很多企业在完成核心系统国产化之后,业务已经稳定跑在 GaussDB 上,但很快会进入下一阶段:经营分析、实时看板、主题查询、风控报表、数据服务层都需要尽快接上。

如何实现呢?把业务数据实时复制到数仓即可。但通常会有如下挑战:
- 历史数据需要快速初始化到位。
- 业务持续写入时,目标端要持续、稳定地追平变化。
- 任务运行出了问题,要能第一时间感知,如果等到下游发现数据不对那就晚了。
- 正式上线前,要能全自动化对复制结果做核验,人工抽样费时费力还容易出错。
这个时候,一条能长期稳定的实时数据复制链路 就很关键了。NineData 最新数据复制链路矩阵,已经支持了 GaussDB -> StarRocks 结构、全量、增量复制,并支持数据对比。
一条真正可上线的实时复制链路,至少要解决五件事
很多工具只能解决其中一段。
有的能做一次性导入,但做不了持续追平;有的能抓增量日志,但前面的结构初始化和后面的结果核验全靠人工补;还有的任务虽然能跑起来,但几乎不可观测,出了问题只能靠人排查。
真正面向生产环境的实时复制,上述所有环节都不能掉链子。NineData 面向这些痛点,把下面五件事做成了闭环。
一、结构复制:先把目标端准备好,复制才有意义
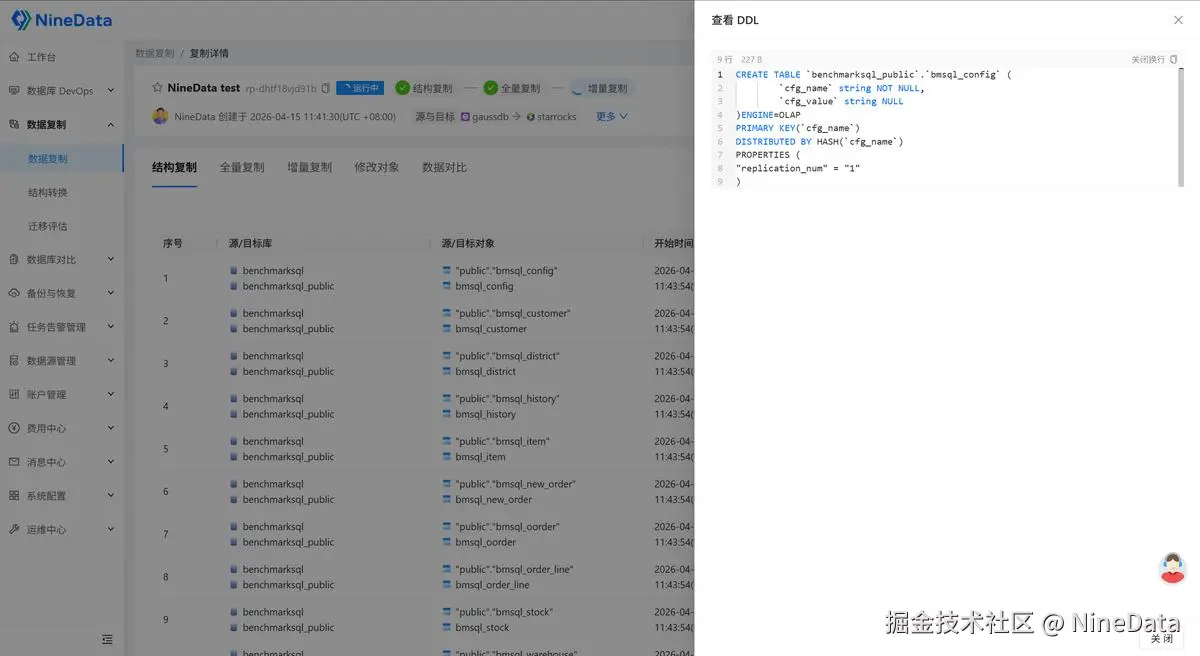
在正式同步开始前,目标端必须先具备承接数据的基础。NineData 支持结构复制,可以先把 GaussDB 中的对象结构初始化到 StarRocks,减少手工建表、手工改结构、人工逐项核对带来的成本。
二、全量复制:先把历史数据给挪过来
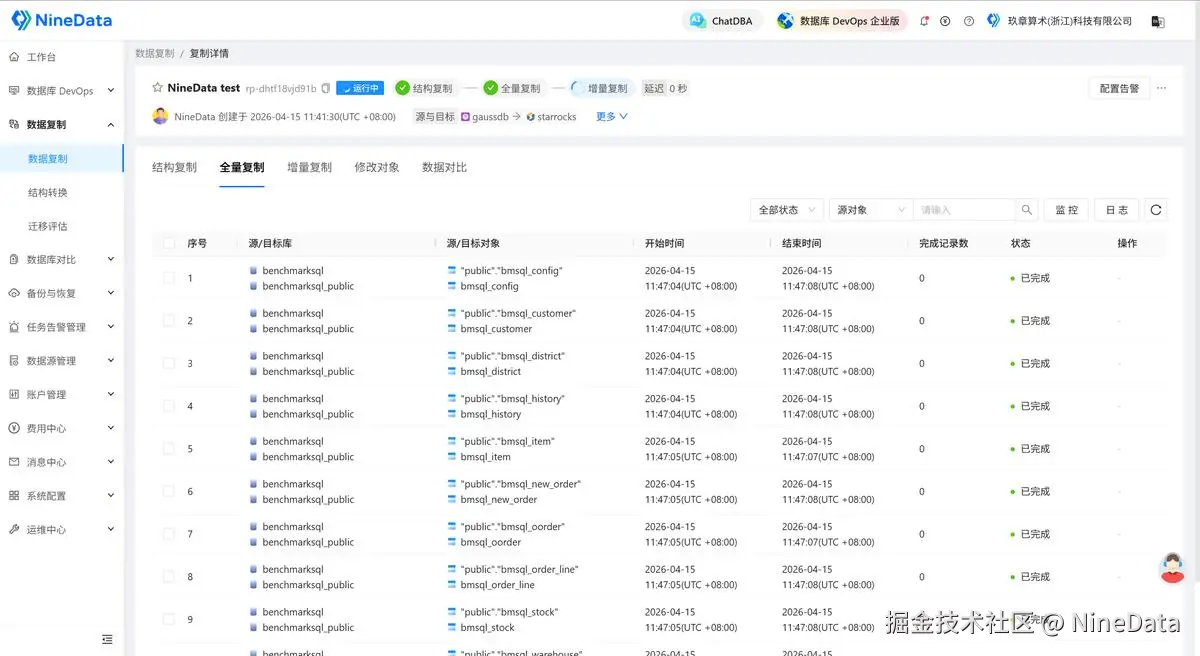
