5.⾃动化构建-make/Makefile
问题导入
为什么需要 make 和 Makefile?
想象一下这个场景:
你写了一个C程序,只有一个文件
main.c,编译时只需要:
bashgcc main.c -o main这很简单,没问题。但当项目变大时,情况完全不同:
bash# 一个有10个源文件的项目 gcc main.c utils.c network.c io.c math.c log.c config.c parser.c crypto.c gui.c -o app每次都要输入这么长的命令?太痛苦了。
更麻烦的是:你只改了
main.c,但上面的命令会重新编译所有文件 ------明明其他9个文件没变过,却要白白等几十秒甚至几分钟。
make就是专门解决这些问题的工具:**make 是一个自动化构建工具,Makefile 是它的配置文件。**你告诉它"怎么编译",它帮你做"只编译改过的文件"这种聪明事。下面我将详细讲解他的原理
bash#没有 Makefile: # 每次都要敲完整命令 gcc main.c utils.c network.c -o app # 清理也要手动删 rm app #有了 Makefile: make # 自动编译 make clean # 自动清理


一、核心概念
核心作用:
-
自动化编译 :只需输入
make,自动处理所有编译链接步骤 -
自动化清理 :
make clean删除生成的文件 -
提高效率 :避免每次手动输入
gcc ...,且只重新编译修改过的文件
二、依赖关系与依赖方法(核心机制)
1. 依赖关系
-
格式 :
目标文件: 依赖文件列表 -
含义:要生成目标,必须先准备好依赖文件
-
类比:就像做蛋糕(目标),必须先有面粉、鸡蛋(依赖)
2. 依赖方法
-
格式 :[Tab键]
命令(注意不是空格!) -
含义:具体如何从依赖生成目标的命令
-
类比:就像"混合面粉鸡蛋,然后烤制"的具体步骤
bash
# 依赖关系:要生成 hello,需要 hello.o
hello: hello.o
gcc hello.o -o hello # 依赖方法(Tab开头)
# 依赖关系:要生成 hello.o,需要 hello.c
hello.o: hello.c
gcc -c hello.c -o hello.o # 依赖方法(Tab开头)
# 伪目标,没有依赖,只有方法,语法上与之前相同,可以理解为依赖空文件列表
.PHONY:clean
clean:
rm -f hello hello.o完整示例:
bash
xqq@ubuntu-server:~/mydir/two$ touch test.c
xqq@ubuntu-server:~/mydir/two$ vim test.c
xqq@ubuntu-server:~/mydir/two$ ll
total 12
drwxrwxr-x 2 xqq xqq 4096 Apr 20 21:48 ./
drwxr-xr-x 4 xqq xqq 4096 Apr 20 21:47 ../
-rw-rw-r-- 1 xqq xqq 69 Apr 20 21:48 test.c
xqq@ubuntu-server:~/mydir/two$ touch Makefile
xqq@ubuntu-server:~/mydir/two$ vim Makefile
xqq@ubuntu-server:~/mydir/two$ cat Makefile
test:test.c
gcc -o test test.c
.PHONY:clean
clean:
rm -f test
xqq@ubuntu-server:~/mydir/two$ make
gcc -o test test.c
xqq@ubuntu-server:~/mydir/two$ ll
total 32
drwxrwxr-x 2 xqq xqq 4096 Apr 20 21:52 ./
drwxr-xr-x 4 xqq xqq 4096 Apr 20 21:47 ../
-rw-rw-r-- 1 xqq xqq 32 Apr 20 21:51 Makefile
-rwxrwxr-x 1 xqq xqq 15960 Apr 20 21:52 test*
-rw-rw-r-- 1 xqq xqq 69 Apr 20 21:48 test.c
xqq@ubuntu-server:~/mydir/two$ ./test
hello world
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test
xqq@ubuntu-server:~/mydir/two$ ll
total 16
drwxrwxr-x 2 xqq xqq 4096 Apr 21 15:28 ./
drwxr-xr-x 4 xqq xqq 4096 Apr 20 21:47 ../
-rw-rw-r-- 1 xqq xqq 65 Apr 20 22:14 Makefile
-rw-rw-r-- 1 xqq xqq 71 Apr 20 22:15 test.c三、Makefile 执行逻辑(关键理解)
当执行 make 时,make 的推理过程:
-
在当前目录下找到 Makefile/makefile中第一个目标(通常是最终可执行文件)
-
检查目标文件和依赖文件的最后修改时间:
-
如果依赖比目标新 (源文件被修改过),则执行依赖方法重新生成
-
如果目标比所有依赖都新 ,则不执行(避免重复编译)
-
-
递归检查依赖的依赖(如
hello.o依赖hello.c) -
如果第一个目标文件所依赖的文件(如
test.o)不存在,make 会在当前 Makefile 中找目标为test.o的规则,然后反向执行依赖方法。
这就是"增量编译"的原理:只重新编译修改过的文件,极大提升大项目编译速度。
make、Makefile的语法推导理解:
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
test:test.o
gcc test.o -o test
test.o:test.s
gcc -c test.s -o test.o
test.s:test.i
gcc -S test.i -o test.s
test.i:test.c
gcc -E test.c -o test.i
.PHONY:clean
clean:
rm -f *.i *.s *.o test
xqq@ubuntu-server:~/mydir/two$ ll
total 16
drwxrwxr-x 2 xqq xqq 4096 Apr 21 19:00 ./
drwxr-xr-x 4 xqq xqq 4096 Apr 20 21:47 ../
-rw-rw-r-- 1 xqq xqq 266 Apr 21 19:00 Makefile
-rw-rw-r-- 1 xqq xqq 71 Apr 20 22:15 test.c
xqq@ubuntu-server:~/mydir/two$ make
gcc -E test.c -o test.i
gcc -S test.i -o test.s
gcc -c test.s -o test.o
gcc test.o -o test
xqq@ubuntu-server:~/mydir/two$ ll
total 60
drwxrwxr-x 2 xqq xqq 4096 Apr 21 19:01 ./
drwxr-xr-x 4 xqq xqq 4096 Apr 20 21:47 ../
-rw-rw-r-- 1 xqq xqq 266 Apr 21 19:00 Makefile
-rwxrwxr-x 1 xqq xqq 15960 Apr 21 19:01 test*
-rw-rw-r-- 1 xqq xqq 71 Apr 20 22:15 test.c
-rw-rw-r-- 1 xqq xqq 17953 Apr 21 19:01 test.i
-rw-rw-r-- 1 xqq xqq 1496 Apr 21 19:01 test.o
-rw-rw-r-- 1 xqq xqq 665 Apr 21 19:01 test.s
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f *.i *.s *.o test
xqq@ubuntu-server:~/mydir/two$ ll
total 16
drwxrwxr-x 2 xqq xqq 4096 Apr 21 19:01 ./
drwxr-xr-x 4 xqq xqq 4096 Apr 20 21:47 ../
