一、基础概念
1. 核心定义
1.1 服务熔断
服务熔断是分布式架构与大模型推理服务中必备的故障隔离机制,类比电路中的保险丝设计逻辑。当底层大模型推理接口出现连续报错、响应超时、GPU显存溢出、服务进程卡死等问题时,熔断机制会主动切断流向故障节点的请求流量。
- **核心作用层级:**不仅保护单一推理实例,更能避免单个节点故障向上传导,引发网关拥堵、队列堆积、全局服务雪崩的连锁问题。
- **大模型专属场景痛点:**大模型单次推理占用GPU显存高、计算时延大,一旦批量长文本请求扎堆故障,极易拖垮整集群算力,熔断就是第一道隔离屏障。
- **触发维度细分:**支持按请求失败率、接口平均超时占比、GPU负载持续峰值、推理队列积压长度多维度联合触发。
- **状态流转逻辑:**常态关闭、故障触发开启、静默等待后进入半开探测,探测请求全部正常才恢复关闭状态,避免盲目恢复二次崩溃。

1.2 服务限流
服务限流是对大模型请求流量做精细化配额管控的流量闸门,通过算法约束单位时间内的请求频次、并发连接数、单次Token上限、单日资源消耗总量。
- **设计核心目的:**防止流量突发暴涨、用户恶意刷量、批量自动化调用挤占有限GPU算力资源。
- **限流维度分层:**分为全局全集群限流、单用户账号限流、单IP限流、单应用密钥限流、单请求内容长度限流五大维度。
- **主流适配策略:**流量超出阈值后,可选择直接拒绝请求、进入队列排队、降级返回精简应答、限制生成字数四种处理方式。
- **大模型适配优势:**区别于普通接口限流,大模型限流重点管控Token消耗而非单纯QPS,从资源本质上做流量约束。
1.3 计费联动
计费联动是把网关风控、限流拦截、熔断状态、推理结果全链路状态,和计价系统做实时关联的业务控制机制,不只是简单的调用次数计费。
- **核心设计逻辑:**区分有效正常请求、限流拦截请求、熔断降级请求、恶意风控请求、推理失败请求,做差异化计费标记。
- **业务价值体现:**实现合规请求正常计费、异常拦截不计费、恶意盗打零计费、推理失败自动退费,从源头控制算力成本流失。
- **联动触发时机:**请求接入校验、流量超限拦截、熔断触发拦截、推理执行成功、资源超限降配全环节,都同步同步计费状态。
1.4 异常流量计费拦截
异常流量包含重复循环请求、无意义超长文本请求、机器批量轮询调用、断点重复重试请求等非业务合规流量。
- 系统通过特征规则识别这类流量后,直接在网关层拦截,不转发至大模型推理节点,同时标记为不计费流量。
- 既节省GPU算力开销,又避免用户产生无意义账单,同时减少无效推理带来的服务负载压力。
1.5 恶意请求风控
恶意请求指向恶意压测、模型能力爬取、批量生成违规内容、盗刷接口配额、竞品爬虫调用等非正常使用行为。
- 风控体系通过IP画像、请求频率曲线、文本内容风控、账号行为轨迹多维度识别,执行分级处置:轻度恶意限流、中度恶意短时封禁、重度恶意永久拉黑,全程不计费并留存调用日志溯源。
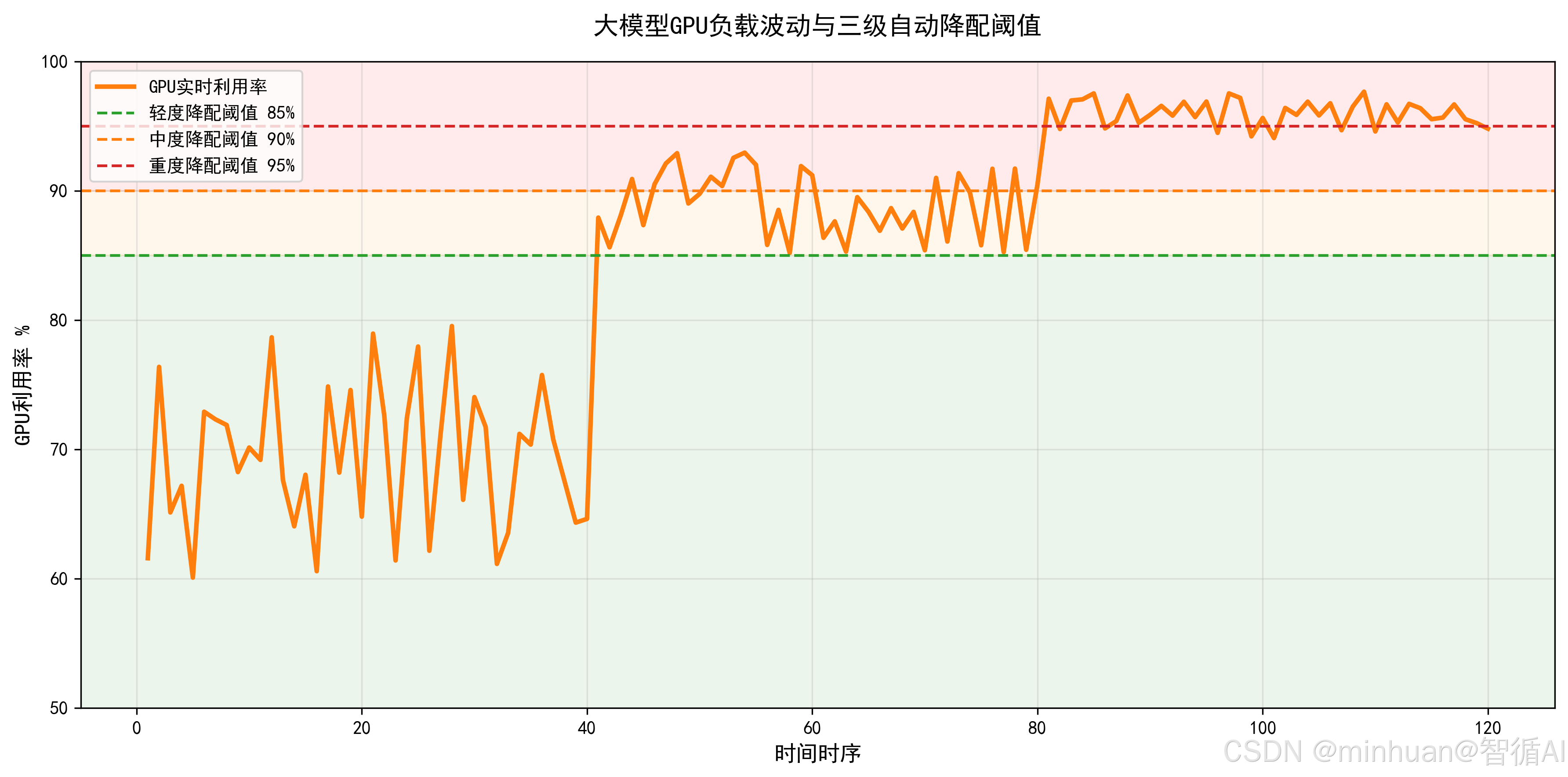
1.6 超限自动降配
超限自动降配是当全局集群或单用户资源消耗、费用消耗超出预设阈值时,系统无需人工干预自动下调服务配置规格。
- **资源超限维度:**GPU利用率峰值、显存持续占用、并发推理数量、单日Token总消耗量、账户余额透支。
- **降配可调维度:**下调最大并发推理数、降低模型推理精度、限制单请求最大生成长度、从高规格GPU切换至低负载算力调度。
- **设计优势:**业务高峰保稳定、低峰控成本,自动实现算力资源的弹性自适应调度。
2. 基础原理
2.1 熔断核心原理
- 以有限状态机为核心架构,搭配滑动时间窗口做请求指标统计。
- 窗口内实时统计成功、失败、超时请求占比,一旦触碰预设阈值自动切换熔断状态;
- 静默周期后通过少量探测请求试探服务恢复情况,科学规避故障反复震荡。
2.2 限流核心原理
- 主流依托令牌桶、漏桶、固定窗口、滑动窗口四类算法。
- 大模型场景优先选用令牌桶,可平滑应对突发流量;
- 滑动窗口用于精准管控单用户时间窗口内调用量,解决固定窗口临界突刺问题。
2.3 计费联动核心原理
- 在网关、推理服务、监控中心、计费系统全链路埋点采集日志,实时抓取请求状态、Token消耗、推理耗时、资源占用信息。
- 结合风控、限流、熔断结果打标签,按标签规则执行计费、免计费、退费逻辑。
2.4 自动降配核心原理
- 实时采集集群硬件指标、业务调用指标、费用消耗指标,配置多级阈值规则。
- 不同超限等级对应不同降配策略,同时配置恢复阈值,当指标回落至安全区间后自动回升原有配置,实现全自动弹性治理。
3. 核心价值
3.1 服务稳定性多层保障
熔断负责故障隔离防雪崩,限流负责流量削峰防过载,风控负责恶意流量隔离,三者叠加形成大模型服务三层防护网,避免单点故障、流量冲击、恶意调用影响整体服务可用性。
3.2 算力成本精细化可控
大模型GPU算力成本高昂,异常流量、恶意调用、无效推理都会造成隐性成本浪费。联动设计实现只有合规成功的有效请求才计费,其余拦截、失败、恶意流量全部免计费,从源头缩减无效算力消耗。
3.3 用户体验分层平衡
正常合规用户无感知透明调用,超限用户给出友好提示而非直接报错,恶意用户严格拦截限制,既保障普通用户使用权益,又杜绝资源被少数恶意客户端挤占。
3.4 商业化业务闭环合规
面向付费API、企业私有化部署、SaaS大模型服务场景,联动架构实现调用可溯源、计费可核算、风险可管控、异常可拦截,满足商业化运营与数据合规审计要求。
3.5 算力资源动态最优调度
高峰时段通过限流熔断保障核心业务优先使用资源,低谷时段自动恢复配置提升算力利用率,超限自动降配抑制资源浪费,实现算力供给和业务需求的动态匹配。
二、核心算法解析
1. 熔断算法
1.1 熔断核心思想
服务熔断本质是故障隔离与服务自愈机制,专门解决大模型推理服务单点故障扩散、请求堆积、GPU资源耗尽的问题。
普通业务接口故障影响范围小,但大模型推理单请求占用显存高、推理时延长,一旦某个节点报错超时,大量重试请求会持续挤占队列,最终拖垮整个集群。
熔断机制通过统计指标、状态流转、静默探测三步,实现自动发现故障、自动拦截流量、自动探测恢复,全程无需人工介入。
1.2 三大熔断状态说明
1.2.1 关闭状态(CLOSE)
- 系统正常运行,所有合法请求正常放行至大模型推理服务。
- 后台持续通过滑动窗口记录每一次请求的成功、失败、超时状态。
- 不做任何流量拦截,只做指标采集与实时统计。
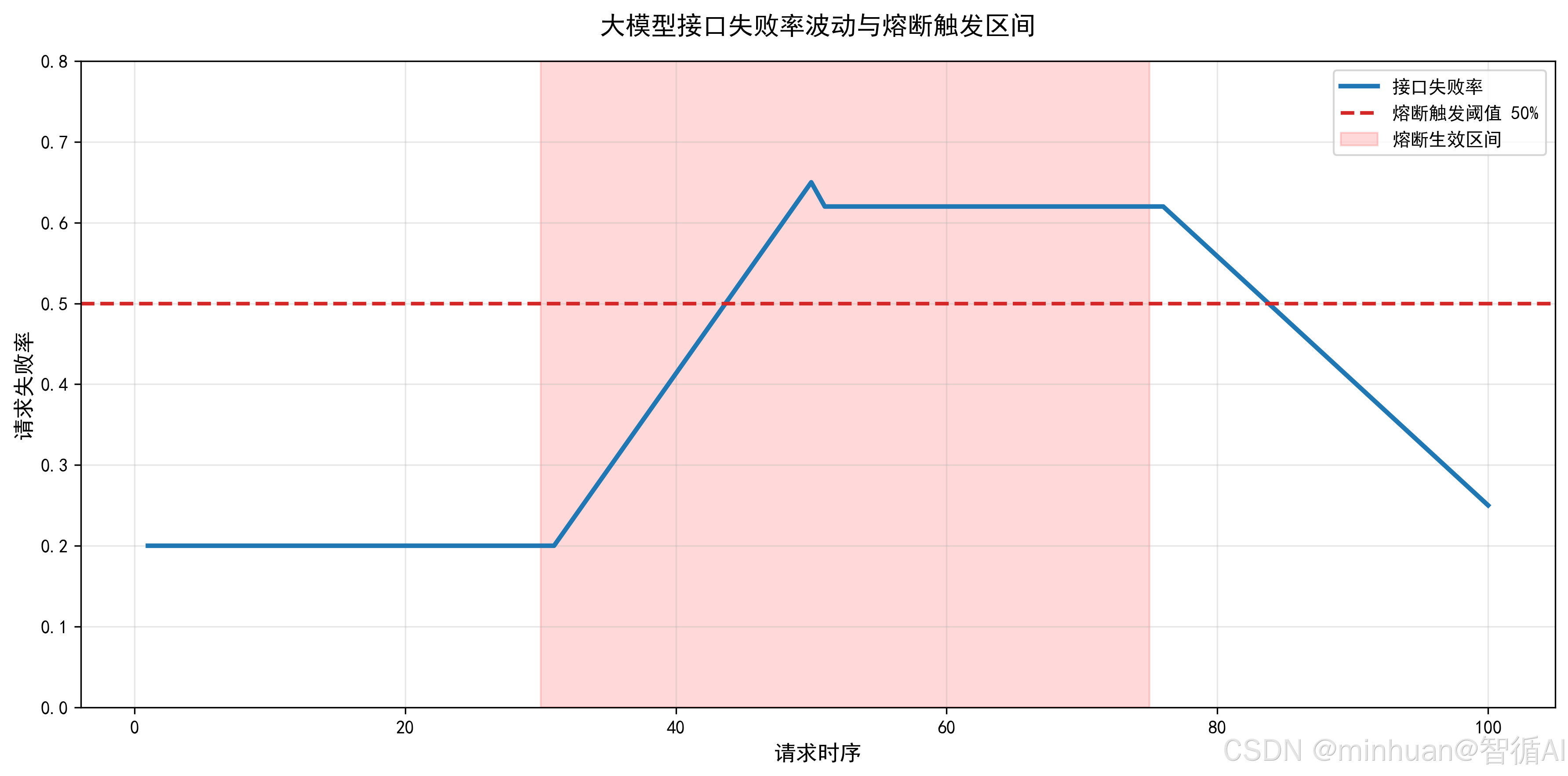
1.2.2 开启状态(OPEN)
- 当窗口内失败率、超时率超过预设阈值,立即切换为熔断开启。
- 直接拦截所有下游请求,不再转发到推理节点,快速止损。
- 开始静默倒计时,固定时长内不接受正常业务请求,给故障服务留出恢复时间。
1.2.3 半开状态(HALF_OPEN)
- 静默时间结束后,自动进入半开探测阶段。
- 不再全部拦截,限量放行少量测试请求试探服务健康度。
- 若探测请求全部成功、时延正常,则判定服务恢复,切回关闭状态;
- 若探测请求仍失败或超时,立刻重新切回熔断开启,继续静默等待。
1.3 滑动窗口统计机制
- 将请求记录固定在固定长度窗口内,比如保留最近100条请求记录。
- 采用队列先进先出,新请求入队、旧请求自动淘汰,保证统计数据实时、滚动、无滞后。
- 可统计两类核心指标:请求失败率、接口平均超时占比。
- 大模型场景额外增加:推理队列积压数、GPU显存占用率、推理超时次数作为联合触发条件。
1.4 可配置核心参数
- 滑动窗口大小:建议设置 100~200 条请求记录
- 失败率触发阈值:默认0.5,可根据业务放宽至0.4~0.6
- 熔断静默时长:默认10秒,高负载大模型可设15~30 秒
