网易新闻数据爬取分析系统技术文档
1. 文档说明
1.1 项目名称
基于 Python 的网易新闻数据爬取分析系统
1.2 文档目标
本文档用于完整说明本项目当前实现形态下的技术架构、关键设计、核心数据模型、爬虫导入链路、权限体系、可视化分析模块、前后端交互方式、部署运行方式以及后续可扩展方向。
本文档不是模板化说明,而是基于当前仓库中的实际代码整理得到,重点覆盖已经落地的关键设计。
1.3 文档适用对象
- 项目开发者
- 毕业设计答辩材料整理人员
- 后续接手维护该项目的工程人员
- 需要基于本系统继续扩展爬虫、分析和可视化功能的使用者
2. 项目概述
本项目是一个面向网易新闻数据的综合性新闻管理分析平台,核心目标是完成以下闭环:
- 从网易新闻站点抓取新闻列表、新闻详情和评论详情
- 将抓取结果结构化写入 Django 后端数据库
- 提供新闻检索、管理、详情查看与评论查看能力
- 对新闻内容、评论互动、发布时间、情感倾向等进行分析
- 通过前端管理端和可视化大屏展示分析结果
当前项目已经从"基础新闻字段存储"升级为"富字段新闻 + 评论明细 + 运营分析 + 权限管理"的综合平台。
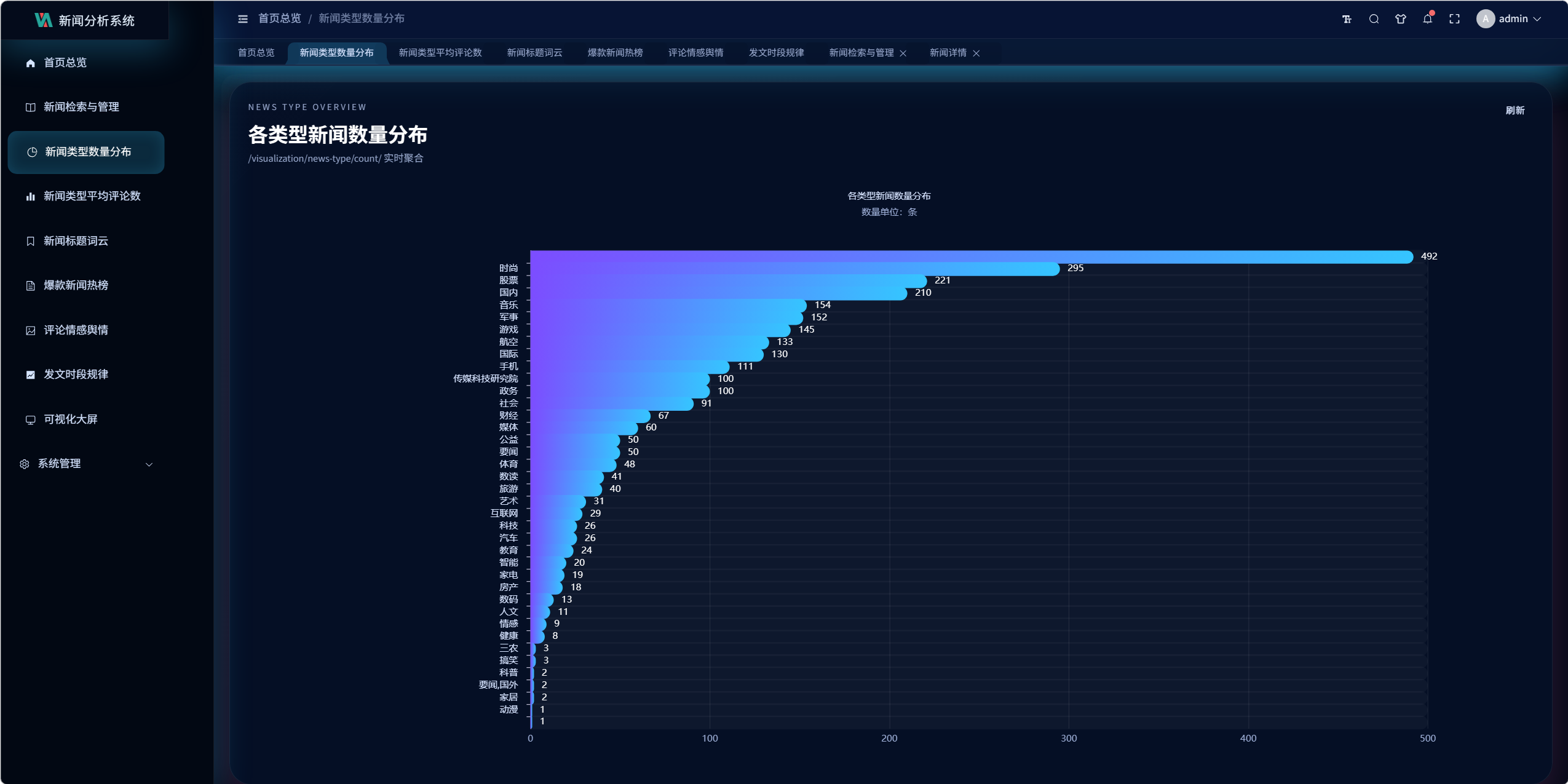
截至 2026-04-19,当前数据库中关键数据规模如下:
| 指标 | 数量 |
|---|---|
| 新闻总量 | 2938 |
| 网易新闻量 | 2936 |
| 评论总量 | 13273 |
| 用户数量 | 2 |
| 角色数量 | 2 |
3. 总体架构设计
3.1 架构组成
项目由三部分组成:
-
NewsCrawler- 原始网易新闻爬虫工程
- 提供网易新闻页面抓取与解析能力
-
DjangoProject1- 当前后端主工程
- 负责用户认证、权限控制、新闻写库、评论写库、分析接口、管理接口
-
simple-admin-ts-master- Vue3 + Vite + TypeScript 前端管理端
- 负责首页总览、新闻检索与管理、新闻详情、图表分析、大屏展示、用户与角色管理
3.2 架构流转
系统主链路如下:
text
网易新闻网页 / 评论接口
↓
NewsCrawler 解析
↓
Django 导入器 netease_importer.py
↓
NewsInfo / NewsComment 数据表
↓
Django API
↓
Vue 管理端 / 可视化大屏3.3 技术选型
后端
- Python 3.8
- Django
- Django REST 风格接口组织方式
- requests
- jieba
- SnowNLP
前端
- Vue 3
- Vite
- TypeScript
- Pinia
- Vue Router
- Element Plus
- ECharts
数据存储
- MySQL 风格数据表设计
- 当前 Django 通过 ORM 管理业务主表
4. 目录结构说明
项目根目录关键结构如下:
text
F:\code\356-基于Python的网易新闻数据分析系统
├── DjangoProject1
│ ├── DjangoProject1
│ └── news
├── NewsCrawler
├── simple-admin-ts-master
├── design_356_news.sql
└── news_analysis.sql4.1 后端目录
DjangoProject1/news 是核心业务目录,关键文件如下:
- models.py
- 用户、角色、新闻、评论及统计模型
- views.py
- 认证、新闻管理、评论、分析接口
- serializers.py
- DTO 校验定义
- netease_importer.py
- 网易抓取导入与评论抓取核心逻辑
- management/commands/crawl_netease_news.py
- 批量抓取新闻命令
- management/commands/backfill_netease_comments.py
