一、基于规则进行关系抽取
首先维护一个关系字典,格式是:
relations2dict = {'夫妻关系':'结婚', '领证', '婚礼',
'合作关系': '搭档', '合作', '签约',
'演员关系': '出演', '角色', '主演'}
基于规则实现关系抽取的原理 (主要分为三个步骤)
- 第一步:定义需要抽取的关系集合,比如【夫妻关系,合作关系,,...】
- 第二步:遍历文章的每一句话,将每句话中非实体和非关系集合里面的词去掉(使用jieba词性标注实现《nr:人名,x:非语素词》)
- 第三步:分别从实体集合和关系集合中,提取关系三元组
import jieba.posseg as pseg
# 需要进行关系抽取的样本数据
samples = ["2014年1月8日,杨幂与刘恺威的婚礼在印度尼西亚巴厘岛举行",
"周星驰和吴孟达在《逃学威龙》中合作出演",
'成龙出演了《警察故事》等多部经典电影']
# 定义需要抽取的关系集合
relations2dict = {'夫妻关系':['结婚', '领证', '婚礼'],
'合作关系': ['搭档', '合作', '签约'],
'演员关系': ['出演', '角色', '主演']}
# 通过jieba词性识别抽取出nr的实体和带有关系的词组
for text in samples:
entities = [] # 存储实体
relations = [] # 存储关系
move_name = [] #存储非素语词
for word, flag in pseg.lcut(text): #分词以后的结果是词语、词性
if flag == 'nr':
entities.append(word)
elif flag == 'x':
if len(move_name) == 0:
move_name.append(text.index(word))
else: #如果有内容,那么里面放的是《,然后把》添加到列表里面
move_name.append(text.index(word))
entities.append(text[move_name[0] + 1: move_name[1]]) #把索引中间的实体添加到实体列表里面
else: #如果既不是nr也不是非素语词中包含的内容,那么遍历关系集合
for key, value in relations2dict.items():
if word in value:
relations.append(key) #如果集合中有这个词,那么把这个词的关系标签返回
if len(entities) >= 2 and len(relations) >= 1:
print("原始文本:", text)
print('提取结果:', entities[0] + '->' + relations[0] + '->' + entities[1])
else:
print("原始文本:", text)
print('不好意思,暂时没能从文本中提取出关系结果')
print('*'*80)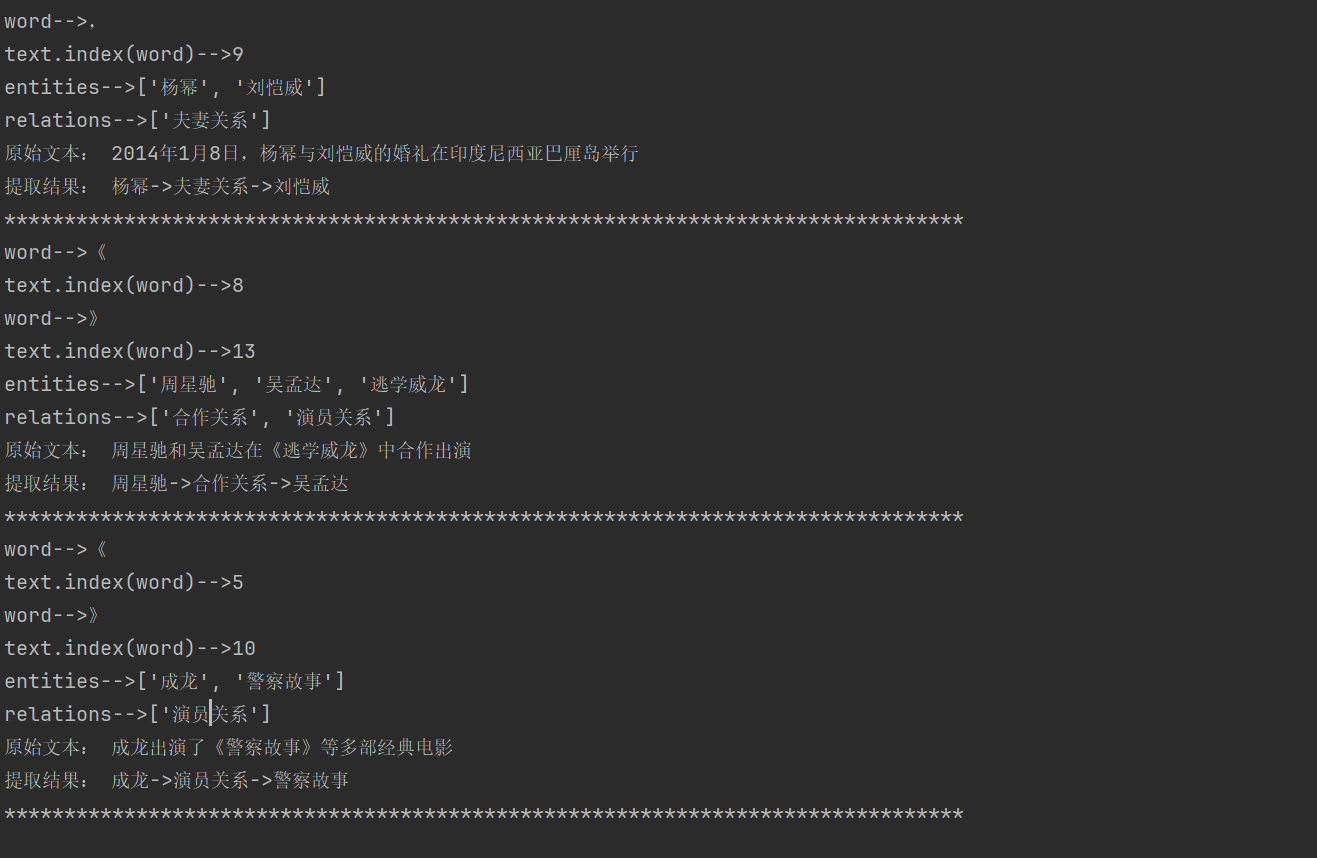
缺点:召回率比较低、可移植性差、无法解决复杂场景
二、Pipeline方法实现关系抽取
- pipeline方法是指在实体识别已经完成的基础上再进行实体之间关系的抽取.
- 早期的流水线学习方法主要采用卷积神经网络 (CNN) 和循环神经网络 (RNN) 两大类结构.其中,CNN多样性卷积核的特性有利于识别目标的结构特征,而RNN能充分考虑长距离词之间的依赖性,其记忆功能有利于识别序列.随着深度学习的不断发展, 研究者不断改进和完善CNN和RNN的方法,并产生了许多变体,如长短期记忆网络 (LSTM) 、双向长短期记忆网 (BI-LSTM) 、等,从而进一步促进了关系抽取的发展.
