摘要:血细胞形态学检查是血液疾病筛查与疗效评估的重要环节,但在显微镜视野下的细胞定位、计数与类型判读高度依赖人工经验,易受染色差异、细胞重叠与背景噪声影响。本文构建了一套基于深度学习的血细胞检测与统计系统,面向外周血/骨髓涂片等图像,实现对白细胞、红细胞及血小板等目标的自动检测、分类与数量统计。方法上以 YOLO 系列作为核心检测器,在迁移学习框架下完成数据标注、质量控制与训练验证划分,并结合颜色归一化与染色扰动增强以提升对跨设备、跨批次成像的鲁棒性;同时对 YOLO 不同版本/尺度模型进行对比实验,给出 mAP、F1、PR 曲线与推理速度等指标分析。系统工程方面采用 PySide6 搭建交互界面,支持图片/视频/显微镜摄像头输入,提供置信度与 IoU 阈值调节、检测框与类别可视化、热力图辅助分析、结果导出与 SQLite 持久化存储等功能。该系统可用于实验室场景下的血细胞检测辅助分析与教学示范,为血细胞智能识别的工程落地提供可复现的实现参考。
文章目录
- 1.前言综述
- 2.数据集介绍
- [3. 模型设计与实现](#3. 模型设计与实现)
- [4. 训练策略与模型优化](#4. 训练策略与模型优化)
- [5. 实验与结果分析](#5. 实验与结果分析)
-
- [5.1 实验设计与设置](#5.1 实验设计与设置)
- [5.2 度量指标](#5.2 度量指标)
- [5.3 实验结果与分析](#5.3 实验结果与分析)
- 6.系统设计与实现
-
- [6.1 系统设计思路](#6.1 系统设计思路)
- [6.2 登录与账户管理 --- 流程图](#6.2 登录与账户管理 — 流程图)
- [7. 下载链接](#7. 下载链接)
- 8.参考文献
1.前言综述
外周血涂片的细胞识别与分类是贫血、感染、血液肿瘤等疾病筛查与分型的重要基础,但显微镜下的人工计数与形态判读高度依赖经验、耗时且存在观察者差异。1在检验医学迈向数字化与智能化的过程中,如何把"看得见的形态学证据"转化为可复核、可统计、可追溯的量化结果,成为血细胞自动检测系统的核心任务。
随着数字显微成像、计算存储与标注工具的普及,深度学习已经成为医学图像自动分析的主流路线,并在检测、分割与分类等任务上系统性超越了传统特征工程范式。2在血细胞场景中,系统既要完成红细胞、白细胞、血小板等多目标的稳健检出,又要兼顾计数准确性与细分类的判别能力,并在有限算力与临床时效要求下完成端到端推理。
在像素级分割方面,U-Net 通过编码器---解码器结构与跳跃连接实现了在小样本条件下的精细边界恢复,为细胞核/细胞质分割与形态量化提供了经典基线。3在目标级检测方面,两阶段框架以候选区域生成与分类回归解耦的方式提升了小目标定位的鲁棒性,Faster R-CNN 及其 RPN 机制是该范式的代表。4当任务从"框出细胞"进一步走向"实例级分割与计数"时,Mask R-CNN 将检测与掩膜预测并行化,为重叠细胞的分离与逐个计数提供了更直接的建模路径。5然而血涂片中血小板与部分异常细胞往往数量稀少且尺寸微小,训练阶段的类别不均衡会显著放大误检与漏检,Focal Loss 对这一难点给出了可迁移的损失层解决思路。6
在临床与检验科的实际落地场景中,系统往往需要在普通 GPU 甚至边缘设备上实现准实时推理,因此以单阶段回归为核心的 YOLO 系列因其速度优势而被广泛用于细胞级目标检测。7
近年视觉 Transformer 以自注意力建模长程依赖,在跨染色、跨显微镜的特征一致性学习上展现潜力,ViT 的提出推动了检测与分类网络从纯卷积骨干向混合骨干的演进。8进一步地,Swin Transformer 通过分层窗口注意力兼顾全局建模与计算效率,为密集预测任务提供了可扩展的通用骨干,使得在高分辨率显微图像上进行多尺度建模更为可行。9
国内研究中,张昊等在 BCCD 数据集上将坐标注意力与改造后的特征金字塔融合到 YOLOv5 中,并通过新增小目标检测层改善血小板识别,体现了"注意力---多尺度---小目标"三类改进对该任务的直接增益。10在轻量化与工程部署方面,Shi 等提出的 GPMB-YOLO 以 YOLOv8n 为基线,引入参数友好的注意力与双向特征金字塔等设计,在提升 mAP 的同时显著压缩模型复杂度,契合检验场景对速度与算力的双重约束。11针对显微图像中细胞边界模糊与特征尺度跨度大等问题,Maitlo 等提出的 AYOLOv5 通过多注意力特征融合与改进的目标框回归损失增强定位质量,为提升复杂背景下的检测稳定性提供了另一条思路。12在白细胞细分类上,Tarimo 等将 YOLOv5 的候选框裁剪与 ViT 的表征能力结合,构建"检测---分类"两阶段流水线并在 16 类任务上取得高精度,说明将检测与细粒度分类解耦仍然具有方法学价值。13与此同时,Kang 等在 ICIP 2024 提出的 CST-YOLO 以改进 YOLOv7 与 CNN-Swin 混合结构为核心,尝试在检测主干中融入更强的注意力表达以应对形态差异较大的细胞类别。14面向跨场景可用性,Jeong 等在 BIBM 2024 报告的两阶段框架使用 YOLOv8 完成完整细胞检测,再用 DenseNet 完成 6 类白细胞分类,为"先检出、再判别"的系统化部署给出了可复用范式。15
尽管相关研究已覆盖检测、分割、细分类等关键环节,但在工程化落地时仍会集中遭遇若干共性难点:染色差异与成像噪声带来的域偏移会削弱模型的泛化能力;细胞重叠、遮挡与边界黏连会导致计数偏差;血小板等极小目标与稀有白细胞类别带来显著的尺度不均衡与类别不均衡;同时,临床应用还要求输出结果具备可解释的可视证据与稳定的推理时延。
在本文的工作中将以 YOLO 族模型为主线构建血细胞检测系统,围绕小目标与多尺度检测对基线模型进行针对性改进,并与多种主流检测器进行统一数据集上的性能对比。与此同时,本文将整理并标注任务相关数据集,完成规范化划分与预处理,并基于 PySide6 设计可交互的检测界面,支持结果可视化、统计与导出,形成可复现实验与可部署应用兼具的完整工程闭环。
主要功能演示:
(1)登录注册演示 :系统启动后首先进入登录界面,用户可选择登录或跳转注册。注册流程在本地 SQLite 中写入用户信息,并对口令采用"随机盐 + 哈希"的方式持久化存储,避免明文风险;登录阶段完成用户名查验与口令校验后,加载该用户的历史检测记录与个性化配置(主题、阈值、默认模型等),再进入主界面。为保证交互一致性,登录态与用户配置在控制层统一管理,支持退出登录与重新登录,以便在同一设备上进行多用户切换。
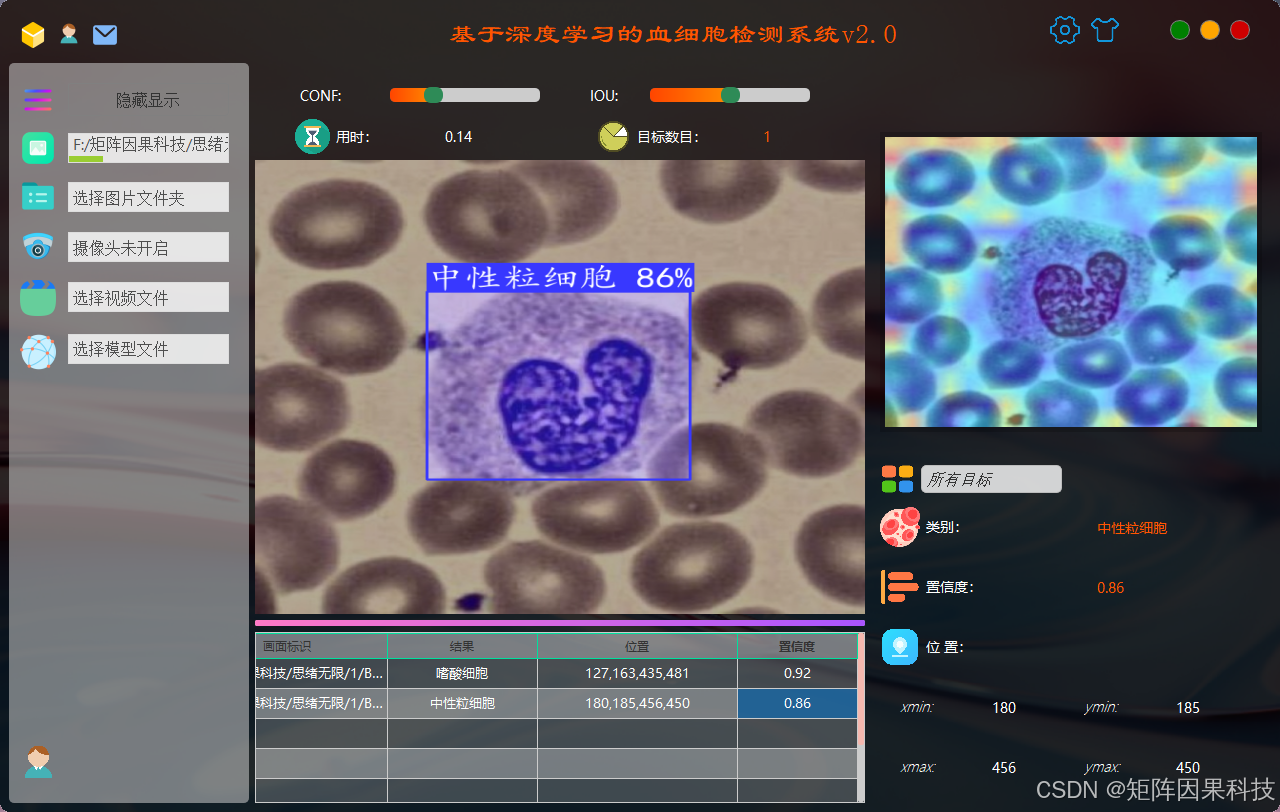
(2)页面布局演示 :主界面采用典型的"显示区 + 控制区 + 结果区"布局组织信息。显示区用于渲染原始图像/视频帧与叠加检测框结果;控制区集中放置输入源切换(图片/视频/摄像头)、置信度阈值与 IoU 阈值调节、推理开关与播放控制等;结果区以表格形式列出每个目标的类别、置信度、坐标等信息,并提供按类别筛选与统计汇总。底部状态栏同步输出推理耗时、帧率、当前模型与运行状态,使检测过程具备可追踪的工程可观测性。
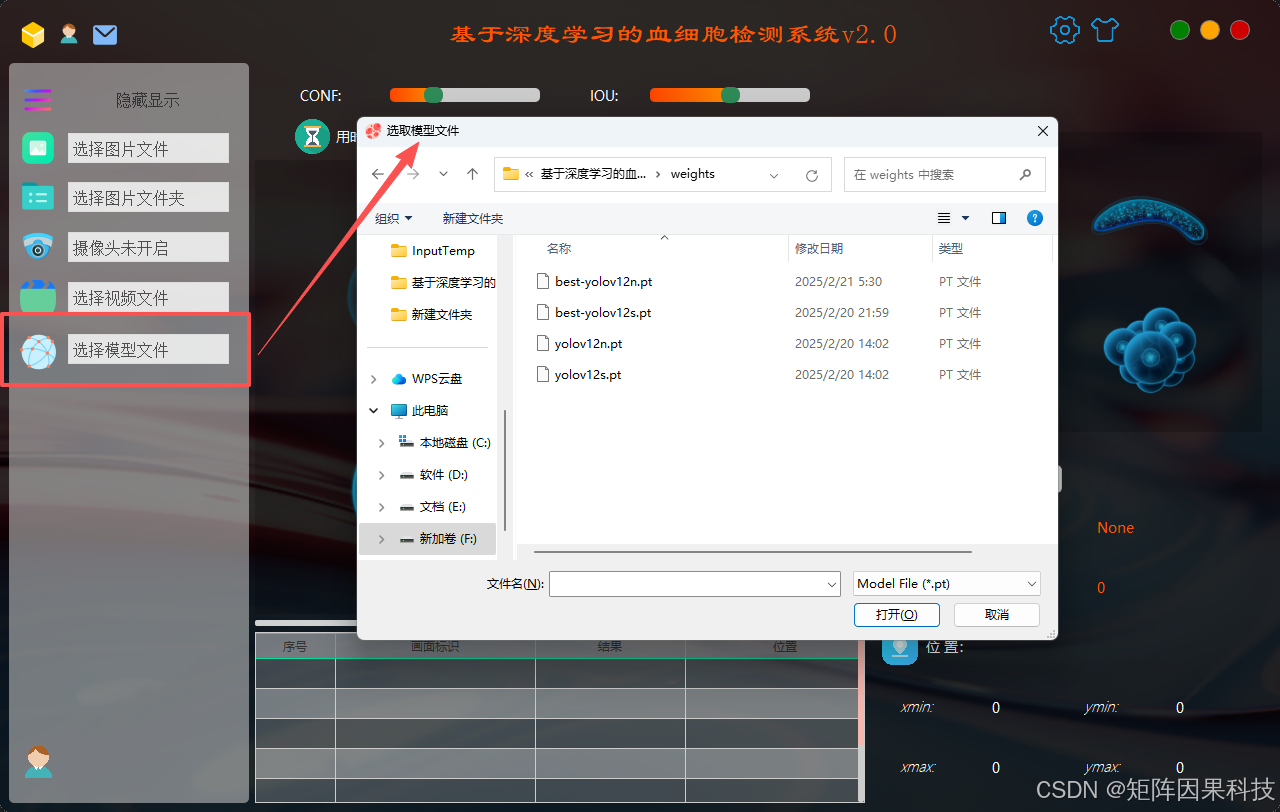
(3)模型选择演示 :系统在界面侧提供模型下拉选择与权重导入入口,支持在 YOLO 系列不同版本/不同尺度间切换(例如轻量模型用于实时预览,更大模型用于离线精检),并允许加载用户自定义的权重文件。模型加载与推理采用独立工作线程执行,通过 Qt 信号-槽机制将推理结果回传主线程更新界面,避免阻塞 UI;切换模型时会进行资源释放与显存复用,并在界面上提示当前模型的输入尺寸与加载状态,从而保证交互过程稳定可控。
(4)主题修改演示 :为适配不同光照环境与读图习惯,系统提供主题切换与样式自定义能力,例如浅色/深色主题、字体大小、控件圆角与间距、图标与背景图替换等。主题样式通过 Qt 样式表(QSS)统一管理,修改后即时生效,并将主题参数写入 SQLite 的用户配置表,实现"按用户保存、登录自动恢复"的个性化体验;该机制使界面呈现与检测功能解耦,便于后续迭代不同风格的 UI 而不影响推理链路。
2.数据集介绍
本项目构建的血细胞检测数据集总计 8,900 张 显微图像,已完成目标框标注与基础清洗,并按照"训练---验证---测试"的工程闭环进行划分:训练集 **6,587 张(74.0%)**用于参数学习,验证集 **1,869 张(21.0%)**用于超参数选择与早停判据,测试集 **444 张(5.0%)**用于最终泛化评估。数据在入库阶段进行了统一命名与格式整理,并对明显失焦、过曝、严重污染(油渍/划痕)样本做了剔除或重采样,保证标注与成像质量的下限一致;标注采用矩形框描述实例位置,标签文件与图像一一对应,满足 YOLO 系列检测器的端到端训练需求。训练批次的 Mosaic 可视化与验证集标签/预测对照图可以直观反映该数据集"密集小目标(血小板)+ 中尺度目标(红细胞)+ 大目标(白细胞)"并存的典型结构特征。
