在刷回溯算法的组合、子集问题时,我们常常会遇到需要去重的情况。以往的套路是:先给数组排序,然后再用 nums[i] == nums[i-1] 进行去重(例如第 90 题:子集 II)。
但在今天这道 491. 递增子序列 中,这个套路彻底失效了!
踩坑预警:为什么不能排序?
题目要求我们从原数组中找出递增的子序列。
如果你一上来习惯性地把原数组排了序,那么原本不递增的序列也就变成了递增序列,完全破坏了原数组元素的相对位置。
结论:本题求自增子序列,绝对不能对原数组进行排序。 既然不能排序,我们就需要在遍历的过程中,动态地记录哪些数字在本层已经被使用过了。
思路分析:树层去重 vs 树枝去重
在回溯算法的树形结构中,我们需要明确两个概念:
-
树枝去重 :纵向递归时的去重。本题中,原数组可能包含相同的数字(如
[4, 7, 7]),合法的递增子序列是可以包含两个7的,所以树枝上不需要去重。 -
树层去重 :横向遍历(
for循环)时的去重。为了防止生成相同的子序列,同一层级不能使用数值相同的元素。所以树层上需要去重。
整体逻辑如下图所示,偷一下卡哥的图
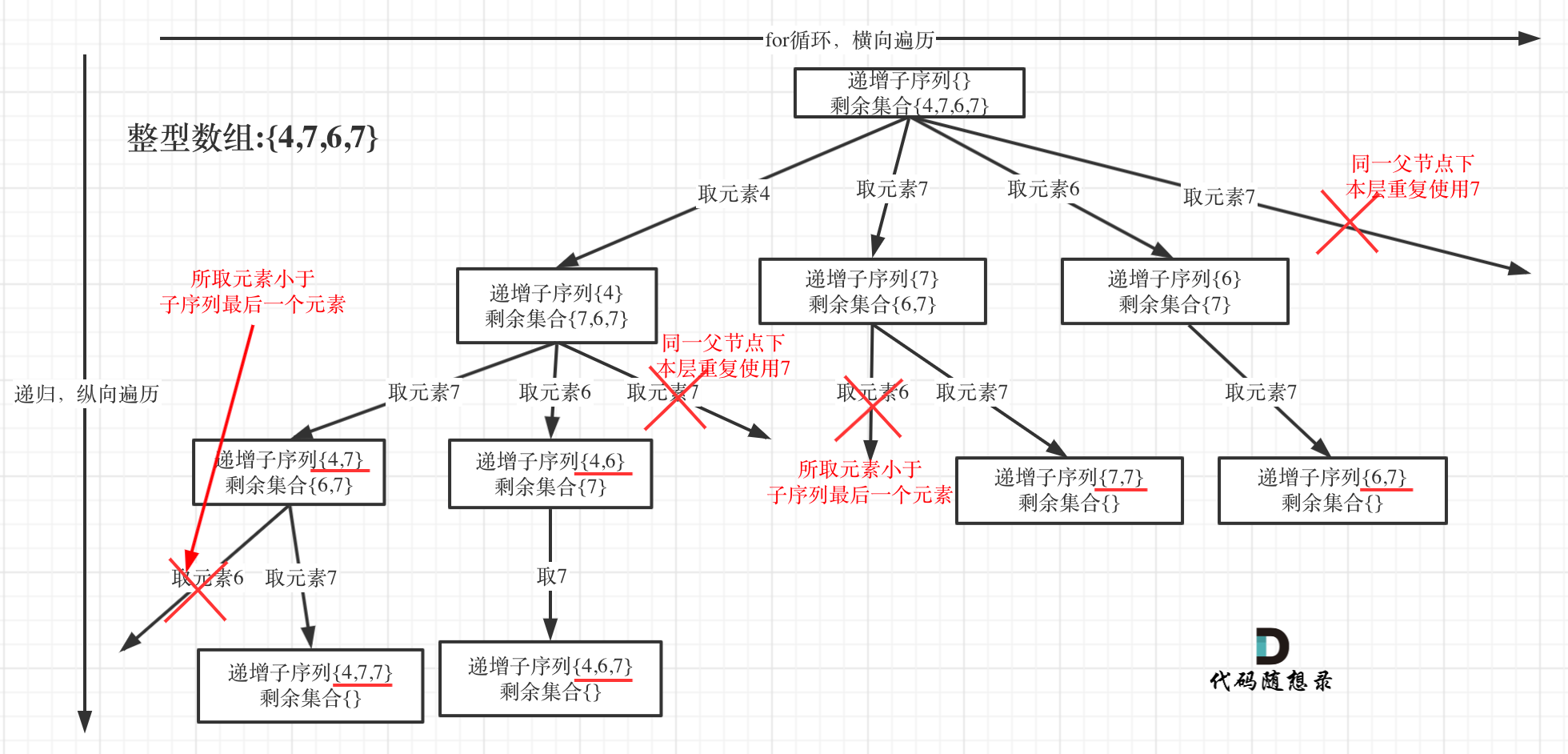
回溯三部曲
既然要树层去重,怎么实现呢?这就进入我们的回溯三部曲:
1. 递归函数参数
我们需要 startIndex 来控制每次搜索的起始位置,还需要一个全局的 path 记录当前路径,一个 result 记录最终结果。
2. 终止条件
本题其实类似求子集问题,也是要收集树形结构上所有满足条件的节点(而不是只收集叶子节点)。
注意: 题目要求递增子序列大小至少为 2。
cpp
if (path.size() > 1) {
result.push_back(path);
// 注意这里不要加 return!因为要收集树上的所有节点,比如收集了 [4, 6] 之后,还要继续向下收集 [4, 6, 7]
}3. 单层搜索逻辑(核心)
在单层遍历的 for 循环中,我们需要做两件事:
-
保证递增: 比较当前元素和
path中的最后一个元素。 -
同层去重: 在每一层定义一个哈希表(或数组)。记录当前层用过的元素,用过就跳过。
灵魂拷问:为什么去重用的
used数组不需要回溯(撤销状态)?因为我们把
used定义在了递归函数内部!每一次调用递归函数(进入下一层树枝),都会重新初始化一个全新的、空的used。它只在当前这一个for循环(这一层树层)里生效,所以不需要在递归回来后撤销状态。
代码实现
1. C++ 终极优化版 (数组哈希技巧)
在 C++ 中,如果每次都用 std::unordered_set 会涉及到频繁的哈希计算和内存分配,由于题目限制数值范围是 [-100, 100],我们完全可以用一个大小为 201 的数组来代替哈希表,这是非常有用的空间换时间技巧!
cpp
#include <vector>
using namespace std;
class Solution {
private:
vector<vector<int>> result;
vector<int> path;
void backtracking(const vector<int>& nums, int startIndex) {
// 收集节点:只要 path 长度大于 1 就加入结果集
if (path.size() > 1) {
result.push_back(path);
// 这里不要 return,要继续往下搜索
}
// 局部变量 used:只负责本层(同层)的去重
// 题目范围是 [-100, 100],加上 100 映射到 [0, 200]
