商品物流数据可视化分析系统技术实现文档
1. 项目概述
本项目是一个面向商品物流、仓储运营与数据分析场景的 Web 可视化分析系统。系统以后端 FastAPI 为核心,使用 MySQL 存储业务数据,通过 Bootstrap 构建响应式页面,通过 ECharts 实现多维度数据可视化。
系统当前数据集位于 data/warehouse.csv, 2025 年数据,数据时间范围为:
- 起始时间:
2025-04-28 05:54:10 - 结束时间:
2025-06-15 18:56:54 - 数据量:
12888条
2. 技术栈
2.1 后端技术
FastAPI:负责 Web 路由、接口服务、页面响应和应用生命周期管理。SQLAlchemy 2.x:负责 ORM 模型定义、数据库连接、查询统计和数据写入。PyMySQL:作为 SQLAlchemy 连接 MySQL 的驱动。Jinja2:负责服务端模板渲染。Starlette SessionMiddleware:负责基于 Cookie 的登录会话维护。
2.2 前端技术
Bootstrap 5.3.3:负责基础栅格、表单、按钮、表格等 UI 组件。ECharts 5.5.1:负责时序图、热力图、桑基图、漏斗图、树图、关系图、散点图、平行坐标、仪表盘等可视化。原生 JavaScript:负责图表初始化、接口请求、城市下钻、品类下钻和页面交互。CSS3:负责现代化视觉风格、固定侧边栏、卡片布局、响应式布局和玻璃拟态效果。
2.3 数据库
数据库统一配置在 app/config.py 中。
默认配置如下:
text
数据库名称:design_94_warehouse
数据库地址:localhost
数据库端口:3306
数据库账号:root
数据库密码:123456系统也支持通过环境变量覆盖配置:
powershell
$env:DB_NAME="design_94_warehouse"
$env:DB_HOST="localhost"
$env:DB_PORT="3306"
$env:DB_USER="root"
$env:DB_PASSWORD="123456"3. 项目目录结构
text
.
├── app
│ ├── routers
│ │ ├── api.py
│ │ └── web.py
│ ├── services
│ │ ├── analytics.py
│ │ └── bootstrap.py
