一、引言
Token作为大模型计费、上下文窗口限制、推理性能评估的核心计量单位,直接关联企业采购费用、接口调用配额、服务稳定性三大关键指标。多数企业初期落地大模型应用时,仅关注功能实现,完全忽略Token消耗治理,最终出现非核心业务占用大量算力资源、个人高频测试消耗高额费用、恶意高频请求拖垮整体服务等一系列隐患。
Token精细化管控,就是针对以上痛点打造的企业级治理方案,核心围绕使用场景、访问用户、请求频率三大核心维度构建节流规则,精准统计每一次请求的输入Token、输出Token、总Token消耗,结合限流、配额分配、动态降级、用量预警等机制,在不影响核心业务正常使用的前提下,最大化压缩无效消耗、优化资源分配、控制整体运营成本。今天我们从基础概念入手,循序渐进讲解 Token 底层原理、管控核心逻辑、完整执行流程、技术实现方案、业务价值,全面理解并落地大模型Token成本优化体系。

二、Token 核心基础
1. Token的核心定义
Token 是大模型语言处理的最小语义单元,是模型理解文本、生成内容、计算消耗的基础载体。不同于日常认知中的汉字、单词、标点符号,Token是模型经过分词器拆分后的独立单元,中文、英文、数字、符号、空格都会被拆分为不同长度的Token。
在自然语言处理与大模型推理场景中,Token 可以理解为模型的"阅读单位",无论是用户输入的提问文本、上传的文档内容、历史对话上下文,还是模型最终生成的回复内容,都会被统一转化为 Token 序列,模型只能基于 Token 序列进行语义理解、逻辑推理与内容生成。
2. Token拆分规则与换算逻辑
不同大模型拥有专属的分词器,拆分规则存在细微差异,但通用换算规律具备统一性。在中文场景下,1个汉字约等于1.5~2个Token,1个英文单词约等于1.2个Token,标点、数字、空格通常单独占用1个Token,长句、复杂专业词汇、乱码字符会进一步增加Token消耗。
以主流通用大模型为例,一段500字的中文业务提问,输入Token大约在750~1000区间,模型生成同等长度的回复会产生等量甚至更多的输出Token。市面上所有公有云大模型接口、私有化部署大模型服务,均采用输入Token + 输出Token分开计费的模式,输出Token单价普遍高于输入Token,这也意味着大段内容生成、长文案创作类场景,会成为成本消耗的核心源头。
3. Token与企业成本的关联
企业级大模型使用过程中,Token 的影响覆盖成本、性能、服务稳定性三大维度。
- 第一是计费成本,公有API按照百万Token阶梯定价,私有化部署虽然无按次计费,但Token总量越高,GPU显存占用、推理时长、算力损耗就越高,间接增加服务器硬件与运维成本。
- 第二是上下文限制,所有大模型都存在固定上下文窗口,如4K、8K、32K上下文,本质就是限制单次请求的最大Token总量,若对话上下文过长、输入内容冗余,会触发上下文溢出,导致对话中断、内容截断。
- 第三是资源挤占问题,企业内部多部门、多用户共用一套大模型服务时,部分高频用户、非核心场景会持续消耗大量Token,导致核心业务高峰期Token资源不足、接口响应延迟、请求排队拥堵。
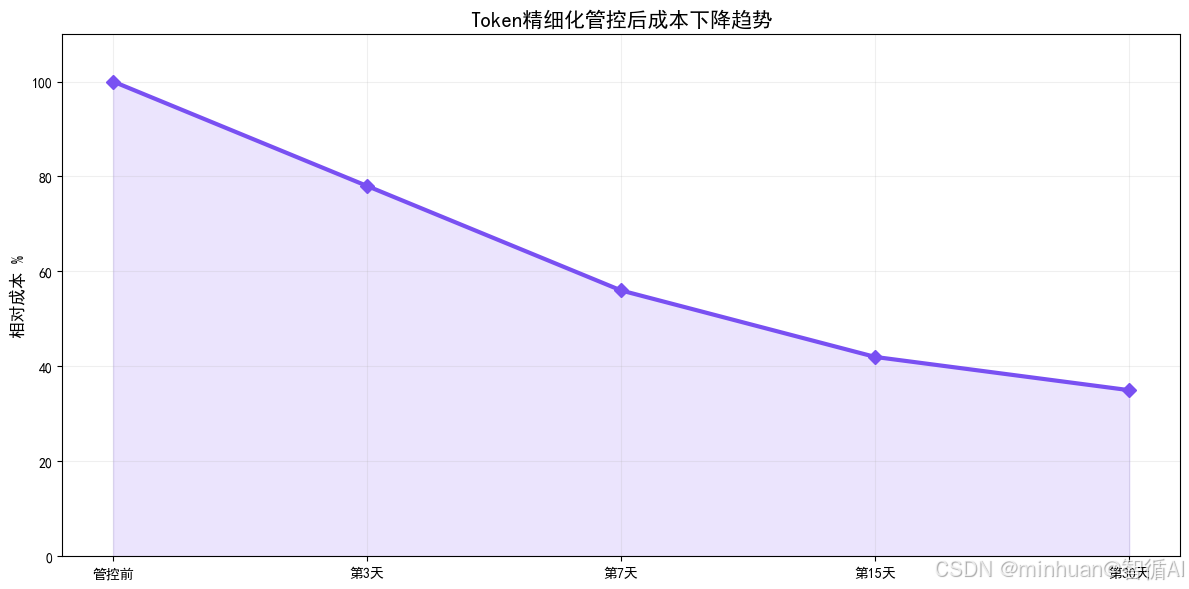
4. Token精细化管控基础
简单来说,Token 精细化管控并非限制大模型的正常使用,而是合理分配、精准管控、按需节流。传统粗放式管理无任何限制,所有用户、所有场景共用无上限配额;
而精细化管控会对不同业务场景划分优先级,对企业内部用户设置每日、每月 Token 配额,对短时间高频重复请求设置频率节流,从源头杜绝无效消耗与资源浪费。
三、Token 消耗底层原理
1. 大模型请求全流程的Token产生原理
每一次完整的大模型对话请求,都会完整产生输入Token与输出Token两大消耗项,两个消耗项的生成具备固定的底层逻辑。
1.1 输入Token
- 用户发起请求时,客户端会将用户提问、历史对话记录、系统提示词、引用的知识库文档片段等全部文本内容,统一传输至大模型服务端。
- 服务端接收文本后,会调用内置Tokenizer分词器,对全部文本进行格式化清洗与分词拆分,转化为模型可识别的数字向量序列,这一过程拆分出的所有单元,即为输入Token。
系统提示词是极易被忽略的高消耗点,实际应用中固定的角色设定、规则约束、输出格式要求,会长期占用固定输入Token,日积月累形成大量固定消耗。
1.2 输出Token
