LangChain是什么
LangChain是一个开发LLM相关业务功能的集大成者,是一个Python的第三方库,提供了各种功能的API。
提供:
- 提示词优化的相关功能API
- 调用各类模型的功能API
- 会话记忆的相关功能API
- 各类文档管理分析的功能API
- 构建Agent智能体的相关功能API
- 各类功能链式执行的能力
LangChain是后续学习RAG开发的主力框架
LangChain环境部署
python
pip install langchain langchain-community langchain-ollama dashscope chromadb- langchain: 核心包
- langchain-community: 社区支持包,提供了更多的第三方模型调用(我们用的阿里云千问模型就需要这个包)
- langchain-ollama: Ollama支持包,支持调用Ollama托管部署的本地模型
- dashscope: 阿里云通义千问的Python SDK
- chromadb: 轻量向量数据库(后续使用)
什么是RAG
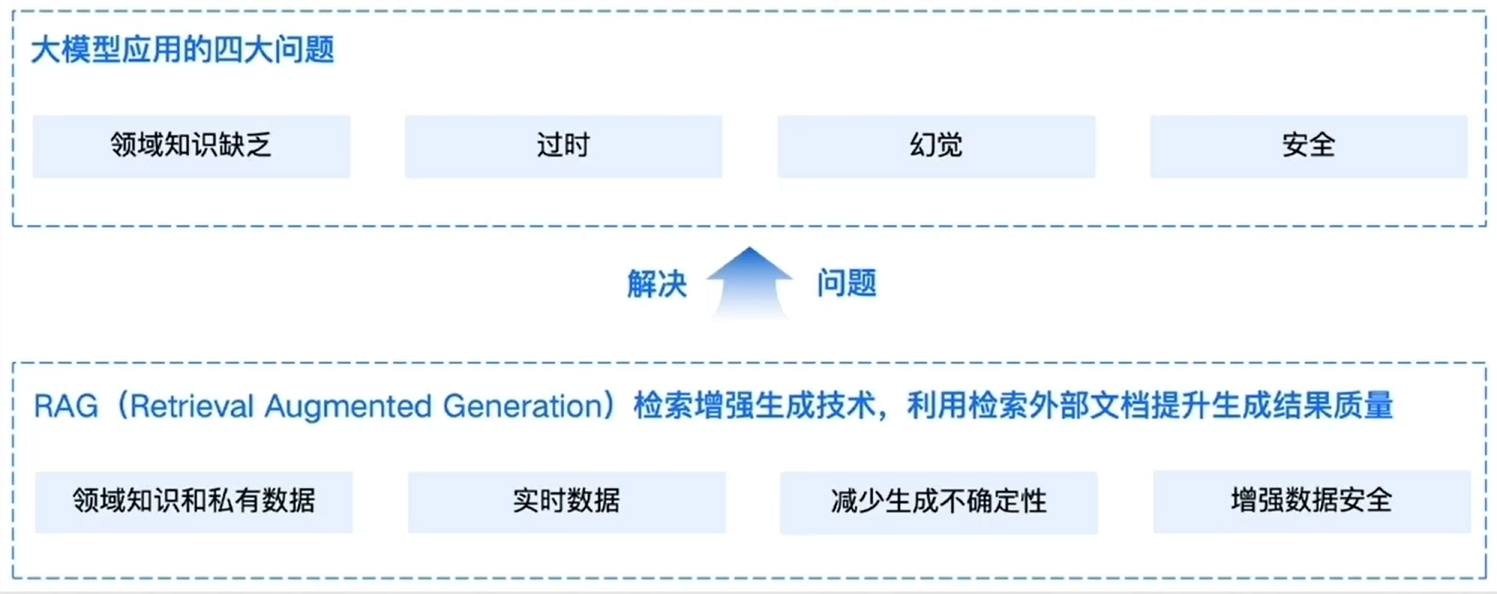
通用的基础大模型存在一些问题:
- LLM的知识不是实时的,模型训练好后不具备自动更新知识的能力,会导致部分信息滞后
