目录
一.加载数据集
使用weather(天气)数据集。其中包含6个字段**(6列)**:
- date:日期,年-月-日格式。
- precipitation:降水量。
- temp_max:最高温度。
- temp_min:最低温度。
- wind:风力。
- weather:天气状况。
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
print(type(df)) # 查看df的类型
print("-----------------------")
print(df.shape) # 查看df的形状
print("-----------------------")
print(df.columns) # 查看df的列名
print("-----------------------")
print(df.dtypes) # 查看df各列数据类型
print("-----------------------")
print(df.info()) # 查看df基本信息运行结果:
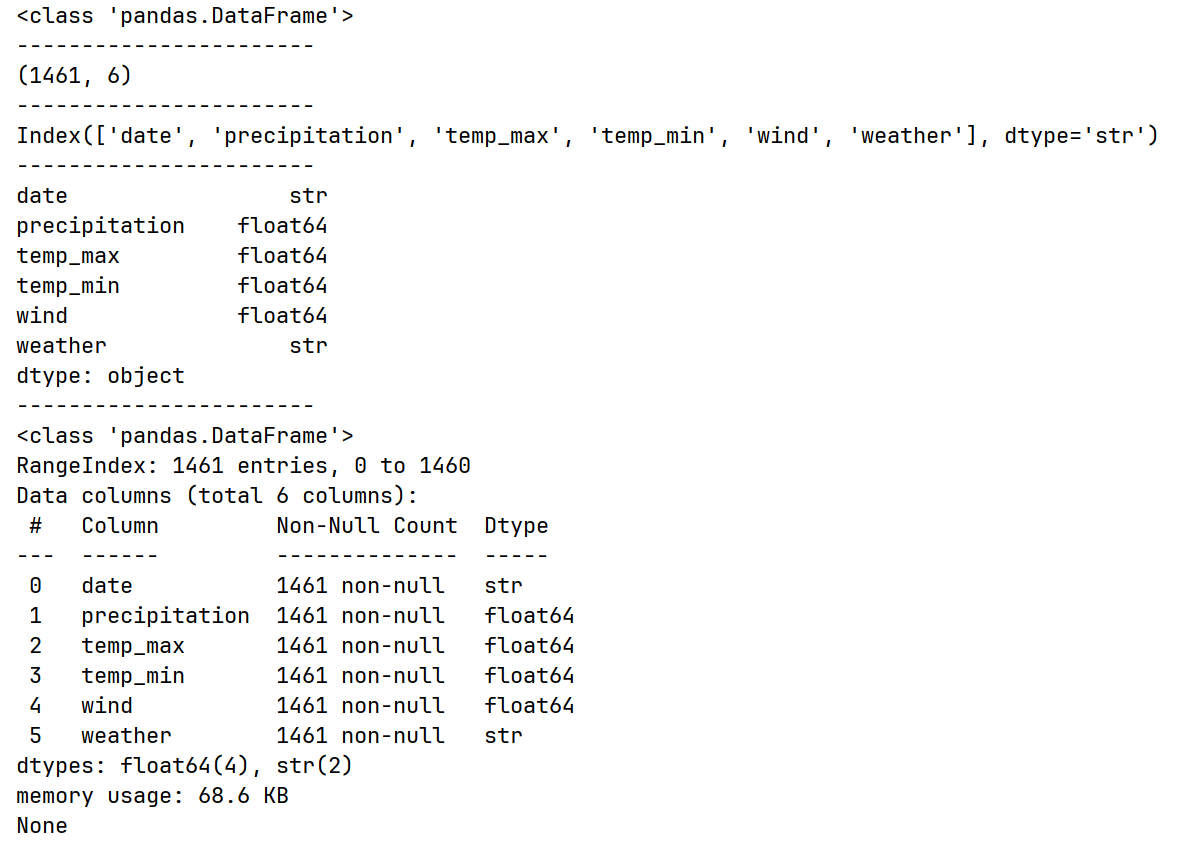
pandas与Python常用数据类型对照:
| Python 原生类型 | pandas 类型 (dtype) | 说明 |
|---|---|---|
int |
int64 |
整数 |
float |
float64 |
浮点数 |
bool |
bool |
布尔值 |
str |
object / string |
字符串(pandas 推荐用 string) |
datetime.datetime |
datetime64[ns] |
日期时间 |
datetime.timedelta |
timedelta64[ns] |
时间差 |
list / dict |
object |
任意 Python 对象 |
二.查看部分数据
1.通过head()、tail()获取前n行或后n行
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
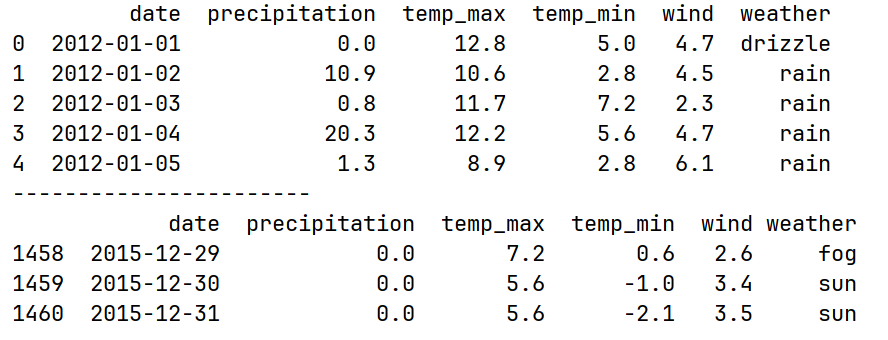
print(df.head())
print("-----------------------")
print(df.tail(3))运行结果:
2.获取一列或多列数据
加载一列数据:
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
df_date_series = df["date"] # 返回的是Series
df_date_dataframe = df[["date"]] # 返回的是DataFrame加载多列数据:
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
df_multi_columns = df[["date", "temp_max", "wind"]]按行获取数据:
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
df.loc[1] # 获取行标签为1的数据
df.loc[[1, 10, 100]] # 获取行标签分别为1、10、100的数据
