
🎈主页传送门:良木生香
🔥个人专栏:《C语言》 《数据结构-初阶》 《程序设计》《鼠鼠的C++学习之路》
🌟人为善,福随未至,祸已远行;人为恶,祸虽未至,福已远离

前言:在上一篇文章中,讲了String类在日常使用时会用到的大部分接口,那么这篇文章就对接口的讲解进行一个收尾,等到下一篇文章就开始对String类进行自己的模拟实现。
目录
3、find_first_of/find_last_of/find_first_not_of/find_last_not_of
今天要讲解的接口如下:
话不多说,我们直接开始吧
1、c_str/copy


这两个接口实际上功能非常相似,但是在拷贝的处理上又有一些不同:
c_str的作用是将一串string类的字符串转换成C语言风格的字符串,也就是字符数组,但实际上在日常使用中使用率并不是很高:
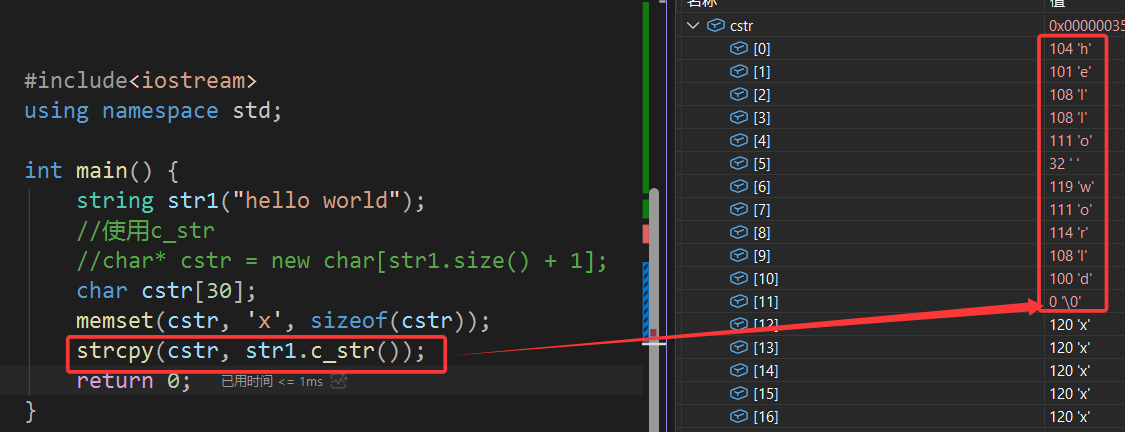
可见在字符串的最后加上了经典的'\0'。但是copy的使用方式又有点不同:
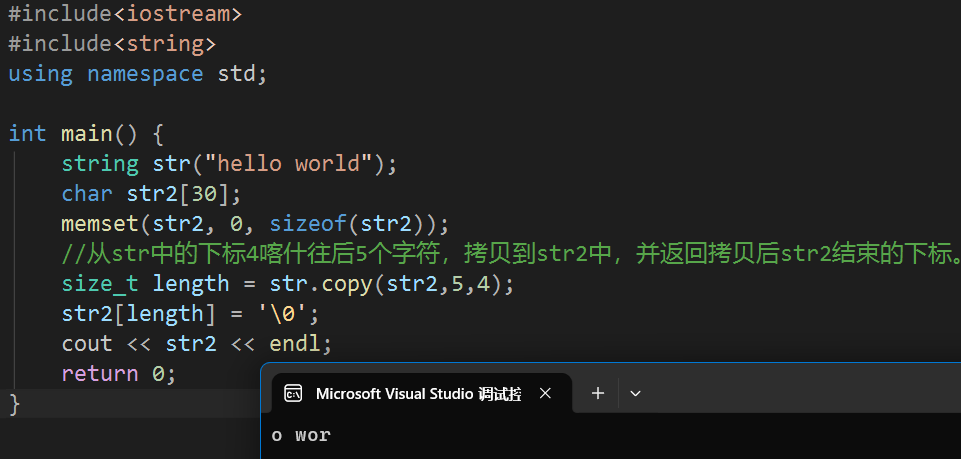
这两个说实话都不怎么用得到,以为用起来实在是不方便多少。
但是接下来这个就会经常会用到了"
2、substr/find/rfind

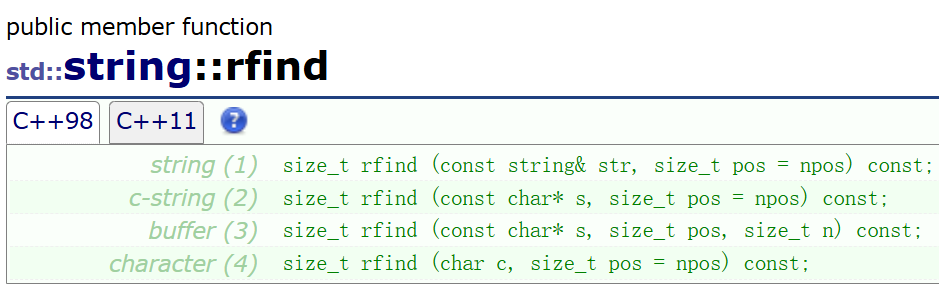
substr顾名思义就是在一串字符串中找出符合标准的字串并将字串作为新的字符串返回。在这里有一个很有意思的小练习---将网址分割:
我们知道,网址由三部分组成:协议+域名+内容:例如:
在这段网址中,就是由"https"+"legacy.cplusplus.com"+"reference/string/string/substr"组成的,想要实现三段内容的分解,就要灵活的运用substr:
cpp
#include<iostream>
using namespace std;
int main() {
