【Agent Skills学习笔记】2小时从会用到会造:什么是Skills?怎么用?怎么写?
本文是系统学习 Agent Skills(以 Anthropic/Claude Skills 体系为主,结合 opencode 实操)后的完整笔记整理:
- 整体思路围绕三个核心目标展开:一套可复用的理解框架(渐进式披露/三层结构) + 一套可落地的使用路径(下载安装到能用) + 一套最小可行的"造 Skill"模板。
- 适合读者:希望把 AI 从"会聊天"提升到"能按 SOP 干活"的同学;以及希望把个人/团队流程沉淀成可复用能力包的开发者。
⚡ 快速参考(先给答案)
-
适用场景:
- 在工作与学习中,如果经常遇到重复性很强的任务(如写周报、生成文档、整理资料、批量处理文件或跑固定分析流程);
- 相比每次都临时"手搓 Prompt",更希望 AI 能稳定按流程做事;
- 目标是把"个人经验、流程或规范"沉淀为 可复用能力包,实现即拿即用。
-
核心结论:
- Skills 可以理解成 AI 的"能力包/岗位说明书 ":把元数据 + 指令 SOP + 资源/脚本 打包,让 AI 按需加载,在特定任务上更稳更专业。
- Skills 的关键不是"写更长的 Prompt",而是用结构化的指令约束 AI 的思考路径,必要时用脚本/资源把确定性步骤做实。
- 最好用的 Skills 往往具备:
- 可触发(名字/描述清晰)
- 可执行(步骤可落地)
- 可校验(有验证/输出规范)
- 可复用(输入输出稳定)
-
最短上手路径:
- 下载/安装一个支持 Skills 的 Agent(本文以 opencode 路线示例)
- 把现成 skill 文件夹拷到 Agent 识别目录