-rw-rw-r-- 1 xqq xqq 266 Apr 21 19:00 Makefile
-rw-rw-r-- 1 xqq xqq 71 Apr 20 22:15 test.c
Make 的依赖解析就是建栈 (正向查找依赖),命令执行就是出栈 (反向执行命令),完美体现了后进先出(LIFO) 的栈特性
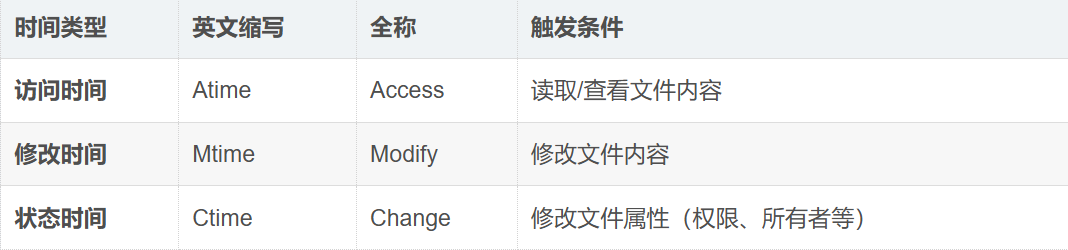
这里再补充一个知识点"ACM"时间
文件 = 内容 + 属性修改文件可能发生三种情况:
只修改内容
只修改属性
两者都修改
三种时间戳
我们可以使用 stat 查看文件状态
三种操作的验证
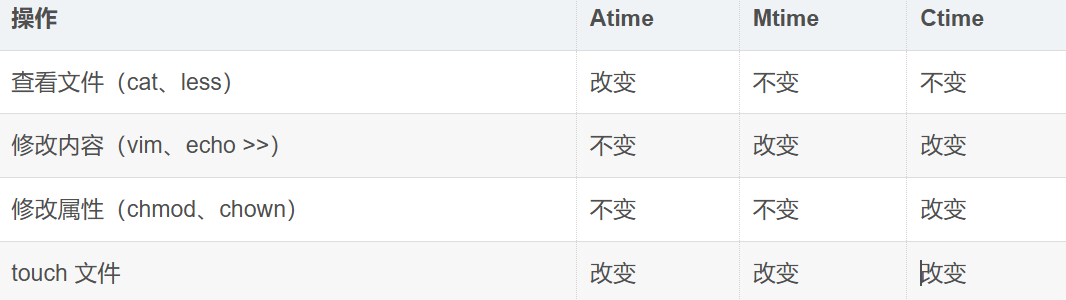
1. 修改文件内容 → 改变 Modify&Changetime
bashxqq@ubuntu-server:~/mydir/one$ stat copy.txt# 查看初始状态 File: copy.txt Size: 70 Blocks: 8 IO Block: 4096 regular file Device: fc03h/64515d Inode: 397262 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1001/ xqq) Gid: ( 1001/ xqq) Access: 2026-04-21 16:51:32.292989776 +0800 Modify: 2026-04-02 15:49:04.000000000 +0800 Change: 2026-04-20 21:44:52.845929713 +0800 Birth: 2026-04-02 20:49:39.279007719 +0800 xqq@ubuntu-server:~/mydir/one$ echo "new line">> copy.txt# 修改文件内容 xqq@ubuntu-server:~/mydir/one$ stat copy.txt# 再次查看 File: copy.txt Size: 79 Blocks: 8 IO Block: 4096 regular file Device: fc03h/64515d Inode: 397262 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1001/ xqq) Gid: ( 1001/ xqq) Access: 2026-04-21 16:51:32.292989776 +0800 Modify: 2026-04-21 16:54:20.706025831 +0800# 改变 Change: 2026-04-21 16:54:20.706025831 +0800# 也改变 Birth: 2026-04-02 20:49:39.279007719 +0800注意:修改内容时,Ctime 也会跟着改变(因为文件大小等属性变了)
2. 修改文件属性 → 改变 Ctime
bashxqq@ubuntu-server:~/mydir/one$ stat copy.txt File: copy.txt Size: 79 Blocks: 8 IO Block: 4096 regular file Device: fc03h/64515d Inode: 397262 Links: 1 Access: (0644/-rw-r--r--) Uid: ( 1001/ xqq) Gid: ( 1001/ xqq) Access: 2026-04-21 16:51:32.292989776 +0800 Modify: 2026-04-21 16:54:20.706025831 +0800 Change: 2026-04-21 16:54:20.706025831 +0800 Birth: 2026-04-02 20:49:39.279007719 +0800 xqq@ubuntu-server:~/mydir/one$ chmod 640 copy.txt# 修改文件权限(只改属性,不改内容) xqq@ubuntu-server:~/mydir/one$ stat copy.txt File: copy.txt Size: 79 Blocks: 8 IO Block: 4096 regular file Device: fc03h/64515d Inode: 397262 Links: 1 Access: (0640/-rw-r-----) Uid: ( 1001/ xqq) Gid: ( 1001/ xqq) Access: 2026-04-21 16:51:32.292989776 +0800 # 不变 Modify: 2026-04-21 16:54:20.706025831 +0800 # 不变 Change: 2026-04-21 16:59:50.383887551 +0800 # 改变 Birth: 2026-04-02 20:49:39.279007719 +0800
3. 查看文件内容 → 改变 Atime
bashxqq@ubuntu-server:~/mydir/one$ stat copy.txt File: copy.txt Size: 79 Blocks: 8 IO Block: 4096 regular file Device: fc03h/64515d Inode: 397262 Links: 1 Access: (0640/-rw-r-----) Uid: ( 1001/ xqq) Gid: ( 1001/ xqq) Access: 2026-04-21 16:51:32.292989776 +0800 Modify: 2026-04-21 16:54:20.706025831 +0800 Change: 2026-04-21 16:59:50.383887551 +0800 Birth: 2026-04-02 20:49:39.279007719 +0800 xqq@ubuntu-server:~/mydir/one$ cat copy.txt# 查看文件(只读,不改内容) #include<stdio.h> int main() { printf("hello world"); return 0; } new line xqq@ubuntu-server:~/mydir/one$ stat copy.txt File: copy.txt Size: 79 Blocks: 8 IO Block: 4096 regular file Device: fc03h/64515d Inode: 397262 Links: 1 Access: (0640/-rw-r-----) Uid: ( 1001/ xqq) Gid: ( 1001/ xqq) Access: 2026-04-21 17:05:23.589854813 +0800#改变 Modify: 2026-04-21 16:54:20.706025831 +0800#不变 Change: 2026-04-21 16:59:50.383887551 +0800#不变 Birth: 2026-04-02 20:49:39.279007719 +0800Make 主要使用 Mtime(修改时间) 来判断文件是否被修改:
当执行
make时:
比较
test的 Mtime 和test.c的 Mtime如果
test.c的 Mtime 更新 → 重新编译否则 → 跳过
总结
Atime (看)→ 查看文件时改变
Mtime (改)→ 修改内容时改变(Make 主要用这个)
Ctime(属性)→ 修改属性时改变
四、关键语法补充
1. 伪目标 (.PHONY)
伪目标是一个标签,而不是真正的目标文件,用于执行特定的命令序列
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
test:test.c
gcc -o test test.c
.PHONY:clean#clean为伪目标
clean:
rm -f test
#普通目标 test 的行为
#Make 检查时间戳,发现 test 比 test.c 新,所以跳过。
xqq@ubuntu-server:~/mydir/two$ make# 第一次:编译(test 不存在)
gcc -o test test.c
xqq@ubuntu-server:~/mydir/two$ make# 第二次:test 已存在且比 test.c 新
make: 'test' is up to date.# 不执行
xqq@ubuntu-server:~/mydir/two$ make# 第三次:仍然不执行
make: 'test' is up to date.