- 半开探测请求数:默认5条,不宜过多,避免再次压垮故障节点
- 联合触发条件:GPU利用率超过95%可强制触发熔断
2. 限流算法
2.1 主流限流算法对比适配
2.1.1 固定窗口计数器
原理:把时间按固定区间切割,如1秒、1分钟,统计窗口内请求数量。
优点:实现简单、计算量小。
缺点:存在临界流量突刺,窗口边界瞬间流量会翻倍,容易冲垮大模型GPU。
适用场景:内部低优先级非核心接口,不建议用于大模型主推理接口。
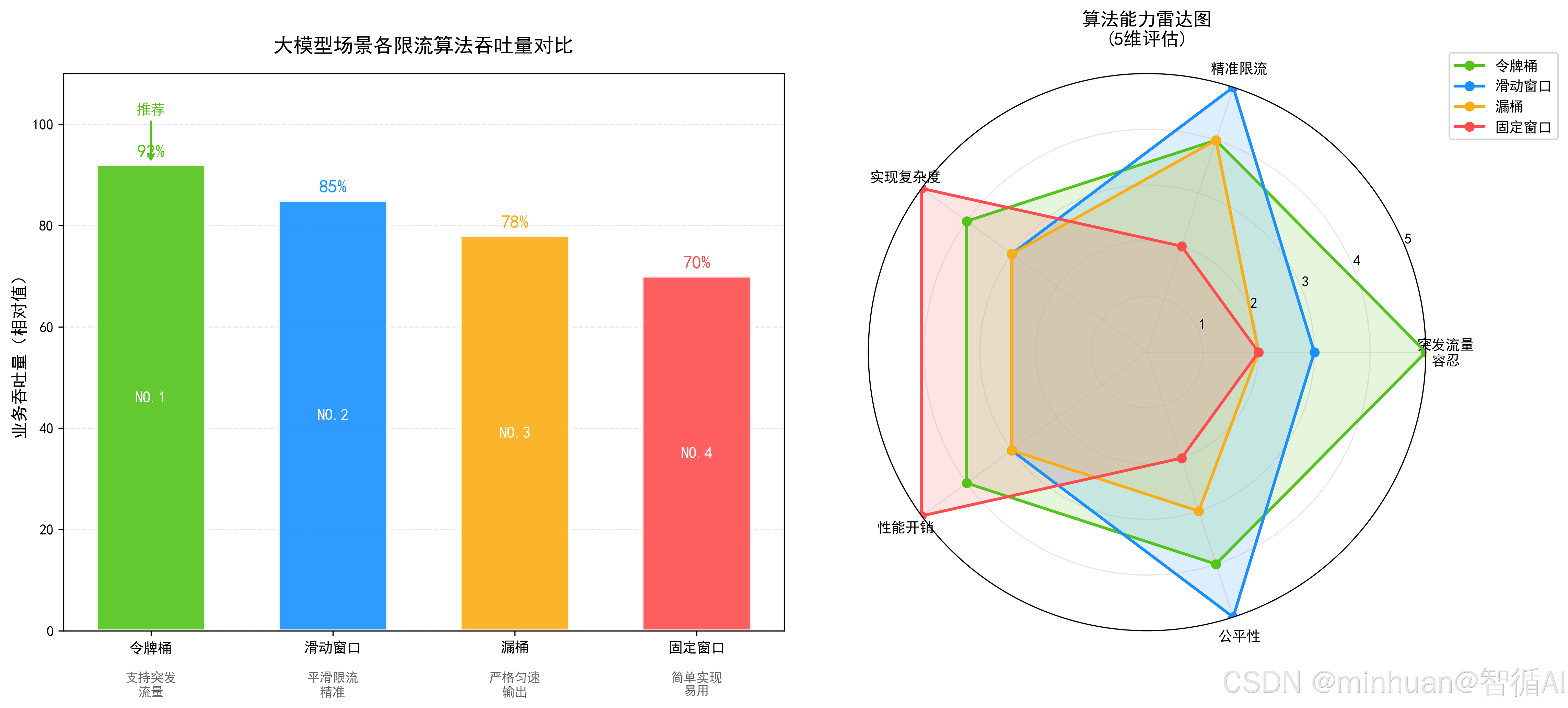
2.1.2 滑动窗口限流
原理:把大时间窗口切分为多个小格子,滚动统计每个小格子请求量。
优点:流量控制平滑,无临界突刺,统计精度高。
缺点:内存占用略高、计算逻辑稍复杂。
适用场景:单用户、单账号、单 IP维度精细化限流,管控小时或每日Token总量。
2.1.3 漏桶算法
原理:请求进入漏斗队列,以固定速率匀速流出处理,超出容量直接丢弃。
优点:强制流量匀速,削峰能力极强。
缺点:无法应对突发业务流量,流量高峰期容易大量排队拦截。
适用场景:大模型异步批量生成、离线任务推理场景。
2.1.4 令牌桶算法
原理:系统按固定速率往桶里生成令牌,请求必须拿到令牌才能执行,桶有最大容量。
优点:允许合理突发流量、平均速率可控、适配大模型瞬时对话高峰。
缺点:需要定时维护令牌生成逻辑。
适用场景:全局集群 QPS 限流、实时对话推理接口,是大模型网关标配算法。
2.2 大模型多维度限流应用
- 全集群限流:限制整个大模型服务集群最大并发、总QPS,保护整体GPU算力。
- 用户级限流:单用户每秒QPS、最大并发会话、每小时Token消耗上限。
- IP 级限流:限制单IP短时间内高频调用,防范机器刷量、爬虫调用。
- 请求内容限流:限制单请求输入最大Token、生成最大输出长度,避免超长文本耗尽显存。
- 应用密钥限流:针对第三方API接入方单独配额管控,商业计费场景必备。
3. 计费联动原理
3.1 全链路埋点架构
在请求完整生命周期每个节点做日志与状态埋点:
- 网关接入层:记录请求来源、用户ID、IP、调用时间、请求特征
- 风控拦截层:标记是否恶意请求、拦截原因
- 限流熔断层:标记是否被限流、是否被熔断拦截
- 推理执行层:记录输入Token、输出Token、推理耗时、GPU资源占用
- 结果返回层:记录请求成功、失败、超时、中断状态
所有埋点数据实时上报至计费中心,作为计费判定唯一依据。
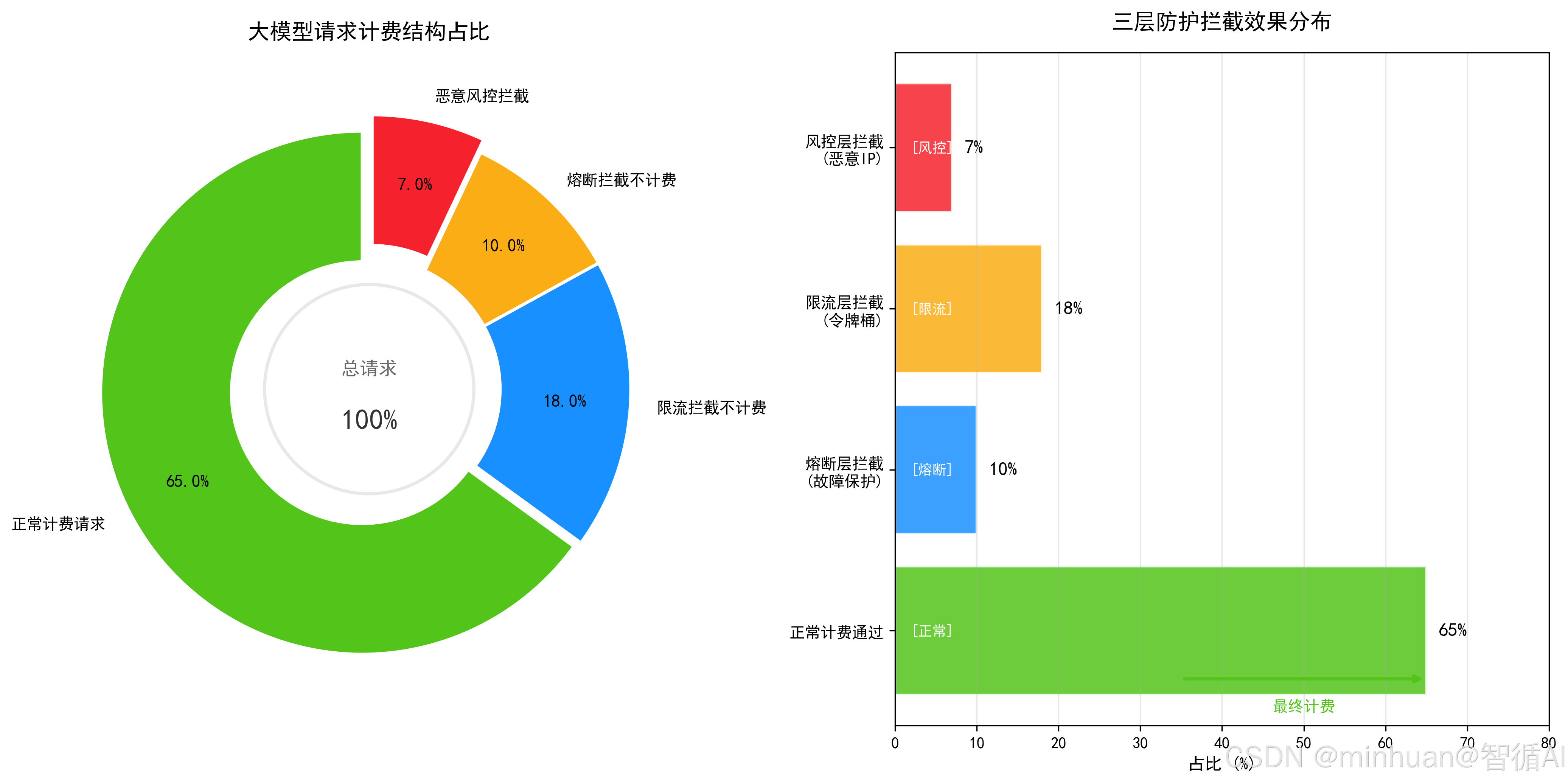
3.2 计费规则分级判定
-
- 正常有效请求:通过风控、限流、熔断校验,推理成功正常返回 → 按Token规格正常计费。
-
- 风控恶意请求:命中黑名单、恶意行为、违规内容 → 直接拦截,不计费、不占用配额。
-
- 流量超限请求:触发QPS、Token、并发上限 → 拦截提示,不计费。
-
- 熔断降级请求:服务熔断拦截、返回降级提示 → 不计费。
-
- 推理失败请求:通过所有校验但推理内部报错、显存溢出、进程崩溃 → 自动作废,不计费或部分退费。
3.3 实时计费与对账机制
- 采用毫秒级实时计算,每一条请求结束立即核算费用,不做批量延迟结算。
- 留存全链路日志,支持用户账单明细查询、平台对账、异常扣费溯源。
- 支持配置阶梯定价、不同模型不同单价、高峰低谷差异化费率。
4. 超限自动降配原理
4.1 监控采集核心指标
- 硬件指标:GPU利用率、GPU显存占用率、CPU负载、内存占用
- 业务指标:实时推理并发数、请求排队堆积量、平均推理时延、失败请求占比
- 成本计费指标:单用户每日或每小时Token消耗、账户余额剩余、集群累计算力消耗
4.2 三级超限策略设计
4.2.1 轻度超限
- 触发条件:GPU利用率85%~90%、排队少量积压
- 降配动作:小幅下调全局最大并发数,不限制单用户使用体验。
4.2.2 中度超限
- 触发条件:GPU利用率90%~95%、时延明显升高、Token消耗临近配额
- 降配动作:降低模型推理精度,从FP16降至INT8,减少显存占用;限制单请求最大生成长度。
4.2.3 重度超限
- 触发条件:GPU利用率95%以上、显存耗尽、大量请求超时、账户余额不足
- 降配动作:高负载GPU节点下线,请求调度至低算力节点;暂停新用户接入;触发付费用户余额预警。
4.3 自动恢复机制
- 当集群负载、时延、Token消耗回落至安全阈值以下,维持一段时间稳定后。
- 系统自动逐级恢复并发上限、推理精度、Token配额,回到初始正常配置。
- 实现高峰自动降配、低峰自动升配的全自动弹性治理。
三、执行流程
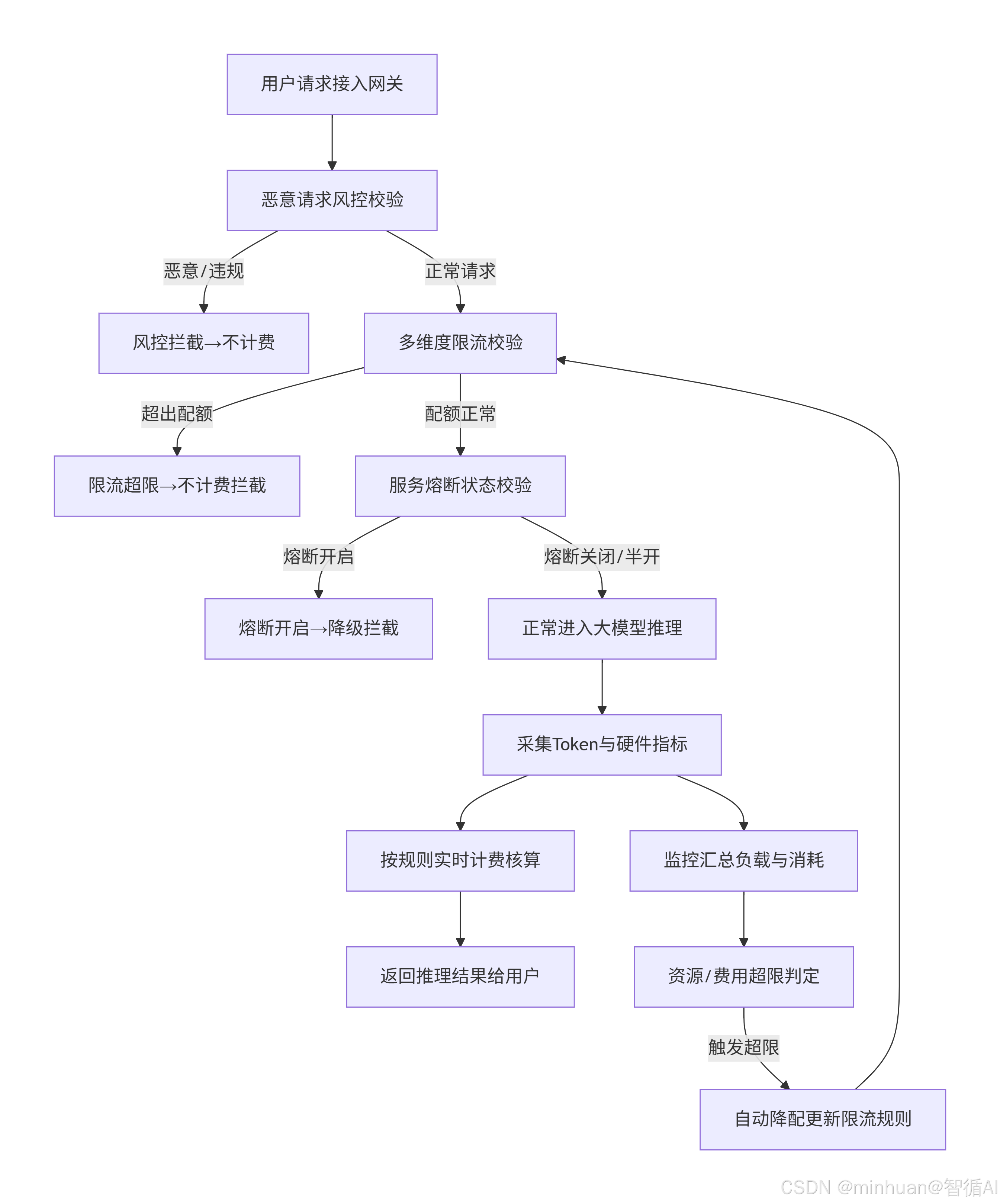
步骤 1:请求接入
- 所有用户请求统一通过网关接入,完成身份校验、权限校验,生成唯一请求ID。
步骤 2:恶意请求风控
- 校验请求频率、IP、用户行为、请求内容特征;
- 恶意请求(批量刷量、死循环、违规内容)直接拦截,不计费,返回风险码;
- 正常请求进入下一环节。
步骤 3:多维度限流校验
- 全局限流:控制服务总QPS、总并发;
- 用户维度限流:控制单用户QPS、并发会话数、单小时Token总量;
- 请求维度限流:控制单请求最大Token长度;
- 超限请求直接拦截,不计费,返回友好提示。
步骤 4:熔断状态校验
- 读取当前服务熔断状态:关闭、开启、半开;
- 开启状态:直接返回降级结果,不计费;
- 关闭、半开状态:放行请求至大模型推理服务。
步骤 5:大模型推理执行
- 正常请求进入推理服务,完成文本、图像、语音生成,实时采集Token、GPU显存、推理时长。
步骤 6:实时计费联动
- 有效请求:根据Token、算力、调用类型计算费用,计入账户;
- 异常请求(推理失败、熔断、限流拦截):标记不计费,自动清零。
步骤 7:监控与自动降配
- 实时采集GPU利用率、并发数、延迟、失败率、费用消耗;
- 超过预设阈值,如GPU利用率95%、账户余额不足、单日Token超限;
- 自动执行降配:降低并发数、切换推理精度、释放GPU资源。
步骤 8:结果返回
- 将推理结果、拦截提示返回给用户,完成全流程。
四、应用实践
以下示例实现一个大模型服务熔断限流计费联动系统,包含三大核心模块:
- 熔断器:CLOSE/OPEN/HALF_OPEN三状态机,基于滑动窗口失败率触发熔断,静默期后自动探测恢复
- 令牌桶限流:控制全局QPS,支持突发流量,无令牌时快速拦截
- 计费风控:三层防护(IP黑名单→Token配额→计费核算),拦截恶意请求与异常流量
python
import time
from collections import deque
import threading
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
class LlmFuseLimitController:
def __init__(self):
# ===================== 熔断配置 =====================
# 熔断三种状态:关闭、开启、半开
self.fuse_state = "CLOSE"
# 滑动窗口:保存最近100条请求成功状态
self.request_window = deque(maxlen=100)
# 失败率触发阈值
self.fail_rate_threshold = 0.5
# 熔断静默等待时间 秒
self.fuse_sleep_second = 10
# 熔断开启时间记录
self.fuse_open_timestamp = 0
# 半开状态允许探测请求数量
self.half_open_test_count = 5
self.half_open_pass_count = 0