- 启动 Agent,问它"有哪些 skills",再用一句话触发
-
常用命令/操作:
- Claude Code(官方仓库给出的方式):
/plugin marketplace add anthropics/skills
- opencode:
- 打开:
opencode - 连接模型:
/connect - 切换模型:
/models
- 打开:
- Claude Code(官方仓库给出的方式):
-
避坑提醒:
- 路径尽量英文,避免中文/空格在某些工具链里出问题。
- Skill 的
name通常要与文件夹名一致(至少要保持唯一、可识别)。 - 只靠"长 Prompt"会漂;要加上输入/输出规范 与验证步骤。
📚 学习目标
- 理解 Skills 的本质:它到底和 Prompt、Tool、Agent 有何区别
- 掌握一个 Skill 的典型结构:
SKILL.md、scripts/、references/、assets/ - 能把一个"重复工作"做成第一个可复用 Skill(最小可行版本)
一、基础概念(是什么)
1.1 Skills 的官方定义(来自 anthropics/skills)
Anthropic 官方仓库对 Skills 的描述是:
- Skills 是一些文件夹,里面包含 instructions(指令) 、可能的 scripts(脚本) 、以及 resources(资源);
- Claude 会在需要时动态加载这些内容,以提高在特定任务上的表现;
- 技能的目标是让 Claude 在"专业任务"上更稳定、更可复用。
参考:GitHub
anthropics/skills仓库 README(Skills / About This Repository)
1.2 一个好用的类比:能力包/岗位说明书