#伪目标 clean 的行为
#.PHONY:clean 告诉 Make 忽略同名文件,无条件执行。
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test #无条件执行-
总是执行依赖方法,不检查时间戳
-
用于
clean、all、install等不生成同名文件的目标 -
在一个 Makefile 里不仅可以存在多个普通目标,也可以存在多个伪目标。当只有伪目标或者说伪目标为第一个目标时,默认执行的就是第一个伪目标的依赖方法。如果要执行其他伪目标依赖方法,就要显式指定
make [伪目标]。 -
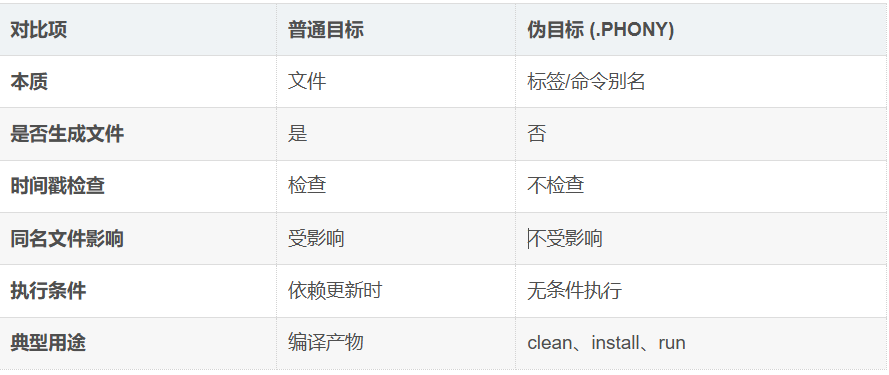
这里就衍生了一个奇怪的问题,那为什么test不给成伪目标无条件执行呢,其实道理很简单,这里是为了提高效率,因为只有当文件内容被修改,才要对文件进行重新编译,假设一个大一点的工程,编译生成可执行文件要很久,又将test声明为伪目标,也就是赋予了他无条件执行权利,假设有个bug要修正,只修改了其中一两个文件,但是在编译时就要对所有文件重新编译,这就浪费了很多时间
2. 变量定义与使用
Makefile 变量通过 变量名 = 值 定义,通过 $(变量名) 使用,配合 @ 可以控制命令是否回显,是提高 Makefile 可维护性的关键工具。
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
.PHONY:fun
fun:
echo $(BIN)
xqq@ubuntu-server:~/mydir/two$ make
echo test#要命令行不回显就像下面加@
test
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
.PHONY:fun
fun:
@echo $(BIN)#带 @(静默执行,不回显命令)
xqq@ubuntu-server:~/mydir/two$ make
test
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=test.c
FLAGS=-o
RM=rm -f
$(BIN):$(SRC)
$(CC) $(SRC) $(FLAGS) $(BIN)
.PHONY:clean
clean:
$(RM) $(BIN)
.PHONY:fun
fun:
@echo $(BIN)
@echo $(CC)
@echo $(SRC)
@echo $(FLAGS)
@echo $(RM)
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c
xqq@ubuntu-server:~/mydir/two$ make
gcc test.c -o test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test test.c
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c
xqq@ubuntu-server:~/mydir/two$ make fun
test
gcc
test.c
-o
rm -f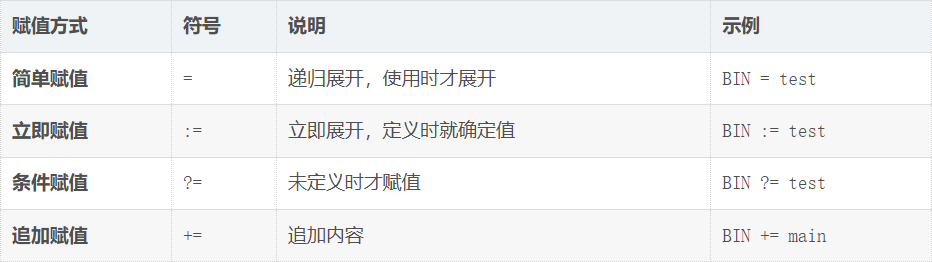
3. 常用自动变量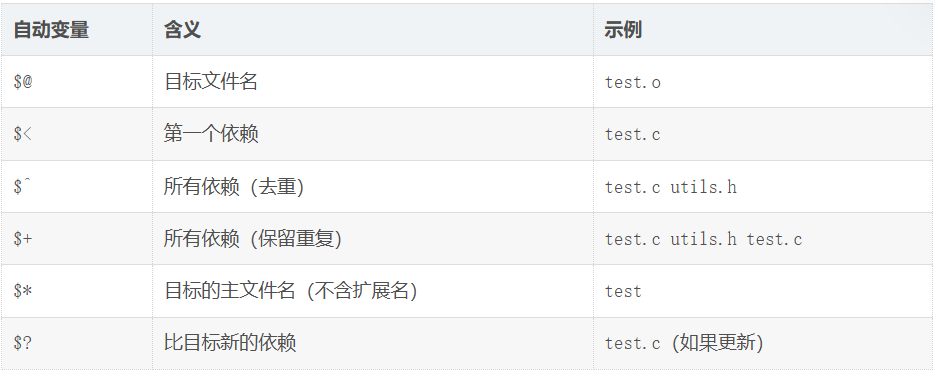
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=test.c
FLAGS=-o
RM=rm -f
$(BIN):$(SRC)
@#$(CC) $(SRC) $(FLAGS) $(BIN)#隐藏注释前面加@
$(CC) $^ $(FLAGS) $@
.PHONY:clean
clean:
$(RM) $(BIN)
.PHONY:fun
fun:
@echo $(BIN)
@echo $(CC)
@echo $(SRC)
@echo $(FLAGS)
@echo $(RM)
xqq@ubuntu-server:~/mydir/two$ make
gcc test.c -o test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test test.c
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test由于依赖方法可以有多行但是要注意tab键,于是我们可以将编译过程优化成可读性更好的编译过程具体方式如下:
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=test.c
FLAGS=-o
RM=rm -f
$(BIN):$(SRC)
@#$(CC) $(SRC) $(FLAGS) $(BIN)
@$(CC) $^ $(FLAGS) $@
@echo "linking $^ to $@"
.PHONY:clean
clean:
@$(RM) $(BIN)
@echo "remove $(BIN)"
.PHONY:fun
fun:
@echo $(BIN)
@echo $(CC)
@echo $(SRC)
@echo $(FLAGS)
@echo $(RM)
xqq@ubuntu-server:~/mydir/two$ make clean
remove test
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=test.c
FLAGS=-o
RM=rm -f
$(BIN):$(SRC)
@#$(CC) $(SRC) $(FLAGS) $(BIN)
@$(CC) $^ $(FLAGS) $@
@echo "linking $^ to $@"
.PHONY:clean
clean:
@$(RM) $(BIN)
@echo "remove $(BIN)"
.PHONY:fun
fun:
@echo $(BIN)
@echo $(CC)
@echo $(SRC)
@echo $(FLAGS)
@echo $(RM)
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c
xqq@ubuntu-server:~/mydir/two$ make
linking test.c to test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test test.c
xqq@ubuntu-server:~/mydir/two$ make clean
remove test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c五、多文件编译:
- 方法一
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=test.c
OBJ=test.o
LFLAGS=-o
FLAGS=-c
RM=rm -f
$(BIN):$(OBJ)
$(CC) $^ $(LFLAGS) $@
%.o:%.c