df.iloc[0] # 获取行位置为0的数据
df.iloc[-1] # 获取行位置为最后一位的数据
df.loc[1, "precipitation"] # 获取行标签为1,列标签为precipitation的数据
df.loc[:, "precipitation"] # 获取所有行,列标签为precipitation的数据
df.iloc[:, [3, 5, -1]] # 获取所有行,列位置为3,5,最后一位的数据
df.iloc[:10, 2:6] # 获取前10行,列位置为2、3、4、5的数据
df.loc[:10, ["date", "precipitation", "temp_max", "temp_min"]] # 通过行列标签获取数据三.分组聚合计算
df.groupby("分组字段")"要聚合的字段".聚合函数()
df.groupby("分组字段", "分组字段2", ...)\["要聚合的字段", "要聚合的字段2", ...].聚合函数()
1.将数据按月分组,并统计最大温度和最小温度的平均值
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
df["month"] = pd.to_datetime(df["date"]).dt.to_period("M") # 将date转换为 年-月 的格式
groupby_month = df.groupby("month") # 按month分组,返回一个分组对象
temp = groupby_month[["temp_max", "temp_min"]] # 从分组对象中选择特定的列
tempMean = temp.mean() # 对每个列求平均值
# 以上代码可以写在一起
# tempMean = df.groupby("month")[["temp_max", "temp_min"]].mean()
print(tempMean)部分运行结果:
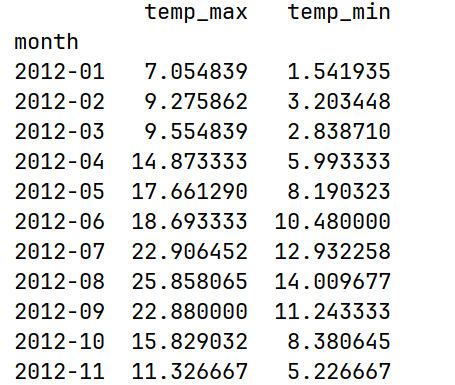
分组后默认会将分组字段作为行索引。如果分组字段有多个,得到的是复合索引。
2.分组频数计算
统计每个月不同天气状况的数量。
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
df["month"] = pd.to_datetime(df["date"]).dt.to_period("M") # 将date转换为 年-月 的格式
print(df.groupby("month")["weather"].nunique())运行结果:
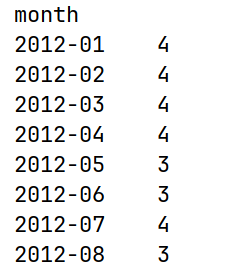
四.基本绘图
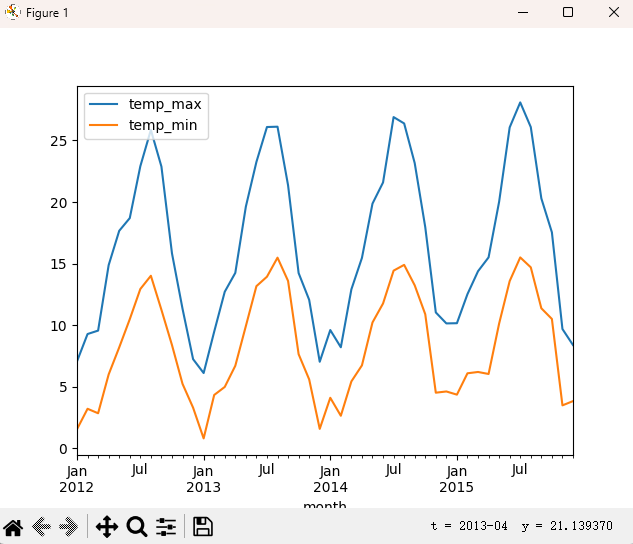
**plot():**pandas 提供的绘图方法,它基于 matplotlib 库(需提前安装)。将前面计算得到的均值结果绘制成图表,默认情况下会绘制折线图,其中 "month" 作为 x 轴,"temp_max" 和 "temp_min" 的均值作为 y 轴。
python
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("data/weather.csv")
