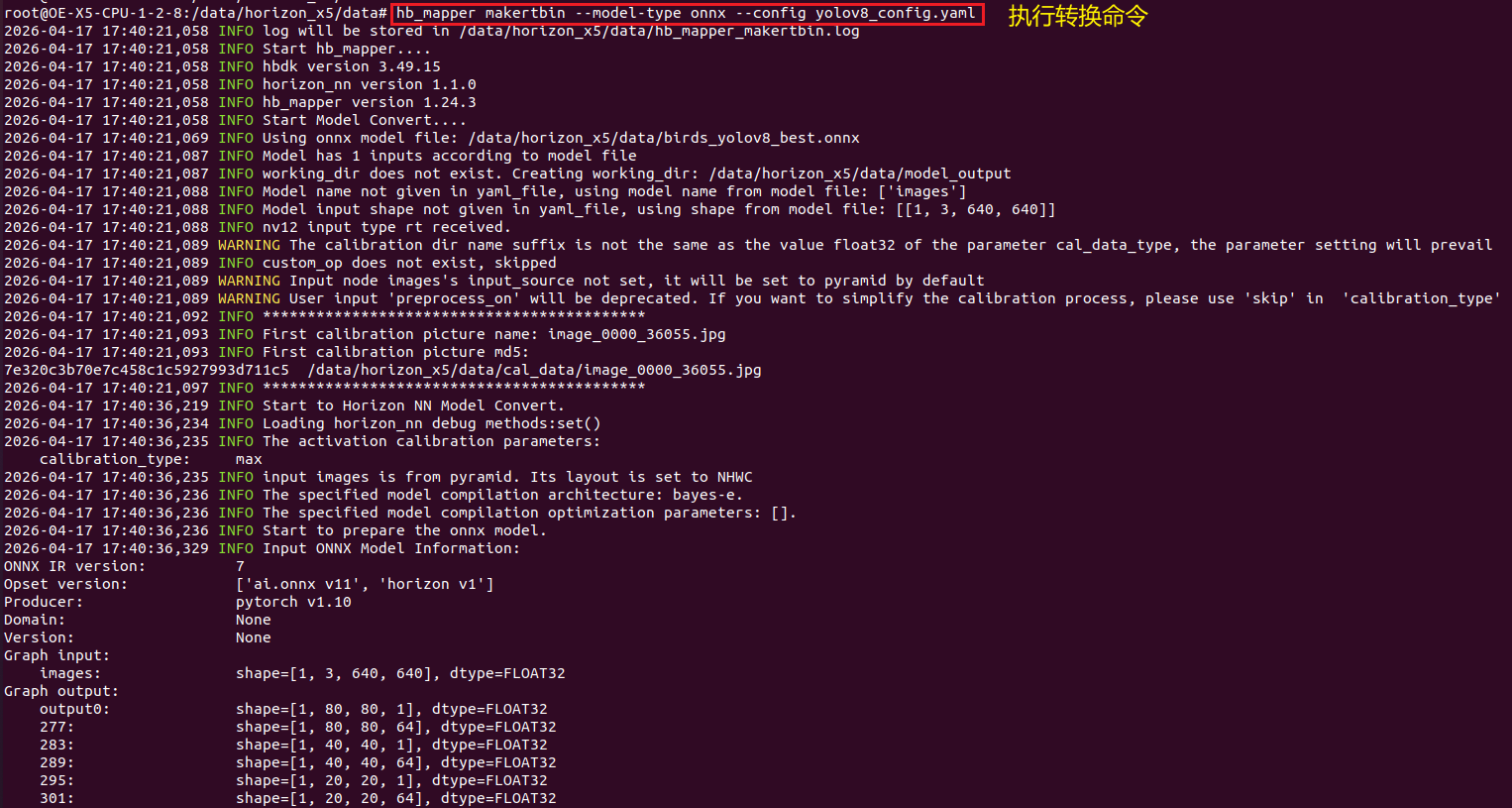
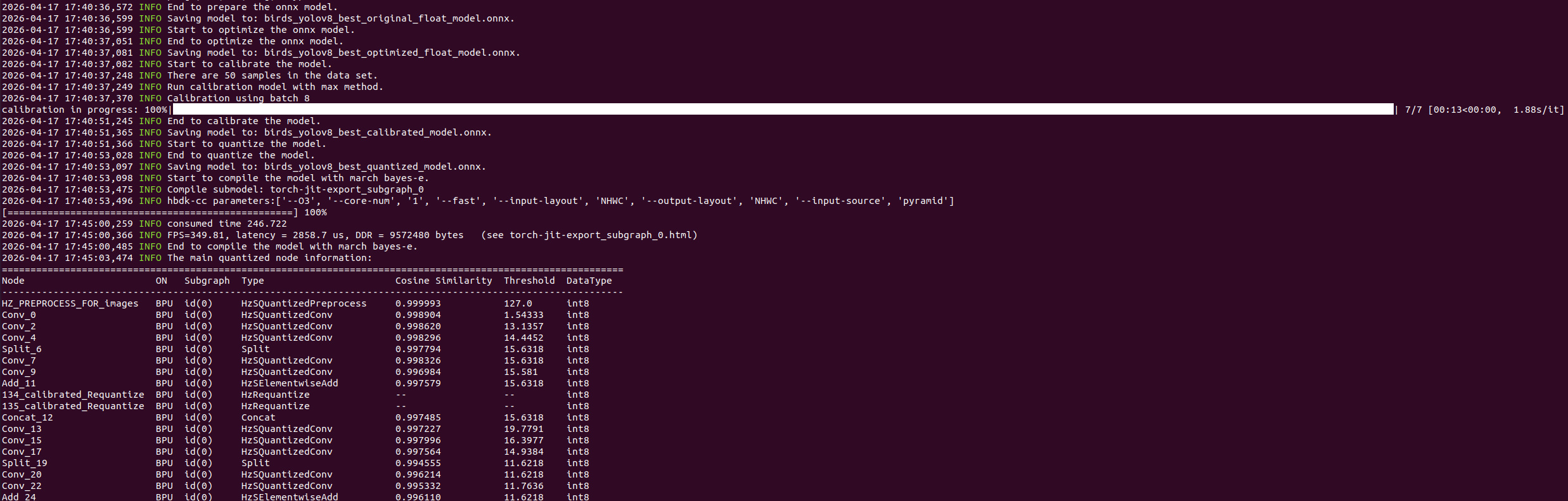
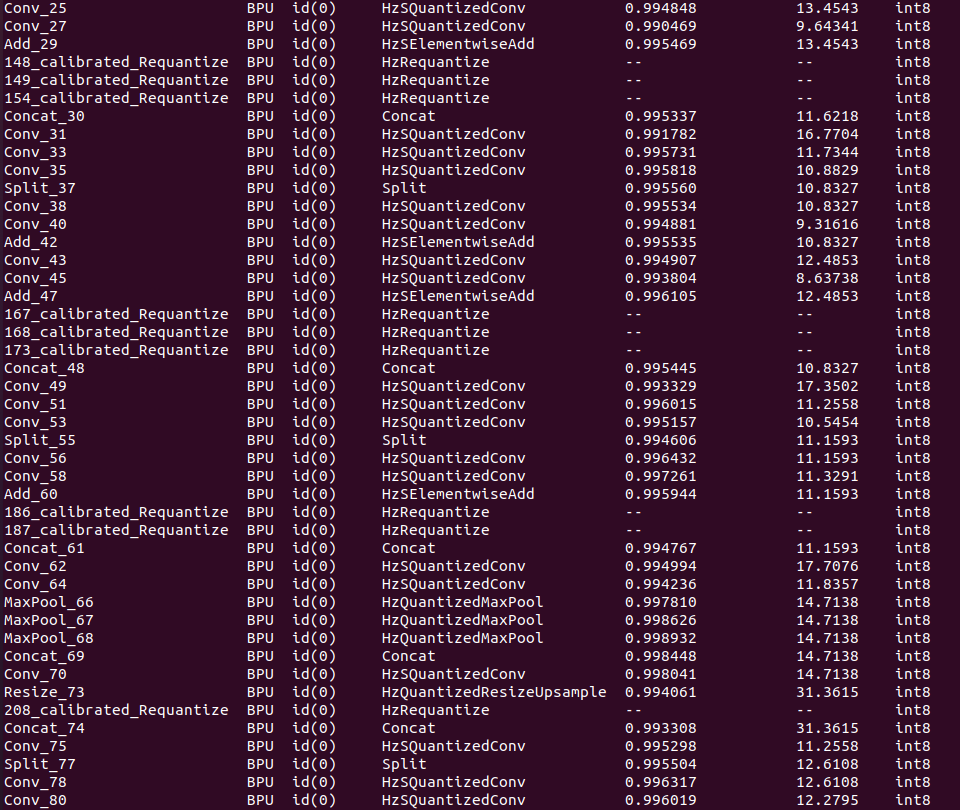
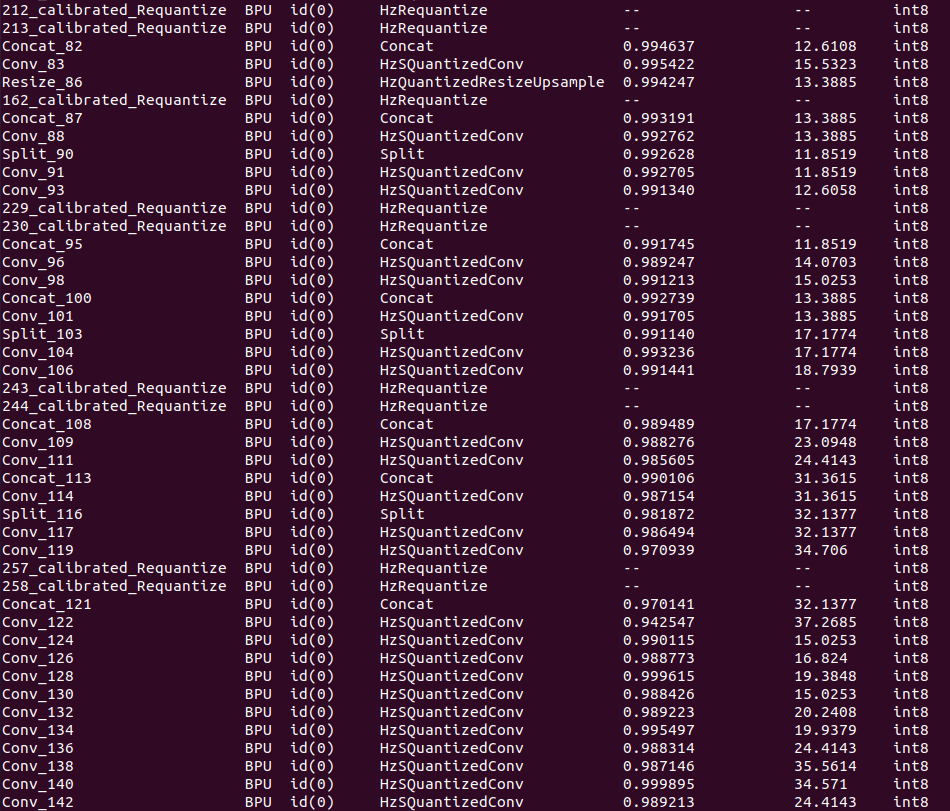
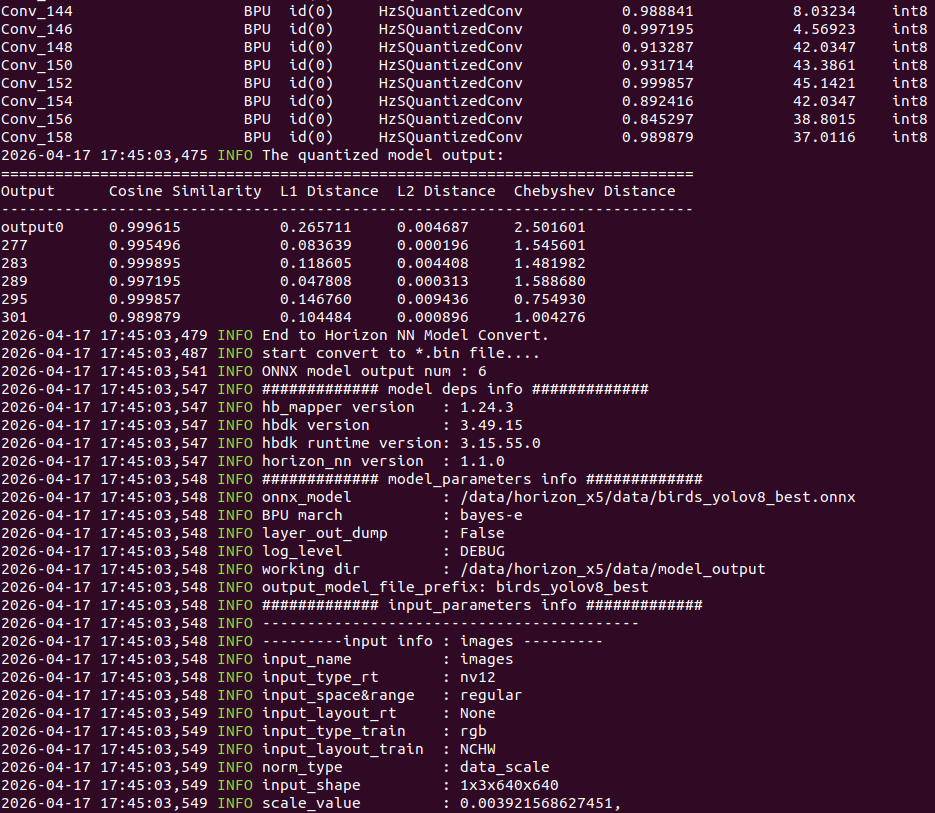
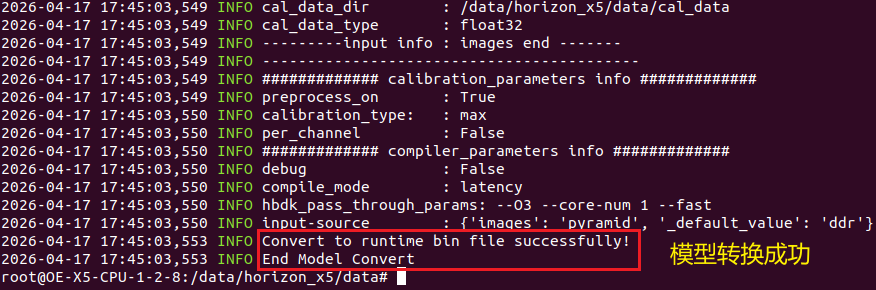
↑可以看到终端输出,模型量化成功
此时,量化好后的bin文件后放在自动生成的RDK_X5_related/model_output文件夹下
