- [从LLM到Agent Skill:AI核心技术全拆解与系统化学习路线](#从LLM到Agent Skill:AI核心技术全拆解与系统化学习路线)
-
- 一、核心概念与关键步骤全拆解(对应图谱9大模块)
-
- [1. 底层引擎:大语言模型(LLM, Large Language Model)](#1. 底层引擎:大语言模型(LLM, Large Language Model))
- [2. 数据处理单元:Token](#2. 数据处理单元:Token)
- [3. 临时记忆体:Context(上下文)](#3. 临时记忆体:Context(上下文))
- [4. 指令交互:Prompt(提示词)](#4. 指令交互:Prompt(提示词))
- [5. 外部能力扩展:Tool(工具)](#5. 外部能力扩展:Tool(工具))
- [6. 工具标准化:MCP(Model Context Protocol,模型上下文协议)](#6. 工具标准化:MCP(Model Context Protocol,模型上下文协议))
- [7. 自主决策系统:Agent(智能体)](#7. 自主决策系统:Agent(智能体))
- [8. 任务定制:Agent Skill(智能体技能)](#8. 任务定制:Agent Skill(智能体技能))
- [9. 概念体系层级关系(核心递进链)](#9. 概念体系层级关系(核心递进链))
- 二、系统化学习路线(分4阶段,从入门到精通)
-
- [阶段1:基础入门(LLM + Token + Context + Prompt)------ 打牢底层认知](#阶段1:基础入门(LLM + Token + Context + Prompt)—— 打牢底层认知)
- [阶段2:进阶能力(Tool + MCP)------ 扩展大模型外部能力](#阶段2:进阶能力(Tool + MCP)—— 扩展大模型外部能力)
- [阶段3:高阶系统(Agent + Agent Skill)------ 构建自主智能系统](#阶段3:高阶系统(Agent + Agent Skill)—— 构建自主智能系统)
- [阶段4:工程落地与生态整合------ 全链路实战](#阶段4:工程落地与生态整合—— 全链路实战)
- 三、学习资源与避坑指南
- 四、Unity开发者定制化学习路线(结合工作场景)
从LLM到Agent Skill:AI核心技术全拆解与系统化学习路线
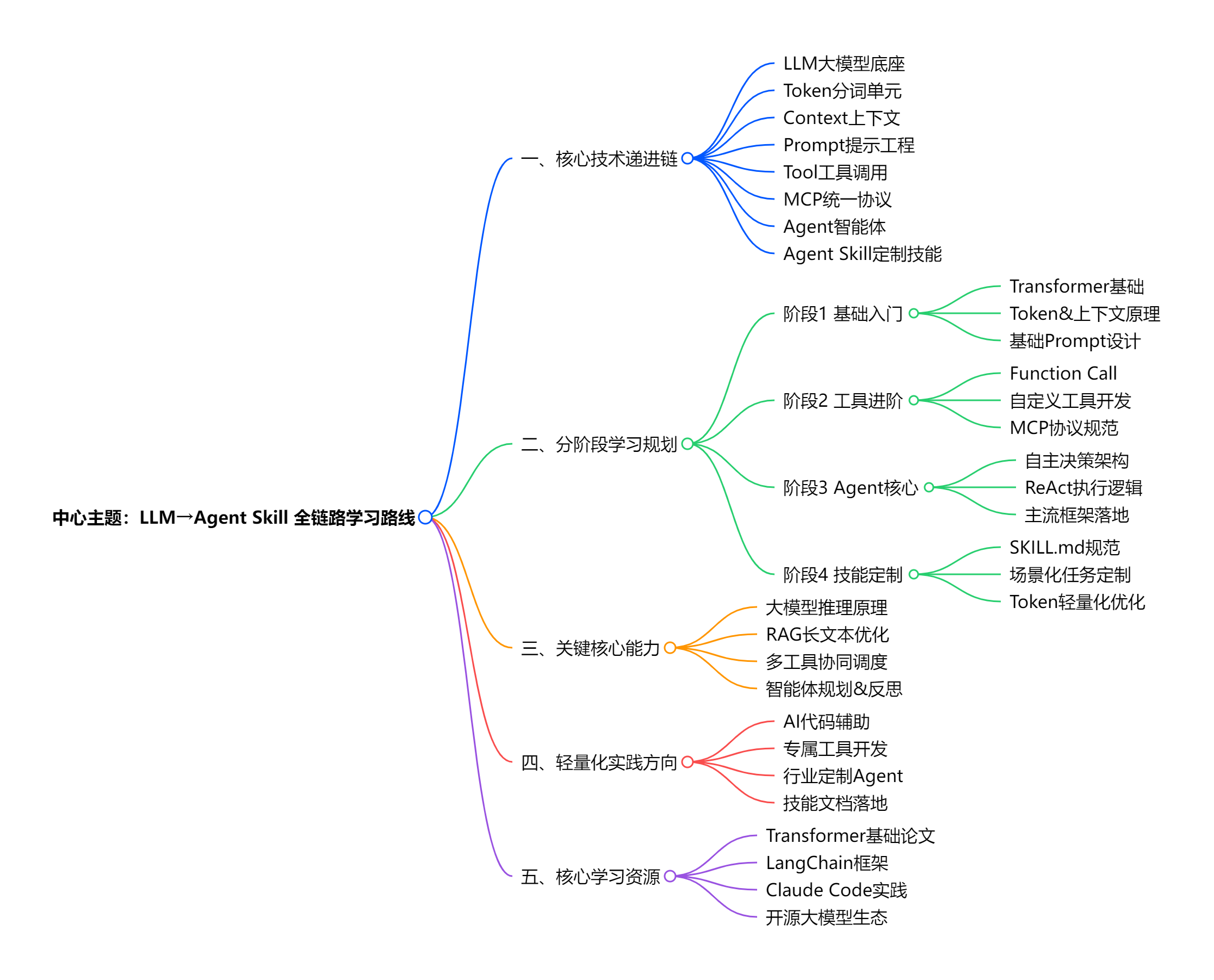
完整拆解从底层大模型到任务定制的全链路关键步骤,并给出分阶段可落地的学习路线,同时适配作为开发者的场景做定制化优化。
一、核心概念与关键步骤全拆解(对应图谱9大模块)
1. 底层引擎:大语言模型(LLM, Large Language Model)
-
核心定义:基于Transformer架构的生成式AI,本质是「文字接龙」------通过预测下一个概率最高的词生成连续文本。
-
技术底座:2017年Google论文《Attention is All You Need》提出的Transformer架构,是所有大模型的技术根基。
-
发展里程碑 :
时间 事件 意义 2017年 Transformer架构提出 奠定大模型技术基础 2022年底 GPT-3.5发布 首个达到可用级别的大模型 2023年3月 GPT-4发布 大幅提升AI能力天花板 2023年后 Claude、Gemini等模型涌现 AI赛道从OpenAI独角戏变为多强竞争 -
学习核心:Transformer自注意力机制、大模型训练/微调/推理原理、主流模型(GPT、Claude、Gemini、开源Llama/Qwen)特性差异。
2. 数据处理单元:Token
-
核心定义 :大模型处理文本的最小单位,由Tokenizer(分词器)将文本切分为片段,再映射为Token ID(数字),解码时还原为文本。
-
关键特性 :与自然语言单位非一一对应