df["month"] = pd.to_datetime(df["date"]).dt.to_period("M") # 将date转换为 年-月 的格式
df.groupby("month")[["temp_max", "temp_min"]].mean().plot()
plt.show()运行结果:
五.常用统计值
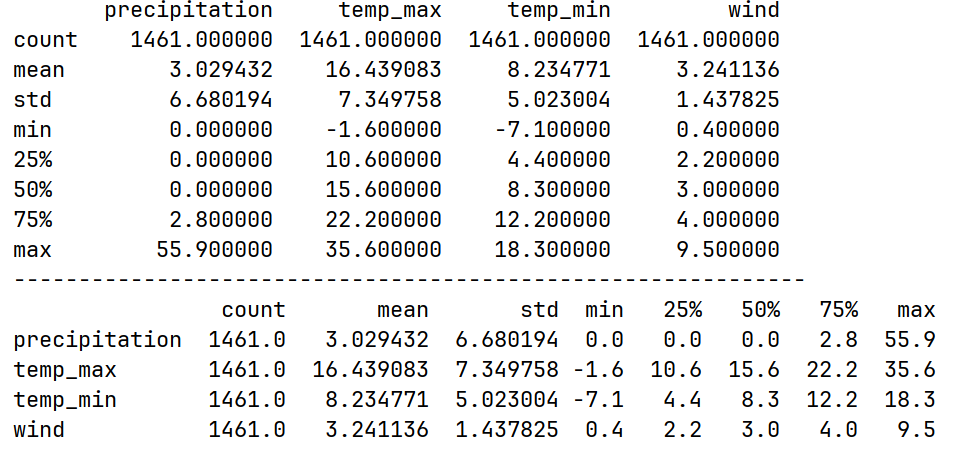
可通过describe()查看常用统计信息。
python
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("data/weather.csv")
print(df.describe())
print("-------------------------------------------------------------")
print(df.describe().T)运行结果:
可通过include参数指定要统计哪些数据类型的列。
python
df.describe(include="all") # 统计所有列
df.describe(include=["float64"]) # 只统计数据类型为float64的列六.常用排序方法
****nlargest(n, 列名1, 列名2,**** ****...**** ****):****按列排序的最大n个
****nsmallest(n, 列名1, 列名2,**** ****...**** ****):****按列排序的最小n个
****sort_values(列名1, 列名2,**** ****...**** ****, asceding=True, False,**** ****...**** ****):****按列升序或降序排序
drop_duplicates ****(subset=列名1, 列名2):****按列去重
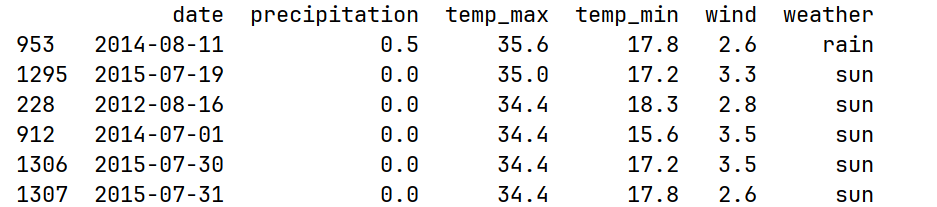
1.找到最高温度最大的30天
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
print(df.nlargest(30, "temp_max"))部分运行结果:
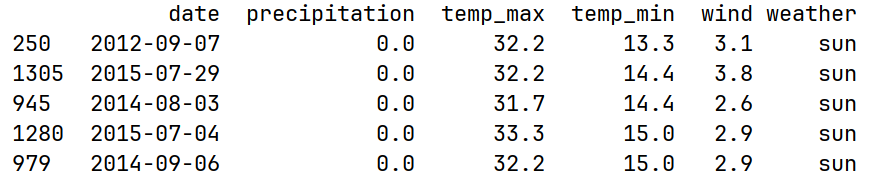
2.从最高温度最大的30天中找出最低温度最小的5天
python
import pandas as pd
df = pd.read_csv("data/weather.csv")
print(df.nlargest(30, "temp_max").nsmallest(5, "temp_min"))运行结果:
3.找出每年的最高温度
python
import pandas as pd
import matplotlib.pyplot as plt
df = pd.read_csv("data/weather.csv")
df["year"] = pd.to_datetime(df["date"]).dt.to_period("Y") # 将date转换为 年 格式
sortDf = df.sort_values(["year", "temp_max"], ascending=[True, False]) # 按year升序,temp_max降序排序
