随着大模型参数量持续攀升,AI 推理对硬件算力与能效的要求愈发严苛,消费级显卡已难以满足企业级、高负载的 AI 部署需求。NVIDIA 面向专业领域推出的 RTX Pro 6000 显卡,专为 AI 计算与专业图形工作流打造,其真实算力表现备受行业关注。
本次针对 230B参数 AI 模型的实测,正是为验证这款专业显卡的核心竞争力 ------ 在顶级 AI 推理任务中,能否以更低功耗、更精简的硬件配置,达成多块旗舰消费级显卡的算力水平。本次测试结果不仅直观展现 RTX Pro 6000 的技术优势,也为专业 AI 算力部署、大模型落地应用提供了关键的硬件参考依据。
一、从一组社区实测数据说起
最近看到一组来自社区工程师的横向测试结果,场景很典型:在单节点环境下运行MiniMax M2.7(230B参数,GGUF/IQ3_XXS量化)的本地推理,对比了几种不同的GPU配置方案。
测试条件统一为32K上下文长度、4096最大输出token,采用相同的GGUF量化方案(UD-IQ3_XXS)。结果如下: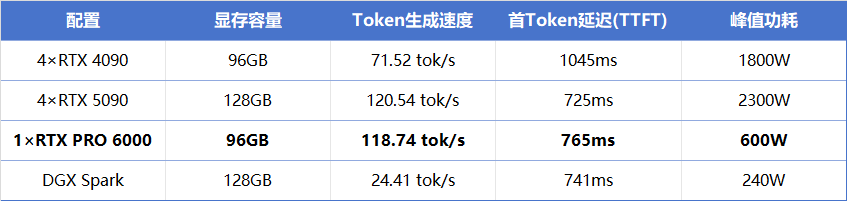
单看token生成速度,PRO 6000与四卡5090几乎打平。但这组结果的意义,并不在于简单比较两类 GPU 的"强弱",而在于揭示一个在大模型推理中越来越关键的事实:系统性能不仅取决于算力规模,还与显存容量、数据路径以及整体架构设计密切相关。
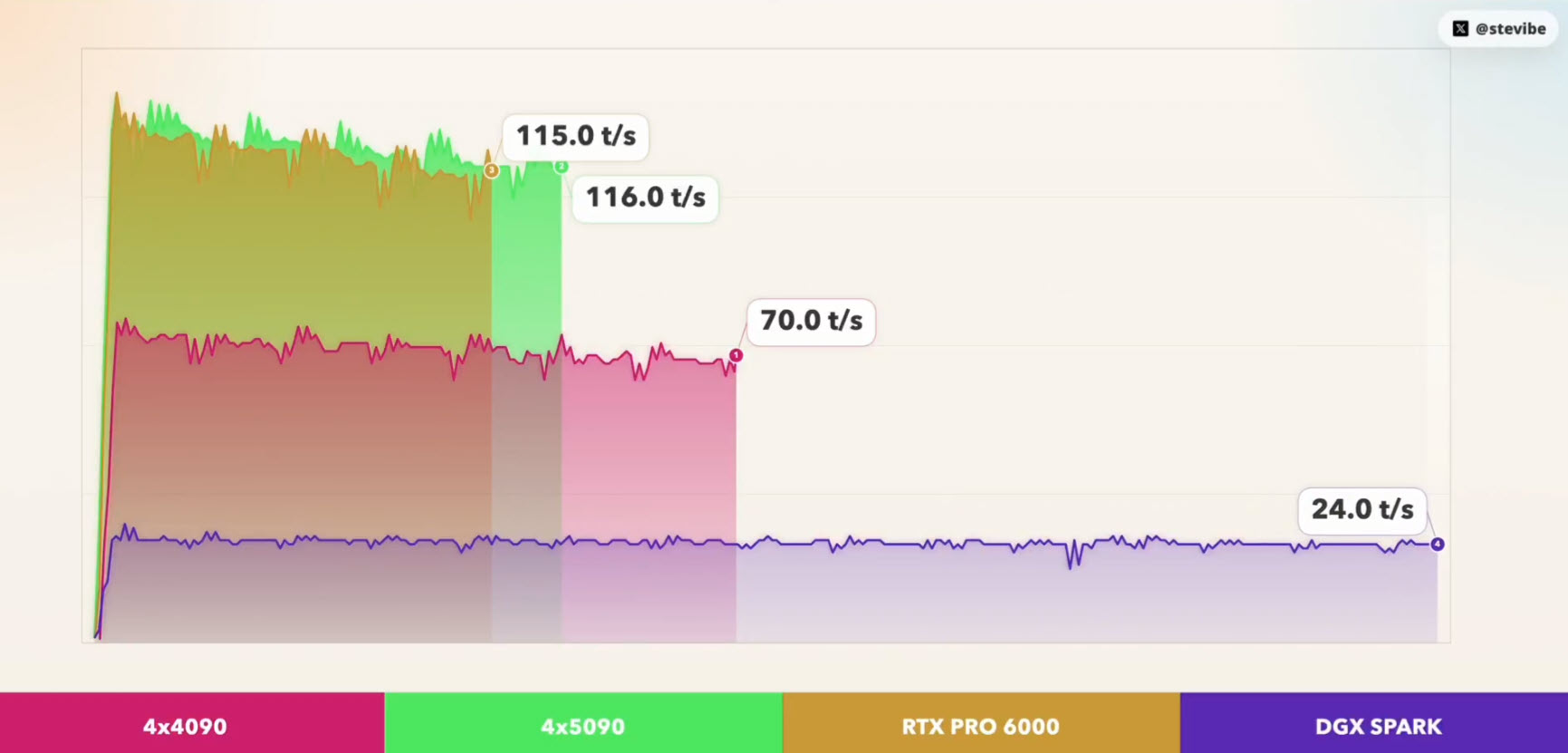
二、数据背后的架构逻辑
2.1 为什么单卡能追平四卡?