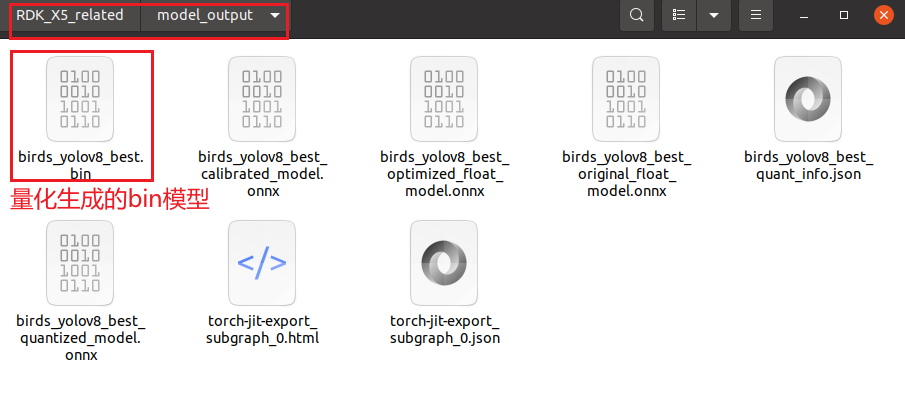
③:在量化生成的.bin模型基础上,剪除其反量化节点:
注意,反量化节点可能有点刚接触的同学不太熟悉,底层数学原理就不一一介绍了,直接按博主流程操作即可
1、查询.bin模型中能够删除的反量化节点名称:
bash
hb_model_modifier birds_yolov8_best.bin如下所示:

2、执行删除命令,注意要把模型名以及对应的节点名改成自己的:
bash
hb_model_modifier birds_yolov8_best.bin \
-r output0_HzDequantize \
-r 276_HzDequantize \