$(CC) $(FLAGS) $< $(LFLAGS) $@
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c
xqq@ubuntu-server:~/mydir/two$ make
gcc -c test.c -o test.o
gcc test.o -o test
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test.o test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c
意思就是:任何一个 .o 文件,都由同名的 .c 文件编译生成
- test1.o ← 由 test1.c 生成
- test2.o ← 由 test2.c 生成
- test3.o ← 由 test3.c 生成
% 类似于通配符,可以匹配任意字符串:
bash
# 例子
%.o: %.c # 匹配: test.o → test.c, main.o → main.c
%.s: %.i # 匹配: test.s → test.i
%.i: %.c # 匹配: test.i → test.c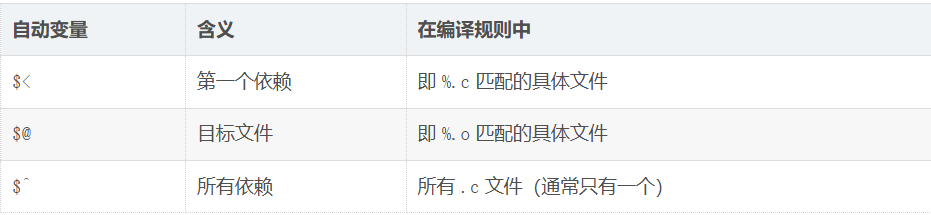
%.o: %.c 是一个"模板规则",告诉 make 如何将任意 .c 源文件编译成同名的 .o 目标文件。$< 代表源文件(.c),$@ 代表目标文件(.o)
- 方法二
bash
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=$(shell ls)
OBJ=test.o
LFLAGS=-o
FLAGS=-c
RM=rm -f
$(BIN):$(OBJ)
$(CC) $^ $(LFLAGS) $@
@echo "linking... $^ to $@"
%.o:%.c
$(CC) $(FLAGS) $< $(LFLAGS) $@
@echo "compiling... $< to $@"
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)
.PHONY:fun
fun:
@echo $(SRC)
xqq@ubuntu-server:~/mydir/two$ make fun
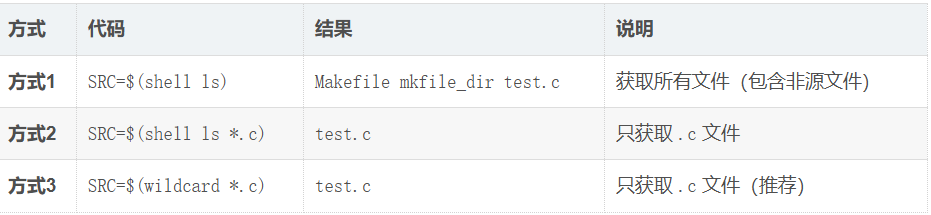
Makefile mkfile_dir test.c#当前目录下的所有文件(shell ls)
#将SRC=$(shell ls)替换成SRC=$(shell ls *.c)后
xqq@ubuntu-server:~/mydir/two$ make fun
test.c
或者使用makefile内置函数wildcard
SRC=$(shell ls)替换成SRC=$(wildcard *.c)也能获取当前目录下所有的.c文件
xqq@ubuntu-server:~/mydir/two$ cat Makefile
BIN=test
CC=gcc
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)#意思就是将SRC内部的.c文件不改变其文件名只改后缀改成.o
LFLAGS=-o
FLAGS=-c
RM=rm -f
$(BIN):$(OBJ)
$(CC) $^ $(LFLAGS) $@
@echo "linking... $^ to $@"
%.o:%.c
$(CC) $(FLAGS) $< $(LFLAGS) $@
@echo "compiling... $< to $@"
.PHONY:clean
clean:
$(RM) $(OBJ) $(BIN)
.PHONY:fun
fun:
@echo $(SRC)
@echo $(OBJ)
xqq@ubuntu-server:~/mydir/two$ make fun
test.c
test.o
xqq@ubuntu-server:~/mydir/two$ make
gcc -c test.c -o test.o
compiling... test.c to test.o
gcc test.o -o test
linking... test.o to test
xqq@ubuntu-server:~/mydir/two$ make clean
rm -f test.o test
xqq@ubuntu-server:~/mydir/two$ ls
Makefile mkfile_dir test.c六、总结:
Makefile 定义"依赖关系"(做什么)和"依赖方法"(怎么做),make 工具根据时间戳智能执行,实现高效的项目自动化构建。
6.Linux第⼀个系统程序−进度条
在实现进度条小程序时要先引入两个概念:
缓冲区
缓冲区是内存中临时存储数据的一块区域。在输入输出(I/O)操作中,数据不会立即写入文件或显示到屏幕,而是先积累在缓冲区里,等到一定条件满足时才真正执行读写操作。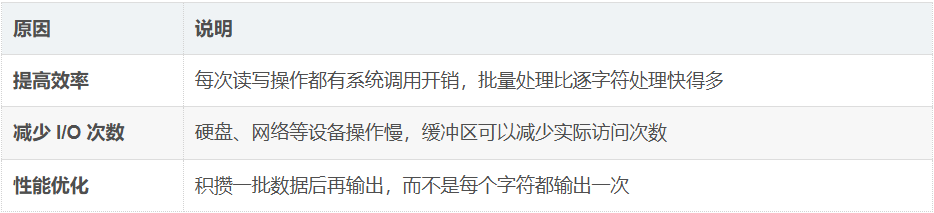
缓冲区的三种类型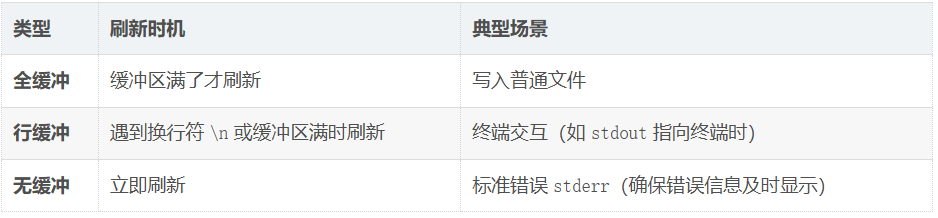
常见问题演示
cpp
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("Hello"); // 没有 \n
sleep(3); // 等待3秒
return 0;
}
//解决方法:
printf("Hello\n"); // 加 \n 立即刷新
// 或
printf("Hello");
fflush(stdout); // 手动刷新缓冲区-
现象:屏幕上3秒内没有任何输出,程序结束后才显示 "Hello"
-
原因 :
stdout是行缓冲,"Hello" 没有换行符,一直等在缓冲区里
手动刷新缓冲区的方法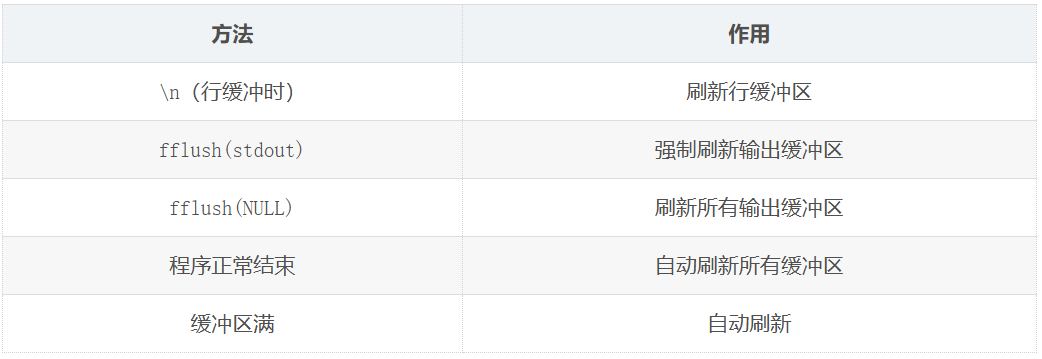
回车、换行
1.\n(换行,Line Feed,LF)
-
作用 :将光标向下移动一行 ,但列位置不变(即垂直移动)
-
在 Unix/Linux中 :
\n就代表回车+换行(即等同于 Enter) -
在 Windows 中 :
\n只是换行,不会回车,光标会跑到下一行的同一列 -
额外作用 :在 C 语言等编程中,
\n会刷新输出缓冲区
2. \r(回车,Carriage Return,CR)
-
作用 :将光标移动到当前行的开头 (第 1 列),但不换行
-
典型应用:
- 覆盖同一行(比如进度条效果:
printf("\rProgress: %d%%", i);)
- 覆盖同一行(比如进度条效果:

1.倒计时程序
1**. 为什么必须用 %2d?**
如果不指定宽度,会出现"残留字符"问题。
问题出在 9 → 99 或 10 → 9 这种位数变化时:
cpp
printf("%d\r", 10); // 输出 "10"
// ... 倒计时
printf("%d\r", 9); // 输出 "9"**屏幕显示结果:**90 // 9 覆盖了 1,但 0 还在!(后面就是80 70 60 ...)