int used[201] = {0};
for (int i = startIndex; i < nums.size(); i++) {
// 剪枝条件 1:当前元素小于 path 的最后一个元素,不满足递增
// 剪枝条件 2:当前元素在本层已经出现过,同层去重
if ((!path.empty() && nums[i] < path.back()) || used[nums[i] + 100] == 1) {
continue;
}
// 标记本层已使用
used[nums[i] + 100] = 1;
path.push_back(nums[i]);
backtracking(nums, i + 1);
path.pop_back(); // 回溯
// 注意:used 不需要回溯撤销!因为它只管本层,下一层会有全新的 used 数组。
}
}
public:
vector<vector<int>> findSubsequences(vector<int>& nums) {
result.clear();
path.clear();
backtracking(nums, 0);
return result;
}
};2. Python 优雅版 (Set 去重)
Python 选手可以直接使用内置的 set(),非常直观:
python
class Solution:
def findSubsequences(self, nums: List[int]) -> List[List[int]]:
res, path = [], []
def backtracking(startIdx):
if len(path) > 1:
res.append(path[:])
# 局部变量,控制同层去重
used = set()
for i in range(startIdx, len(nums)):
if (path and nums[i] < path[-1]) or (nums[i] in used):
continue
used.add(nums[i])
path.append(nums[i])
backtracking(i + 1)
path.pop()
backtracking(0)
return res3. C 语言硬核版
C 语言与 C++ 的数组哈希思路一致,只是需要手动管理内存:
objectivec
// --- 全局变量定义 ---
int** res; // 存放最终结果的二维数组
int res_count; // 记录结果集中的数组个数
int* path; // 存放当前正在搜寻的路径(子序列)
int path_count; // 记录当前路径的长度
int** column_sizes; // 记录结果集中每个一维数组的长度
// --- 回溯核心逻辑 ---
void backtracking(int* nums, int numsSize, int startIdx) {
// 收集节点:只要路径长度大于1,就存入结果集
if (path_count > 1) {
// 为当前结果分配内存
res[res_count] = (int*)malloc(sizeof(int) * path_count);
for (int i = 0; i < path_count; ++i) {
res[res_count][i] = path[i];
}
// 记录这一行的长度
(*column_sizes)[res_count] = path_count;
res_count++;
}