- 评论回填命令
4.2 前端目录
simple-admin-ts-master/src/views 为主要页面目录,关键页面如下:
- overview.vue
- 首页总览
- index.vue
- 新闻检索与管理
- detail.vue
- 新闻详情与评论展示
- echarts5.vue
- 评论情感舆情分析
- bigScreen.vue
- 可视化大屏
- system/user/index.vue
- 用户管理
- system/role/index.vue
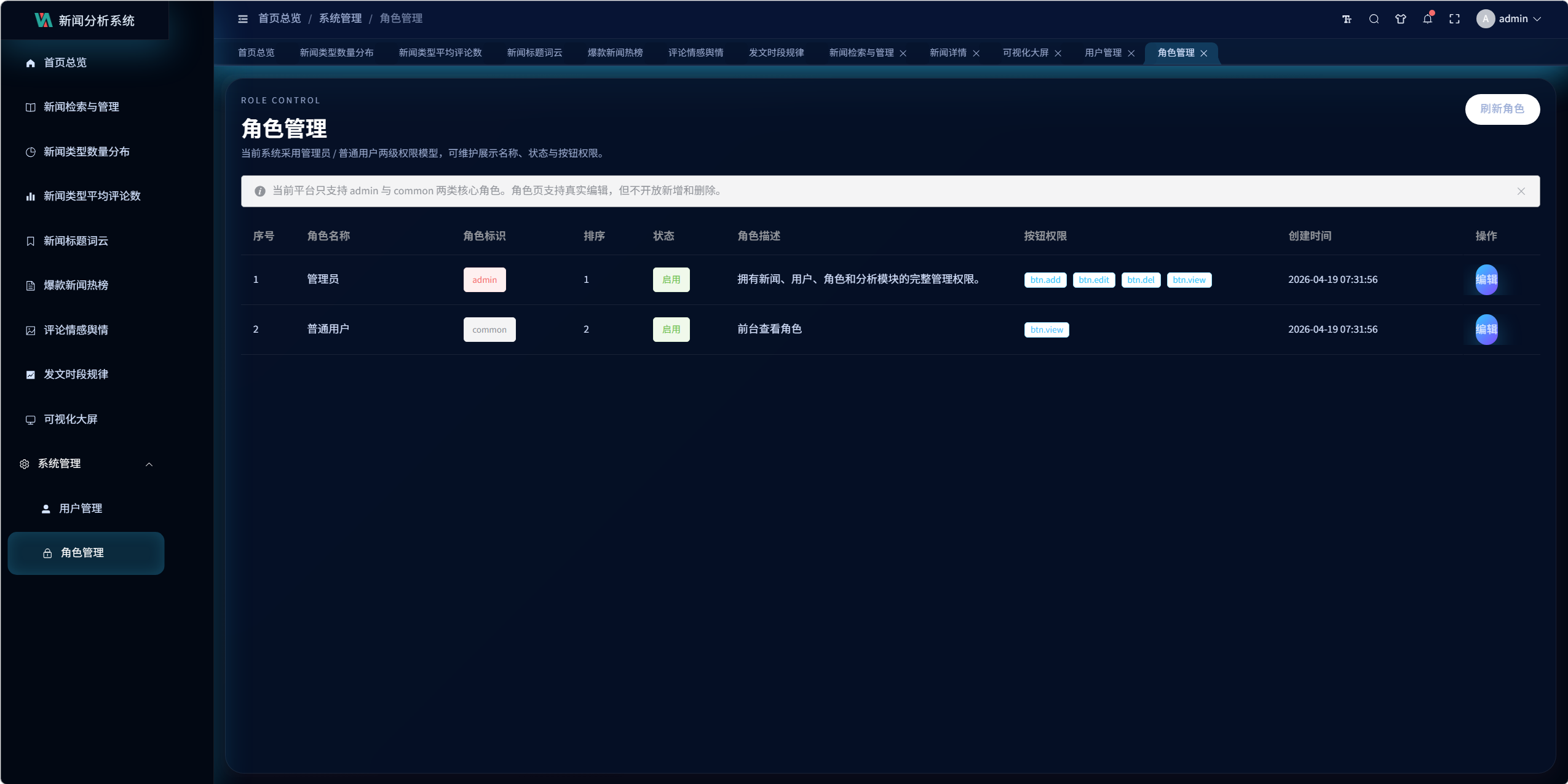
- 角色管理
5. 后端核心设计
5.1 认证与权限设计
5.1.1 认证方式
项目当前采用 Django signing 机制签发轻量认证令牌,而不是引入完整 JWT。
设计原因:
- 项目规模适中
- 认证需求集中在前后端分离管理端
- 令牌中只需要保存用户基础身份信息
- 依赖更少,便于毕业设计环境部署
5.1.2 认证流程
- 用户访问登录接口
/login/ - 后端校验用户名和密码
- 使用
signing.dumps生成 token - 前端将 token 写入会话存储
- 后续请求通过
Authorization: Bearer <token>鉴权
5.1.3 角色模型
当前系统只支持两级角色:
-
admin- 管理员
- 拥有新闻增删改查、用户管理、角色管理、分析模块访问权限
-
common- 普通用户
- 拥有新闻查看、检索和分析看板访问权限
该设计是一个刻意收敛的权限模型,目的是让路由权限、按钮权限和角色配置保持一致,避免毕业设计项目中出现过度复杂但无法维护的 RBAC 体系。
5.1.4 内置演示账号
系统启动登录时会自动确保以下内置用户存在:
admin / 123456string111 / string111
这样可以避免演示环境中因误删账号导致整个系统无法登录。
5.2 API 组织设计
后端接口全部集中在 urls.py 中注册,分为以下几类:
5.2.1 用户与角色接口
/register//login//current_user//system/users/list//system/users/create//system/users/update//system/users/delete/<id>//system/roles/list//system/roles/update/
5.2.2 新闻管理接口
/news/list//news/add//news/update//news/<news_id>//news/<news_id>/comments//news/delete/<news_id>/
5.2.3 可视化分析接口
/visualization/news-type/count//visualization/news-type/avg-comments//visualization/content/title-word-cloud//visualization/images/cover-ratio//visualization/images/comment-impact//visualization/top-news//visualization/content-length//visualization/hot-news/dashboard//visualization/comments/sentiment//visualization/publish-time/analysis//visualization/overview/dashboard//visualization/big-screen/dashboard/
5.3 视图层设计思想
后端接口采用"函数式视图 + 统一辅助函数"的方式组织。
核心思路包括:
-
_require_authenticated_user- 统一认证校验
-
_require_admin_user- 统一管理员权限校验
-
_serialize_news- 统一新闻序列化