- LLM领域知识是缺乏的,大模型的知识来源于训练数据,这些数据主要来自公开的互联网和开源数据集,无法覆盖特定领域或高度专业化的内部知识
- 幻觉问题,LLM有时会在回答中生成看似合理但实际上是错误的信息
- 数据安全性
解释:
RAG(Retrieval-Augmented Generation)即检索增强生成,为大模型提供了从特定数据源检索到的信息,以此来修正模型的答案。可以总结为一个公式:RAG = 检索技术 + LLM 提示。
RAG工作流图解
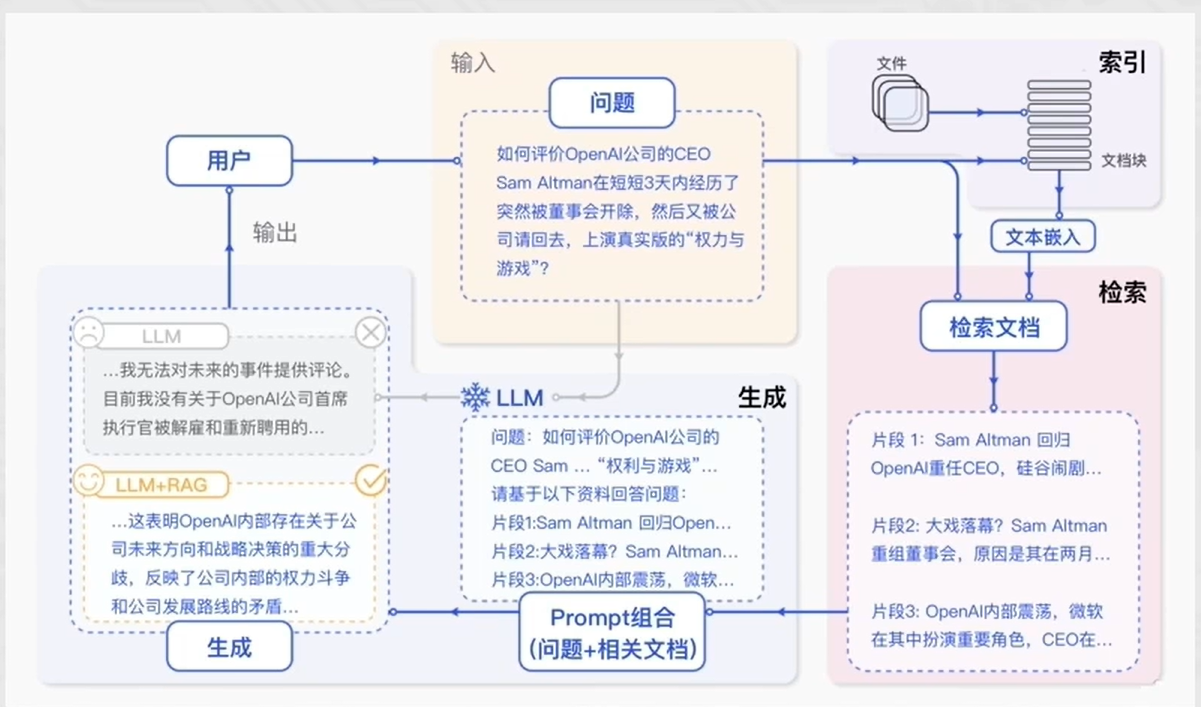
RAG标准流程:
过程:
- 形成离线文档,知识库,将知识库提取,形成向量数据库
- 用户提问先进行向量检索,相似度匹配,然后将匹配的内容和原始问题一起给大模型
- 然后大模型进行处理分析,总结出来回答
总结:
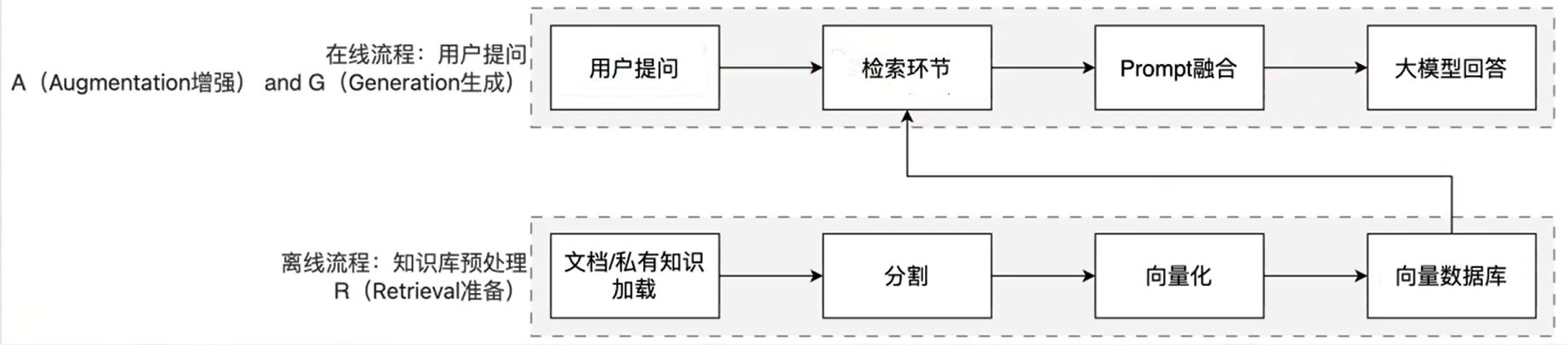
RAG有两条线:
- 离线准备,需要一直不停的去维护知识库
- 在线提问,用户提问,提问时不直接问大模型,先去向量数据库寻找,将寻找出来的资料融合,再问大模型
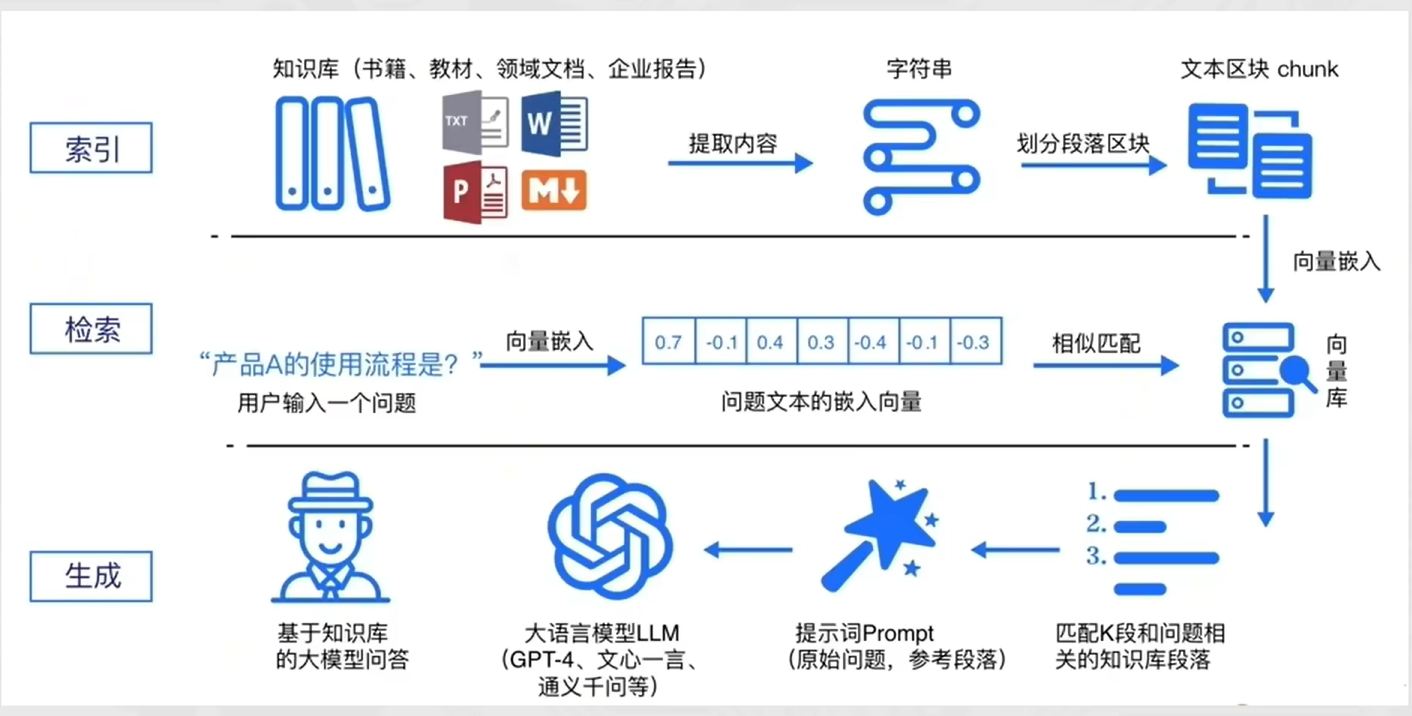