-r 283_HzDequantize \
-r 288_HzDequantize \
-r 295_HzDequantize \
-r 300_HzDequantize如下所示:
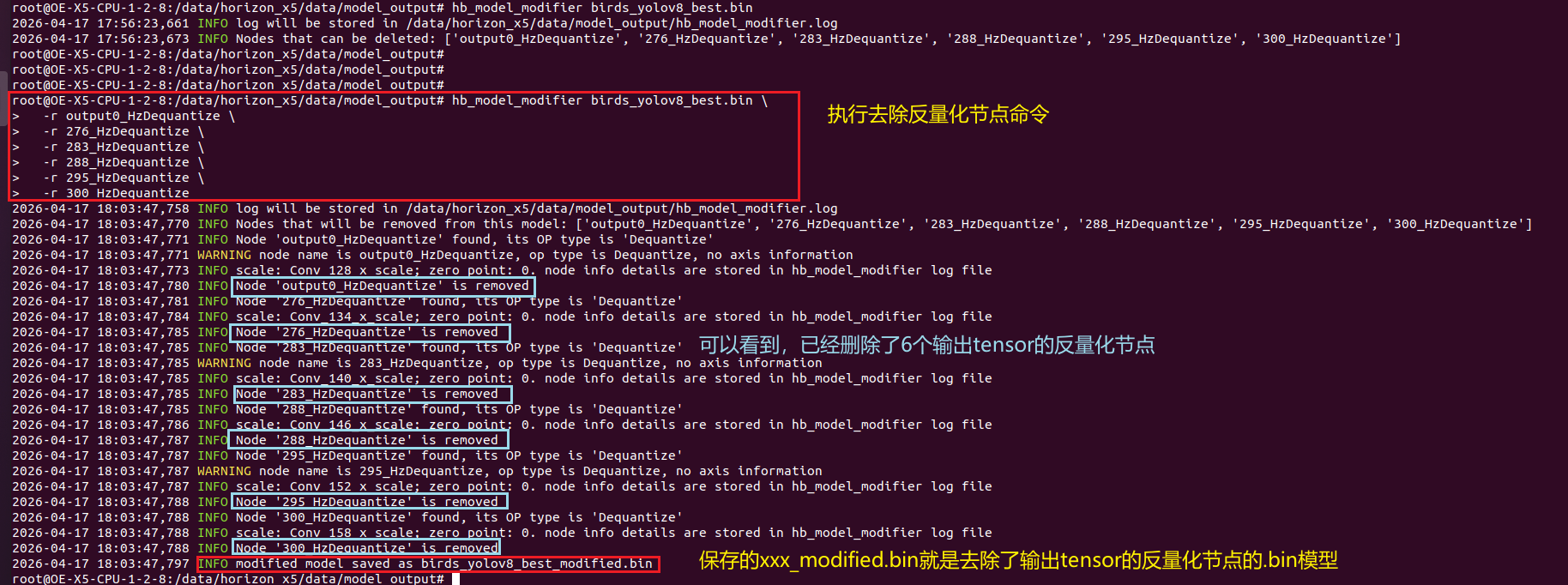
↑可以看到,已经生成了birds_yolov8_best_modified.bin,这里modified的意思就是指去除了反量化节点后的.bin模型,而且这个xxx_modified.bin模型同样保存在 model_output 文件夹下:
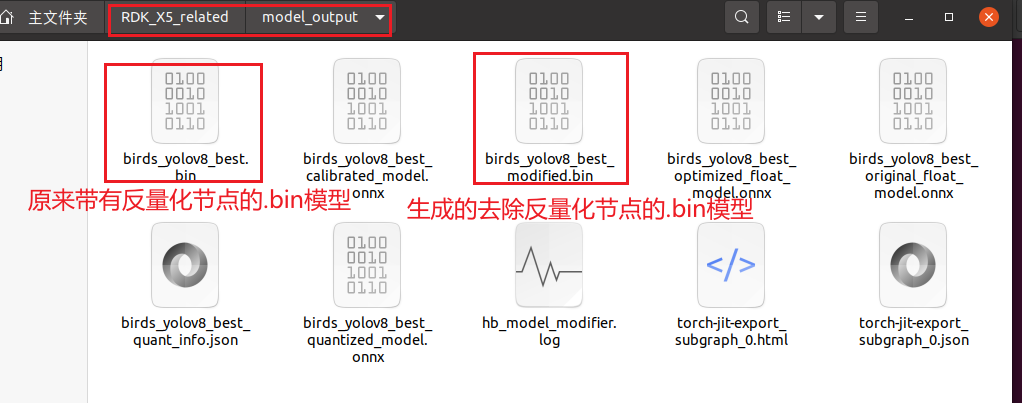