-
_serialize_comment- 统一评论序列化
-
_safe_int- 统一安全整型转换
-
_parse_datetime_string- 统一时间解析
这种做法相比完全类视图的优势是:
- 对于毕业设计和中型后台项目更直接
- 调试成本低
- 新接口开发速度快
- 易于在同一个文件中集中维护分析函数
6. 数据模型设计
6.1 用户表 users
模型位置:
核心字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| username | CharField | 用户名 |
| password | CharField | 密码 |
| EmailField | 邮箱 | |
| phone | CharField | 手机号 |
| info | TextField | 个人简介 |
| face | CharField | 头像地址 |
| role_sign | CharField | 角色标识 |
| addtime | DateTimeField | 注册时间 |
设计特点:
- 用户模型保持轻量
- 与角色不做复杂多对多绑定,而是直接通过
role_sign关联角色配置 - 更适合当前两级角色系统
6.2 角色表 role_profile
核心字段:
| 字段 | 类型 | 说明 |
|---|---|---|
| role_name | CharField | 角色名称 |
| role_sign | CharField | 角色标识 |
| description | TextField | 描述 |
| sort | IntegerField | 排序 |
| status | BooleanField | 启停状态 |
| auth_buttons | TextField | 按钮权限 JSON |
| route_scopes | TextField | 路由范围 JSON |
| create_time | DateTimeField | 创建时间 |
| update_time | DateTimeField | 更新时间 |
设计原因:
- 角色数量少,JSON 文本化按钮权限足够用
- 不引入复杂权限表,降低维护成本
- 前后端都可直接消费角色配置
6.3 新闻表 news_info
这是系统最核心的数据表。
核心字段如下:
| 字段 | 说明 |
|---|---|
| news_title | 新闻标题 |
| news_summary | 新闻摘要 |
| news_image | 主封面图 |
| news_text | 正文全文 |
| news_commentCount | 评论总数 |
| news_type | 新闻类型 |
| news_platform | 来源平台 |
| news_url | 原文链接 |
| news_external_id | 网易文章 ID |
| news_source | 来源 |
| news_source_url | 来源链接 |
| news_author | 作者/责任编辑 |
| news_location | 新闻归属地 |
| news_publish_time | 真实发布时间 |
| news_word_count | 正文字数 |
| news_image_count | 图片数量 |
| news_comment_detail_count | 已抓评论数 |
| news_hot_comment_count | 热门评论数 |
| news_latest_comment_count | 最新评论数 |
| news_content_blocks | 结构化正文块 |
| news_images | 图片列表 |
| news_keywords | 关键词列表 |
| news_raw_payload | 原始抓取 payload |
| crawl_time | 抓取时间 |
关键设计 1:保留结构化正文块
