一、SSE 核心概念
1. 什么是SSE流式传输
SSE,全称Server-Sent Events,即服务器推送事件,是基于HTTP长连接的单向流式传输协议,核心能力是服务器持续向客户端推送数据,无需客户端反复发起请求,天然适配大模型逐字流式输出场景。

1.1 核心特性
- 协议基础:基于标准HTTP/HTTPS协议,无需额外升级服务、无需WebSocket双工协议,接入成本极低,兼容所有现代浏览器、后端服务。
- 传输方向:服务器 → 客户端单向推送,大模型场景中仅需后端持续输出推理文本,无需客户端实时交互,完美匹配需求。
- 数据格式:固定以"data: 内容\n\n"为标准分片格式,后端逐段生成、前端逐段解析,无等待、无全量加载延迟。
- 自动重连机制:原生支持连接断开后默认3秒重连,可自定义重连策略,是大模型流式输出不中断的基础保障。
- 无状态与长连接结合:HTTP无状态特性保证服务轻量化,长连接模式保证流式连续性,平衡性能与稳定性。
1.2 与WebSocket的区别
| 对比维度 | SSE | WebSocket | 大模型场景适配性 |
|---|---|---|---|
| 连接方式 | HTTP 长连接 | 独立双工协议 | SSE 更轻量 |
| 传输方向 | 单向推送 | 双向通信 | 大模型仅需服务端推送 |
| 重连能力 | 原生支持 | 需手动实现 | SSE 零代码自愈 |
| 代理兼容 | 兼容所有 HTTP 代理 | 部分代理需配置 | SSE 生产环境更稳定 |
| 资源消耗 | 低(单连接占用内存 < 1MB) | 较高(双工维护状态) | 高并发大模型接口优选 |
2. SSE基础工作流程
-
- 客户端发起连接:前端通过 EventSource 对象发起 HTTP 请求,请求头携带 Accept: text/event-stream 标识流式需求。
-
- 后端建立长连接:服务端接收请求,设置响应头"Content-Type: text/event-stream、Cache-Control: no-cache、Connection: keep-alive", 保持连接不关闭。
-
- 流式数据推送:后端按"data: 分片内容\n\n"格式持续发送数据,大模型每生成一个字符或片段,立即推送至前端。
-
- 前端实时解析:前端监听message事件,逐段接收数据、实时渲染,实现"打字机效果"。
-
- 连接关闭:大模型推理完成,后端发送"data: DONE\n\n:标识结束,双端正常关闭连接;若异常断开,触发重连机制。
3. SSE对大模型的意义
大模型推理具有耗时久、输出长、需实时展示三大特性,SSE是解决该场景的最优方案:
-
- 消除等待延迟:传统接口需等待大模型全量推理完成才返回数据,SSE实现 "边推理边输出",用户无需等待,体验提升10倍以上。
-
- 降低内存压力:大模型单次输出可达数万字符,全量返回会导致前端内存暴涨、后端响应超时,SSE 分片传输将内存占用降低90%。
-
- 提升接口可用性:大模型推理时长波动大(1-30 秒),SSE 长连接避免 HTTP 超时中断,保证完整输出。
-
- 适配高并发场景:SSE轻量长连接特性,支持单服务同时维护数千个流式连接,满足大模型服务高并发需求。
-
- 简化全栈开发:无需复杂双工协议,前后端基础代码即可实现流式输出,降低大模型服务开发门槛。
二、基础演示
1. 后端基础代码
python
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import asyncio
import time
app = FastAPI()
# 允许跨域(前端可直接访问)
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# ====================== 核心流式生成器(完整版:心跳+防泄漏+超时+断开感知) ======================
async def llm_complete_stream_generator(request: Request):
# 配置参数
MAX_CONNECTION_TIMEOUT = 60 # 最大连接超时 60秒
HEARTBEAT_INTERVAL = 30 # 心跳间隔 30秒
SIMULATE_LLM_DELAY = 0.2 # 模拟大模型推理延迟
# 模拟大模型流式输出内容
llm_content = [
"你", "好", ",", "我", "是", "智", "能", "大", "模", "型", ",",
"我", "可", "以", "帮", "你", "处", "理", "各", "种", "问", "题", "。",
"今", "天", "天气", "不", "错", ",", "适", "合", "学", "习", "S", "S", "E", "流", "式", "开", "发", "。"
"S", "S", "E", "是", "基", "于","H", "T", "T", "P", "长", "连", "接", "的", "单", "向", "流", "式", "传", "输", "协", "议", ",", "核", "心", "能", "力", "是", "服", "务", "器", "持", "续", "向", "客", "户", "端", "推", "送", "数", "据", ",", "无", "需", "客", "户", "端", "反", "复", "发", "起", "请", "求", ",", "天", "然", "适", "配", "大", "模", "型", "逐", "字", "流", "式", "输", "出", "场", "景", "。"
]
start_time = time.time()
last_data_time = time.time()
try:
# 先发送连接成功消息
yield f"data: [CONNECTED] SSE 连接建立成功\n\n"
await asyncio.sleep(0.1)
# 遍历推送大模型分片
for chunk in llm_content:
# 1. 检测客户端是否断开(防泄漏核心)
if await request.is_disconnected():
print("[后端] 客户端已断开连接,终止推理")
