原文链接:https://arxiv.org/abs/2603.00654
简介:本文是第一个4D雷达-图像融合的协同感知(CP)方法。为解决深度模糊和智能体空间分散带来的错位,本文建立雷达锚定的几何共识。几何结构修正(GSR)将雷达几何和视觉语义对齐,生成可靠的、几何一致的表达。不确定性感知的通信(UAC)将选择性传输建模为条件熵降低过程,基于智能体间的分歧排列特征优先级。最后,共识驱动的集成器通过共享的几何锚,聚合多智能体信息,以得到全局一致的表达。本文方法有sota性能和较低的通信开销。
3. 方法
3.1 问题描述
假设协同感知系统包含 N N N个连接的智能体。智能体 i ∈ { 1 , ⋯ , N } i\in\{1,\cdots,N\} i∈{1,⋯,N}装备了多视角摄像机和一个4D雷达,产生局部观测 O i = { I i , R i } \mathcal O_i=\{\mathcal I_i,\mathcal R_i\} Oi={Ii,Ri},其中 I i \mathcal I_i Ii与 R i \mathcal R_i Ri表示图像和雷达测量。智能体基于观测提取局部BEV特征 F i ∈ R C × H × W F_i\in\mathbb R^{C\times H\times W} Fi∈RC×H×W(表达在其自身的坐标系下)。
自车 i i i会将其自身的BEV特征与接收自附近智能体的消息 { P j → i } j ∈ N ( i ) \{P_{j\rightarrow i}\}{j\in\mathcal N(i)} {Pj→i}j∈N(i)聚合:
F i c o l l a b = Φ θ ( F i , { P j → i } j ∈ N ( i ) ) F_i^{collab}=\Phi\theta(F_i,\{P_{j\rightarrow i}\}_{j\in\mathcal N(i)}) Ficollab=Φθ(Fi,{Pj→i}j∈N(i))
其中 Φ θ \Phi_\theta Φθ为CP模型。目标是在通信预算约束下最大化协同感知性能:
max θ ∑ i = 1 N g ( F i c o l l a b , y i ) , s . t . ∑ j ∈ N ( i ) ∣ P j → i ∣ ≤ B c o m m \max_\theta\sum_{i=1}^Ng(F_i^{collab},y_i),\;s.t.\sum_{j\in\mathcal N(i)}|P_{j\rightarrow i}|\leq B_{comm} θmaxi=1∑Ng(Ficollab,yi),s.t.j∈N(i)∑∣Pj→i∣≤Bcomm
其中 y i y_i yi为智能体 i i i的监督真值, g g g为任务度量, B c o m m B_{comm} Bcomm为通信预算。
3.2 RC-GeoCP概述
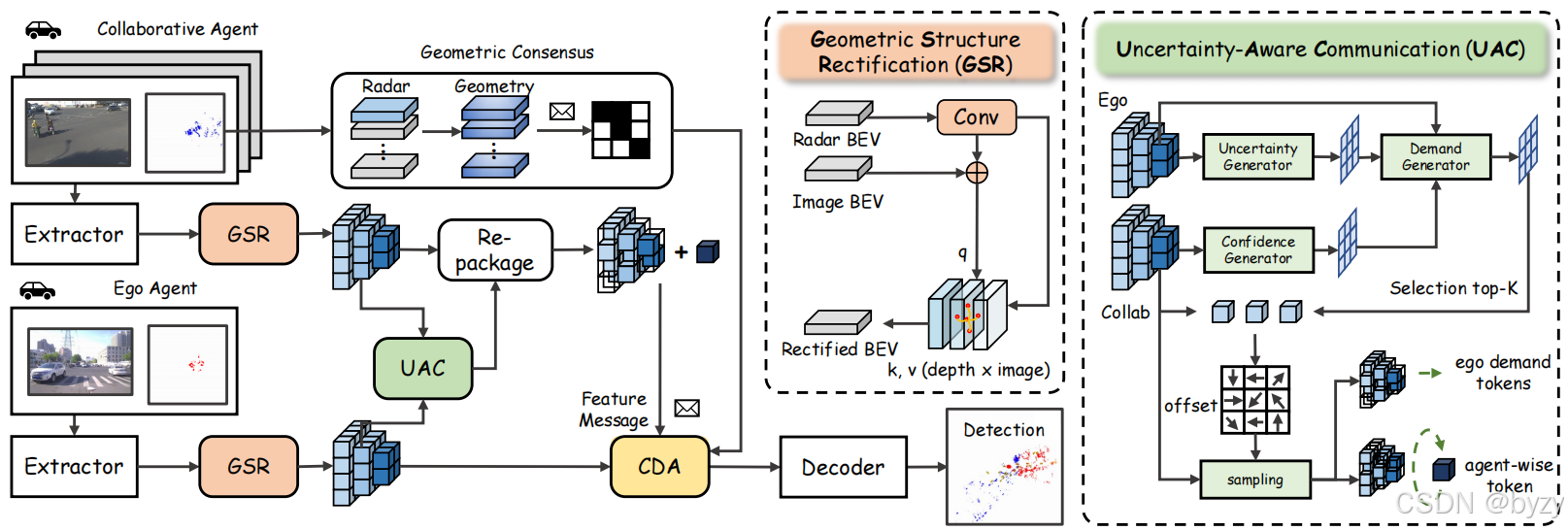
如图所示,给定局部观测 O i = { I i , R i } \mathcal O_i=\{\mathcal I_i,\mathcal R_i\} Oi={Ii,Ri},智能体会提取图像和雷达BEV特征 F i c a m , F i r a d F_i^{cam},F_i^{rad} Ficam,Firad。
- 为了减小视角依赖的分散,相机BEV特征被雷达几何修正,即 F ~ i = R ( F i c a m ∣ F i r a d ) \tilde F_i=\mathcal R(F_i^{cam}|F_i^{rad}) F~i=R(Ficam∣Firad),以保证空间一致的多模态协同感知。