news_content_blocks 不是简单字符串,而是 JSON 列表,用于保留段落、图片等正文结构。
设计价值:
- 新闻详情页可以按原始内容顺序渲染
- 便于后续做正文内容分析
- 比仅存
news_text更适合富文本展示
关键设计 2:区分真实发布时间与抓取时间
news_publish_time表示新闻原始发布时间crawl_time表示系统抓取时间
这样可以避免早期项目中"把抓取时间误当发布时间"的问题。
关键设计 3:保留原始 payload
news_raw_payload 用于保存原始爬虫解析结果,作用包括:
- 方便问题排查
- 便于后续新增字段时回溯原始数据
- 避免首次入库时信息丢失
6.4 评论表 news_comment
该表负责承载评论详情。
核心字段:
| 字段 | 说明 |
|---|---|
| news_id | 所属新闻 |
| comment_platform | 评论平台 |
| comment_external_id | 评论外部 ID |
| comment_doc_id | 新闻外部 ID |
| comment_parent_external_id | 父评论 ID |
| comment_root_external_id | 根评论 ID |
| comment_chain | 评论链 |
| comment_level | 评论层级 |
| comment_content | 评论正文 |
| comment_create_time | 评论时间 |
| comment_vote_count | 点赞数 |
| comment_against_count | 反对数 |
| comment_reply_count | 回复数 |
| comment_share_count | 分享数 |
| comment_user_id | 用户 ID |
| comment_user_nickname | 用户昵称 |
| comment_user_avatar | 用户头像 |
| comment_user_location | 用户地区 |
| comment_user_title | 用户头衔 |
| comment_source | 评论来源 |
| comment_is_hot | 是否热门 |
| comment_is_latest | 是否最新 |
| comment_hot_rank | 热门排序 |
| comment_latest_rank | 最新排序 |
| comment_raw_payload | 原始 payload |
| crawl_time | 抓取时间 |
关键设计 4:评论去重
评论表通过:
unique_together = ('comment_platform', 'comment_external_id')
来控制去重。
这样可以支持:
- 同一评论多次回填不会重复插入
- 评论补抓时可以做更新而不是重复写入
7. 爬虫与数据导入设计
7.1 设计目标
本项目没有直接重写一个新的网易爬虫,而是采用:
- 保留原始
NewsCrawler的解析能力 - 在 Django 中增加
netease_importer.py - 由 Django 管理命令统一调用
这样实现了"原始爬虫能力复用 + 后端统一入库"的设计。
7.2 导入器设计
核心文件:
- netease_importer.py
该文件负责:
- 构建 requests session
- 提取种子页新闻 URL
- 从网易文章页抽取正文与元信息
- 标准化 URL 与 doc_id
- 扩展已有文章相关推荐
- 抓取评论详情
- 写入或更新
NewsInfo/NewsComment
7.3 种子页设计
系统内置多个网易频道页作为种子来源:
https://www.163.com/https://news.163.com/https://sports.163.com/https://money.163.com/https://tech.163.com/https://war.163.com/- 以及其他频道