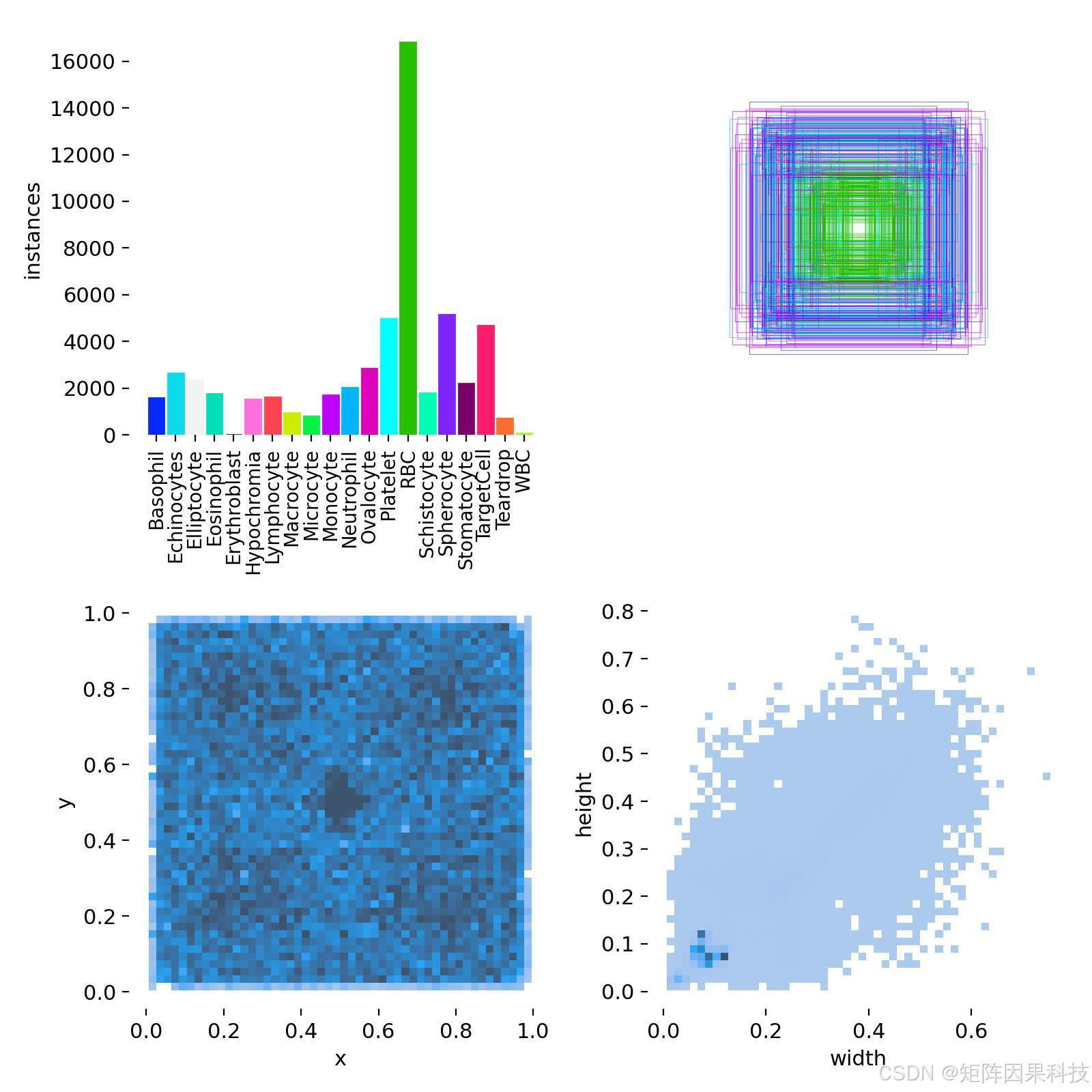
从类别分布与标注统计来看,数据集中红细胞(RBC)实例数显著高于其他类别,呈现典型的长尾分布;血小板(Platelet)数量处于第二梯队但单体尺度更小,对检测器的特征分辨率与召回率提出更高要求;各类白细胞(如 Neutrophil、Monocyte、Basophil 等)在数量上相对稀疏但形态差异更强,决定了分类头的判别上限。标注框中心点在视野内分布较为均匀,但宽高分布表现出明显的多峰特征:一部分框对应血小板等极小目标,另一部分对应白细胞等大目标;这种"尺度混合 + 类别不均衡"的数据形态,直接解释了为何后续模型设计与训练策略需要强调多尺度特征融合、正负样本分配稳定性以及对小目标的专门优化。老思在后续实验中也会据此将阈值、输入分辨率与增强策略作为关键变量进行控制,以确保对该数据集的评估具有可复现性与可解释性。
📊 数据集规格说明 (Dataset Specification)
| 维度 | 参数项 | 详细数据 |
|---|---|---|
| 基础信息 | 标注软件 | LabelImg |
| 标注格式 | YOLO TXT (Normalized) | |
| 数量统计 | 训练集 (Train) | 6,587 张 (74.0%) |
| 验证集 (Val) | 1,869 张 (21.0%) | |
| 测试集 (Test) | 444 张 (5.0%) | |
| 总计 (Total) | 8,900 张 | |
| 类别清单 | Class ID: 0 | Basophil / 嗜碱细胞 |
| Class ID: 1 | Echinocytes / 刺状红细胞 |
|
| Class ID: 2 | Elliptocyte / 椭圆形红细胞 |
|
| Class ID: 3 | Eosinophil / 嗜酸细胞 |
|
| Class ID: 4 | Erythroblast / 红细胞前体 |
|
| Class ID: 5 | Hypochromia / 低色素症 |
|
| Class ID: 6 | Lymphocyte / 淋巴细胞 |
|
| Class ID: 7 | Macrocyte / 大细胞 |
|
| Class ID: 8 | Microcyte / 小细胞 |
|
| Class ID: 9 | Monocyte / 单核细胞 |
|
| Class ID: 10 | Neutrophil / 中性粒细胞 |
|
| Class ID: 11 | Ovalocyte / 椭圆细胞 |
|
| Class ID: 12 | Platelet / 血小板 |
|
| Class ID: 13 | RBC / 红细胞 |
|
| Class ID: 14 | Schistocyte / 裂片细胞 |
|
| Class ID: 15 | Spherocyte / 球形细胞 |
|
| Class ID: 16 | Stomatocyte / 口形细胞 |
|
| Class ID: 17 | TargetCell / 靶细胞 |
|
| Class ID: 18 | Teardrop / 泪滴细胞 |
|
| Class ID: 19 | WBC / 白细胞 |
|
| 图像规格 | 输入尺寸 | 640 * 640 |
| 数据来源 | 显微镜血涂片图像(BloodCells_SIXU_* 命名体系),手动清洗与预处理 |
3. 模型设计与实现
面向血细胞显微图像的检测任务,模型需要同时满足三个约束:其一,密集小目标 (如血小板)对特征分辨率与召回率极为敏感;其二,红细胞形态类(如椭圆形、裂片、靶形、泪滴等)存在较强的细粒度外观差异但类间边界并不总是清晰;其三,系统侧需在 GUI 中实现交互式推理,因此推理链路必须稳定、易部署。基于这些约束,老思将检测器选型收敛到 YOLO 族:单阶段检测在速度与工程可用性上更贴近"界面实时预览 + 可导出结果"的应用形态,同时其多尺度特征融合与端到端训练范式更适合密集目标场景。Ultralytics 文档对 YOLO12 的定位是"注意力为中心的实时检测器",强调在保持实时性的同时引入更强的全局建模能力,这与本任务中"同类目标形态多变、跨视野背景扰动明显"的特点较为契合。(Ultralytics Docs)
在基线模型选择上,若仅从 backbone 的表达能力讨论,经典卷积骨干(ResNet、MobileNet、EfficientNet)在特征复用与轻量化方面各有优势,但它们往往需要额外设计检测颈部与检测头才能形成完整的端到端检测器。相比之下,YOLO 系列将"骨干特征提取---多尺度融合---检测头"作为统一结构进行协同优化,更利于在同一训练脚本中完成增强策略、损失与分配策略的系统调参。本文默认采用 YOLO12n 作为主模型,原因并非单纯追求更大的网络容量,而是希望利用 YOLO12 的注意力模块在复杂纹理背景下提升目标可分性;同时保留 YOLO11/YOLOv10 等轻量模型作为可切换方案,以便在 GUI 端根据硬件与实时性要求选择更合适的速度---精度折中。(Ultralytics Docs)
从网络结构实现角度看,本文将检测器抽象为三段式信息流:输入图像经过骨干网络形成多尺度语义特征,随后在颈部进行自顶向下与自底向上的融合,最终由检测头在不同尺度特征图上输出类别与边界框。YOLO12 的关键差异在于其注意力中心化 设计:文档与公开论文均提到 Area Attention、R-ELAN、以及以 7 × 7 7\times7 7×7 可分离卷积作为"位置感知器"的结构,用以在较低代价下获得更大的有效感受野,并通过可选 FlashAttention 进一步降低注意力计算的内存访存开销。(Ultralytics Docs) 对于血小板这类极小目标,本文在实现中优先保证浅层高分辨率特征的可用性:训练侧将输入统一到 640 × 640 640\times640 640×640,并在特征融合阶段保持对小尺度层(高分辨率层)的充分利用,使检测头能够在"细粒度纹理 + 局部对比度变化"条件下维持较高召回。
检测头与标签分配策略直接决定训练稳定性与推理效率。YOLOv10 提出的一条重要思路是"训练期 one-to-many 监督、推理期 one-to-one 输出",以降低对 NMS 的依赖并改善端到端延迟;Ultralytics 文档也用示意图给出了 backbone--PAN--双头的整体信息流。(Ultralytics Docs) 这一思想对 GUI 场景尤其友好:当推理后处理变轻,界面刷新频率更稳定;同时在密集目标(血小板)场景中,one-to-many 的丰富监督也有助于缓解"高 IoU 正样本稀缺"导致的早期训练不充分问题。
损失函数方面,本文采用"分类---回归"联合优化的常见形式,并针对小目标与类间相似的特点,优先保证定位质量与分类置信度的可校准性。分类损失以二元交叉熵为核心(多类场景下对每一类做独立 Sigmoid),其形式为
L c l s = − ∑ c = 1 K ( y c log p c + ( 1 − y c ) log ( 1 − p c ) ) , L_{\mathrm{cls}}=-\sum_{c=1}^{K}\Big(y_c\log p_c+(1-y_c)\log(1-p_c)\Big), Lcls=−c=1∑K(yclogpc+(1−yc)log(1−pc)),
其中 p c p_c pc 为预测概率, y c ∈ 0 , 1 y_c\in{0,1} yc∈0,1 为类别标签。为降低过拟合并抑制"极少数类被过度自信预测",实现中可引入标签平滑,将 y c y_c yc 替换为
y c ′ = ( 1 − ε ) y c + ε K , y_c'=(1-\varepsilon)y_c+\frac{\varepsilon}{K}, yc′=(1−ε)yc+Kε,
使模型在长尾分布下更易获得稳定的置信度分布。(Ultralytics Docs)
边界框回归部分采用 IoU 系列损失(例如 CIoU)以同时约束重叠、中心距离与长宽比:
L C I o U = 1 − I o U + ρ 2 ( b , b ∗ ) c 2 + α v , L_{\mathrm{CIoU}}=1-\mathrm{IoU}+\frac{\rho^2(\mathbf{b},\mathbf{b}^*)}{c^2}+\alpha v, LCIoU=1−IoU+c2ρ2(b,b∗)+αv,
其中 ρ ( ⋅ ) \rho(\cdot) ρ(⋅) 表示预测框与真值框中心点距离, c c c 为最小外接框对角线长度, v v v 描述长宽比一致性, α \alpha α 为平衡系数。对于高精度定位,很多现代 YOLO 实现还会引入分布式回归思想(DFL 类损失)以提升边界离散化表达能力,本文在 Ultralytics 框架下沿用其默认实现,并将总损失写作
L = λ b o x L b o x + λ c l s L c l s + λ d f l L d f l , L=\lambda_{\mathrm{box}}L_{\mathrm{box}}+\lambda_{\mathrm{cls}}L_{\mathrm{cls}}+\lambda_{\mathrm{dfl}}L_{\mathrm{dfl}}, L=λboxLbox+λclsLcls+λdflLdfl,
三项权重由框架默认值与验证集表现共同确定。(Ultralytics Docs)
工程实现层面,本文基于 Ultralytics 提供的统一接口完成模型加载、训练与导出,并将推理封装进系统的 Detector 处理层:初始化时读取权重与类别映射,推理时完成预处理(Resize/Normalize)、前向计算与后处理(阈值过滤、必要时的轻量 NMS/one-to-one 输出),最后将检测框、类别与置信度通过 Qt 信号发送给界面层完成绘制与统计。由于本项目类别包含 20 类血细胞/红细胞形态目标,推理输出除 bbox 与 score 外,还会同步生成"按类别计数"的结构化结果,便于后续写入 SQLite 并支持历史查询与导出。
如果你希望这一节把"本文对 YOLO 的具体改进点"也一并写进来(例如是否加 P2 小目标层、是否引入坐标注意力/CBAM、是否调整正负样本分配或损失权重),你把改动点用一句话列出来,老思就按你真实实现把这一节进一步落细到"可复现实验"的程度。
4. 训练策略与模型优化
血细胞显微图像的训练过程本质上是在"尺度混合、密集小目标、类别长尾、跨染色域偏移"四类因素的共同约束下寻找稳定收敛的最优点。老思在本项目中采用 Ultralytics 训练管线组织实验,环境以 Python 3.12 与 PyTorch 为主,GPU 侧使用 RTX 4090(CUDA 加速),并开启混合精度以降低显存压力、提升吞吐;同时固定随机种子并尽量使用确定性算子,保证不同轮次与不同模型对比时的可复现性。训练过程中每个 epoch 进行一次验证集评估,保存验证集主指标最优的权重(best.pt),并结合早停机制避免后期过拟合或无效迭代。
考虑到本任务的标注框同时覆盖血小板等极小目标与白细胞等大目标,输入尺寸统一到 640 × 640 640\times640 640×640 以兼顾推理时延与小目标分辨率;优化器由框架自动选择(通常在 SGD/AdamW 等候选中依据配置决定),学习率采用余弦退火并配合 warmup,使初期梯度更新更平滑,降低密集目标场景中"早期震荡导致的召回塌陷"。此外,权重衰减用于抑制过拟合,EMA(指数滑动平均)在经验上能够提升验证阶段的稳定性与泛化表现,因而默认保持开启。对于类别长尾问题,训练侧不依赖单一技巧:一方面通过增强策略扩大少数类的有效曝光,另一方面通过合理的正负样本分配与损失权重设置,使梯度贡献不会长期被 RBC 等高频类别主导;在必要时也可以对少数类样本进行过采样或启用类别权重,但这类操作需要以验证集 PR/F1 的变化为准,避免引入新的偏置。
数据增强策略以"增加域随机性但不破坏形态学证据"为原则:训练前中期启用 Mosaic、随机缩放/平移/轻度旋转、HSV 抖动与对比度扰动,用于覆盖染色深浅、光照变化与视野位置变化;而在训练后期逐步弱化强增强(例如在最后若干轮关闭 Mosaic),让网络在更接近真实分布的样本上细化边界框回归与类别判别,从而提升定位精度与置信度校准能力。由于血细胞分类高度依赖细胞核纹理与胞质染色差异,增强强度需要受控:过强的颜色变换或几何形变会破坏形态学细节,导致模型学到与临床判读不一致的伪特征,因此训练中应以验证集的"细粒度类别混淆"变化作为调参依据,而不仅仅追求 mAP 的单点提升。
为便于复现实验,本文采用的默认训练超参数如下(若你后续提供实际日志,我可以按你的真实配置替换并把解释写得更贴近实现):
| 名称 | 作用(简述) | 数值 |
|---|---|---|
| epochs | 最多训练轮数 | 120 |
| patience | 早停耐心(验证无提升则停止) | 50 |
| batch | 总批大小 | 16 |
| imgsz | 输入分辨率 | 640 |
| pretrained | 载入预训练权重 | true |
| optimizer | 优化器类型 | auto |
| lr0 | 初始学习率 | 0.01 |
| lrf | 最终学习率占比 | 0.01 |
| momentum | 动量系数 | 0.937 |
| weight_decay | 权重衰减 | 0.0005 |
| warmup_epochs | 学习率预热轮数 | 3.0 |
| mosaic | Mosaic 增强强度/概率 | 1.0 |
| close_mosaic | 后期关闭 Mosaic 的轮数 | 10 |
在模型部署与系统响应优化方面,训练完成后通常需要将权重导出为更高效的推理格式以支撑 GUI 的交互体验。工程上优先采用 ONNX 作为中间表示,进一步可转换为 TensorRT 引擎以获得更低的端到端时延;推理阶段使用 FP16 既能保持较高精度,又能显著降低显存占用并提升吞吐。与此同时,界面端将推理放入独立工作线程,主线程仅负责渲染与交互,避免因单帧推理波动导致 UI 卡顿;后处理阶段对阈值过滤与 NMS(或 one-to-one 输出模式)进行轻量化实现,并将"检测框列表 + 类别统计"作为结构化结果一次性回传,从而减少跨线程数据拷贝与界面刷新开销。综合而言,这一套训练与优化策略的目标不是追求单指标极值,而是让模型在真实显微图像的复杂条件下保持稳定收敛,并在系统层面实现可持续的实时交互与结果可追溯。
5. 实验与结果分析
5.1 实验设计与设置
为保证不同检测器在血细胞场景下的对比具有可解释性,本文在同一数据集划分(共 8,900 张,Train/Val/Test=6,587/1,869/444)与一致训练策略下,对 YOLO 系列 8 种模型进行横向评测。考虑到系统侧需要在 PySide6 界面中提供近实时推理与可视化交互,实验同时报告精度指标与端到端时延,并将推理耗时分解为预处理(PreTime)、模型前向(InfTime)与后处理(PostTime)。对比模型覆盖轻量级 n/t/tiny 组(YOLOv5nu、YOLOv6n、YOLOv7-tiny、YOLOv8n、YOLOv9t、YOLOv10n、YOLOv11n、YOLOv12n)以及更高容量的 s 组(YOLOv5su、YOLOv6s、YOLOv7、YOLOv8s、YOLOv9s、YOLOv10s、YOLOv11s、YOLOv12s)。所有模型统一输入尺寸为 640 × 640 640\times640 640×640,训练轮数为 120,最终在同一评估集上汇报 Precision、Recall、F1、mAP@0.5 与 mAP@0.5:0.95,同时记录参数量与 FLOPs 以刻画复杂度。
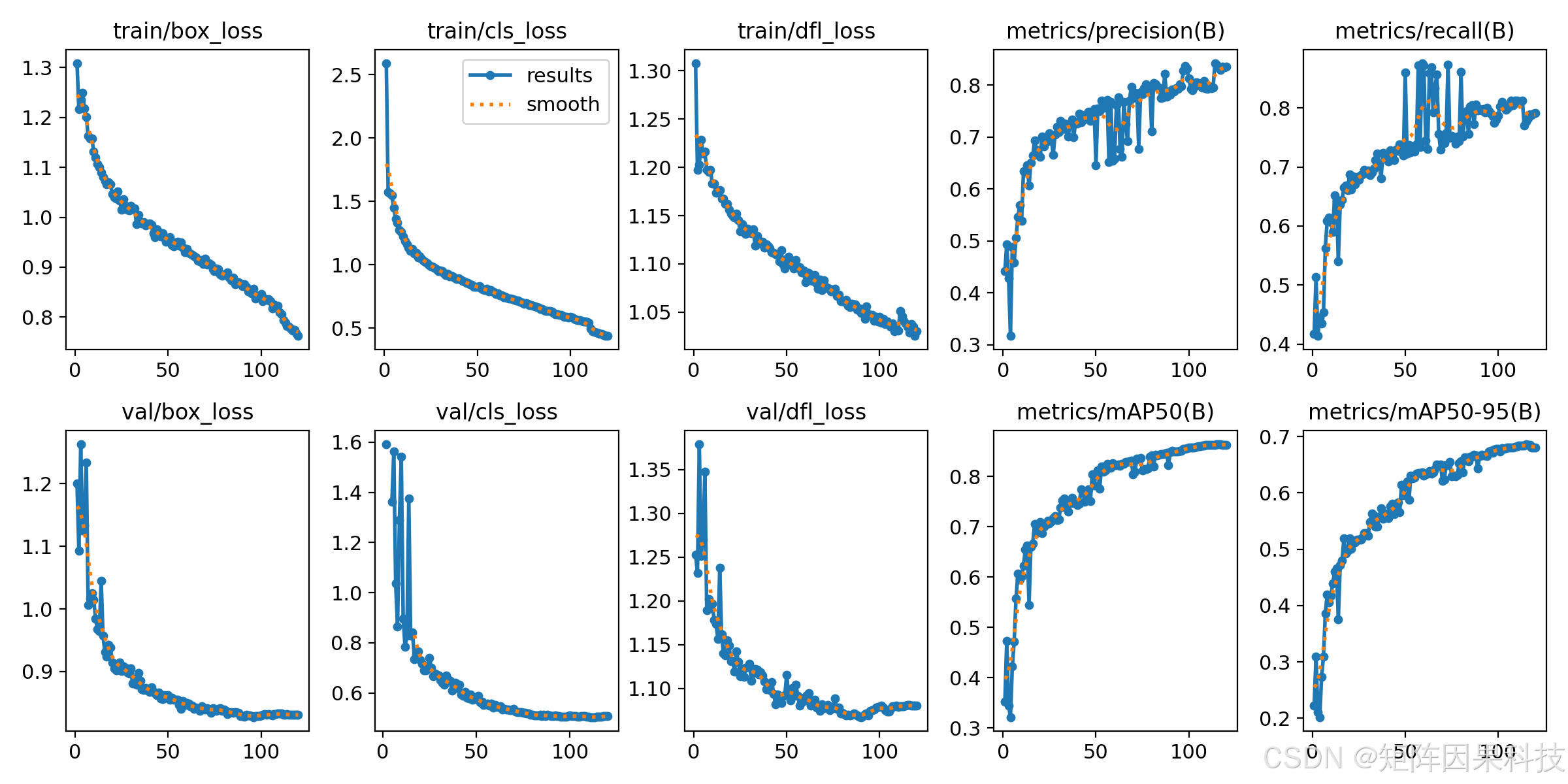
图 5-1 训练过程损失与评价指标曲线(results.png)
5.2 度量指标
检测性能以 Precision、Recall、F1 与 mAP 为核心。对于给定类别,精确率与召回率分别定义为
P = T P T P + F P , R = T P T P + F N , P=\frac{TP}{TP+FP},\qquad R=\frac{TP}{TP+FN}, P=TP+FPTP,R=TP+FNTP,
其中 T P / F P / F N TP/FP/FN TP/FP/FN 分别表示真阳性、假阳性与假阴性。综合权衡查准与查全时采用
F 1 = 2 P R P + R . F1=\frac{2PR}{P+R}. F1=P+R2PR.