因为 9 只覆盖了第一个字符 1,第二个字符 0 没有被覆盖,残留下来了。
2. %2d 解决了什么?
cpp
printf("%2d\r", 10); // 输出 "10"(占2个宽度)
printf("%2d\r", 9); // 输出 " 9"(前面补一个空格,占2个宽度)屏幕显示:
-
第一步:
10 -
第二步:
9(空格+9,完整覆盖了10的两个字符位置)
结果:9,看起来是 9(前面有个空格,但肉眼不太明显),没有残留字符。
3. 更好的方案:%02d(推荐)
如果不想要前面的空格,想要 09、08 这样显示:printf("%02d\r", i); // 输出 09, 08, 07...
也可以%-2d ,和 %02d 一样能解决残留字符问题,只是显示风格不同(左对齐 和 补零)。
代码如下:
cpp
#include<stdio.h>
#include<unistd.h>
int main()
{
int i=9;
while(i>=0)
{
printf("%02d\r",i);//\r 让光标回到行首,覆盖之前的数字
fflush(stdout);//由于\r没有刷新缓冲区,所以要手动刷新
i--;
sleep(1);
}
printf("\n");// 最后换行,避免终端显示异常
return 0;
}2.进度条程序--version1
cpp
xqq@ubuntu-server:~/mydir/three/processbar$ cat process.c
#include"process.h"
#include<string.h>
#include<unistd.h>
#define NUM 101
#define STYLE '#'
void process_v1()
{
char buffer[NUM];
memset(buffer,0,sizeof(buffer));//将101个字节全部设为 \0(空字符)
const char* lable="|/-\\";
int len=strlen(lable);
int cnt=0;
while(cnt<=100)
{
printf("[%-100s][%d%%][%c]\r",buffer,cnt,lable[cnt%len]);//预留100个字符空间,并左对齐
fflush(stdout);
buffer[cnt]=STYLE;
cnt++;
usleep(50000);
}
printf("\n");//防止命令行覆盖
}效果如下:

当前代码只是按时间匀速刷新(usleep(50000)),假装完成了 0% → 100%,完全没有获取真实任务的进度。于是我们的version2出来了
3.进度条程序--version2
一个真正的进度条,应该结合场景,边下载,边更新进度条,真实任务进度 → 获取当前完成量 → 计算百分比 → 更新进度条显示,具体实现如下:
main.c
cpp
#include"process.h"
#include<stdio.h>
#include<unistd.h>
double total=1024.0;//总下载数据大小(假设1G)
double speed=1.0;//下载速度1MB/s
void Download()
{
double current=0;//当前下载量
while(current<=total)//下载量不够就继续
{
FlushProcess(total,current);//刷新进度
//下载代码
usleep(3000);//充当下载数据
current+=speed;
}
printf("\ndownload %.2lfMB Done\n",current);
}
int main()
{
//process_v1();
Download();
Download();
Download();
return 0;
}process.c
cpp
#include"process.h"
#include<string.h>
#include<unistd.h>
#define NUM 101
#define STYLE '#'
void process_v1()
{
char buffer[NUM];
memset(buffer,0,sizeof(buffer));//将101个字节全部设为 \0(空字符)
const char* lable="|/-\\";
int len=strlen(lable);
int cnt=0;
while(cnt<=100)
{
printf("[%-100s][%d%%][%c]\r",buffer,cnt,lable[cnt%len]);//预留100个字符空间,并左对齐
fflush(stdout);
buffer[cnt]=STYLE;
cnt++;
usleep(50000);
}
printf("\n");//防止命令行覆盖
}
void FlushProcess(double total,double current)
{
char buffer[NUM];
memset(buffer,0,sizeof(buffer));
const char* lable="|/-\\";
int len=strlen(lable);
static int cnt=0;
//不需要自己循环,填充#
int num=(int)(current*100/total);
for(int i=0;i<num;i++)
{
buffer[i] =STYLE;
}
double rate= current/total;
cnt%=len;
printf("[%-100s][%.1f%%][%c]\r",buffer,rate*100,lable[cnt]);
cnt++;
fflush(stdout);
}process.h
cpp
#pragma once
#include<stdio.h>
void process_v1();
void FlushProcess(double total,double current);效果如下:

优化:进度显示与业务逻辑解耦
cpp
#include"process.h"
#include<stdio.h>
#include<unistd.h>
double total=1024.0;//总下载数据大小(假设1G)
double speed=1.0;//下载速度1MB/s
typedef void (*callback_t)(double total,double current);//定义函数指针类型
//回调函数
void Download(callback_t cb)
{
double current=0;//当前下载量
while(current<=total)//下载量不够就继续
{
cb(total,current);//刷新进度
//下载代码
usleep(3000);//充当下载数据
current+=speed;
}
printf("\ndownload %.2lfMB Done\n",current);
}
//回调函数
void Upload(callback_t cb)
{
double current=0;//当前下载量
while(current<=total)//下载量不够就继续
{
cb(total,current);//刷新进度
//下载代码
usleep(3000);//充当下载数据
current+=speed;
}
printf("\nUpload %.2lfMB Done\n",current);
}
int main()
{
//process_v1();
Download(FlushProcess);
Download(FlushProcess);
Upload(FlushProcess);
Upload(FlushProcess);
return 0;
}7.版本控制器Git
Git 本质上就是一个"专业版的 Ctrl+S 历史记录 + 团队协作工具" 。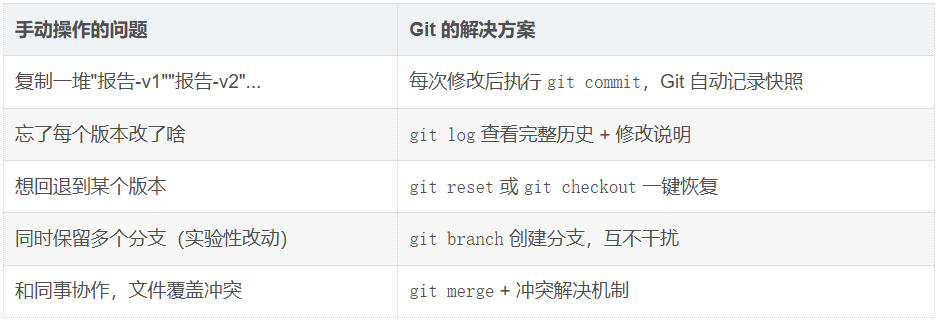
cpp
工作目录 暂存区 本地仓库 远程仓库
(Working Dir) → (Index/Stage) → (Local Repo) → (Remote Repo)
↓ ↓ ↓ ↓
正在编辑 git add git commit git push
的文件 暂存改动 永久记录 同步到云端什么是版本控制?