设计原因:
- 提高新闻覆盖面
- 避免只从单频道抓取导致类型偏斜
- 适合生成更丰富的新闻分析结果
7.4 新闻抓取命令
命令文件:
- crawl_netease_news.py
主要参数:
| 参数 | 说明 |
|---|---|
| --max-articles | 最大抓取新闻数 |
| --depth | 相关推荐扩展深度 |
| --sleep | 请求间隔 |
| --seed-url | 自定义种子页 |
| --article-url | 指定文章链接 |
| --existing-seed-limit | 使用库内已有文章做二次扩展 |
| --no-update-existing | 命中旧数据时跳过更新 |
| --include-comments | 同时抓评论 |
| --new-comment-pages | 最新评论抓取页数 |
| --hot-comment-pages | 热门评论抓取页数 |
| --comment-page-size | 评论分页大小 |
| --dry-run | 演练模式 |
| --recent-days | 只抓最近 N 天新闻 |
关键设计 5:最近 N 天抓取
新增 --recent-days 后,系统可以只保留最近几天内发布的新闻。
设计目的:
- 避免数据长期集中在某一天
- 支撑"最近 7 天"分析需求
- 更适合运营时效分析和热榜分析
7.5 评论回填命令
命令文件:
- backfill_netease_comments.py
作用:
- 针对已经入库但评论详情不足的新闻补抓评论
- 同步刷新评论总数和已抓评论数
主要参数:
| 参数 | 说明 |
|---|---|
| --news-id | 指定新闻 ID |
| --limit | 最多回填多少条新闻 |
| --sleep | 每条新闻间隔 |
| --new-comment-pages | 最新评论页数 |
| --hot-comment-pages | 热门评论页数 |
| --comment-page-size | 每页评论数 |
| --all | 扫描全部新闻 |
| --dry-run | 演练模式 |
| --recent-days | 只回填最近 N 天新闻 |
关键设计 6:评论差额优先
回填命令默认优先处理:
news_comment_detail_count < news_commentCount- 或
news_comment_detail_count = 0
即优先回填评论缺口大的新闻,提升系统整体分析价值。
7.6 实际抓取链路
抓取链路可以概括为:
text
种子页 → 提取文章 URL → 文章详情解析 → 新闻入库
↓
doc_id 提取
↓
网易评论接口抓取
↓
评论去重写入 news_comment
↓
回写 news_commentCount / news_comment_detail_count 等统计字段8. 新闻详情与评论展示设计
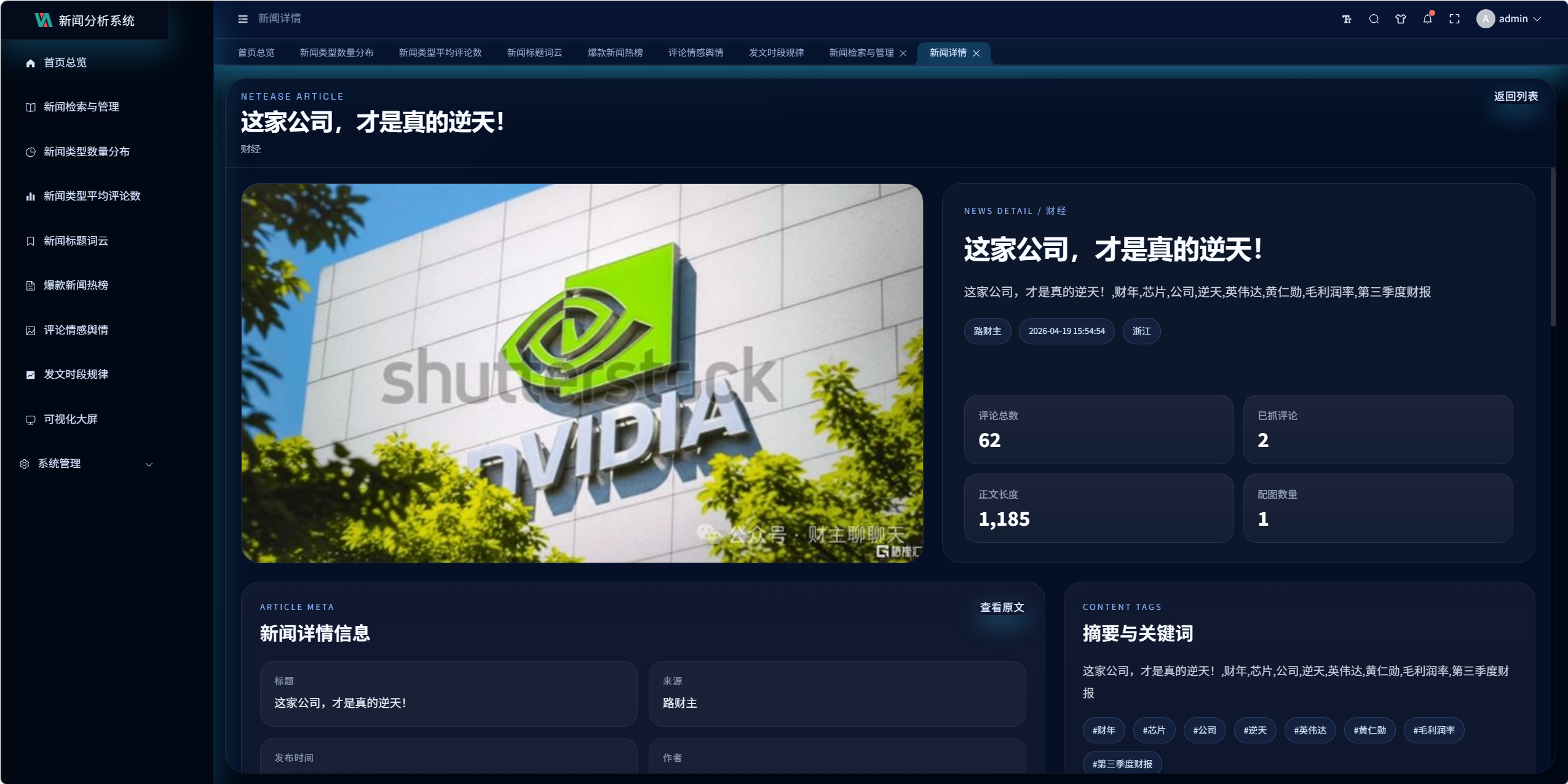
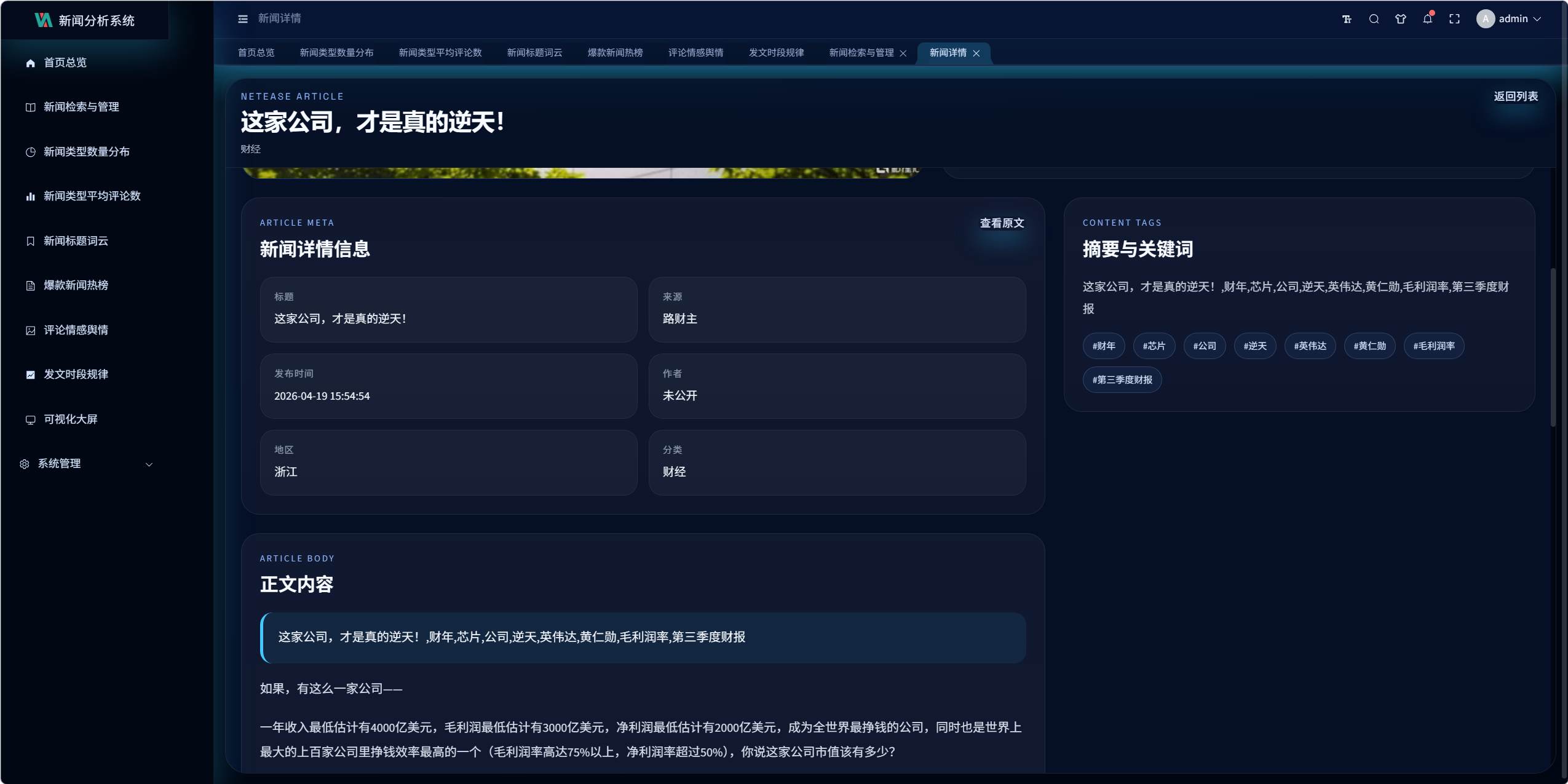
8.1 新闻详情页设计
前端文件:
- detail.vue
页面展示内容包括:
- 标题
- 封面图
- 摘要
- 发布时间
- 来源
- 作者
- 地区
- 评论总数
- 图片墙
- 关键词
- 结构化正文内容
- 评论列表与互动指标
8.2 结构化正文渲染
详情页优先使用 news_content_blocks 渲染正文。
优势:
- 可按段落顺序展示
- 可混排图片与文字
- 比单纯渲染整段文本更贴近真实新闻页
若结构化内容不可用,则回退到 news_text。
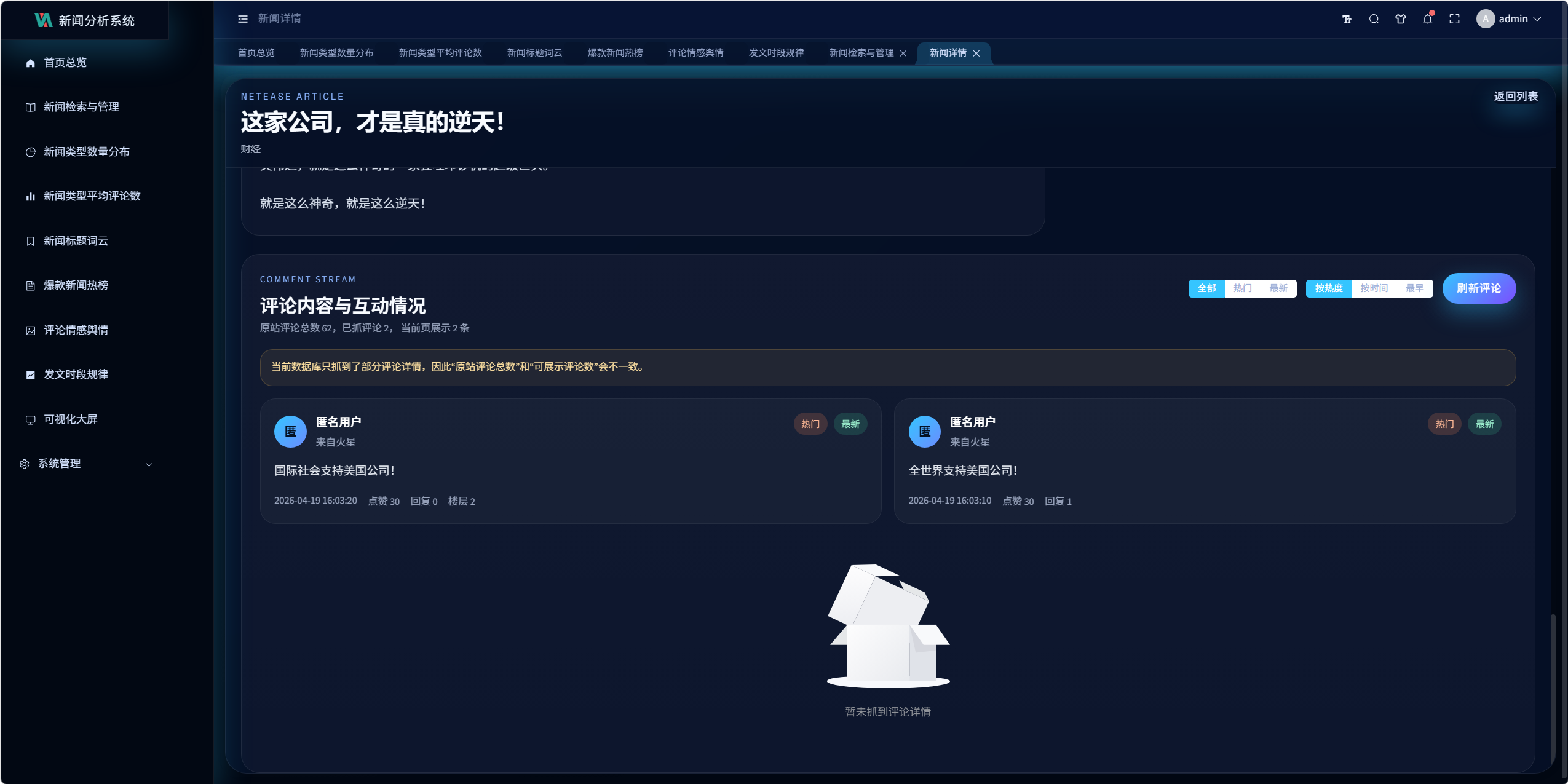
8.3 评论展示策略
详情页评论采用分页展示,当前一页显示 8 条。
页面会同时区分:
- 原站评论总数
- 当前数据库已抓评论数
- 当前页展示条数