│ ├── static
│ │ ├── css
│ │ │ └── main.css
│ │ ├── js
│ │ │ └── dashboard.js
│ │ └── vendor
│ │ ├── bootstrap
│ │ └── echarts
│ ├── templates
│ │ ├── analysis.html
│ │ ├── base.html
│ │ ├── dashboard.html
│ │ ├── favorites.html
│ │ ├── recommendations.html
│ │ └── profile.html
│ ├── config.py
│ ├── database.py
│ ├── dependencies.py
│ ├── models.py
│ ├── security.py
│ └── templating.py
├── data
│ └── warehouse.csv
├── main.py
├── requirements.txt
├── package.json
├── README.md
└── 技术实现文档.md4. 启动流程
应用入口为 main.py。
启动时系统会执行以下步骤:
- 创建 FastAPI 应用实例。
- 注册 SessionMiddleware。
- 挂载
/static静态资源目录。 - 注册 Web 页面路由和 API 路由。
- 在应用启动事件中初始化数据库。
- 自动创建数据库和表结构。
- 自动创建默认管理员账号。
- 当物流记录表为空时,从
data/warehouse.csv导入数据。
启动命令:
powershell
uvicorn main:app --reload默认访问地址:
text
http://127.0.0.1:8000默认管理员账号:
text
用户名:admin
密码:Admin@1235. 数据模型设计
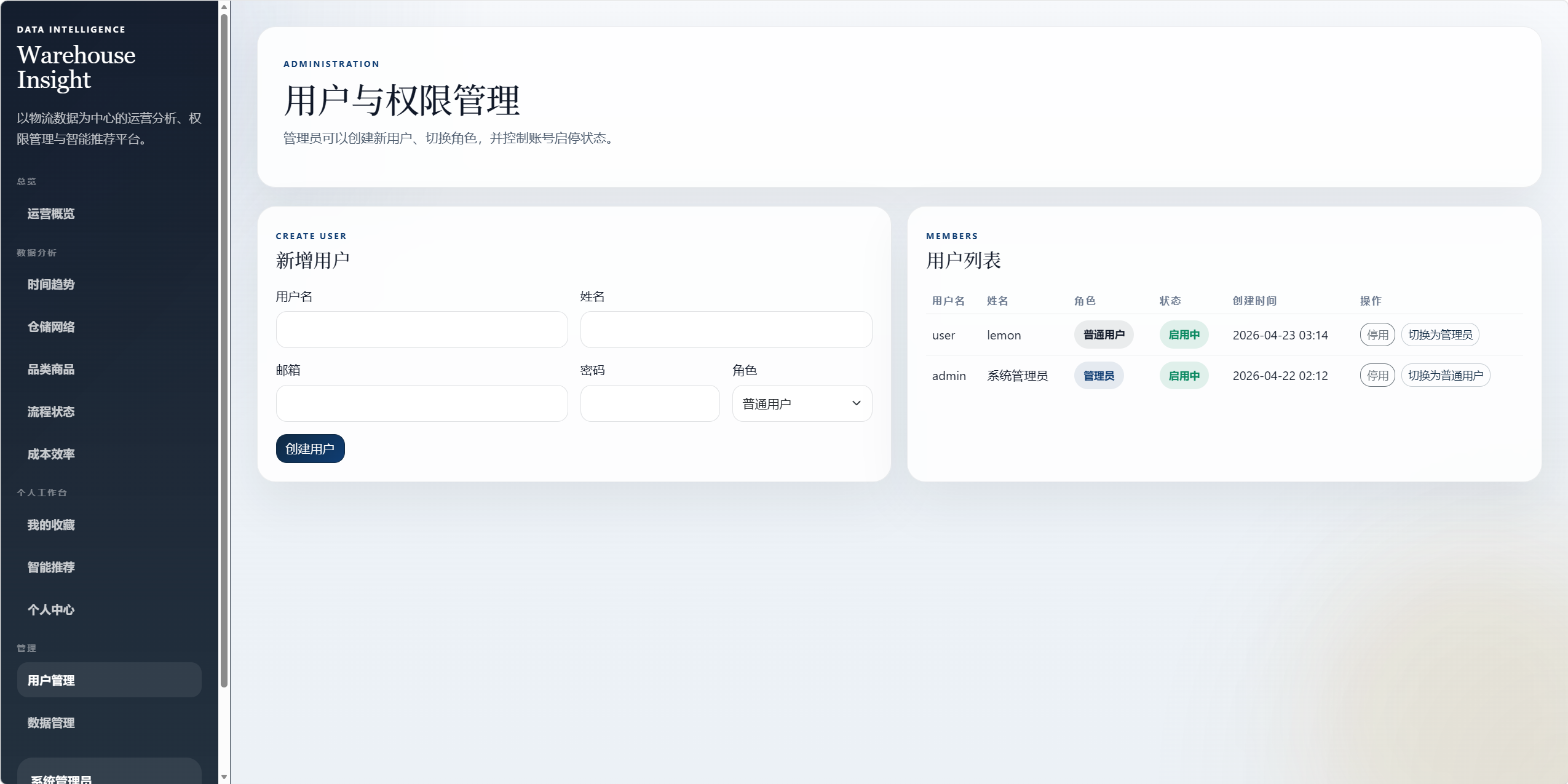
5.1 用户表 users
用户表用于登录、注册、权限控制和个人中心。
核心字段:
id:用户主键。username:用户名,唯一。password_hash:密码哈希。full_name:姓名。email:邮箱。role:角色,支持admin和user。preferred_category:用户偏好商品类别,用于推荐。bio:个人简介。is_active:账号是否启用。
