在图论和算法学习中,DFS(深度优先搜索)和BFS(广度优先搜索)是两种最基础、最常用的遍历算法。
提示:可以先阅读一下两篇博客,然后再阅读本篇博客。https://blog.csdn.net/2301_79932175/article/details/159286874?spm=1001.2014.3001.5502
https://blog.csdn.net/2301_79932175/article/details/159319728?spm=1001.2014.3001.5502
一、概念
DFS(Depth-First Search,深度优先搜索):优先"往深走"。从起始节点出发,沿着一条路径一直探索到无法再深入(没有未访问的邻接节点),再回溯到上一个节点,继续探索其他未走的路径,直到遍历完所有节点。就像走迷宫时,一条路走到黑,走不通就回头换另一条路。
BFS(Breadth-First Search,广度优先搜索):优先"往宽走"。从起始节点出发,先遍历完起始节点的所有邻接节点(即"广度"),再依次遍历每个邻接节点的邻接节点,层层递进,直到遍历完所有节点。就像往水里扔一颗石头,水波从中心向四周扩散,依次覆盖所有区域。
二、核心区别
1. 核心思想差异
DFS:深度优先,回溯探索。核心是"不撞南墙不回头",优先探索一条路径的尽头,再回溯处理其他分支,强调"纵向挖掘"。
BFS:广度优先,层层递进。核心是"先扫完眼前,再往远处走",优先处理当前节点的所有邻居,再处理邻居的邻居,强调"横向覆盖"。
2. 实现方式差异
两者的实现依赖不同的数据结构。
DFS:主要依赖 栈(Stack) 或 递归(递归的本质是调用栈)。
- 递归实现:代码简洁,无需手动维护栈,但要注意递归深度(过深可能导致栈溢出);
- 栈实现:手动维护栈,控制灵活,避免递归栈溢出问题。
BFS:主要依赖 队列(Queue)。
- 必须手动维护队列,将当前节点的邻接节点依次入队,遵循"先进先出(FIFO)"原则,确保先处理完当前层,再进入下一层。
3. 遍历顺序差异
遍历顺序是两者最明显的区别,我们用一个简单的二叉树(根节点A,左孩子B,右孩子C,B的左孩子D)来举例:
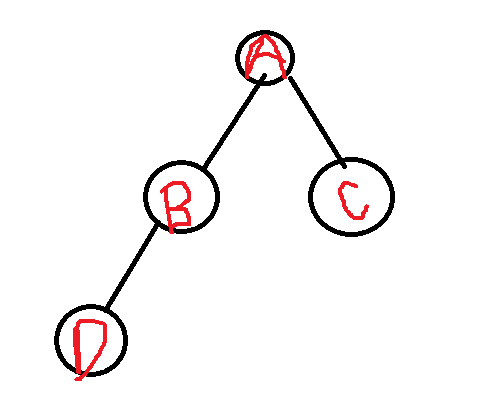
- DFS遍历顺序(以先序遍历为例):A → B → D → C(先往深走,先访问根,再访问左子树,最后右子树);
- BFS遍历顺序:A → B → C → D(先访问根,再访问根的所有孩子,再访问孩子的孩子,层层遍历)。
4. 空间复杂度差异
空间复杂度主要取决于"需要存储的未访问节点数量",与图/树的结构相关:
DFS:空间复杂度为 O(h),h 是图/树的深度(递归栈或栈中存储的节点数,最多等于深度)。
- 极端情况:如果是一棵单链树(每个节点只有一个孩子),h = n(n为节点总数),空间复杂度为 O(n);
- 最优情况:如果是一棵完全二叉树,h = logn,空间复杂度为 O(logn)。
BFS:空间复杂度为 O(w),w 是图/树的最大宽度(队列中最多存储的节点数,即某一层的最大节点数)。
- 极端情况:如果是一棵完全二叉树,最大宽度接近 n/2,空间复杂度为 O(n);
- 最优情况:如果是一棵单链树,最大宽度为 1,空间复杂度为 O(1)。
5. 适用场景差异
DFS适合场景
-
路径搜索(如:寻找从起点到终点的任意一条路径);
-
拓扑排序(如:任务调度、课程安排,处理依赖关系);
-
连通性判断(如:判断图中两个节点是否连通);
-
回溯法相关问题(如:子集、排列、组合、N皇后)。
BFS适合场景
-
最短路径搜索(如:无权图中,寻找从起点到终点的最短路径,这是BFS的核心优势);
-
层序遍历(如:二叉树的层序遍历、图的分层访问);
-
广度优先的连通性判断(如:寻找图中所有与起始节点连通的节点);
-
迷宫问题(寻找最短逃生路线)。
三、误区
- DFS比BFS快?------ 不一定。遍历速度取决于图/树的结构,比如单链树中,DFS和BFS速度一致;完全二叉树中,两者速度也相差不大,主要区别是空间和适用场景。
- BFS只能求最短路径?------ 只适用于无权图。如果图有权重,求最短路径需要用Dijkstra算法等,不能用BFS。
四、总结
DFS和BFS都是基础的遍历算法,核心区别在于搜索顺序和数据结构。
- DFS:栈/递归,深度优先,回溯探索,适合路径、拓扑排序、回溯问题;
- BFS:队列,广度优先,层层递进,适合无权图最短路径、层序遍历。
最后:如果大家有具体的题目,可以留言,一起讨论~~~~~