版本控制 是一种记录一个或若干文件内容变化,以便将来查阅特定版本修订情况的系统。更简单的说法:版本控制 = 文件变化的时间机器 + 多人协作的桥梁
仓库分为本地仓库和远端仓库,两者本质都是一个文件夹,只不过本地仓库是在自己电脑上的硬盘上的文件夹,远端仓库就是托管在云服务器(或任何远程主机)上的一个 Git 仓库 ,本质上也是一个带 .git 的文件夹*,通过 push/pull 保持同步。去中心化分布式版本控制 = 每个开发者电脑上都有一个完整的项目历史仓库,不依赖中央服务器就能完成大部分版本管理操作,中央服务器只是方便协作的"约定节点"而非"唯一权威"。*
在gitee创建项⽬
Gitee 上点「新建仓库」→ 填名称 → 创建 → 本地 git push 上去
下载项⽬到本地
命令:git clone url 这⾥的 url 就是刚刚建⽴好的项⽬的链接
Git三板斧
工作目录 → git add → 暂存区 → git commit → 本地仓库 → git push → 远端仓库 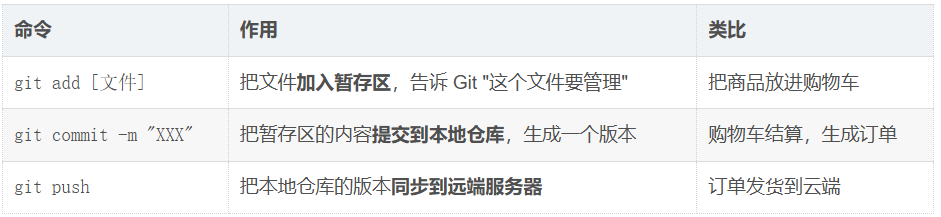
注意:
- 未
add的文件,Git 不会跟踪它的变化。 - git提交时只会提交变化的部分
- 暂存区不是一个你可以直接看到的文件夹,它存储在项目根目录下的
.git隐藏文件夹内部的索引文件中。 git status是 Git 中最常用的命令之一,用于**查看当前工作区和暂存区的状态,**内容包含:当前在哪个分支、哪些文件被修改了但还没 add、哪些文件已经 add 了但还没 commit- **
git commit -m "XXX"**就是给这次提交贴个标签,说明"我做了什么",方便以后查看历史时知道每个版本的意义。 - **
.gitignore是一个文本文件,**用来告诉 Git 哪些文件或文件夹不要跟踪、不要提交到仓库。 - git log 是查看提交历史的命令,显示谁、什么时候、提交了什么、为什么提交
Linux 本地仓库 和 Windows 本地仓库 在地位上是完全对等的,所以它们之间才可以通过一个共享的远程仓库(比如在 Gitee/Github 上)作为桥梁,方便地进行数据交换和同步,在 Windows 上我们可以通过 TortoiseGit 工具(非必须也可以使用命令行)拉取更新