平均精度 mAP@0.5 表示在 IoU 阈值 0.5 下对各类别 AP 的平均,mAP@0.5:0.95 则是在 0.5 , 0.55 , ... , 0.95 {0.5,0.55,\ldots,0.95} 0.5,0.55,...,0.95 多阈值下的平均,更能反映定位框回归质量与对遮挡/黏连目标的鲁棒性。由于血涂片中血小板与部分异常红细胞形态属于典型小目标与细粒度类别,mAP@0.5:0.95 往往比 mAP@0.5 更敏感,也更能体现模型在"边界贴合度"上的差异。
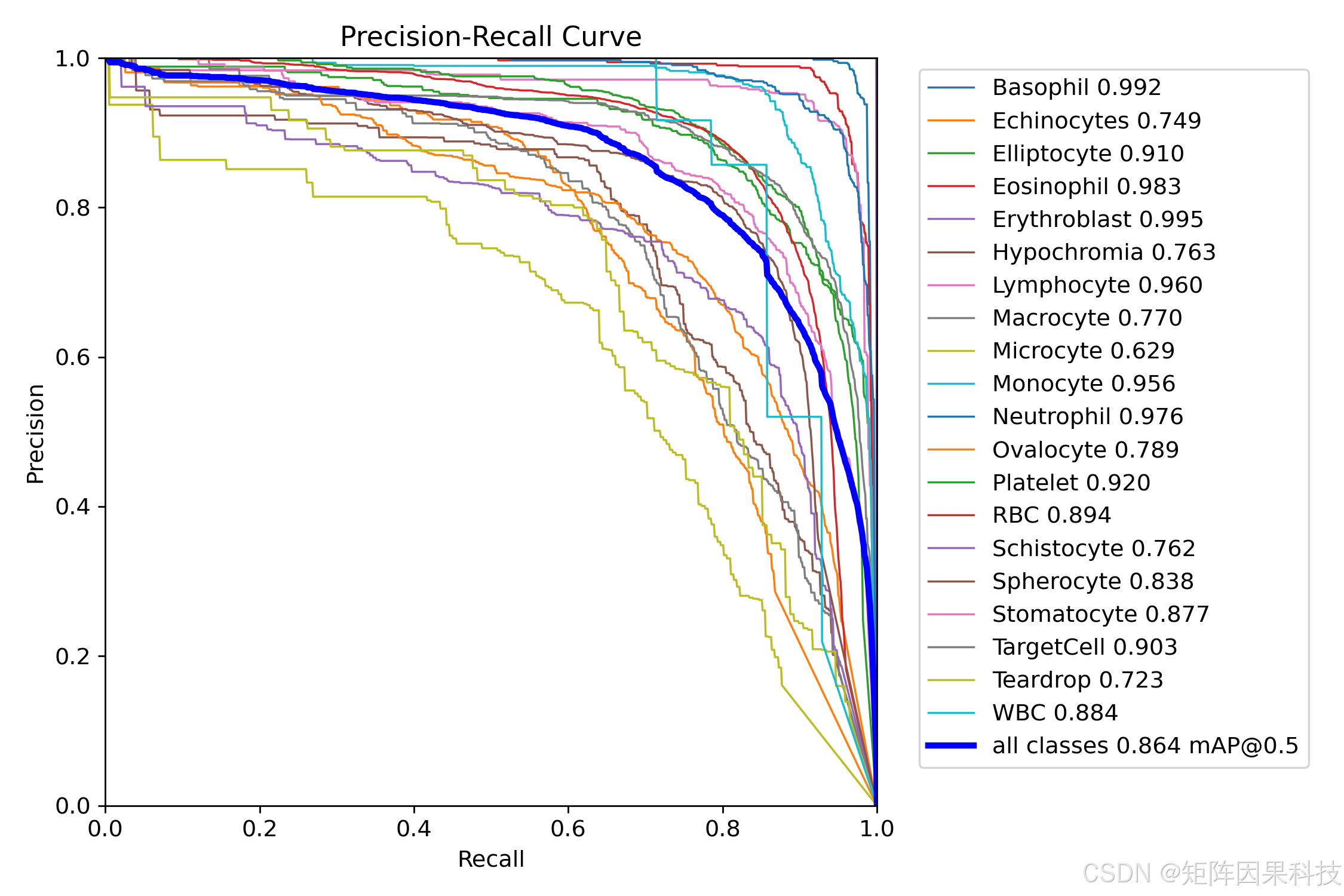
图 5-2 PR 曲线与各类别 AP(PR_curve.png)
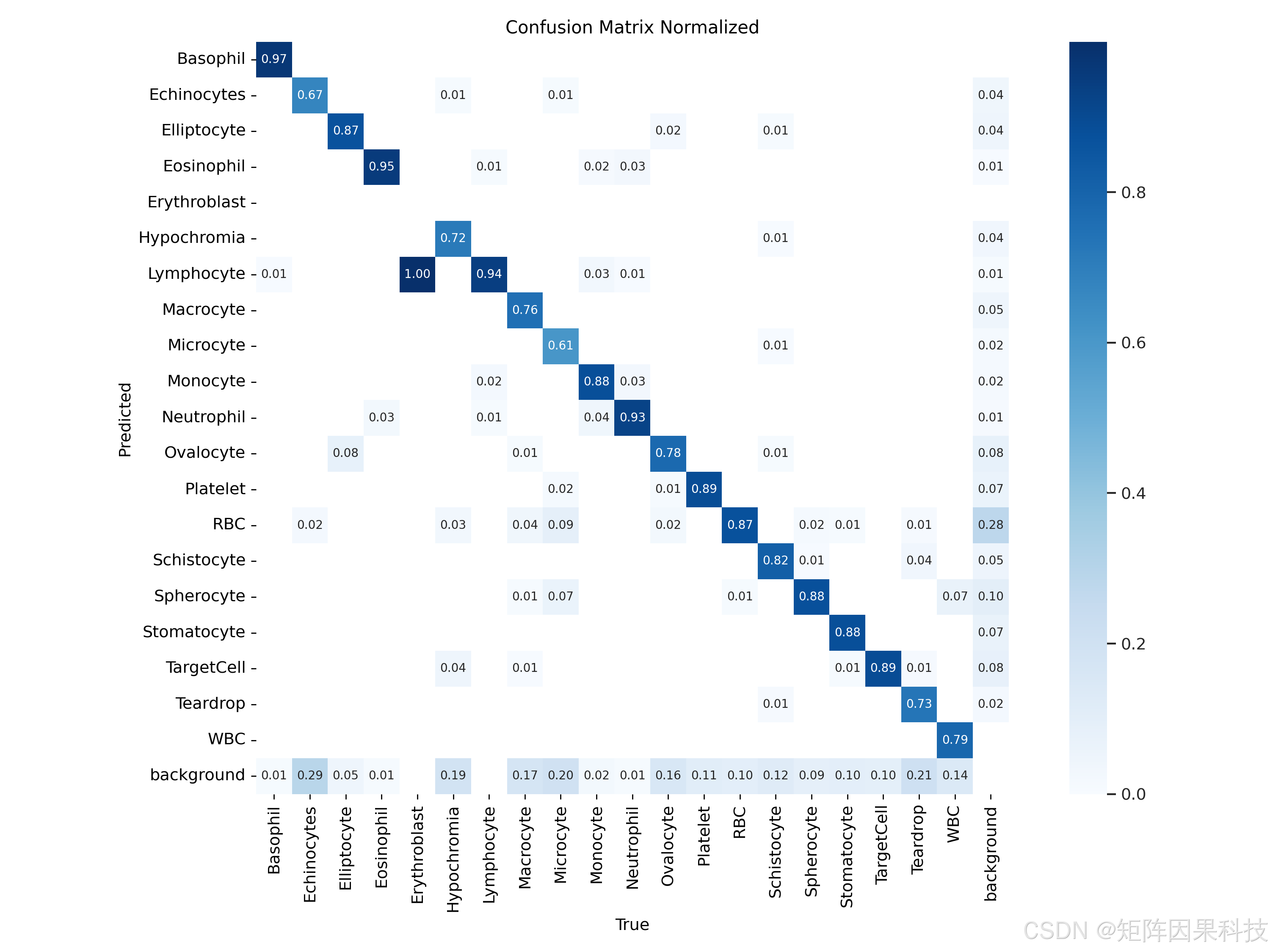
图 5-3 归一化混淆矩阵(confusion_matrix_normalized.png)
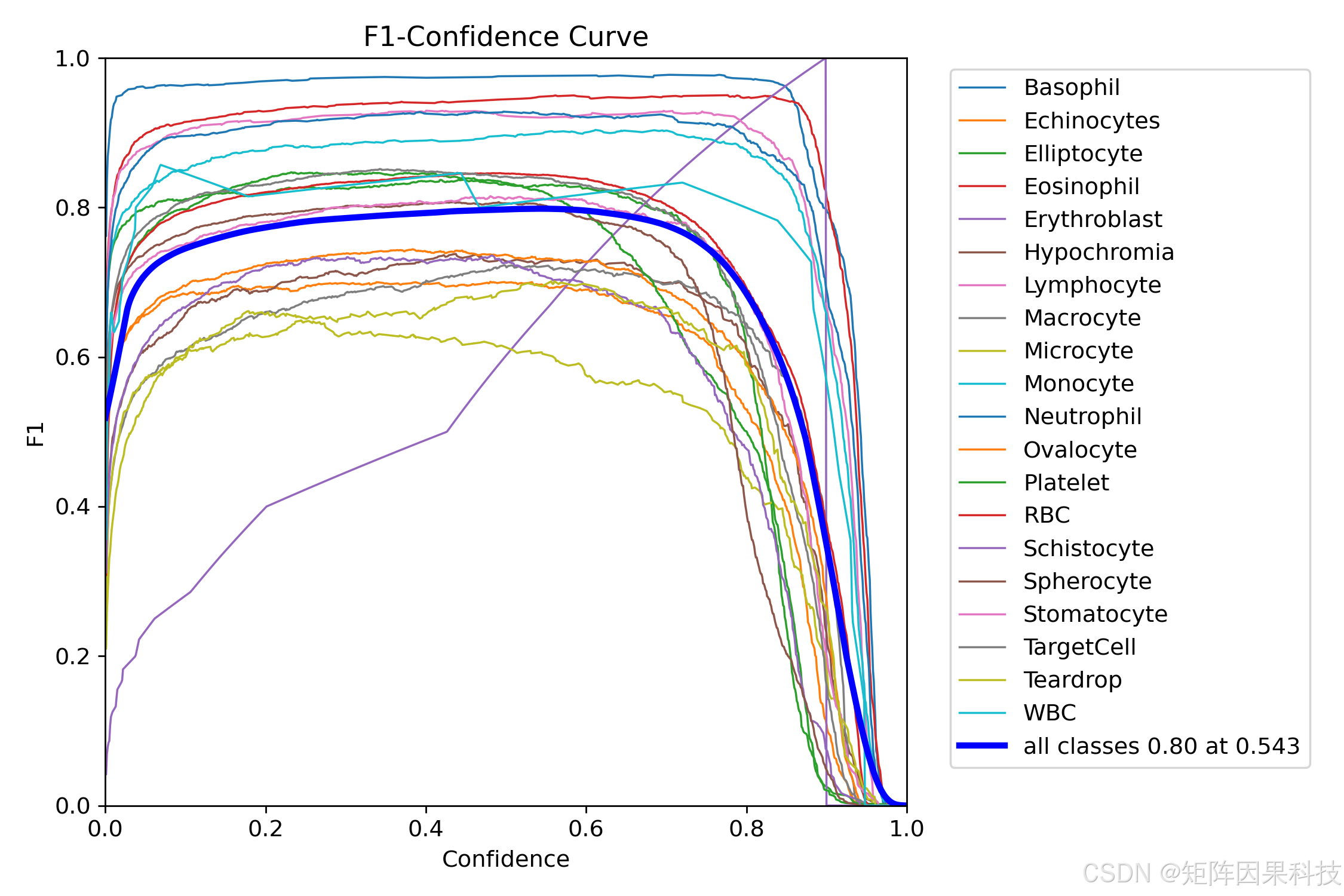
图 5-4 F1-Confidence 曲线(F1_curve.png)
5.3 实验结果与分析
从训练收敛过程看,模型在前 10--20 个 epoch 内实现了指标的快速爬升,随后进入平滑增长阶段;训练端与验证端的 box/cls/dfl 损失整体单调下降,mAP@0.5 与 mAP@0.5:0.95 在中后期逐步趋于平台,未出现明显的反向震荡,说明在当前增强与学习率策略下优化过程较为稳定。指标曲线与损失变化如图 5-1 所示,其中验证集 mAP@0.5 在后期稳定在 0.85 以上,mAP@0.5:0.95 稳定在 0.65--0.69 区间,这与血细胞任务中"类别细粒度、边界易黏连"的难度结构一致:IoU 阈值提升后对定位误差更敏感,因此 mAP@0.5:0.95 的绝对值显著低于 mAP@0.5。
在轻量级 n/t/tiny 组(表 5-1)中,YOLOv10n 在 mAP@0.5 与 mAP@0.5:0.95 上取得最优(0.832/0.647),相较 YOLOv6n 分别提升 0.097 与 0.096,体现了在相同数据与训练设置下,新一代检测头/分配策略对定位质量的系统性增益。与此同时,YOLOv8n 的推理延迟最低(Total≈10.17 ms,对应约 98 FPS),且 mAP@0.5:0.95 达到 0.638,与 YOLOv10n 的差距仅约 0.008;在需要更高帧率的界面实时预览场景中,YOLOv8n 更接近"精度可接受、速度更稳"的部署点。YOLOv7-tiny 的 Precision/Recall/F1 较高(P=0.835,R=0.760,F1=0.796),但其后处理耗时显著增大(Post≈4.06 ms),导致总时延升至 21.08 ms;这类开销在视频流场景中会直接表现为 UI 刷新频率下降,因此更适合作为离线分析或低帧率场景的备选。对应的跨模型平均 PR 曲线如图 5-9 所示,整体上 YOLOv8n 与 YOLOv10n 在高召回区域仍能保持较高精度,曲线包络明显优于 YOLOv6n。
表 5-1 轻量级(n/t/tiny)模型对比(RTX 3070 Laptop GPU, 8GB)
| Model | Params(M) | FLOPs(G) | Pre(ms) | Inf(ms) | Post(ms) | Total(ms) | FPS | Precision | Recall | F1 | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5nu | 2.6 | 7.7 | 1.90 | 7.73 | 1.31 | 10.94 | 91.41 | 0.760 | 0.733 | 0.746 | 0.809 | 0.618 |
| YOLOv6n | 4.3 | 11.1 | 2.17 | 6.78 | 1.39 | 10.34 | 96.71 | 0.674 | 0.671 | 0.673 | 0.735 | 0.551 |
| YOLOv7-tiny | 6.2 | 13.8 | 2.28 | 14.74 | 4.06 | 21.08 | 47.44 | 0.835 | 0.760 | 0.796 | 0.811 | 0.601 |
| YOLOv8n | 3.2 | 8.7 | 1.95 | 6.83 | 1.39 | 10.17 | 98.33 | 0.788 | 0.745 | 0.766 | 0.829 | 0.638 |
| YOLOv9t | 2.0 | 7.7 | 1.87 | 16.51 | 1.29 | 19.67 | 50.84 | 0.782 | 0.740 | 0.761 | 0.782 | 0.592 |