- pipeline方法流程:
- 先对输入的句子进行实体抽取,将识别出的实体分别组合;然后再进行关系分类.
- 注意:这两个子过程是前后串联的,完全分离.
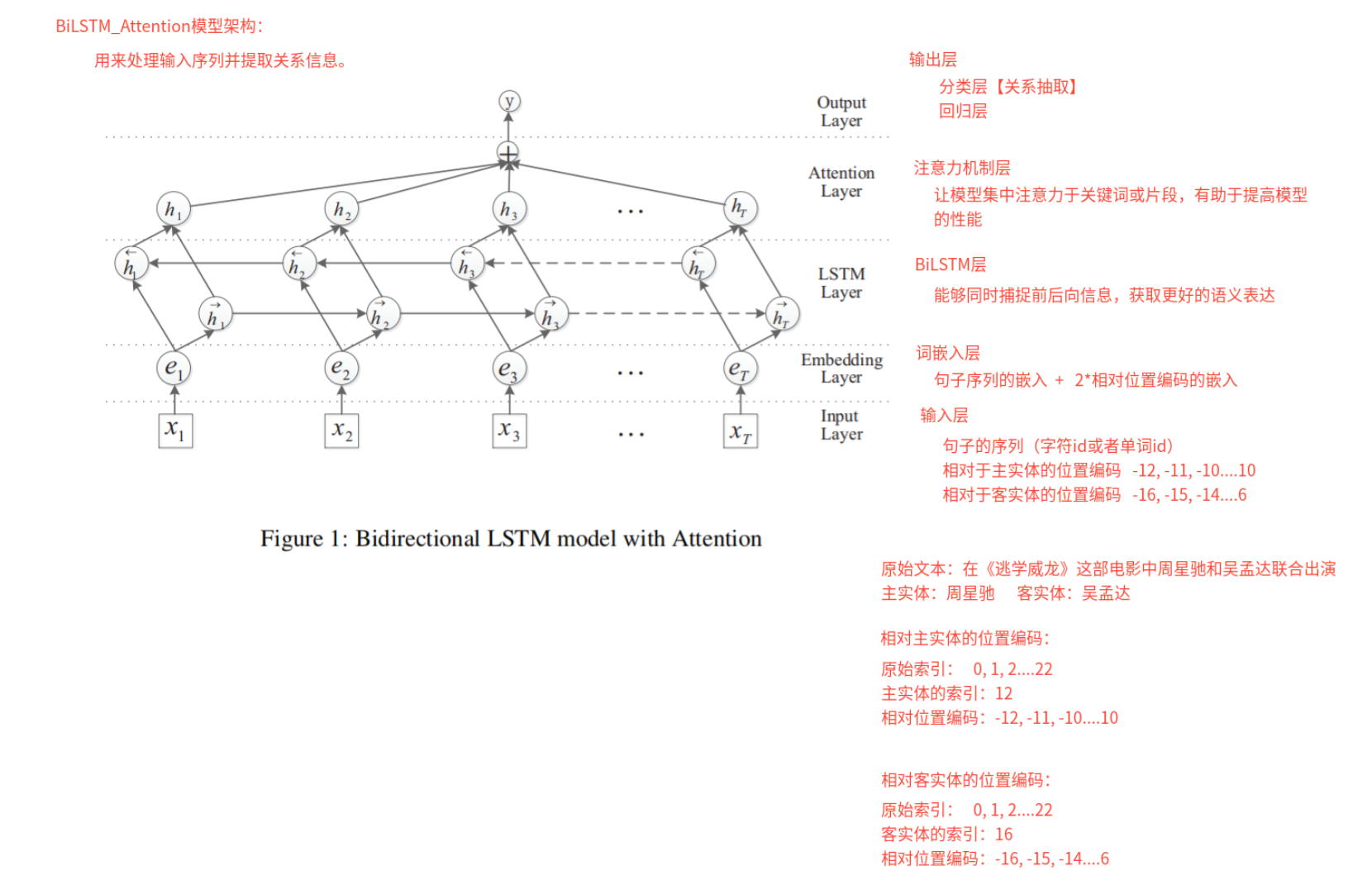
2.1 BiLSTM+Attention算法思想
- BiLSTM+Attention模型最初由Zhou等人在2016年的论文《Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification》中提出.
- 该模型结合了双向长短时记忆网络 (Bidirectional LSTM) 和注意力机制 (Attention) ,用于处理输入序列并提取关系信息. 该模型并被应用于关系分类任务.
- 这个模型是用来实现提取关系的,所以需要先把序列的NER识别出来才能使用这个模型实现关系识别
- 现在关系抽取的模型很多是基于BiLSTM+Attention实现的
2.2 BiLSTM+Attention模型架构
输入层支持输入字符、单词序列
输入层需要输入的内容:
- 字符或单词序列(解释:既可以是字符组成的序列也可以是单词组成的序列)
- 相对于主实体、客实体的位置编码(让神经网络识别位置信息)
2.2.1Attention思想
注意力机制 = 模仿人的注意力 读一句话、看一张图时,不会平均用力 ,而是重点关注关键信息,忽略无关信息,给重要内容更高权重、不重要内容更低权重。
使用中间语义张量c完成注意力权重的分配
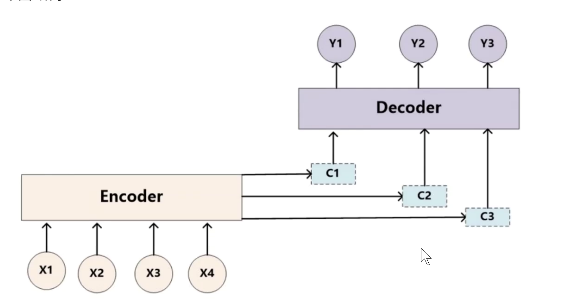
注意力是怎么得到的?
