论文:Sortformer: A Novel Approach for Permutation-Resolved Speaker Supervision in Speech-to-Text Systems
简称:Sortformer
作者:Taejin Park, Ivan Medennikov, Kunal Dhawan, Weiqing Wang, He Huang, Nithin Rao Koluguri, Krishna C. Puvvada, Jagadeesh Balam, Boris Ginsburg
时间:2025
会议:ICML 2025
任务:Speaker Diarization + Multi-speaker ASR Speaker Supervision
前言
端到端 speaker diarization(SD) 模型做"谁在什么时候说话",但这几年的各种比赛和真实场景需求,都倾向于解决多说话人 ASR 问题,即"谁在什么时间说了什么"。Sortformer 是英伟达团队提出,将 SD 任务丝滑融入多说话人 ASR ,能提升多说话人 ASR 的识别准确率。
一、Sort Loss
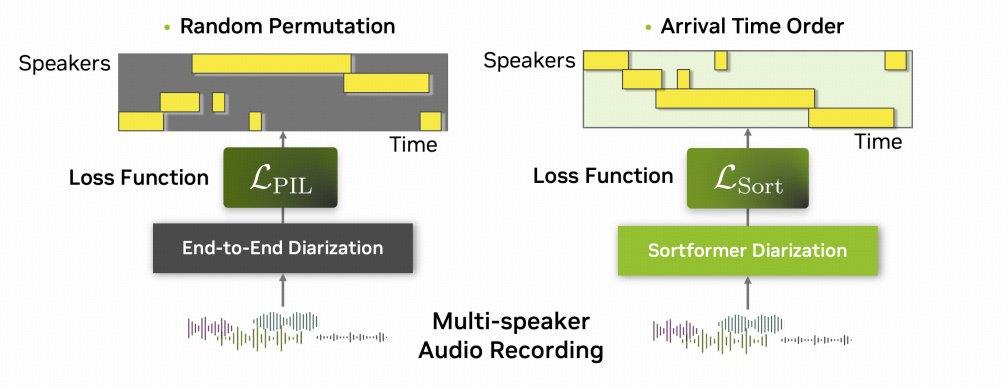
图1 Sortformer 在 PIL 基础上引入了基于首次出现时间的 Sort Loss
1.1 PIL
EEND 利用无序的 permutation invariant loss(PIL), 反向传播,找到和预测最匹配的排列。
设输入是长度为 T T T 的帧级特征序列:
X = ( x 1 , x 2 , ... , x T ) , x t ∈ R D X = (\mathbf{x}_1, \mathbf{x}_2, \ldots, \mathbf{x}_T), \quad \mathbf{x}_t \in \mathbb{R}^{D} X=(x1,x2,...,xT),xt∈RD
模型输出每一帧上 K K K 个潜在 speaker 槽位的活动概率:
P = p 1 , ... , p T = f Θ ( x 1 , ... , x T ) P = \\mathbf{p}_1, \\ldots, \\mathbf{p}_T = f_{\Theta}(\mathbf{x}_1, \ldots, \mathbf{x}_T) P=p1,...,pT=fΘ(x1,...,xT)
其中
p t = p 1 , t , p 2 , t , ... , p K , t ⊤ ∈ 0 , 1 K \mathbf{p}_t = p_{1,t}, p_{2,t}, \\ldots, p_{K,t}^{\top} \in 0,1^K pt=p1,t,p2,t,...,pK,t⊤∈0,1K
这里:
- K K K 是模型允许的最大 speaker 数
- p k , t p_{k,t} pk,t 表示第 k k k 个槽位在第 t t t 帧说话的后验概率
设