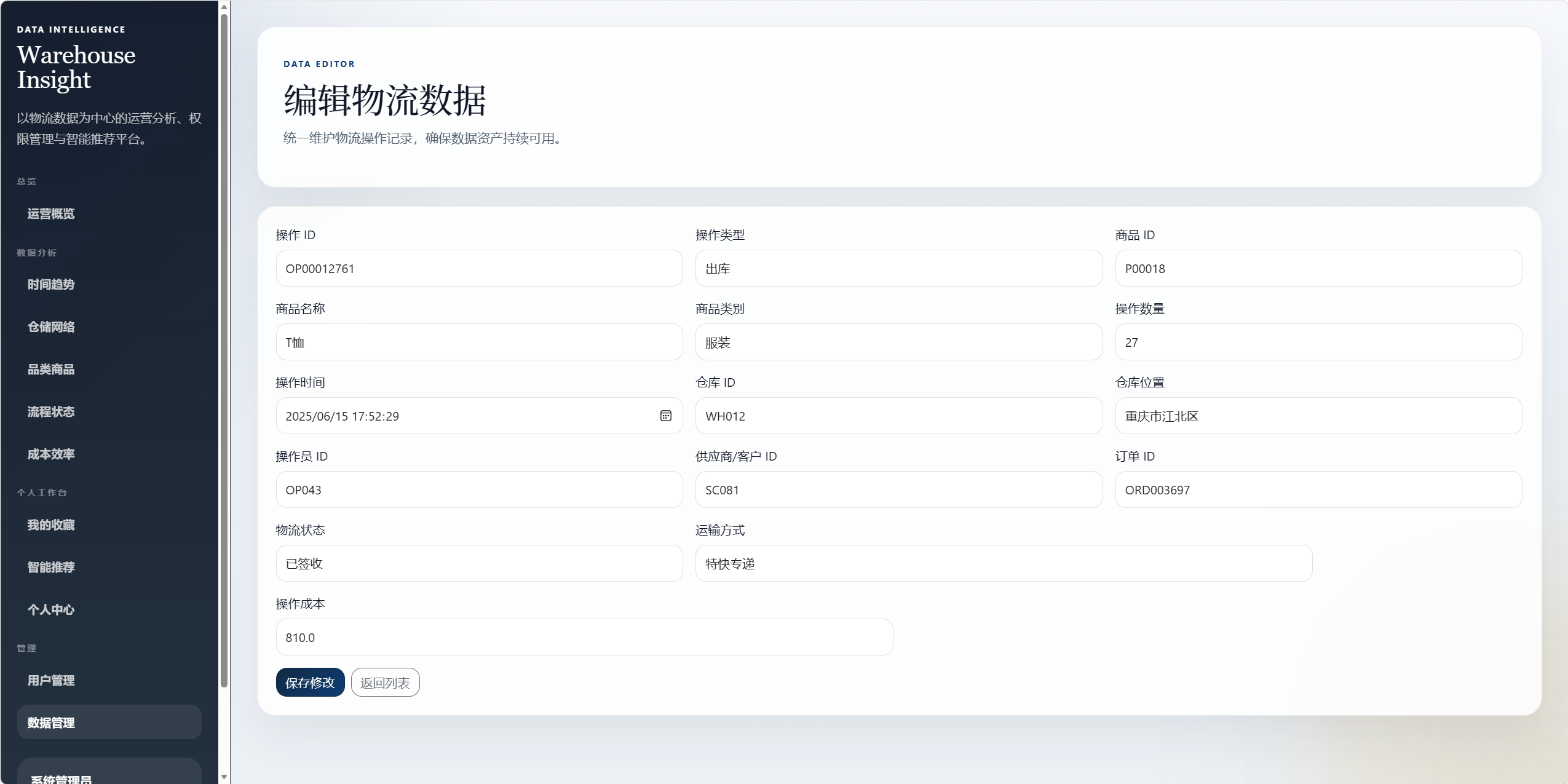
5.2 物流记录表 warehouse_records
物流记录表对应 warehouse.csv 中的业务数据。
核心字段:
operation_id:操作 ID。operation_type:操作类型。product_id:商品 ID。product_name:商品名称。product_category:商品类别。operation_quantity:操作数量。operation_time:操作时间。operation_date:操作日期。warehouse_id:仓库 ID。warehouse_location:仓库位置。warehouse_city:解析后的城市。operator_id:操作员 ID。partner_id:供应商或客户 ID。order_id:订单 ID。logistics_status:物流状态。transport_mode:运输方式。operation_cost:操作成本。
5.3 收藏表 favorite_products
收藏表用于记录用户关注的商品,并作为推荐算法的输入。
核心字段:
user_id:用户 ID。product_id:商品 ID。product_name:商品名称。product_category:商品类别。created_at:收藏时间。
同一用户不能重复收藏同一个商品。
6. 数据导入与 2025 年数据修正
数据导入逻辑位于 app/services/bootstrap.py。
系统会在首次启动时检查 warehouse_records 表是否为空:
- 如果为空,则读取
data/warehouse.csv并导入 MySQL。 - 如果不为空,则不重复导入,避免覆盖用户已有数据。
本次数据修正已完成两部分:
data/warehouse.csv中所有操作时间已从 2024 年平移到 2025 年。- MySQL 中已导入的
warehouse_records.operation_time和warehouse_records.operation_date也同步平移到 2025 年。
修正后验证结果:
text
CSV 数据量:12888
CSV 最早时间:2025-04-28 05:54:10
CSV 最晚时间:2025-06-15 18:56:54
数据库数据量:12888