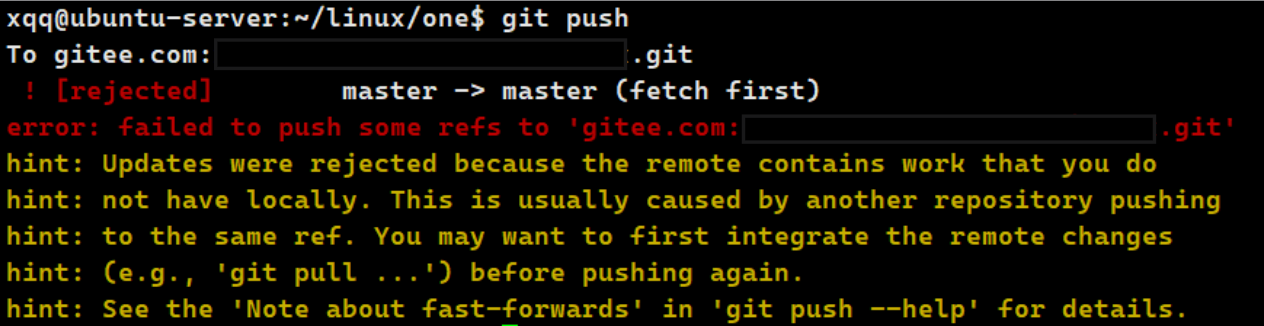
当我们在一个平台修改了文件并提交后,在另一个平台编辑同文件然后进行git push时会冲突,下面演示的就是在windows修改文件然后再linux继续修改同一个文件的案例
- 远程仓库(Gitee) 有 Windows 提交的新内容(本地没有)
- Linux 本地仓库,基于旧的版本修改了同一个文件 Git 拒绝 push,因为会覆盖远程的新内容
简单说:远程有更新,本地不是最新版本,Git 不允许直接 push。
git push被拒绝 → 先git pull拉取远程更新 → 有冲突就手动解决 →git add+git commit→ 再git push建议:

8.调试器 - gdb/cgdb使⽤
GDB (GNU Debugger)是 Linux 下最常用的 C/C++ 调试工具,CGDB 是它的增强版(带源代码窗口界面)。
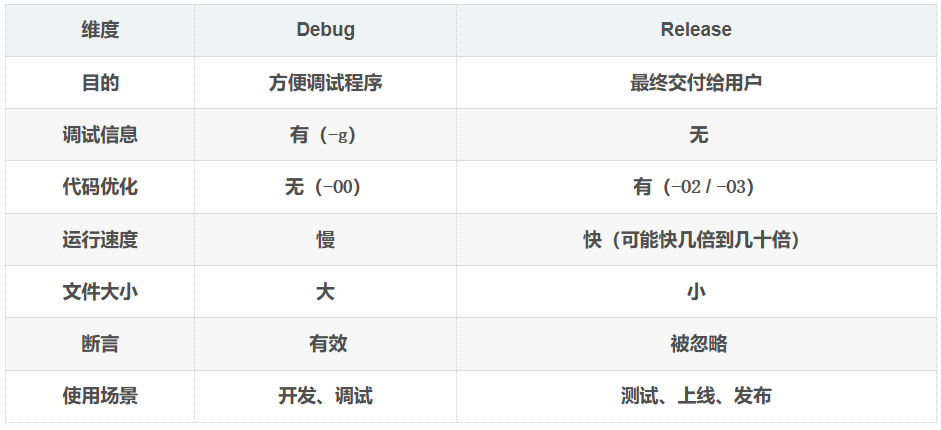
Debug vs Release

GCC 默认编译是Release 模式 (无调试符号,有优化),也就不能进行调试,想调试必须加 -g 参数。 这就是为什么 No debugging symbols found 的原因。

bash
xqq@ubuntu-server:~/linux/three/processbar$ cat Makefile
SRC=$(wildcard *.c)
OBJ=$(SRC:.c=.o)
BIN=processbar
$(BIN):$(OBJ)
gcc $^ -o $@
%.o:%.c
gcc -c $< -g#加上-g选项
.PHONY:
clean:
rm -f $(OBJ) $(BIN)1.GDB的使用
开始: gdb binFile(可执行程序)
退出: ctrl + d 或 quit 调试命令
由于 CGDB = GDB + 源代码窗口,100% 兼容 GDB 命令,完全可以直接取代。学会 CGDB,等于学会 GDB。所以这里我们重点讲解CGDB
2.CGDB详解
调试代码:
cpp
#include <stdio.h>
int Sum(int s, int e)
{