- 模型完成语义解析与逻辑计算后,开始生成回复内容,每输出一句话、一个词汇,都会实时生成对应的Token单元,最终拼接为完整回复文本,这部分动态生成的内容,即为输出 Token。
模型生成内容属于自回归逐Token输出模式,内容越长、逻辑越复杂、格式越繁琐,输出Token消耗越高,推理耗时也会同步增加。
2. 不同业务场景的Token消耗差异原理
企业内部不同业务场景的Token消耗结构存在本质区别,这也是按场景节流管控的核心依据:
- 智能客服、简短问答、指令纠错等轻量化场景,输入文本简短、回复内容精炼,整体 Token 消耗低、请求频次高;
- 长文案撰写、行业报告生成、多文档总结、RAG 知识库问答等重型场景,需要加载大量参考文档,输入 Token 基数大,模型长文本输出进一步拉高整体消耗。
- AI智能体、多轮连续对话场景存在特殊消耗特征,多轮对话会持续拼接历史上下文,每一轮提问都会叠加过往所有对话的Token,随着对话轮次增加,单次请求 Token消耗会呈线性上涨,极易快速耗尽上下文窗口与用户配额。
- 测试场景、临时查询场景、内部员工娱乐式提问属于无效高消耗场景,无业务价值但请求随意、无节制,是企业成本浪费的主要来源,需要通过场景分级进行严格节流限制。
3. 请求频率过高引发的Token连锁损耗原理
单纯的单次Token消耗可控,但高频密集请求会引发连锁损耗,放大成本压力:
- 短时间内大量重复请求会让大模型服务端持续处于高负载状态,缓存机制失效、重复分词计算、显存频繁占用释放,同等业务量下产生额外的隐性Token损耗与算力损耗。
- 高频请求会触发模型接口的并发限制,若无频率节流管控,会出现接口限流报错、请求超时、服务熔断等问题,影响核心业务使用。
从底层原理来看,频率节流本质是通过限制单位时间内的请求次数、单位时间内的累计 Token 总量,平滑请求峰值,避免瞬时资源挤占,既控制 Token 消耗,又保障服务稳定性。
四、Token 精细化管控维度
1. 按业务场景分层节流管控
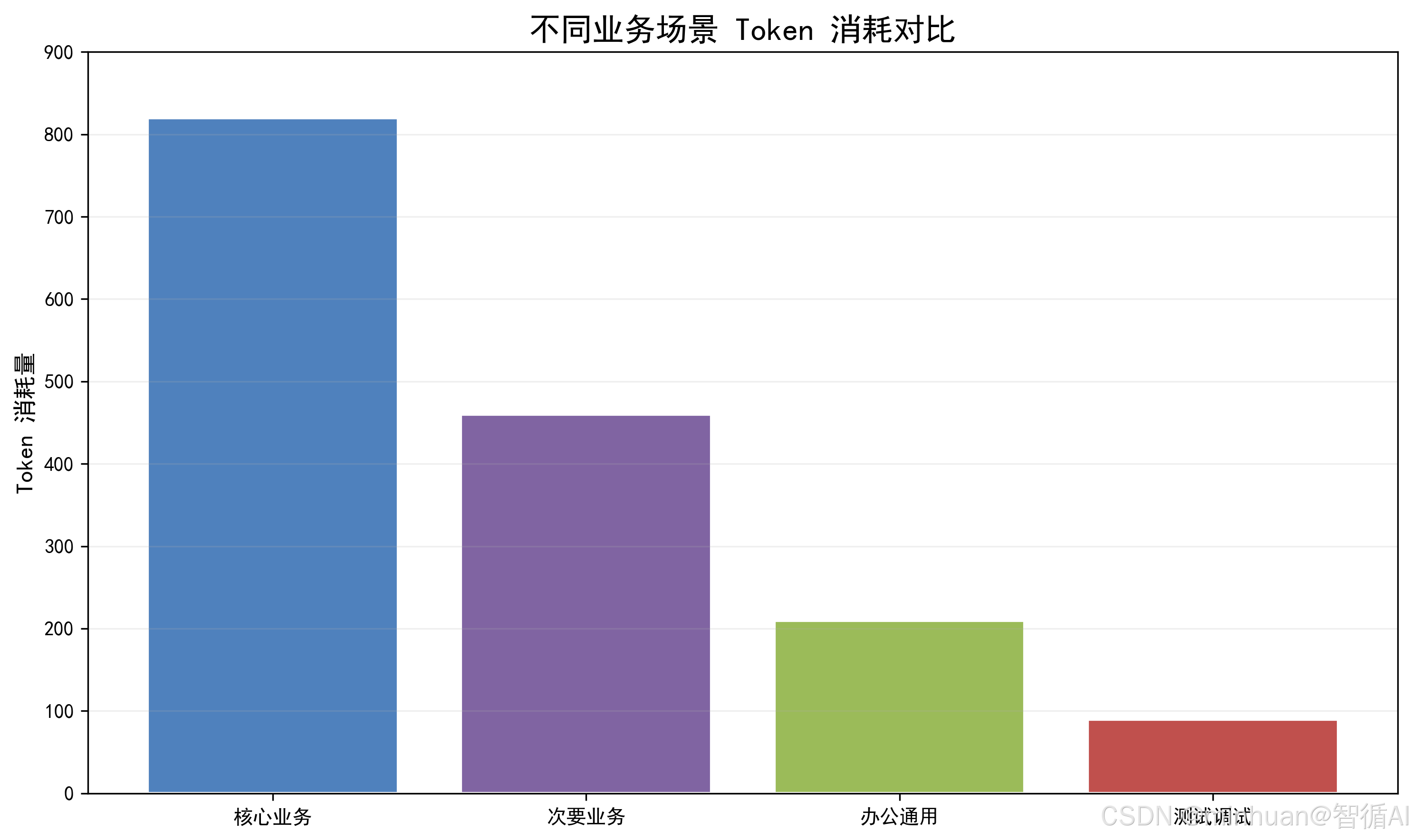
场景化管控是Token精细化治理的第一层核心架构,核心思路是业务分级、配额差异化、规则定制化。结合企业业务价值与使用刚需,可将大模型使用场景划分为核心业务场景、次要业务场景、通用办公场景、测试临时场景四大类别。
1.1 核心业务场景
- 此场景包含对外智能客服、客户咨询解答、核心业务流程 AI 辅助、付费产品 AI 能力等;
- 这类场景直接关联企业营收与客户体验,需要配置无限制或高额度Token配额,仅做用量监控,不做严格限流降级。
1.2 次要业务场景
- 此场景涵盖内部业务报表生成、部门协作文案优化、常规数据解析等;
- 具备固定业务价值,但容错性较高,可设置每日固定Token配额,超出配额后触发内容精简、模型降级(切换小参数低成本模型)等节流策略。
1.3 通用办公场景
- 此场景为全员日常文案修改、简单提问、会议纪要整理等轻量化需求;
- 使用人数多、使用频次高、单条消耗低但整体总量庞大,需要设置严格的单场景Token上限、单次输入输出长度限制,压缩冗余内容消耗。
1.4 测试与临时场景
- 此场景包含开发调试、员工个人测试、临时碎片化提问;
- 无正式业务价值,是成本浪费重灾区,需配置最低额度配额,限制短文本输入、禁止长内容生成,超额直接拦截请求。
场景管控的技术落地核心是为每一类场景分配独立场景标识,请求携带场景ID进行上报,服务端基于场景ID匹配预设的Token阈值、限流规则、模型规格,实现全自动差异化节流。
2. 按用户维度配额化精细管控
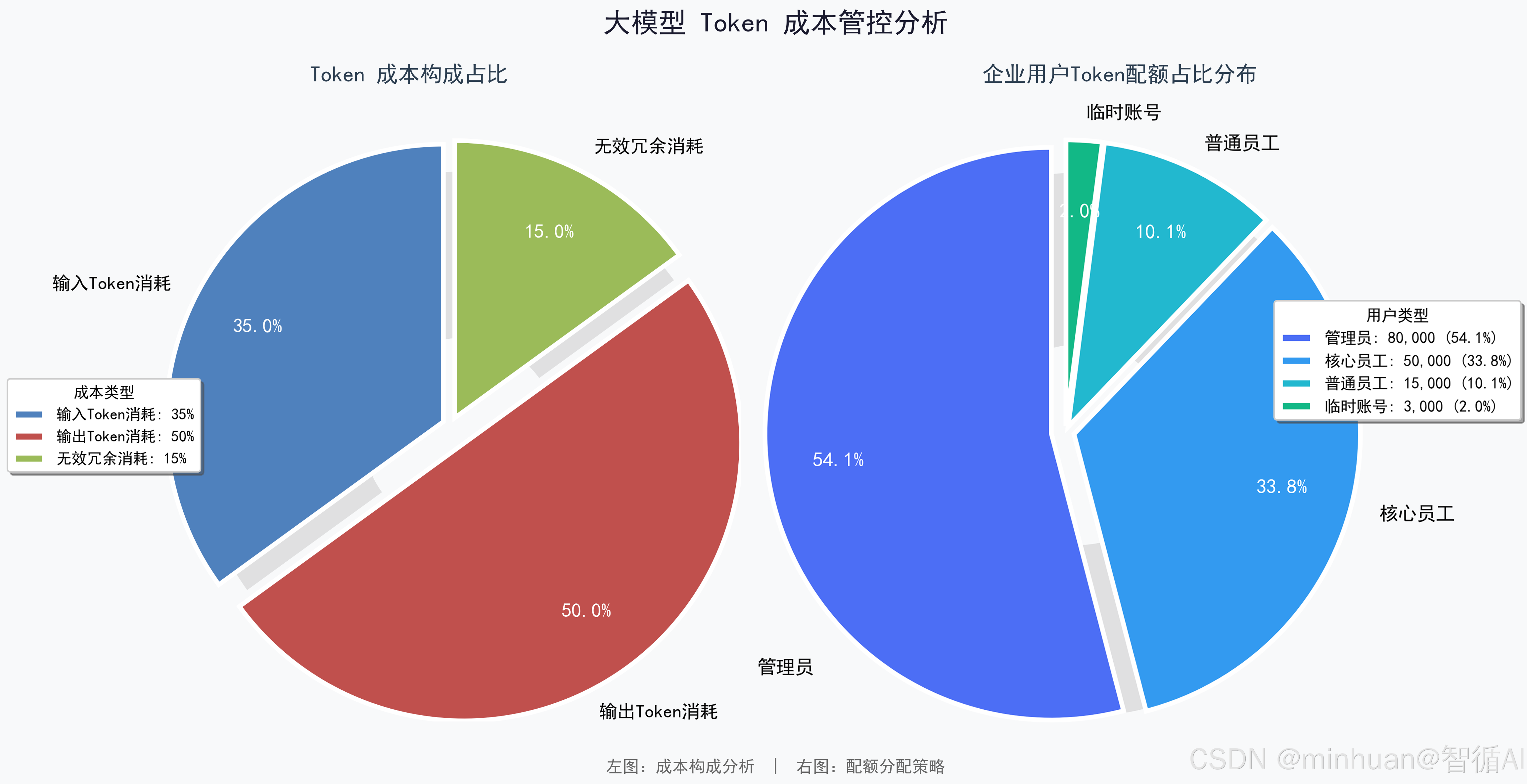
用户维度管控聚焦资源公平分配、杜绝个体滥用,适配企业多员工、多账号、多角色共用大模型服务的架构。企业内部可按照组织架构、岗位角色、使用权限划分用户等级,包括管理员用户、业务正式用户、普通员工用户、临时访客用户。
不同用户等级配置差异化的每日Token总额度、单次请求Token上限、月度累计用量上限:
- 业务核心岗位员工配置高配额,满足高频业务使用需求;
- 普通员工配置基础配额,覆盖日常轻量化办公需求;
- 临时访客、外部合作人员配置极低配额,防止外部资源滥用。
同时需要搭建用户级用量统计体系,实时记录每一位用户的累计输入Token、输出Token、请求次数、峰值使用时段:
- 针对长期超额使用、非工作时段高频调用的用户进行用量预警;