理解一:解码器会计算编码器所有输入词的隐藏状态和解码器上一时刻隐藏状态的相似度,,然后进行归一化(把计算分数归一化为权重),使用中间语义张量c分配注意力权重。
理解二:q、k计算注意力分数,然后使用归一化得到注意力权重,作用到v上(中间语义张量c分配权重)
注意力计算在TransFormer里面的计算:
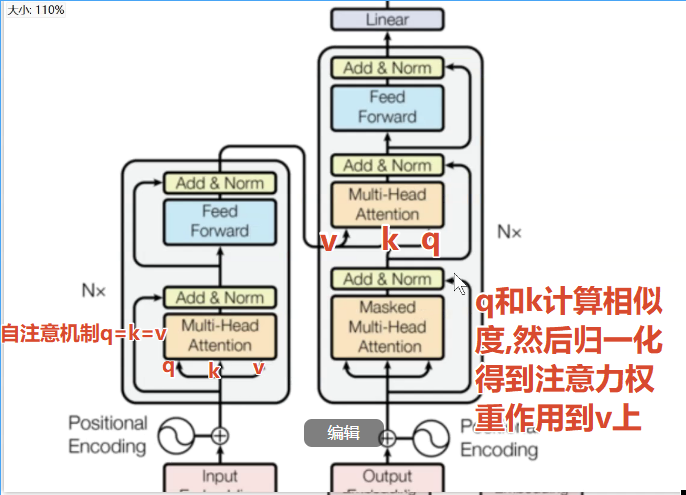
注意力计算在BiLSTM+Attention 里面的计算:

比如:
句子1:
猫 坐在 温暖的 沙发 上 晒太阳
问题:谁在晒太阳?
- 你不会每个字都看一样认真
- 自动重点盯:猫(核心)
- 弱化:温暖、上、晒太阳 这些次要词
放到 AI 里:AI 会给每个词打一个注意力分数:
- 猫:分数很高(重点关注)
- 沙发:中等
- 温暖、上:分数很低(忽略)
本质:权重分配,重要的多关注,不重要的少关注。
翻译句子2:
tom chasc jerry
在翻译不同部分的时候分配不同的权重
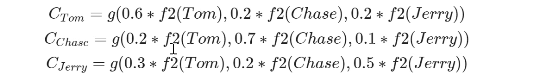
2.3代码实现关系抽取
整体实现思路
1、获取数据,例如通过人工数据标注或者第三方数据等。
2、对数据进行处理,构造训练数据
3、构建DataSet类
4、加载数据集 DataLoader
5、定义模型(embedding、线性层、CRF层)
6、初始化模型、loss、优化器、前向传播、反向传播、梯度更新
7、模型训练、评估
8、模型加载、测试
2.3.1项目架构

2.3.2config.py
import torch
import os
base_dir = os.path.dirname(os.path.abspath(__file__))
# print(f'base_dir-->{base_dir}')
class Config(object):
def __init__(self):
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# self.device = "mps"
self.train_data_path = os.path.join(base_dir, "data/train.txt")
self.test_data_path = os.path.join(base_dir, "data/test.txt")
self.rel_data_path = os.path.join(base_dir, "data/relation2id.txt")
self.embedding_dim = 128 # 句子序列的嵌入维度
self.pos_dim = 32 # 位置编码的嵌入维度
self.hidden_dim = 200
self.epochs = 50
self.batch_size = 32
self.max_len = 70
self.learning_rate = 1e-3
if __name__ == '__main__':
conf = Config()
print(conf.train_data_path)2.4数据处理
因为数据来自于开源数据集,提取的实体以及关系使用空格分割。但是由于原文本里面也有空格,会影响提取效果,此处限制提取的次数(例如提取前三个空格的实体内容)
2.4.1关系转换为id格式
处理前:
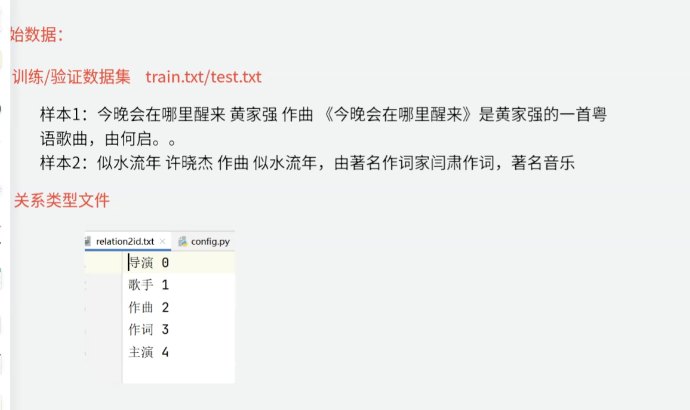
处理方法:遍历原始文本,限制切分次数,读取第三次切分的内容。然后把关系文件转化为字典,根据字典把提取出原文本的关系,然后使用tag2id的方式把标签转化为id。
处理后:

2.4.2 序列转换为id(属于bilstm_attention输入内容)
处理前:

处理方式:
便利原文内容,使用jieba分词,然后使用word2id的字典把分词以后的序列转换为索引序列
处理结果:

2.4.3 获取相对位置编码并转换为正值(属于bilstm_attention输入内容)
处理方式:
先拿到原始索引和主体索引,然后得到主实体、客实体相对位置编码

然后遍历编码最小值,相对编码加上编码最小值的相反数,这样就得到了正值,然后就可以使用正值找到这个实体对应的向量表示了。

2.4.4 小结
- 输入内容包含输入序列id、主实体、客实体相对位置编码这三项,都需要遍历原始文本得到
- 原始数据如何转变为最后的结果:

2.4.5代码实现
思路:
-
系转换为id:读取csv,按照空格切分,然后把读取到的数据转换为字典的格式
-
使用maxsplit=3限定切分三次(如果切分结果不是四个,那么直接返回数据有问题)
-
把切分得到的主实体、客实体、原文本保存到列表里面,然后使用列表【索引】的方式可以得到主实体和客实体
-
**如何获取主实体索引和客实体索引?**使用原文本.index(列表【主实体索引值】)方法可以得到主实体的索引,客实体索引获取的方式类似
-