- 在带宽约束下,周围的每个智能体 j j j基于不确定性感知的需求图 W i , j W_{i,j} Wi,j选择稀疏的token集合,表达为 S j → i = S ( F ~ j ∣ W i , j ) S_{j\rightarrow i}=\mathcal S(\tilde F_j|W_{i,j}) Sj→i=S(F~j∣Wi,j)。反映了自车对互补信息的需求。
- 最后,自车使用共识驱动的操作聚合接收到的token,记为 F i c o l l a b = A ( F ~ i , { S j → i } ∣ { W i , j , G j → i r a d } ) F_i^{collab}=\mathcal A(\tilde F_i,\{S_{j\rightarrow i}\}|\{W_{i,j},G_{j\rightarrow i}^{rad}\}) Ficollab=A(F~i,{Sj→i}∣{Wi,j,Gj→irad}),其中 G j → i r a d G_{j\rightarrow i}^{rad} Gj→irad为每个智能体的几何共识。
3.3 几何结构修正(GSR)
协同感知需要跨智能体几何一致性,传统的LSS范式会导致深度-语义扩散,即单目不确定性使语义沿深度轴产生模糊,导致空间错位。本文提出GSR,使用稀疏4D雷达线索作为物理锚,锚定相机语义。
首先初始化基于雷达的查询场 Q i = F i c a m + Φ i n i t ( D ( F i r a d ) ) Q_i=F_i^{cam}+\Phi_{init}(\mathcal D(F_i^{rad})) Qi=Ficam+Φinit(D(Firad)),其中 D \mathcal D D为下采样, Φ i n i t \Phi_{init} Φinit为零初始化的卷积层。可变形交叉注意力通过将BEV查询提升为垂直柱体,并将参考点 q q q投影到图像空间,来聚合多视图图像特征 F i i m g F_i^{img} Fiimg,得到修正的表达 F i r e c t F_i^{rect} Firect:
F i r e c t ( q ) = ∑ n = 1 N K n B ⋅ ϕ ( F 3 D , P ( q ) + Δ q n ) F_i^{rect}(q)=\sum_{n=1}^NK_nB\cdot\phi(F^{3D},\mathcal P(q)+\Delta q_n) Firect(q)=n=1∑NKnB⋅ϕ(F3D,P(q)+Δqn)
其中 Δ q n \Delta q_n Δqn为基于 Q i Q_i Qi的偏移量, F 3 D F^{3D} F3D为基于图像特征和深度概率建立的特征空间。
上述过程其实就是BEVFormer的视图变换过程,区别在于查询的定义方式。
随后,自适应门控校准平衡了视觉丰富度和几何精度,其中雷达作为指导者而非决策者。门控机制减弱了不确定性较强时雷达的影响,以保留纯相机语义的基准性能。最终的修正特征 F ~ i \tilde F_i F~i为
F ~ i = F i r e c t + σ ( G ( F i r e c t ) ) ⊙ Ψ ( F i r a d ) \tilde F_i=F_i^{rect}+\sigma(\mathcal G(F_i^{rect}))\odot \Psi(F_i^{rad}) F~i=Firect+σ(G(Firect))⊙Ψ(Firad)
其中 σ \sigma σ为sigmoid函数, G \mathcal G G为门控卷积。这保证了雷达几何主要在视觉不确定性较高的区域指导表达。
3.4 不确定性感知的通信(UAC)
协同感知需要在带宽约束下识别可靠和互补的信息。本文提出UAC作为以自车为中心的条件熵下降过程。通过动态评估认知不确定性和智能体间的分歧,RC-GeoCP策略性地分配带宽来解决几何模糊性而非强化冗余。这一需求驱动的机制保证传输的token有效地填充了感知的空白,同时保证高通信效率。
