一句话介绍
结合检索信号与 logit 信号生成草稿的投机解码方法,在各 benchmark 上一致实现 2 倍加速,超越所有 training-free 基线,比需要额外训练的 EAGLE-3 还快
- 论文标题:RACER: Retrieval-Augmented Contextual Rapid Speculative Decoding
- 论文地址 :http://arxiv.org/pdf/2604.14885
- 作者背景:武汉大学、上海交通大学
- 代码地址 :https://github.com/hkr04/RACER
动机
大模型做自回归解码时,每步只生成一个 token,而且前一个 token 是后一个 token 的输入,形成严格的链式依赖,需要做大量串行的前向运算,速度很慢
投机解码(Speculative Decoding) 是目前最有效的加速策略之一。它的核心思路是:
- 草稿阶段:一个快速的"草稿生成器"(drafter)先预测接下来的多个 token 候选
- 验证阶段:目标模型一次性并行验证这些候选(只需要一次前向计算)
当前常见的投机解码方法可分为两类:
模型驱动:训练一个轻量级辅助模型来当草稿生成器。代表方法有 Medusa(在目标模型顶部接多个预测头)、EAGLE 系列(利用目标模型的中间特征训练一个 Transformer 层)。效果好,但代价是额外的训练成本、显存占用和模型对齐问题。