| YOLOv10n | 2.3 | 6.7 | 2.08 | 11.24 | 0.63 | 13.95 | 71.68 | 0.783 | 0.737 | 0.759 | 0.832 | 0.647 |
| YOLOv11n | 2.6 | 6.5 | 2.11 | 9.44 | 1.42 | 12.97 | 77.10 | 0.796 | 0.724 | 0.758 | 0.794 | 0.606 |
| YOLOv12n | 2.6 | 6.5 | 1.91 | 12.47 | 1.37 | 15.75 | 63.49 | 0.779 | 0.732 | 0.755 | 0.827 | 0.638 |
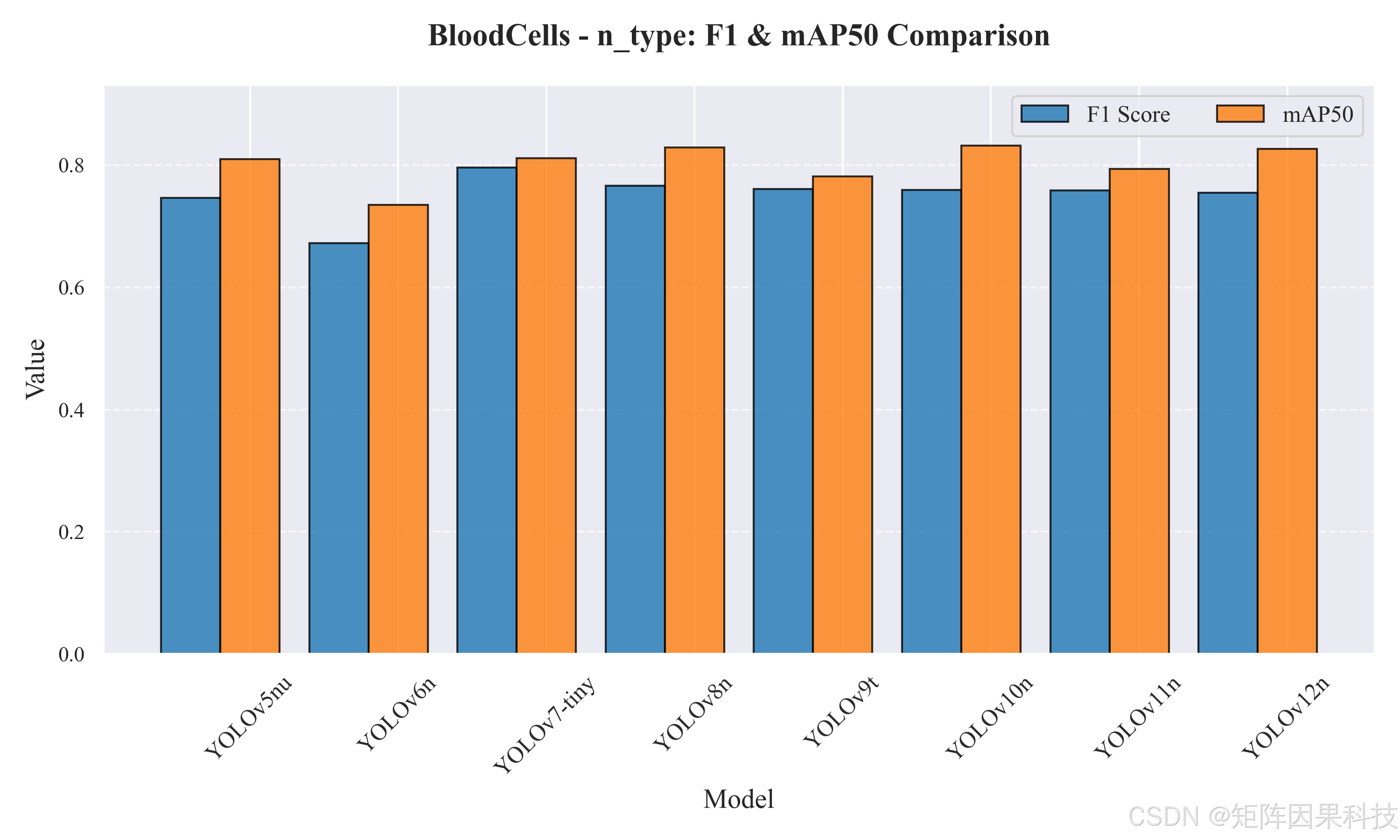
图 5-5 n 型模型 F1 与 mAP50 对比(BloodCells_n_type_comparison.png)
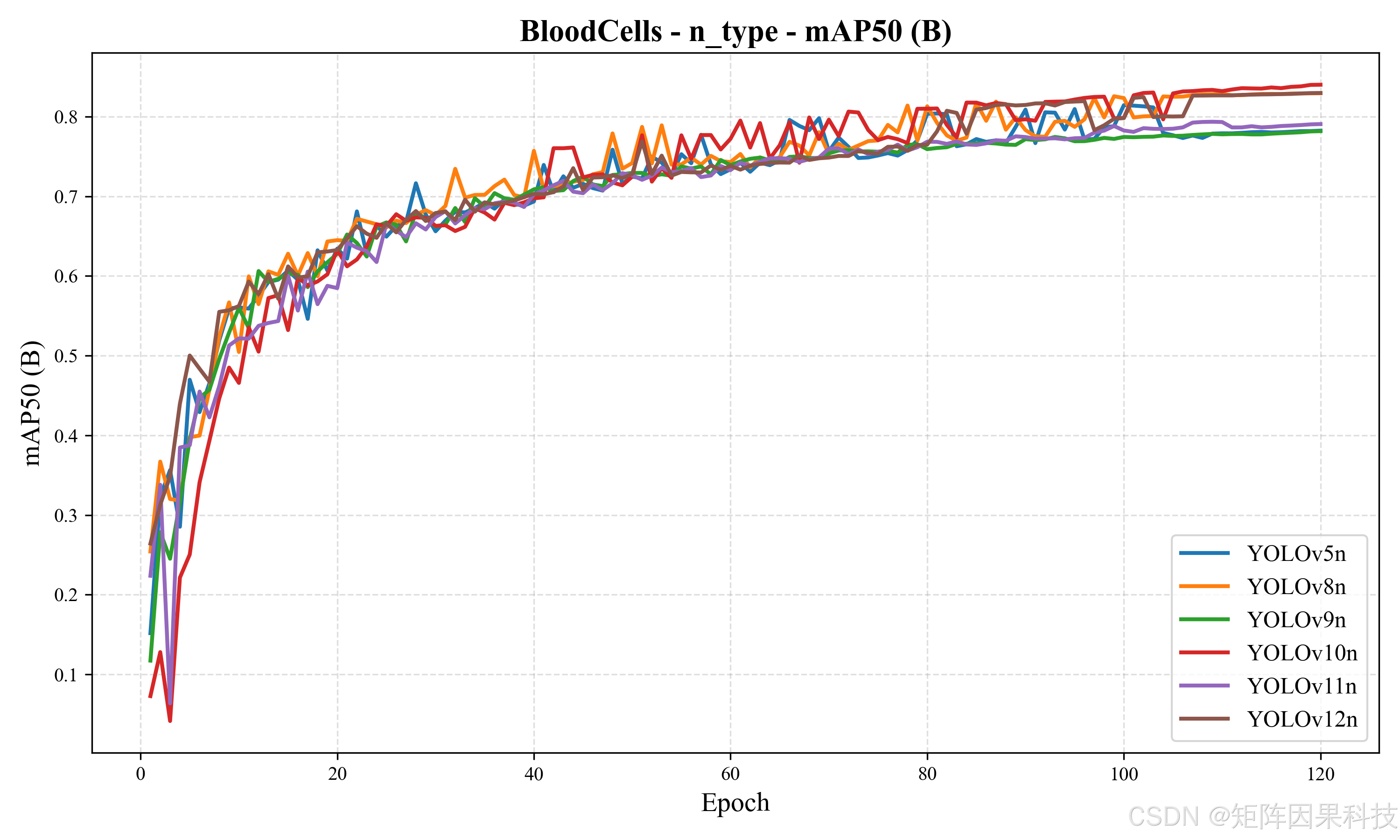
图 5-7 n 型模型 mAP50 收敛曲线(BloodCells_n_type_metrics_mAP50(B).png)
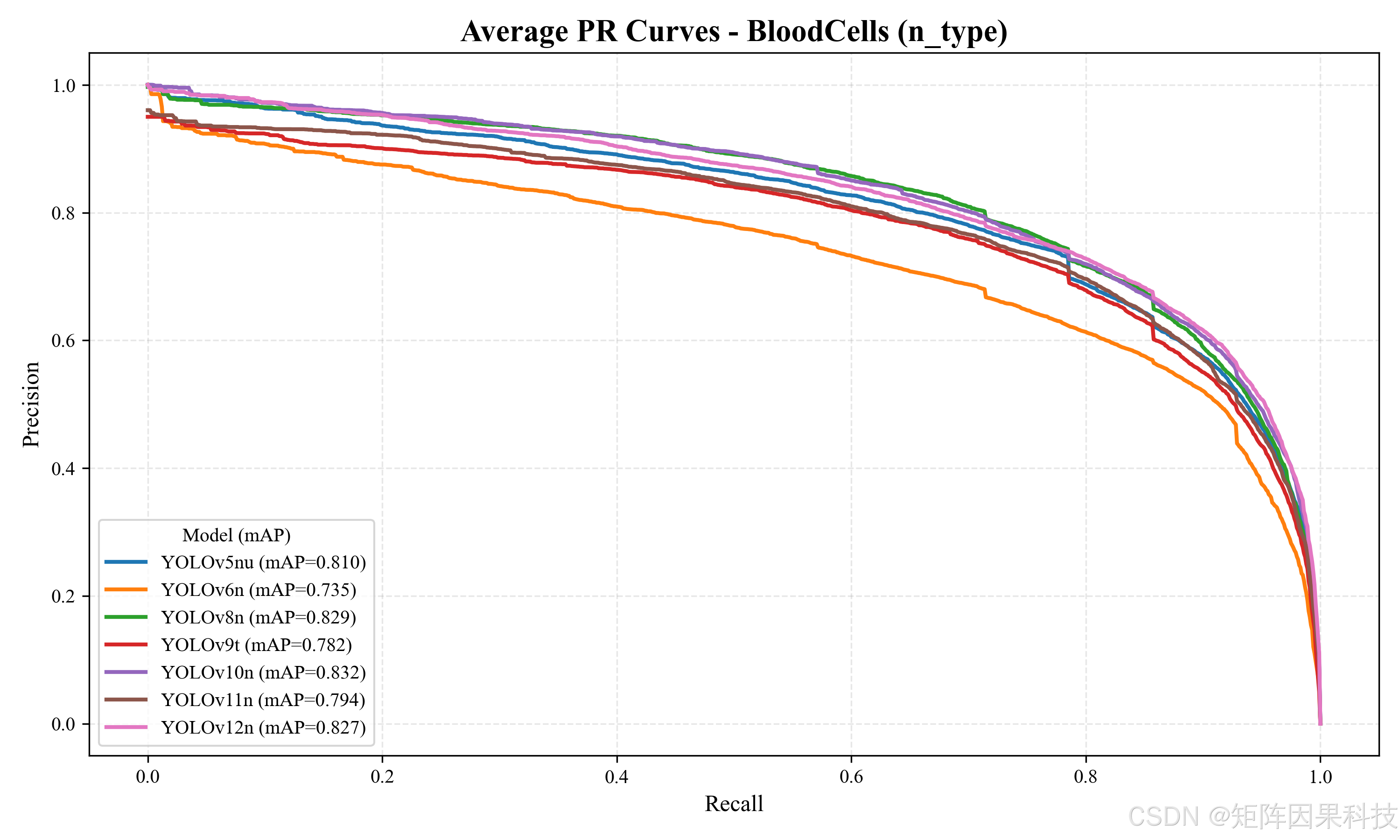
图 5-9 n 型模型平均 PR 曲线(BloodCells_n_type_pr_curve.png)
进一步观察 s 组(表 5-2),整体精度水平相较 n 组有稳定提升:以 YOLOv8 为例,mAP@0.5:0.95 从 0.638(v8n)提升至 0.678(v8s),增量约 0.040,说明在血细胞这种"细粒度类别 + 多尺度目标"任务上,适度提高模型容量能够改善高 IoU 区间的定位一致性。YOLOv12s 在 mAP@0.5:0.95 上达到组内最优 0.686,同时维持较高的 mAP@0.5(0.864);若系统更关注检测框贴合与后续基于框的二次分析(例如形态学裁剪复核),YOLOv12s 的优势更明确。另一方面,YOLOv11s 的 mAP@0.5:0.95 为 0.682,与 YOLOv12s 的差距仅 0.004,但总时延减少约 3.27 ms(FPS≈74),更接近 GUI 实时交互的部署需求;老思在工程实现中更倾向将 YOLOv11s 作为默认在线推理模型,将 YOLOv12s 作为"精检模式"的可切换选项。尽管 YOLOv7 在精度上仍具竞争力(mAP@0.5=0.868,F1=0.829),但其推理耗时显著偏高(Total≈29.52 ms),在持续视频流检测中更容易成为帧率瓶颈。跨模型平均 PR 曲线如图 5-10 所示,s 组曲线在中高召回区间整体上移,体现了容量增加对稳定召回与抑制误检的综合贡献。
表 5-2 s 级模型对比(RTX 3070 Laptop GPU, 8GB)
| Model | Params(M) | FLOPs(G) | Pre(ms) | Inf(ms) | Post(ms) | Total(ms) | FPS | Precision | Recall | F1 | mAP50 | mAP50-95 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| YOLOv5su | 9.1 | 24.0 | 2.28 | 8.45 | 1.51 | 12.24 | 81.70 | 0.838 | 0.803 | 0.820 | 0.864 | 0.676 |
| YOLOv6s | 17.2 | 44.2 | 2.22 | 8.59 | 1.45 | 12.26 | 81.57 | 0.734 | 0.809 | 0.770 | 0.814 | 0.634 |
| YOLOv7 | 36.9 | 104.7 | 2.44 | 23.62 | 3.46 | 29.52 | 33.88 | 0.853 | 0.806 | 0.829 | 0.868 | 0.675 |
| YOLOv8s | 11.2 | 28.6 | 2.31 | 7.66 | 1.42 | 11.39 | 87.80 | 0.821 | 0.774 | 0.797 | 0.865 | 0.678 |
| YOLOv9s | 7.2 | 26.7 | 2.12 | 18.66 | 1.39 | 22.17 | 45.11 | 0.791 | 0.761 | 0.776 | 0.834 | 0.646 |
| YOLOv10s | 7.2 | 21.6 | 2.21 | 11.38 | 0.60 | 14.19 | 70.47 | 0.755 | 0.726 | 0.740 | 0.808 | 0.625 |