数据库最早时间:2025-04-28 05:54:10
数据库最晚时间:2025-06-15 18:56:54
数据库 2024 年记录数:07. 权限与登录设计
7.1 登录注册
登录和注册逻辑位于 app/routers/web.py。
系统支持:
- 用户注册。
- 用户登录。
- 用户退出。
- Session 登录态维护。
- 停用账号拦截。
7.2 密码安全
密码处理逻辑位于 app/security.py。
系统使用 PBKDF2-HMAC-SHA256 对密码进行哈希:
- 每个密码生成独立随机盐。
- 使用固定迭代次数提升暴力破解成本。
- 登录时使用常量时间比较,降低时序攻击风险。
7.3 权限控制
权限依赖位于 app/dependencies.py。
主要权限类型:
get_current_user:要求用户已登录且账号启用。get_admin_user:要求当前用户为管理员。
Web 页面中也使用 require_login 和 require_admin 对页面访问做控制。
8. 页面与功能模块
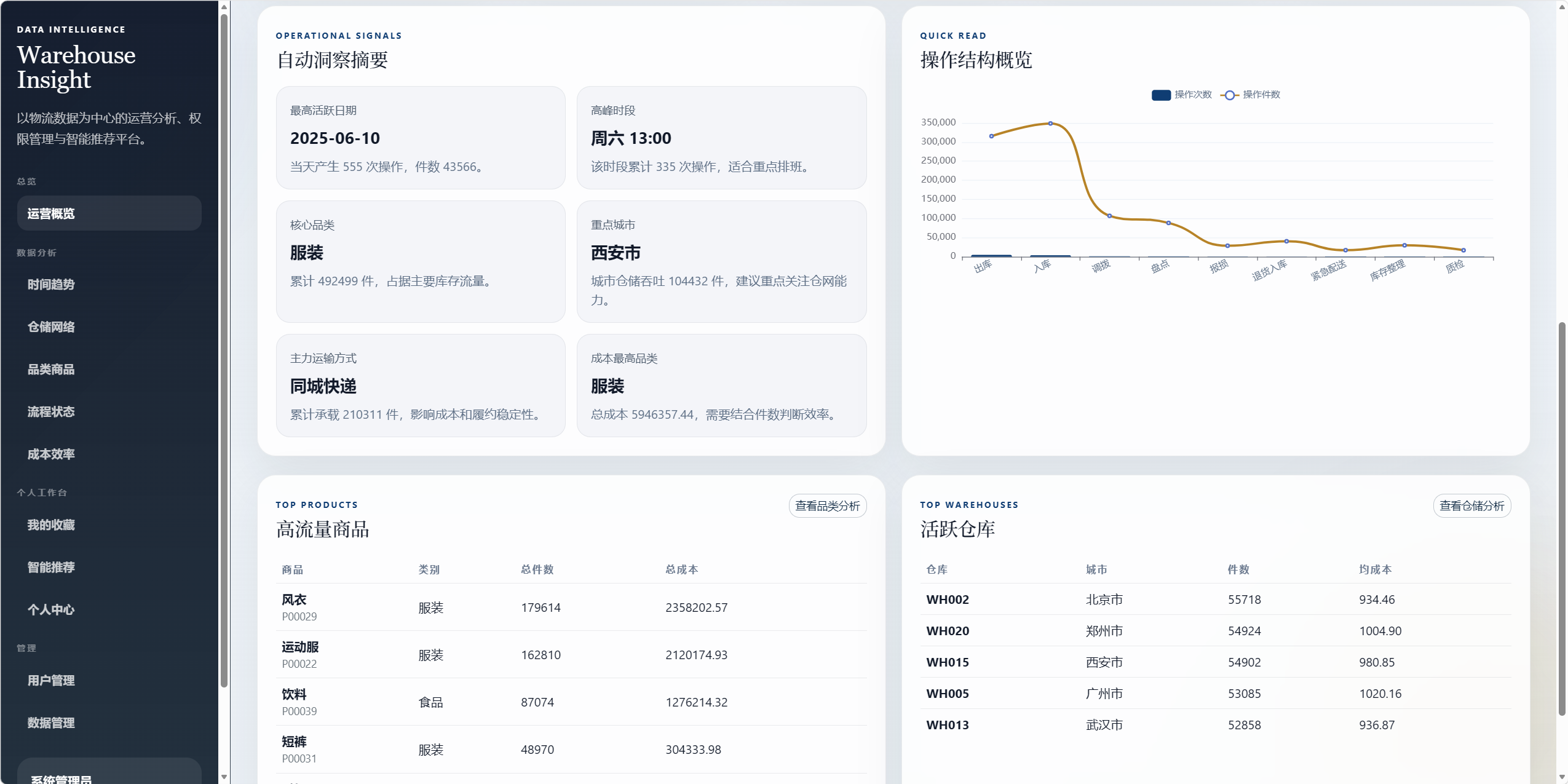
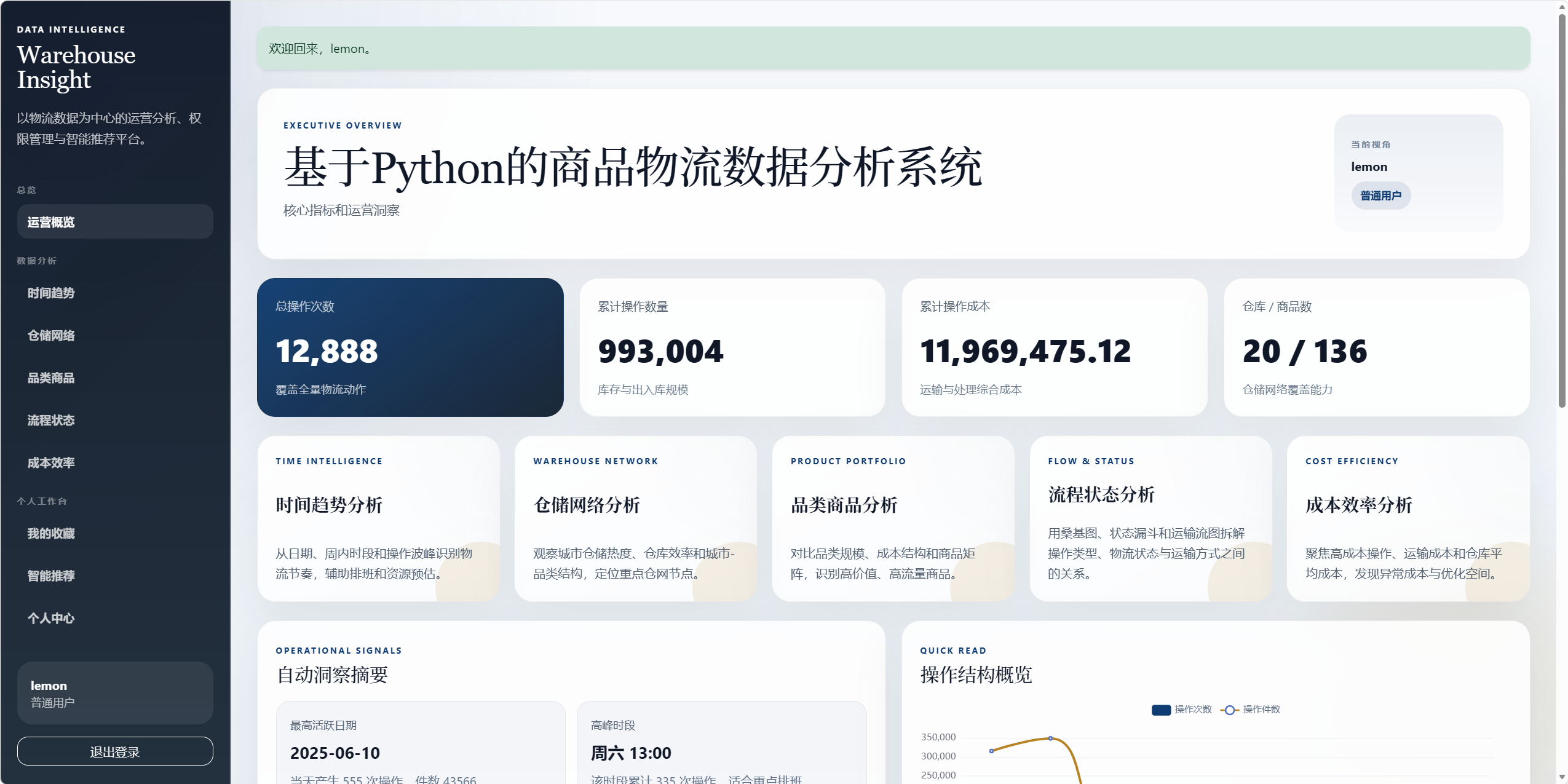
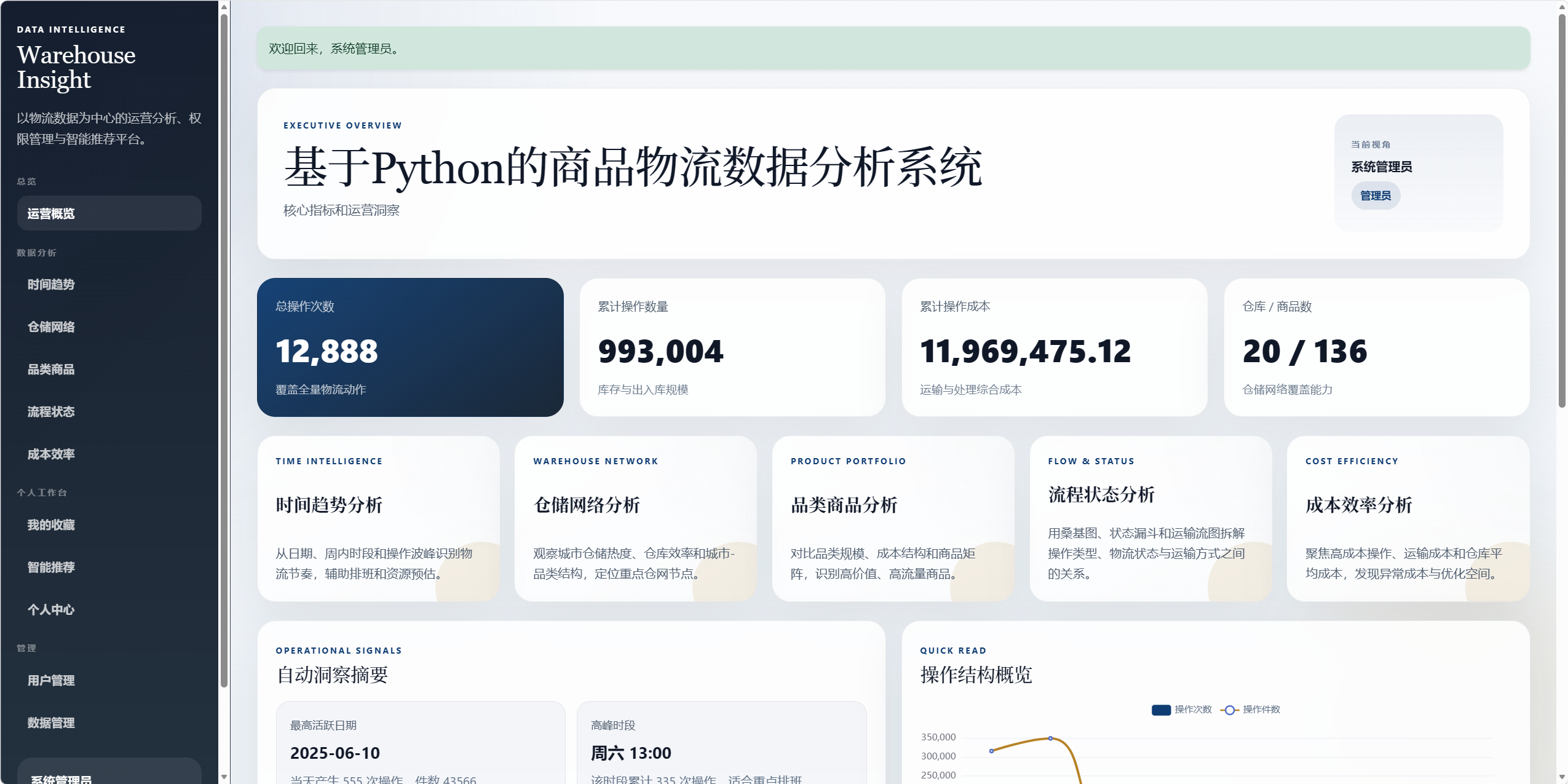
8.1 运营概览 /dashboard
运营概览不再堆叠所有图表,而是作为系统入口页。
展示内容:
- 总操作次数。
- 累计操作数量。
- 累计操作成本。
- 仓库数和商品数。
- 自动洞察摘要。
- 分析模块快捷入口。
- 高流量商品。
- 活跃仓库。
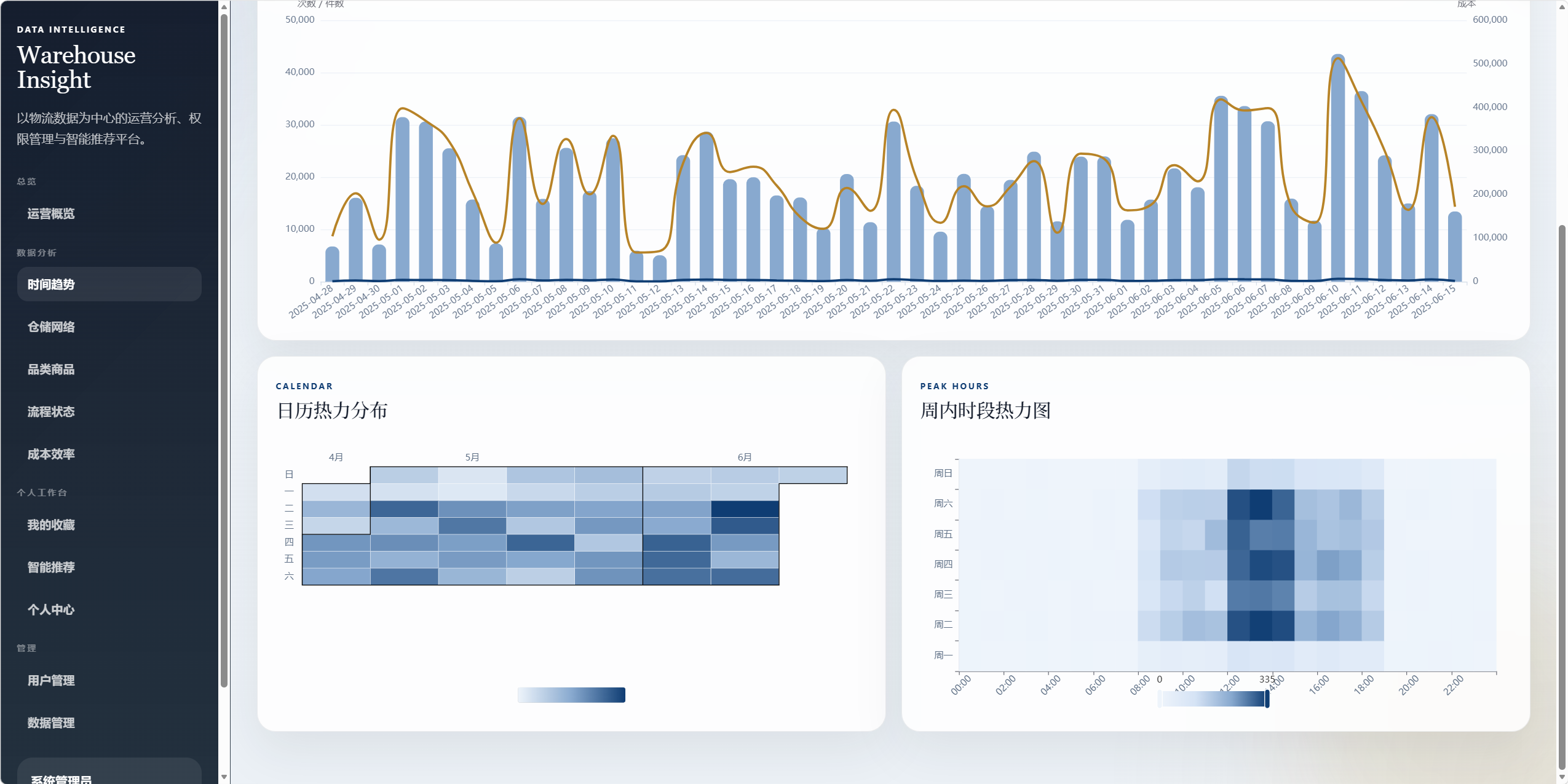
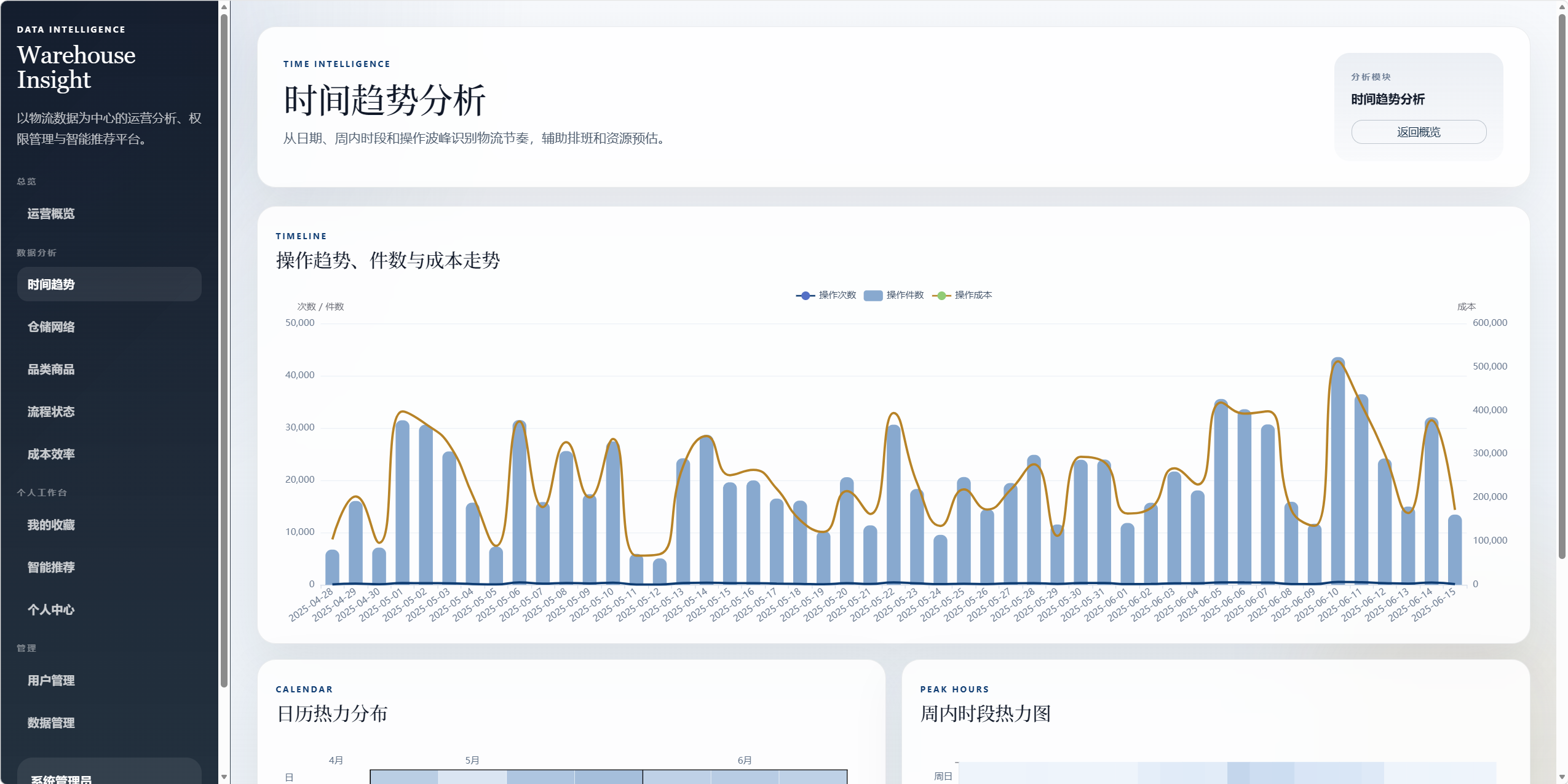
8.2 时间趋势分析 /analysis/time
用于分析物流操作的时间节奏。
图表包括:
- 操作趋势、件数与成本走势。
- 日历热力图。
- 周内时段热力图。
可回答的问题:
- 哪些日期操作更密集。
- 哪些时段是仓储操作高峰。
- 成本是否随操作量同步波动。
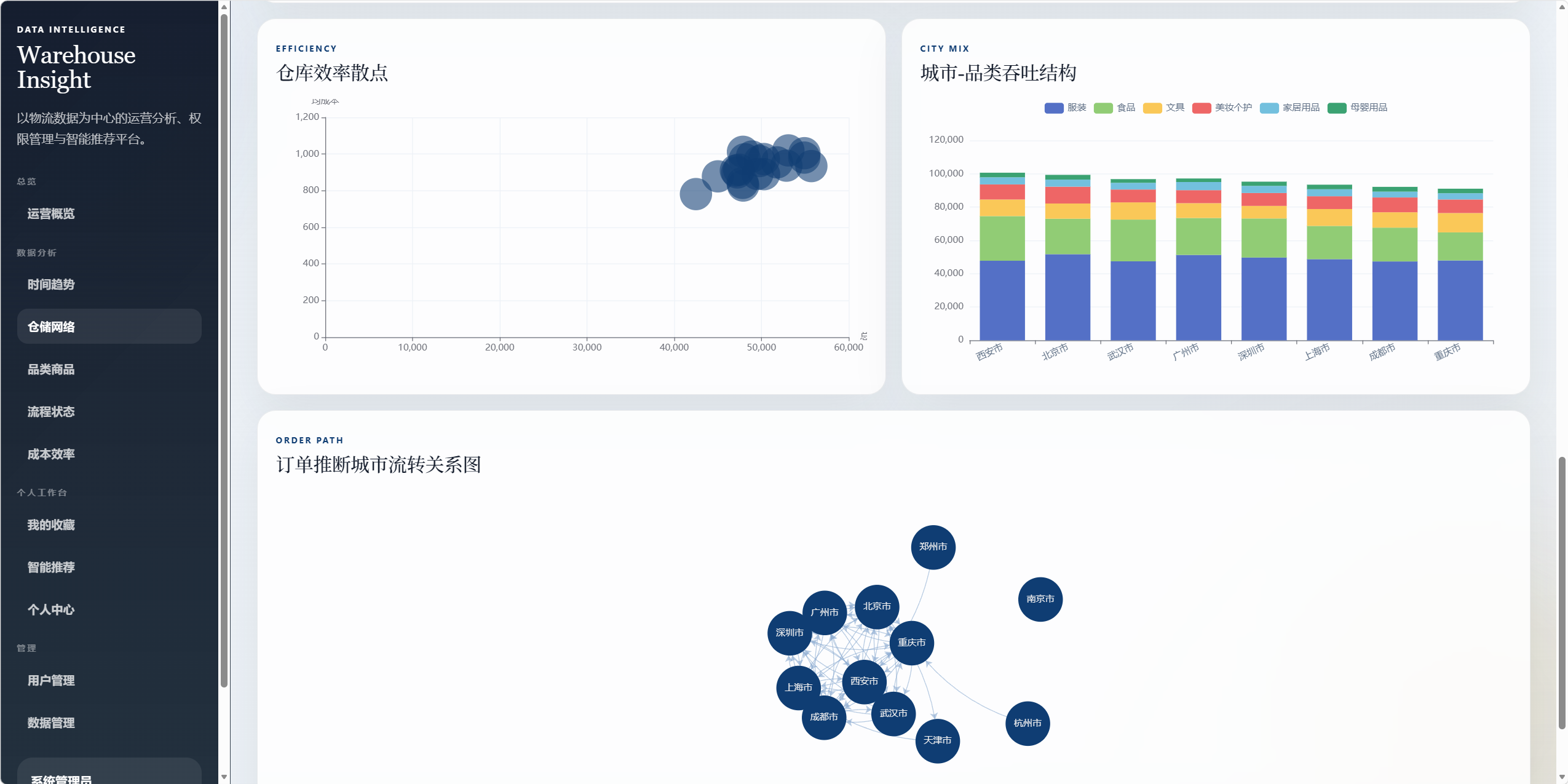
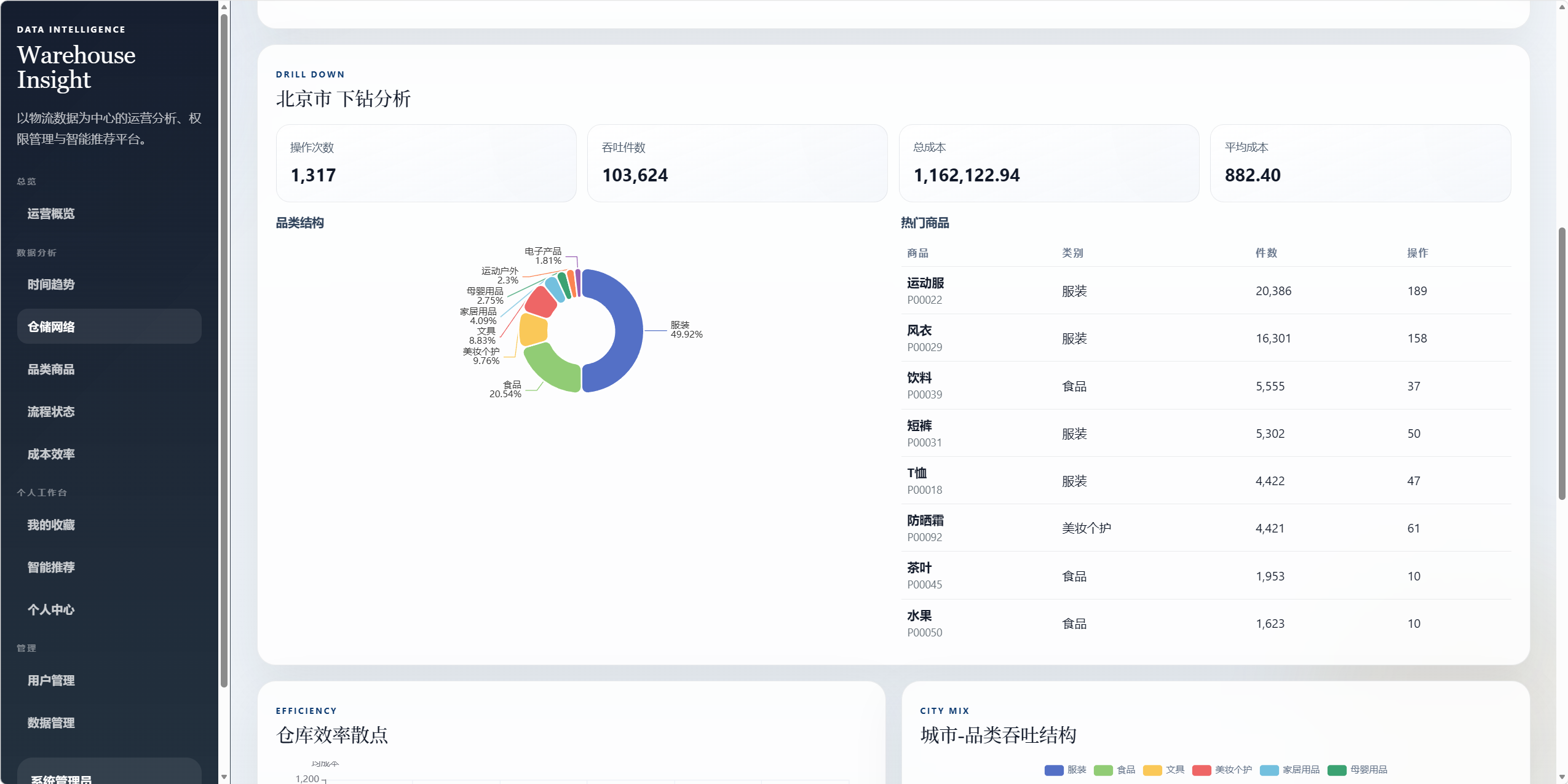
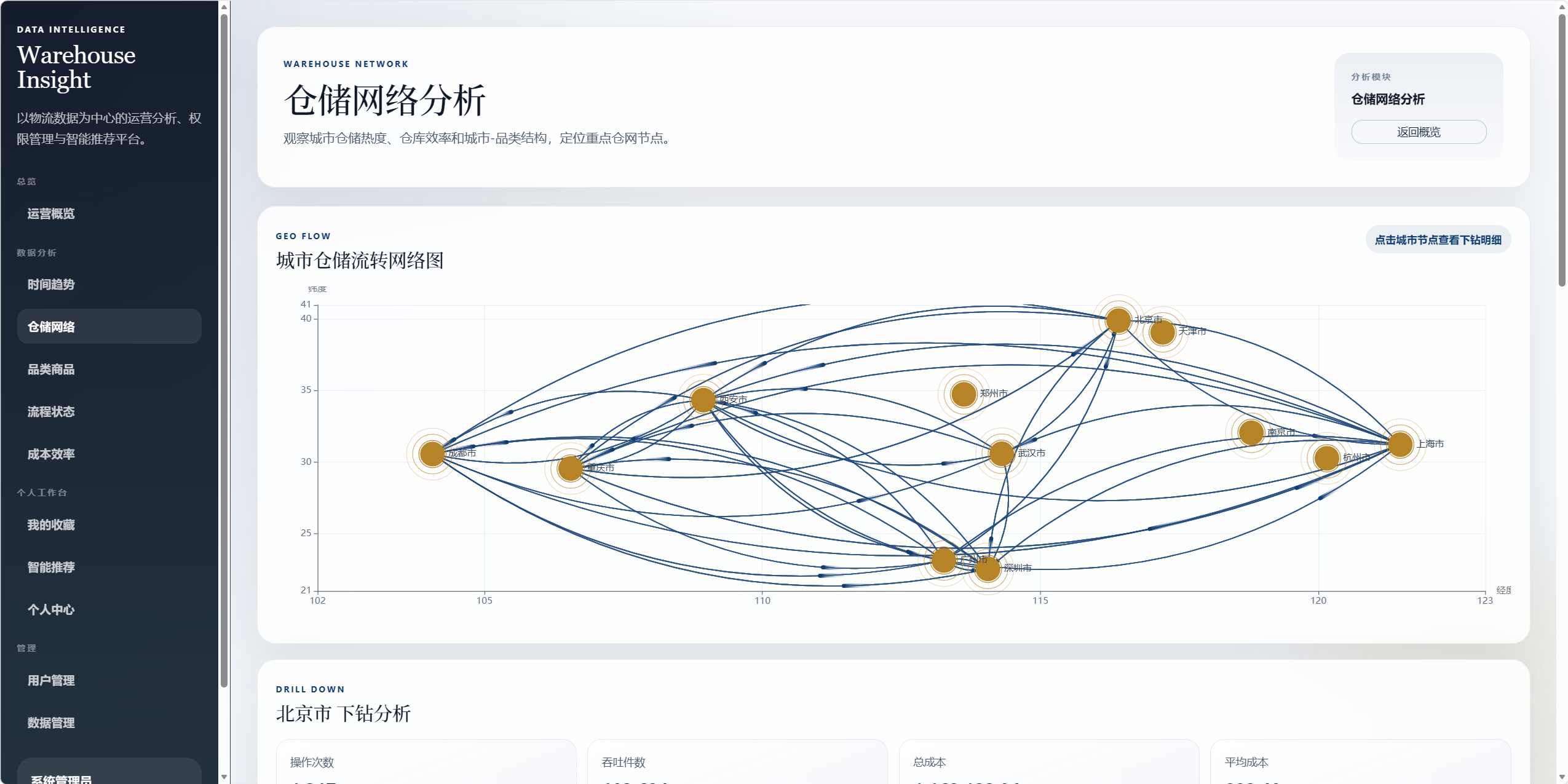