string URL("https://legacy.cplusplus.com/reference/string/string/substr/");
//现在对协议进行分割,首先要先找到:
size_t pos_Colon = URL.find(':');
if (pos_Colon != string::npos) { //说明找到了
string Colon = URL.substr(0, pos_Colon);
cout << Colon << endl;
//现在对域名进行查找:
size_t pos_domain = URL.find('/',pos_Colon+3);
if (pos_domain != string::npos) { //说明找到了/
string domain = URL.substr(pos_Colon + 3, pos_domain-(pos_Colon+3));
cout << domain << endl;
//现在对内容进行查找:
size_t pos_txt = URL.rfind('/');
if (pos_txt != string::npos) { //说明/找到了
string txt = URL.substr(pos_domain, pos_txt - pos_domain);
cout << txt << endl;
}
}
}
return 0;
}整体的思路就是,先确定分隔点,再用find()函数找到分割点的下标,再用substr用起始位置往后分割点下标长度的位置将字串分割出来,就得到了协议,域名和内容。
我们也可以用substrl来输出文件后缀名:
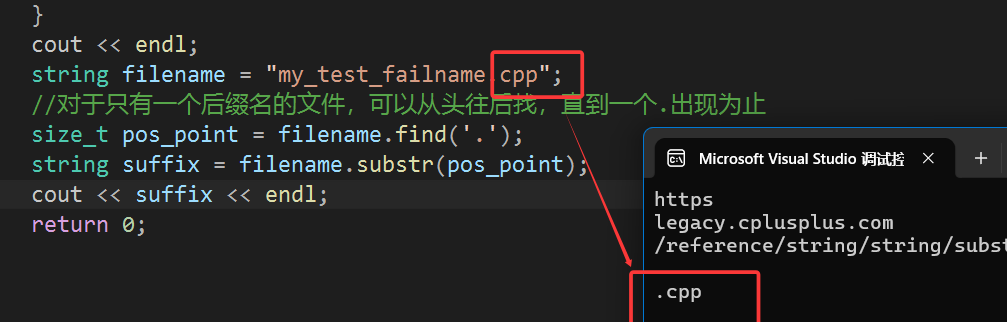
这种方法通常只适用于有单个后缀名的文件,如果有多个后缀名就不能这么使用了,否则:
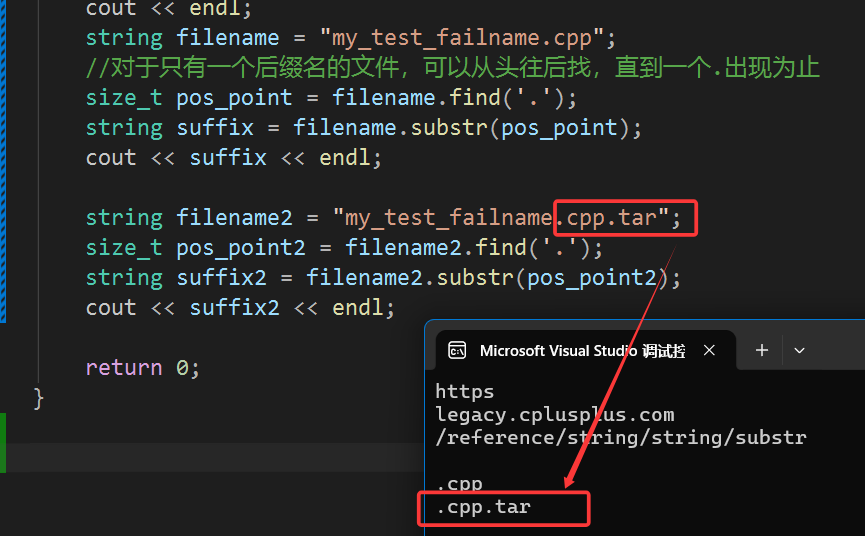
这样就会将所有后缀名全部打印出来,但是我们想要的只有一个,该怎么办呢?