这样可以避免用户误以为"页面没展示全"而实际是"数据库只抓到了部分评论"。
9. 前端管理端设计
9.1 前端路由设计
前端路由集中定义在:
- route.ts
主要页面包括:
| 路由 | 页面 | 角色 |
|---|---|---|
/home |
首页总览 | admin/common |
/news/manage |
新闻检索与管理 | admin/common |
/news/detail |
新闻详情 | admin/common |
/echart1 |
新闻类型数量分布 | admin/common |
/echart2 |
新闻类型平均评论数 | admin/common |
/echart3 |
新闻标题词云 | admin/common |
/echart4 |
爆款新闻热榜 | admin/common |
/echart5 |
评论情感舆情 | admin/common |
/echart6 |
发文时段规律 | admin/common |
/big-screen |
可视化大屏 | admin/common |
/system/user |
用户管理 | admin |
/system/role |
角色管理 | admin |
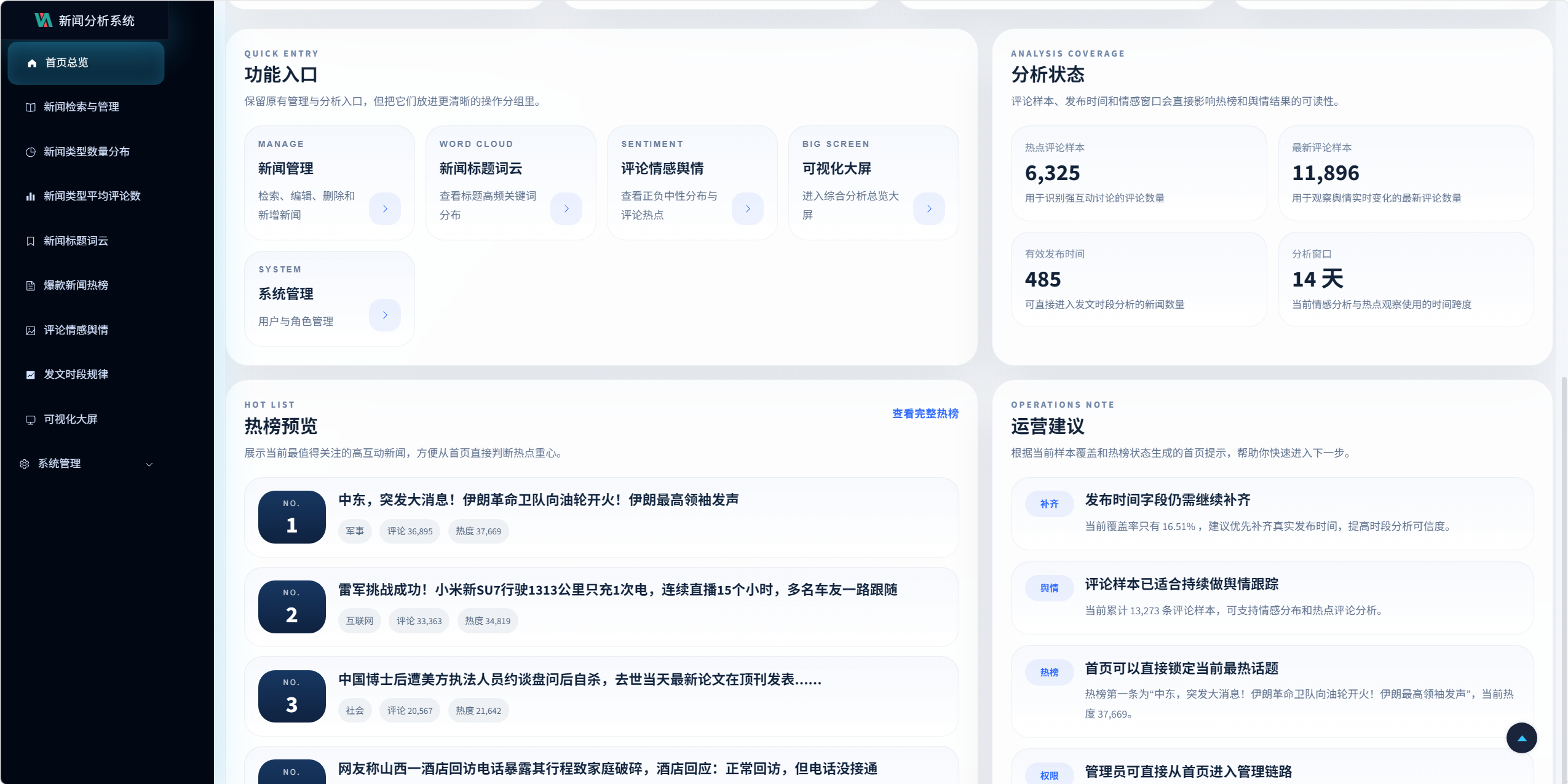
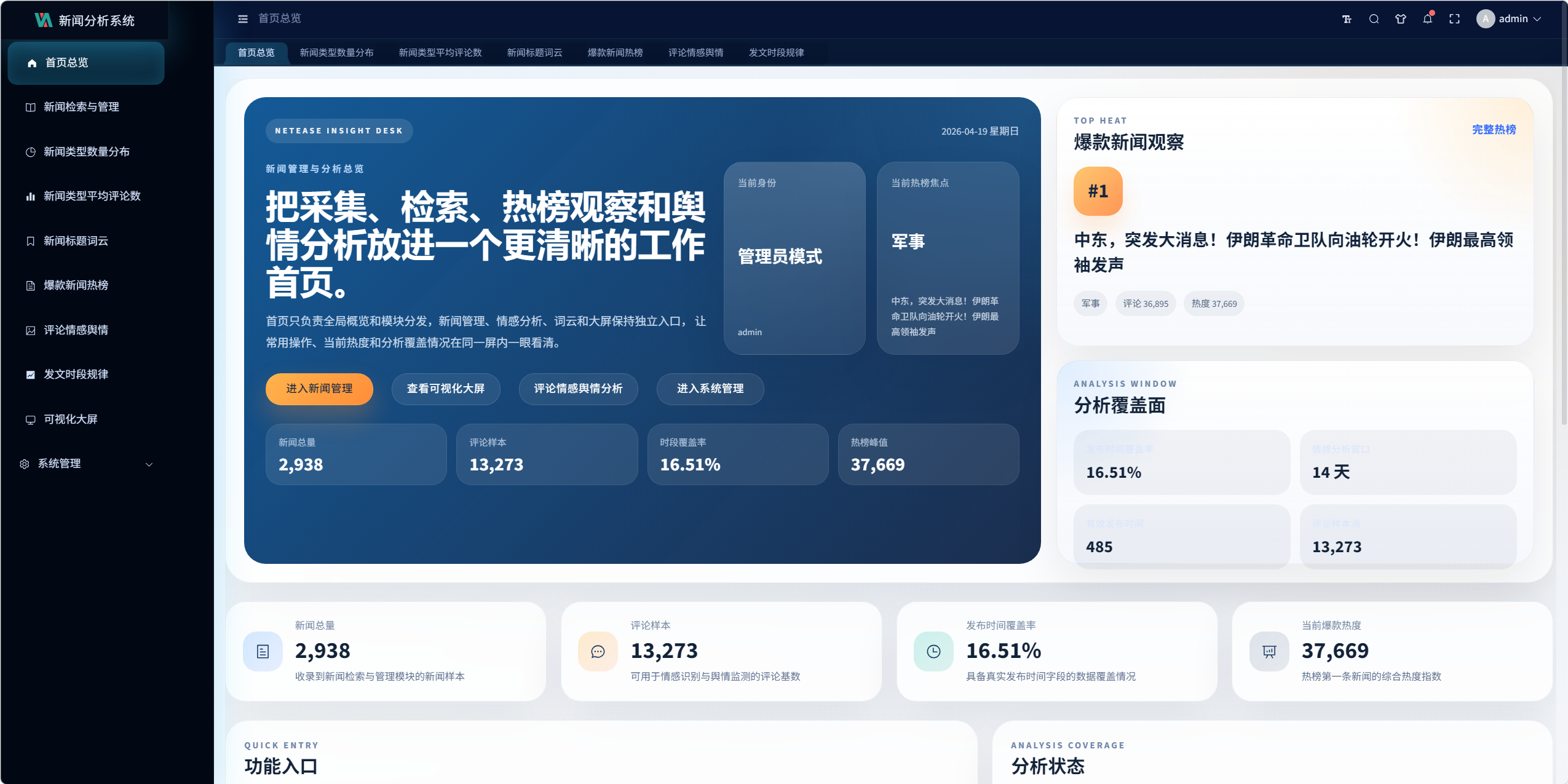
9.2 首页总览设计
首页文件:
- overview.vue
设计目标:
- 首页只展示全局概况,不承担重操作
- 把管理、分析和大屏入口统一汇总
- 提供热榜焦点、数据覆盖率和运营建议
页面模块包括:
- 顶部主视觉区
- 当前身份显示
- 热榜焦点
- 指标卡
- 快捷入口
- 分析覆盖状态
- 热榜预览
- 运营建议
关键设计 7:首页轻量接口
首页不再直接并发调多个重型分析接口,而是走:
/visualization/overview/dashboard/
聚合轻量数据,避免首页被情感分析等重计算接口拖慢。
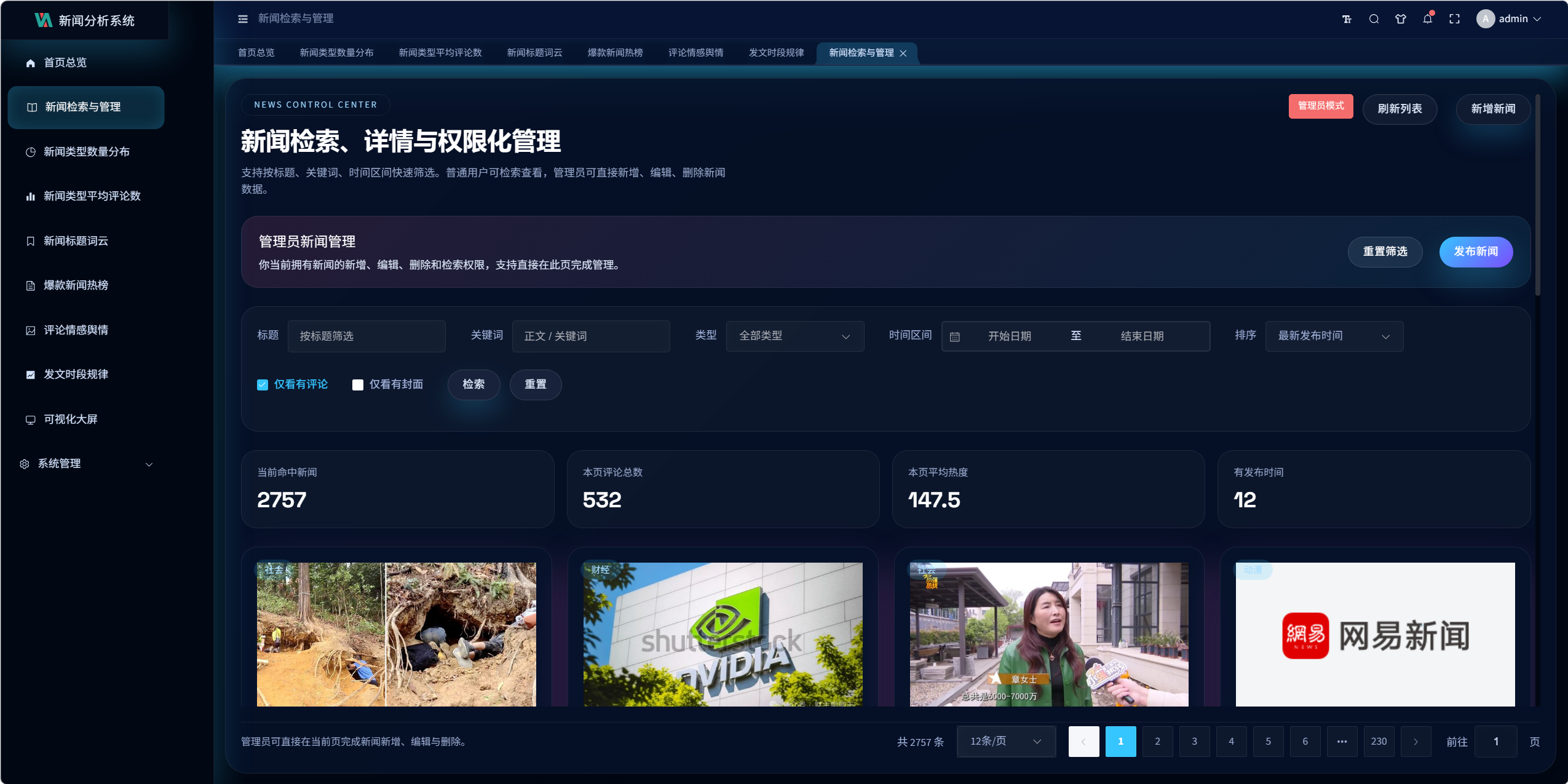
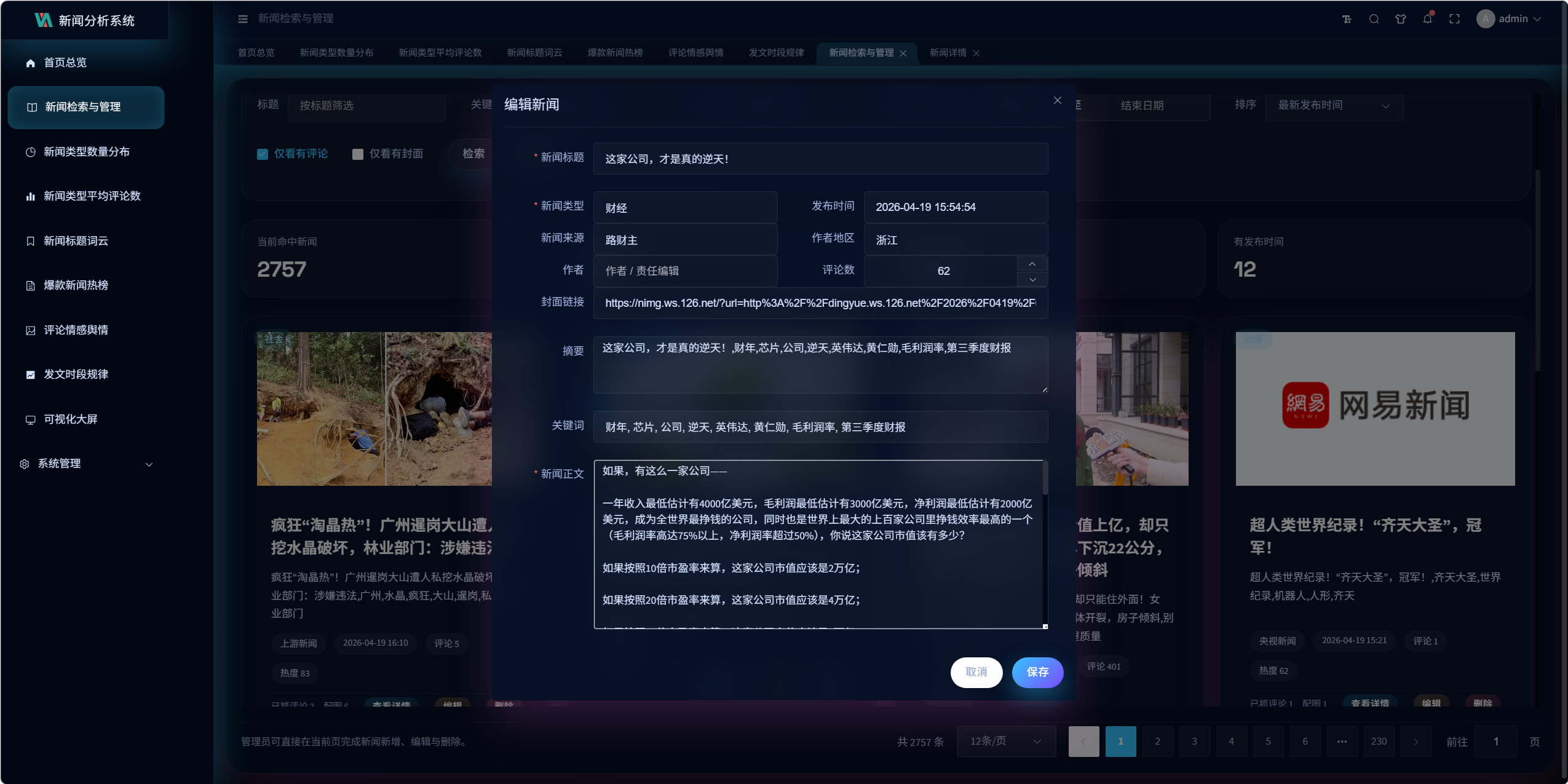
9.3 新闻检索与管理设计
页面支持:
- 标题搜索
- 关键词搜索
- 时间区间筛选
- 类型筛选
- 按发布时间 / 评论数 / 热度排序
管理员额外支持:
- 新增新闻
- 编辑新闻
- 删除新闻
普通用户仅保留查看和分析入口。
9.4 用户与角色管理设计
用户管理
管理员可以:
- 查看用户列表
- 创建用户
- 修改用户基础信息和角色
- 删除非内置用户
角色管理
当前只维护两种核心角色:
admincommon
角色管理支持:
- 编辑显示名称
- 编辑状态
- 编辑按钮权限
- 编辑描述
不支持新增第三类角色,这是与前端路由体系保持一致的设计取舍。
10. 可视化分析设计
10.1 分析模块概览
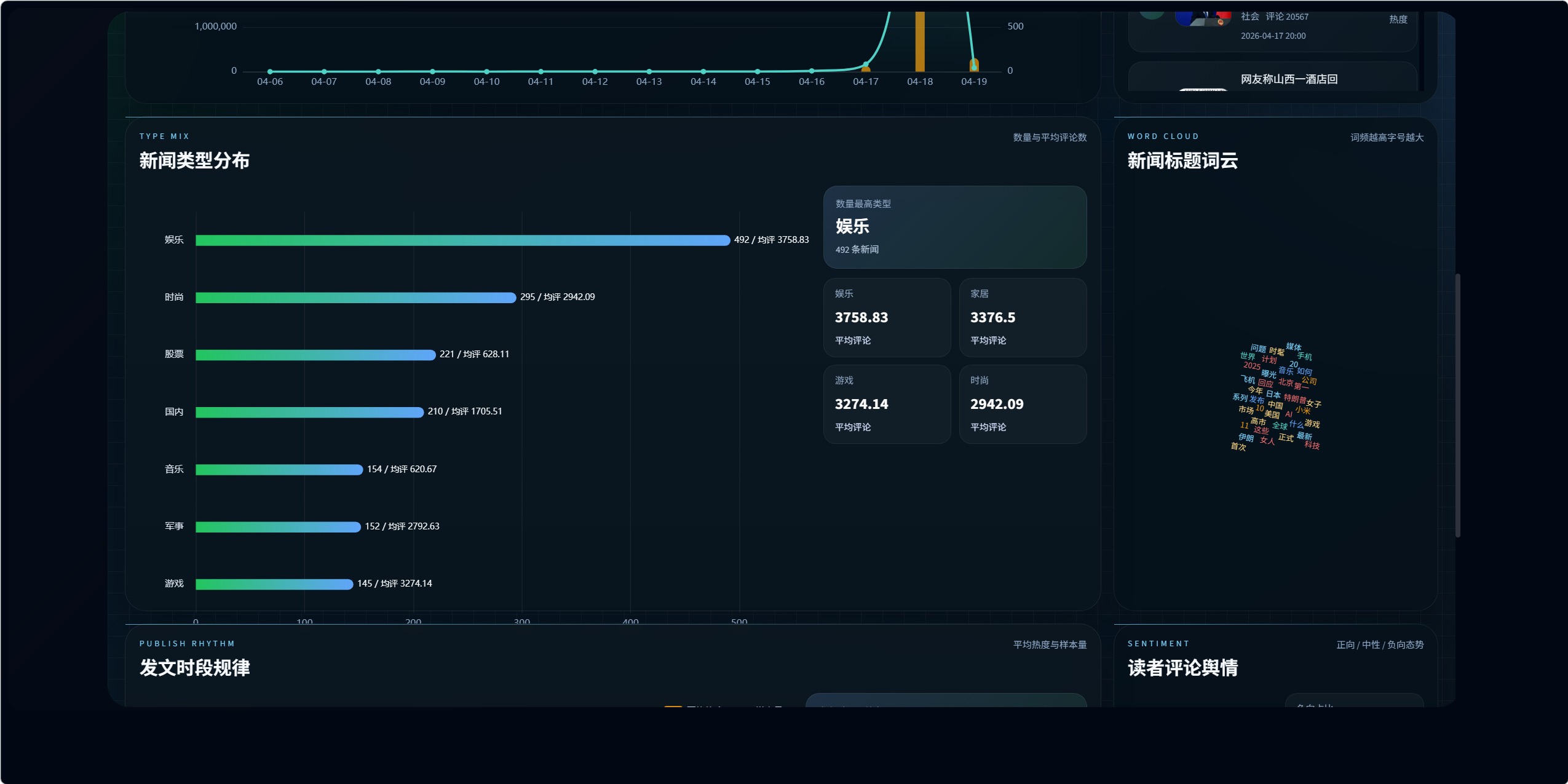
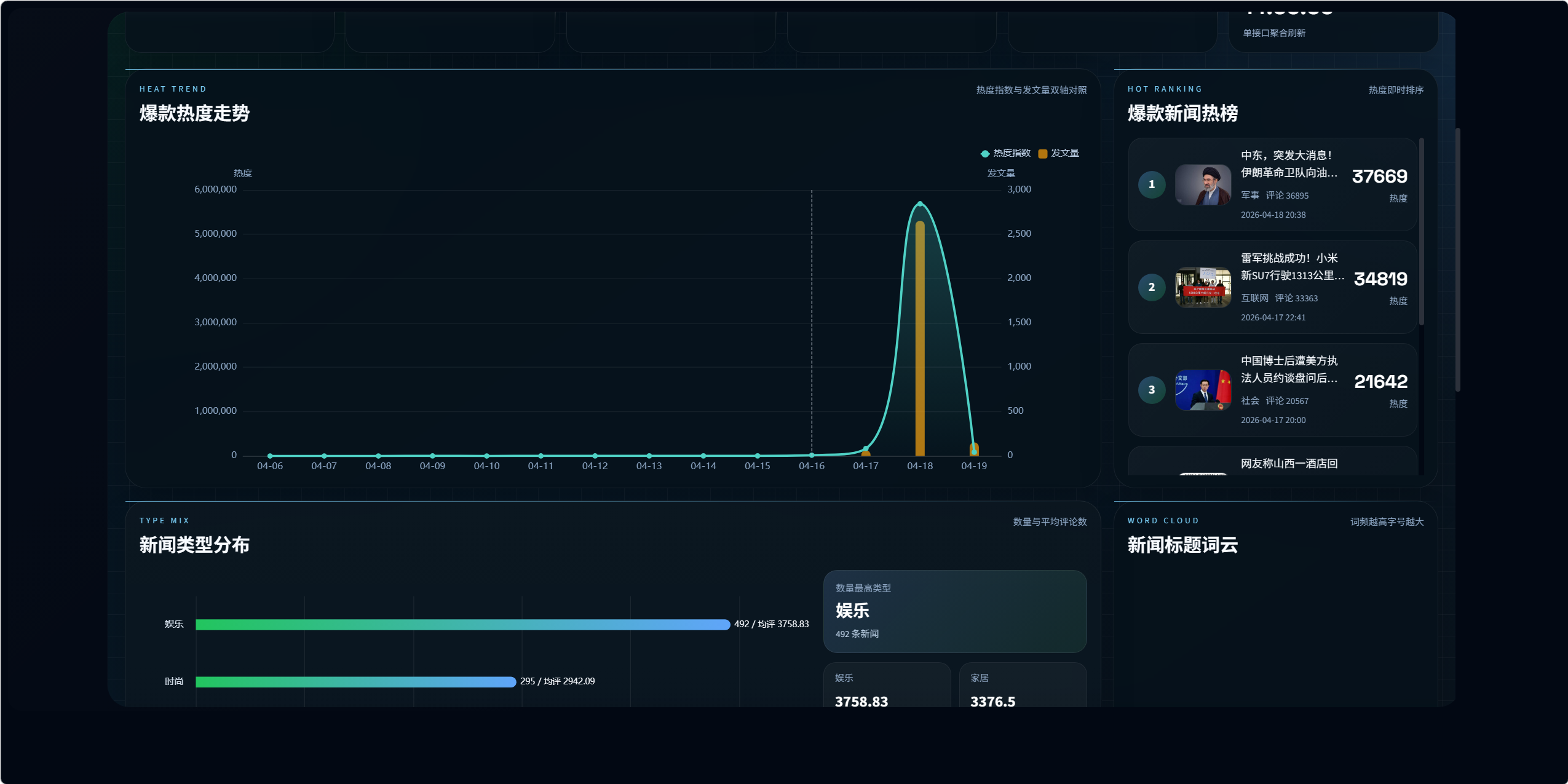
当前系统已实现以下分析模块:
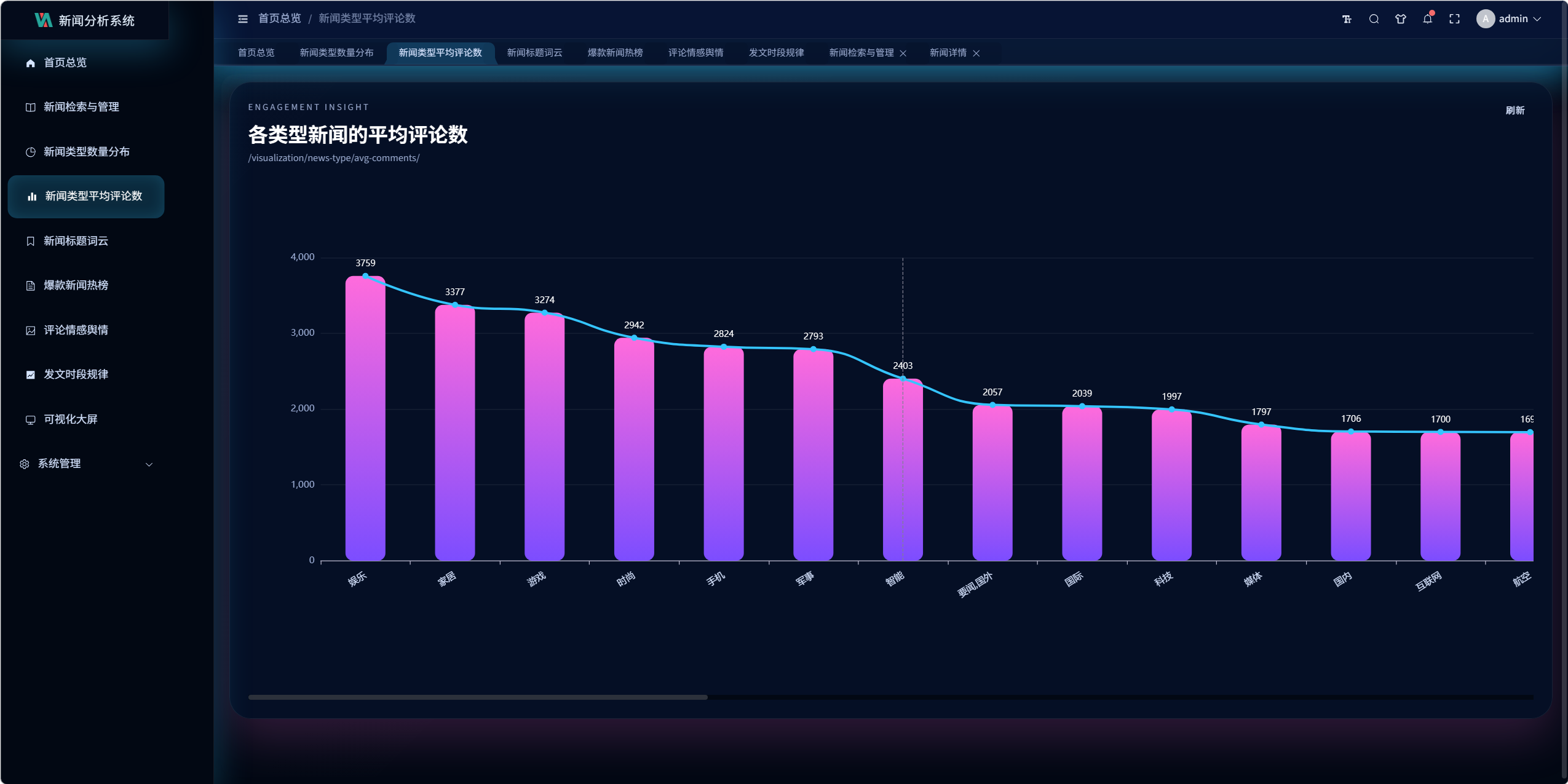
- 新闻类型数量分布
- 各类型新闻平均评论数
- 新闻标题词云
- 爆款新闻热榜与热度走势
- 读者评论情感舆情分析
- 新闻发布时段规律分析
- 可视化大屏聚合展示
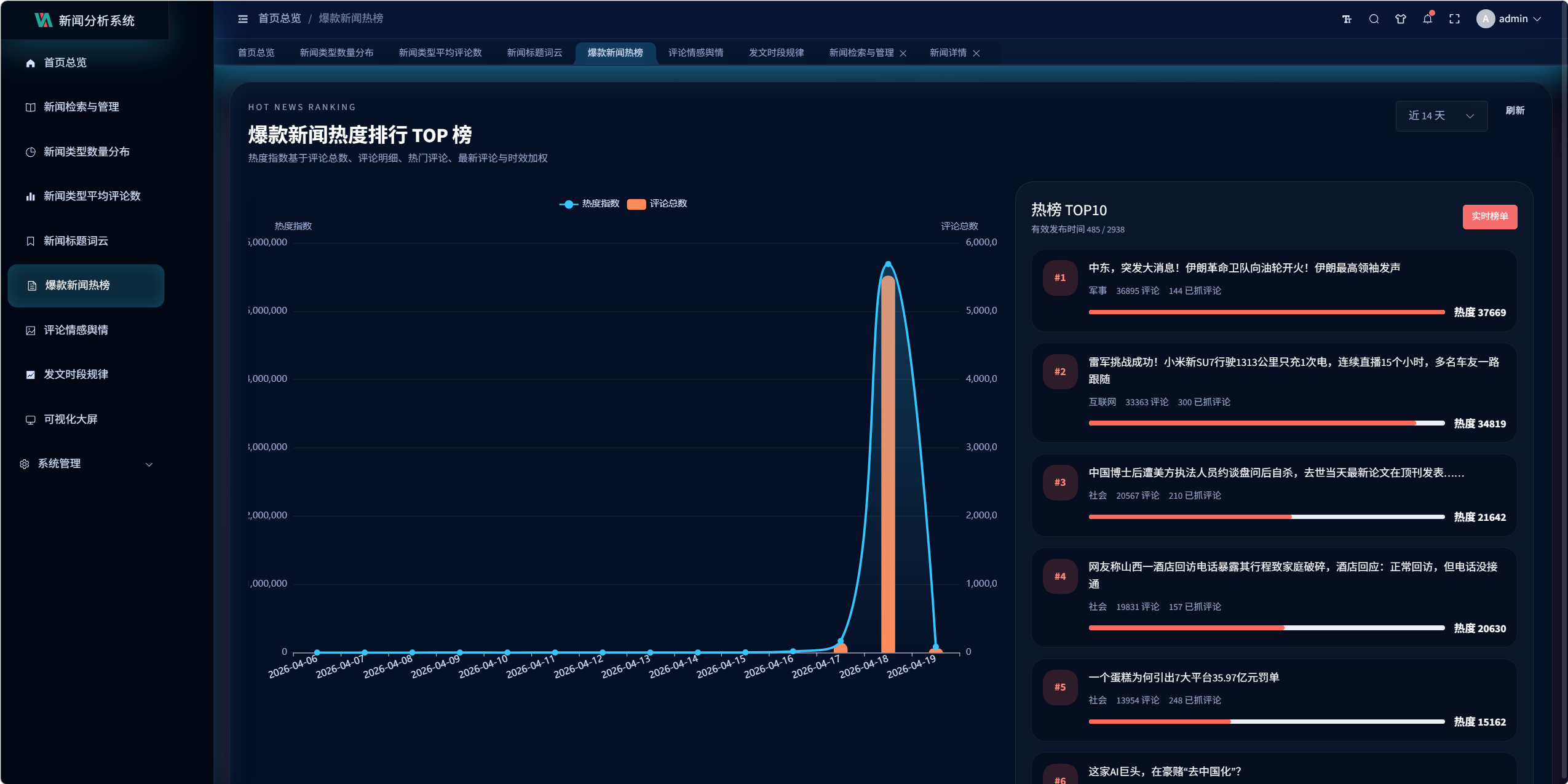
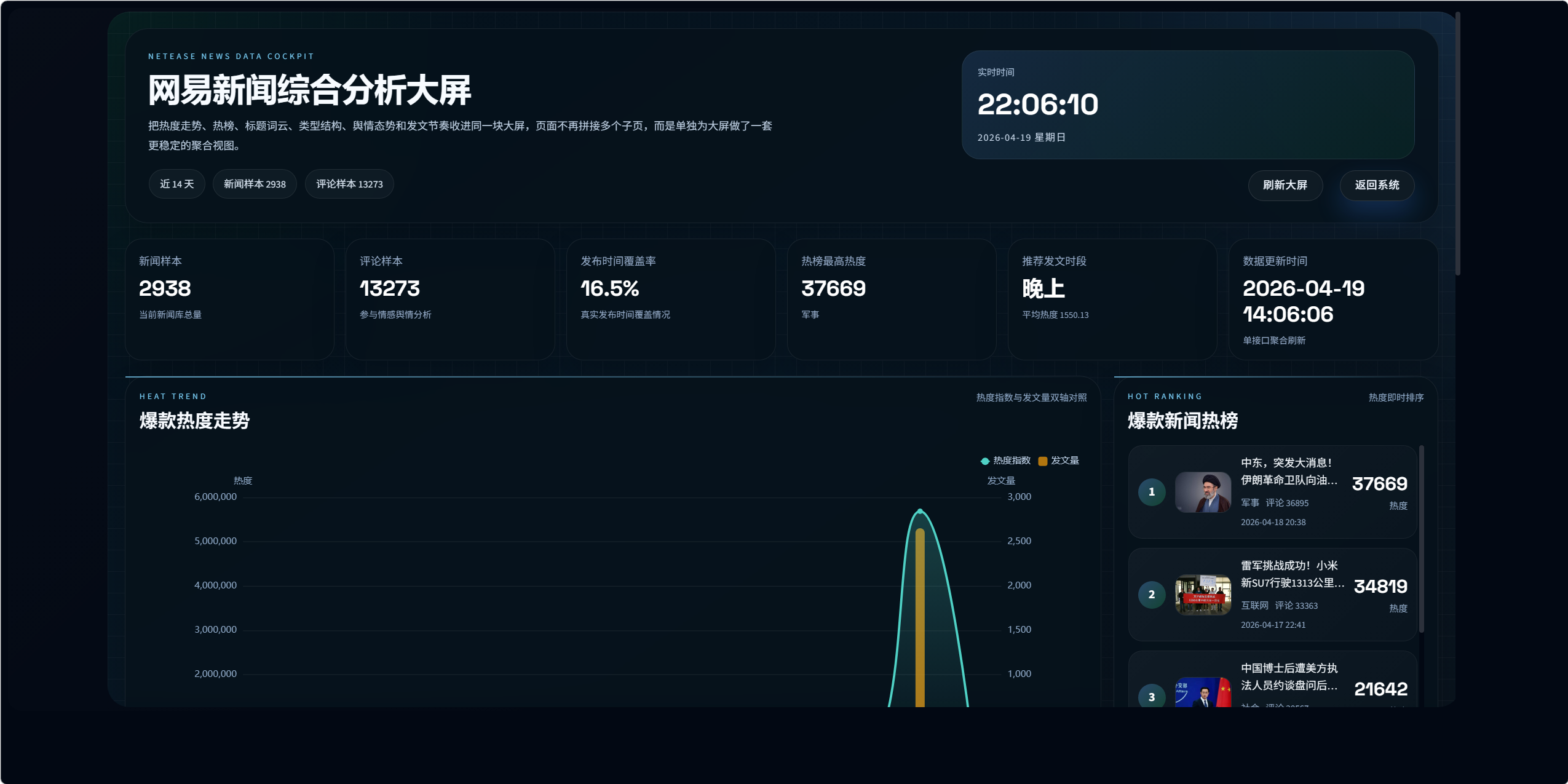
10.2 爆款热榜设计
接口:
/visualization/hot-news/dashboard/
该模块没有使用真实阅读数,因为网易公开页面没有稳定可用的阅读字段。
当前热度公式为:
text
评论总数
+ 评论详情数量 * 2.4
+ 热门评论数量 * 3.0
+ 最新评论数量 * 1.8