- 针对异常账号的批量请求、恶意刷量行为进行自动拦截。
用户管控的核心价值在于打破"平均化资源分配"的弊端,让Token资源向高价值使用者倾斜,避免少数高频用户占用过半算力资源,保障整体使用公平性与成本可控性。
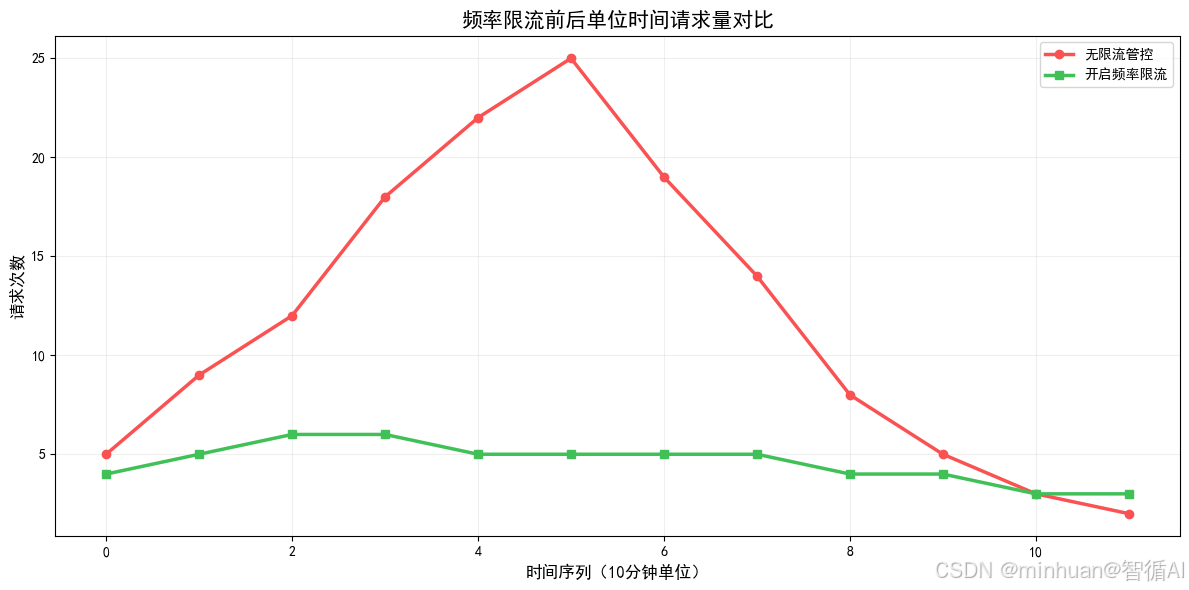
3. 按请求频率动态限流节流
请求频率管控是抵御瞬时流量冲击、控制短期Token暴涨的关键手段,分为请求次数限流与流量 Token 限流两种模式。请求次数限流针对接口调用频次,限制单用户、单场景每分钟或每小时最大请求次数,防止短时间内密集刷屏式调用。
流量Token限流更加精细化,不单纯限制请求次数,而是统计单位时间内的累计Token消耗,例如限制单用户每小时累计消耗不超过5000Token,即使请求次数少,但单次大Token长文本请求,也会触发节流限制。
频率管控支持动态弹性策略:
- 工作日白天业务高峰期适度放宽限流规则,保障业务运转;
- 夜间、节假日低峰期收紧限制,关闭非核心场景的大模型能力,最大限度降低闲置消耗。
- 搭配滑动窗口限流算法,替代传统固定窗口限流,避免临界时间点的流量峰值击穿,让节流规则更加平滑合理。
五、Token 精细化管控流程

1. 请求接入与参数捕获
- 所有大模型接口请求统一接入网关层或中间件层,作为 Token 管控的统一入口,实现全请求无遗漏拦截。
- 请求到达后,系统自动捕获三大核心关键参数:请求所属场景标识、发起请求的用户唯一 ID、请求时间戳、原始输入文本、模型参数配置。
- 调用Tokenizer分词工具,实时计算当前请求的预估输入Token,提前判断输入内容是否超长、是否超出场景与用户的单次配额限制。
- 若输入Token直接超限,无需转发至大模型服务,直接提前拦截并返回友好提示,节约无效接口调用成本。
这一步是前置节流的关键,能够从源头拦截高消耗无效请求,减少大模型服务的无用算力消耗。
2. 多维规则校验与权限判断
完成Token预计算后,系统依次执行三层规则校验,顺序为场景规则→用户配额规则→频率限流规则。
- 首先校验当前场景的运行状态、场景每日剩余 Token 配额、场景允许使用的模型规格,禁止低优先级场景调用高成本大参数模型。
- 其次校验当前用户的当日、当月累计 Token 用量,判断是否超出个人配额上限,若已超额则触发降级或拦截;
- 最后通过滑动窗口统计当前用户、当前场景的近期请求频次与累计 Token 流量,校验频率限流规则,判断是否存在高频异常调用。
三层规则全部校验通过后,请求才会正常放行;任意一项规则触发阈值,会执行预设的节流策略,包括请求拦截、模型降级、内容精简、延迟响应、用量预警五种处理方式,根据业务优先级自动匹配。
3. 大模型推理执行与实时Token统计
放行后的请求转发至大模型推理服务,模型完成语义处理与内容生成后,返回完整回复内容;服务端返回精准的实际输入Token、实际输出Token、总消耗 Token官方统计数据。
相较于前端预估Token,模型原生返回的统计数据具备绝对精准性,会作为后续计费、用量统计、配额扣减的核心依据;系统同步记录本次请求的全量日志,包含用户信息、场景信息、时间、输入输出 Token、模型类型、消耗耗时、处理状态,形成完整的 Token 消耗日志台账。
4. 配额扣减、数据汇总与用量监控
基于精准Token消耗数据,实时扣减对应用户、对应场景的剩余配额,更新当日、累计用量统计数据。台定时任务按小时、按天、按维度汇总消耗数据,生成多维度报表,包含场景消耗排行、用户消耗排行、时段消耗分布、模型成本占比等。
配置多级预警机制,当场景配额剩余不足 20%、用户用量接近上限、整体日消耗同比暴涨时,自动推送短信、企业微信、邮件预警通知,方便运维与业务人员及时调整管控策略,避免成本失控。
5. 动态策略调整与闭环优化
Token管控并非固定规则,需要形成闭环优化机制。定期复盘全量消耗数据,分析高消耗场景的合理性、高频用户的使用诉求、限流规则的严苛程度:
- 针对合理的业务增长需求,适度上调配额;
- 针对无效消耗持续偏高的场景,收紧节流规则;
- 针对模型成本差异,引导低价值场景切换轻量化模型。
六、应用实践
基于本地的google-bert/bert-base-chinese分词器实现精准Token 计算,实现场景管控、用户配额、频率限流三大核心能力,包含请求校验、Token 统计、配额扣减、限流判断全流程
python
import time