8.3 仓储网络分析 /analysis/warehouse
用于分析仓储城市和仓库网络。
图表包括:
- 城市仓储流转网络图。
- 城市节点点击下钻。
- 仓库效率散点图。
- 城市-品类吞吐结构堆叠图。
- 订单推断城市流转关系图。
下钻交互:
- 点击城市节点后,页面会展示该城市的操作次数、吞吐件数、总成本、平均成本。
- 同时展示该城市品类结构和热门商品。
城市流转推断逻辑:
- 按
订单ID聚合同一订单的多条记录。 - 按
操作时间排序。 - 如果同一订单前后记录出现不同城市,则推断为一次城市间流转。
- 统计城市间流转频次,形成流向图和关系图。
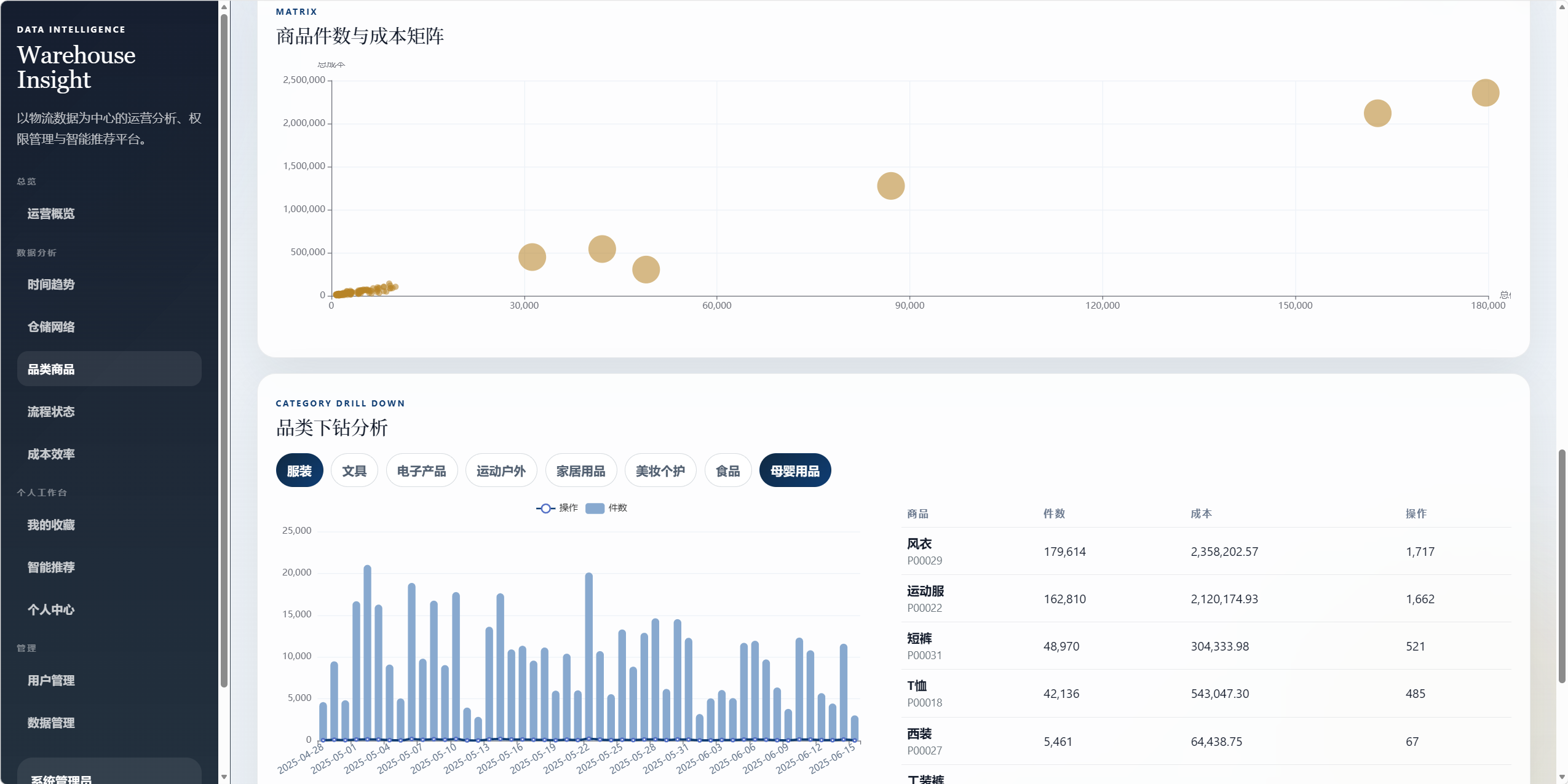
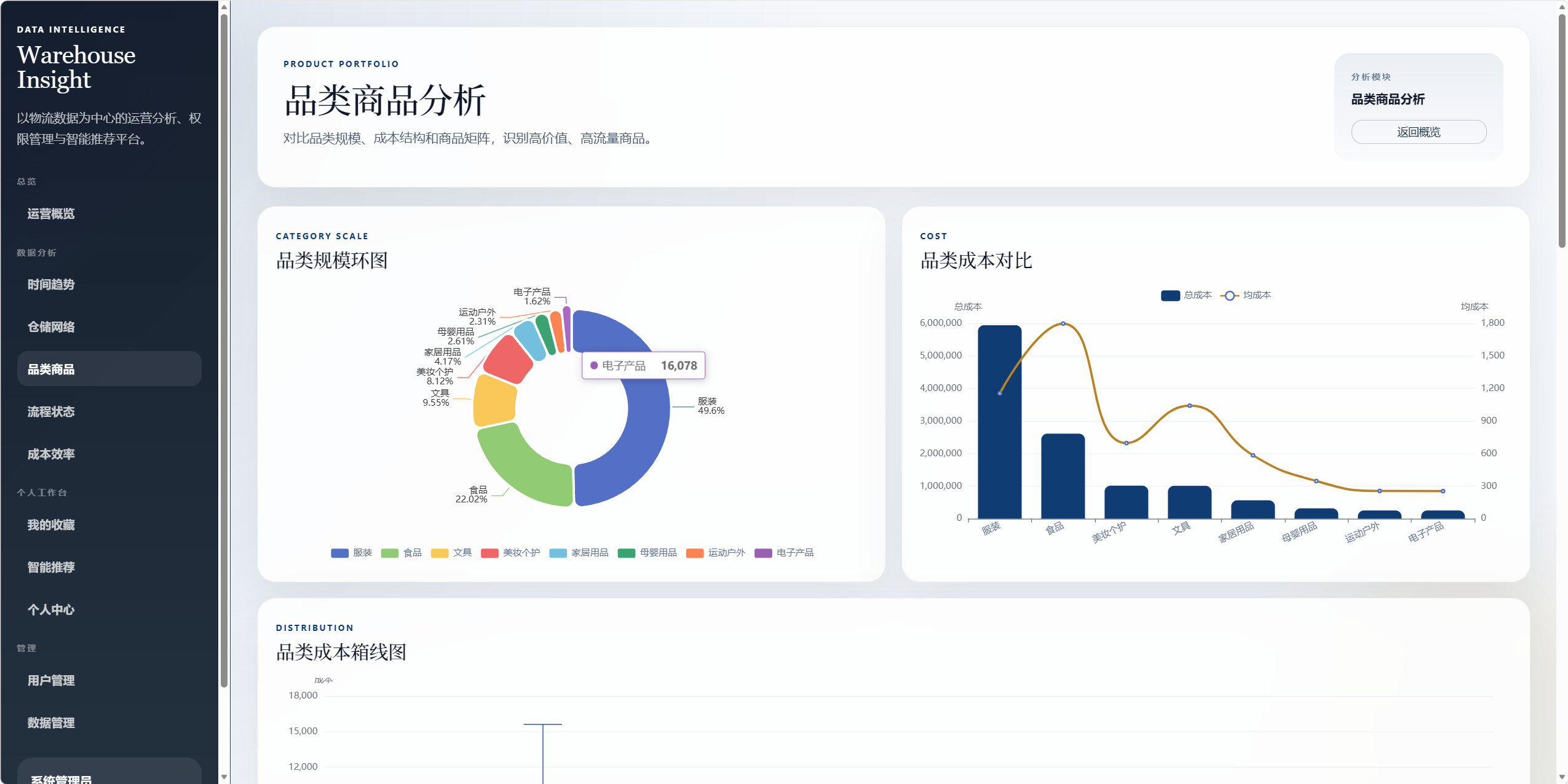
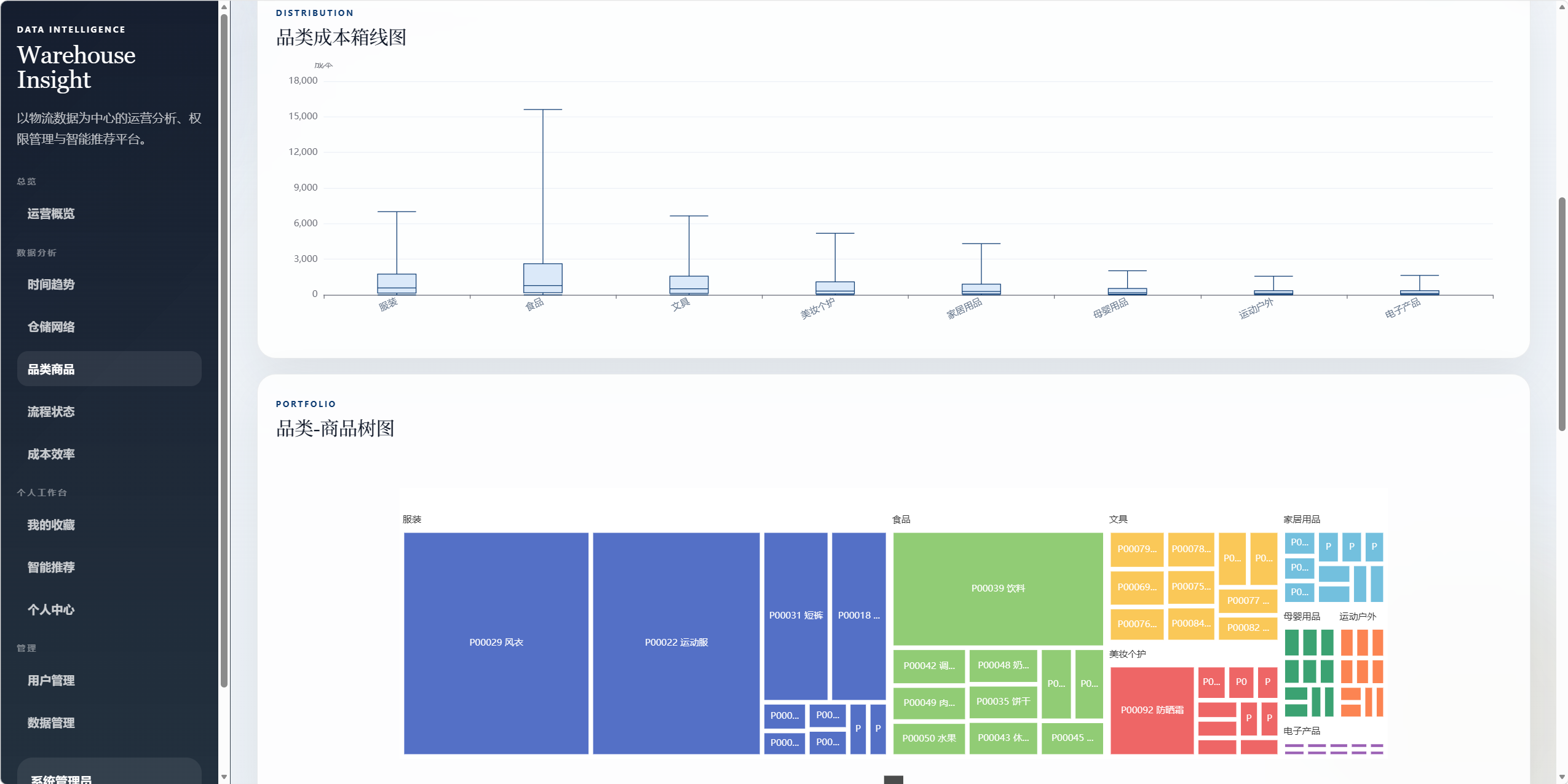
8.4 品类商品分析 /analysis/product
用于分析商品类别和商品运营表现。
图表包括:
- 品类规模环图。
- 品类成本对比图。
- 品类成本箱线图。
- 品类-商品树图。
- 商品件数与成本矩阵。
- 品类下钻趋势图。
下钻交互:
- 点击或选择品类后,展示该品类的趋势、商品排名和成本情况。
可回答的问题:
- 哪个品类吞吐量最大。
- 哪个品类成本最高。
- 哪些商品属于高流量高成本商品。
- 各品类成本分布是否存在异常。
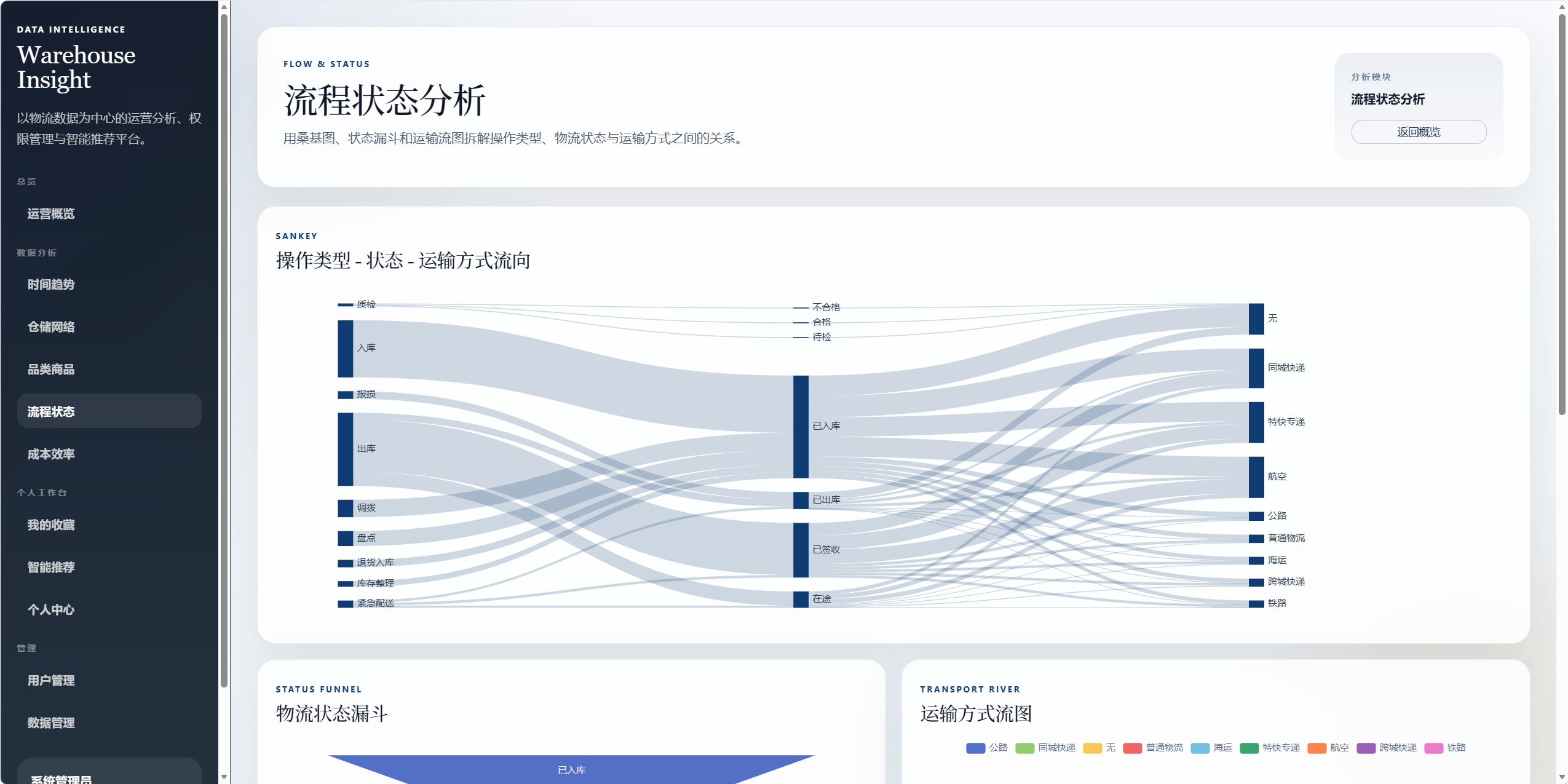
8.5 流程状态分析 /analysis/flow
用于分析操作类型、物流状态和运输方式之间的关系。
图表包括:
- 操作类型 - 状态 - 运输方式桑基图。
- 物流状态漏斗图。
- 运输方式流图。
- 操作类型结构图。
可回答的问题:
- 不同操作类型最终流向哪些物流状态。
- 哪些运输方式承担了主要物流流量。
- 状态分布是否存在明显瓶颈。
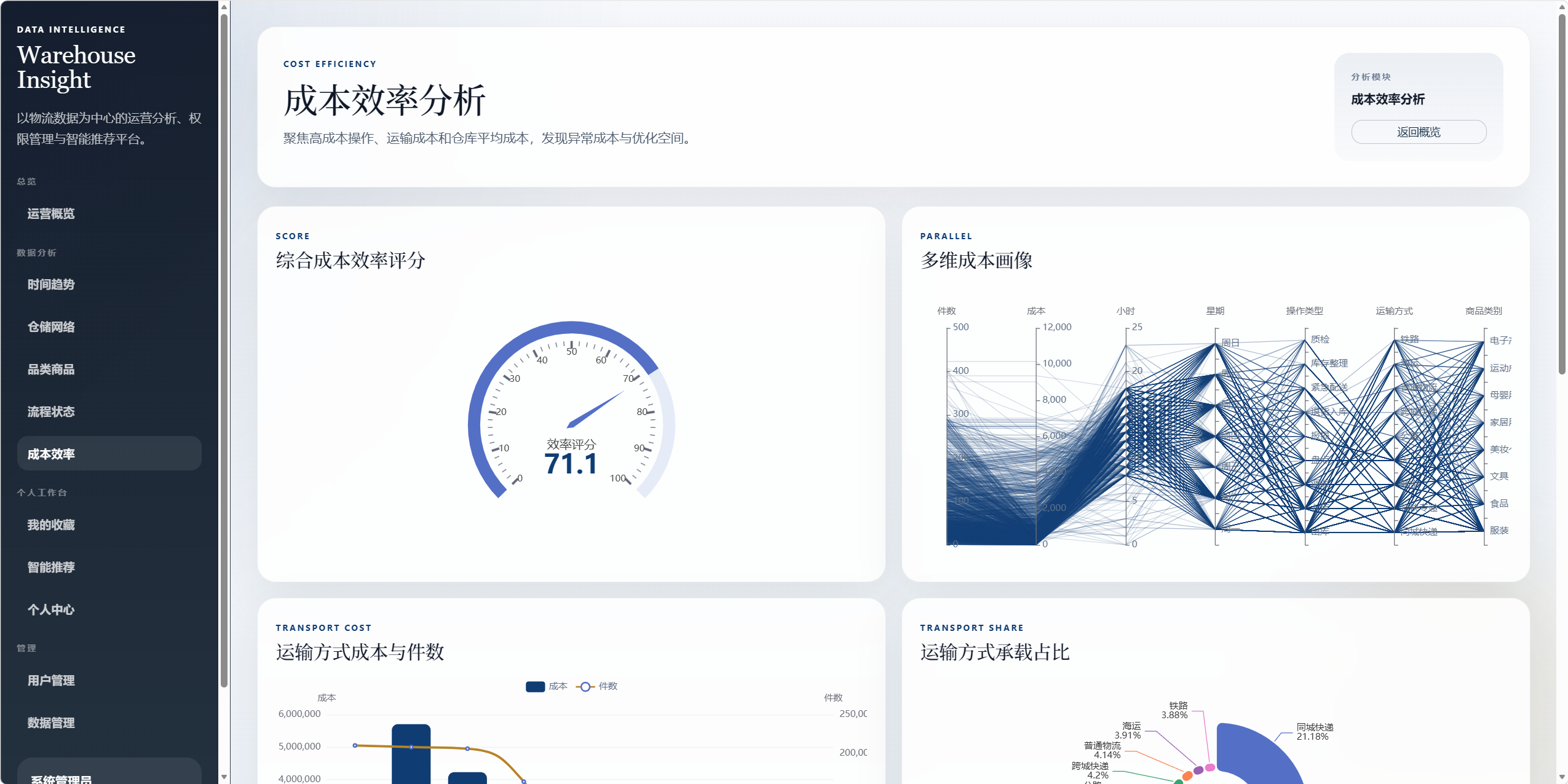
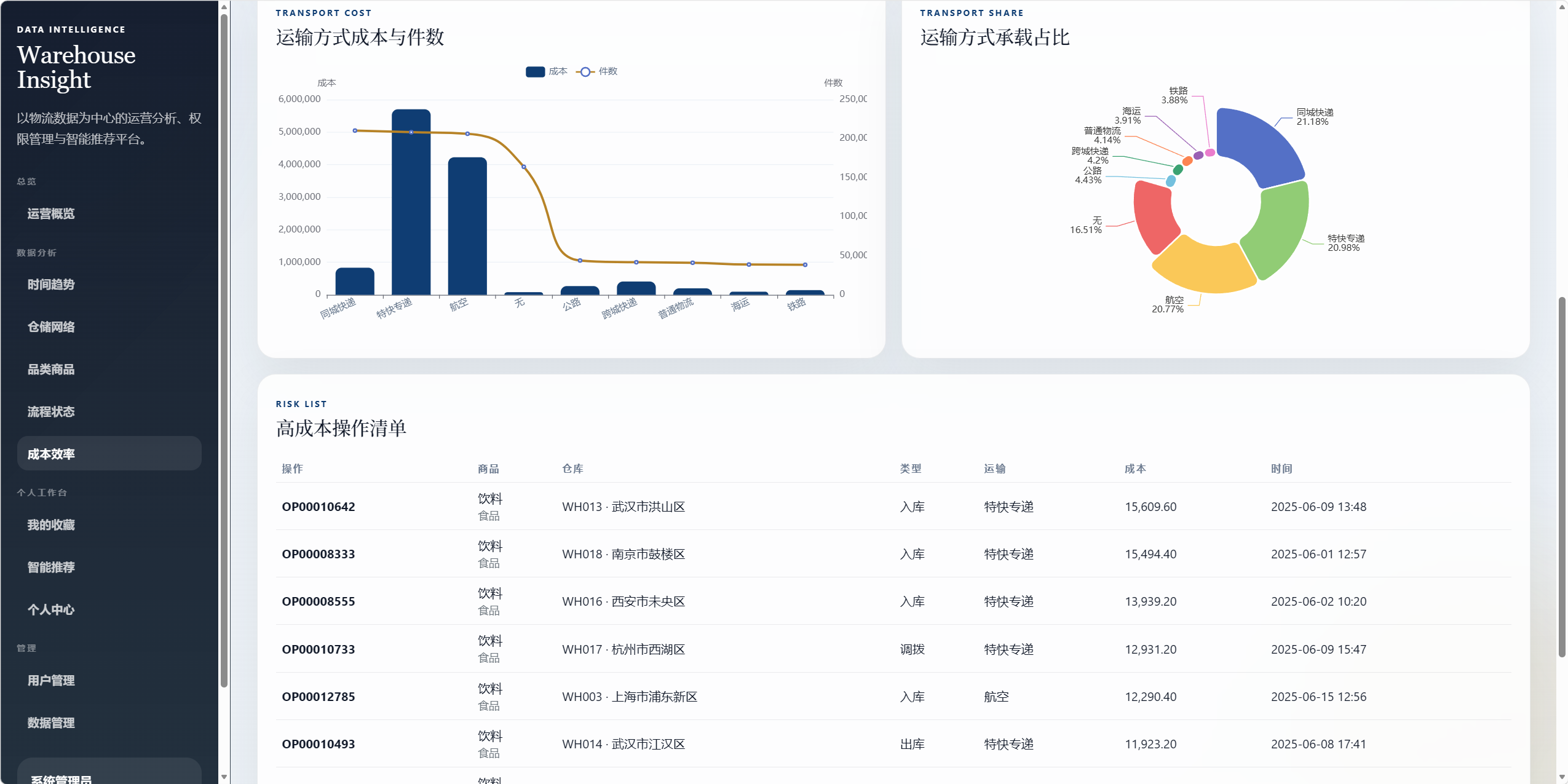
8.6 成本效率分析 /analysis/efficiency
用于分析成本结构和运营效率。
图表包括:
- 综合成本效率仪表盘。
- 多维成本画像平行坐标。
- 运输方式成本与件数对比。
- 运输方式承载占比。