break
# 2. 检测连接超时(防挂死)
if time.time() - start_time > MAX_CONNECTION_TIMEOUT:
yield f"data: [ERROR] 连接超时({MAX_CONNECTION_TIMEOUT}s),自动关闭\n\n"
break
# 3. 心跳保活(防止代理断开长连接)
if time.time() - last_data_time > HEARTBEAT_INTERVAL:
yield f"data: [HEARTBEAT]\n\n"
last_data_time = time.time()
print("[后端] 发送心跳包")
# 4. 模拟大模型逐字输出
await asyncio.sleep(SIMULATE_LLM_DELAY)
yield f"data: {chunk}\n\n"
last_data_time = time.time()
# 正常结束
yield f"data: [DONE]\n\n"
print("[后端] 大模型输出完成,连接正常关闭")
except Exception as e:
# 异常兜底
yield f"data: [ERROR] 服务异常:{str(e)}\n\n"
finally:
# 强制释放资源(防连接泄漏)
print("[后端] 资源已释放,连接结束")
# ====================== SSE 流式接口 ======================
@app.get("/api/llm/sse")
async def sse_llm_api(request: Request):
return StreamingResponse(
llm_complete_stream_generator(request),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Accel-Buffering": "no", # 禁用Nginx缓冲,保证实时性
"Transfer-Encoding": "chunked"
}
)
# 启动服务
if __name__ == "__main__":
import uvicorn
print("SSE 服务启动:http://127.0.0.1:8000/api/llm/sse")
print("前端打开 html 即可查看流式输出")
uvicorn.run(app, host="0.0.0.0", port=8000)细节说明:
- 生成器函数:使用 async def 异步生成器,避免阻塞服务端线程,适配大模型高并发推理。
- SSE 格式严格规范:必须以 data: 开头、\n\n 结尾,否则前端无法解析分片。
- 结束与异常标识:DONE 标识正常结束,ERROR 标识异常,前端可精准判断状态。
- 禁用缓冲头:X-Accel-Buffering: no 强制代理服务器实时转发数据,避免分片堆积延迟。
2. 前端基础代码
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>SSE 大模型流式输出(稳定版)</title>
<style>
body { padding: 20px; font-size: 16px; line-height: 1.6; }
#content { padding: 15px; border: 1px solid #eee; min-height: 300px; white-space: pre-wrap; }
.status { margin: 10px 0; color: #666; }
.error { color: red; }
.success { color: #009688; }
.heart { color: #999; font-size: 12px; }
</style>
</head>
<body>
<h2>SSE 大模型流式输出(稳定版:心跳+重连+防泄漏)</h2>
<div class="status" id="status">等待连接...</div>
<div id="content"></div>
<script>
// ====================== 全局配置 ======================
const SSE_URL = "http://127.0.0.1:8000/api/llm/sse";
const MAX_RECONNECT_TIMES = 5; // 最大重连次数
let eventSource = null;
let reconnectCount = 0;
let content = document.getElementById('content');
let status = document.getElementById('status');
// ====================== 初始化 SSE ======================
function startSSE() {
// 防止重复创建连接(防泄漏)
if (eventSource) {
eventSource.close();
eventSource = null;
}
status.textContent = "正在连接 SSE...";
status.className = "status";
// 创建连接
eventSource = new EventSource(SSE_URL);
// ====================== 接收消息 ======================
eventSource.onmessage = function (e) {
let data = e.data.trim();
// 连接成功
if (data.startsWith("[CONNECTED]")) {
status.textContent = data.replace("[CONNECTED]", "");
status.className = "status success";
reconnectCount = 0;
return;
}
// 心跳包(忽略渲染)
if (data === "[HEARTBEAT]") {
status.textContent = "连接正常 · 心跳保活中";