Skills 可以理解成 AI 的"能力包/岗位说明书 ":把元数据 + 指令 SOP + 资源/脚本 打包,让 AI 按需加载,在特定任务上更稳更专业。
1.3 核心术语对比(建议表格)
| 术语 | 含义 | 使用场景 | 常见误区 |
|---|---|---|---|
| Prompt | 一次性提示词/指令 | 轻量、临时、低复用 | 越写越长、越写越乱、不可验证 |
| Skill | 可复用能力包(元数据+SOP+资源) | 重复任务、需要稳定流程 | 以为只是"更长 Prompt",忽略资源/校验 |
| Tool | 可被调用的外部能力(脚本/接口) | 确定性计算/检索/执行 | 把 Tool 当 Skill,缺少流程/输出规范 |
| Agent | 规划+执行的主体(会调度工具/skills) | 多步骤任务、复杂工作流 | 只堆工具,不做边界与规范 |
二、原理详解(为什么这样做)
2.1 "渐进式披露":Skills 背后的设计哲学
Skills 的设计哲学是"渐进式披露",让 AI 像人类专家一样按需调动知识与流程。
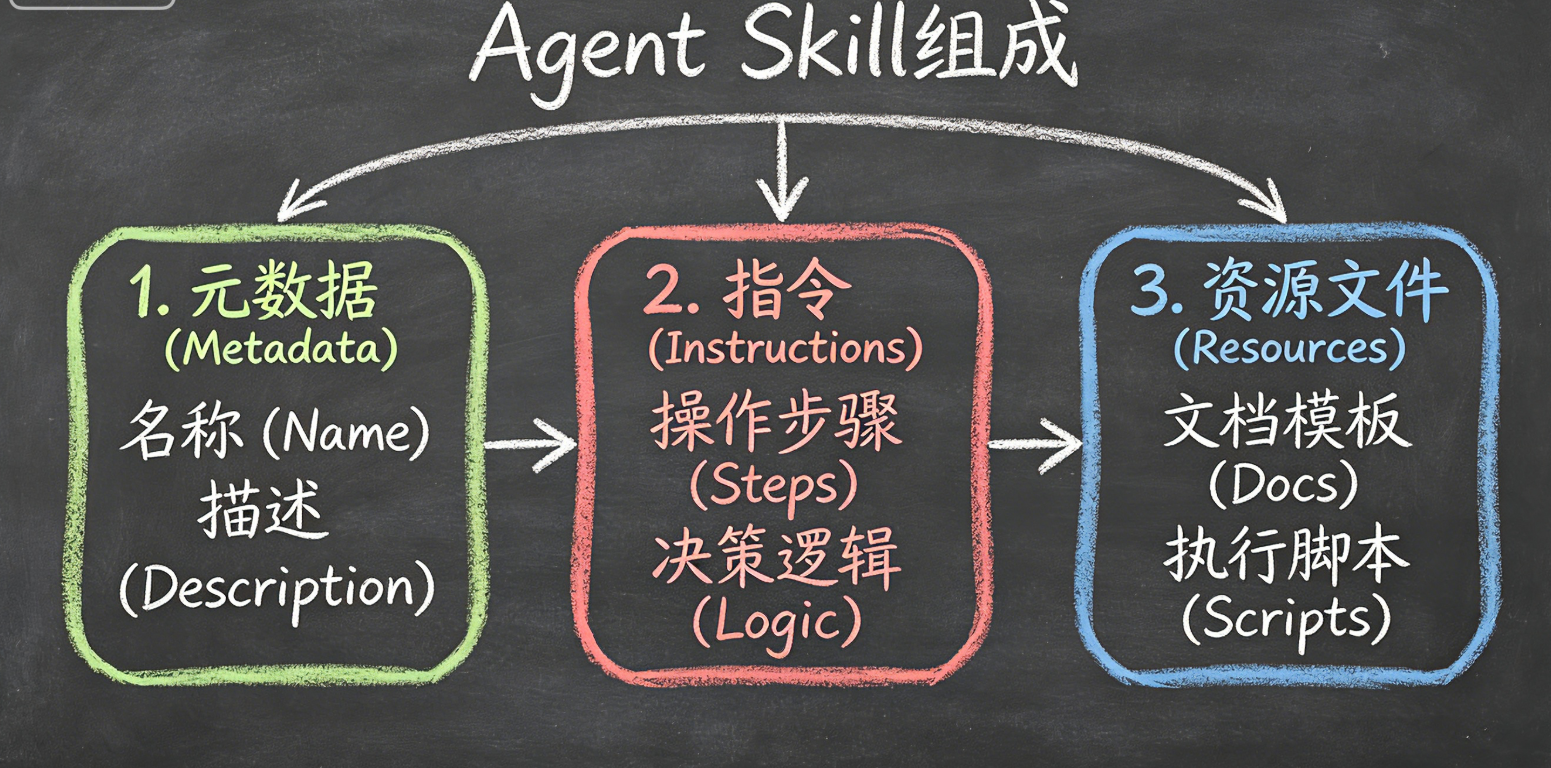
2.2 Skill 的三层结构:元数据层 / 指令层 / 资源层
一个 Skill 的典型结构包括:
-
🥥 元数据层(识别与触发)
- 相当于 Skill 的"名片":
name+description - 目的:让 Agent 的意图识别更容易命中所需技能
- 相当于 Skill 的"名片":
-
🍗 指令层(思考与规划)
- 相当于"专家 SOP 注入":告诉 AI 先做什么、后做什么、如何判断成功、输出是什么