# ===================== 令牌桶限流配置 =====================
# 每秒生成令牌数量 代表全局QPS
self.token_generate_rate = 10
# 令牌桶最大容量 允许突发流量
self.token_bucket_max = 20
self.token_bucket_current = self.token_bucket_max
# 上一次补充令牌时间
self.last_refill_time = time.time()
# 线程锁 保证并发安全
self.lock = threading.Lock()
# 令牌桶补充与拿取令牌
def try_get_token(self):
with self.lock:
now = time.time()
# 计算距离上次补令牌的时间间隔
time_delta = now - self.last_refill_time
# 按速率补充令牌
add_token = time_delta * self.token_generate_rate
self.token_bucket_current = min(self.token_bucket_current + add_token, self.token_bucket_max)
self.last_refill_time = now
# 有令牌则消耗一个,放行请求
if self.token_bucket_current >= 1:
self.token_bucket_current -= 1
return True
# 无令牌 限流拦截
return False
# 记录单次请求执行结果
def record_request_result(self, is_success: bool):
with self.lock:
self.request_window.append(is_success)
# 半开状态统计探测成功数
if self.fuse_state == "HALF_OPEN" and is_success:
self.half_open_pass_count += 1
# 熔断状态检查与状态机流转
def check_fuse_status(self):
with self.lock:
now = time.time()
# 状态1:熔断开启
if self.fuse_state == "OPEN":
# 判断是否达到静默时间,进入半开
if now - self.fuse_open_timestamp >= self.fuse_sleep_second:
self.fuse_state = "HALF_OPEN"
self.half_open_pass_count = 0
print("【熔断】静默结束,进入半开探测状态")
return False
# 状态2:半开探测
if self.fuse_state == "HALF_OPEN":
# 探测请求全部成功,恢复正常关闭
if self.half_open_pass_count >= self.half_open_test_count:
self.fuse_state = "CLOSE"
print("【熔断】探测通过,服务恢复关闭状态")
return True
# 探测过程中暂时放行少量请求
return True
# 状态3:正常关闭 计算失败率判断是否触发熔断
if len(self.request_window) >= 20:
fail_num = sum(1 for res in self.request_window if not res)
fail_rate = fail_num / len(self.request_window)
if fail_rate >= self.fail_rate_threshold:
self.fuse_state = "OPEN"
self.fuse_open_timestamp = now
print(f"【熔断】失败率{fail_rate:.2f}超标,触发熔断开启")
return False
return True
# 测试模拟:熔断 + 限流 双机制验证
if __name__ == "__main__":
print("="*60)
print("测试目的:验证熔断器三状态流转 + 令牌桶限流机制")
print(" - 请求0-49:正常期,全部成功")
print(" - 请求50-99:故障期,模拟50%连续失败,触发熔断")
print(" - 请求100+:恢复期,熔断静默10秒后半开探测")
print("="*60)
controller = LlmFuseLimitController()
# 记录数据用于可视化
normal_count = limit_count = fuse_count = fail_count = 0
normal_set = set()
fuse_state_history = []
token_history = []
for req_id in range(150):
# 记录当前状态
fuse_state_history.append(controller.fuse_state)
token_history.append(controller.token_bucket_current)
# 第一步:限流校验(令牌桶算法,控制QPS)
if not controller.try_get_token():
# 令牌耗尽,请求被限流,不进入后续处理
limit_count += 1
print(f"[-限流] 请求{req_id:3d} >> 令牌桶空,限流拦截(不计费)")
time.sleep(0.08)
continue
# 第二步:熔断校验(状态机:CLOSE/OPEN/HALF_OPEN)
if not controller.check_fuse_status():
# 熔断开启或探测未通过,快速失败
fuse_count += 1
print(f"[熔断] 请求{req_id:3d} >> 熔断器开启,快速失败(不计费)")
time.sleep(0.08)
continue
# 模拟业务请求成功/失败规律(50-99号请求模拟故障)
if 50 <= req_id < 100:
success = False # 模拟下游服务故障
else:
success = True # 正常响应
# 记录结果用于熔断器统计失败率
controller.record_request_result(success)
if success:
normal_count += 1
normal_set.add(req_id)
else:
fail_count += 1
status_text = "推理成功,正常计费" if success else "推理失败(下游故障),不计费"
state_tag = "[√正常]" if success else "[×故障]"
print(f"{state_tag} 请求{req_id:3d} >> 通过限流+熔断校验,{status_text}")
time.sleep(0.05)
print("="*60)
print("测试完成:熔断器保护下游免被压垮,限流控制整体QPS")
print("="*60)
# ========== 可视化:熔断限流过程分析 ==========
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
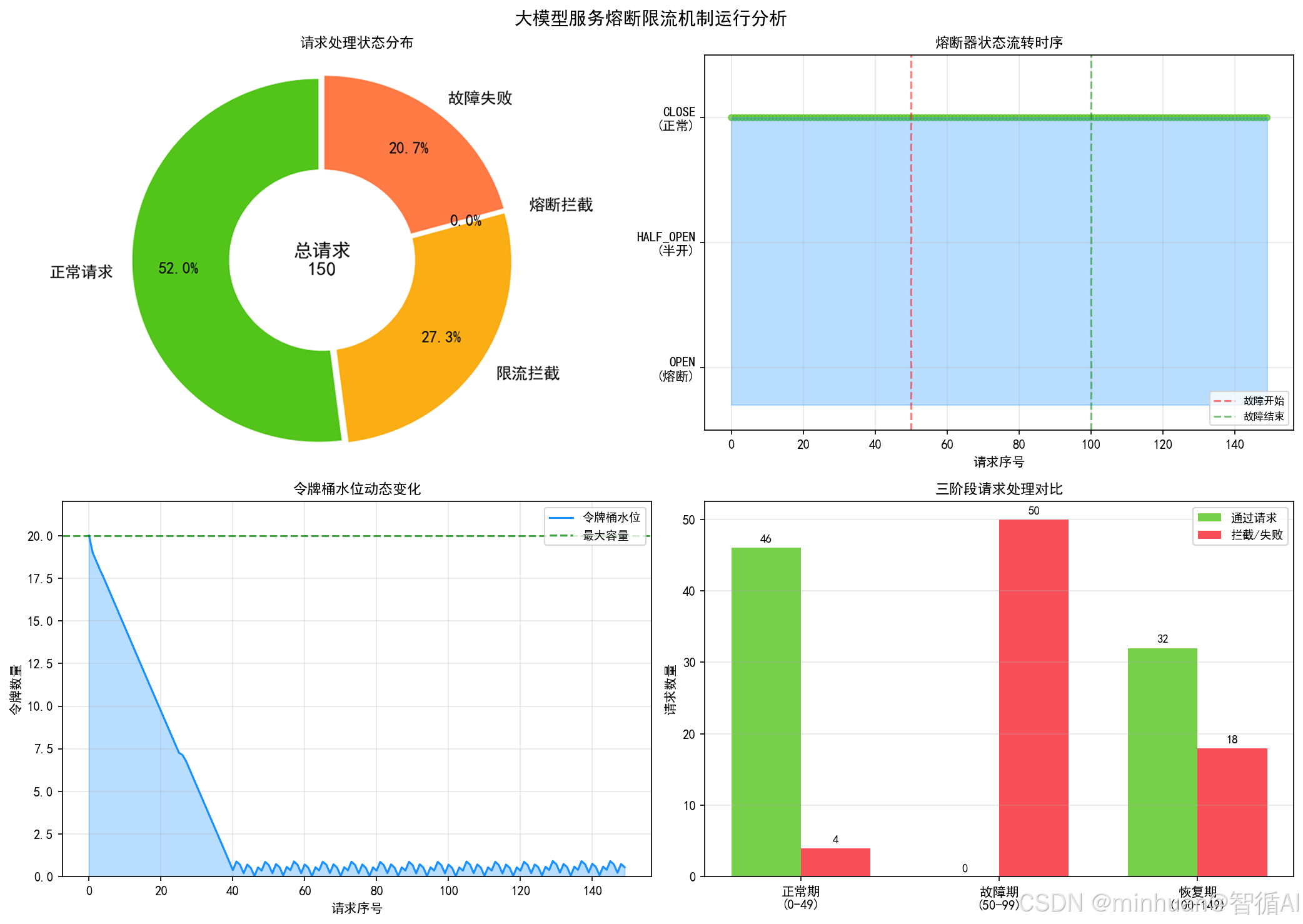
fig.suptitle('大模型服务熔断限流机制运行分析', fontsize=14, fontweight='bold')