免模型(model-free):不需要额外模型,直接从推理过程中挖掘信号。这里又细分为:
- 检索型(PLD, REST, SAM Decoding):在已生成的上下文或外部语料中查找 n-gram 精确匹配,把匹配到的后续 token 作为草稿
- Logits 型(Token Recycling, LogitSpec):利用目标模型每步产生的概率分布(logits),从 top-k 候选中构建草稿树
模型每生成一个 token,都会输出覆盖整个词表的概率分布------我们通常只取最高概率的那个 token,但其余 top-k 候选同样蕴含有用信息。Logits 型方法把每步的 top-k 候选保存为一张邻接矩阵("token A 后面最可能跟哪些 token"),然后从中展开草稿树。
两种免模型方法各有明显短板:检索型只在有精确匹配时才有效,遇到新内容就束手无策;Logits 型虽然不依赖匹配、任何时候都能给出候选(概率分布永远存在),但它只有模型内部的统计估计,缺乏来自实际上下文的结构性信号
解决方案
核心思想
作者提出 RACER 方法 (Retrieval-Augmented Contextual Rapid Speculative Decoding),它的洞察简洁而直接:检索提供"已见信息"(seen information),logits 提供"未见信息"(unseen information),两者天然互补,应该被统一起来
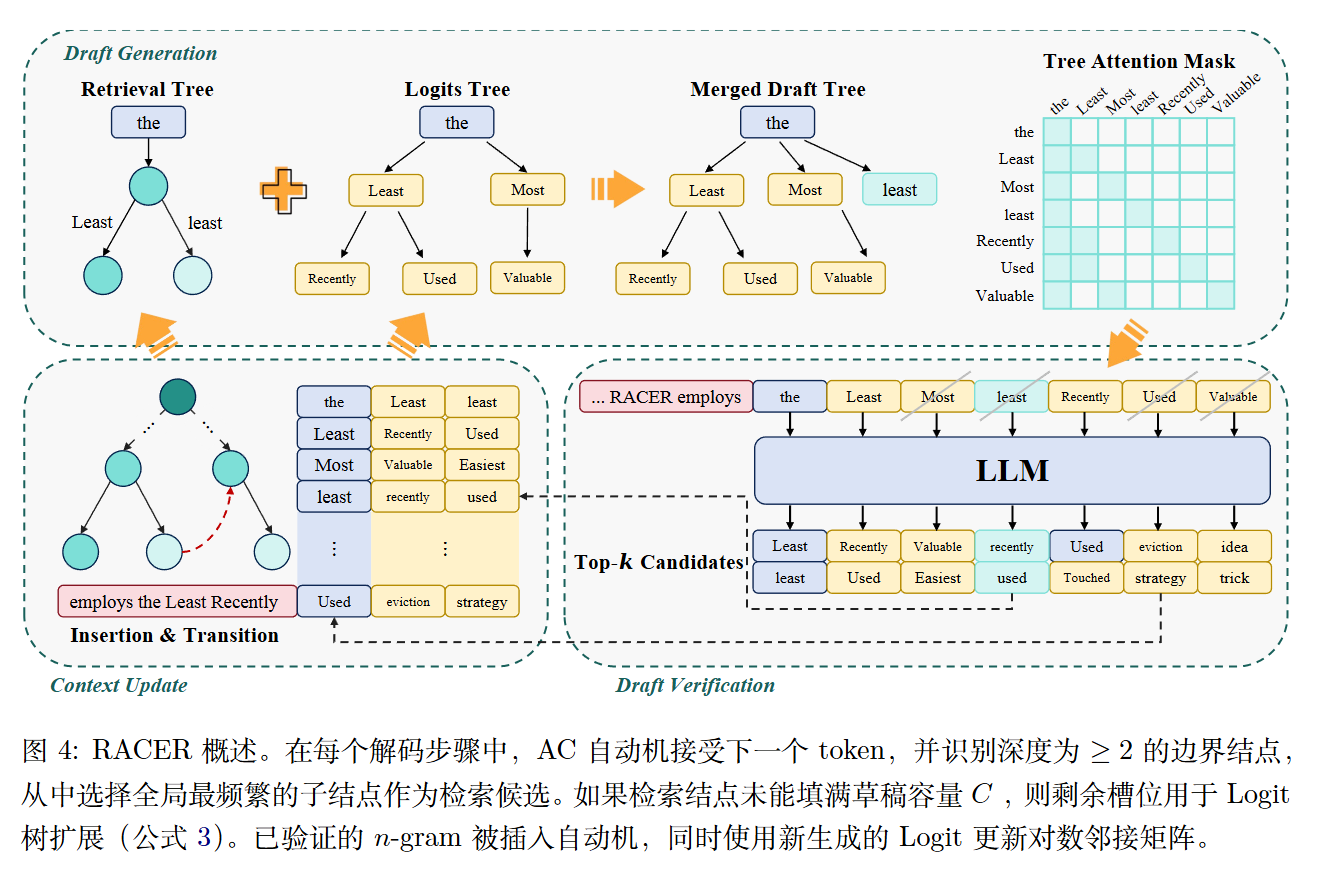
具体来说,RACER 同时维护两棵草稿树:
- Logits Tree:基于历史 logits 的 top-k 邻接矩阵,通过 BFS 展开构建
- Retrieval Tree:基于 AC 自动机的 n-gram 检索,通过频率排序展开
两棵树合并成一棵统一的草稿树,交给目标模型一次性验证。整个过程不需要训练、不引入额外模型、内存开销极低,真正做到即插即用。
Logits Tree 构建
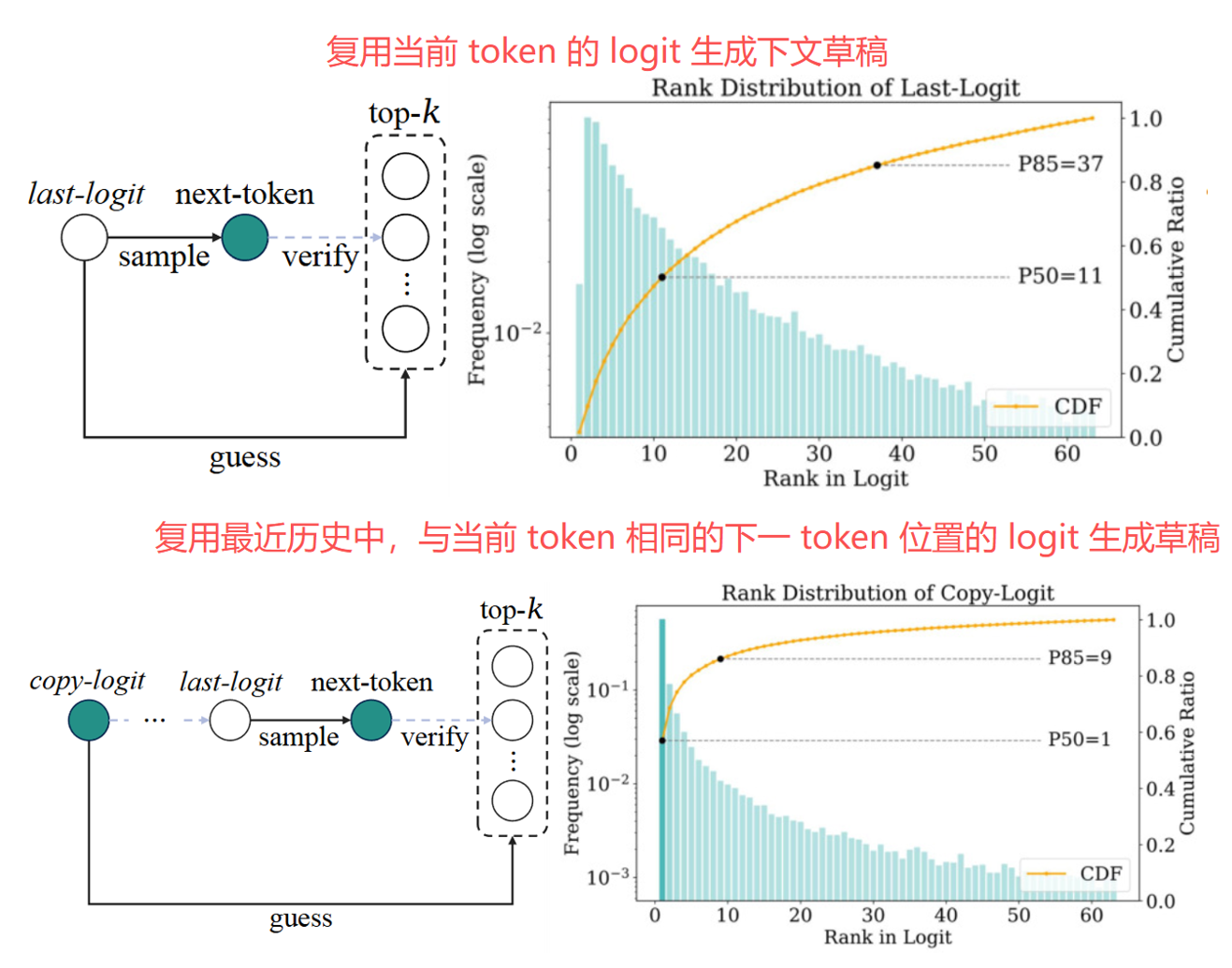
如何在只有当前位置的 logits 的情况下,近似出后续的概率分布?RACER 对比了两种策略:
- Last-Logit(直接复用当前步):假设相邻位置的分布变化不大,直接把当前步的 logits 当作下一步的近似。好比说"刚才模型觉得 A 最可能,那下一步也先按这个分布来猜"
- Copy-Logit(复用历史同 token) :如果当前生成的 token 是 X,就去历史中找最近一次也生成了 X 的位置,把那个位置下一步的真实 logits 借过来用
在 Vicuna-7B + Spec-Bench 上,固定只展开一层草稿,取 top-63 个候选 token,然后让目标模型验证,结果如下:
| 策略 | MAT(平均接受 token 数) | 50% 覆盖所需排名 | 85% 覆盖所需排名 |