给定修正的特征 F ~ i ∈ R C × H × W \tilde F_i\in\mathbb R^{C\times H\times W} F~i∈RC×H×W,建立多尺度BEV金字塔 { F ~ i ( l ) } l = 1 L \{\tilde F_i^{(l)}\}_{l=1}^L {F~i(l)}l=1L以支持尺度自适应的通信。对每个附近智能体 j j j,RC-GeoCP传输的不是密集的BEV特征,而是选定的自车需求token和可学习的智能体token。
选定的自车需求token 。每个智能体首先在其局部坐标系下预测语义置信度图(反映了智能体的局部感知可靠性),并与自车对齐:
C j → i ( l ) = T j → i ( σ ( Φ c o n f ( l ) ( F ~ j ( l ) ) ) ) C_{j\rightarrow i}^{(l)}=\mathcal T_{j\rightarrow i}(\sigma(\Phi_{conf}^{(l)}(\tilde F_j^{(l)}))) Cj→i(l)=Tj→i(σ(Φconf(l)(F~j(l))))
其中 T j → i \mathcal T_{j\rightarrow i} Tj→i表示智能体 j j j到 i i i的传输通信过程。传输 C j → i ( l ) C_{j\rightarrow i}^{(l)} Cj→i(l)可在带宽约束下支持不确定性感知的协同。自车估计自己的感知不确定性 U i ( l ) = 1 − C i ( l ) U_i^{(l)}=1-C_i^{(l)} Ui(l)=1−Ci(l),强调了需要附近智能体提供额外信息的区域。
看上去 C j → i ( l ) ∈ ( 0 , 1 ) H ( l ) × W ( l ) C_{j\rightarrow i}^{(l)}\in(0,1)^{H^{(l)}\times W^{(l)}} Cj→i(l)∈(0,1)H(l)×W(l),且 C i ( l ) = σ ( Φ c o n f ( l ) ( F ~ j ( l ) ) ) C_i^{(l)}=\sigma(\Phi_{conf}^{(l)}(\tilde F_j^{(l)})) Ci(l)=σ(Φconf(l)(F~j(l)))。 T j → i \mathcal T_{j\rightarrow i} Tj→i应该也包括了坐标变换操作。
为了识别互补证据,RC-GeoCP建模了智能体间的感知分歧 D i , j ( l ) D_{i,j}^{(l)} Di,j(l)作为自车语义和周围智能体置信度的条件函数:
D i , j ( l ) = Φ d i f f ( l ) ( F ~ i ( l ) ∣ U i ( l ) , C j → i ( l ) ) D_{i,j}^{(l)}=\Phi_{diff}^{(l)}(\tilde F_i^{(l)}|U_i^{(l)},C_{j\rightarrow i}^{(l)}) Di,j(l)=Φdiff(l)(F~i(l)∣Ui(l),Cj→i(l))
其中 Φ d i f f ( l ) \Phi_{diff}^{(l)} Φdiff(l)为卷积层。更高的值表示智能体 j j j的信息与自车感知存在偏差,因此可能更有价值。基于该分歧信号,自车为每个附近智能体推断需求权重