Y = y 1 , y 2 , ... , y K ⊤ ∈ R K × T Y = \\mathbf{y}_1, \\mathbf{y}_2, \\ldots, \\mathbf{y}_K^{\top} \in \mathbb{R}^{K \times T} Y=y1,y2,...,yK⊤∈RK×T
表示参考标签矩阵, P ∈ R K × T P \in \mathbb{R}^{K \times T} P∈RK×T 表示模型输出。
PIL 是在所有 speaker 排列里,找一个和预测最匹配的排列:
L P I L ( Y , P ) = min π ∈ Π 1 T K ∑ t = 1 T ∑ k = 1 K B C E ( y π ( k ) , t , p k , t ) (1) L_{\mathrm{PIL}}(Y, P) = \min_{\pi \in \Pi} \frac{1}{TK}\sum_{t=1}^{T}\sum_{k=1}^{K} \mathrm{BCE}(y_{\pi(k),t}, p_{k,t}) \tag1 LPIL(Y,P)=π∈ΠminTK1t=1∑Tk=1∑KBCE(yπ(k),t,pk,t)(1)
其中:
- Π \Pi Π 是所有 speaker 排列的集合
- π ( k ) \pi(k) π(k) 表示排列后第 k k k 个参考 speaker
- B C E ( ⋅ , ⋅ ) \mathrm{BCE}(\cdot,\cdot) BCE(⋅,⋅) 是二元交叉熵函数
观察式(1),PIL 中是所有排列算 BCE,取最小。这里不方便与后续的 ASR 耦合,因为 ASR 一般是按生成 token 算交叉熵损失,如果再跟着 PIL 一起匹配排序,逻辑就会变得很复杂。
1.2 Sort Loss
论文提出了 Arrival Time Order(ATS),将说话人按照首次出现时间排序,
Ψ ( y k ) = min { t ′ ∣ y k , t ′ ≠ 0 , t ′ ∈ 1 , T } = t k 0 \Psi(\mathbf{y}k) = \min\{t' \mid y{k,t'} \neq 0,\ t' \in 1,T\} = t_k^{0} Ψ(yk)=min{t′∣yk,t′=0, t′∈1,T}=tk0
是第 k k k 个 speaker 第一次开口的帧位置。
令 η \eta η 表示按首次到达时间排序后的索引函数,则排序后的 ground truth(GT)满足:
Y η = y η ( 1 ) , y η ( 2 ) , ... , y η ( K ) Y_{\eta} = \\mathbf{y}_{\\eta(1)}, \\mathbf{y}_{\\eta(2)}, \\ldots, \\mathbf{y}_{\\eta(K)} Yη=yη(1),yη(2),...,yη(K)
并且:
Ψ ( y η ( 1 ) ) ≤ Ψ ( y η ( 2 ) ) ≤ ⋯ ≤ Ψ ( y η ( K ) ) \Psi(\mathbf{y}{\eta(1)}) \le \Psi(\mathbf{y}{\eta(2)}) \le \cdots \le \Psi(\mathbf{y}_{\eta(K)}) Ψ(yη(1))≤Ψ(yη(2))≤⋯≤Ψ(yη(K))