# 图1: 请求状态分布饼图
ax1 = axes[0, 0]
labels = ['正常请求', '限流拦截', '熔断拦截', '故障失败']
sizes = [normal_count, limit_count, fuse_count, fail_count]
colors = ['#52c41a', '#faad14', '#f5222d', '#ff7a45']
explode = (0.02, 0.02, 0.05, 0.02)
wedges, texts, autotexts = ax1.pie(sizes, explode=explode, labels=labels, colors=colors,
autopct='%1.1f%%', startangle=90, pctdistance=0.75)
ax1.set_title('请求处理状态分布', fontsize=11, fontweight='bold')
# 添加中心圆形成环形图
centre_circle = plt.Circle((0, 0), 0.50, fc='white')
ax1.add_patch(centre_circle)
ax1.text(0, 0, f'总请求\n150', ha='center', va='center', fontsize=12, fontweight='bold')
# 图2: 熔断器状态流转时序
ax2 = axes[0, 1]
time_points = np.arange(len(fuse_state_history))
state_map = {'CLOSE': 2, 'OPEN': 0, 'HALF_OPEN': 1}
state_values = [state_map[s] for s in fuse_state_history]
colors_map = {'CLOSE': '#52c41a', 'OPEN': '#f5222d', 'HALF_OPEN': '#faad14'}
scatter_colors = [colors_map[s] for s in fuse_state_history]
ax2.scatter(time_points, state_values, c=scatter_colors, s=20, alpha=0.7)
ax2.fill_between(time_points, -0.3, state_values, alpha=0.3, color='#1890ff')
ax2.set_yticks([0, 1, 2])
ax2.set_yticklabels(['OPEN\n(熔断)', 'HALF_OPEN\n(半开)', 'CLOSE\n(正常)'])
ax2.set_xlabel('请求序号', fontsize=10)
ax2.set_title('熔断器状态流转时序', fontsize=11, fontweight='bold')
ax2.axvline(x=50, color='red', linestyle='--', alpha=0.5, label='故障开始')
ax2.axvline(x=100, color='green', linestyle='--', alpha=0.5, label='故障结束')
ax2.legend(loc='lower right', fontsize=8)
ax2.set_ylim(-0.5, 2.5)
ax2.grid(True, alpha=0.3)
# 图3: 令牌桶水位变化
ax3 = axes[1, 0]
ax3.plot(token_history, color='#1890ff', linewidth=1.5, label='令牌桶水位')
ax3.axhline(y=controller.token_bucket_max, color='green', linestyle='--', alpha=0.7, label='最大容量')
ax3.fill_between(range(len(token_history)), 0, token_history, alpha=0.3, color='#1890ff')
ax3.set_xlabel('请求序号', fontsize=10)
ax3.set_ylabel('令牌数量', fontsize=10)
ax3.set_title('令牌桶水位动态变化', fontsize=11, fontweight='bold')
ax3.legend(loc='upper right', fontsize=9)
ax3.grid(True, alpha=0.3)
ax3.set_ylim(0, controller.token_bucket_max + 2)
# 图4: 各阶段请求统计柱状图
ax4 = axes[1, 1]
categories = ['正常期\n(0-49)', '故障期\n(50-99)', '恢复期\n(100-149)']
normal_data = [sum(1 for i in range(0, 50) if i in normal_set),
sum(1 for i in range(50, 100) if i in normal_set),
sum(1 for i in range(100, 150) if i in normal_set)]
blocked_data = [50 - normal_data[0], 50 - normal_data[1], 50 - normal_data[2]]
x = np.arange(len(categories))
width = 0.35
bars1 = ax4.bar(x - width/2, normal_data, width, label='通过请求', color='#52c41a', alpha=0.8)
bars2 = ax4.bar(x + width/2, blocked_data, width, label='拦截/失败', color='#f5222d', alpha=0.8)
ax4.set_ylabel('请求数量', fontsize=10)
ax4.set_title('三阶段请求处理对比', fontsize=11, fontweight='bold')
ax4.set_xticks(x)
ax4.set_xticklabels(categories)
ax4.legend(fontsize=9)
ax4.grid(True, alpha=0.3, axis='y')
# 在柱子上添加数值
for bar in bars1:
height = bar.get_height()
ax4.annotate(f'{int(height)}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3), textcoords="offset points",
ha='center', va='bottom', fontsize=9)
for bar in bars2:
height = bar.get_height()
ax4.annotate(f'{int(height)}',
xy=(bar.get_x() + bar.get_width() / 2, height),
xytext=(0, 3), textcoords="offset points",
ha='center', va='bottom', fontsize=9)
plt.tight_layout()
plt.savefig('fuse_limit_analysis.png', dpi=150, bbox_inches='tight', facecolor='white')