语言单位 与Token的关系 示例 中文词语 可能被拆分 "工作坊"→"工作"+"坊" 英文常见词 通常对应1个Token "hello"→1个Token 复杂英文单词 可能被拆分 "helpful"→"help"+"ful" 特殊字符 可能需多个Token ✅→3个Token -
量化参考 :
- 1个Token ≈ 0.75个英文单词 / 1.5-2个汉字
- 40万Token ≈ 60-80万汉字 或 30万英文单词
-
学习核心:BPE(字节对编码)分词原理、不同模型Tokenizer差异、Token计数对API成本/上下文窗口的影响。
3. 临时记忆体:Context(上下文)
-
核心定义 :大模型每次处理任务的信息总和(临时记忆),包含用户问题、对话历史、当前输出Token、工具列表、System Prompt等。
-
核心限制 :
Context Window(上下文窗口),即模型最大可处理的Token数量,决定了模型能"记住"的对话/文档规模。 -
主流模型上下文窗口对比 :
模型 Context Window(Token) 约合汉字数量 GPT-5.4 105万 约157.5万 Gemini 3.1 Pro 100万 约150万 Claude Opus 4.6 100万 约150万 -
突破限制方案:RAG(检索增强生成)------从知识库抽取与问题最相关的片段,仅将关键信息送入模型,大幅降低Token消耗。
-
学习核心:上下文窗口优化、RAG技术原理与工程落地、长上下文处理实践。
4. 指令交互:Prompt(提示词)
- 核心定义 :给大模型的问题/指令,直接决定输出质量;分为两类:
User Prompt:用户输入的具体任务(如"帮我写一首诗")System Prompt:开发者后台配置的人设与做事规则(如"你是耐心的数学老师,引导学生思考而非直接给答案")
- Prompt Engineering(提示词工程) :
- 核心原则:清晰、具体、明确
- 现状:重要性下降(门槛低+大模型能力提升,可自主理解模糊意图)
- 学习核心:System Prompt设计、高效Prompt编写、思维链(CoT)/Few-Shot等进阶提示技巧。
5. 外部能力扩展:Tool(工具)
-
核心定义 :大模型调用的外部函数,弥补大模型实时信息缺失、计算能力弱的短板,让模型感知/影响外部环境。
-
完整工作流程 :
- 用户提问 → 平台转发(含工具列表)
- 大模型分析 → 生成工具调用指令
- 平台执行调用 → 获取结果
- 大模型整理结果 → 自然语言输出
-
角色分工 :
角色 职责 大模型 选择工具、生成参数、归纳结果 工具 执行具体功能(如查天气、算数学、查数据库) 平台 转发信息、执行工具调用 -
学习核心:Function Call原理与格式、自定义工具开发、工具调用错误处理与优化。
6. 工具标准化:MCP(Model Context Protocol,模型上下文协议)
- 核心定义:统一的工具接入标准,解决不同AI平台工具接入规范不统一的问题(类比Type-C充电口统一标准)。
- 核心价值:工具开发者只需按MCP规范开发一次,即可在所有支持MCP的平台使用,大幅降低适配成本。
- 学习核心:MCP协议规范、跨平台工具开发与适配、MCP生态落地。
7. 自主决策系统:Agent(智能体)
- 核心定义 :能够自主规划、自主调用工具、持续工作直至完成用户任务的系统,是大模型从"问答工具"到"自主助手"的核心升级。
- 核心能力:多步骤推理、工具选择、流程控制
- 代表产品:Claude Code、Codex、Gemini CLI等
- 典型构建模式:ReAct、Plan and Execute等
- 学习核心:Agent架构原理、主流Agent框架(LangChain、AutoGPT等)、Agent规划与反思机制、多Agent协作。
8. 任务定制:Agent Skill(智能体技能)
- 核心定义 :给Agent的说明文档,包含任务规则、执行步骤、输出格式等,实现Agent的任务定制化。
- 标准结构 :
- 元数据层:名称(name)、描述(description)