有了排序后的参考标签,Sort Loss 就可以直接定义为:
L S o r t ( Y , P ) = L B C E ( Y η , P ) = 1 K ∑ k = 1 K L B C E ( y η ( k ) , q k ) L_{\mathrm{Sort}}(Y,P) = L_{\mathrm{BCE}}(Y_{\eta}, P) = \frac{1}{K}\sum_{k=1}^{K} L_{\mathrm{BCE}}(\mathbf{y}_{\eta(k)}, \mathbf{q}_k) LSort(Y,P)=LBCE(Yη,P)=K1k=1∑KLBCE(yη(k),qk)
1.3 Hybrid Loss
作者指出 ATS 的估计不是很稳定,比如说话人很多时,两人同时开口时,或者语音边界不太清晰时。加入 PIL 效果更好,于是进一步提出
L h y b r i d = α ⋅ L S o r t + ( 1 − α ) ⋅ L P I L L_{\mathrm{hybrid}} = \alpha \cdot L_{\mathrm{Sort}} + (1-\alpha)\cdot L_{\mathrm{PIL}} Lhybrid=α⋅LSort+(1−α)⋅LPIL
实验里使用的是:
α = 0.5 \alpha = 0.5 α=0.5
论文思路是
Sort Loss提供稳定顺序语义PIL提供 permutation 匹配的鲁棒性
不同于 SA-EEND / EEND-EDA,sortformer 中使用了位置编码。
二、多说话人 ASR
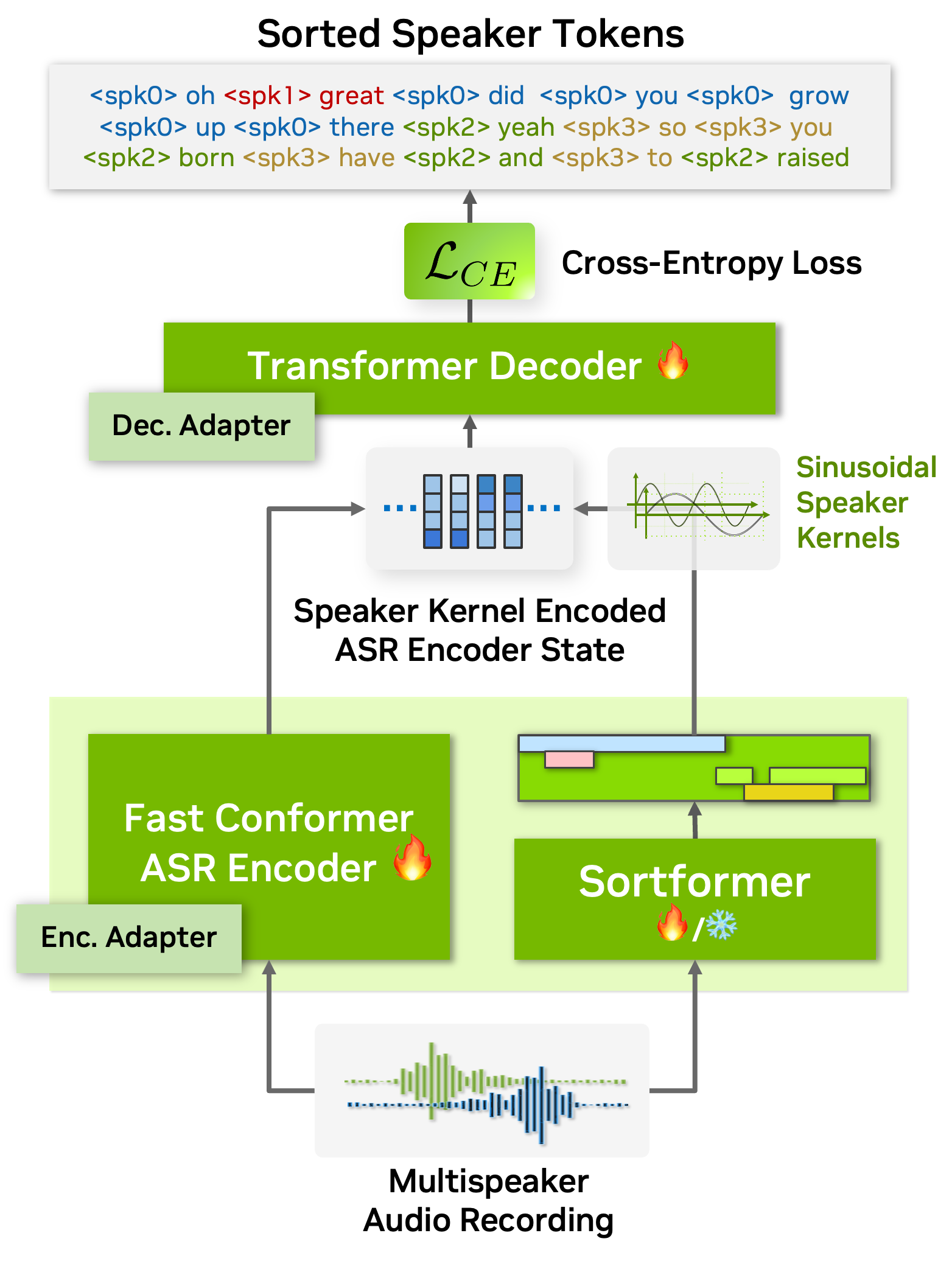
图2 MS-ASR 系统图
如图 2 所示,sortformer是 SD 模块,通过正弦说话人核(sinusoidal speaker kernels)将说话人信息融入 ASR 训练中。下面重点说明 sortformer 结构,和正弦说话人核。
2.1 sortformer
论文的 stand-alone diarizer 结构可以概括成:
text
输入声学特征
-> NEST encoder
-> 18 层 Transformer encoder
-> 2 层前馈层
-> 4 路 sigmoid 输出关键配置如下:
- 预编码器:
L-size NEST - NEST 参数量:约
115M - Transformer encoder:
18层 - hidden size:
192 - 最大 speaker 数:
4 - 总参数量:约
123M
NEST 网络是自监督预训练的 FastConformer,一个很强的预训练声学前端,可以理解为 wav2vec 2.0 / HuBERT 一类模型。
注意这里是 4 路输出,这和 EEND-EDA 不同,EEND-EDA 是确定 k k k 个说话人后,然后进行 k k k 分类。但 sortformer 是设置一个最大支持人数,然后通过 ATS 将说话人固定到靠前槽位。
2.2 正弦说话人核
设第 k k k 个说话人的正弦核为:
κ k , z = sin ( 2 π k z M ) \kappa_{k,z} = \sin\left(\frac{2\pi k z}{M}\right) κk,z=sin(M2πkz)
其中:
- M M M 是 ASR encoder state 的维度
- z z z 是 embedding 维度索引
于是第 k k k 个说话人核写成:
γ k = κ k , 1 , κ k , 2 , ... , κ k , M \gamma_k = \\kappa_{k,1}, \\kappa_{k,2}, \\ldots, \\kappa_{k,M} γk=κk,1,κk,2,...,κk,M
再把所有说话人核堆成矩阵:
Γ = γ 1 , γ 2 , ... , γ K ⊤ ∈ R K × M \Gamma = \\gamma_1, \\gamma_2, \\ldots, \\gamma_K^{\top} \in \mathbb{R}^{K \times M} Γ=γ1,γ2,...,γK⊤∈RK×M
设:
- A ∈ R M × T A \in \mathbb{R}^{M \times T} A∈RM×T 是 ASR encoder state
- P ∈ R K × T P \in \mathbb{R}^{K \times T} P∈RK×T 是 Sortformer 输出的 speaker supervision
论文用下面的方式注入 speaker 信息:
A ~ = A ∥ A ∥ 2 + Γ ⊤ P \tilde{A} = \frac{A}{\lVert A \rVert_2} + \Gamma^{\top} P A~=∥A∥2A+Γ⊤P
在 encoder 表示层上,为每个时间位置加入"属于哪个有序说话人槽位"的连续监督。即把原本纯声学的 encoder state,变成了带说话人结构的 encoder state。 这样,说话人信息变成了可微、可联合训练、可继续往 decoder 传播的中间表示。 后续的 ASR decoder,不需要再做额外 permutation matching。可以直接交叉熵损失训练
L A S R = C E ( sorted transcript , predicted logits ) L_{\mathrm{ASR}} = \mathrm{CE}(\text{sorted transcript}, \text{predicted logits}) LASR=CE(sorted transcript,predicted logits)
三、模型训练
3.1. diarization 训练数据
论文里的 Sortformer diarizer 训练数据由两部分构成:
| 数据类型 | 时长 |
|---|---|
| 真实多说话人数据 | 2030h |
| 模拟混合数据 | 5150h |
| 合计 | 7180h |
真实数据包括:
- Fisher English Training Speech Part 1/2
- AMI IHM
- DIHARD3-dev
- VoxConverse-v0.3
- ICSI
- AISHELL-4
- NIST SRE 2000 CALLHOME Part1