return;
}
// 异常信息
if (data.startsWith("[ERROR]")) {
content.innerHTML += `<span class="error">${data}</span>\n`;
status.textContent = "连接异常";
status.className = "status error";
closeSSE();
return;
}
// 正常结束
if (data === "[DONE]") {
content.innerHTML += "\n<span class='success'>✅ 输出完成</span>";
status.textContent = "任务完成";
closeSSE();
return;
}
// 正常流式内容
content.innerHTML += data;
status.textContent = "正在接收流式数据...";
};
// ====================== 异常 & 重连 ======================
eventSource.onerror = function (err) {
console.error("SSE 异常:", err);
closeSSE();
// 超过最大重连次数
if (reconnectCount >= MAX_RECONNECT_TIMES) {
status.textContent = `重连失败(已重试${reconnectCount}次),请刷新页面`;
status.className = "status error";
return;
}
// 渐进式重连(避免雪崩)
reconnectCount++;
let delay = reconnectCount === 1 ? 1000 :
reconnectCount === 2 ? 3000 : 5000;
status.textContent = `连接断开,${delay/1000}秒后第${reconnectCount}次重连...`;
status.className = "status error";
setTimeout(() => startSSE(), delay);
};
}
// ====================== 安全关闭连接(防泄漏) ======================
function closeSSE() {
if (eventSource) {
eventSource.close();
eventSource = null;
}
}
// ====================== 页面关闭时自动释放(防泄漏) ======================
window.addEventListener('beforeunload', () => {
closeSSE();
});
// 启动
window.onload = startSSE;
</script>
</body>
</html>细节说明:
- EventSource 对象:SSE 原生 API,自动维护长连接、自动重连,无需手动处理心跳。
- 状态判断:精准识别正常分片、结束标识、异常标识,保证渲染逻辑纯净。
- 资源释放:结束或异常时主动调用 close(),避免前端连接残留。
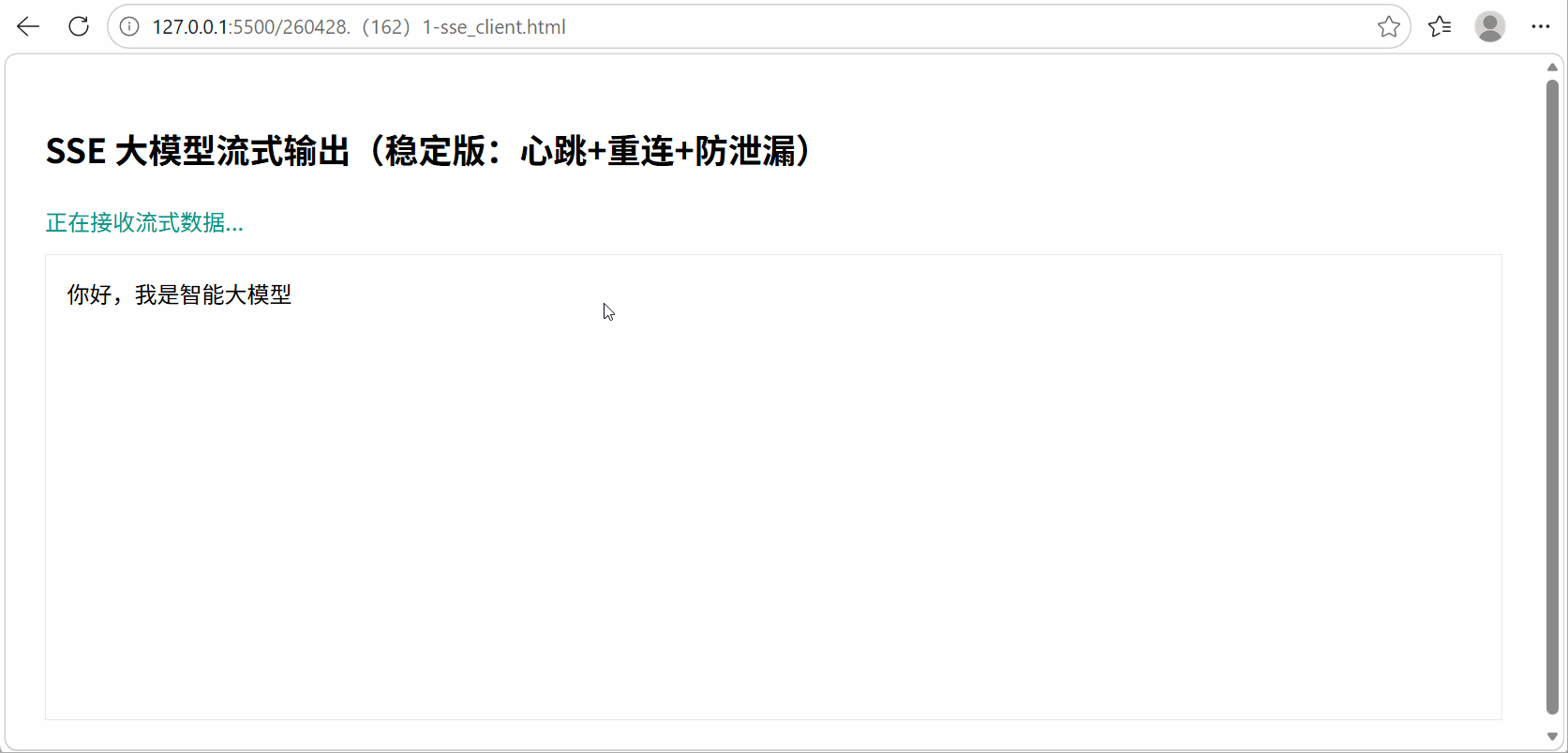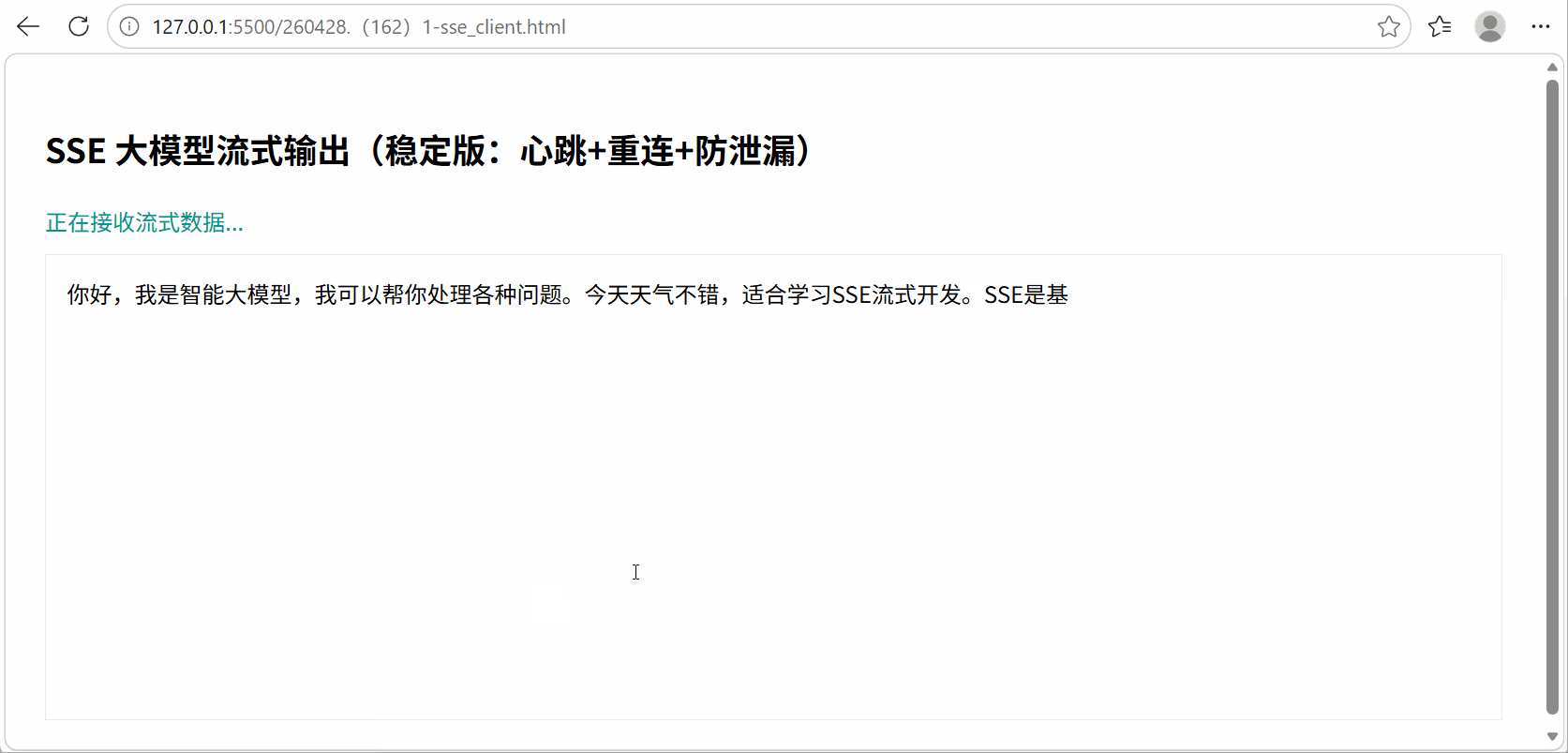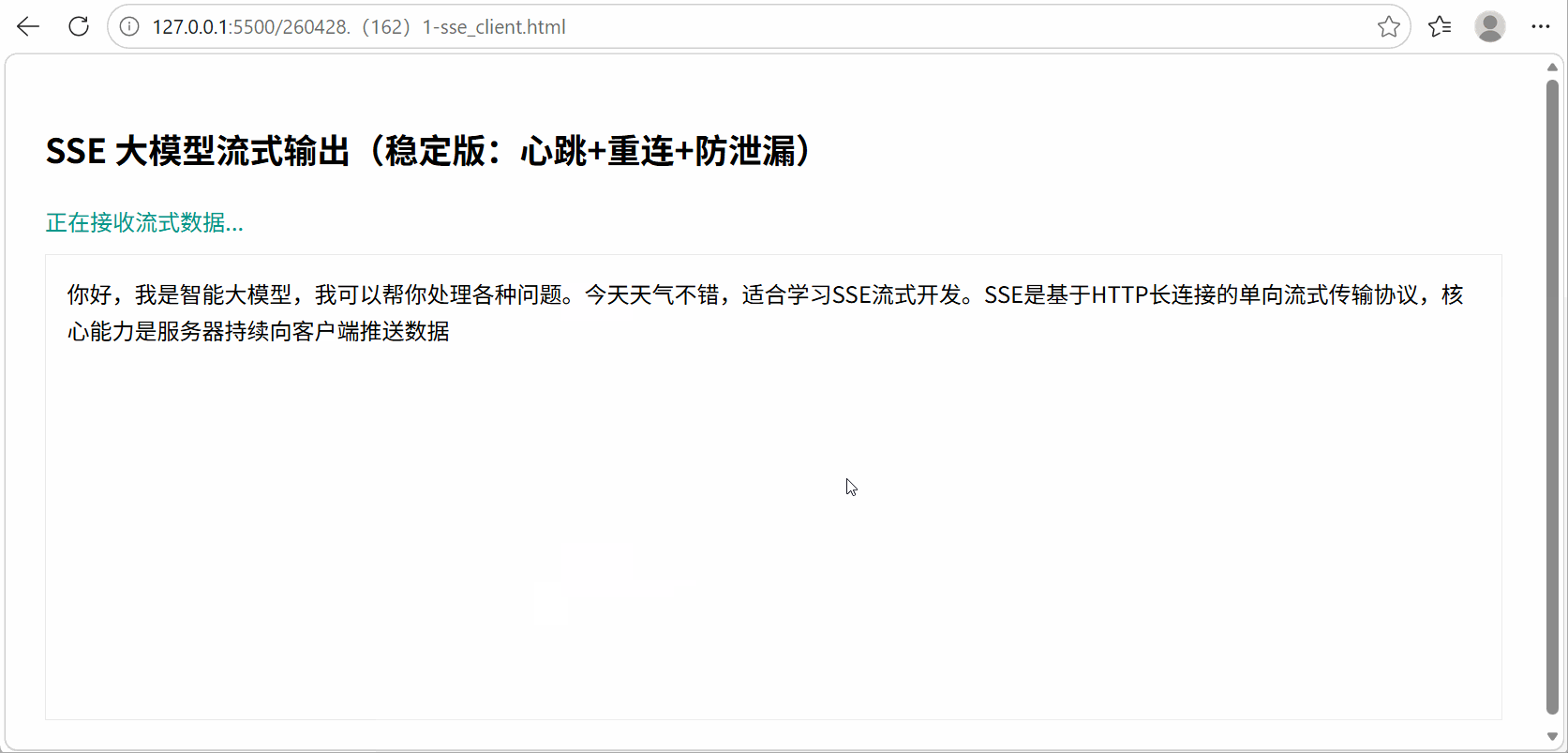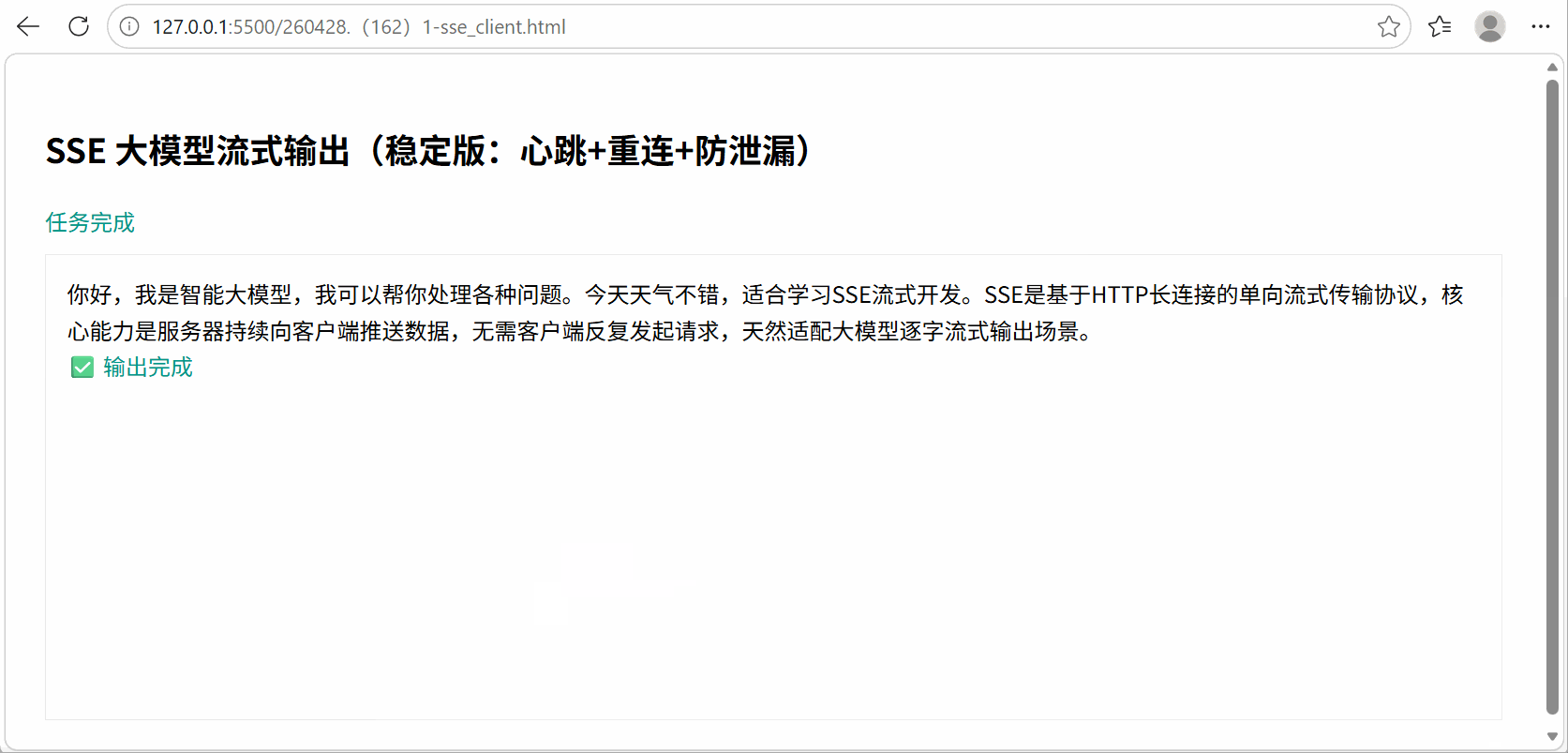
3. 应用启动测试
在终端窗口目录启动:python sse_server.py即可运行;
输出过程演示:
三、长连接泄漏治理
1. 核心概念
长连接泄漏是指:SSE连接已失效或已经结束,但前后端未释放连接资源,导致连接持续占用内存、文件描述符,最终引发服务崩溃。大模型场景中,推理时长波动大、用户强制关闭页面、网络闪断,极易引发连接泄漏。
连接泄漏的危害:
-
- 后端资源耗尽:单连接占用文件描述符,泄漏数千个连接后,服务无法新建连接,直接宕机。
-
- 内存持续暴涨:连接未释放,大模型推理上下文、数据流持续占用内存,导致OOM内存溢出。
-
- 接口不可用:资源耗尽后,新用户无法建立连接,整个大模型服务瘫痪。
-
- 日志泛滥:失效连接持续报错,淹没正常日志,无法排查问题。
2. 后端连接治理方案
2.1 超时自动关闭
- 为每个 SSE 连接设置最大超时时间,大模型场景建议30秒,超时后强制关闭连接、释放资源。
- 实现方式:异步任务监听连接时长,超时后终止生成器、关闭流。
2.2 客户端断开感知
- 监听StreamingResponse断开事件,客户端关闭页面或网络中断时,立即终止大模型推理、释放连接。
- 技术细节:FastAPI中通过request.is_disconnected() 感知客户端状态。
2.3 连接数限流
- 限制单服务最大并发SSE连接数,如1000,超过阈值拒绝新连接,防止资源耗尽。
2.4 生成器异常捕获
- 全覆盖捕获大模型推理、数据推送异常,异常发生时强制结束生成器,避免连接挂起。
2.5 后端防泄漏示例
python
from fastapi import Request
async def llm_stream_generator(request: Request):
max_timeout = 30 # 30秒超时
start_time = time.time()
llm_output = ["你", "好", ",", "大", "模", "型", "服", "务"]
try:
for chunk in llm_output:
# 感知客户端是否断开
if await request.is_disconnected():
print("客户端已断开,终止连接")
break
# 超时判断
if time.time() - start_time > max_timeout:
yield "data: [ERROR] 连接超时,自动关闭\n\n"
break
await asyncio.sleep(0.1)
yield f"data: {chunk}\n\n"