print(sortDf.drop_duplicates("year")) # 按year去重运行结果:

也可以用分组聚合的方式获得结果:
python
print(df.groupby("year")[["temp_max"]].max())七.案例:简单数据分析练习
使用employees(员工)数据集,其中包含10个字段:
- employee_id:员工id。
- first_name:员工名称。
- last_name:员工姓氏。
- email:员工邮箱。
- phone_number:员工电话号码。
- job_id:员工工种。
- salary:员工薪资。
- commission_pct:员工佣金比例。
- manager_id:员工领导的id。
- department_id:员工的部门id。
以下是我自己的练习代码,部分代码有更好更优的写法。这里我就不一一演示了。
python
import pandas as pd
import matplotlib.pyplot as plt
# 加载数据
df = pd.read_csv("data/employees.csv")
# 查看数据
# print(df.shape)
# print(df.columns)
# print(df.describe())
# print(df.head())
# df.info()
# 找出薪资最低、最高的员工
# sortSalary = df.sort_values("salary", ascending = True)
# print(sortSalary.iloc[0, :])
# print("----------------------------------------------------")
# print(sortSalary.iloc[-1, :])
# 找出薪资最高的10名员工
# max10Salary = df.sort_values("salary", ascending = False).head(10)
# print(max10Salary[["employee_id", "first_name", "salary"]])
# 查看所有部门id
# print(df[["department_id"]].drop_duplicates())
# print(df["department_id"].unique())
# 查看每个部门的员工数
# print(df.groupby("department_id")["employee_id"].count().rename("employee_count"))
# 绘图
# df.groupby("department_id")["employee_id"].count().rename("employee_count").plot(kind="bar")
# plt.show()
# 薪资的分布
# print(df["salary"].mean())
# print(df["salary"].median())
# print(df["salary"].std())
# 找出平均薪资最高的部门id
print(df.groupby("department_id")["salary"].mean().nlargest(1))