| YOLOv11s | 9.4 | 21.5 | 2.37 | 9.74 | 1.36 | 13.47 | 74.24 | 0.834 | 0.811 | 0.822 | 0.861 | 0.682 |
| YOLOv12s | 9.3 | 21.4 | 2.09 | 13.23 | 1.42 | 16.74 | 59.74 | 0.837 | 0.778 | 0.807 | 0.864 | 0.686 |
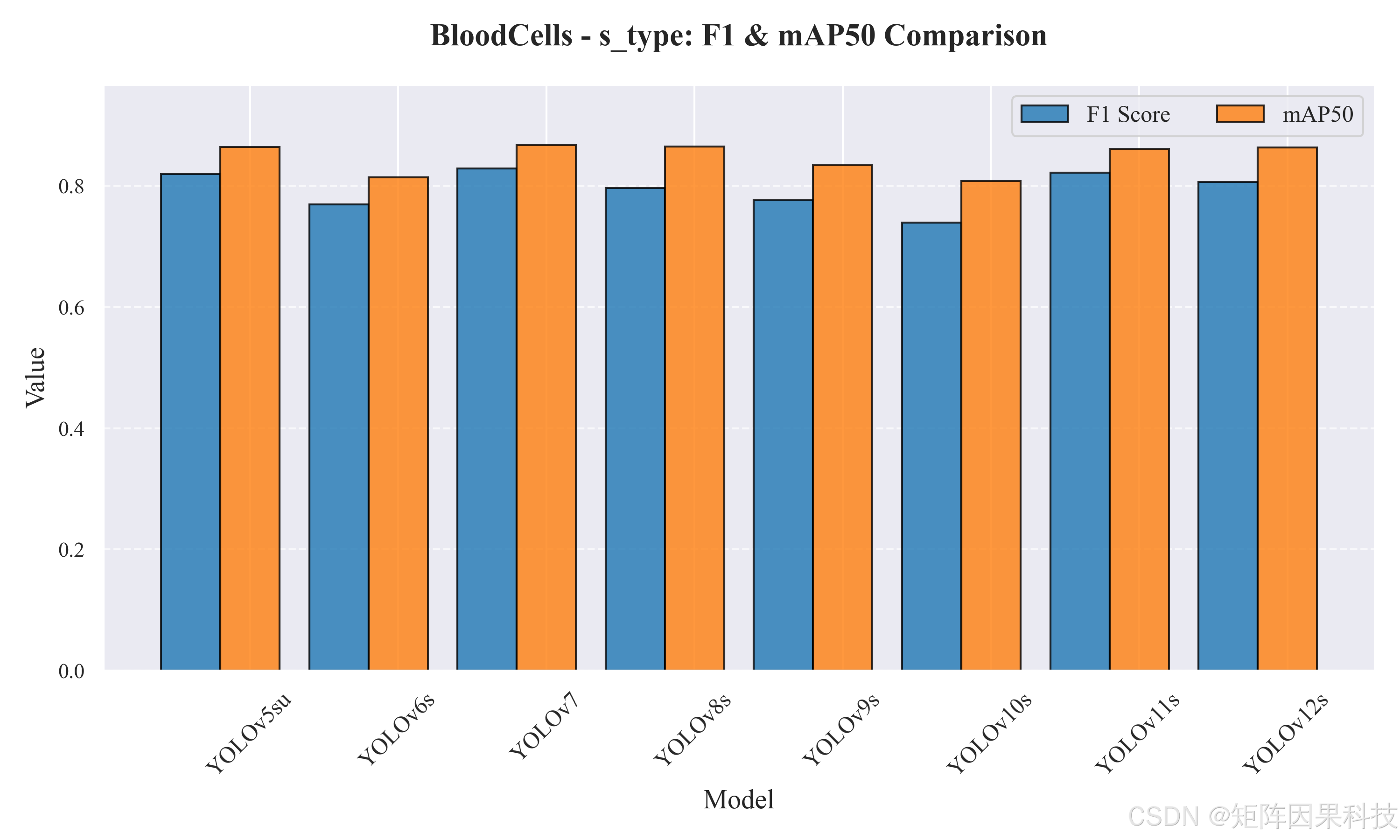
图 5-6 s 型模型 F1 与 mAP50 对比(BloodCells_s_type_comparison.png)
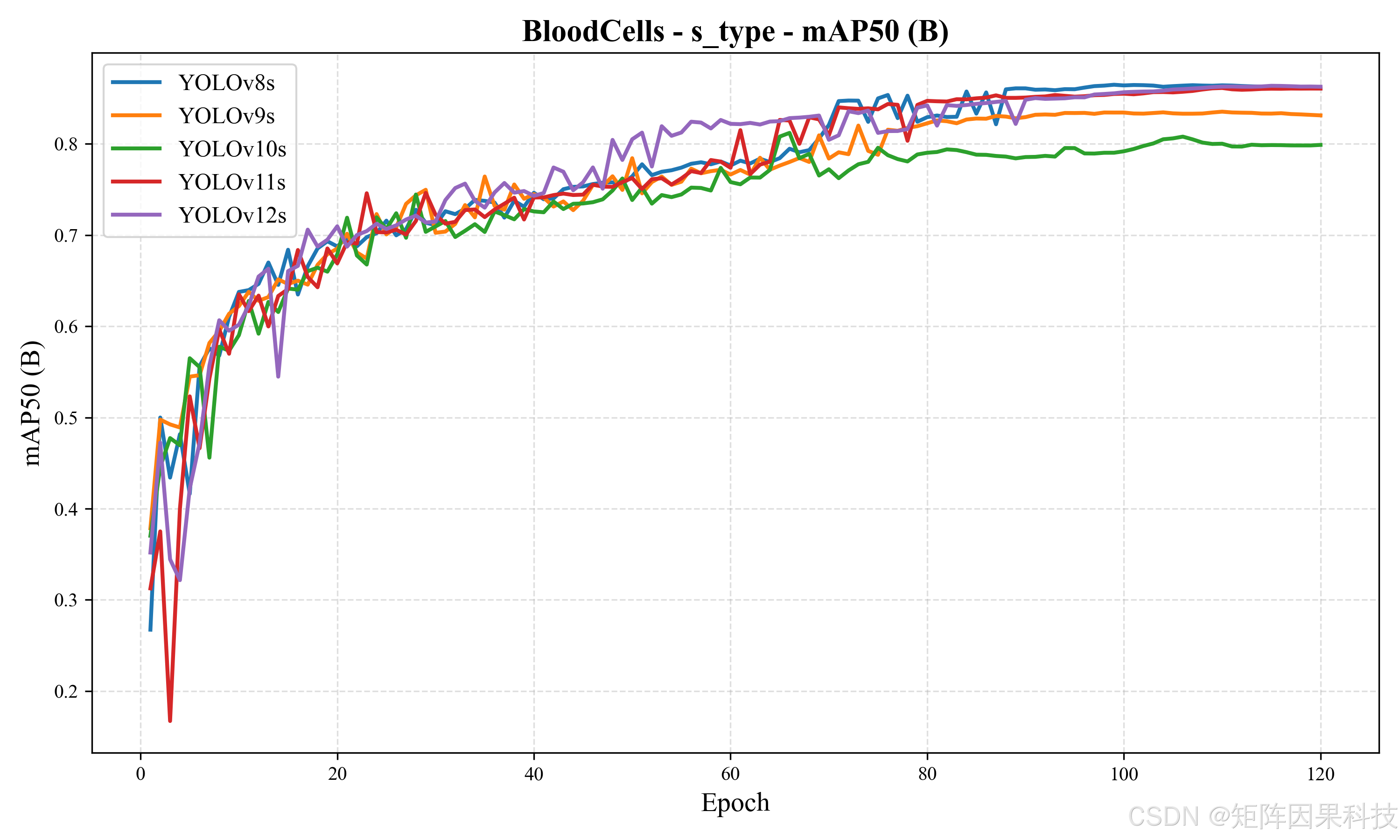
图 5-8 s 型模型 mAP50 收敛曲线(BloodCells_s_type_metrics_mAP50(B).png)
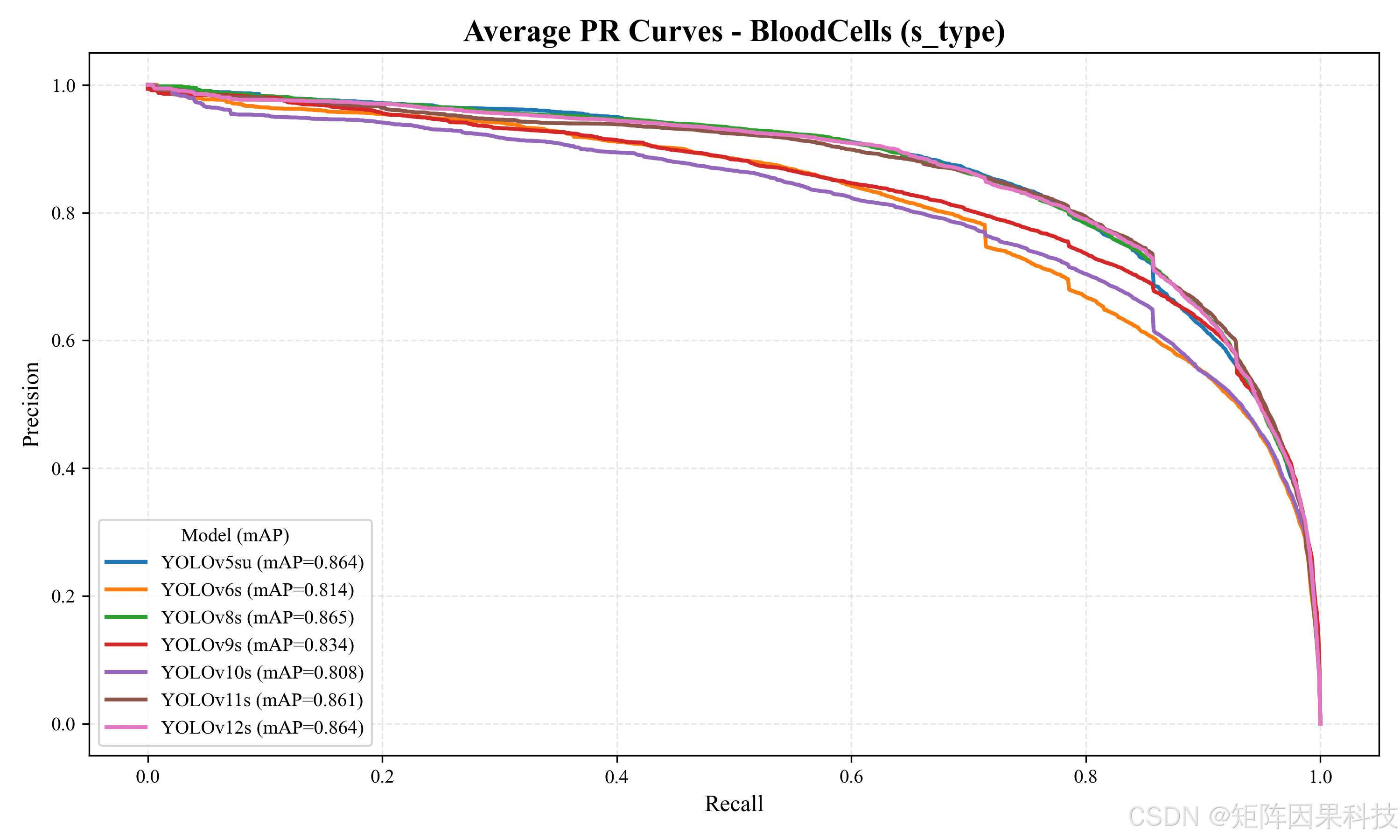
图 5-10 s 型模型平均 PR 曲线(BloodCells_s_type_pr_curve.png)
从类别层面分析,图 5-2 给出了单模型的 PR 曲线与各类别 AP,整体 mAP@0.5 为 0.864。白细胞相关类别(Basophil 0.992、Eosinophil 0.983、Erythroblast 0.995、Neutrophil 0.976、Lymphocyte 0.960、Monocyte 0.956)普遍较高,主要原因在于核质结构与染色特征明显、类间差异更强,模型更容易学习到稳定判别模式。相对而言,红细胞形态类呈现出明显的难度梯度,Microcyte(0.629)、Teardrop(0.723)、Echinocytes(0.749)、Hypochromia(0.763)等类别 AP 偏低,这与其在真实涂片中常伴随轻度失焦、边界黏连、以及与"普通 RBC"共享大量局部纹理的事实一致;当尺度变化与形态差异主要体现在轮廓细节时,检测框回归与分类边界会同时变得敏感,误检与漏检更易发生。该现象在混淆矩阵中同样得到印证:Microcyte 的对角线准确率约为 0.61,Echinocytes 约为 0.67,而 Basophil 与 Neutrophil 等类别对角线值分别达到 0.97 与 0.93(图 5-3)。此外,混淆矩阵的 background 列/行显示部分红细胞形态类别更容易与背景发生互相干扰,意味着在密集视野与弱对比度背景下,模型需要更强的小目标特征与更稳定的阈值策略来抑制假阳性,同时提高难类的召回。
阈值选取对系统侧体验具有直接影响。图 5-4 的 F1-Confidence 曲线显示整体最优点约为 F1=0.80,Confidence=0.543,这意味着当置信度阈值过低时假阳性会快速累积,而阈值过高又会压缩召回并导致计数偏低。基于该曲线,本文在系统默认配置中将 Conf 设定在 0.55 左右作为折中起点,并允许用户在 UI 中结合实际视野质量(染色深浅、细胞密度、是否重叠)进行交互式微调,从而在"检出尽量全"与"误报尽量少"之间获得更稳定的可用性。
图 5-5 至图 5-10(柱状图、收敛曲线与平均 PR 曲线)进一步从"最终指标与训练动态"两个角度揭示了模型差异:n 组中 YOLOv10n 在高 IoU 指标上领先,而 YOLOv8n 在速度上最具优势;s 组中 YOLOv12s 在 mAP@0.5:0.95 上最优,YOLOv11s 则提供了更接近部署需求的精度与时延平衡。综合精度、速度与系统交互稳定性三方面因素,本文后续系统默认推理模型更推荐 YOLOv11s(在线)与 YOLOv12s(精检)两种模式并存的配置,使用户能够在不同业务场景下以最小成本切换速度与精度侧重点。
6.系统设计与实现
6.1 系统设计思路
本系统以"检测推理链路可控、界面交互稳定、结果可追溯"为核心目标,将业务逻辑按典型三层职责拆分为 MainWindow(控制层)---Ui_MainWindow(界面层)---Detector(处理层) ,并以 SQLite 提供持久化支撑。MainWindow 作为中枢调度者,负责状态机管理、输入源生命周期(图片/视频/摄像头)控制、模型选择与参数下发(Conf/IoU 等),同时协调推理线程的启动、暂停与结束,避免耗时操作阻塞主线程事件循环。Ui_MainWindow 仅承担可视化与交互呈现,包括图像显示、检测框绘制、结果表格与类别统计、状态栏帧率与耗时等,使界面响应与推理计算解耦,从而保持 GUI 的可用性与可维护性。