import threading
from collections import defaultdict
from transformers import AutoTokenizer
from modelscope.hub.snapshot_download import snapshot_download
import matplotlib.pyplot as plt
# ===================== 1. 初始化基础配置 =====================
# 设置中文字体
plt.rcParams['font.sans-serif'] = ['SimHei', 'Arial']
plt.rcParams['axes.unicode_minus'] = False
cache_dir = "D:\\modelscope\\hub"
model_name = "google-bert/bert-base-chinese"
# 下载模型到本地
local_bert_path = snapshot_download(
model_name,
cache_dir=cache_dir,
revision="master"
)
# 加载模型和分词器(选用轻量级的bert-base-chinese,CPU可运行)
tokenizer = AutoTokenizer.from_pretrained(local_bert_path)
# 场景等级配置:key=场景ID,value=每日总Token配额、允许最大单次Token
scene_config = {
"core_service": {"daily_quota": 100000, "single_max_token": 8000, "level": 1},
"business_office": {"daily_quota": 50000, "single_max_token": 4000, "level": 2},
"daily_office": {"daily_quota": 20000, "single_max_token": 2000, "level": 3},
"test_debug": {"daily_quota": 5000, "single_max_token": 1000, "level": 4}
}
# 用户配额配置:key=用户ID,value=每日Token配额
user_quota_config = {
"user_admin_001": 80000,
"user_biz_002": 50000,
"user_staff_003": 15000,
"user_test_004": 3000
}
# 频率限流配置:每分钟最大请求数、每分钟最大Token消耗
rate_limit_config = {
"req_per_min": 10,
"token_per_min": 5000
}
# ===================== 2. 全局统计存储(内存级) =====================
# 场景每日消耗、用户每日消耗
scene_used_token = defaultdict(int)
user_used_token = defaultdict(int)
# 频率限流:滑动窗口统计(时间戳列表、Token消耗列表)
user_req_time = defaultdict(list)
user_min_token = defaultdict(list)
# 时间工具
def get_current_timestamp():
return time.time()
# ===================== 3. 核心工具方法 =====================
# 计算文本Token数量
def calc_text_token(text: str) -> int:
"""精准计算文本Token数量"""
tokens = tokenizer.encode(text, truncation=False)
return len(tokens)
# 清理过期限流数据(滑动窗口60秒)
def clear_overdue_data(user_id: str):
now = get_current_timestamp()
# 清理60秒外的请求记录
user_req_time[user_id] = [t for t in user_req_time[user_id] if now - t < 60]