模拟混合数据来自:
- LibriSpeech
- NIST SRE04-10
- 开源 speech data simulator
其中模拟器参数基本用默认值,只改了:
- overlap ratio:
0.12 - average silence ratio:
0.1
3.2. diarization 训练配置
论文中的关键配置如下:
- 训练分两阶段:先用真实数据 + 模拟数据预训练,再只用真实数据微调
- 样本长度:
90s - batch size:
4 - optimizer:
AdamW - learning rate:
1e-4 - weight decay:
1e-3 - min learning rate:
1e-6 - warmup:
2500steps - scheduler:inverse square-root annealing
- 不使用 SpecAugment
- 训练资源:
8 nodes × 8 NVIDIA Tesla V100 = 64 × V100
3. 多说话人 ASR 训练数据
真实录音上的 multi-speaker ASR 训练集由以下数据混合而成:
- AMI IHM train
- ICSI
- DiPCo
- Fisher Part 1/2 中随机抽取的 30K 段
最终真实 multi-speaker ASR 训练语料约为: 230 hours 230\ \text{hours} 230 hours
四、实验结果
4.1. stand-alone diarization:Hybrid Loss 最稳
论文在 diarization 上比较了三种训练方式:
PIL onlySort Loss onlyHybrid Loss
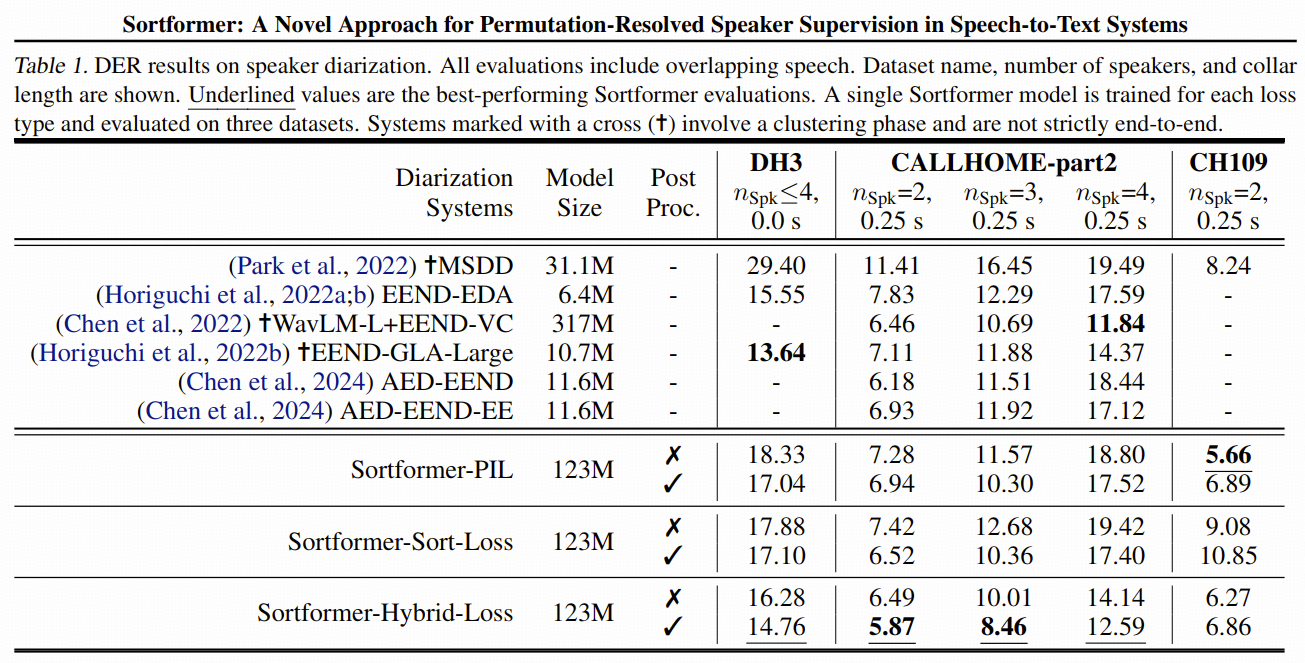
论文实验结果:Sort Loss 单独用时已经能接近 PIL;而把 Sort Loss 和 PIL 混合后,整体表现最好。
第一次看到这个实验结果,是反直觉的。因为 Sort Loss 选出的排列是 PIL 排列的其中一种,不应该加了时序信息后,两者效果一样。如果说 Sort Loss 和 PIL 结果接近,那意味着,ATS 这种排列,基本就是使 BCE 最小的排列了。
英伟达官方开源代码中,PIL 并不是严格的所有排列算 BCE,然后取最小得到的 PIL。
4.2. multi-speaker ASR:接入 Sortformer 后,WER 和 cpWER 都下降
论文在 Canary 架构上接入 Sortformer speaker supervision,观察到:
- 在真实多说话人录音上,加入 Sortformer 后 WER / cpWER 优于不带 speaker supervision 的系统
- 在
LibriSpeechMix上,Sortformer-MS-Canary相比MS-Canary,在2-mix和3-mix上分别获得了约30%和25%的相对错误率下降
五、总结
Sortformer 提供了一种将 SD 融入多说话人 ASR 的思路,局限是论文当前最多支持 4 个说话人。