- 高成本操作清单。
可回答的问题:
- 成本效率整体水平如何。
- 哪些运输方式成本压力较大。
- 哪些操作记录成本异常偏高。
- 成本与件数、操作类型、运输方式、品类之间有什么关系。
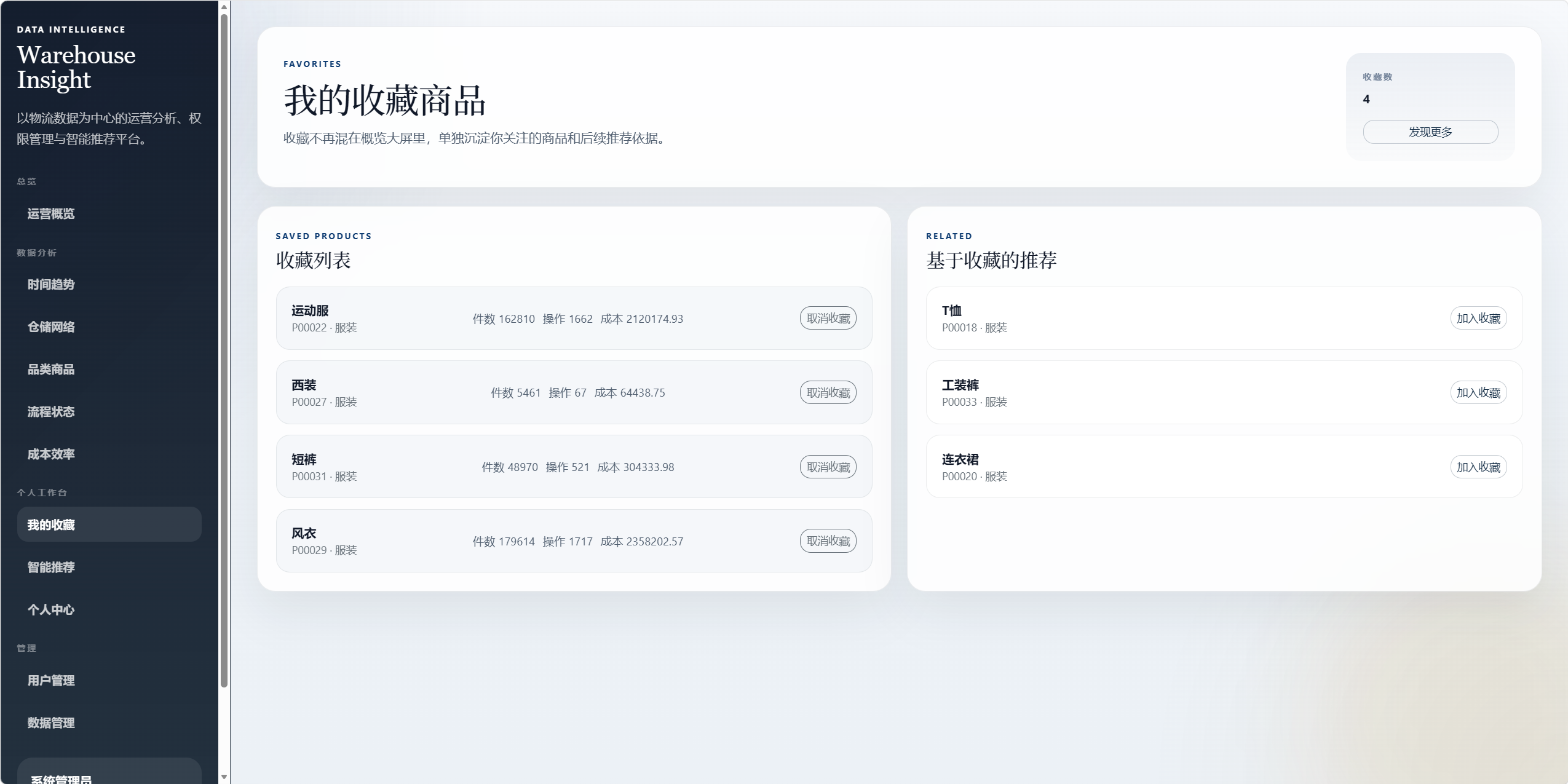
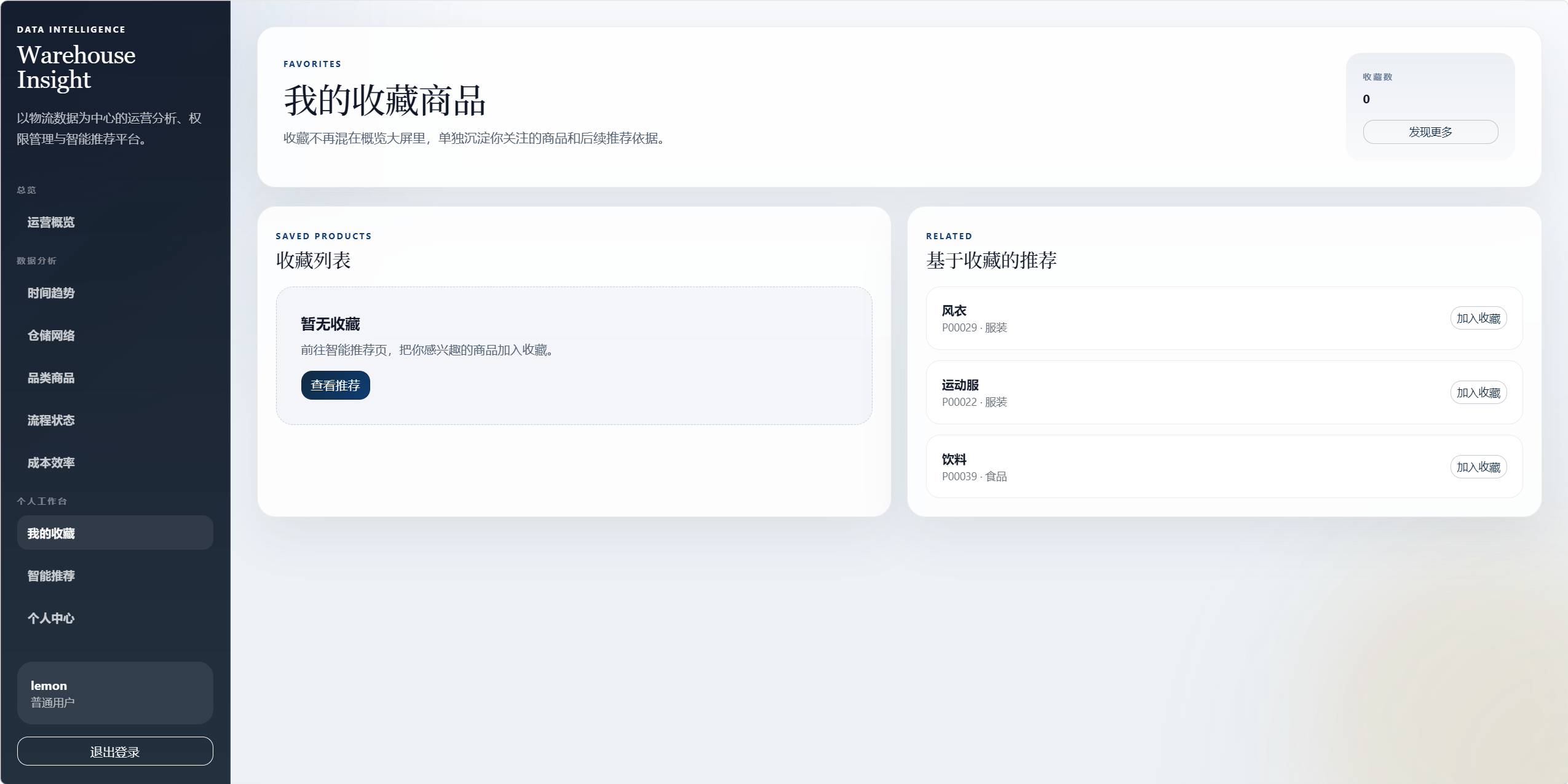
8.7 我的收藏 /favorites
收藏功能独立成页面,避免和数据分析页面混杂。
功能包括:
- 查看已收藏商品。
- 取消收藏。
- 查看基于收藏的相关推荐。
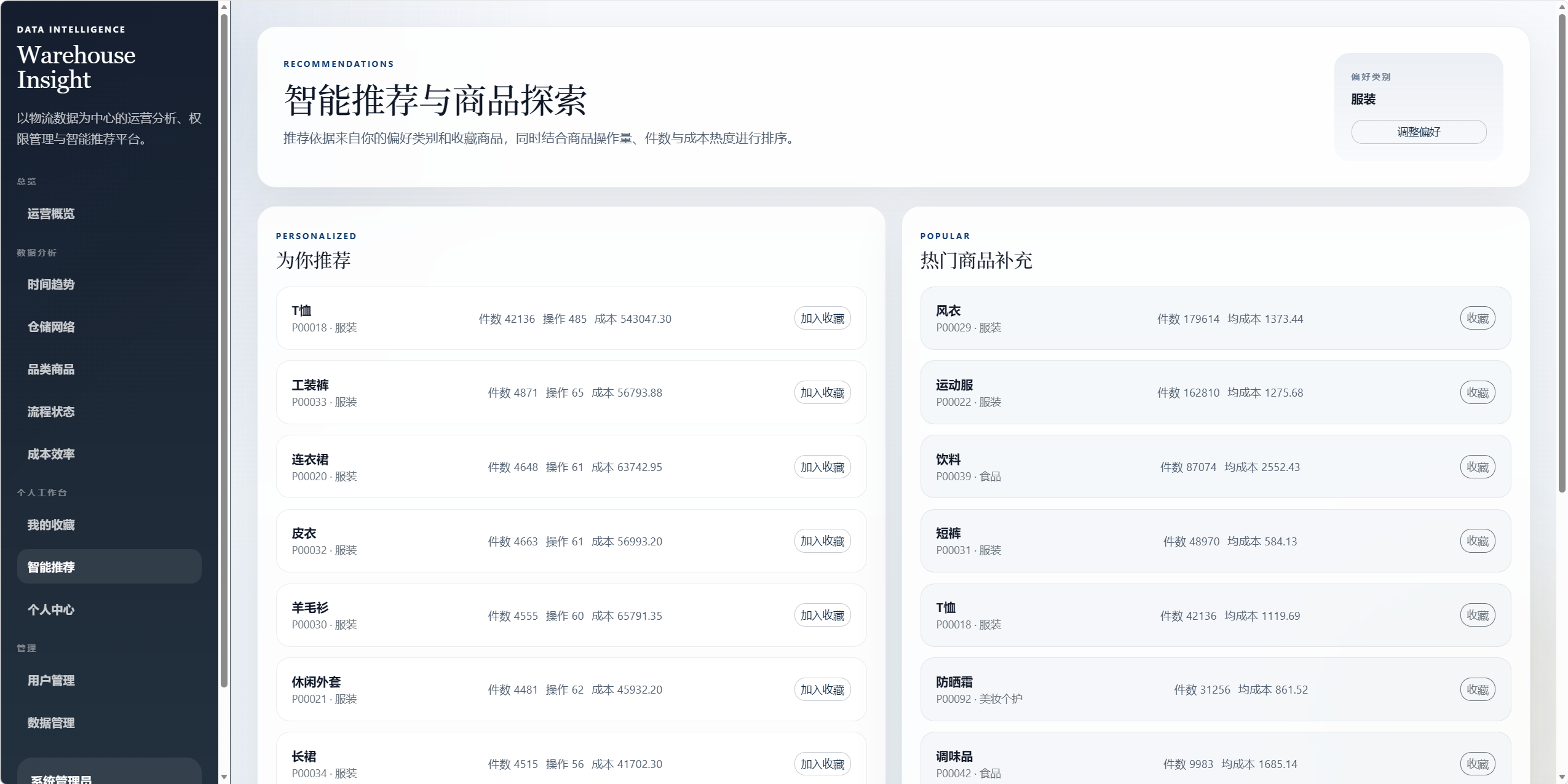
8.8 智能推荐 /recommendations
推荐功能独立成页面。
推荐依据:
- 用户偏好类别。
- 用户收藏商品所属类别。
- 商品操作量。
- 商品总件数。
- 商品总成本。
- 商品操作频次。
推荐目标:
- 帮助用户快速发现关注度高、业务价值高、与兴趣相关的商品。
8.9 个人中心 /profile
个人中心用于维护用户账号资料。
功能包括:
- 修改姓名。
- 修改邮箱。
- 修改个人简介。
- 设置偏好类别。
- 修改密码。
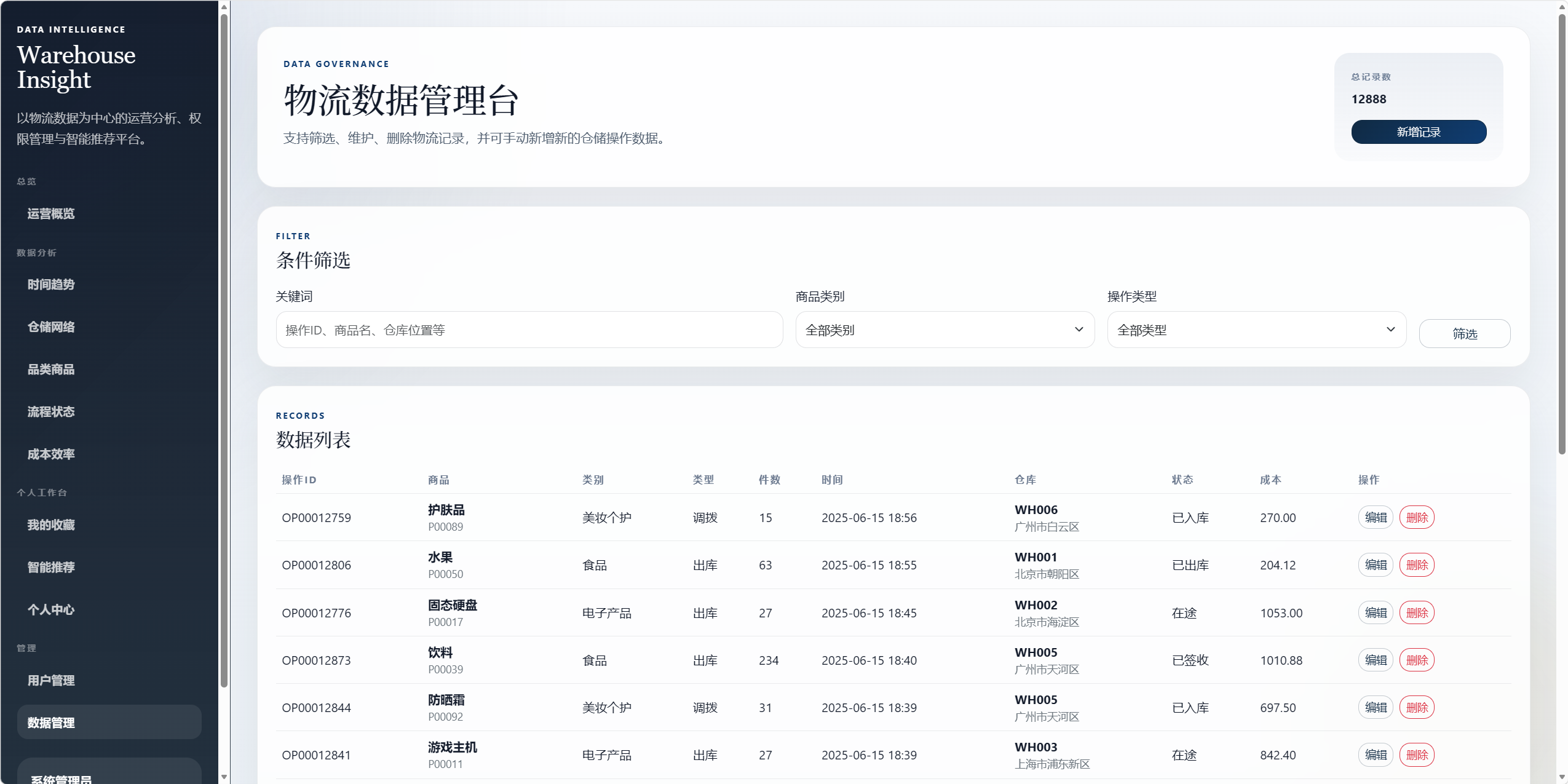
8.10 管理功能
管理员功能仍保留,主要包括:
- 用户管理。
- 用户角色切换。
- 账号启停。
- 物流数据增删改查。
9. 可视化实现
可视化数据统一由 /api/dashboard 接口提供,前端 app/static/js/dashboard.js 会根据当前页面存在的图表容器自动渲染对应图表。
这样设计的好处:
- 不同页面可以复用同一份分析数据。
- 不需要为每个页面重复编写接口。
- 页面拆分后仍能保持数据口径一致。
- 新增图表时只需扩展后端 payload 和前端渲染函数。
当前已实现的图表类型:
- 折线图。
- 柱状图。
- 环图。
- 桑基图。
- 漏斗图。
- 热力图。
- 日历热力图。
- 主题河流图。
- 树图。
- 散点图。
- 关系图。
- 箱线图。
- 平行坐标。
- 仪表盘。
- 经纬度流转图。
- 堆叠柱状图。
10. 交互设计
10.1 城市下钻
仓储网络页中,用户点击城市节点后,会触发 ECharts click 事件。
前端根据城市名称从 city_drilldown 数据集中读取该城市明细,并更新:
- 城市指标卡。
- 城市品类结构图。
- 城市热门商品表。
10.2 品类下钻
品类商品页中,用户选择品类按钮后,会读取 category_drilldown 中对应品类的数据,并更新:
- 品类趋势图。
- 品类热门商品表。
10.3 成本画像
成本效率页使用平行坐标展示多维数据。
维度包括:
- 件数。
- 成本。
- 小时。
- 星期。
- 操作类型。
- 运输方式。
- 商品类别。
该图适合观察高成本记录在多维特征上的分布情况。
11. 静态资源本地化
为避免 CDN 加载失败导致样式和图表空白,项目已将 Bootstrap 和 ECharts 复制到本地静态目录。
本地资源路径:
text
app/static/vendor/bootstrap/bootstrap.min.css
app/static/vendor/bootstrap/bootstrap.bundle.min.js
app/static/vendor/echarts/echarts.min.js模板中不再引用 cdn.jsdelivr.net,因此系统在离线或网络受限环境下也可以正常显示页面样式和图表。
12. UI 设计说明
系统 UI 参考现代商业分析产品的简约风格,整体视觉特点如下:
- 固定左侧导航栏。
- 深色侧边栏与浅色内容区形成对比。
- 卡片式分析模块。
- 大标题和清晰的信息层级。
- 柔和阴影和圆角。
- 浅色背景渐变。
- 数据图表与表格并列展示。
- 个人功能和分析功能分区清晰。
左侧导航分为:
- 总览。
- 数据分析。
- 个人工作台。
- 管理。
这样用户不会被大量图表一次性淹没,可以按分析目标逐层进入。
13. API 说明
13.1 /api/dashboard
方法:GET
认证:需要登录。
返回内容:
overview:核心指标。trend:时间趋势。calendar_heatmap:日历热力。heatmap:周内时段热力。city_route_flow:城市流转图。city_transition_graph:城市关系图。city_drilldown:城市下钻数据。category_drilldown:品类下钻数据。category_ring:品类规模。category_cost_bar:品类成本。category_cost_boxplot:品类成本分布。sankey:流程桑基图。status_funnel:状态漏斗。theme_river:运输方式流图。parallel_records:多维成本画像。high_cost_records:高成本操作清单。favorites:用户收藏。recommendations:用户推荐。