user_min_token[user_id] = user_min_token[user_id][-len(user_req_time[user_id]):]
# ===================== 4. 三层规则校验核心方法 =====================
def check_scene_rule(scene_id: str, input_token: int) -> tuple[bool, str]:
"""场景规则校验:配额+单次上限"""
if scene_id not in scene_config:
return False, "非法场景ID,禁止访问"
config = scene_config[scene_id]
# 单次Token超限
if input_token > config["single_max_token"]:
return False, f"当前场景单次Token上限{config['single_max_token']},请求超限"
# 每日场景配额超限
if scene_used_token[scene_id] + input_token > config["daily_quota"]:
return False, f"【{scene_id}】场景今日Token配额已用尽,请稍后再试"
return True, "场景校验通过"
def check_user_rule(user_id: str, input_token: int) -> tuple[bool, str]:
"""用户配额规则校验"""
if user_id not in user_quota_config:
return False, "非法用户,禁止访问"
user_total = user_quota_config[user_id]
if user_used_token[user_id] + input_token > user_total:
return False, f"当前用户今日Token配额已用尽"
return True, "用户配额校验通过"
def check_rate_limit(user_id: str, input_token: int) -> tuple[bool, str]:
"""请求频率限流校验"""
clear_overdue_data(user_id)
# 请求次数限制
if len(user_req_time[user_id]) >= rate_limit_config["req_per_min"]:
return False, "请求过于频繁,请一分钟后重试"
# 分钟Token流量限制
curr_min_token = sum(user_min_token[user_id])
if curr_min_token + input_token > rate_limit_config["token_per_min"]:
return False, "短时间内Token消耗过高,已触发流量限流"
return True, "频率限流校验通过"
# ===================== 5. 大模型请求统一入口 =====================
def llm_request_handler(user_id: str, scene_id: str, prompt: str) -> dict:
"""
大模型请求统一处理入口
:param user_id: 操作用户ID
:param scene_id: 业务场景ID
:param prompt: 用户输入提问文本
:return: 请求结果、消耗信息
"""
# 1. 预计算输入Token
input_token = calc_text_token(prompt)
print(f"【请求预校验】用户:{user_id} 场景:{scene_id} 输入Token:{input_token}")
# 2. 三层规则校验
scene_ok, scene_msg = check_scene_rule(scene_id, input_token)
if not scene_ok:
return {"code": 403, "msg": scene_msg, "data": None}
user_ok, user_msg = check_user_rule(user_id, input_token)