yield "data: [DONE]\n\n"
finally:
# 最终强制释放资源
print("SSE 连接已正常释放")3. 前端连接治理方案
3.1 面卸载主动关闭
- 监听beforeunload事件,用户关闭页面、刷新时,主动调用eventSource.close()。
3.2 异常状态强制清理
- 监听error事件,异常发生后立即关闭连接,禁止无限重连导致泄漏。
3.3 单例连接控制
- 禁止重复创建EventSource对象,保证同一时间只有一个有效连接。
3.4 前端防泄漏示例
python
// 页面卸载时关闭连接
window.addEventListener('beforeunload', function() {
if (eventSource) {
eventSource.close();
}
});
// 异常强制关闭
eventSource.onerror = function(error) {
console.error('连接异常');
eventSource.close();
eventSource = null;
};四、心跳保活与断连重连
1. 心跳保活设计
1.1 为什么需要心跳
代理服务器Nginx会自动关闭闲置超过60秒的长连接,大模型推理间隙若没有数据传输,连接会被静默断开,导致输出中断。
1.2 心跳保活核心方案
-
- 心跳分片格式:后端定时发送无业务意义的心跳包,格式:"data: HEARTBEAT\n\n",前端忽略不渲染。
-
- 心跳间隔:建议30秒,小于代理闲置超时时间,持续维持连接活性。
-
- 双端心跳逻辑
- 后端:无业务数据推送时,定时发送心跳包;有业务数据时,暂停心跳。
- 前端:识别心跳标识,不渲染、不处理,仅维持连接。
1.3 后端心跳实现代码
python
async def llm_stream_generator(request: Request):
heartbeat_interval = 30 # 30秒心跳
last_data_time = time.time()
llm_output = ["你", "好", "大", "模", "型"]
try:
for chunk in llm_output:
# 心跳逻辑:超时发送心跳
while time.time() - last_data_time > heartbeat_interval:
yield "data: [HEARTBEAT]\n\n"
last_data_time = time.time()
if await request.is_disconnected():
break
await asyncio.sleep(1)
yield f"data: {chunk}\n\n"
last_data_time = time.time()
yield "data: [DONE]\n\n"
finally:
print("连接释放")2. 断连重连设计
2.1 重连核心需求
网络闪断、服务重启、代理超时导致连接断开后,无需用户操作,自动重连并恢复大模型流式输出。
2.2 渐进式重连策略
渐进式重连是指在网络异常后,采用递增延迟(如1秒、2秒、4秒...)的方式尝试重连,而非立即高频重试。这样可避免大量客户端同时重连造成服务器瞬时压力过大,防止系统雪崩,确保服务稳定性。
- 首次重连:延迟 1 秒,快速恢复。
- 二次重连:延迟 3 秒,避免频繁请求。
- 三次及以上:延迟 5 秒,最大重试 5 次,防止无效重连压垮服务。
2.3 前端重连实现代码
javascript
let reconnectCount = 0;
const maxReconnect = 5; // 最大重连次数
let reconnectTimer = null;
function initSSE() {
eventSource = new EventSource('http://127.0.0.1:8000/sse/llm');
eventSource.onerror = function(error) {
eventSource.close();
reconnectCount++;
// 超过最大重连次数,停止重连
if (reconnectCount > maxReconnect) {
contentDiv.innerHTML += "<br/><span style='color:red;'>连接失败,请刷新页面重试</span>";
return;
}
// 渐进式延迟重连
const delay = reconnectCount === 1 ? 1000 : reconnectCount === 2 ? 3000 : 5000;
console.log(`${delay/1000}秒后第${reconnectCount}次重连`);
clearTimeout(reconnectTimer);
reconnectTimer = setTimeout(() => initSSE(), delay);
};
}五、分片异常处理
1. 常见分片异常类型
- 分片丢失:网络波动导致部分数据未送达前端,输出内容缺失。
- 分片乱序:大模型多线程推理、网络抖动,导致分片顺序错误,文本混乱。
- 格式错误:后端未按 data: \n\n 格式推送,前端无法解析,连接中断。
- 超大分片:单分片超过浏览器代理限制,导致数据截断。
- 空分片:后端推送空数据,前端渲染异常空白。
2. 后端分片异常处理方案
2.1 格式强校验
- 封装统一SSE分片工具函数,强制校验格式,自动补全 data: 和 \n\n。
2.2 分片大小限制
- 单分片最大长度限制为1024字符,超过则自动拆分,避免代理截断。
2.3 有序推送
- 大模型推理结果加入序号标识,如 data: {"index":1,"content":"你"}\n\n,保证顺序。
2.4 异常兜底
- 捕获所有分片推送异常,返回标准错误分片,避免连接崩溃。
3. 前端分片异常处理方案
3.1 格式校验
- 接收数据后,校验是否为标准格式,非格式数据直接忽略,避免渲染错误。
3.2 乱序重排
- 根据后端序号缓存分片,按顺序渲染,解决乱序问题。
3.3 丢失重传
- 检测到序号中断,触发重连,从断点恢复数据。
3.4 空值过滤
- 过滤空分片、心跳分片,保证渲染内容纯净。
六、前后端容错设计
1. 后端容错体系