W i , j ( l ) = σ ( Φ t r u s t ( l ) ( F ~ i ( l ) ∣ D i , j ( l ) ) ) ∑ k ∈ { i } ∪ N ( i ) σ ( Φ t r u s t ( l ) ( F ~ i ( l ) ∣ D i , k ( l ) ) ) + ϵ W_{i,j}^{(l)}=\frac{\sigma(\Phi_{trust}^{(l)}(\tilde F_i^{(l)}|D_{i,j}^{(l)}))}{\sum_{k\in\{i\}\cup\mathcal N(i)}\sigma(\Phi_{trust}^{(l)}(\tilde F_i^{(l)}|D_{i,k}^{(l)}))+\epsilon} Wi,j(l)=∑k∈{i}∪N(i)σ(Φtrust(l)(F~i(l)∣Di,k(l)))+ϵσ(Φtrust(l)(F~i(l)∣Di,j(l)))
其表达了给定智能体 j j j的信息下,以自车为中心的需求,并跨所有参与智能体归一化。 Φ t r u s t ( l ) \Phi_{trust}^{(l)} Φtrust(l)为堆叠的卷积层。
在带宽约束下,RC-GeoCP在稀疏token而非密集特征层面进行通信。令 Λ ( l ) = { 1 , ⋯ , H ( l ) } × { 1 , ⋯ , W ( l ) } \Lambda^{(l)}=\{1,\cdots,H^{(l)}\}\times\{1,\cdots,W^{(l)}\} Λ(l)={1,⋯,H(l)}×{1,⋯,W(l)}为BEV网格索引集合, W i , j ( l ) ∈ ( 0 , 1 ) H ( l ) × W ( l ) W_{i,j}^{(l)}\in(0,1)^{H^{(l)}\times W^{(l)}} Wi,j(l)∈(0,1)H(l)×W(l)为不确定性感知的需求图。本文选择 W i , j ( l ) W_{i,j}^{(l)} Wi,j(l)中的top-K token子集,其位置 Ω i , j ( l ) ⊆ Λ ( l ) \Omega_{i,j}^{(l)}\subseteq\Lambda^{(l)} Ωi,j(l)⊆Λ(l):
Ω i , j ( l ) = T o p K ( W i , j ( l ) , K ( l ) ) \Omega_{i,j}^{(l)}=TopK(W_{i,j}^{(l)},K^{(l)}) Ωi,j(l)=TopK(Wi,j(l),K(l))
其中 K ( l ) = ⌈ ρ ( l ) ⋅ ∣ Λ ( l ) ∣ ⌉ , ρ ( l ) ∈ ( 0 , 1 ] K^{(l)}=\lceil\rho^{(l)}\cdot|\Lambda^{(l)}|\rceil,\rho^{(l)}\in(0,1] K(l)=⌈ρ(l)⋅∣Λ(l)∣⌉,ρ(l)∈(0,1]为尺度 l l l对应的token比例,以控制通信预算, ∣ Λ ( l ) ∣ = H ( l ) W ( l ) |\Lambda^{(l)}|=H^{(l)}W^{(l)} ∣Λ(l)∣=H(l)W(l)。
传输前,RC-GeoCP会在智能体 j j j的局部坐标系下细化选定的token,以更好地捕捉互补的几何与语义上下文。可变形细化操作用于在选定区域内( p ∈ Ω i , j ( l ) p\in\Omega_{i,j}^{(l)} p∈Ωi,j(l))进行内容自适应的采样:
F ˉ j ( l ) ( p ) = D ( l ) ( F ~ j ( l ) , p ) + F ~ j ( l ) ( p ) \bar F^{(l)}_j(p)=\mathcal D^{(l)}(\tilde F_j^{(l)},p)+\tilde F_j^{(l)}(p) Fˉj(l)(p)=D(l)(F~j(l),p)+F~j(l)(p)
其中 D ( l ) \mathcal D^{(l)} D(l)为可变形注意力。