if not user_ok:
return {"code": 403, "msg": user_msg, "data": None}
rate_ok, rate_msg = check_rate_limit(user_id, input_token)
if not rate_ok:
return {"code": 429, "msg": rate_msg, "data": None}
# 3. 模拟大模型生成,计算输出Token
mock_resp = "大模型返回的业务回复内容,用于模拟真实生成场景"
output_token = calc_text_token(mock_resp)
total_token = input_token + output_token
# 4. 扣减配额、记录消耗
scene_used_token[scene_id] += total_token
user_used_token[user_id] += total_token
# 记录限流数据
user_req_time[user_id].append(get_current_timestamp())
user_min_token[user_id].append(total_token)
# 5. 返回结果
return {
"code": 200,
"msg": "请求成功",
"data": {
"prompt": prompt,
"response": mock_resp,
"input_token": input_token,
"output_token": output_token,
"total_token": total_token
}
}
# ===================== 6. 测试运行 =====================
if __name__ == "__main__":
print("=" * 60)
print("【测试用例1】核心业务场景 正常请求")
print("=" * 60)
res1 = llm_request_handler(
user_id="user_biz_002",
scene_id="core_service",
prompt="请分析本月客户咨询数据,总结核心问题并给出优化建议"
)
print(f"结果: {res1}\n")
print("=" * 60)
print("【测试用例2】高频请求限流测试(同一用户连续请求11次,触发限流)")
print("=" * 60)
test_user = "user_test_004"
test_scene = "test_debug"
for i in range(11):
res = llm_request_handler(
user_id=test_user,
scene_id=test_scene,
prompt=f"第{i+1}次测试提问"
)
status = "✓ 成功" if res["code"] == 200 else f"✗ 限流: {res['msg']}"
print(f" 第{i+1}次请求: {status}")
print()
print("=" * 60)
print("【测试用例3】Token流量限流测试(短时间内大量Token消耗)")
print("=" * 60)
# 先清空之前的限流记录
user_req_time["user_staff_003"] = []
user_min_token["user_staff_003"] = []
long_prompt = "这是一段非常长的测试文本," * 50 # 约 1500 字符,约 1000+ tokens
for i in range(6):
res = llm_request_handler(
user_id="user_staff_003",
scene_id="business_office",
prompt=long_prompt
)
status = "✓ 成功" if res["code"] == 200 else f"✗ 限流: {res['msg']}"
print(f" 第{i+1}次长文本请求: {status}")
print()
print("=" * 60)
print("【测试用例4】单次Token超限测试")
print("=" * 60)