- 这是让 AI 从"泛化回答"切换到"按行业最佳实践做事"的关键
-
🍞 资源层(执行与校验)
- 资源可以是脚本/模板/参考文档
- 目的:把确定性动作交给程序,把关键规范放在可引用的外部记忆里,提高可靠性
三、完整实战(怎么用):从下载安装到"能用 Skills 干活"
说明:官方仓库给了 Claude Code 的安装方式;我的笔记以 opencode 为例,演示"安装 Agent -> 连接模型 -> 放入 skills -> 触发使用"的完整链路。
3.1 环境准备
- 系统:Windows / macOS 均可
- Agent:opencode(示例)或 Claude Code(官方路径)
https://opencode.ai/download
https://opencode.ai/docs - 模型:可用 Anthropic / 国内模型(如智谱等,取决于你的工具支持)
3.2 安装 Agent(opencode 示例)
在此我直接展示图形化版本的
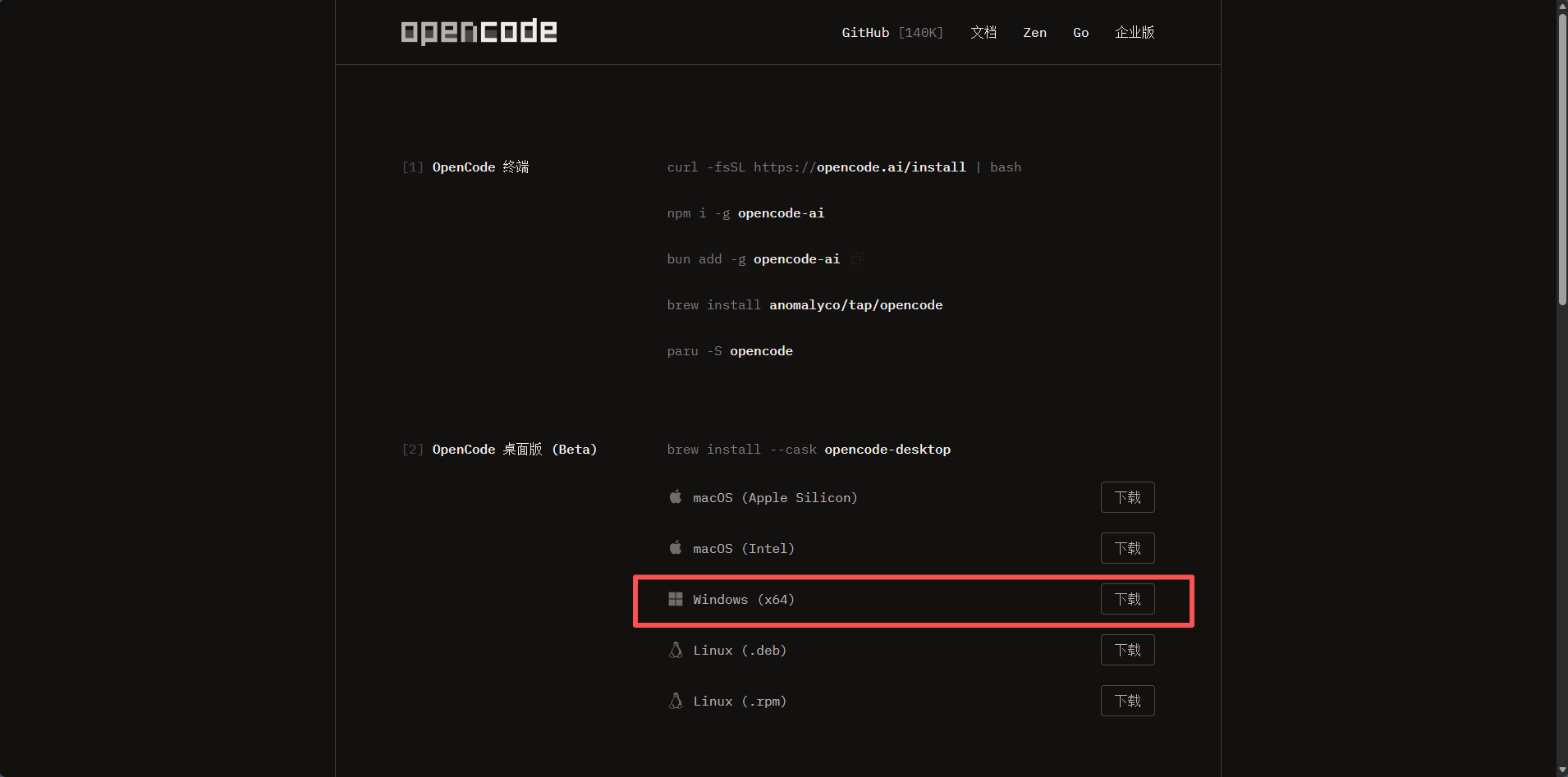
- Tips:安装后记得让环境变量生效(如重启终端/重新加载配置)
3.3 准备模型 API_KEY 并连接模型
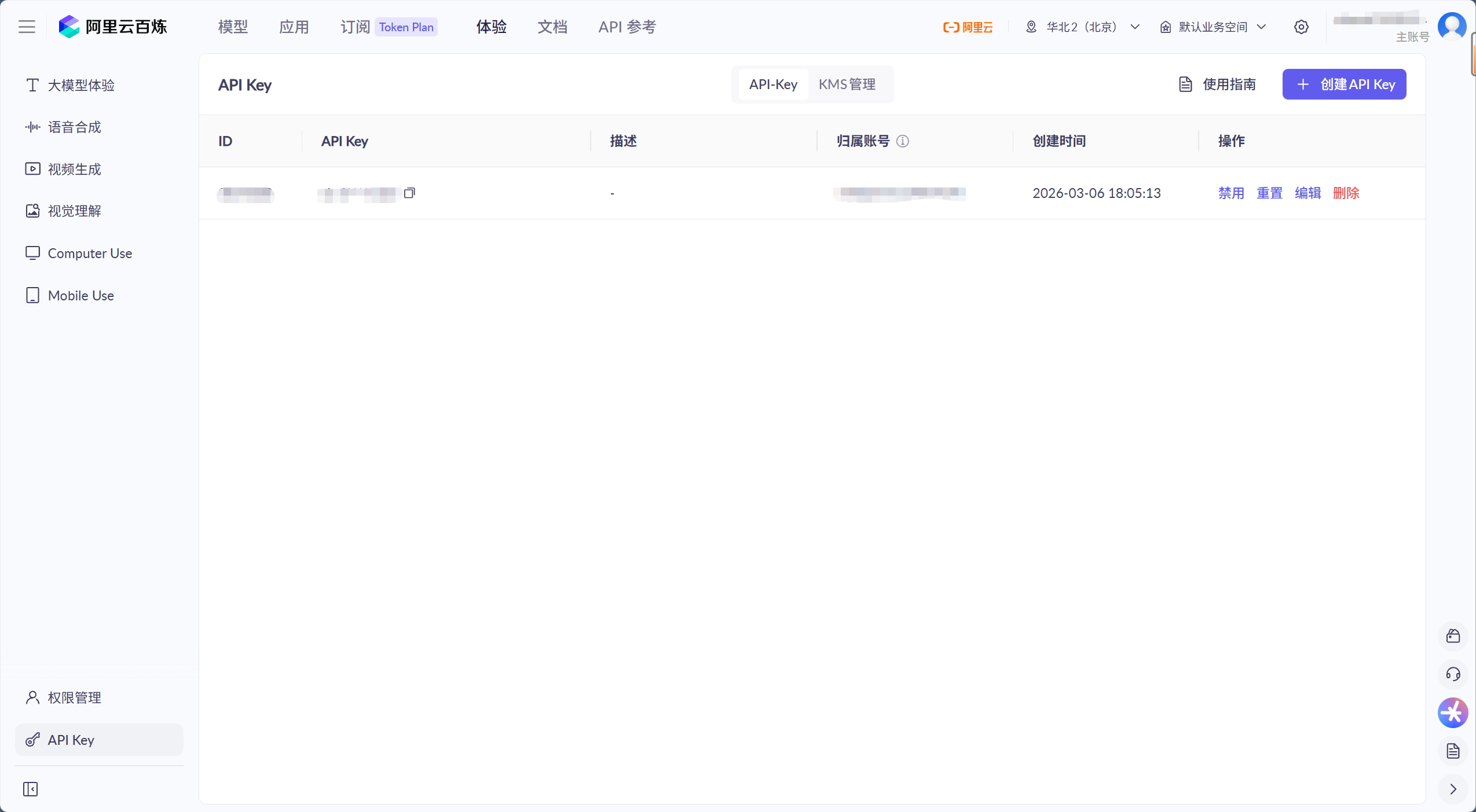
以"阿里云"为例:
-
去开放平台创建
API_KEY
-
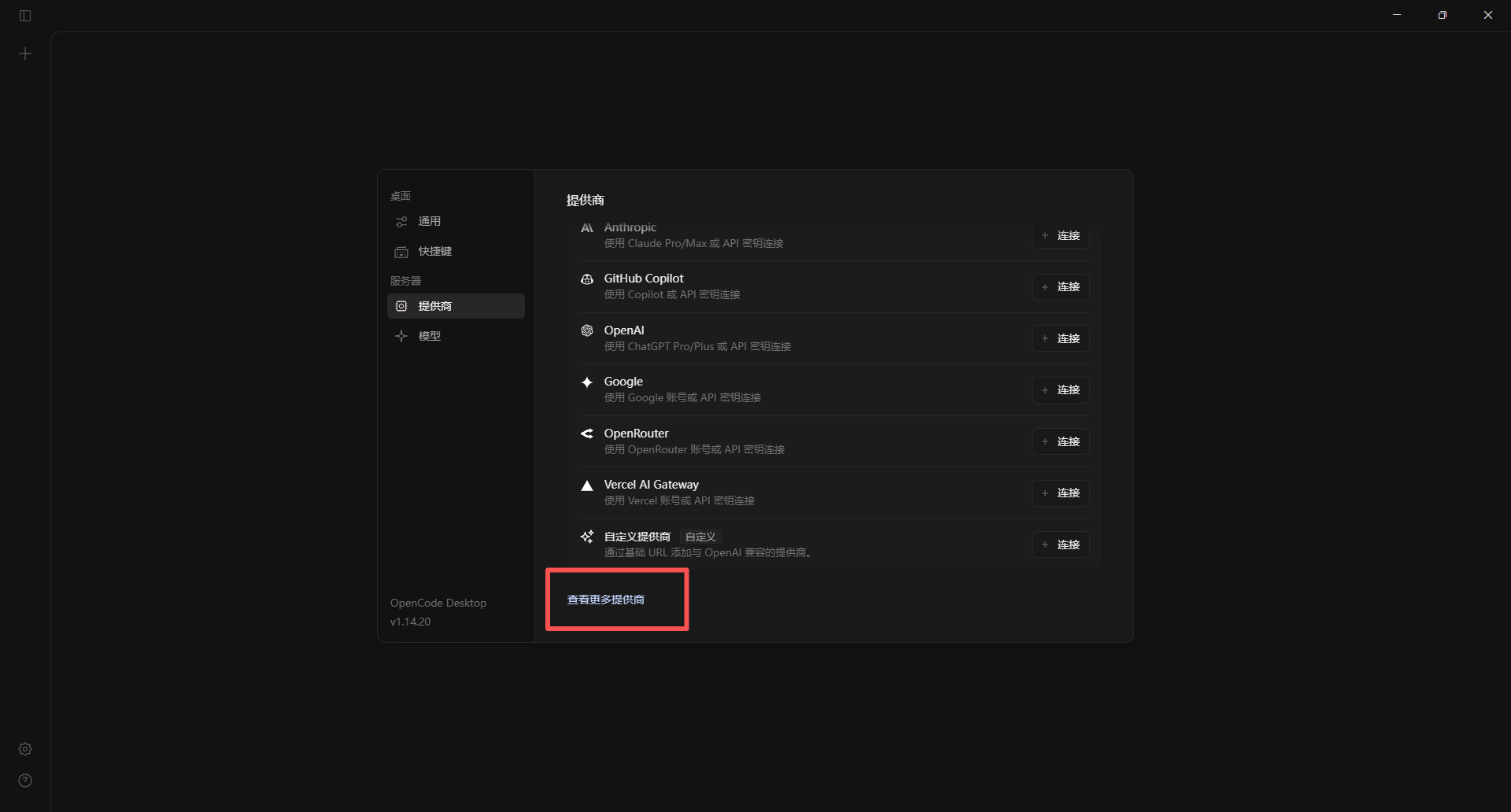
在 opencode 里点击设置
-
搜索对应提供商,输入 key,选择模型
3.4 下载 Skills(从哪里找现成技能)
我的笔记里给了很多来源,这里整理成"收藏夹"级别的清单:
- Anthropic 官方仓库:
https://github.com/anthropics/skills - 社群/市场:
https://skillsmp.com/zh、https://skillstore.io/zh-hans - 合集:
https://github.com/ComposioHQ/awesome-claude-skillshttps://github.com/JackyST0/awesome-agent-skillshttps://agent-skills.md/(大集合)
建议:优先从"官方/高星/维护频繁"的仓库挑选,并自己做一层"可用性验证"。
3.5 使用 Skills(最关键:放到哪里 + 怎么触发)
3.5.1 项目级使用(推荐:与项目绑定)
我的笔记给了一个清晰结构:
- 在项目根目录下创建:
.opencode/skills/(或.opencode/skill/也可) - 把下载好的 skill 文件夹拷贝进去
- 在项目目录打开 opencode
- 问它"有哪些 skills",再提具体需求让它执行
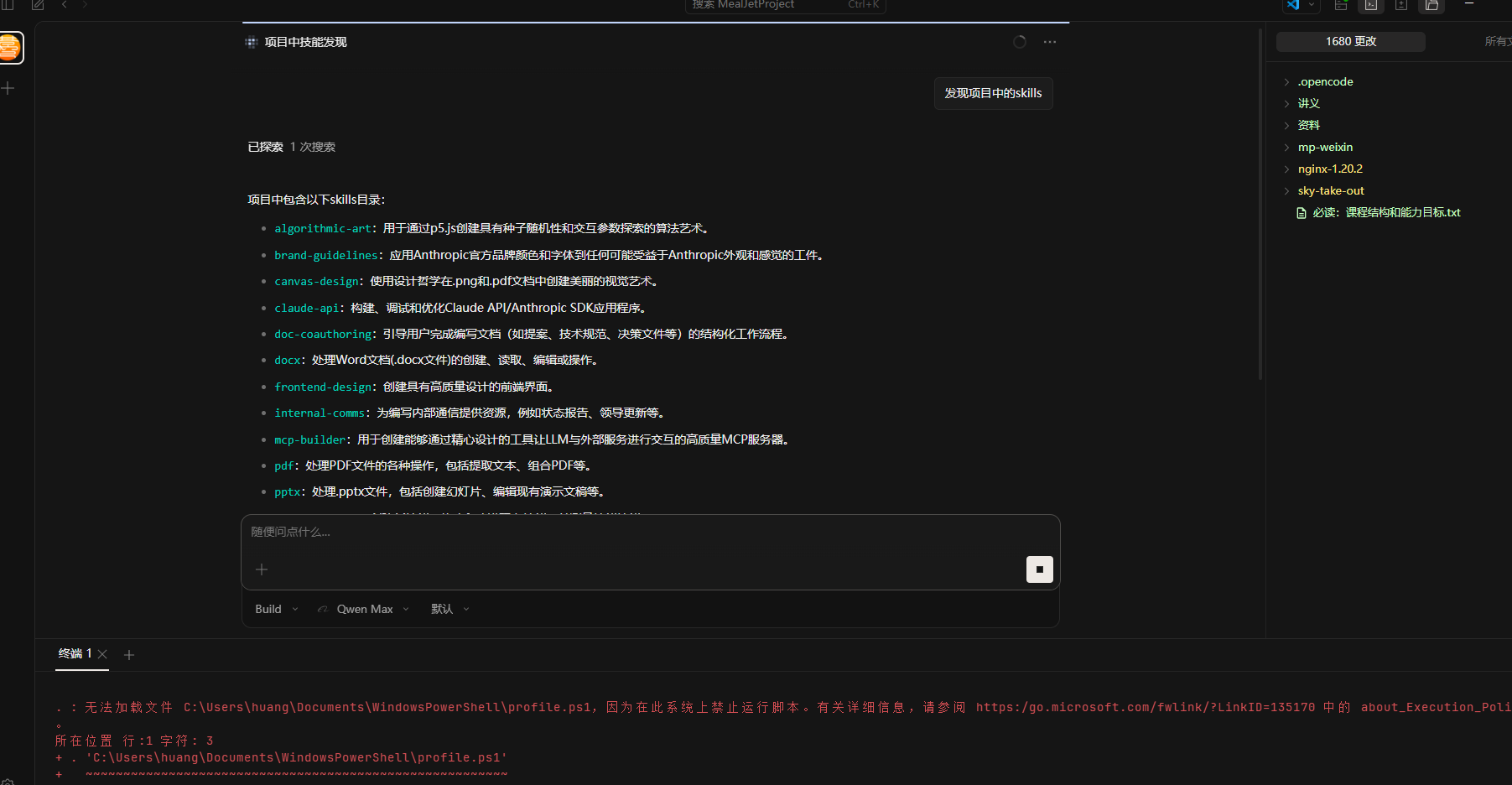
四、Skill 的内部结构(怎么组织一个可维护的 Skill)
结合官方仓库与参考文章,一个典型 skill 结构如下:
text
skill-name/
SKILL.md # 核心说明(必须)
scripts/ # 可执行脚本(可选)
references/ # 参考资料/规范/流程(可选)
assets/ # 模板/静态资源(可选)4.1 SKILL.md:最小必需品
官方仓库强调:一个基础 skill 就是"文件夹 + SKILL.md"。
SKILL.md 主要包含:
- YAML frontmatter:
name:唯一标识(通常小写+连字符)description:清晰描述"做什么/什么时候用"
- Markdown 正文:
- 指令(流程、规则、输出要求)
- Examples(触发示例)
- Guidelines(边界、注意事项)
官方还指出:仓库里很多 skills 是 Apache 2.0,但
docx/pdf/pptx/xlsx属于 source-available(可参考但不是开源许可)。
4.2 scripts / references:把"确定性"和"规范性"外置
- scripts:把可确定执行的事情交给脚本(解析、格式化、生成文件、批量处理)
- references:把规则/模板外置(如报告结构、抽取规则、对照表、品牌规范)
我的笔记里的"周报生成器 Skill"就是很典型的组合:
- 指令里定义"收集数据 -> 处理数据 -> 组织结构 -> 生成报告"的 SOP
- 脚本负责 git 分析、todo 解析、聚合、HTML->PDF
- resources 提供模板文件
五、从会用到会造:做一个最小可行 Skill(以"周报生成器/资料整理"为例)
下面我把笔记里最有价值的"造 Skill"内容,整理成我可以直接照抄的最小模板。
5.1 Step 1:创建技能文件夹
例如:weekly-report-generator/
5.2 Step 2:创建 SKILL.md(元数据)
md
---
name: weekly-report-generator
description: 自动生成项目周报,从 git 提交、issue、todo 文件和用户输入中提取信息,生成结构化周报
---
# Weekly Report Generator
## 核心流程
1) 收集数据
2) 处理数据