任何实时链路,都不是上来就"实时",而是先把历史数据补齐。
NineData 支持全量复制,先把历史数据同步到 StarRocks,完成分析侧初始化。这样一来,后续无论是实时看板、经营分析,还是主题查询和报表服务,就可以立即开始。
三、增量复制:实时数据复制能力,真正的核心就在这里
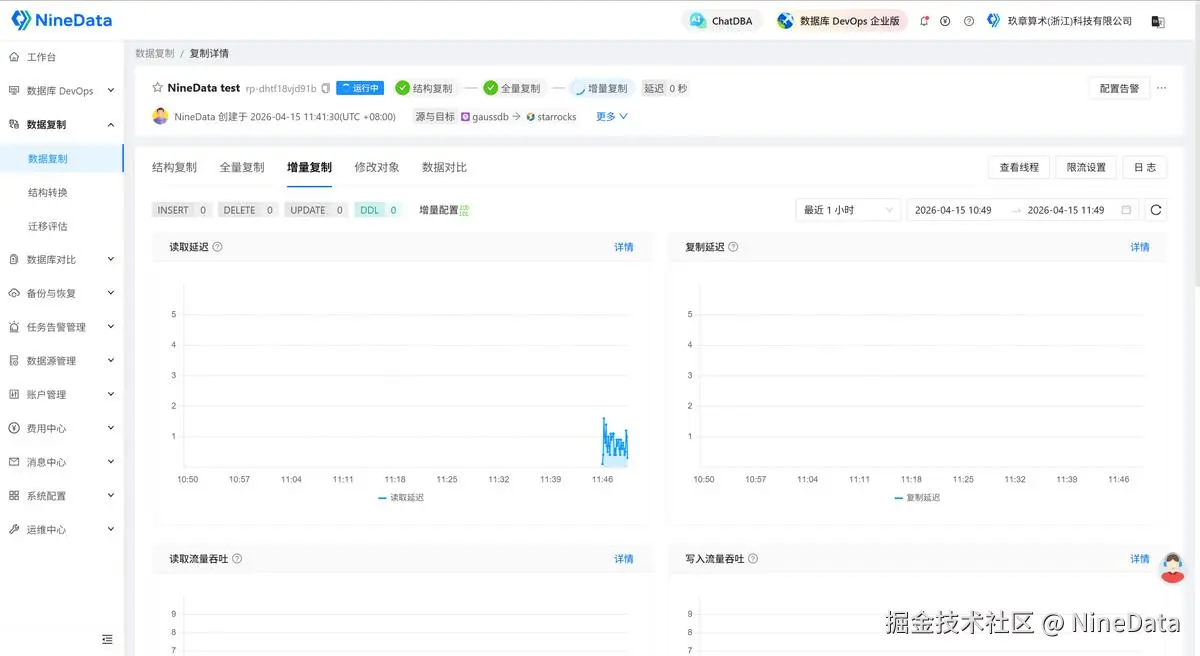
既然是"实时",那它就必须可以追平业务变化。持续让目标端保持和源端的数据一致。
NineData 支持增量复制。在源端业务持续写入的情况下,新增、更新、删除的数据变化可以持续同步到 StarRocks,让目标端不断追上源端状态。
这意味着整条链路不再依赖人工导出、定时脚本或批量补数,而是可以真正变成一条持续运行的数据通道。