|---|---|---|---|
| Last-Logit | 1.57 | Rank 11 | Rank 37 |
| Copy-Logit | 1.87 | Rank 1 | Rank 9 |
Copy-logit 展示出极强的头部集中效应:在所有被接受的草稿 token 中,有 50% 恰好就是排名第 1 的候选,前 9 名就覆盖了 85%。相比之下,last-logit 需要看到 Rank 11 才覆盖 50%,分布更分散
基于上述头部集中效应,RACER 设计了一种自适应的树展开策略,简单来说就是排名靠前的子节点获得更多的展开预算(宽度),排名靠后的预算指数递减,形成上层宽、下层窄的金字塔结构
Retrieval Tree 构建
AC 自动机
已有的检索型方法(如 REST)常使用后缀数组做子串匹配,原理是将文本的所有后缀排序建索引,从而支持高效的任意子串查找。比如对字符串 "abcab",它的后缀有 "abcab", "bcab", "cab", "ab", "b",排序后建立索引,就能快速查找任意子串出现的位置
但在持续生成的场景中,它有一个致命问题:空间随上下文长度线性增长,没有淘汰机制(增删操作的代价较高),长文本生成时内存会不断膨胀
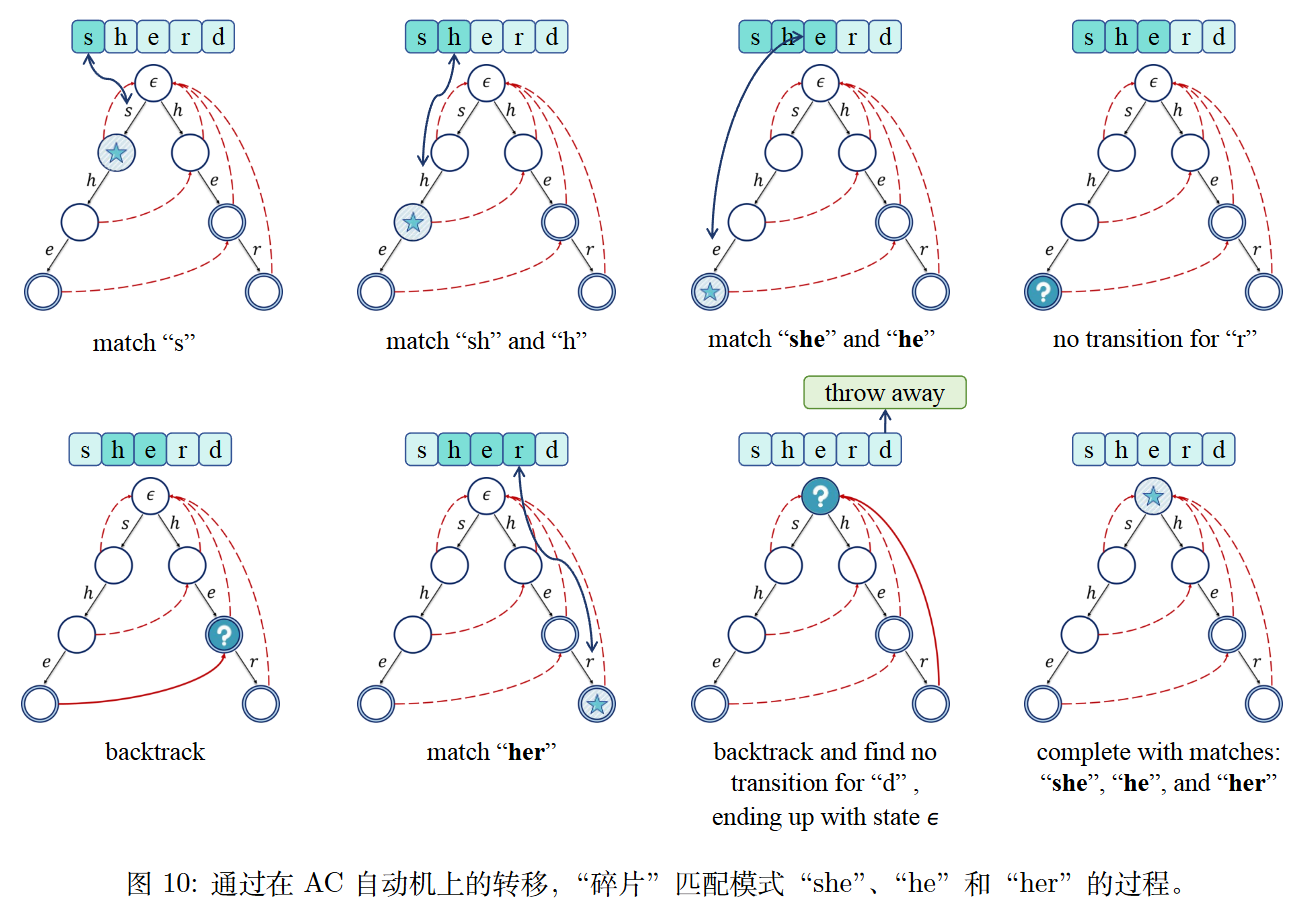