申明新的列表分别存存储原始文本得到的字符、相对主实体编码、相对客实体编码
from P04_RE.Bilstm_Attention_RE.config import Config
from collections import Counterconf = Config()
1)获取关系类型字典
relation2id = {}
with open(conf.rel_data_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip().split(' ')
relation2id[line[0]] = int(line[1])print(f'relation2id-->{relation2id}')
2)处理数据,获取训练、测试数据集格式
def get_txt_data(file_path):
datas = [] # 存储每个文本中的字符
labels = [] # 存储每个文本中的标签id
positionE1 = [] # 存储每个文本中相对于实体1的位置
positionE2 = [] # 存储每个文本中相对于实体2的位置
entities = [] # 存储每个文本中的实体对,便于后续使用# 优化点:为了保证每种关系类型的数量均衡,需要统计每个关系类型的样本数量,让每种类型的数量不超过2000 count_dict = {k: 0 for k in relation2id} # 定义一个计数器,用于统计每种关系类型的数量,初始数量为0 with open(file_path, 'r', encoding='utf-8') as f: for line in f: # 1)对每个样本进行处理,按照空格进行切分,获取主实体、客实体、关系和原始文本。 line_list = line.strip().split(' ', maxsplit=3) # 需要使用maxsplit来指定最大的切割次数 # print(f'line_list-->{line_list}') if len(line_list) != 4: # 如果切割的结果不等于4,则跳过 continue if line_list[2] not in relation2id: # 如果关系不在关系字典中,则跳过 continue if count_dict[line_list[2]] >= 2000: # 如果当前关系类型的数量已经超过了2000,则跳过 continue # 2)将关系通过relation2id字典转成具体的数值,然后放到labels列表中。 labels.append(relation2id[line_list[2]]) # 3)将主实体和客实体放到子列表中,然后放到entities列表中。 entities.append([line_list[0], line_list[1]]) # 4)获取datas,positionE1和positionE2 sentence_str = line_list[3] # 获取主实体的索引 e1_index = sentence_str.index(line_list[0]) # 获取客实体的索引 e2_index = sentence_str.index(line_list[1]) # 定义3个空列表,分别存储每个文本中的字符、主实体的相对位置编码和客实体的相对位置编码。 sentence, position1, position2 = [], [], [] for index, word in enumerate(sentence_str): # ①遍历原始文本,将每个字符存储到一个子列表中,遍历完成后再存到datas列表中。 sentence.append(word) # ②先获取主实体的索引,在遍历过程中使用原始索引-主实体的索引,获取相对于主实体的位置编码,存储到一个子列表中,遍历完成后再存到positionE1列表中。 position1.append(index - e1_index) # ③使用相同的方式,获取客实体的相对位置编码。 position2.append(index - e2_index) # ④将3个子列表分别放到datas,positionE1和positionE2列表中。 datas.append(sentence) positionE1.append(position1) positionE2.append(position2) # print(f'datas-->{datas}') # print(f'positionE1-->{positionE1}') # print(f'positionE2-->{positionE2}') # print(f'entities-->{entities}') # print(f'labels-->{labels}') # 每处理完一个样本后,对对应的类型数量进行加一 count_dict[line_list[2]] += 1 # break return datas, labels, positionE1, positionE2, entities3)文本数字化表示处理,得到 word2id, id2word