对业务侧来说,这才是实时数据复制的有效输出:我不止替你搬一次,而是一直在替你监视源端变化,一直在搬。
四、预检查:把问题尽量留在上线前
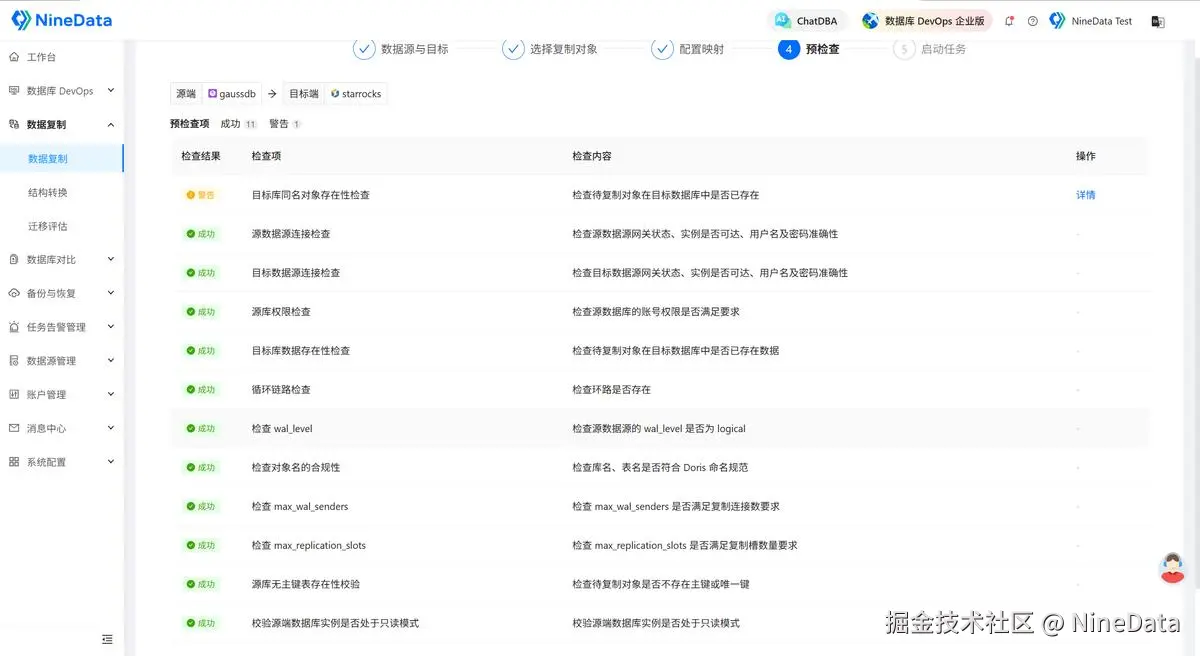
NineData 在任务启动前提供预检查能力,可以提前识别这条链路里最关键的风险点,包括:
- 源端和目标端连接是否正常
- 账号权限是否满足要求
- 目标端是否存在同名对象或已有数据
- wal_level、max_replication_slots、max_wal_senders 等关键参数是否满足增量复制要求
它的目的很直接:把问题尽量暴露在迁移之前,让迁移任务流畅地跑起来。
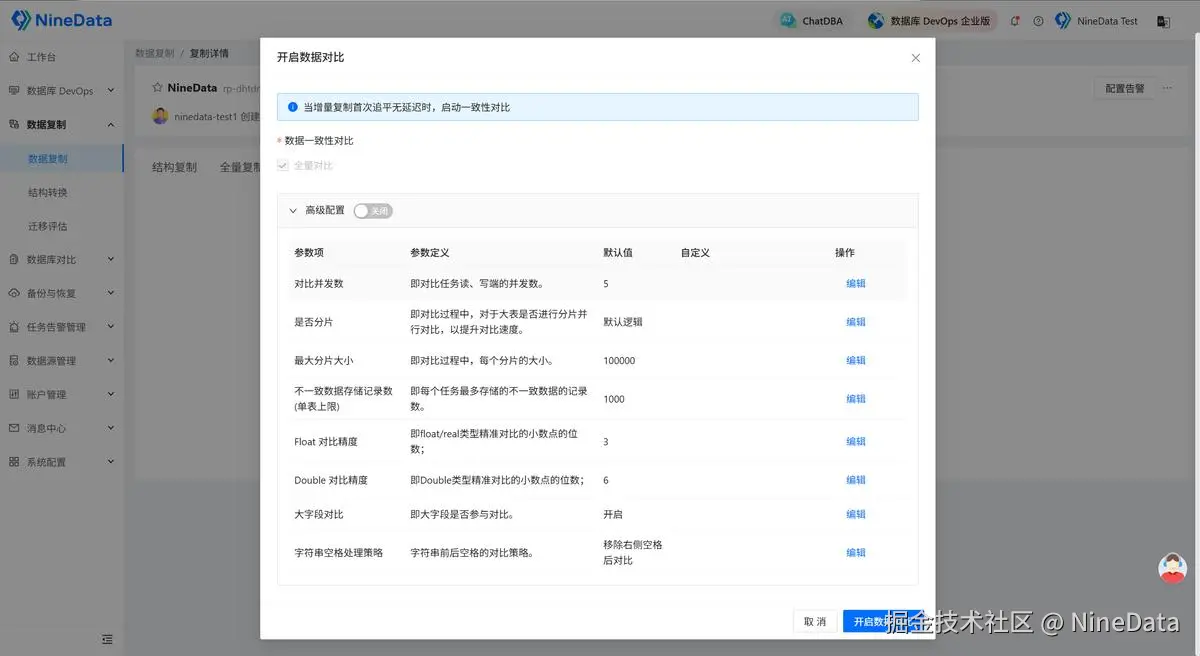
五、监控、告警、数据对比:任务跑起来还不够,配套设施也得跟上