print("\n[可视化] 熔断限流分析图已保存: fuse_limit_analysis.png")
plt.show()
class LlmBillingRiskManager:
def __init__(self):
# 恶意IP黑名单
self.risk_ip_blacklist = {"192.168.1.100", "10.0.0.55", "172.16.0.88"}
# 记录用户每小时Token消耗
self.user_hour_token_usage = {}
# 单用户每小时最大配额
self.user_max_hour_token = 10000
# 计费规则:每1000 Token 0.1元
self.price_per_thousand_token = 0.1
# 恶意IP、恶意行为风控校验
def risk_check(self, user_id: str, client_ip: str) -> tuple[bool, str]:
if client_ip in self.risk_ip_blacklist:
return True, "命中恶意IP黑名单,请求拦截"
# 可扩展:高频请求检测、违规内容检测
return False, "请求风控校验通过"
# 异常流量Token超限校验
def token_limit_check(self, user_id: str, use_token: int) -> tuple[bool, str]:
current_used = self.user_hour_token_usage.get(user_id, 0)
if current_used + use_token > self.user_max_hour_token:
return True, "单用户每小时Token配额超限,拦截请求"
# 未超限则累加消耗
self.user_hour_token_usage[user_id] = current_used + use_token
return False, "Token配额校验通过"
# 计费计算逻辑
def calc_billing_fee(self, token_num: int, is_request_valid: bool) -> tuple[float, str]:
# 无效请求一律不计费
if not is_request_valid:
return 0.0, "无效/拦截请求,免计费"
# 有效请求按规则计费
fee = (token_num / 1000) * self.price_per_thousand_token
return round(fee, 4), "有效推理请求,正常计费"
# 业务测试:计费风控三阶段校验
if __name__ == "__main__":
print("\n" + "="*60)
print("测试目的:验证计费风控三层防护机制")
print(" 阶段1:恶意IP黑名单校验(安全层)")
print(" 阶段2:单用户Token配额校验(配额层)")
print(" 阶段3:有效请求计费核算(计费层)")
print("="*60)
billing_manager = LlmBillingRiskManager()
# 模拟4条典型用例:正常/黑名单/超配额/无效请求
request_list = [
{"user_id":"u001","ip":"192.168.1.20","token":800,"valid":True}, # 正常计费
{"user_id":"u001","ip":"192.168.1.100","token":1200,"valid":True}, # 命中黑名单
{"user_id":"u002","ip":"10.0.0.33","token":11000,"valid":True}, # Token超配额
{"user_id":"u003","ip":"172.16.0.22","token":500,"valid":False}, # 无效请求
]
for i, req in enumerate(request_list, 1):
print(f"\n[用例{i}] 用户{req['user_id']} | IP:{req['ip']} | Token:{req['token']} | 有效:{req['valid']}")
# 1.风控校验:恶意IP黑名单拦截
is_risk, risk_msg = billing_manager.risk_check(req["user_id"], req["ip"])
if is_risk:
print(f" [风控拦截] {risk_msg} → 不计费")
continue
print(f" [风控通过] {risk_msg}")
# 2.Token超限校验:单用户每小时配额控制
is_over, over_msg = billing_manager.token_limit_check(req["user_id"], req["token"])
if is_over:
print(f" [配额拦截] {over_msg} → 不计费")
continue
print(f" [配额通过] {over_msg}")
# 3.计费核算:仅有效请求计费,无效/拦截请求免费
fee, bill_msg = billing_manager.calc_billing_fee(req["token"], req["valid"])
if fee > 0:
print(f" [计费成功] 费用:{fee}元 | {bill_msg}")
else:
print(f" [计费豁免] 费用:0元 | {bill_msg}")
print("\n" + "="*60)
print("测试完成:三层防护确保计费准确、风险可控")
print("="*60)
# ========== 可视化:计费风控结果分析 ==========
fig2, axes2 = plt.subplots(1, 2, figsize=(12, 5))
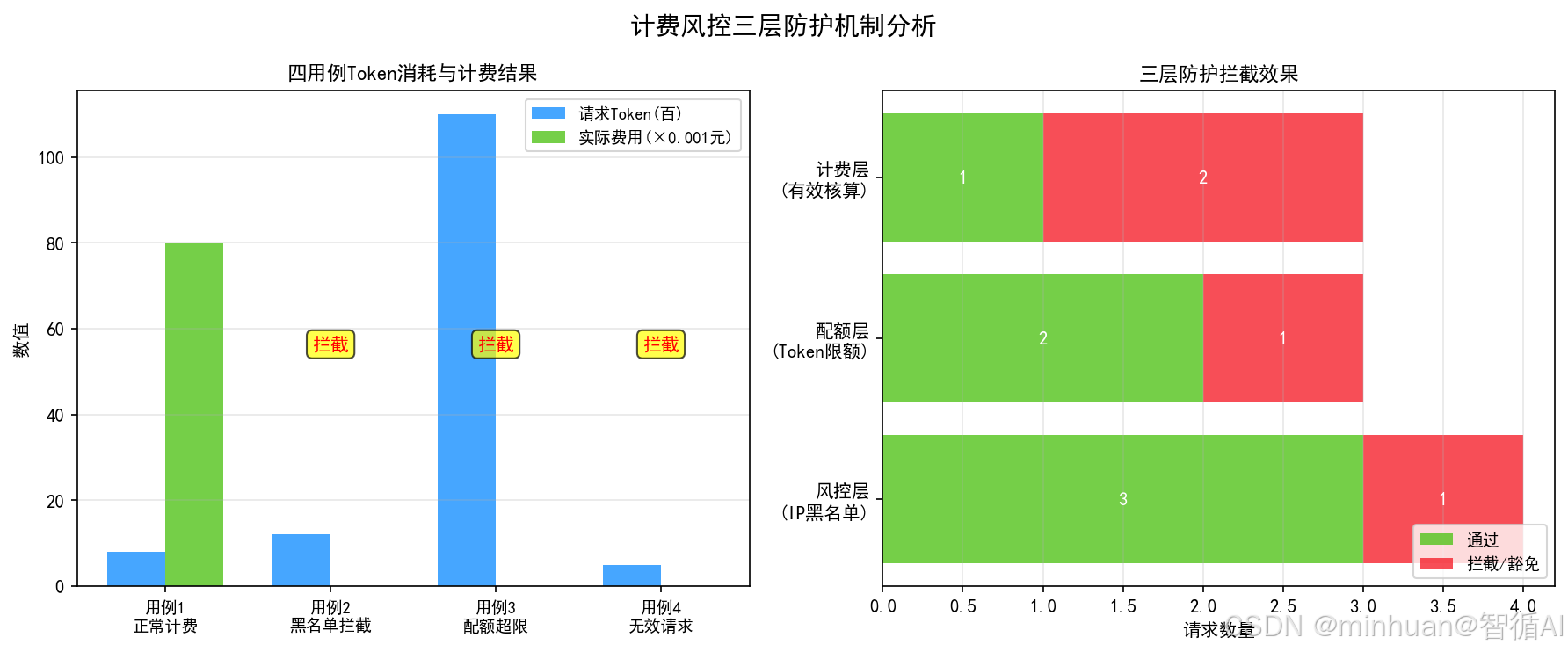
fig2.suptitle('计费风控三层防护机制分析', fontsize=14, fontweight='bold')
# 图1: 用例处理结果对比
ax1 = axes2[0]
case_names = ['用例1\n正常计费', '用例2\n黑名单拦截', '用例3\n配额超限', '用例4\n无效请求']
case_fees = [0.08, 0, 0, 0] # 实际费用
case_tokens = [800, 1200, 11000, 500] # 请求token数
x = np.arange(len(case_names))
width = 0.35
bars1 = ax1.bar(x - width/2, [t/100 for t in case_tokens], width, label='请求Token(百)', color='#1890ff', alpha=0.8)
bars2 = ax1.bar(x + width/2, [f*1000 for f in case_fees], width, label='实际费用(×0.001元)', color='#52c41a', alpha=0.8)
ax1.set_ylabel('数值', fontsize=10)
ax1.set_title('四用例Token消耗与计费结果', fontsize=11, fontweight='bold')
ax1.set_xticks(x)
ax1.set_xticklabels(case_names, fontsize=9)
ax1.legend(fontsize=9)