3) 组织周报结构
4) 生成报告
## 输出规范
- 输出 HTML:weekly-report-YYYY-MM-DD.html
- 输出 PDF:weekly-report-YYYY-MM-DD.pdf
## 验证方式
- 生成文件是否存在
- 数据统计是否与 git log/issue 数量一致
## 注意事项
- 非 git 仓库则跳过 git log 分析
- 无 todo/issue 则提示用户补充5.3 Step 3:把"资源层"做实(可选但强烈推荐)
scripts/git-analyzer.pyscripts/todo-parser.pyreferences/report-structure.mdassets/report-template.html
实操建议:先不写脚本,先把 SOP + 输出规范写死,让 AI 稳定按流程产出;然后再把"最耗时/最确定"的步骤脚本化。
5.4 把 Skill 用到"写博文"场景(实战落地思路)
在日常写作中,一个典型的痛点是:文章结构相对固定,但材料来源(笔记、链接或混合内容)往往多变。这类"结构固定、输入多变"的工作,恰好是 Skills 擅长的应用场景:
- 写作结构固定化:复用经过验证的博文模板;
- 资料整理规则固定化:实现链接提取、要点归类及引用规范的自动化;
- 产出物标准化:每篇文章都能稳定生成流程图、时序图及对应的绘图脚本。
基于此思路,可以将写作流程拆解为两个核心技能:
java-middleware-blog-skillai-blog-skill
并在 SKILL.md 里强制要求输出:
- 快速参考
- 概念表格
- 原理流程图(Mermaid)
- 实战步骤
- 避坑与面试问答
- 待确认清单