// 局部变量 used 数组,控制【同层去重】
// 题目限制 nums[i] 范围在 [-100, 100],加上 100 后映射到 [0, 200]
int used[201] = {0};
for (int i = startIdx; i < numsSize; ++i) {
// 剪枝条件:
// 1. 如果新加入的元素比 path 中最后一个元素小(不满足递增)
// 2. 如果该元素在本层已经被使用过(同层去重)
if ((path_count > 0 && nums[i] < path[path_count - 1]) || used[nums[i] + 100] == 1) {
continue;
}
// 标记本层该数字已使用
used[nums[i] + 100] = 1;
// 做出选择:加入路径
path[path_count++] = nums[i];
// 递归进入下一层
backtracking(nums, numsSize, i + 1);
// 回溯:撤销选择
path_count--;
// 注意:used 数组不需要撤销!因为它只控制当前这一层的循环
}
}
int** findSubsequences(int* nums, int numsSize, int* returnSize, int** returnColumnSizes) {
// 1. 预估最大结果数量
// 题目约定 nums 的长度最多为 15,子序列最多大概有 2^15 = 32768 种可能。
// 分配一个足够大的空间 35000 防止越界。
int max_res = 35000;
// 2. 初始化全局指针和计数器
res = (int**)malloc(sizeof(int*) * max_res);
path = (int*)malloc(sizeof(int) * numsSize);
// 给 returnColumnSizes 也要分配对应的空间,用来记录 res 里每一行的长度
*returnColumnSizes = (int*)malloc(sizeof(int) * max_res);
column_sizes = returnColumnSizes; // 绑定到全局变量,方便在 backtracking 中修改
res_count = 0;
path_count = 0;
// 3. 开始回溯搜索
backtracking(nums, numsSize, 0);
// 4. 设置返回参数并返回结果
*returnSize = res_count; // 告诉系统我们一共找到了多少个符合条件的子序列
return res;
}复杂度分析
-
时间复杂度: O(n * 2^n)。其中 n 是数组的长度。最坏情况下,所有元素都是递增的,总共有 2^n 个子序列,每次将合法的子序列放入结果集需要 O(n) 的时间。
-
空间复杂度: O(n)。主要消耗在于递归调用栈的深度以及辅助数据结构(
path数组),层数最深为 n。每一次调用的局部used数组大小固定为 201,是常数级别的空间开销,可以认为是 O(1),总栈空间依然是 O(n)。
总结
这道题是深刻理解回溯算法中"去重"概念的绝佳练习。
记住这个法则:
-
可以排序的去重: 排序 +
i > startIndex && nums[i] == nums[i-1]。 -
不能排序的同层去重: 在递归函数内部使用局部变量
used数组/Set,且不需要回溯used的状态。
搞懂了这个局部变量的魔法,以后遇到类似的树层去重问题,你就能一眼看破了!
照例贴上卡哥的代码随想录