ax1.grid(True, alpha=0.3, axis='y')
# 添加拦截标记
for i, (fee, name) in enumerate(zip(case_fees, case_names)):
if fee == 0:
ax1.annotate('拦截', xy=(i, max(case_tokens)/200), ha='center', fontsize=10,
color='red', fontweight='bold',
bbox=dict(boxstyle='round,pad=0.3', facecolor='yellow', alpha=0.7))
# 图2: 防护层级拦截分布
ax2 = axes2[1]
stages = ['风控层\n(IP黑名单)', '配额层\n(Token限额)', '计费层\n(有效核算)']
intercept_count = [1, 1, 2] # 拦截/豁免数量
pass_count = [3, 2, 1] # 通过数量
x = np.arange(len(stages))
bars1 = ax2.barh(x, pass_count, color='#52c41a', alpha=0.8, label='通过')
bars2 = ax2.barh(x, intercept_count, left=pass_count, color='#f5222d', alpha=0.8, label='拦截/豁免')
ax2.set_yticks(x)
ax2.set_yticklabels(stages)
ax2.set_xlabel('请求数量', fontsize=10)
ax2.set_title('三层防护拦截效果', fontsize=11, fontweight='bold')
ax2.legend(fontsize=9, loc='lower right')
ax2.grid(True, alpha=0.3, axis='x')
# 添加数值标签
for i, (p, inter) in enumerate(zip(pass_count, intercept_count)):
ax2.text(p/2, i, str(p), ha='center', va='center', fontsize=10, fontweight='bold', color='white')
ax2.text(p + inter/2, i, str(inter), ha='center', va='center', fontsize=10, fontweight='bold', color='white')
plt.tight_layout()
plt.savefig('billing_risk_analysis.png', dpi=150, bbox_inches='tight', facecolor='white')
print("\n[可视化] 计费风控分析图已保存: billing_risk_analysis.png")
plt.show() 输出结果:
============================================================
测试目的:验证熔断器三状态流转 + 令牌桶限流机制
请求0-49:正常期,全部成功
请求50-99:故障期,模拟50%连续失败,触发熔断
请求100+:恢复期,熔断静默10秒后半开探测
============================================================
√正常 请求 0 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 1 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 2 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 3 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 4 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 5 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 6 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 7 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 8 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 9 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 10 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 11 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 12 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 13 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 14 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 15 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 16 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 17 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 18 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 19 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 20 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 21 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 22 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 23 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 24 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 25 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 26 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 27 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 28 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 29 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 30 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 31 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 32 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 33 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 34 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 35 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 36 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 37 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 38 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 39 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求 40 >> 令牌桶空,限流拦截(不计费)