- 请求容错:校验请求头是否包含text/event-stream,非SSE请求直接拒绝。
- 推理容错:大模型推理超时、报错,立即返回错误标识,释放连接。
- 资源容错:内存、文件描述符不足时,优雅关闭旧连接,保证服务可用。
- 降级容错:高并发时,降级为非流式输出,保证接口不宕机。
2. 前端容错体系
- 渲染容错:异常数据标红展示,不阻塞整体渲染,提供重试按钮。
- 重连容错:最大重连次数限制,避免无限重连导致浏览器崩溃。
- 缓存容错:缓存已接收的流式数据,重连后从断点继续渲染,不重复展示。
- 兼容性容错:低版本浏览器不支持SSE时,降级为轮询请求,保证功能可用。
七、实践: 大模型接口流式响应
1. 本地模型的流式接口
基于FastAPI + ChatGLM2-6B 搭建本地大模型API服务,支持非流式和流式两种调用方式:
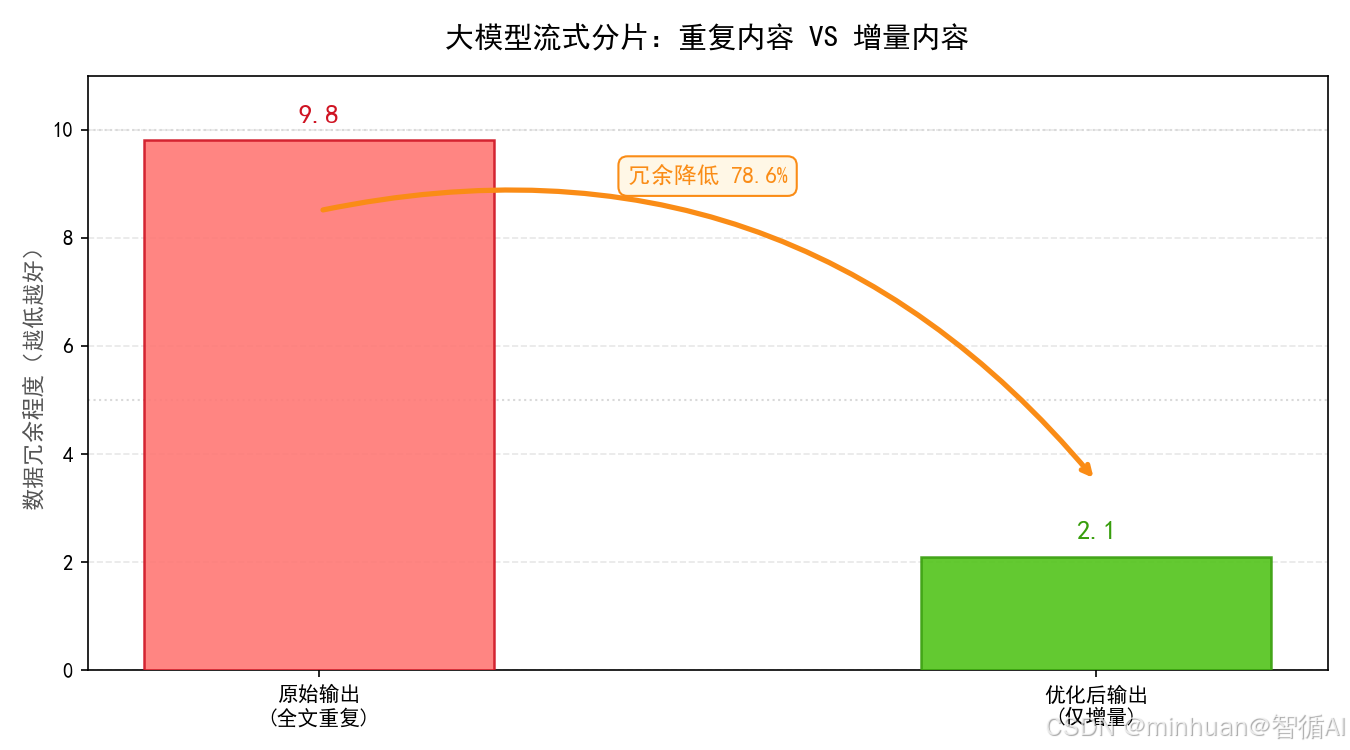
- 流式增量输出:通过 delta_mode 参数控制(True=增量/False=全量),增量模式下仅返回新增文本片段,减少带宽占用,提升用户体验。
- SSE 协议封装:流式响应遵循Server-Sent Events格式,客户端可逐字渲染,实现打字机效果。
python
# 1. 导入需要的库
from fastapi import FastAPI, HTTPException
from fastapi.responses import StreamingResponse
from transformers import AutoTokenizer, AutoModel, AutoConfig
import torch
import uvicorn
from modelscope import snapshot_download
import warnings
import json
warnings.filterwarnings("ignore")
# --- 显式定义全局变量 ---
model = None
tokenizer = None
model_name = "ZhipuAI/chatglm2-6b"
cache_dir = "/home/model"
# 2. 初始化FastAPI应用
app = FastAPI(title="ChatGLM2-6B 本地API", description="基于ChatGLM2-6B模型的本地化部署接口")
# 3. 加载模型和Tokenizer
print("正在下载/校验模型缓存...")
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
print(f"正在加载模型,路径: {local_model_path}")
tokenizer = AutoTokenizer.from_pretrained(local_model_path, trust_remote_code=True)
# 修复ChatGLM配置兼容性问题
config = AutoConfig.from_pretrained(local_model_path, trust_remote_code=True)
if not hasattr(config, 'max_length'):
config.max_length = config.seq_length if hasattr(config, 'seq_length') else 8192
# 使用AutoModel加载
try:
if not torch.cuda.is_available():
raise RuntimeError("未检测到GPU,请确保CUDA环境配置正确")
print(f"检测到GPU: {torch.cuda.get_device_name(0)}")
print(f"GPU显存: {torch.cuda.get_device_properties(0).total_memory / 1024**3:.2f} GB")
model = AutoModel.from_pretrained(
local_model_path,
config=config,
trust_remote_code=True,
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
device_map="auto"
)
device = next(model.parameters()).device
print(f"模型加载成功!当前设备: {device}")
except Exception as e:
print(f"加载失败: {e}")
model = None
# 4. 定义API接口 - 原接口
@app.post("/chat", summary="ChatGLM2-6B对话接口")
def chat(question: str):
if model is None:
raise HTTPException(status_code=500, detail="模型未加载,请检查服务器启动日志")
try:
response, history = model.chat(tokenizer, question, history=[])
return {"question": question, "answer": response}
except Exception as e:
raise HTTPException(status_code=500, detail=f"推理出错: {str(e)}")
# 5. 扩展接口 - OpenAI兼容的 /v1/chat/completions
@app.post("/v1/chat/completions", summary="OpenAI兼容对话接口")
async def chat_completions(payload: dict):
"""
兼容 OpenAI /v1/chat/completions 接口
接收参数:
prompt: 用户输入文本 (string)
stream: 是否流式返回 (bool, 可选,默认false)
返回:
stream=false: {"choices": [{"text": "..."}]}
stream=true: SSE流式返回
"""
if model is None:
raise HTTPException(status_code=500, detail="模型未加载,请检查服务器启动日志")
prompt = payload.get("prompt", "")
is_stream = payload.get("stream", False)
delta_mode = payload.get("delta_mode", True) # True=增量 False=全量
if not prompt:
raise HTTPException(status_code=400, detail="prompt不能为空")
# 非流式返回
if not is_stream:
try:
response, _ = model.chat(tokenizer, prompt, history=[])
return {
"id": "chatcmpl-local",
"object": "text_completion",
"model": model_name,
"choices": [
{
"text": response,
"index": 0,
"finish_reason": "stop"
}
]
}
except Exception as e:
raise HTTPException(status_code=500, detail=f"推理出错: {str(e)}")
# 流式返回 (SSE)
async def generate_stream():
try:
last_response = "" # 记录上一次累计回复,用于计算增量
for response, _ in model.stream_chat(tokenizer, prompt, history=[]):
if delta_mode:
# 增量模式:只发送新增部分
delta_content = response[len(last_response):]
last_response = response
content_to_send = delta_content
else:
# 全量模式:每次发送完整累计文本
content_to_send = response
# 只在有内容时才发送
if content_to_send:
chunk = {
"id": "chatcmpl-local",
"object": "chat.completion.chunk",
"model": model_name,
"choices": [
{
"delta": {"content": content_to_send},
"index": 0,
"finish_reason": None
}
]
}
data_str = json.dumps(chunk, ensure_ascii=False)
yield f"data: {data_str}\n\n"
# 结束标记
end_chunk = {
"id": "chatcmpl-local",
"object": "chat.completion.chunk",
"choices": [{"delta": {}, "index": 0, "finish_reason": "stop"}]
}
end_str = json.dumps(end_chunk, ensure_ascii=False)
yield f"data: {end_str}\n\n"
yield "data: [DONE]\n\n"
except Exception as e:
err_str = json.dumps({"error": str(e)}, ensure_ascii=False)
yield f"data: {err_str}\n\n"
return StreamingResponse(
generate_stream(),
media_type="text/event-stream"
)
# 6. 启动API服务
if __name__ == "__main__":
print("启动API服务,访问地址: http://0.0.0.0:8000")
print(" 接口1: POST /chat (原接口)")
print(" 接口2: POST /v1/chat/completions (OpenAI兼容)")
uvicorn.run(app, host="0.0.0.0", port=8000)先启动服务,我们配的是在linux环境下:
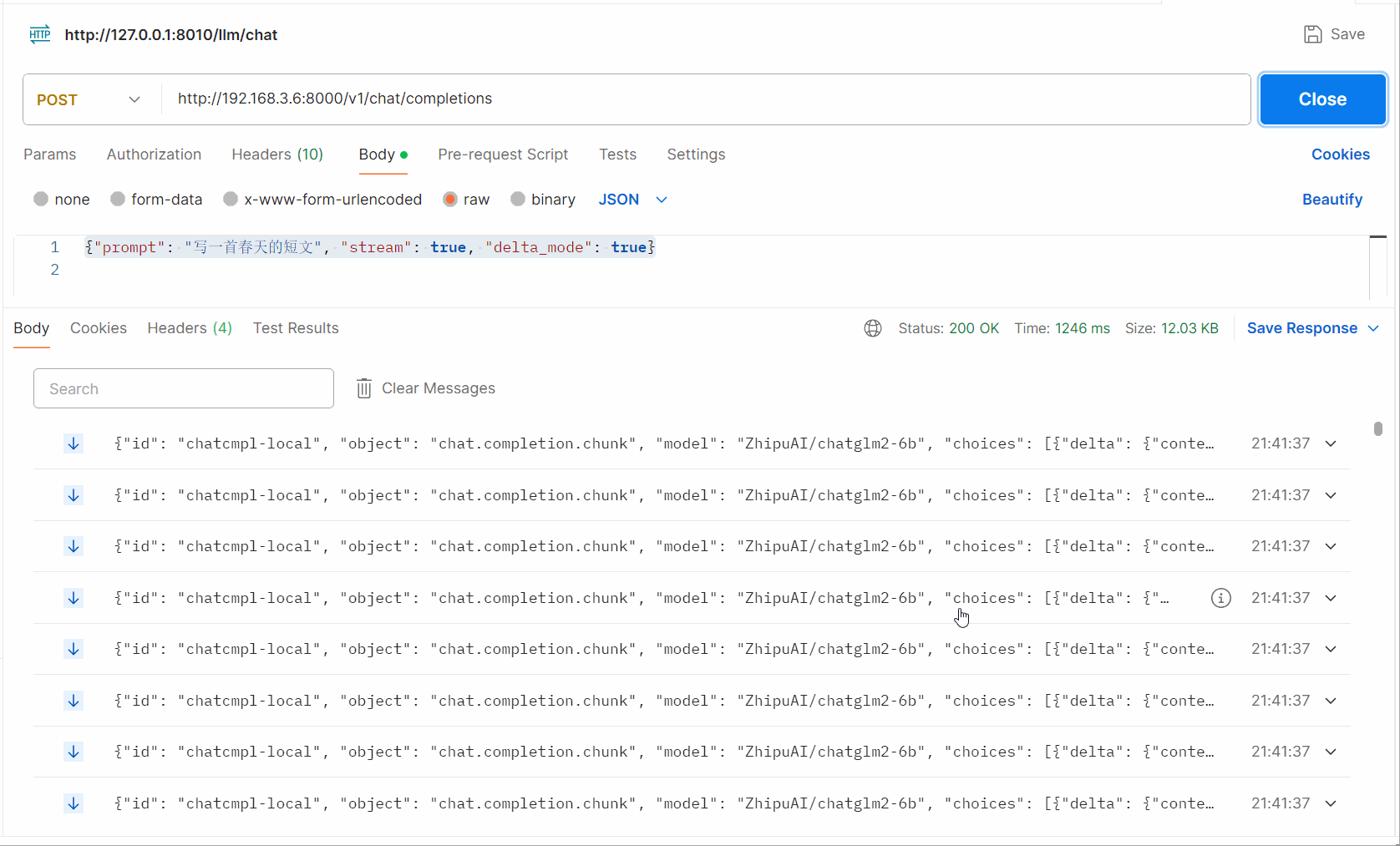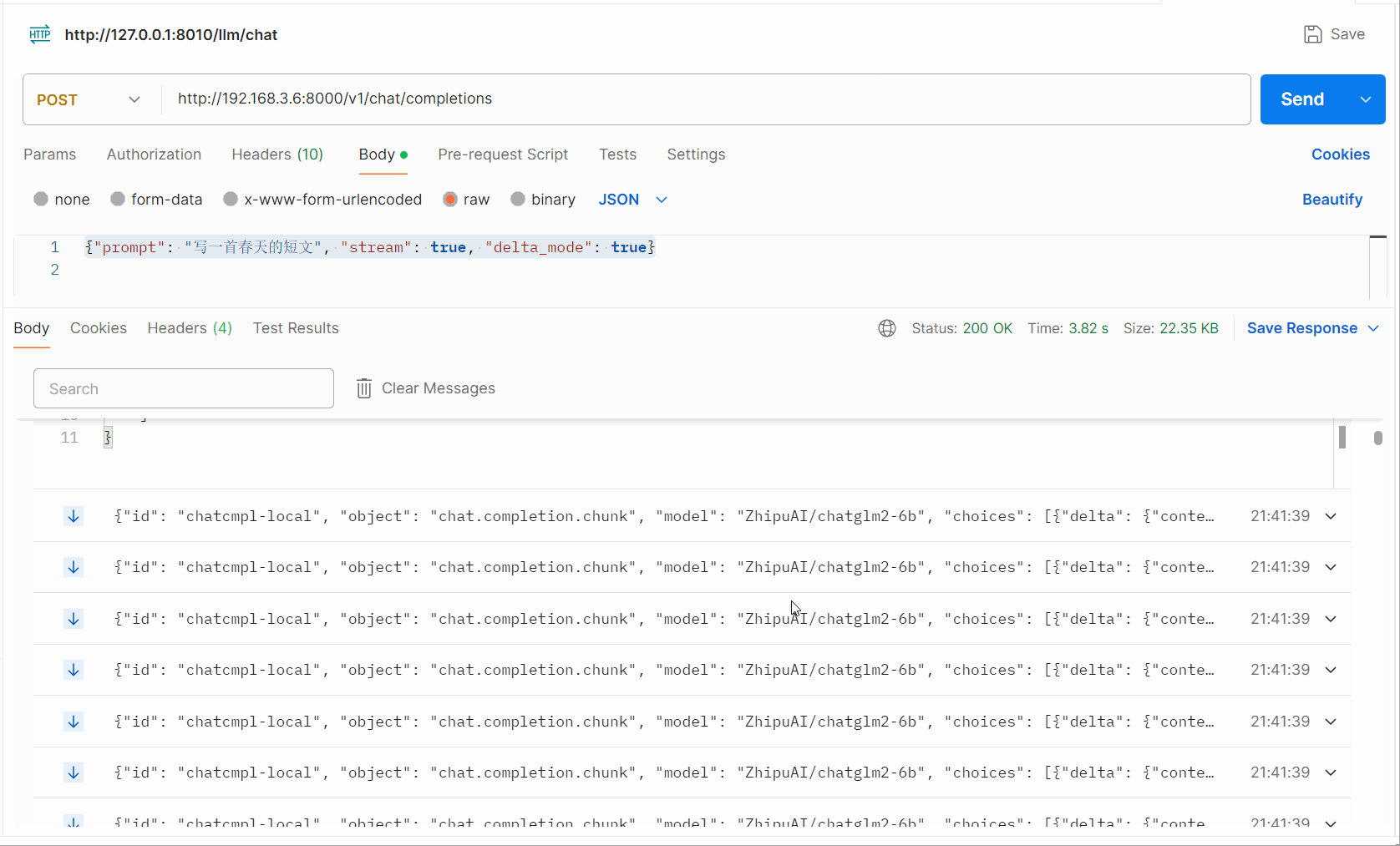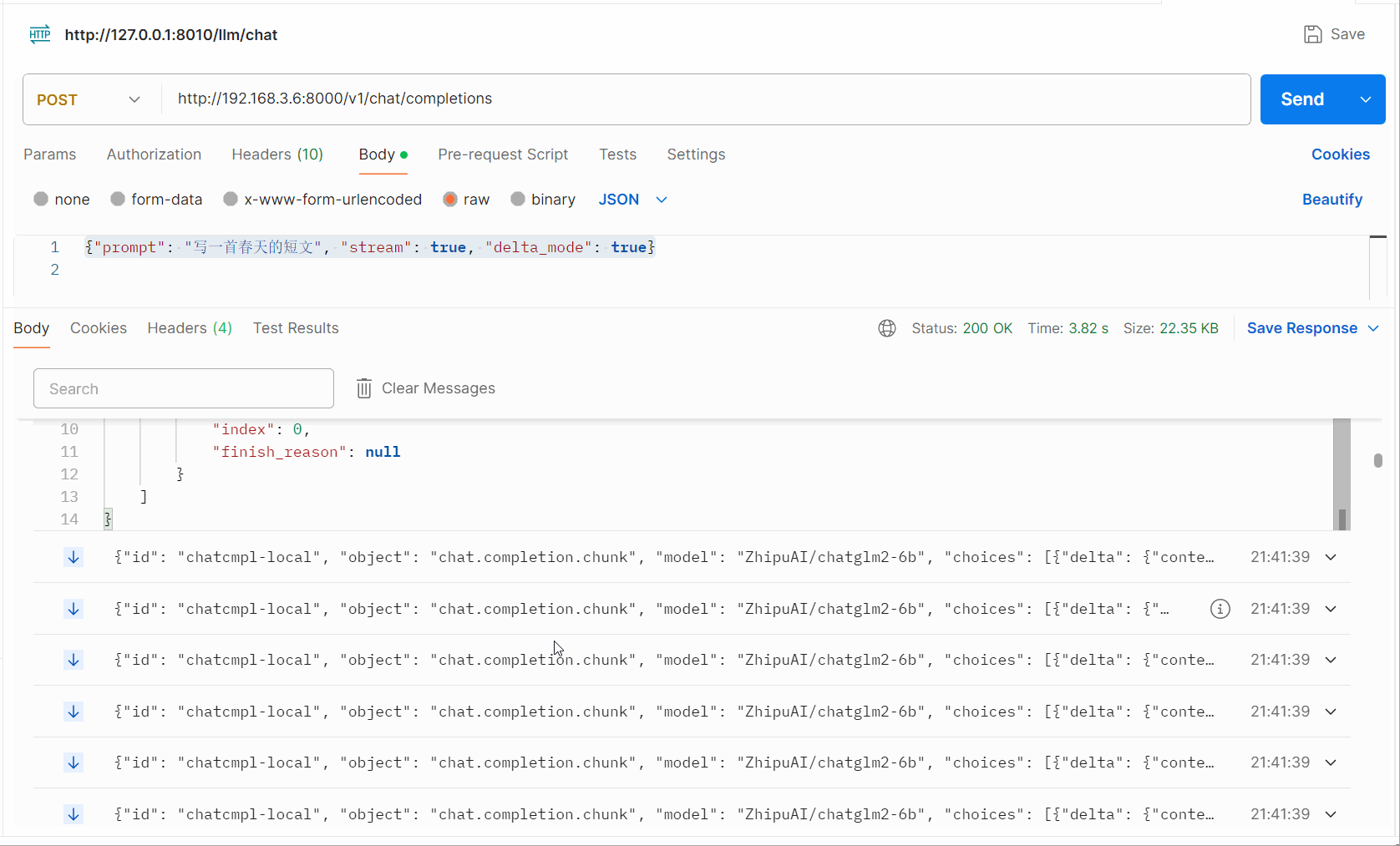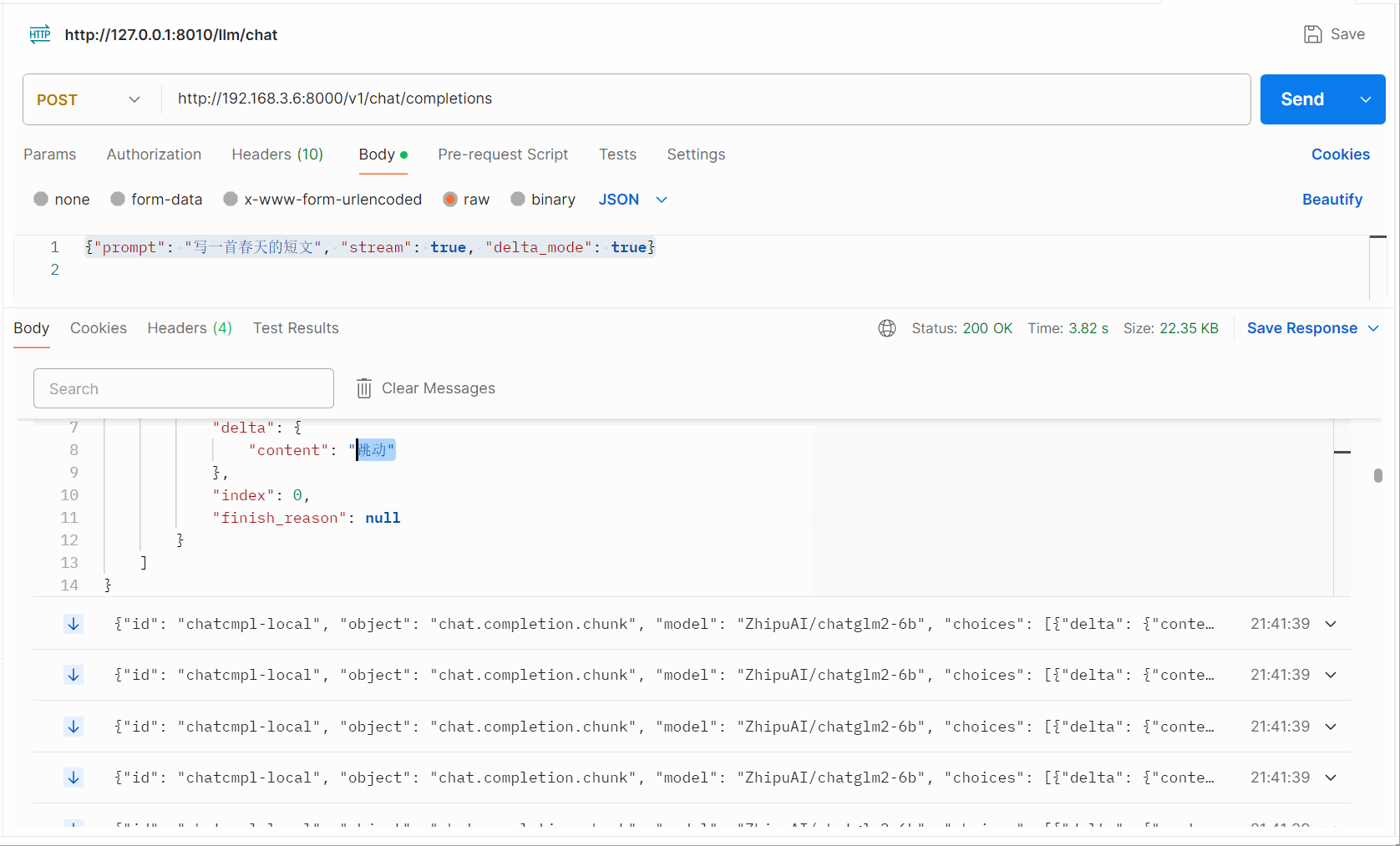
Postman调试接口观察流式输出的展示:
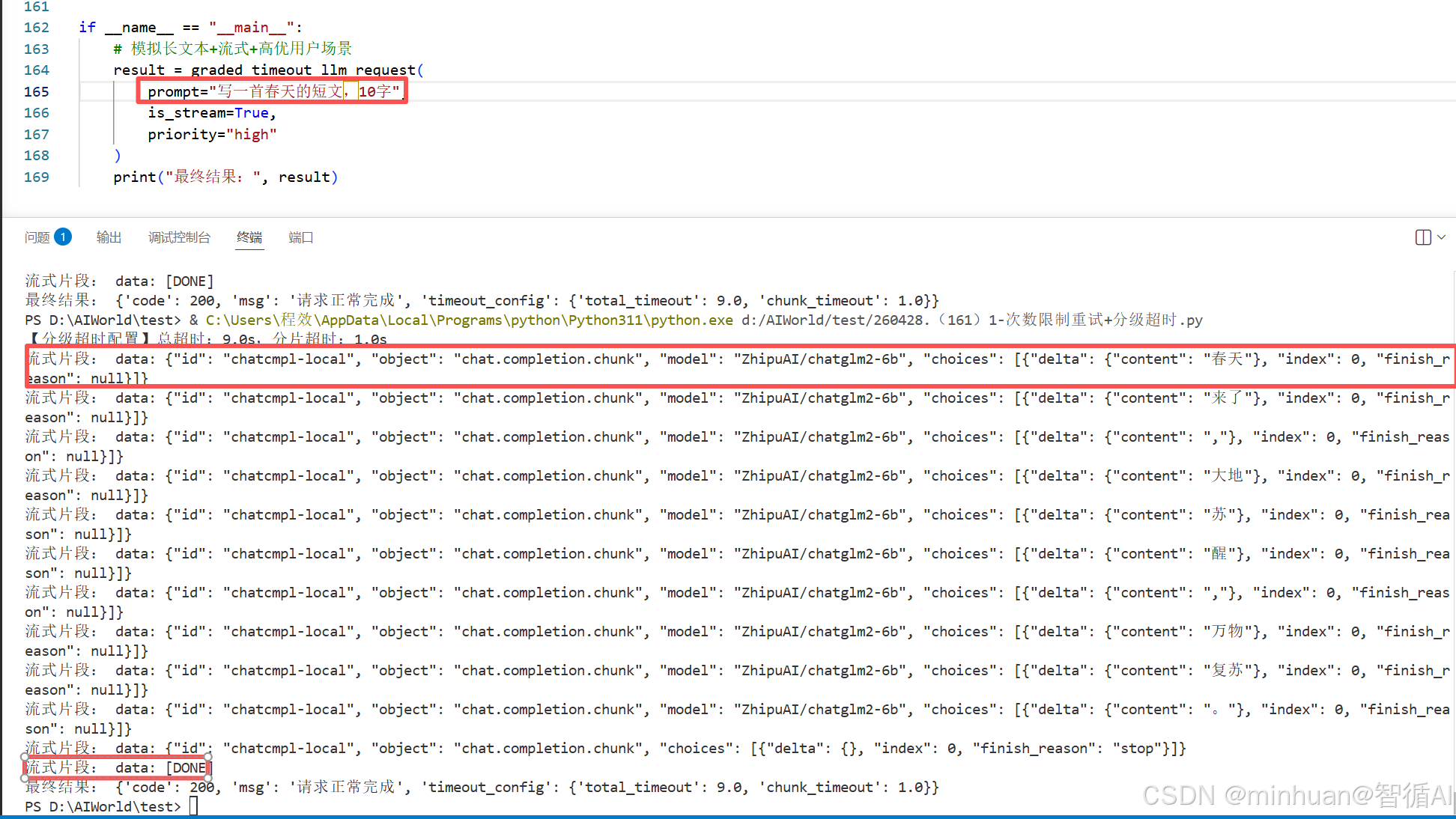
为了更直观的理解,我们输出了一个短句,显示了整个流式输出内容的细节:
2. 完整的后端示例
python
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
from fastapi.middleware.cors import CORSMiddleware
import asyncio
import requests
import time
import uuid
import json
app = FastAPI()
# ========== 屏蔽 Windows asyncio transport 层连接断开错误 ==========
def _asyncio_exception_handler(loop, context):
"""
自定义 asyncio 异常处理器:
- 屏蔽 ConnectionResetError(客户端强制断开)
- 屏蔽 _ProactorBasePipeTransport._call_connection_lost 相关错误
- 其他异常正常打印
"""
exception = context.get("exception")
# 屏蔽 ConnectionResetError
if isinstance(exception, ConnectionResetError):