六、开发避坑总结(高频错误)
6.1 典型问题清单
-
技能命中率低
- 原因:
name/description太泛、与用户话术不匹配 - 解决:把描述写成"动词+对象+场景",并提供 2-3 个触发示例
- 原因:
-
能生成但不稳定/跑偏
- 原因:只有目标没有流程;没有输出规范与验证
- 解决:补齐 SOP、输出 schema、验收清单
-
材料来源杂,引用混乱
- 原因:没有"可信度标注"与"引用区"
- 解决:固定一个
references模块,区分官方/第三方/个人笔记
6.2 最佳实践
- 先把"流程与验收标准"写清楚,再考虑脚本化
- Skill 输出尽量结构化(标题层级、表格、固定段落),方便我二次审核
- 对于带外部链接的内容,统一放"参考链接"区,并在正文标注来源类型
七、面试考点(能说出来)
7.1 高频问题
-
Q1:Skills 和 Prompt 有什么区别?
- A:Prompt 更像一次性指令;Skill 是可复用能力包,包含元数据(触发)+ SOP(思考/规划)+ 资源(执行/校验),支持按需加载。
-
Q2:为什么 Skills 能省 token?
- A:因为平时只保留元数据(很小),只有命中意图才加载完整指令与资源,符合"渐进式披露"。
-
Q3:如何衡量一个 Skill 写得好不好?
- A:看四点:可触发(命中率)、可执行(SOP)、可校验(验收/验证)、可复用(输入输出稳定)。
7.2 进阶追问
- Skill / Tool / Agent 的边界怎么划?
- Skill:流程与规范(SOP)
- Tool:确定性动作
- Agent:规划+调度+执行主体
本文为MY_TEUCK原创实战学习笔记,持续更新Java后端与AI应用领域干货,问题欢迎评论区交流。