- 指令层:目标、执行步骤、判断规则、输出格式、示例
- 技术实现规范 :
- 存储形式:Markdown文档(文件名必须为
SKILL.md) - 存储位置:特定目录(如Claude Code的
claude/skills文件夹) - 加载机制:仅在用户问题与技能名称/描述相关时加载,节省Token
- 存储形式:Markdown文档(文件名必须为
- 学习核心:Skill文档编写规范、自定义Skill开发、渐进式披露机制(Token优化)。
9. 概念体系层级关系(核心递进链)
LM(核心引擎) → Token(数据单位) → Context(记忆空间) → Prompt(交互接口) → Tool(外部能力) → MCP(工具标准) → Agent(决策系统) → Agent Skill(任务定制)
- 补充细节 :
- Transformer由Google提出,OpenAI通过GPT系列引爆应用
- Token切分基于BPE(字节对编码)算法
- Agent Skill支持运行代码、引用资源,采用渐进式披露节省Token
- RAG技术专门解决Context Window限制问题
二、系统化学习路线(分4阶段,从入门到精通)
阶段1:基础入门(LLM + Token + Context + Prompt)------ 打牢底层认知
目标 :理解大模型核心原理,掌握基础交互与优化
学习内容:
- LLM基础:
- 精读《Attention is All You Need》,掌握Transformer自注意力、编码器-解码器结构
- 了解主流大模型(GPT-3.5/4、Claude、Gemini、开源Llama/Qwen)的特性与适用场景
- Token与Context:
- 学习BPE分词原理,用
tiktoken库实践Token计数,理解Token与汉字/单词的换算 - 学习上下文窗口限制,入门RAG技术原理
- 学习BPE分词原理,用
- Prompt工程:
- 掌握System Prompt设计、高效User Prompt编写,学习Few-Shot、Chain-of-Thought(思维链)等技巧
实践任务:
- 掌握System Prompt设计、高效User Prompt编写,学习Few-Shot、Chain-of-Thought(思维链)等技巧
- 用
tiktoken统计代码、技术文档的Token数,理解长代码的Token消耗 - 编写一个高质量System Prompt(如"专业的技术顾问,输出带注释的可运行代码"),测试输出效果
- 用LangChain入门案例实现简单RAG,处理长文档,解决上下文不足问题
阶段2:进阶能力(Tool + MCP)------ 扩展大模型外部能力
目标 :掌握工具调用与标准化,让大模型"能做事"
学习内容:
- Tool工具调用:
- 学习OpenAI/Anthropic/Google的Function Call规范与格式
- 用Python开发自定义工具(如项目打包工具、Shader性能分析工具)
- 学习工具调用的参数校验、错误处理、结果优化
- MCP协议:
- 学习MCP(Model Context Protocol)的规范与设计思想
- 按MCP标准重构工具,实现跨平台兼容
实践任务:
- 开发一个项目代码审查工具,集成到GPT/Claude
- 用MCP规范重构工具,适配Claude Code等多平台
- 搭建完整工具调用流程:用户提问→工具调用→结果返回→自然语言输出
阶段3:高阶系统(Agent + Agent Skill)------ 构建自主智能系统
目标 :掌握Agent架构,实现任务定制化自主执行
学习内容:
- Agent智能体:
- 学习Agent核心架构(ReAct、Plan-and-Execute等模式)
- 掌握主流Agent框架(LangChain、AutoGPT、Claude Code、Gemini CLI)
- 学习Agent的规划、反思、工具选择、多步骤推理机制
- Agent Skill:
- 学习