RACER 选择了 Aho-Corasick(AC)自动机作为检索结构,其本质上是一棵字典树(trie / 前缀树),额外维护了失配链接:当前路径匹配失败时,能快速跳转到最长合法后缀对应的位置继续匹配,避免从头开始。相比之下,字典树天然支持固定容量 + 节点淘汰,更适合长文本场景
LRU 淘汰
AC 自动机中存储的是已生成文本中的 n-gram 模式------比如生成过"人工智能技术"就会存入 人工, 智能、智能, 技术 等节点。随着不断生成新文本,新 n-gram 需要插入,但节点容量有上限。RACER 额外使用一个 LRU 双向链表来管理这个固定容量的缓存,并通过一张 hash map 来记录链表结点与树结点之间的对应关系。LRU 链表支持 3 种操作:
- Touch(标记访问):匹配过程中经过某个节点时,将其移到 LRU 链表头部,标记为"最近使用"
- Insert(插入):新 n-gram 沿字典树路径逐层插入;如果容量已满,淘汰最久未访问的叶子节点,把它重置后重新分配
- Evict(淘汰):只淘汰叶子节点(因为 Touch 时会同时标记所有祖先,父节点永远比子节点"新鲜"),不会破坏树结构
- 匹配:沿着目标序列在 trie 中游走,每经过一个结点都执行 Touch;匹配失败时,沿着树的 failure link 回退到最长合法后缀,并 Touch 它的所有祖先,标记为已访问,直到完全匹配或回退到根结点