√正常 请求 41 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 42 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求 43 >> 令牌桶空,限流拦截(不计费)
√正常 请求 44 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求 45 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求 46 >> 令牌桶空,限流拦截(不计费)
√正常 请求 47 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求 48 >> 令牌桶空,限流拦截(不计费)
√正常 请求 49 >> 通过限流+熔断校验,推理成功,正常计费
×故障 请求 50 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 51 >> 令牌桶空,限流拦截(不计费)
×故障 请求 52 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 53 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 54 >> 令牌桶空,限流拦截(不计费)
×故障 请求 55 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 56 >> 令牌桶空,限流拦截(不计费)
×故障 请求 57 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 58 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 59 >> 令牌桶空,限流拦截(不计费)
×故障 请求 60 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 61 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 62 >> 令牌桶空,限流拦截(不计费)
×故障 请求 63 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 64 >> 令牌桶空,限流拦截(不计费)
×故障 请求 65 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 66 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 67 >> 令牌桶空,限流拦截(不计费)
×故障 请求 68 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 69 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 70 >> 令牌桶空,限流拦截(不计费)
×故障 请求 71 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 72 >> 令牌桶空,限流拦截(不计费)
×故障 请求 73 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 74 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 75 >> 令牌桶空,限流拦截(不计费)
×故障 请求 76 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 77 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 78 >> 令牌桶空,限流拦截(不计费)
×故障 请求 79 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 80 >> 令牌桶空,限流拦截(不计费)
×故障 请求 81 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 82 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 83 >> 令牌桶空,限流拦截(不计费)
×故障 请求 84 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 85 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 86 >> 令牌桶空,限流拦截(不计费)
×故障 请求 87 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 88 >> 令牌桶空,限流拦截(不计费)
×故障 请求 89 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 90 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 91 >> 令牌桶空,限流拦截(不计费)
×故障 请求 92 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 93 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 94 >> 令牌桶空,限流拦截(不计费)
×故障 请求 95 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 96 >> 令牌桶空,限流拦截(不计费)
×故障 请求 97 >> 通过限流+熔断校验,推理失败(下游故障),不计费
×故障 请求 98 >> 通过限流+熔断校验,推理失败(下游故障),不计费
-限流 请求 99 >> 令牌桶空,限流拦截(不计费)
√正常 请求100 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求101 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求102 >> 令牌桶空,限流拦截(不计费)