def get_word_id(file_path):
datas, labels, positionE1, positionE2, entities = get_txt_data(file_path)
# 初始化一个列表,用来存储所有的去重之后的字符
vocab_list = ['PAD', 'UNK']
for sentence in datas: # 遍历所有的句子
for word in sentence: # 遍历句子中的每个字符
if word not in vocab_list: # 如果字符不在vocab_list中,则添加到vocab_list中
vocab_list.append(word)
# print(f'vocab_list-->{vocab_list}')# 生成word2id、id2word的字典 word2id = {word: i for i, word in enumerate(vocab_list)} id2word = {i: word for i, word in enumerate(vocab_list)} # print(f'word2id-->{word2id}') # print(f'id2word-->{id2word}') return word2id, id2word4)把句子 words 转为 id 形式,并自动补全或截断为 max_len 长度。
def sentence_padding(sequence, word2id):
'''
注意:在这个项目中,我们需要设置一个全局max_len。
:param sequence: 句子的字符列表 比如 ['《', '今', '晚', '会'...]
:param word2id: word2id字典
:return: 句子的id列表
'''
# 把word转成id
sequence_id = [word2id.get(word, word2id['UNK']) for word in sequence]
# 自动补全或截断为 max_len 长度
if len(sequence_id) >= conf.max_len:
sequence_id = sequence_id[:conf.max_len]
else:
sequence_id = sequence_id + [word2id['PAD']] * (conf.max_len - len(sequence_id))return sequence_id5)负值相对编码处理
def pos(origin_id):
if origin_id <= -70: # 如果小于-70,都按-70进行处理,则返回0
return 0
elif origin_id > -70 and origin_id < 70:
return origin_id + 70
elif origin_id >= 70: # 如果大于70,都按70进行处理,则返回140
return 1406)将id进行数字转换,防止为负数,而且进行句子长度的补齐或者截断
def position_padding(position):
# print(f'position-->{position}')
# 将负值转成正数
position = [pos(i) for i in position]
# 自动补全或截断为 max_len 长度
if len(position) >= conf.max_len:
position = position[:conf.max_len]
else:
position = position + [141] * (conf.max_len - len(position)) # 这里使用141作为填充值return positionif name == 'main':
# datas, labels, positionE1, positionE2, entities = get_txt_data(conf.train_data_path)
# # print(f'labels-->{labels}')
# print(Counter(labels))get_word_id(conf.train_data_path)
2.4.6相对位置编码处理
注意:在这个项目中,我们需要设置一个全局的max_len,原因如下:
因为这个模型用到了相对位置编码,这个相对位置编码需要进行embedding。它在进行embedding的时候,需要设置embedding层的vocab_size(这里指的是有多少个相对位置编码,而不是字符的数量),这个值会在构建模型时写死(这个值的范围是(-最大值+1)~最大值-1))!所以,一旦写死之后,句子的最大长度也就确定了(写死以后相对位置索引确定下来了,句子长度自然也就确定下来了),所以后续在使用时,就不能超过这个句子的最大长度。因为一旦超过之后,超过的位置编码就没有办法进行embedding查表了。
所以这里需要根据样本的情况,指定句子的最大长度,然后在使用时,将样本统一成最大长度。经过统计,这里 max_len为70。

查询相对位置索引的向量化表示不能使用负值查询,所以要转换为正值,下面是转换方法:

2.4.7dataloader.py
import torch
from torch.utils.data import Dataset, DataLoader
from P04_RE.Bilstm_Attention_RE.config import Config
from P04_RE.Bilstm_Attention_RE.utils.process import get_txt_data, get_word_id, sentence_padding, position_padding
conf = Config()
word2id, id2word = get_word_id(conf.train_data_path)
# 1.构建Dataset类
class MyDataset(Dataset):
def __init__(self, file_path):
super(MyDataset, self).__init__()
self.datas, self.labels, self.positionE1, self.positionE2, self.entities = get_txt_data(file_path)
def __len__(self):
return len(self.datas)
def __getitem__(self, index):
return self.datas[index], self.labels[index], self.positionE1[index], self.positionE2[index], self.entities[index]
# 2.构建自定义函数collate_fn()
def collate_fn(batch_data):
# print(f'batch_data-->{batch_data}')
# 1)获取batch_data中的数据
sequences = [data[0] for data in batch_data]
labels = [data[1] for data in batch_data]
positionE1 = [data[2] for data in batch_data]
positionE2 = [data[3] for data in batch_data]
entities = [data[4] for data in batch_data]
# 2)使用word2id字典,将字符转成id, 同时将样本长度进行统一
sequence_ids = [sentence_padding(sequence, word2id) for sequence in sequences]
# print(f'sequence_ids-->{sequence_ids}')
# 3)使用负值转成正数的函数,将负值转成正数,同时将样本长度进行统一
positionE1_ids = [position_padding(position) for position in positionE1]
positionE2_ids = [position_padding(position) for position in positionE2]
# 4)将数据转成张量,并且移动到GPU上
datas_tensor = torch.tensor(sequence_ids, dtype=torch.long).to(conf.device)
labels_tensor = torch.tensor(labels, dtype=torch.long).to(conf.device)
positionE1_tensor = torch.tensor(positionE1_ids, dtype=torch.long).to(conf.device)
positionE2_tensor = torch.tensor(positionE2_ids, dtype=torch.long).to(conf.device)
return datas_tensor, labels_tensor, positionE1_tensor, positionE2_tensor, entities
# 3.构建get_loader_data函数,获得数据迭代器
def get_data_loader():