然后现在可以把birds_yolov8_best.bin和birds_yolov8_best_modified.bin这两个模型都复制到PC端本地了,然后上传到RDK X5开发板上
八、RDK X5边缘模型部署
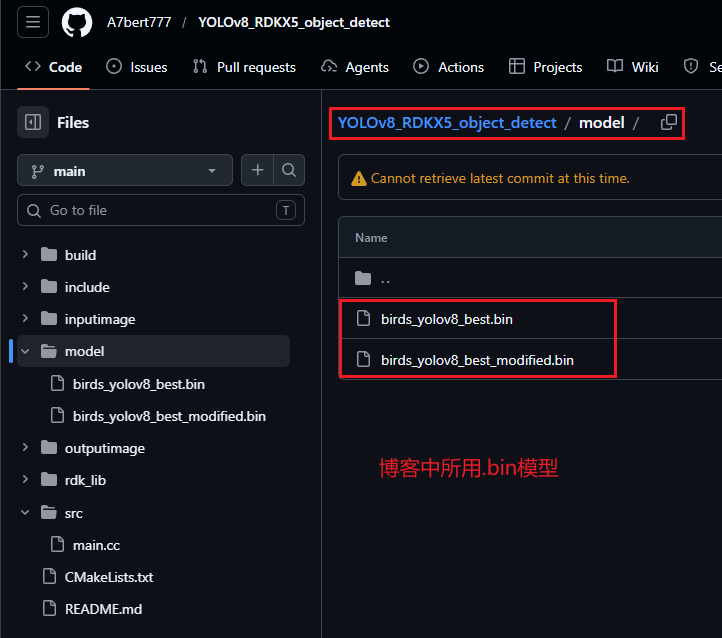
在完成上述流程后,我们已经得到了符合要求的.bin以及xxx_modified.bin模型了,此时打开第三个项目文件,即博主的个人仓库,我已经把自己的birds_yolov8_best.bin和birds_yolov8_best_modified.bin这两个模型放到了Github项目的model文件夹下、测试图片放到inputimage文件夹下,大家 git clone 后可直接先把编译的相关内容删掉然后重新编译,再用我的模型和图片直接运行测试