SKILL.md编写规范,掌握元数据+指令层的结构设计 - 学习渐进式披露机制,优化Token消耗
实践任务:
- 学习
- 用LangChain搭建一个技术博客自动生成Agent
- 为Claude Code开发专属Skill(如
SRP Batcher配置Skill、光照烘焙优化Skill,存为SKILL.md) - 测试Agent的自主执行能力,优化规划与反思逻辑
阶段4:工程落地与生态整合------ 全链路实战
目标 :从0到1落地完整AI系统,适配业务场景
学习内容:
- 全链路整合:
- 整合LLM、RAG、Tool、MCP、Agent、Skill,搭建完整AI工作流
- 学习大模型应用的工程化(部署、监控、成本优化、Token优化)
- 业务适配:
- 针对游戏开发场景定制Agent与Skill(如内存泄漏排查、Shader优化、AssetBundle打包)
- 学习大模型应用的安全、合规、隐私保护
- 前沿跟进:
- 跟进Agent、MCP、长上下文、RAG等领域的最新技术
实践任务:
- 跟进Agent、MCP、长上下文、RAG等领域的最新技术
- 搭建面向游戏开发的AI助手系统:集成LLM(GPT-4/Claude)、RAG(游戏官方文档知识库)、Tool(游戏项目分析工具)、MCP标准化、Agent(自动代码审查/优化)、Skill(游戏光照优化、SRP Batcher配置等)
- 优化系统的Token消耗、响应速度、输出质量,落地到实际开发流程
三、学习资源与避坑指南
推荐学习资源
- 基础理论 :
- 论文:《Attention is All You Need》(Transformer基石)、《ReAct: Synergizing Reasoning and Acting in Language Models》(Agent经典)
- 课程:DeepLearning.AI《Large Language Models Specialization》(吴恩达团队,LLM入门)、LangChain官方文档(Agent/Tool/RAG学习)
- 工具实践 :
tiktoken(OpenAI官方Token计数库)- LangChain(Agent/Tool/RAG框架)
- Claude Code(Agent Skill实践)
- MCP官方文档(工具标准化)
- 开源项目 :
- Llama 3(开源大模型)、Qwen(通义千问开源模型)
- AutoGPT(经典Agent项目)、LangGraph(LangChain的Agent编排工具)
避坑指南
- 不要跳过基础:直接学Agent而不懂LLM/Token/Context,会无法理解Agent的限制与优化点
- Prompt工程不要过度神话:大模型能力提升后,清晰的指令比复杂的提示技巧更重要
- 工具调用要重视错误处理:大模型生成的工具参数可能错误,必须做参数校验与容错
- Agent不是越复杂越好:简单的ReAct模式足够多数场景,过度复杂的规划会降低效率
- Token优化是核心:长上下文、Skill的渐进式披露、RAG都是为了节省Token,降低成本+提升速度
四、Unity开发者定制化学习路线(结合工作场景)
针对作为Unity程序员的背景,将学习路线与工作深度结合,最大化提升开发效率:
- 基础阶段:用LLM做Unity代码助手,优化Prompt(如"帮我写URP Lit Shader,带SRP Batcher兼容代码"),理解长代码的Token消耗
- 进阶阶段:开发Unity专属Tool(如"Unity项目打包工具"、"Shader性能分析工具"、"内存泄漏排查工具"),用MCP标准化适配多平台
- 高阶阶段 :开发Unity专属Agent(如"自动优化Unity项目内存的Agent"、"Shader代码审查Agent"),编写Unity相关Skill(如
SRP Batcher配置Skill、光照烘焙优化Skill、YooAsset打包配置Skill) - 落地阶段:搭建Unity开发AI助手,集成到你的开发流程,实现代码生成、审查、优化、打包的全流程自动化