+ 配图数量 * 0.6
+ 时效加权关键设计 8:热度替代公式
由于真实阅读量不可稳定获取,系统使用可解释的互动热度公式替代"虚假的阅读数"。
这比直接伪造阅读数更可靠,也更适合论文和答辩中说明设计合理性。
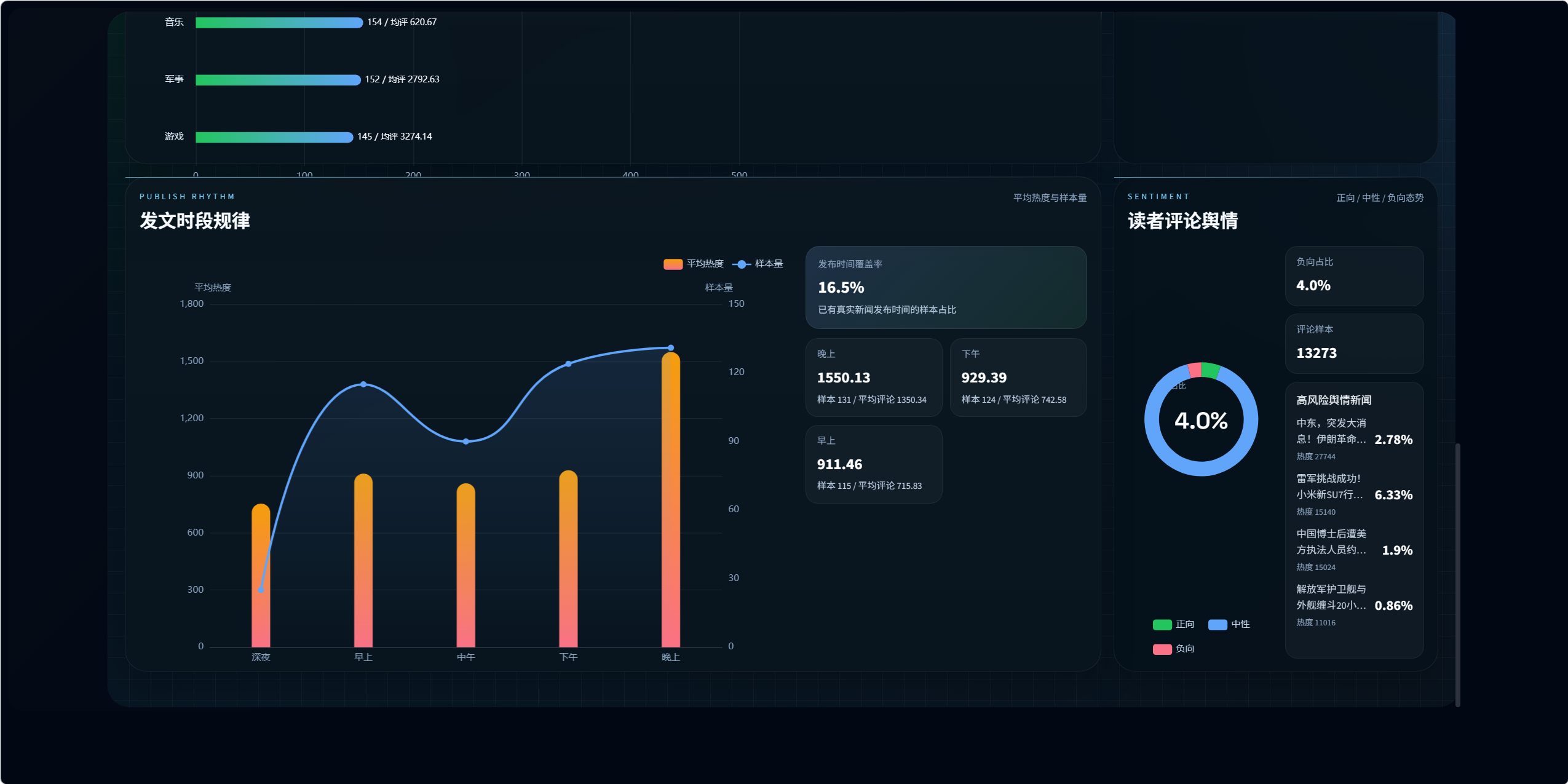
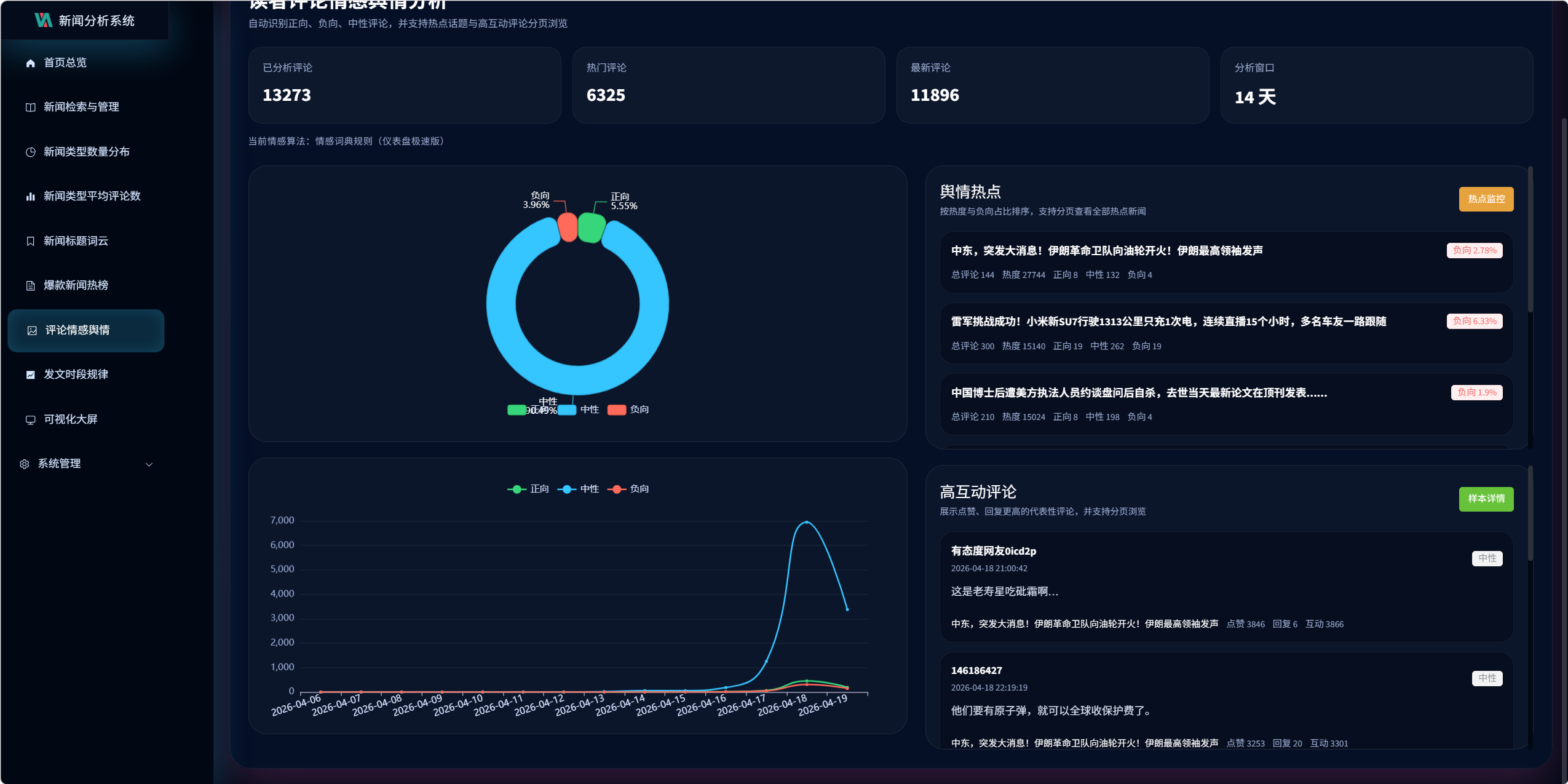
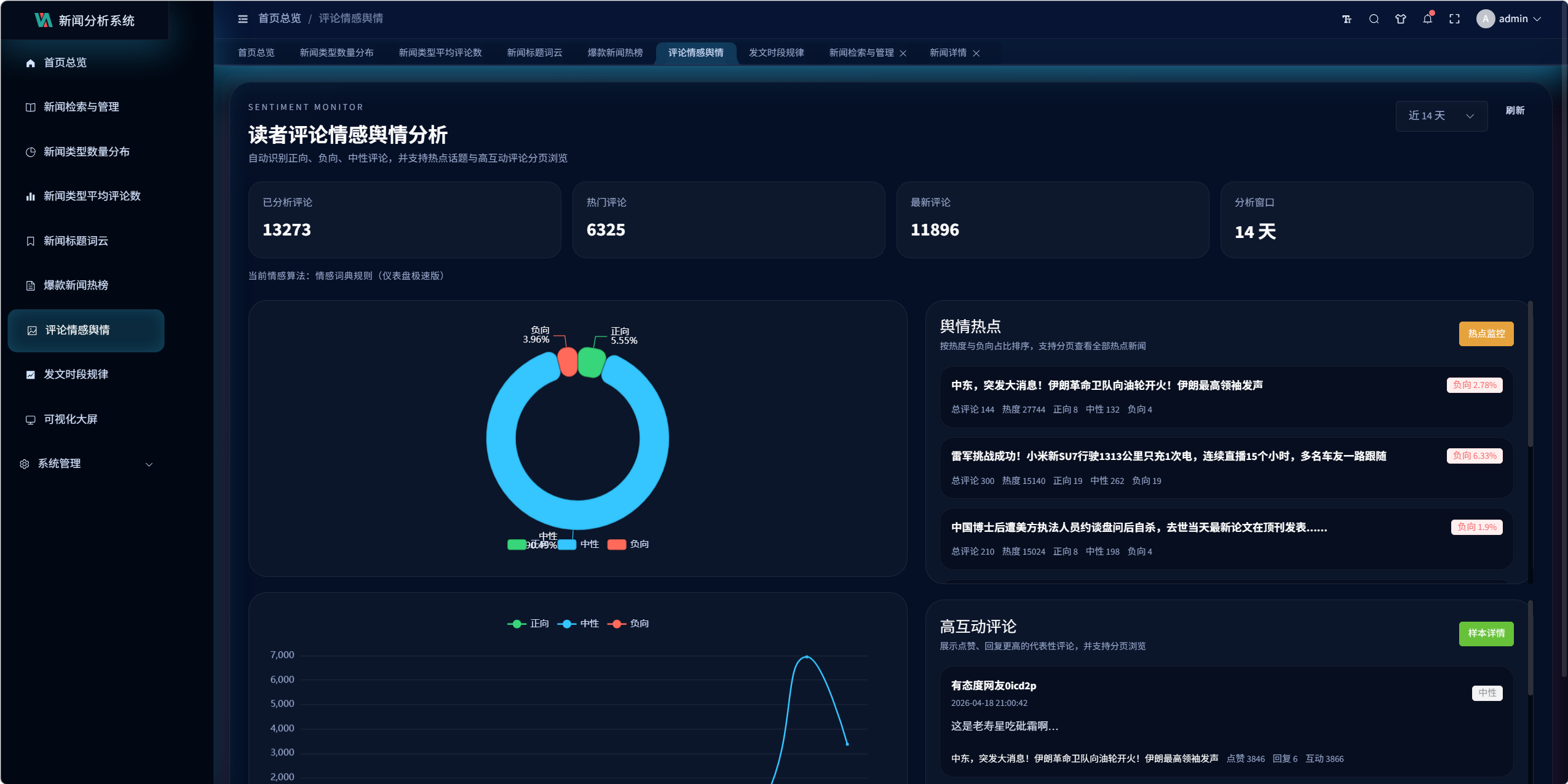
10.3 评论情感舆情分析设计
接口:
/visualization/comments/sentiment/
页面:
- echarts5.vue
该模块展示:
- 正向 / 中性 / 负向分布
- 情感趋势
- 舆情热点新闻
- 高互动评论样本
- 分页浏览
关键设计 9:仪表盘极速版情感分析
当前后端在仪表盘场景下采用:
情感词典规则(仪表盘极速版)
原因是对一万多条评论逐条运行更重的模型分析会导致首屏超时。
当前设计分为两层:
-
仪表盘场景
- 采用规则版
- 响应更快
- 保障页面稳定
-
高精度分析能力
- 后端保留
SnowNLP + 词典校正的混合分析逻辑 - 适合后续扩展为离线批处理或更高精度分析模式
- 后端保留
当前情感算法说明
系统已实现的情感分析要素包括:
- jieba 分词
- 正负向词典
- 否定词修正
- 程度副词修正
- 中性提示词修正
- 反讽提示词修正
- SnowNLP 混合能力
但在舆情大盘接口中,为保证速度和稳定性,当前返回的是更轻量的规则版结果。
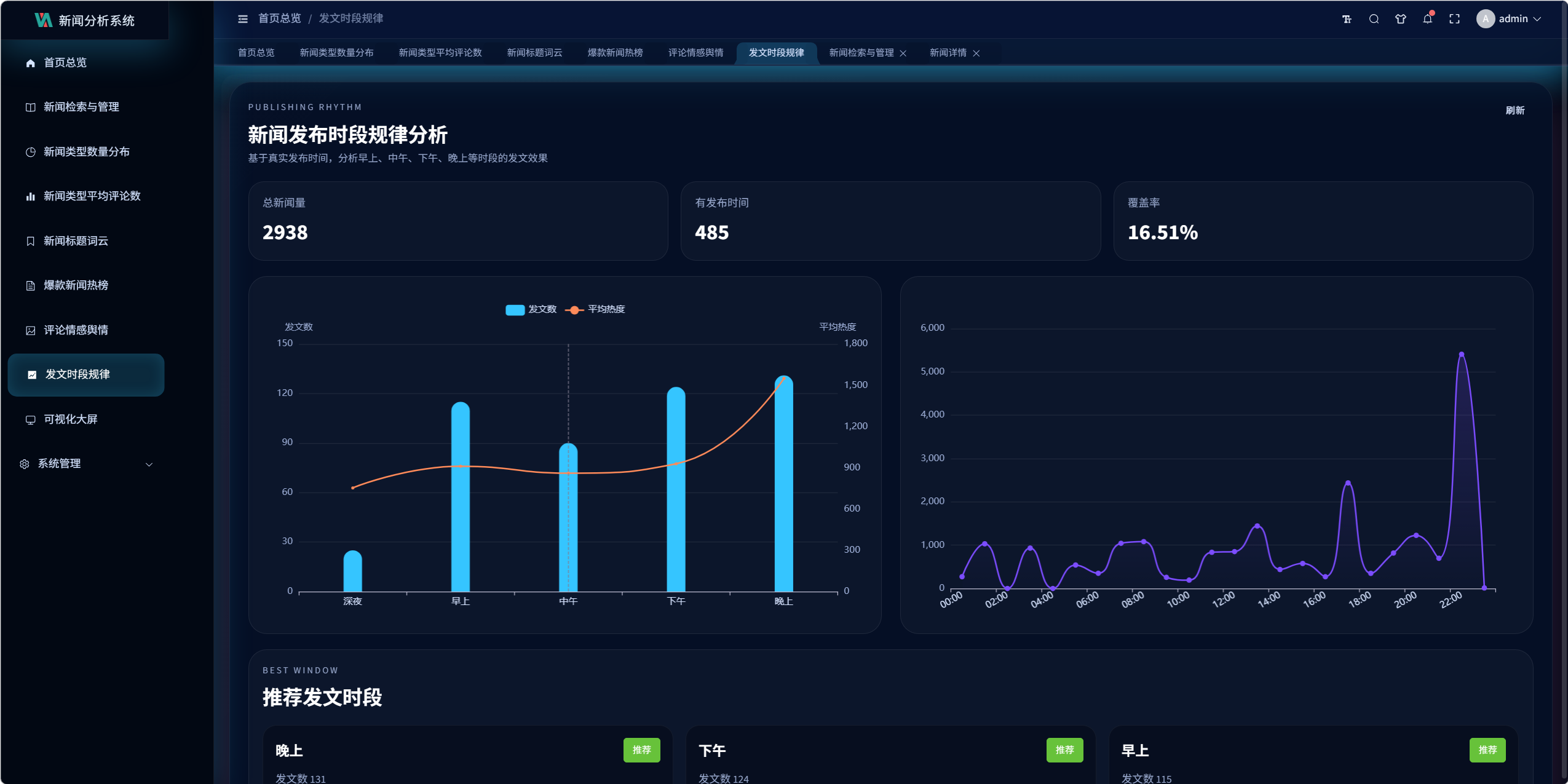
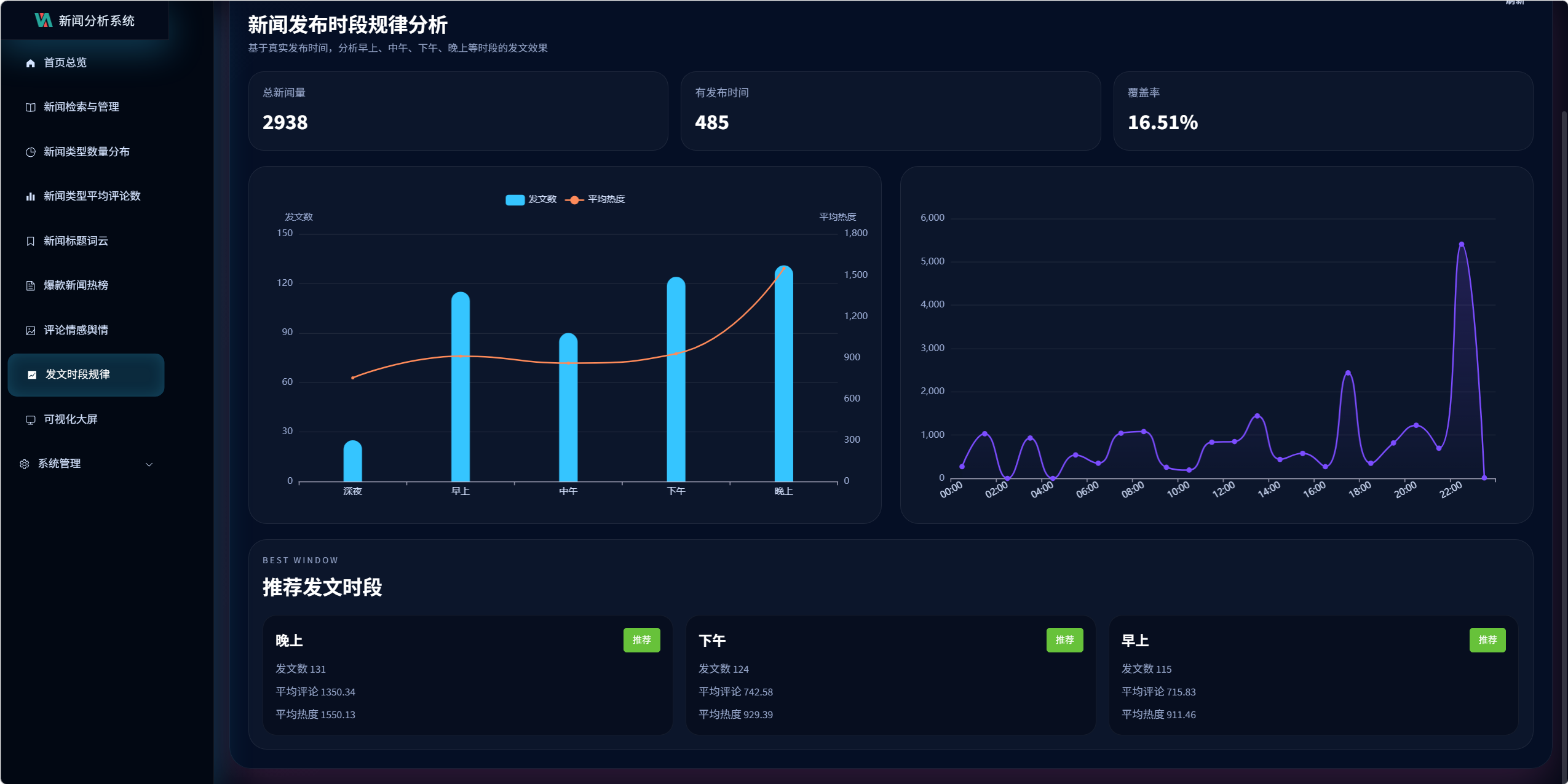
10.4 发文时段规律分析设计
接口:
/visualization/publish-time/analysis/
时段划分:
- 深夜:0-6
- 早上:6-10
- 中午:10-14
- 下午:14-18
- 晚上:18-24
输出内容:
- 各时段新闻数量
- 各时段平均评论数
- 各时段平均热度
- 小时级数据分布
- 发布时间覆盖率
该模块的前提是 news_publish_time 必须尽量完整,因此发布时间字段的抓取质量会直接影响时段分析效果。
10.5 可视化大屏设计
页面:
- bigScreen.vue
接口:
/visualization/big-screen/dashboard/
大屏采用聚合接口单次返回:
- 类型分布
- 平均评论数
- 词云
- 热榜
- 舆情
- 发文规律
关键设计 10:大屏聚合接口
大屏最开始如果逐个调用多个分析接口,会出现:
- 请求数量多
- 任一接口失败会拖垮整屏
- 页面加载不稳定
因此改为单聚合接口,提升了稳定性与前端实现一致性。
11. 首页与大屏 UI 设计思路
11.1 首页设计原则
- 不把首页做成"杂乱的功能堆叠页"
- 首页负责总览与导航,不承载全部分析图表
- 强化当前身份、热榜焦点和覆盖率信息
- 让用户进入系统后快速知道下一步去哪里
11.2 大屏设计原则
- 大屏不是简单嵌套普通页面
- 每个图表有独立卡片区域
- 通过固定网格控制视觉秩序
- 提供时间显示、标题和返回系统按钮
- 限制图表高度,避免溢出与裁切
12. 关键性能与稳定性设计
12.1 首页接口轻量化
首页通过独立总览接口避免调用重型分析接口。
12.2 舆情接口缓存
舆情分析模块已加入缓存策略,翻页时不重复全量计算。
12.3 分析接口降级保护
情感分析接口已加入异常降级逻辑,即使个别评论文本异常,也不会导致整页返回 500。
12.4 评论去重与增量回填
评论表通过外部 ID 去重,支持多次回填。
12.5 真实发布时间优先
分析模块优先基于真实发布时间,而不是抓取时间,保证时段分析可信度。
13. 项目运行说明
13.1 后端启动
powershell
cd F:\code\356-基于Python的网易新闻数据分析系统\DjangoProject1