RAG 标准流程由索引(Indexing)、检索(Retriever)和生成(Generation)三个核心阶段组成。
详细流程:
-
索引阶段,通过处理多种来源多种格式的文档提取其中文本,将其切分为标准长度的文本块(chunk),并进行嵌入向量化(embedding),向量存储在向量数据库(vector database)中。
- 加载文件
- 内容提取
- 文本分割,形成chunk
- 文本向量化
- 存向量数据库
-
检索阶段,用户输入的查询(query)被转化为向量表示,通过相似度匹配从向量数据库中检索出最相关的文本块。
- query向量化
- 在文本向量中匹配出与问句向量相似的top_k个
-
生成阶段,检索到的相关文本与原始查询共同构成提示词(Prompt),输入大语言模型(LLM),生成精确且具备上下文关联的回答。
- 匹配出的文本作为上下文和问题一起添加到prompt中
- 提交给LLM生成答案
RAG核心价值
- 解决知识实效性问题:大模型的训练数据有截止时间,RAG 可以接入最新文档(如公司财报、政策文件),让模型输出 "与时俱进"。
- 降低模型幻觉:模型的回答基于检索到的事实性资料,而非纯靠自身记忆,大幅减少编造信息的概率。
- 无需重新训练模型:相比微调(Fine-tuning),RAG 只需更新知识库,成本更低、效率更高。