- 插入:要插入某个 n-gram 时,从 root 出发找到其前缀结点,创建新的边并 Touch 新结点;如果容量已满,找到链表尾部的结点执行 Evict
这实际上利用了自然语言的 Zipf 长尾分布 特性:少数 n-gram 反复出现(如 def、return、self.),而绝大多数 n-gram 只出现一两次。淘汰这些罕见模式几乎不会损失匹配能力。实验表明,约 10,000 个节点就足以达到最佳效果(几十 MB 内存),再增加也无显著收益
以上所有操作都在 O(1) 或 O(d) 时间内完成(d 为 n-gram 长度,通常 ≤ 10),几乎不增加推理延迟
基于频率的候选选择
检索到匹配后,RACER 不是简单取最长匹配的后续 token,而是:
- 收集所有匹配位置(包括通过失配链接找到的短匹配)的后续子树
- 按频率排序所有候选
- 选择出现最频繁的 top-k 候选
这确保了检索草稿兼具多样性和统计可靠性
融合策略
给定固定的草稿容量 C(默认 64),RACER 的集成策略非常直接:
- 检索优先:先按频率选取检索候选(因为来自精确匹配,可靠性高)
- Logits 补充:剩余容量分配给 Logits Tree 做 BFS 展开
- Trie 合并:两棵树通过字典树合并成统一草稿树
- 正向反馈:检索匹配到的上下文会刷新 logits 的邻接矩阵,使后续 logits 预测更准确
消融实验清晰地展示了两个组件的互补性:
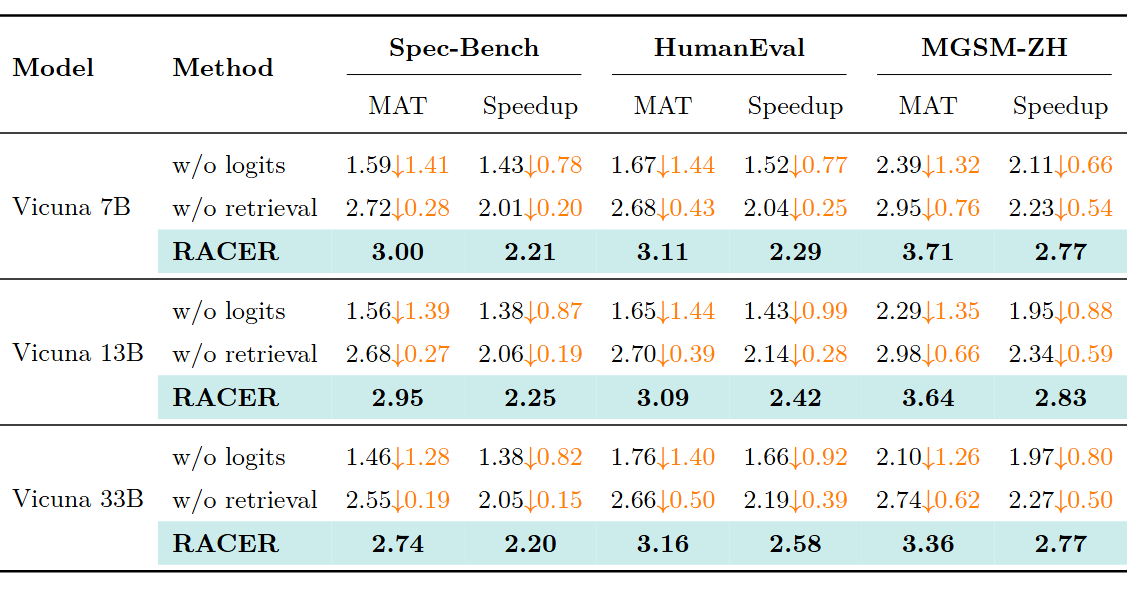
去掉 Logits 的影响最大(MAT 下降超过 1),说明 logits 是投机扩展的主力。去掉 Retrieval 的影响在推理任务上尤为明显(MGSM-ZH 下降 0.7),说明检索在重复模式丰富的场景中提供了关键的结构性引导
实验结果
RACER 在三个基准上进行了全面评估,覆盖通用、代码和推理任务。
与 training-free 方法对比
在 Vicuna 系列(7B/13B/33B)上,RACER 全面超越 PLD、REST、Token Recycling、LogitSpec:
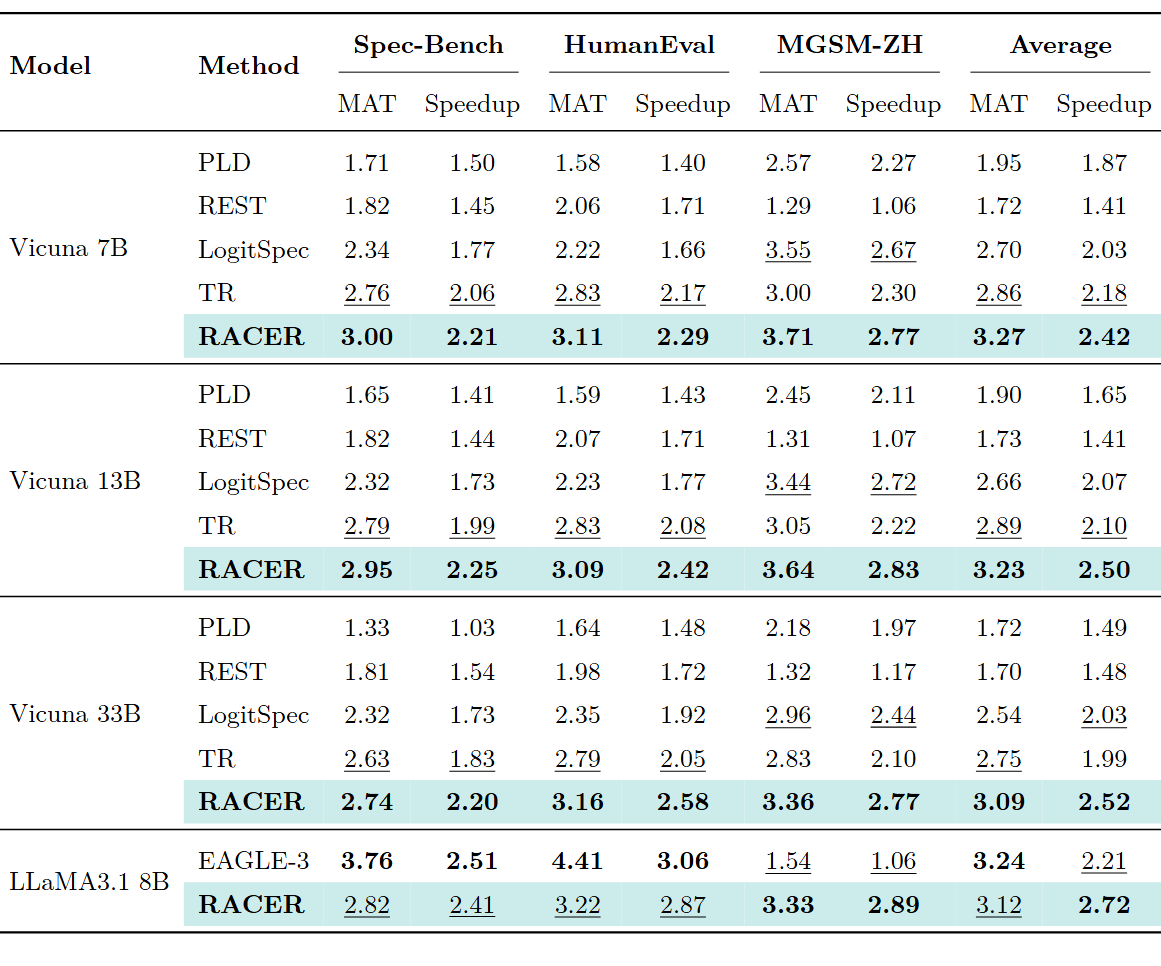
值得注意的是,RACER 的优势随模型规模增大而扩大:33B 上领先 TR 达 0.53x。
与 EAGLE-3 对比
EAGLE-3 是当前最强的 model-based 方法,需要额外训练草稿模型。虽然 EAGLE-3 在 MAT 上通常更高(毕竟有专门训练的模型),但 RACER 在端到端加速比上经常更优:
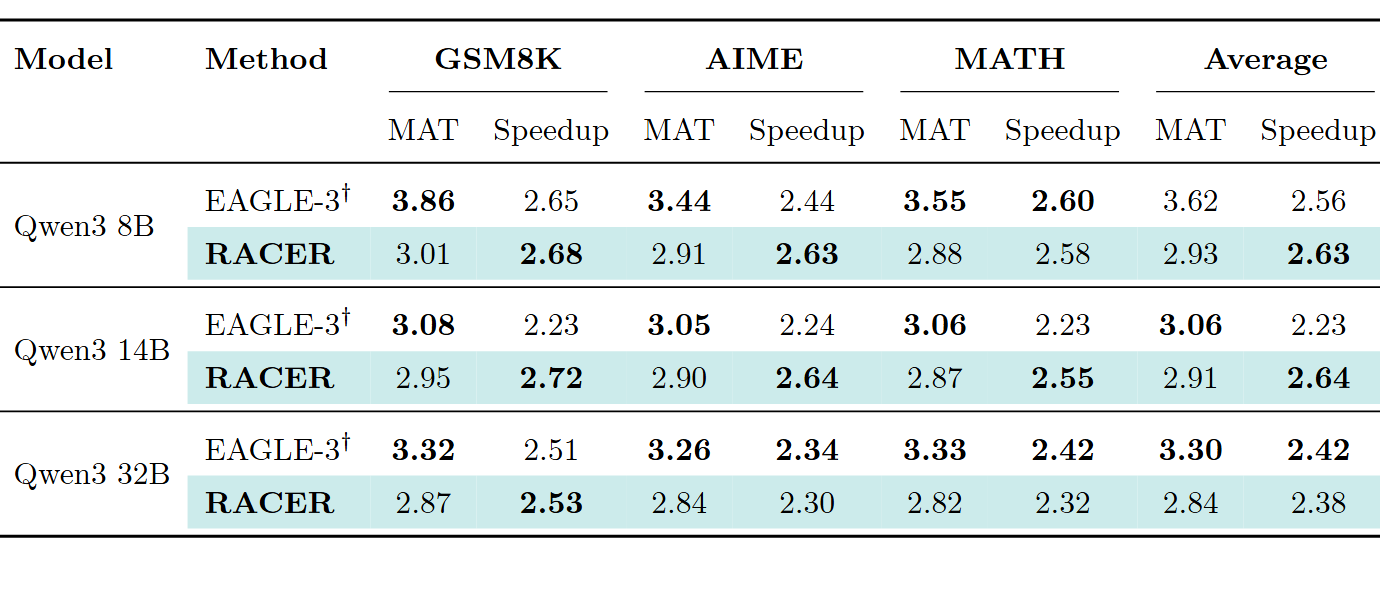
原因在于:
- EAGLE-3 的额外草稿模型需要计算开销,模型越大越明显
- EAGLE-3 在中文推理(MGSM-ZH)上表现不佳(Qwen3-8B 仅 0.86x),可能因训练数据分布偏英文