D:/software/anaconda3/envs/python38/python.exe manage.py runserver 127.0.0.1:800013.2 前端启动
powershell
cd F:\code\356-基于Python的网易新闻数据分析系统\simple-admin-ts-master
npm run dev13.3 数据抓取
抓最近 7 天网易新闻并同步评论:
powershell
cd F:\code\356-基于Python的网易新闻数据分析系统\DjangoProject1
D:/software/anaconda3/envs/python38/python.exe manage.py crawl_netease_news --recent-days 7 --max-articles 180 --depth 1 --sleep 0.05 --existing-seed-limit 180 --include-comments --new-comment-pages 3 --hot-comment-pages 2 --comment-page-size 2013.4 评论回填
powershell
cd F:\code\356-基于Python的网易新闻数据分析系统\DjangoProject1
D:/software/anaconda3/envs/python38/python.exe manage.py backfill_netease_comments --recent-days 7 --limit 300 --sleep 0.05 --new-comment-pages 5 --hot-comment-pages 3 --comment-page-size 2013.5 后端检查
powershell
D:/software/anaconda3/envs/python38/python.exe manage.py check13.6 前端构建
powershell
cd F:\code\356-基于Python的网易新闻数据分析系统\simple-admin-ts-master
npm run build14. 当前已解决的关键问题
项目演进过程中,已经针对以下问题做过修正:
- Python 3.8 下
str | None注解报错 - 首页总览因重分析接口超时导致加载失败
- 评论情感分析接口首屏过慢和 500 风险
- 管理端登录状态失效导致的 401 问题
- 普通用户账号和管理员账号演示登录问题
- 新闻详情页滚动、长图显示和评论分页问题
- 大屏多接口并发导致的稳定性问题
- 系统管理菜单图标与激活态显示问题
这些修正确保了当前系统已经具备可演示、可抓取、可管理、可分析的整体能力。
15. 当前局限与后续优化建议
15.1 已知局限
- 网易公开页面缺少稳定真实阅读数字段
- 评论接口不一定能拿到原站全部评论内容
- 情感分析极速版更偏实用,精度仍有提升空间
- 用户与角色系统当前是两级模型,不适合复杂组织权限
- 部分早期历史新闻缺真实发布时间
15.2 后续优化方向
- 增加离线高精度情感分析任务
- 新增定时抓取任务调度
- 增加新闻内容主题分类模型
- 增加关键词检索高亮和全文索引
- 引入更细粒度角色权限体系
- 将大屏扩展为自动轮播与全屏播控模式
- 对评论做主题聚类与热点事件演化分析
16. 项目总结
本项目已经从单纯的新闻信息展示系统,升级为一个围绕网易新闻数据构建的完整数据平台,具备以下完整链路能力:
- 网易新闻抓取
- 新闻详情解析
- 评论详情回填
- 富字段结构化入库
- 管理员与普通用户分级权限
- 新闻检索与管理
- 新闻详情与评论展示
- 热榜、词云、舆情、时段规律分析
- 首页总览与可视化大屏展示
从工程视角看,本项目的关键价值不只在于"能抓到新闻",更在于完成了:
- 从爬虫到数据库的稳定导入链路
- 从数据库到分析接口的结构化输出
- 从分析接口到管理前端和大屏的可视化表达
这使得项目具备了较完整的新闻数据管理与分析闭环。