可学习的智能体token 。为了补偿top-k选择时丢弃的信息,本文还引入多尺度智能体token来聚合剩下的特征。剩余特征定义为 F ~ j ( l ) , r e s = { F ~ j ( l ) ( p ) ∣ p ∉ Ω i , j ( l ) } \tilde F_j^{(l),res}=\{\tilde F_j^{(l)}(p)|p\notin\Omega_{i,j}^{(l)}\} F~j(l),res={F~j(l)(p)∣p∈/Ωi,j(l)}。可学习的智能体token a j ( l ) a_j^{(l)} aj(l)通过多头交叉注意力聚合剩余特征:
e j ( l ) = A t t n ( a j ( l ) , F ~ j ( l ) , r e s , F ~ j ( l ) , r e s ) e_j^{(l)}=Attn(a_j^{(l)},\tilde F_j^{(l),res},\tilde F_j^{(l),res}) ej(l)=Attn(aj(l),F~j(l),res,F~j(l),res)
紧凑嵌入 e j ( l ) e_j^{(l)} ej(l)捕捉了选定token之外的互补信息,以保留稀疏通信下的全局上下文。
局部细化后,每个附近智能体传输选定的自车需求token和智能体token,转化到自车坐标系下:
S j → i ( l ) = T j → i ( { F ˉ j ( l ) ( p ) ∣ p ∈ Ω i , j ( l ) } ∪ { e j ( l ) } ) S_{j\rightarrow i}^{(l)}=\mathcal T_{j\rightarrow i}(\{\bar F^{(l)}j(p)|p\in\Omega{i,j}^{(l)}\}\cup \{e_j^{(l)}\}) Sj→i(l)=Tj→i({Fˉj(l)(p)∣p∈Ωi,j(l)}∪{ej(l)})
其中 S j → i ( l ) S_{j\rightarrow i}^{(l)} Sj→i(l)表示智能体 j j j到自车的通信token集。自车保留了其完整的BEV表达,而附近智能体仅传输稀疏的、需求驱动的token,以及紧凑的、智能体级别的嵌入。该设计在确保带宽高效通信的同时,保留了选定区域之外的互补上下文信息。
除了token选择之外,自车需求图通过将置信度logit值聚合到共享的占用图中,来监督协作一致性,从而在训练过程中促进可靠智能体的一致性。这种设计实现了具有不确定性感知的通信,该机制具有带宽效率优势,且与下游融合过程紧密耦合。
3.5 共识驱动的集成器(CDA)
RC-GeoCP使用CDA来保证多智能体聚合时的几何一致性,其中来自雷达的几何共识为调节融合提供共享的物理参考。
每个智能体首先利用雷达特征,通过可学习映射和sigmoid函数来预测基于雷达的几何可靠性图。可靠性分数会对齐到自车坐标系,以在不传输雷达特征的前提下提供几何感知的置信度。对齐的跨智能体几何共识记为 G i , j ( l ) ( p ) G_{i,j}^{(l)}(p) Gi,j(l)(p),即智能体 j j j在位置 p p p处的归一化几何可靠性。
通过将几何信息注入注意力logit,该几何共识可以驱动token聚合。对附近智能体 j j j,收集其传输的token { t j , m ( l ) } m = 1 M \{t_{j,m}^{(l)}\}{m=1}^{M} {tj,m(l)}m=1M,并stack得到
X j → i ( l ) = t j , 1 ( l ) , ⋯ , t j , M ( l ) ⊤ ∈ R M × C , M = ∣ Ω i , j ( l ) ∣ + 1 X{j\rightarrow i}^{(l)}=t_{j,1}\^{(l)},\\cdots,t_{j,M}\^{(l)}^\top\in\mathbb R^{M\times C},M=|\Omega_{i,j}^{(l)}|+1 Xj→i(l)=tj,1(l),⋯,tj,M(l)⊤∈RM×C,M=∣Ωi,j(l)∣+1