230B模型用4bit量化后,权重约占用80-85GB。PRO 6000的96GB显存刚好能完整吞下整个模型,推理过程全在单卡内完成,没有跨设备通信。
四张5090虽然合计128GB显存更大,但模型需要切分到四张卡上执行,每张卡都要维护完整的KV Cache副本,再加上层间同步开销,实际效率并没有线性提升。
这里有个细节容易被忽略:token/s测的是单序列连续生成 的吞吐,没有反映并发批处理 能力。
如果同时服务8个用户请求,四卡5090可以通过数据并行把请求分发到不同卡上,总吞吐反而会反超单卡PRO 6000。
所以这组数据更适合理解"单任务推理路径",而不是完整的生产负载表现。

2.2 功耗差异的深层含义
真正值得关注的是效率维度:
●功耗比:PRO 6000以600W实现了与2300W四卡集群相当的推理性能,能效比约为后者的3.8倍
●空间占用:单卡方案省去了多卡互联的物理空间、散热风道设计以及供电冗余
●通信开销:多卡推理必然涉及NVLink或PCIe的显存同步,在自回归生成场景下,这种开销会随着batch size增大而累积
对于需要在标准42U机柜中部署多套推理节点的企业而言,这意味着在相同的电力配额下,PRO 6000方案可以部署更多并发实例。
2.3 消费级与专业级的隐性边界
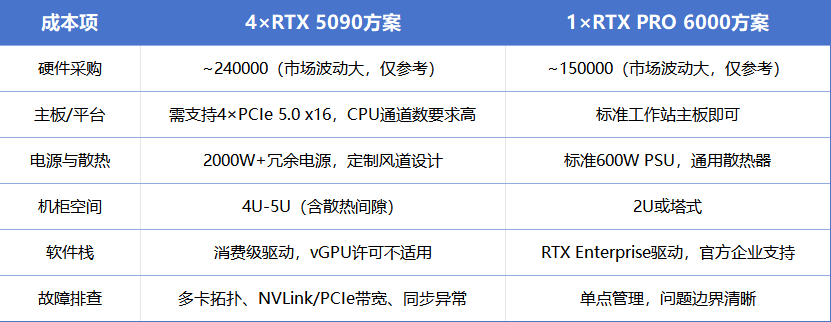
如果只看硬件采购价,四张5090约14,000,单张PRO 6000约9,500,消费级似乎仍有价格优势。但企业部署的成本模型要复杂得多: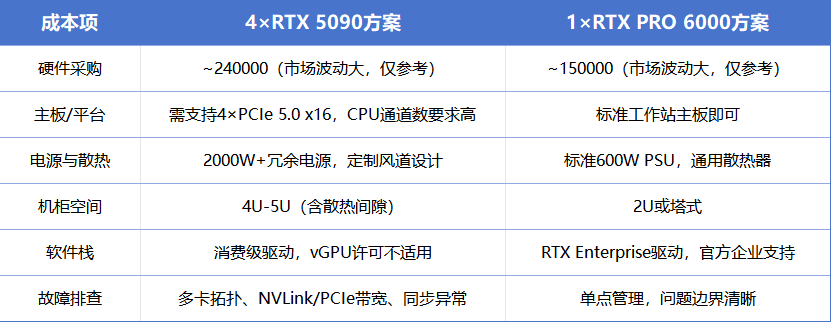 在三年TCO模型里,PRO 6000的运维成本优势会逐渐抹平初始采购价差,尤其是在需要7×24小时稳定运行的生产环境。
在三年TCO模型里,PRO 6000的运维成本优势会逐渐抹平初始采购价差,尤其是在需要7×24小时稳定运行的生产环境。
三、选型决策:从业务负载出发
企业级GPU选型,更适合围绕实际负载展开,而非单纯对比参数。
3.1 按模型规模划分
3.2 按并发特征划分
●单用户/低并发:大显存单卡更适合,TTFT稳定,无多卡调度开销
●中等并发(10-50 QPS):2-4卡架构更均衡,可通过数据并行提升总吞吐
●高并发(50+ QPS):多卡或多节点集群更具优势,需配合负载均衡与请求路由
3.3 按部署阶段划分
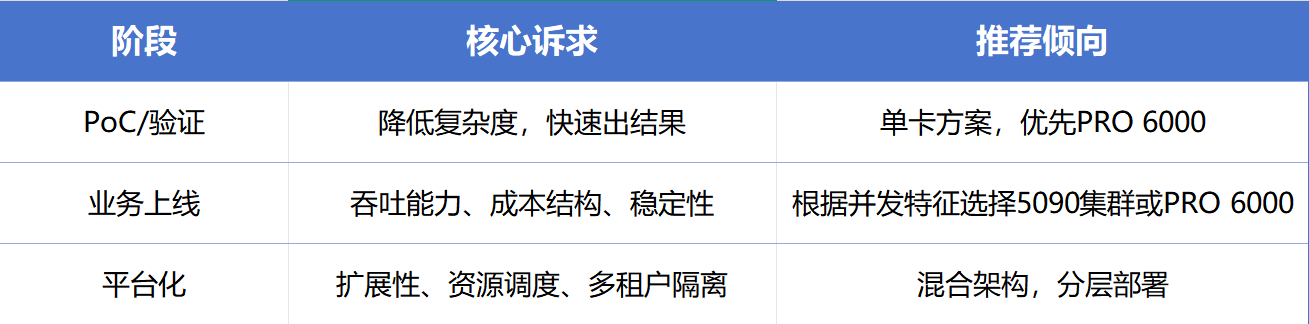
四、系统效率:被低估的性能杠杆
在实际项目中,GPU型号只是性能的基础条件,系统设计往往决定最终能释放多少潜力。
去年我们做过一个对比测试:同样的4×RTX 5090配置,默认vLLM部署 vs 经过TensorRT-LLM优化、KV Cache量化、Continuous Batching调优后的表现,吞吐差异达到2.3倍。这个幅度相当于硬件升级一代的收益。
关键优化点包括:
推理引擎选择:vLLM适合快速验证,TensorRT-LLM适合生产环境极致性能