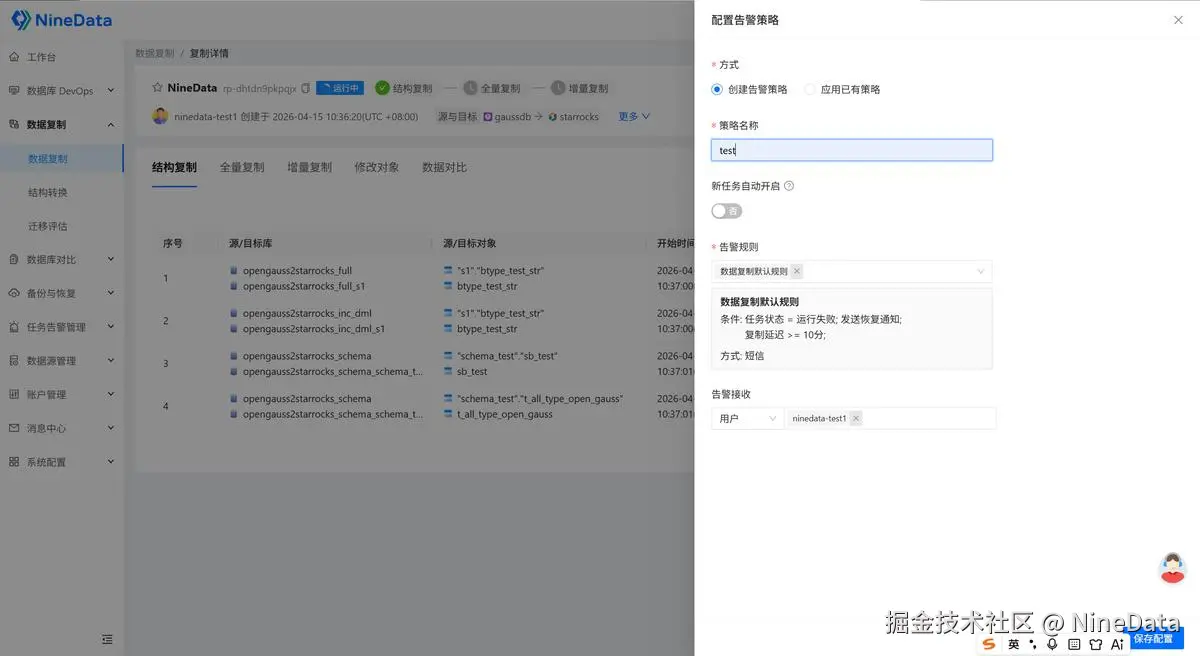
实时复制最怕的,是报错了没人知道;是延迟了很久才被发现;是源和目标的数据不一致。
NineData 在这条链路中提供了任务状态、运行监控、异常定位和告警能力,帮助团队持续感知复制状态。
更关键的是,NineData 还提供了数据对比能力。对于企业来说,项目上线前不用再只靠抽样检查几张表、看几条 SQL 来判断有没有风险,而是可以通过 NineData 的自动化能力对复制结果做更明确的核验。
写在最后
NineData 在 GaussDB > StarRocks 这条链路上做的,是把结构复制、全量复制、增量复制、预检查、监控告警、数据对比串成了一条真正面向生产环境的实时数据复制链路。
而这正是 NineData 真正和其他工具拉开差距的地方。