# 训练集
train_dataset = MyDataset(conf.train_data_path)
train_dataloader = DataLoader(train_dataset,
batch_size=conf.batch_size,
shuffle=False, # 在写代码的时候,需要把shuffle设置为 Fasle; 在训练时,需要把shuffle设置为 True
collate_fn=collate_fn,
drop_last=True
)
# 验证集
test_dataset = MyDataset(conf.test_data_path)
test_dataloader = DataLoader(test_dataset,
batch_size=conf.batch_size,
shuffle=False,
collate_fn=collate_fn,
drop_last=True
)
return train_dataloader, test_dataloader
if __name__ == '__main__':
train_dataloader, test_dataloader = get_data_loader()
# for x in train_dataloader:
# print(f'x-->{x}')
# break
for datas_tensor, labels_tensor, positionE1_tensor, positionE2_tensor, entities in train_dataloader:
print(f'datas_tensor-->{datas_tensor.shape}')
print(f'labels_tensor-->{labels_tensor.shape}')
print(f'positionE1_tensor-->{positionE1_tensor.shape}')
print(f'positionE2_tensor-->{positionE2_tensor.shape}')
print(f'entities-->{entities}')
break2.5 BiLSTM_Attention模型架构
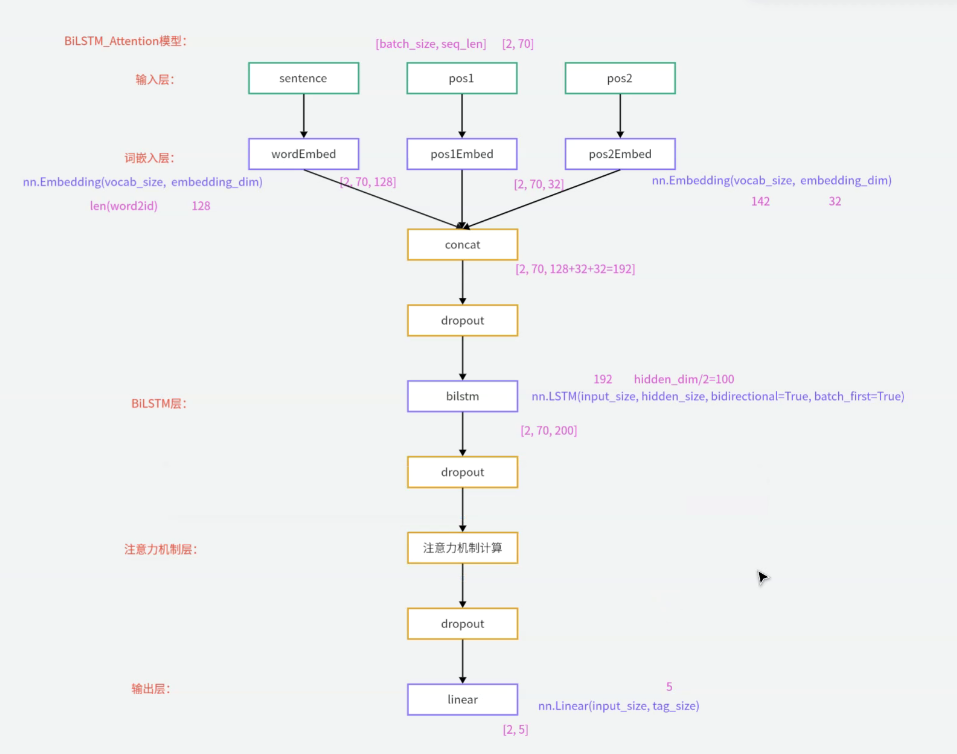
架构解析:
输入包括三个部分:序列、主实体位置编码、客实体位置编码
序列、编码分别经过嵌入层处理:
词嵌入层:
维度表示:【vocab_size(词表大小),embedding_dim】
输入:【batch_size,seq_len】
输出:【batch_size,seq_len,embedding_dim】(把每个词转换为向量表示)
转化过程:查表!不是计算!
假设:
batch_size = 2(2 句话)
seq_len = 3(每句 3 个词)
vocab_size = 128(词表 128 个词)
embedding_dim = 128(每个词转 128 维向量)
输入是:
plaintext
句子1:[10, 20, 5] 句子2:[3, 88, 12]形状:
[2, 3]Embedding 层是一个大表:
plaintext
编号0 → [0.1, 0.3, ... 128个数字] 编号1 → [0.5, 0.2, ... 128个数字] ... 编号10 → [0.7, 0.9, ... 128个数字] <-- 我们要找它 ... 编号127 → [0.2, 0.5, ... 128个数字]转化方式:
输入里的每个数字 → 去表里查对应的一行向量
- 最终输出形状怎么来的?
输入:
[2句话,3个词]每个词 → 查成
128维向量所以输出变成:
[2,3,128]也就是:batch_size, seq_len, embedding_dim
位置嵌入层:把每个位置编码转换为向量表示【vocab_size(位置序列大小),embedding_dim】序列向量表示:【batch_size,seq_len(限制的最大长度),embedding_dim】
相对位置编码向量表示:【batch_size,seq_len,embedding_dim】
因为BiLSTM只能输入一个,需要把三个转换结果拼接起来,BiLSTM是双向模型,所以真是的hidden_size需要除以2才是hidden_size真正的隐藏大小
BiLSTM层输入:拼接后的序列+主实体位置编码+客实体的相对位置编码
输出:【batch_size,seq_len,hidden_size*2(每个词的上下文向量)】
注意力机制层输入:【batch_size,seq_len,hidden_size*2】
输出:【batch_size,hidden_size*2】
给 seq_len 个词分别算权重,加权求和,把 70 个向量 合并成 1 个向量