KV Cache管理:长上下文场景下,KV Cache占用可能超过模型权重本身,需启用分页注意力(PagedAttention)或压缩策略
批处理策略:动态batching vs continuous batching,对TPOT(Time Per Output Token)影响显著
存储与数据通路:模型权重加载速度、PCIe带宽、NUMA拓扑,都会影响到首token延迟
一句话总结:GPU决定性能上限,系统设计决定实际能达到的高度。

五、赋创方案实践:分层架构设计
在过去的项目交付中,RTX PRO 6000与RTX 5090很少是"二选一"的关系,更多是以分层架构组合使用。
一个金融客户的实际部署案例如下:
生产集群层:RTX PRO 6000 × 4
→ 承载核心大模型推理(70B+参数),长上下文客服场景,要求TTFT < 800ms
推理服务层:RTX 5090 × 8
→ 中小模型(7B-14B)高并发API服务,峰值QPS 200+,通过Kubernetes HPA自动扩缩容
开发测试层:RTX 5080/4090 × 1
→ 模型微调、Prompt工程、A/B测试,与生产环境物理隔离
该架构在实际应用中具备以下特点:
资源隔离:生产环境与开发测试环境相互独立
成本优化:不同规模模型匹配不同硬件层级
弹性扩展:各层可根据业务需求独立扩容
在实施过程中可以观察到,软件层优化对性能释放的影响往往较为显著。例如,在相同硬件条件下,通过推理引擎优化、KV Cache 管理优化以及批处理策略调整,整体吞吐能力通常可以获得明显提升。
六、结论与选型检查清单
围绕 RTX PRO 6000 与 RTX 5090 的选型,本质上是:单节点效率与集群扩展能力之间的平衡问题
两类 GPU 分别对应不同的优化方向,在企业级场景中并不存在统一最优解。更有效的方式,是结合模型规模、并发需求与基础设施条件进行整体设计。
FAQ:RTX PRO 6000 与 RTX 5090 选型常见问题
Q1:RTX PRO 6000 是否可以完全替代多卡 RTX 5090?
A:不能,前者适合单节点大模型推理,后者更适合高并发与集群扩展场景。
Q2:230B 模型测试结果是否代表真实业务性能?
A:不完全代表,该类测试更多反映特定量化与单任务推理条件下的表现。
Q3:企业部署大模型时,优先考虑显存还是算力?
A:通常优先考虑显存容量是否满足模型加载,其次再优化算力与吞吐。
Q4:RTX 5090 多卡部署的主要优势是什么?
A:通过横向扩展提升整体吞吐能力,更适合多用户与高并发服务。
Q5:RTX PRO 6000 的核心价值是什么?
A:在于大显存带来的单卡完整推理能力与更低的系统复杂度。
Q6:推理性能优化主要依赖硬件还是软件?
A:两者共同决定,但在实际项目中软件调优对性能提升影响往往更显著。
Q7:是否必须在 RTX PRO 6000 和 RTX 5090 之间二选一?
A:不需要,实际部署中更常见的是分层组合架构。
Q8:企业如何验证选型是否合理?
A:建议通过 PoC 测试关键指标(如 TTFT、吞吐、并发能力)后再做决策。