return
msg = context.get("message", "")
# 屏蔽 proactor 连接丢失相关日志
if "connection_lost" in msg or "_call_connection_lost" in msg:
return
# 其他异常交给默认处理器
loop.default_exception_handler(context)
@app.on_event("startup")
async def _install_exception_handler():
loop = asyncio.get_running_loop()
loop.set_exception_handler(_asyncio_exception_handler)
print("[启动] 已安装自定义 asyncio 异常处理器(屏蔽客户端断开噪音)")
# ====================================================================
# 跨域配置
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 大模型配置
LLM_API_URL = "http://192.168.3.6:8000/v1/chat/completions"
TASK_TOTAL_TIMEOUT = 120
CHUNK_INTERVAL_TIMEOUT = 15
class RealLLMStream:
def __init__(self, prompt: str, continue_text: str = ""):
self.prompt = prompt
self.continue_text = continue_text
self.request_id = str(uuid.uuid4())
self.last_full_text = "" # 缓存上一次完整文本,用于算增量
def sync_stream(self):
payload = {
"prompt": self.prompt,
"stream": True,
"request_id": self.request_id,
"continue_content": self.continue_text
}
try:
response = requests.post(
url=LLM_API_URL,
json=payload,
stream=True,
timeout=TASK_TOTAL_TIMEOUT
)
response.raise_for_status()
last_chunk_time = time.time()
for line in response.iter_lines(decode_unicode=True):
current_time = time.time()
if current_time - last_chunk_time > CHUNK_INTERVAL_TIMEOUT:
raise TimeoutError("推理僵死,分片间隔超时")
last_chunk_time = current_time
if not line or not line.strip():
continue
# 去掉开头 data:
line = line.strip()
if line.startswith("data:"):
line = line.replace("data:", "").strip()
try:
chunk_json = json.loads(line)
choices = chunk_json.get("choices", [])
if not choices:
continue
delta = choices[0].get("delta", {})
content = delta.get("content", "")
# 服务端已发增量内容,直接转发,无需再计算增量
if content:
print("增量片段:", content)
yield f"data: {content}\n\n"
# 判断生成结束
finish_reason = choices[0].get("finish_reason")
if finish_reason is not None:
yield "data: [DONE]\n\n"
return
except json.JSONDecodeError:
continue
yield "data: [DONE]\n\n"
except Exception as e:
print("大模型流式异常:", str(e))
yield f"data: [ERROR] {str(e)}\n\n"
@app.get("/api/llm/sse")
async def sse_llm_api(request: Request, prompt: str, continue_content: str = ""):
llm = RealLLMStream(prompt, continue_content)
async def async_wrapper():
try:
for chunk_text in llm.sync_stream():
if await request.is_disconnected():
print("[SSE] 客户端断开,终止大模型请求")
break
try:
yield chunk_text
except (ConnectionResetError, GeneratorExit):
print("[SSE] 客户端连接已关闭,停止推送")
return
await asyncio.sleep(0)
except Exception as e:
print(f"[SSE] async_wrapper 异常: {e}")
finally:
print("[SSE] async_wrapper 结束")
return StreamingResponse(
async_wrapper(),
media_type="text/event-stream",
headers={
"Cache-Control": "no-cache",
"Connection": "keep-alive",
"X-Accel-Buffering": "no"
}