使用rfind():
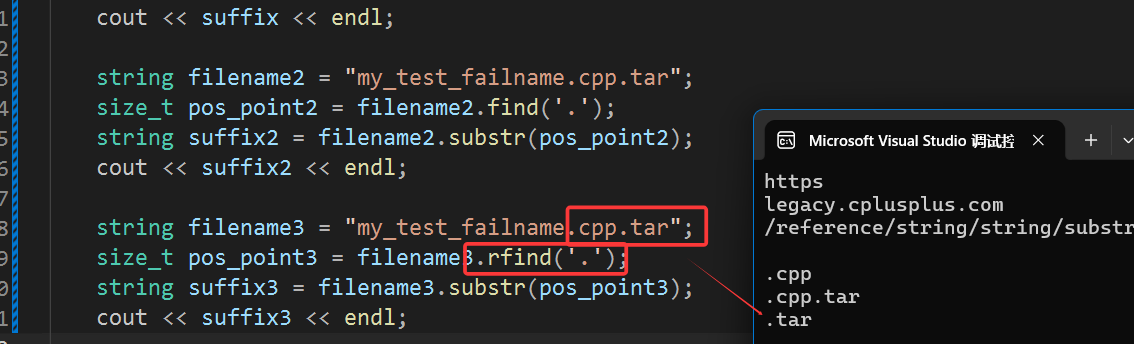
这样就实现了只打印最后一个文件名的功能了。
3、find_first_of/find_last_of/find_first_not_of/find_last_not_of
find_first_of_的功能就是,找出string中第一个存在于string_main中的字符,并返回他们的下标。
find_last_of_的功能就是,找出string中最后一个存在于string_main中的字符,并返回他的下标。
find_first_not_of_的功能就是,找出string中第一个不存在于string_main中的字符,并返回他的下标。
find_last_not_of_的功能就是,找出string中最后一个不存在于string_main中的字符,并返回他的下标。
这里就只演示find_first_of的与用法,其他的可以以此类推:
这段代码的功能就是将str1中的字母转换成*.
那么以上就是本次所有的内容了
文章是自己写的哈,有什么描述不对的、不恰当的地方,恳请大佬指正,看到后会第一时间修改,感谢您的阅读~~~~
本次文章的代码如下,就没有手写笔记了:
cpp
#define _CRT_SECURE_NO_WARNINGS 520
#include<iostream>
#include<cstring>
#include<string>
using namespace std;
int main() {
string str("hello world");
char* cstr = new char[str.size() + 1];
strcpy(cstr, str.c_str());
cout << cstr << endl;
return 0;
}
#include<iostream>
using namespace std;
int main() {
string str1("hello world");
//使用c_str
//char* cstr = new char[str1.size() + 1];
char cstr[30];
memset(cstr, 'x', sizeof(cstr));
strcpy(cstr, str1.c_str());
return 0;
}
#include<iostream>
#include<string>
using namespace std;
int main() {
string str("hello world");
char str2[30];
memset(str2, 0, sizeof(str2));
//从str中的下标4喀什往后5个字符,拷贝到str2中,并返回拷贝后str2结束的下标。
size_t length = str.copy(str2,5,4);
str2[length] = '\0';
cout << str2 << endl;
return 0;
}
#include<iostream>
using namespace std;
int main() {
string URL("https://legacy.cplusplus.com/reference/string/string/substr/");
//现在对协议进行分割,首先要先找到:
size_t pos_Colon = URL.find(':');
if (pos_Colon != string::npos) { //说明找到了
string Colon = URL.substr(0, pos_Colon);
cout << Colon << endl;
//现在对域名进行查找:
size_t pos_domain = URL.find('/',pos_Colon+3);
if (pos_domain != string::npos) { //说明找到了/
string domain = URL.substr(pos_Colon + 3, pos_domain-(pos_Colon+3));
cout << domain << endl;
//现在对内容进行查找:
size_t pos_txt = URL.rfind('/');
if (pos_txt != string::npos) { //说明/找到了
string txt = URL.substr(pos_domain, pos_txt - pos_domain);
cout << txt << endl;
}
}
}
cout << endl;
string filename = "my_test_failname.cpp";
//对于只有一个后缀名的文件,可以从头往后找,直到一个.出现为止
size_t pos_point = filename.find('.');
string suffix = filename.substr(pos_point);
cout << suffix << endl;
string filename2 = "my_test_failname.cpp.tar";
size_t pos_point2 = filename2.find('.');
string suffix2 = filename2.substr(pos_point2);
cout << suffix2 << endl;
string filename3 = "my_test_failname.cpp.tar";
size_t pos_point3 = filename3.rfind('.');
string suffix3 = filename3.substr(pos_point3);
cout << suffix3 << endl;
return 0;
}
#include<iostream>
using namespace std;
int main() {
string str1("sfdnbasidfnbsiehioug;lasidnv");
string main_string("aeiou");
//string::iterator it = str1.begin();
size_t pos = str1.find_first_of(main_string);
while (pos != string::npos) {
str1[pos] = '*';
pos = str1.find_first_of(main_string, pos + 1);
}
cout << str1 << endl;
return 0;
}想要实现的小伙伴可以将除了想要运行的头文件范围之外的头文件全部屏蔽掉即可