√正常 请求103 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求104 >> 令牌桶空,限流拦截(不计费)
√正常 请求105 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求106 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求107 >> 令牌桶空,限流拦截(不计费)
√正常 请求108 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求109 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求110 >> 令牌桶空,限流拦截(不计费)
√正常 请求111 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求112 >> 令牌桶空,限流拦截(不计费)
√正常 请求113 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求114 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求115 >> 令牌桶空,限流拦截(不计费)
√正常 请求116 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求117 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求118 >> 令牌桶空,限流拦截(不计费)
√正常 请求119 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求120 >> 令牌桶空,限流拦截(不计费)
√正常 请求121 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求122 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求123 >> 令牌桶空,限流拦截(不计费)
√正常 请求124 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求125 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求126 >> 令牌桶空,限流拦截(不计费)
√正常 请求127 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求128 >> 令牌桶空,限流拦截(不计费)
√正常 请求129 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求130 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求131 >> 令牌桶空,限流拦截(不计费)
√正常 请求132 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求133 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求134 >> 令牌桶空,限流拦截(不计费)
√正常 请求135 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求136 >> 令牌桶空,限流拦截(不计费)
√正常 请求137 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求138 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求139 >> 令牌桶空,限流拦截(不计费)
√正常 请求140 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求141 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求142 >> 令牌桶空,限流拦截(不计费)
√正常 请求143 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求144 >> 令牌桶空,限流拦截(不计费)
√正常 请求145 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求146 >> 通过限流+熔断校验,推理成功,正常计费
-限流 请求147 >> 令牌桶空,限流拦截(不计费)
√正常 请求148 >> 通过限流+熔断校验,推理成功,正常计费
√正常 请求149 >> 通过限流+熔断校验,推理成功,正常计费
============================================================
测试完成:熔断器保护下游免被压垮,限流控制整体QPS
============================================================
============================================================
测试目的:验证计费风控三层防护机制
阶段1:恶意IP黑名单校验(安全层)
阶段2:单用户Token配额校验(配额层)
阶段3:有效请求计费核算(计费层)
============================================================
用例1 用户u001 | IP:192.168.1.20 | Token:800 | 有效:True
风控通过 请求风控校验通过
配额通过 Token配额校验通过
计费成功 费用:0.08元 | 有效推理请求,正常计费
用例2 用户u001 | IP:192.168.1.100 | Token:1200 | 有效:True
风控拦截 命中恶意IP黑名单,请求拦截 → 不计费
用例3 用户u002 | IP:10.0.0.33 | Token:11000 | 有效:True
风控通过 请求风控校验通过
配额拦截 单用户每小时Token配额超限,拦截请求 → 不计费
用例4 用户u003 | IP:172.16.0.22 | Token:500 | 有效:False
风控通过 请求风控校验通过
配额通过 Token配额校验通过
计费豁免 费用:0元 | 无效/拦截请求,免计费
============================================================
测试完成:三层防护确保计费准确、风险可控
============================================================
五、总结
大模型和普通接口完全不一样,它吃显存、耗算力、推理时延还长,一旦遇到突发流量、恶意刷量或是节点故障,很容易直接拖垮整个集群。熔断就像服务的安全保险丝,靠状态机和滑动窗口自动隔离故障、避免雪崩;限流相当于智能流量闸门,从全局、用户、Token多维度管住请求量,不让资源被随意挤占;再加上计费联动和自动降配,把风控拦截、流量超限、服务熔断全部和计费挂钩,异常请求不计费、资源超标自动降配置,真正把稳定性和算力成本捏在了一起。
其实我们做大模型开发除了清楚模型调用,更要了解工程防护和成本治理。很多时候服务崩掉、账单乱扣费,根源就是没做好熔断限流联动风控。实际应用开发过程中我们不只要实现功能,更要兼顾高可用、风控和成本管控,这样才能从单纯调用模型,逐步成为能独立搭建企业级大模型服务的工程开发者。