处理层 Detector 封装预训练权重加载、推理与后处理:输入帧首先完成尺寸归一与归一化,再进入 YOLO 前向推理,随后执行阈值过滤与(必要的)NMS/one-to-one 输出整理,并生成结构化结果(bbox、类别、置信度、计数)。跨层通信采用 Qt 的信号-槽机制:Detector 在线程内产出结果后,通过信号把轻量数据结构发送给 MainWindow/UI,UI 侧只做绘制与展示而不做重计算,从而在视频流场景下保持稳定刷新。与之对应,结果与配置的持久化由 SQLite 完成:检测记录、用户偏好(主题、默认阈值、默认模型)等以"用户隔离"的方式写入数据库,使不同账号拥有独立的历史空间,并支持后续筛选、查询与导出,形成"推理---展示---存储---回显"的闭环。
在工程实现上,老思更强调"可切换与可扩展":模型侧默认以 YOLOv12n/YOLOv11s 作为常用权重,但允许用户在界面中导入同族权重文件并动态切换;输入侧对图片、视频、摄像头统一抽象为帧流接口,便于复用同一套预处理与后处理逻辑;界面侧通过主题切换、图标与背景资源加载实现外观定制,同时保持业务数据结构不随 UI 风格变化而变化,降低后续迭代的耦合成本。
图 系统流程图
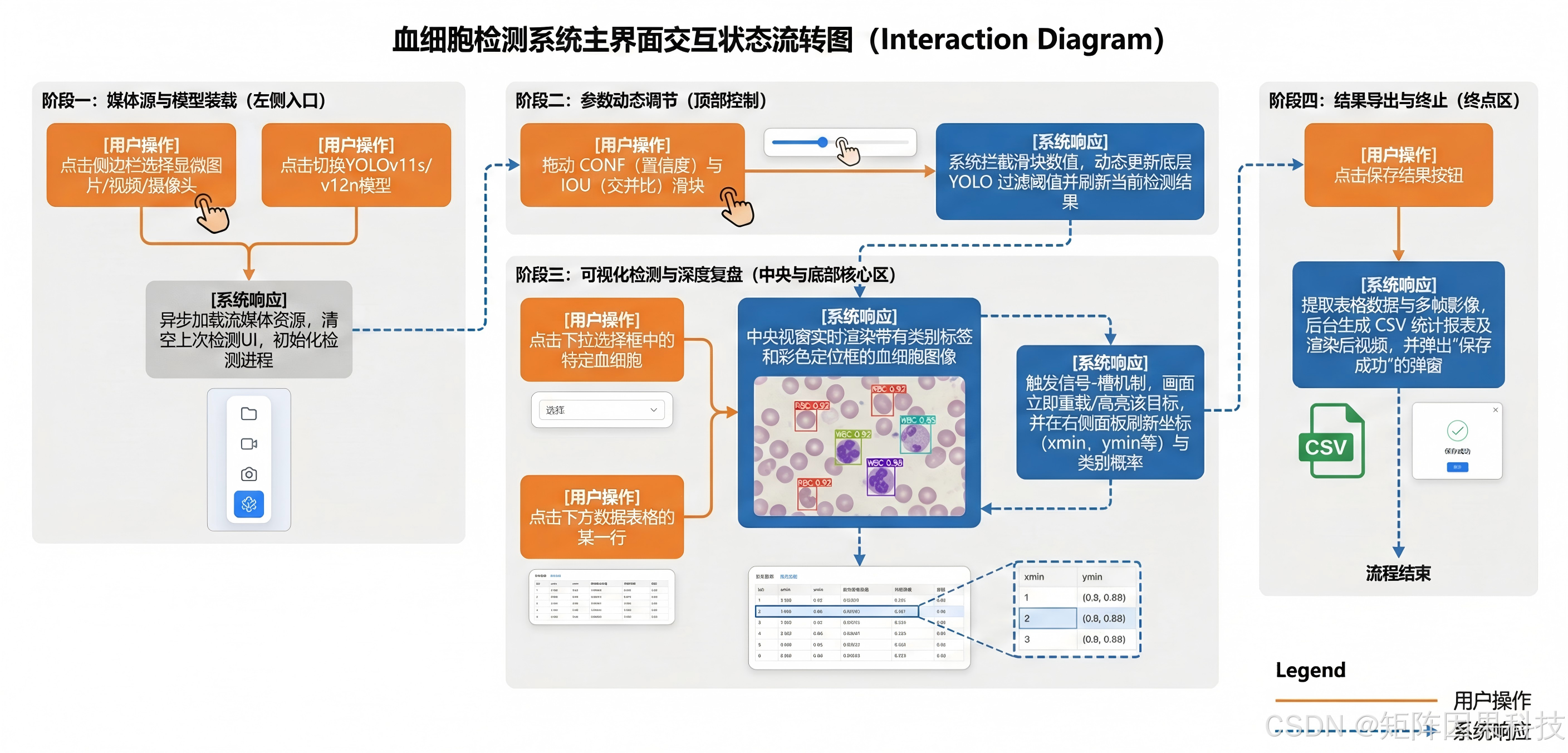
图注:系统从初始化到多源输入,完成预处理、推理与界面联动,并通过交互形成闭环。
6.2 登录与账户管理 --- 流程图
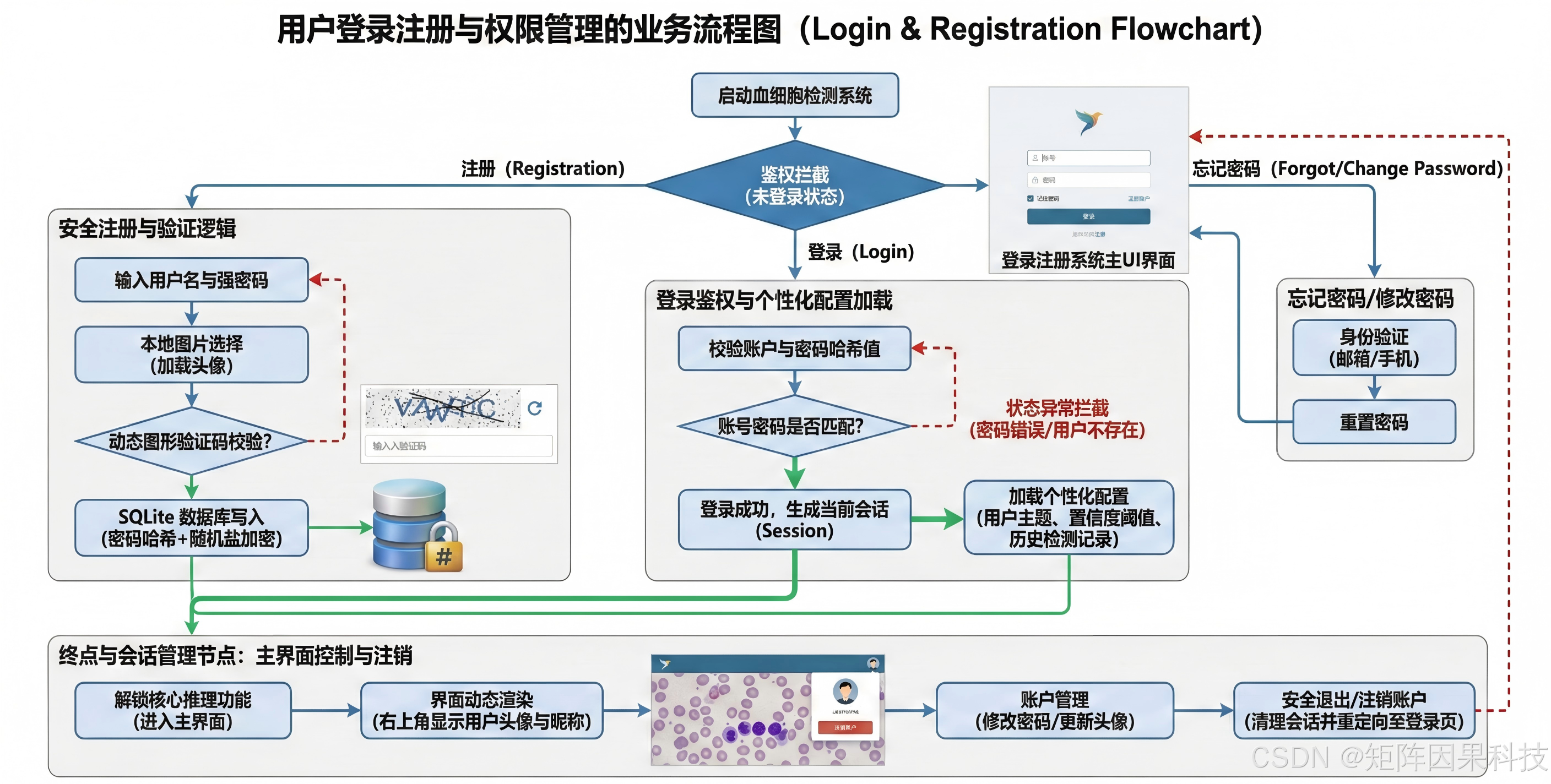
登录与账户管理的设计目标是在不干扰主检测链路的前提下,实现"身份校验---个性化配置---历史可追溯"的闭环体验:用户在登录/注册阶段完成 SQLite 侧的账号写入与口令校验,系统在通过认证后加载该用户的主题、默认模型与阈值等偏好,并同步读取历史检测记录以支持回看与筛选;进入主界面后,资料修改(头像/密码)与检测结果存储共享同一套持久化机制,保证设置变更可即时生效且跨会话保留;当用户注销或切换账号时,MainWindow 统一释放当前会话资源并回到登录界面,从而使每个用户拥有独立的配置与结果空间,同时保持与"选择输入---推理---展示---导出/入库"的主流程自然衔接。
7. 下载链接
若您想获得博文中涉及的实现完整全部资源文件 (包括测试图片、视频,py, UI文件,训练数据集、训练代码、界面代码等),这里见可参考博客与视频,已将所有涉及的文件同时打包到里面,点击即可运行,完整文件截图如下:
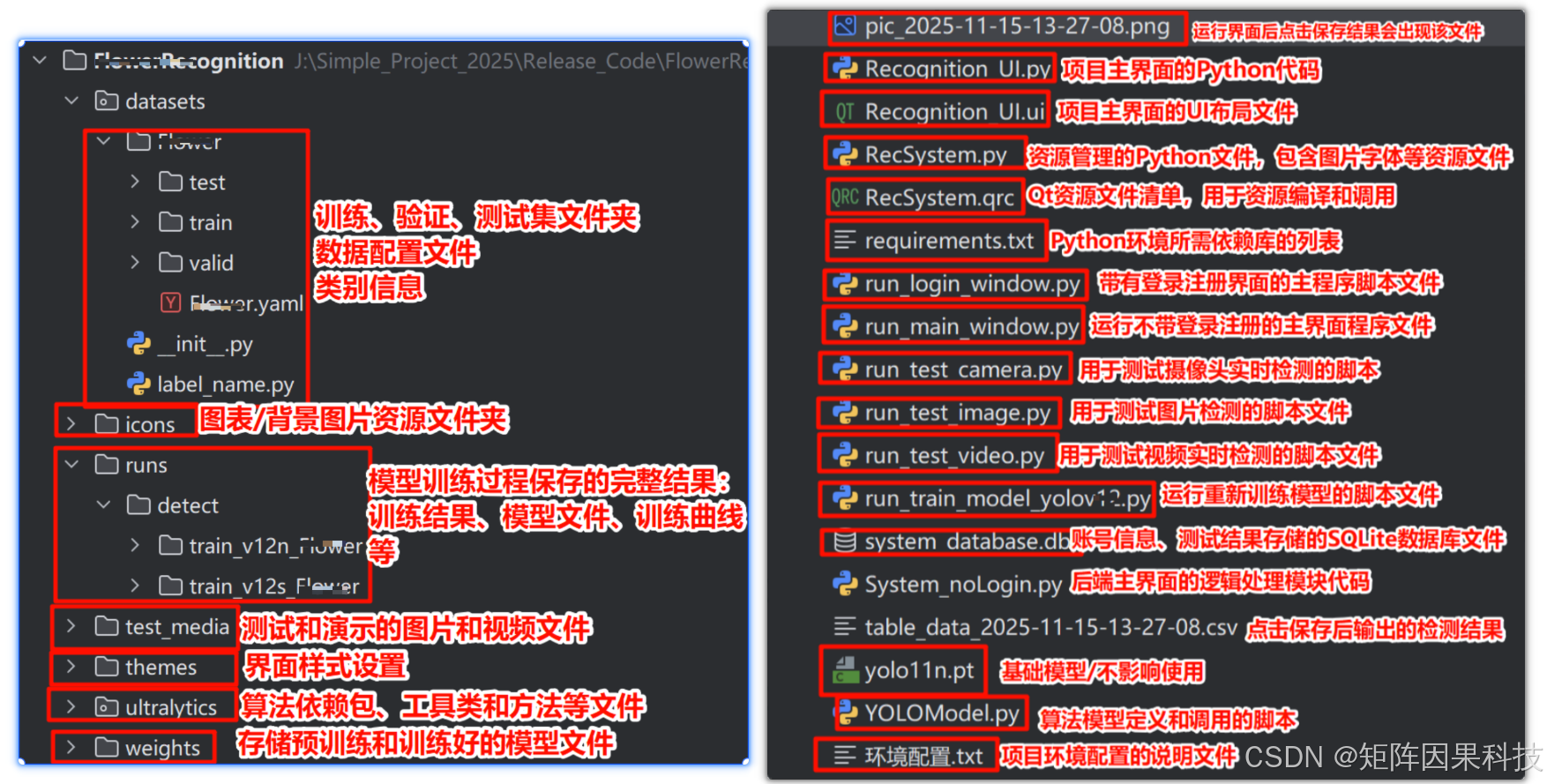
完整资源中包含数据集及训练代码,环境配置与界面中文字、图片、logo等的修改方法请见视频,项目完整文件请见项目介绍及功能演示视频处给出:➷➷➷
详细介绍文档博客 :YOLOv5至YOLOv12升级:血细胞检测系统的设计与实现(完整代码+界面+数据集项目)
环境配置博客教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境配置教程;
或者环境配置视频教程:(1)Pycharm软件安装教程;(2)Anaconda软件安装教程;(3)Python环境依赖配置教程
数据集标注教程(如需自行标注数据):数据标注合集
8.参考文献
1 Margret I N, Rajakumar K. Deep learning techniques for analyzing peripheral blood smears: a meta-analysisJ. Neural Computing and Applications, 2025, 37: 18039-18065.
2 Litjens G, Kooi T, Bejnordi B E, et al. A survey on deep learning in medical image analysisJ. Medical Image Analysis, 2017, 42: 60-88.
3 Ronneberger O, Fischer P, Brox T. U-Net: Convolutional Networks for Biomedical Image SegmentationC//Medical Image Computing and Computer-Assisted Intervention -- MICCAI 2015. Cham: Springer, 2015: 234-241.
4 Ren S, He K, Girshick R, Sun J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal NetworksC//Advances in Neural Information Processing Systems 28 (NIPS 2015). 2015: 91-99.