super_long_prompt = "测试文本" * 300 # 远超 2000 token 限制
res4 = llm_request_handler(
user_id="user_staff_003",
scene_id="daily_office",
prompt=super_long_prompt
)
status = "✓ 成功" if res4["code"] == 200 else f"✗ 拒绝: {res4['msg']}"
print(f"结果: {status}")
print()
print("=" * 60)
print("【测试用例5】场景配额耗尽测试")
print("=" * 60)
# 模拟耗尽 test_debug 场景的配额(每日 5000 tokens)
scene_used_token["test_debug"] = 4900
res5 = llm_request_handler(
user_id="user_test_004",
scene_id="test_debug",
prompt="消耗剩余配额的请求"
)
status = "✓ 成功" if res5["code"] == 200 else f"✗ 拒绝: {res5['msg']}"
print(f"第1次请求(剩余约100 tokens): {status}")
res6 = llm_request_handler(
user_id="user_test_004",
scene_id="test_debug",
prompt="再次请求"
)
status = "✓ 成功" if res6["code"] == 200 else f"✗ 拒绝: {res6['msg']}"
print(f"第2次请求(配额已耗尽): {status}")输出结果:
Downloading Model from modelscope to directory: D:\modelscope\hub\google-bert\bert-base-chinese
============================================================
【测试用例1】核心业务场景 正常请求
============================================================
【请求预校验】用户:user_biz_002 场景:core_service 输入Token:27
结果: {'code': 200, 'msg': '请求成功', 'data': {'prompt': '请分析本月客户咨询数据,总结核心问题并给出优化建议', 'response': '大模型返回的业务回复内容,用于模拟真实生成场景', 'input_token': 27, 'output_token': 25, 'total_token': 52}}
============================================================
【测试用例2】高频请求限流测试(同一用户连续请求11次,触发限流)
============================================================
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第1次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第2次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第3次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第4次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第5次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第6次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第7次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第8次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第9次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第10次请求: ✓ 成功