项目地址:https://github.com/A7bert777/YOLOv8_RDKX5_object_detect
如果项目对大家有所帮助,希望点个免费的小星星:
git clone后把项目复制到开发板上,按如下流程操作:
如果需要直接测试博主的模型效果,如下所示:
可以在进入build文件夹,直接执行:
bash
./rdk_yolov8_detect查看运行结果。
如果使用自己的模型,修改流程如下所示:
①:cd build,删除所有build文件夹下的内容
②:cd src 修改main.cc,修改main函数中的如下几处内容:
先修改模型路径名、输入图片文件夹路径、输出图片文件夹路径、以及REMOVE_DEQUANT_NODE参数
这里着重说一下REMOVE_DEQUANT_NODE参数,
如果你加载的模型你是带反量化节点的模型,即xxx.bin,则REMOVE_DEQUANT_NODE设置为0或1都可以,
如果加载的是xxx_modified.bin,则REMOVE_DEQUANT_NODE必须设置为1
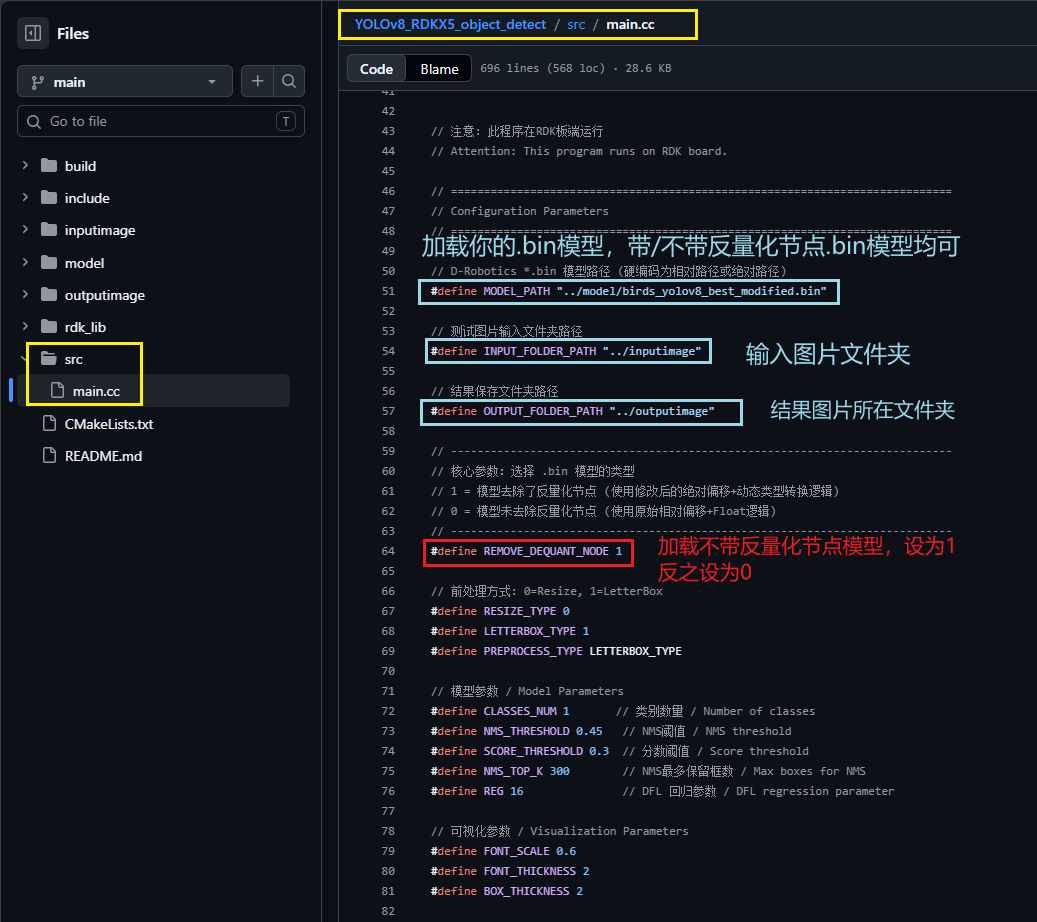
再修改CLASSES_NUM、NMS阈值、得分阈值:
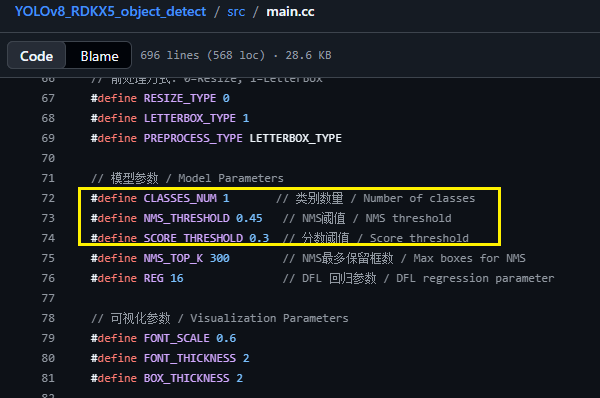
再修改类别名:博主模型只识别一个类别:"bird",如果要识别多个类别,后面加","后换行