RACER 因为不依赖任何训练数据,在各语言、各任务上都保持稳定
推理模型上的表现
在 OpenPangu-7B 和 Qwen3 系列(8B/14B/32B)等推理模型上,RACER 同样表现出色。推理模型通常生成更长的输出(包含大量 <think> 思考链),这为检索组件提供了丰富的重复模式,RACER 的加速效果尤为显著。
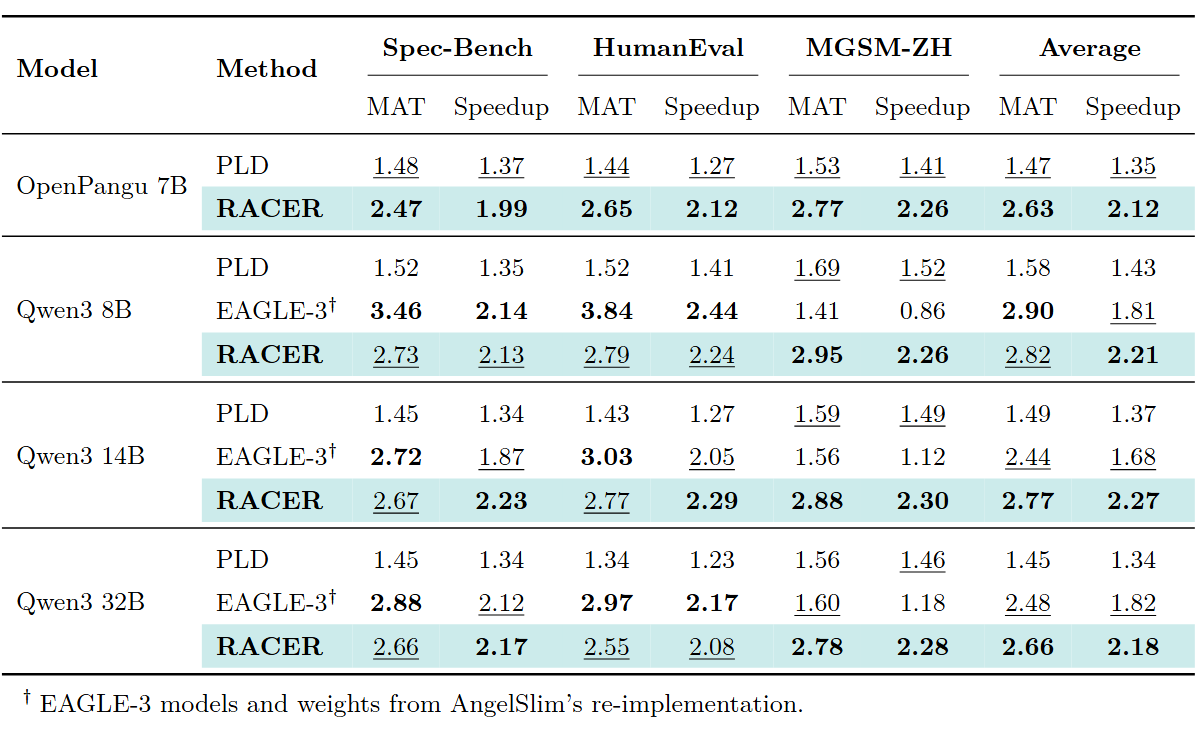
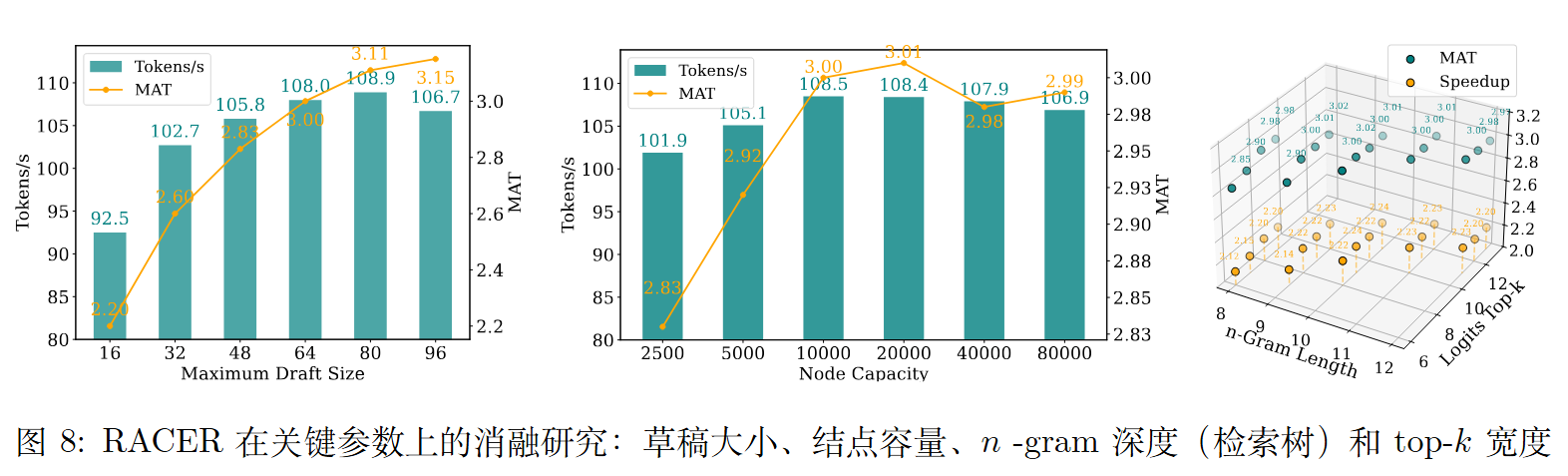
参数鲁棒性
RACER 对超参数不敏感:
- 草稿容量:16→64 稳步提升,64 后饱和
- AC 自动机容量:10K~20K 节点最佳,更大无明显收益
- n-gram 深度 × top-k 宽度:在 (9-11) × (8-10) 范围内性能平坦
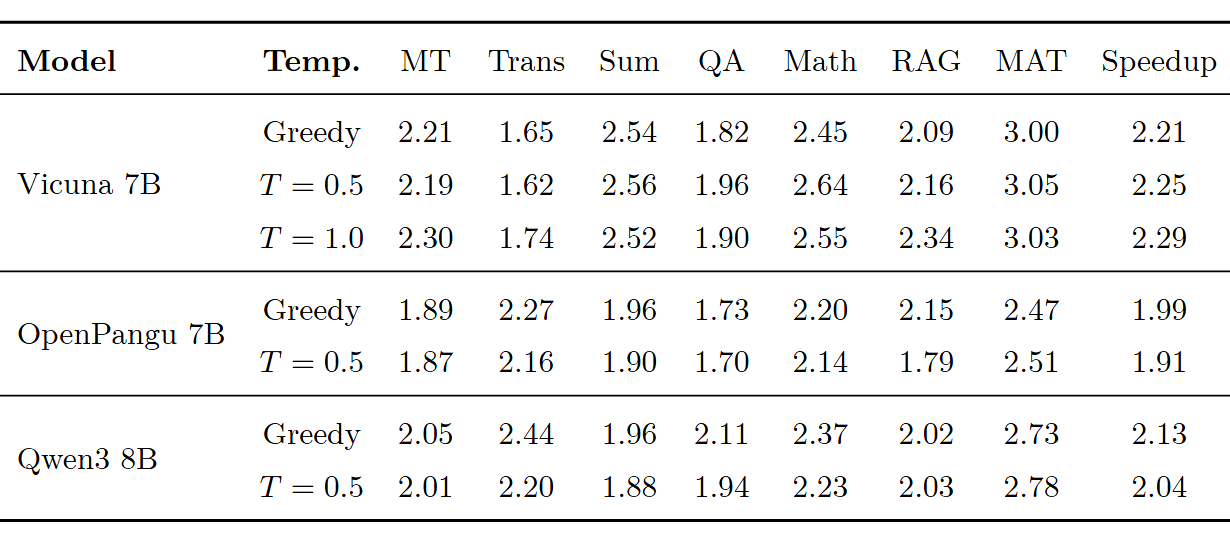
采样温度鲁棒性
在不同采样温度(greedy, T=0.5, T=1.0)下,RACER 的加速比几乎不变。这意味着在实际部署中不需要为不同的解码策略重新调参。
时间开销分析
在 Vicuna-7B + HumanEval 的案例研究中,草稿生成、logits 更新、检索更新的时间开销加在一起,相比模型前向计算(prefill + verification)可以忽略不计。RACER 的加速完全来自减少目标模型的调用次数,不引入显著的额外开销