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:9
第11次请求: ✗ 限流: 请求过于频繁,请一分钟后重试
============================================================
【测试用例3】Token流量限流测试(短时间内大量Token消耗)
============================================================
Token indices sequence length is longer than the specified maximum sequence length for this model (652 > 512). Running this sequence through the model will result in indexing errors
【请求预校验】用户:user_staff_003 场景:business_office 输入Token:652
第1次长文本请求: ✓ 成功
【请求预校验】用户:user_staff_003 场景:business_office 输入Token:652
第2次长文本请求: ✓ 成功
【请求预校验】用户:user_staff_003 场景:business_office 输入Token:652
第3次长文本请求: ✓ 成功
【请求预校验】用户:user_staff_003 场景:business_office 输入Token:652
第4次长文本请求: ✓ 成功
【请求预校验】用户:user_staff_003 场景:business_office 输入Token:652
第5次长文本请求: ✓ 成功
【请求预校验】用户:user_staff_003 场景:business_office 输入Token:652
第6次长文本请求: ✓ 成功
============================================================
【测试用例4】单次Token超限测试
============================================================
【请求预校验】用户:user_staff_003 场景:daily_office 输入Token:1202
结果: ✗ 拒绝: 短时间内Token消耗过高,已触发流量限流
============================================================
【测试用例5】场景配额耗尽测试
============================================================
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:11
第1次请求(剩余约100 tokens): ✗ 拒绝: 请求过于频繁,请一分钟后重试
【请求预校验】用户:user_test_004 场景:test_debug 输入Token:6
第2次请求(配额已耗尽): ✗ 拒绝: 请求过于频繁,请一分钟后重试
七、总结
总的来说,Token精细化管控早已不是单纯的技术附加能力,而是企业落地大模型绕不开的核心必修课。通常我们在引入大模型初期,只关注功能能否实现,如果放任Token自由消耗,等到账单激增、服务卡顿之后,才意识到成本和资源管控的重要性。其实弄懂Token的底层消耗逻辑后就会明白,大部分成本浪费都来自无差别调用:低效测试场景随意刷屏、长上下文冗余堆积、高频重复请求挤占资源,这些问题只要通过场景、用户、频率三维节流,就能从源头有效规避。按业务优先级划分场景配额、给不同用户配置合理用量、用限流机制平滑峰值流量,整套逻辑落地门槛并不高,却能带来非常可观的降本效果。
学习大模型不能只聚焦 Prompt 编写、接口调用这类表层能力,更要了解从工程化和成本视角思考问题。从长远看,以后我们会越发主动熟悉Token计算规则、限流算法与用量统计逻辑。未来企业大模型规模化普及是必然趋势,兼具功能开发、性能优化与成本管控的综合能力,才是长久的核心竞争力,了解精细化治理,才能让大模型应用走得更稳、更长远。