修改完成后,保存main.cc
再删除inputimage和outputimage下的所有图片,然后将你要批量检测的图片放到inputimage下后,
在build路径下执行如下命令:
bash
cmake ..
bash
make,
终端结果如下所示:
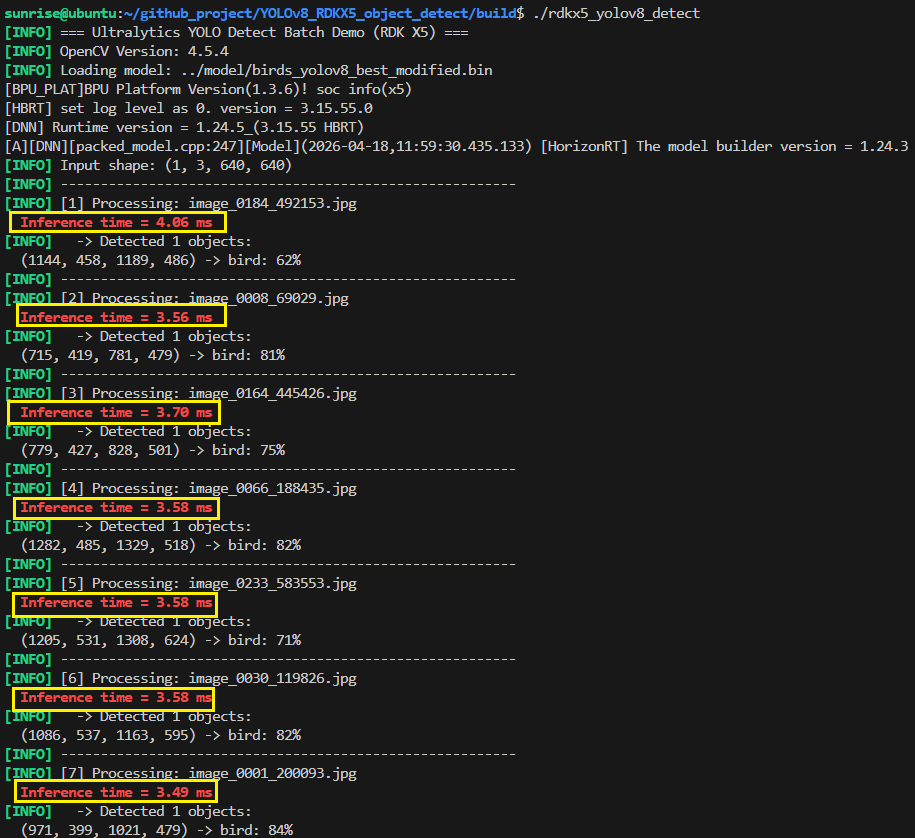
注意,此时使用的是xxx_modified.bin模型跑出的结果。
现在换成xxx.bin模型后,修改REMOVE_DEQUANT_NODE参数后再次make后运行,如下所示:
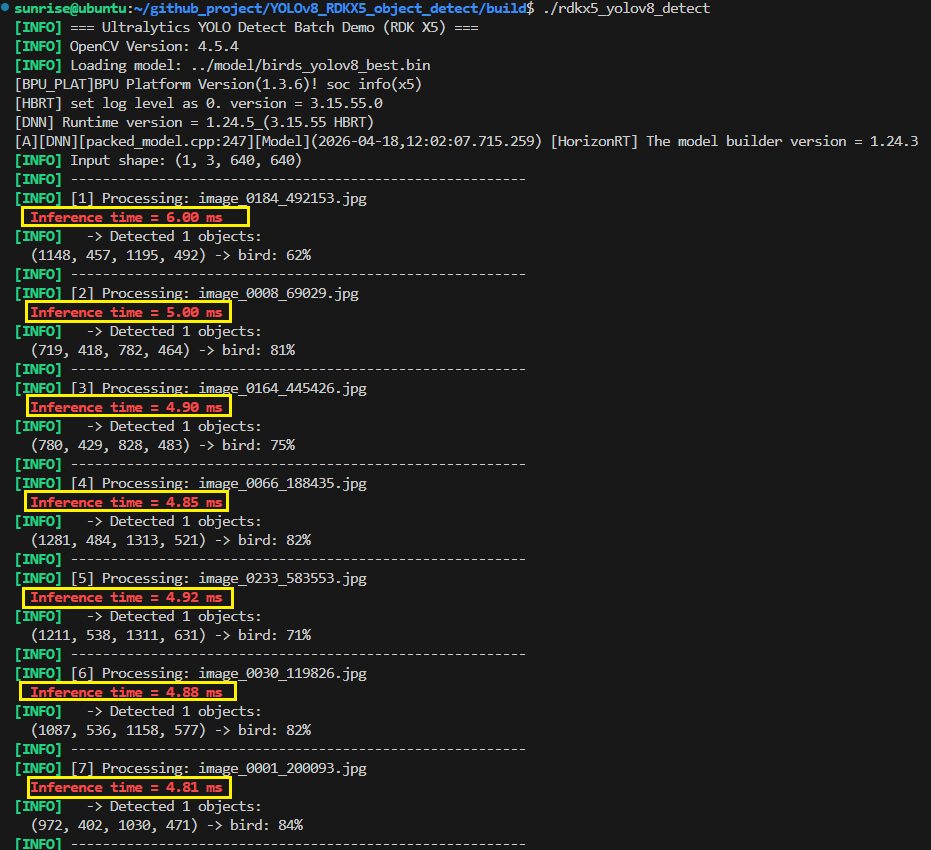
两次结果对比可以明显看到,去除了反量化节点后的xxx_modified.bin模型的推理速度明显要快于xxx.bin模型,所以说xxx.bin模型和xxx_modified.bin模型都可以用,但是xxx_modified.bin模型对RDKX5上的Sunrise5 SoC更加又好,优化了大量的总线带宽被严重挤占的问题,对于开发板整体运行情况有较大改善。
以下是博主在RDKX5上完成推理自测后的结果图:
原图1:

结果图1:

原图2:
结果图2:

上述即博主此次更新的YOLOv8部署地瓜RDK X5适配Sunrise 5 SoC的全部流程,包含PT转ONNX转.bin/modified.bin的完整步骤,欢迎交流!