随后,计算基于内容的注意力logit:
A j → i ( l ) = X j → i ( l ) ( X j → i ( l ) ) ⊤ C A_{j\rightarrow i}^{(l)}=\frac{X_{j\rightarrow i}^{(l)}(X_{j\rightarrow i}^{(l)})^\top}{\sqrt C} Aj→i(l)=C Xj→i(l)(Xj→i(l))⊤
以建模来自智能体 j j j的token的逐对相似度。
为注入几何一致性,本文为每个选定的token分配对应位置 p ∈ Ω i , j ( l ) p\in\Omega_{i,j}^{(l)} p∈Ωi,j(l)的几何共识 G i , j ( l ) ( p ) G_{i,j}^{(l)}(p) Gi,j(l)(p),作为logit先验。注意力矩阵按下式得到:
A j → i ( l ) = S o f t m a x ( A j → i ( l ) + log g j → i ( l ) ) A_{j\rightarrow i}^{(l)}=Softmax(A_{j\rightarrow i}^{(l)}+\log g_{j\rightarrow i}^{(l)}) Aj→i(l)=Softmax(Aj→i(l)+loggj→i(l))
其中 g j → i ( l ) ∈ R M g_{j\rightarrow i}^{(l)}\in\mathbb R^M gj→i(l)∈RM为token的几何先验stack的结果,softmax沿token维度归一化。
只介绍了选定token的几何先验,智能体token的几何先验如何得到?
重新聚合的token集合按下式计算:
X ^ j → i ( l ) = A j → i ( l ) X j → i ( l ) \hat X_{j\rightarrow i}^{(l)}=A_{j\rightarrow i}^{(l)}X_{j\rightarrow i}^{(l)} X^j→i(l)=Aj→i(l)Xj→i(l)
最后,重新聚合的token被还原到BEV网格,得到协同表达,与自车需求图融合得到 F c o l l a b , ( l ) F^{collab,(l)} Fcollab,(l)。随后进行多尺度协同特征融合:
F c o l l a b = F ( { F c o l l a b , ( l ) } l = 1 L ) F^{collab}=\mathcal F(\{F^{collab,(l)}\}_{l=1}^L) Fcollab=F({Fcollab,(l)}l=1L)
其中 F \mathcal F F为轻量级多尺度融合操作。
自车的BEV特征 F ~ i \tilde F_i F~i呢?
该设计通过几何共识调节归一化融合权重与基于内容的注意力,从而实现基于物理且空间一致性高的多智能体聚合。通过基于雷达的几何共识对聚合过程进行调节,CDA算法无需额外通信开销,即可实现基于物理且空间一致性高的多智能体感知。
4. 实验
定义一个基本通信单位为64x64x256x4字节。通信成本表示为总传输字节数除以该基本单位。
这里的基本通信单位应该是传输一张特征图的通信量,其分辨率为64x64,通道数为256,每个值是32位浮点数。
时间延迟通过从前一个时间戳中检索样本来模拟。
总结。本文的方法进行了三次传输:
- 在UAC模块开始时传输语义置信度图
- 在UAC模块结束时传输token
- 在CDA模块开始时传输基于雷达的几何可靠性图