14. 推荐算法说明
推荐逻辑位于 app/services/analytics.py。
推荐策略:
- 获取用户收藏商品所属类别。
- 获取用户个人中心设置的偏好类别。
- 在这些类别中排除已收藏商品。
- 按商品热度进行排序。
排序参考因素:
- 商品累计操作数量。
- 商品操作次数。
- 商品累计成本。
该策略适合课程设计和业务演示场景,逻辑清晰、可解释性强。
15. 验证与测试
本项目已执行以下验证:
powershell
python -m compileall main.py app
node --check app\static\js\dashboard.js页面冒烟测试覆盖:
/dashboard/analysis/time/analysis/warehouse/analysis/product/analysis/flow/analysis/efficiency/favorites/recommendations/profile/api/dashboard
数据修正验证覆盖:
- CSV 数据量。
- CSV 最早和最晚时间。
- 数据库数据量。
- 数据库最早和最晚时间。
- 数据库 2024 年记录数。
16. 后续扩展建议
后续如果继续完善,可以考虑:
- 增加日期范围筛选。
- 增加城市、品类、运输方式筛选。
- 将
/api/dashboard拆分为多个细粒度接口,减少单次响应体积。 - 增加导出分析报告功能。
- 增加图表截图功能。
- 增加管理员数据导入页面。
- 增加更多推荐策略,例如协同过滤、相似商品推荐。
- 增加异常检测模型,例如高成本异常、库存波动异常。
17. 总结
本系统已经形成完整的商品物流数据分析闭环:
- 数据从 CSV 导入 MySQL。
- FastAPI 提供页面和接口服务。
- SQLAlchemy 完成数据建模和统计分析。
- Jinja2 渲染业务页面。
- Bootstrap 和自定义 CSS 提供现代化 UI。
- ECharts 提供多类型深度可视化。
- 用户系统提供登录、个人中心、收藏和推荐。
- 管理员系统提供用户管理和数据管理。
当前数据集已统一更新为 2025 年,系统功能和展示逻辑保持不变。