5 He K, Gkioxari G, Dollár P, Girshick R. Mask R-CNNC//Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 2961-2969.
6 Lin T Y, Goyal P, Girshick R, He K, Dollár P. Focal Loss for Dense Object DetectionC//Proceedings of the IEEE International Conference on Computer Vision (ICCV). 2017: 2980-2988.
7 Redmon J, Divvala S, Girshick R, Farhadi A. You Only Look Once: Unified, Real-Time Object DetectionC//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016: 779-788.
8 Dosovitskiy A, Beyer L, Kolesnikov A, et al. An Image is Worth 16×16 Words: Transformers for Image Recognition at ScaleC//International Conference on Learning Representations (ICLR). 2021.
9 Liu Z, Lin Y, Cao Y, et al. Swin Transformer: Hierarchical Vision Transformer Using Shifted WindowsC//Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV). 2021: 10012-10022.
10 张昊, 郑广海, 张鑫, 吕娜. 改进YOLOv5框架的血细胞检测算法J. 计算机系统应用, 2023, 32(5): 123-131.
11 Shi C, Zhu D, Zhou C, Cheng S, Zou C. Gpmb-yolo: a lightweight model for efficient blood cell detection in medical imagingJ. Health Information Science and Systems, 2024, 12: 24.
12 Maitlo A, Jatoi M A, Khand Z H, et al. AYOLOv5: A novel method for blood cell detectionJ. Biomedical Signal Processing and Control, 2024, 88: 105530.
13 Tarimo S A, Jang M-A, Ngasa E E, et al. WBC YOLO-ViT: 2 Way - 2 stage white blood cell detection and classification with a combination of YOLOv5 and vision transformerJ. Computers in Biology and Medicine, 2024, 169: 107875.
14 Kang M, Ting C-M, Ting F F, Phan R C-W. CST-Yolo: A Novel Method For Blood Cell Detection Based On Improved Yolov7 And CNN-Swin TransformerC//Proceedings of the IEEE International Conference on Image Processing (ICIP). 2024: 3024-3029.
15 Jeong K, Kim M, Cho G, et al. A Two-stage AI Framework to Detect and Classify White Blood Cells for Supporting Diseases Diagnosis in Veterinary MedicineC//IEEE International Conference on Bioinformatics and Biomedicine (BIBM). 2024: 4436-4443.
近年文献1与10--15的出版信息可在 Springer、ScienceDirect、DOAJ、dblp 等数据库页面检索核验。 (Springer)