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8010)3. 完整的前端示例
html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<meta charset="UTF-8">
<title>SSE 接入真实大模型</title>
<style>
body { padding: 20px; font-size: 16px; }
#prompt { width: 100%; padding: 10px; margin-bottom: 10px; }
#content {
padding: 15px; border: 1px solid #eee;
min-height: 300px; white-space: pre-wrap;
line-height: 1.6;
}
.status { margin: 10px 0; color: #666; }
.error { color: red; }
.success { color: #009688; }
button { padding: 10px 20px; cursor: pointer; }
</style>
</head>
<body>
<h2>SSE + 真实大模型流式输出</h2>
<textarea id="prompt" rows="3" placeholder="请输入问题...">你好,请介绍一下AI大模型</textarea>
<br>
<button onclick="startSSE()">开始流式输出</button>
<div class="status" id="status">等待输入...</div>
<div id="content"></div>
<script>
let eventSource = null;
let reconnectCount = 0;
const MAX_RECONNECT = 5;
const content = document.getElementById('content');
const status = document.getElementById('status');
// 关闭连接
function closeSSE() {
if (eventSource) {
eventSource.close();
eventSource = null;
}
}
// 启动 SSE(带 prompt 参数)
function startSSE() {
closeSSE();
content.innerHTML = "";
reconnectCount = 0;
const prompt = document.getElementById('prompt').value.trim();
if (!prompt) {
alert("请输入问题");
return;
}
// 拼接带参数的接口
const url = `http://127.0.0.1:8010/api/llm/sse?prompt=${encodeURIComponent(prompt)}`;
eventSource = new EventSource(url);
status.textContent = "连接大模型中...";
// 接收消息
eventSource.onmessage = e => {
const data = e.data.trim();
if (data === "[DONE]") {
status.textContent = "✅ 输出完成";
closeSSE();
return;
}
if (data.startsWith("[ERROR]")) {
content.innerHTML += `<span class="error">${data}</span>`;
status.textContent = "异常断开";
closeSSE();
return;
}
content.innerHTML += data;
status.textContent = "正在实时输出...";
};
// 异常重连
eventSource.onerror = err => {
closeSSE();
if (reconnectCount >= MAX_RECONNECT) {
status.textContent = "重连失败,请重试";
return;
}
reconnectCount++;
setTimeout(startSSE, reconnectCount === 1 ? 1000 : 3000);
};
}
// 页面关闭释放连接
window.addEventListener('beforeunload', closeSSE);
</script>
</body>
</html>4. 完整结果输出
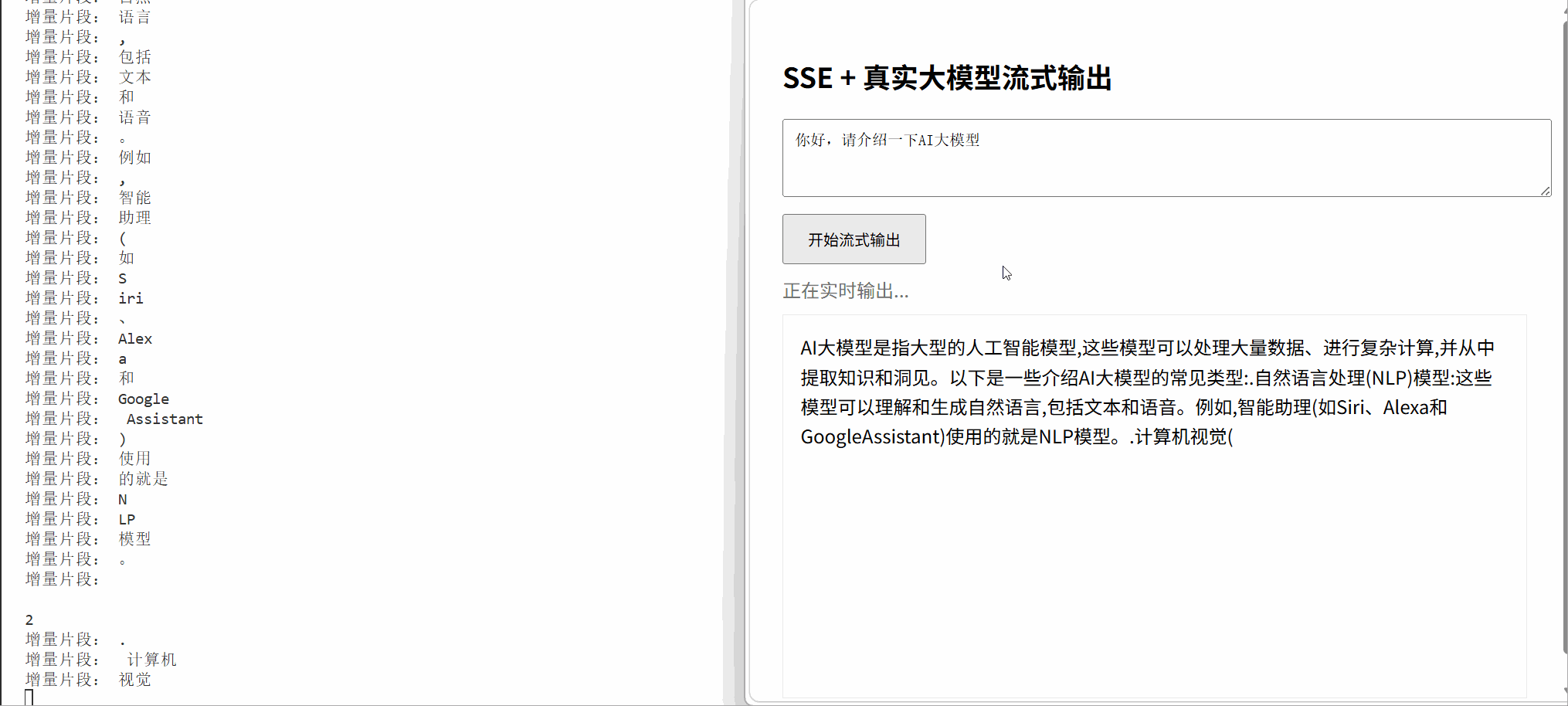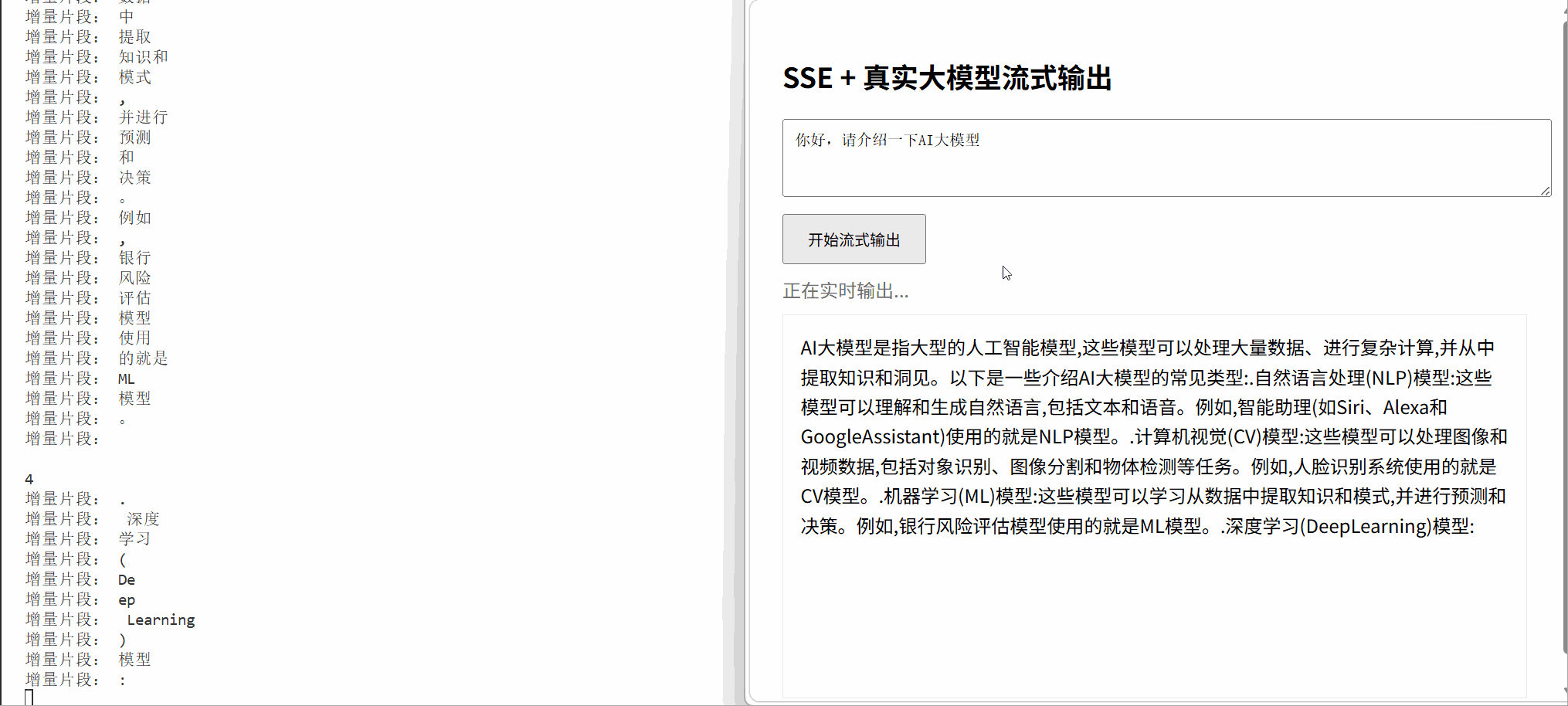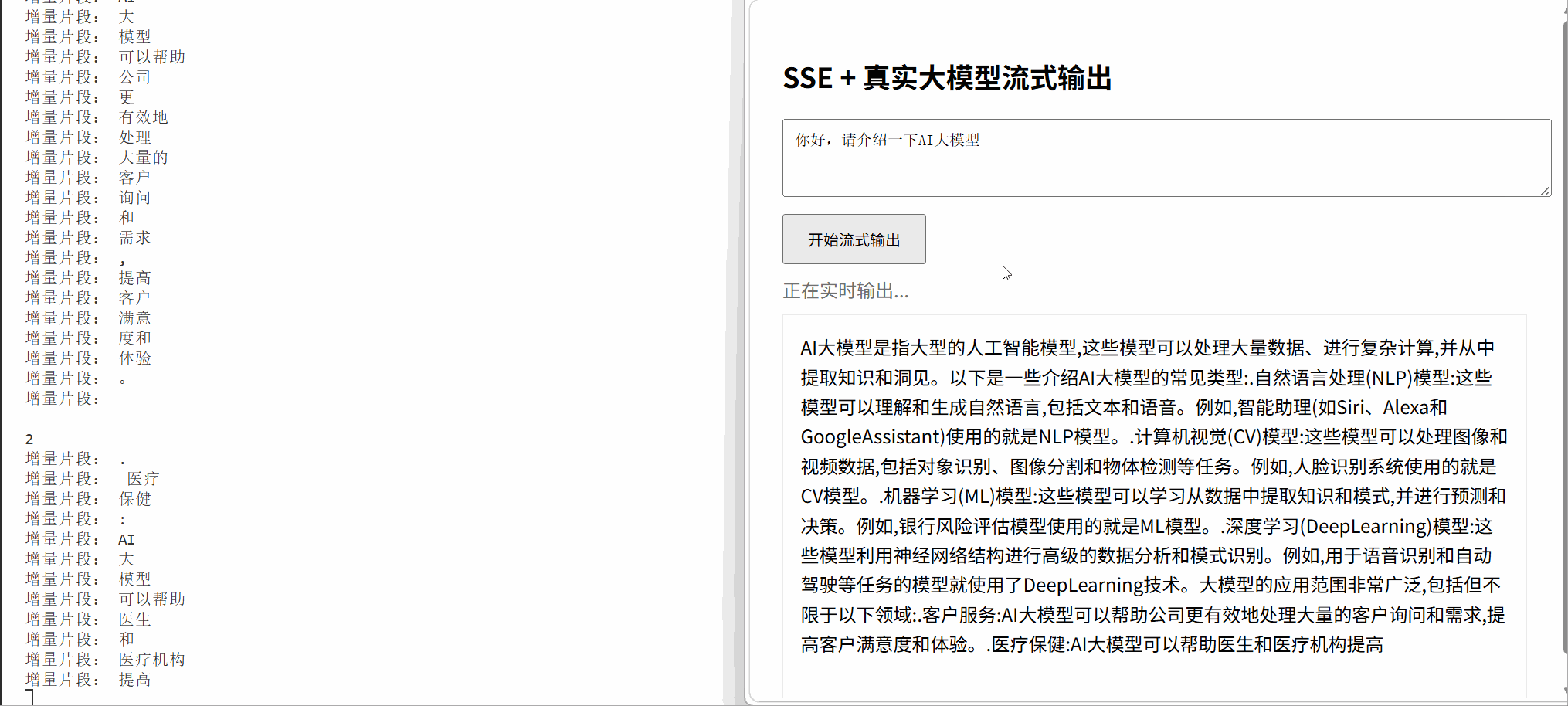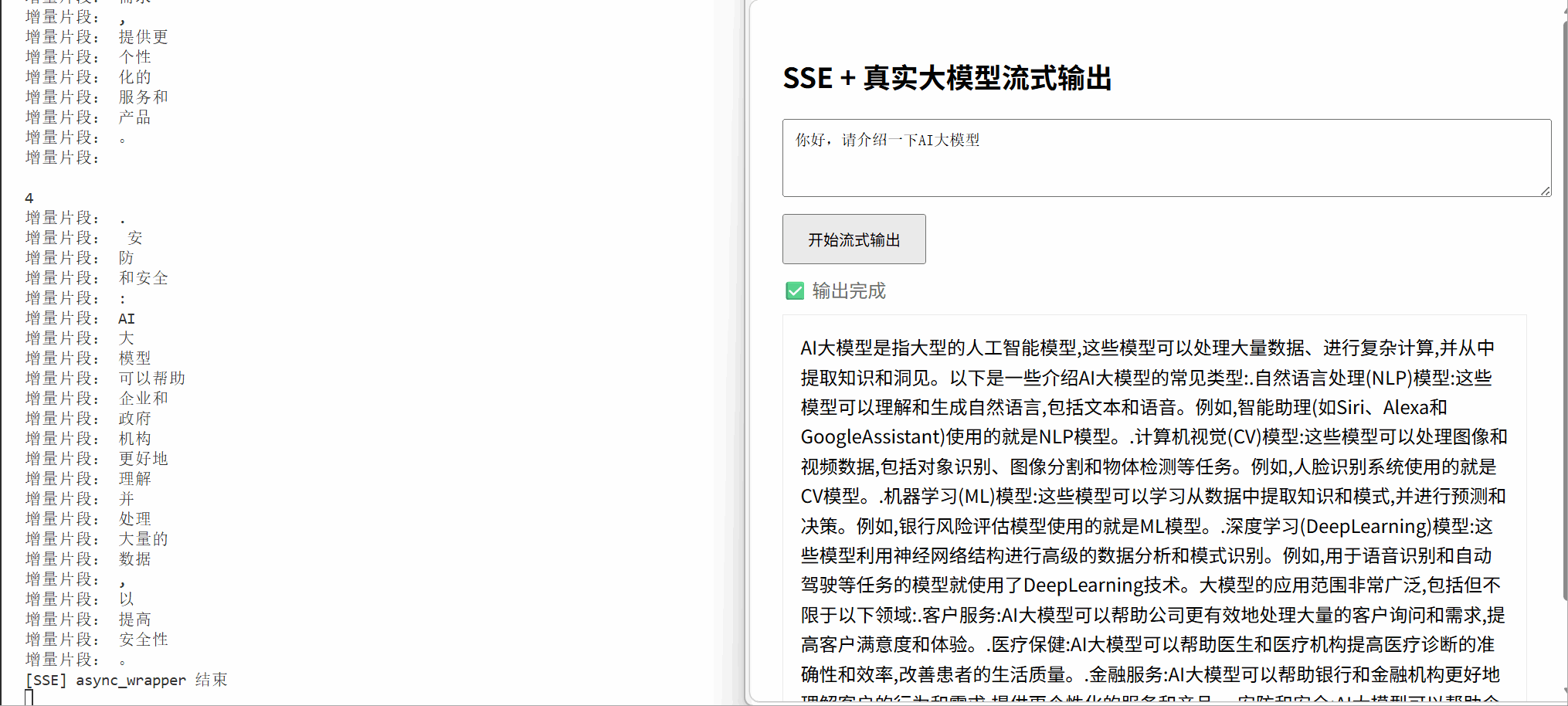
八、总结
整体梳理完大模型场景下SSE流式接口的整套设计,看似简单的长连接流式推送,真正落地生产一点都不简单。SSE依托HTTP协议天生轻量、无需额外协议适配,特别适配大模型逐字流式输出的场景,比WebSocket 更适合纯服务端单向推送的业务。但实际开发里很容易踩坑,最常见就是长连接泄漏、静默断连、分片乱序重复这几类问题。通常我们只实现了基础流式输出,却忽略了心跳保活、分片超时检测、客户端断开感知这些细节,一旦放到局域网或代理环境下,就会出现推理僵死、内容重复堆叠、连接挂死占用资源的情况。
同时通过对接ChatGLM 这类大模型流式接口也发现,很多本地模型返回的并不是标准增量分片,而是每次返回完整全文,如果不做增量截取处理,前端必然出现文字无限复读。这也提醒我们,对接第三方大模型接口不能直接照搬示例,一定要先适配数据格式、做增量去重、异常捕获。顺着长连接生命周期去理解每一个容错环节,把心跳保活、超时控制、断连重连、资源释放这些能力固化成模板。后续开发大模型流式业务时,既能减少线上 bug,也能快速搭建高可用的AI流式服务。