int result = 0;
for(int i = s; i <= e; i++)
{
result += i;
}
return result;
}
int main()
{
int start = 1;
int end = 100;
printf("I will begin\n");
int n = Sum(start, end);
printf("running done, result is: [%d-%d]=%d\n", start, end, n);
return 0;
}GDB/CGDB 常用命令速查表
一、源代码查看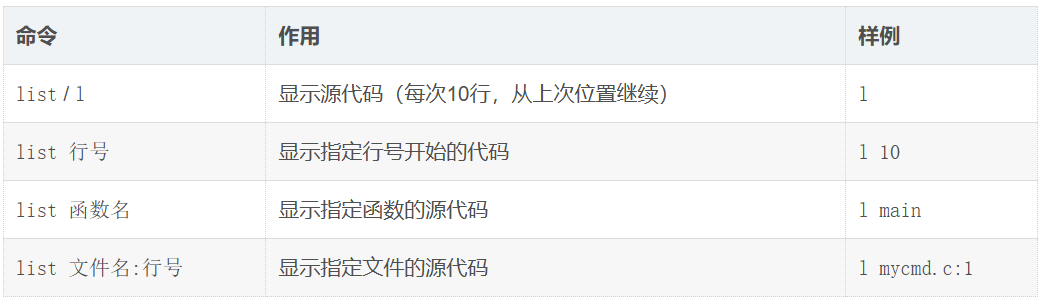
二、程序执行控制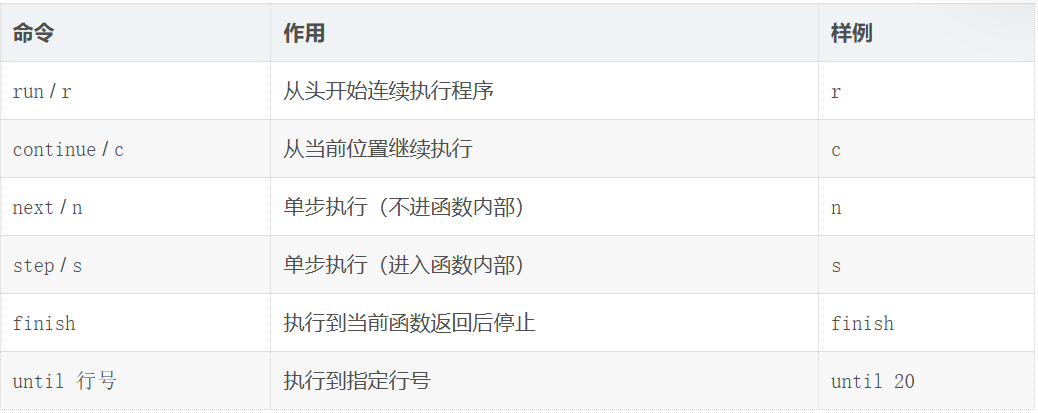

三、断点管理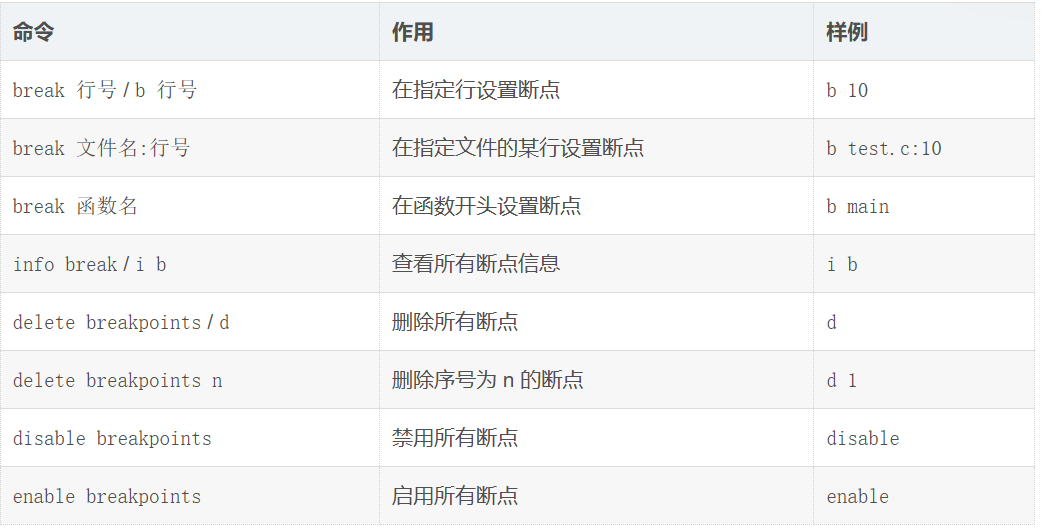
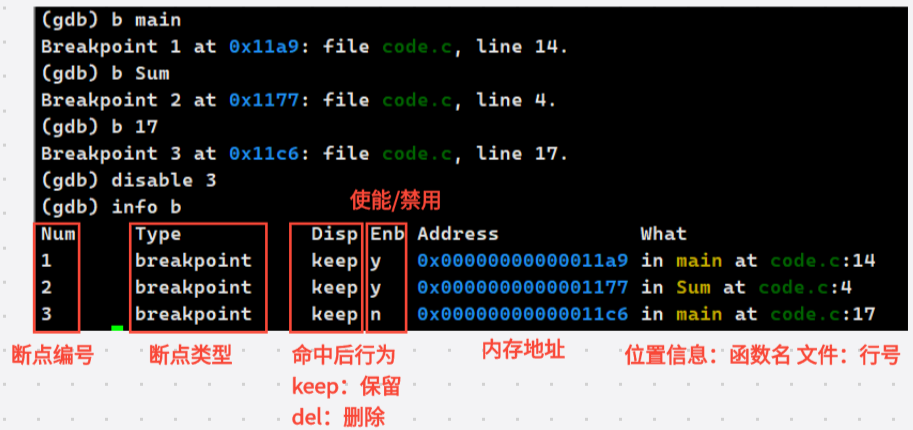
注意:
- 删除或者使能断点只能用断点编号删除也就是info b展示的断点编号,不能使用d/disable 行号来删除或者使能
- 断点的本质就是把代码进行块级别划分,以块为单位进行快速定位bug区域
四、变量查看与跟踪 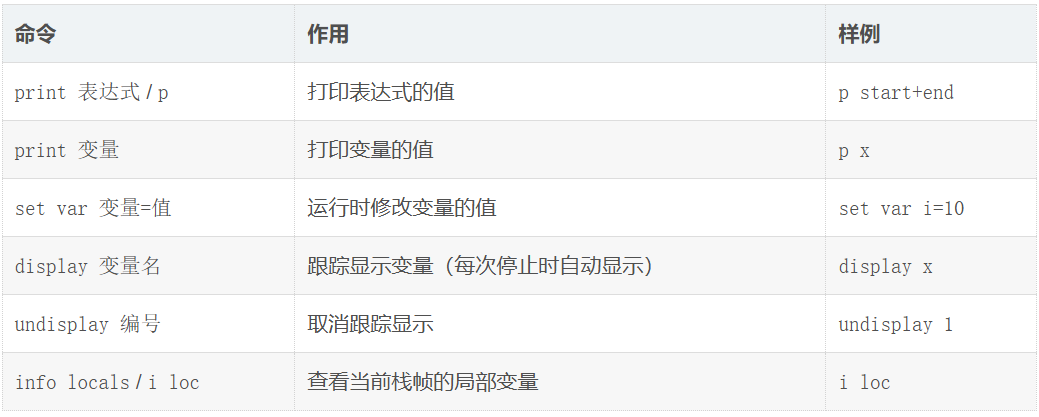
注意:还是一样,如果要取消跟踪变量要undisplay +编号而不是变量名
五、调用栈查看与退出调试器
CGDB 中按回车的行为:直接按回车 = 重复执行上一条命令
调试技巧
watch
watch执⾏时监视⼀个表达式(如变量)的值。如果监视的表达式在程序运⾏期间的值发⽣变化,GDB 会暂停程序的执⾏,并通知使⽤者
只需要在 GDB 命令行中输入 watch 命令即可:
bash
watch <表达式>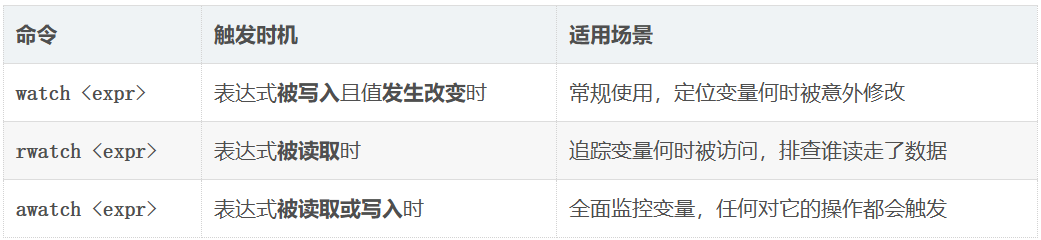
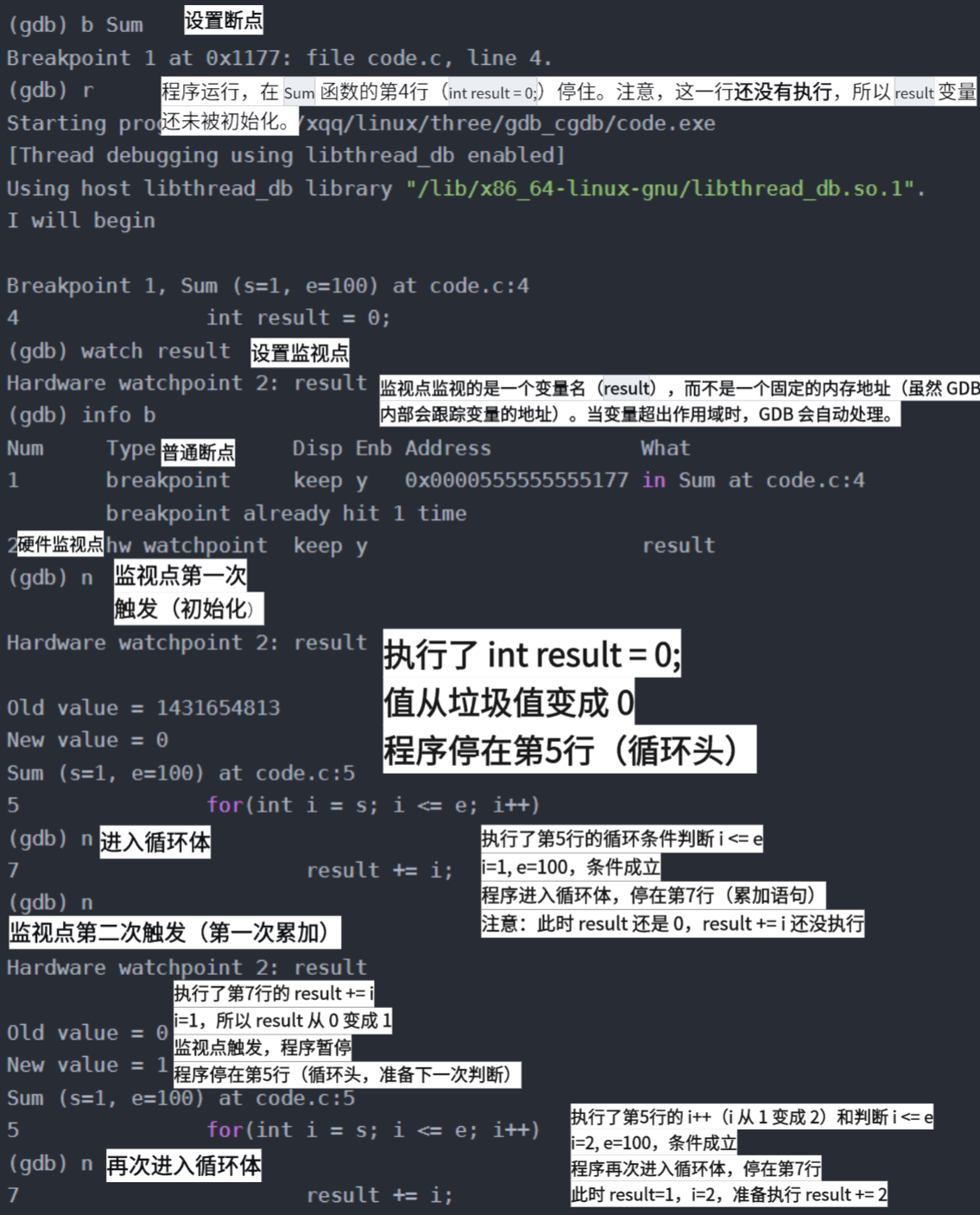
set var确定问题原因
set var 正是 GDB/CGDB 中一个非常强大且高效的调试技巧,可以在程序运行时直接修改变量的值,无需重新编译。
bash
set var <变量名> = <新值>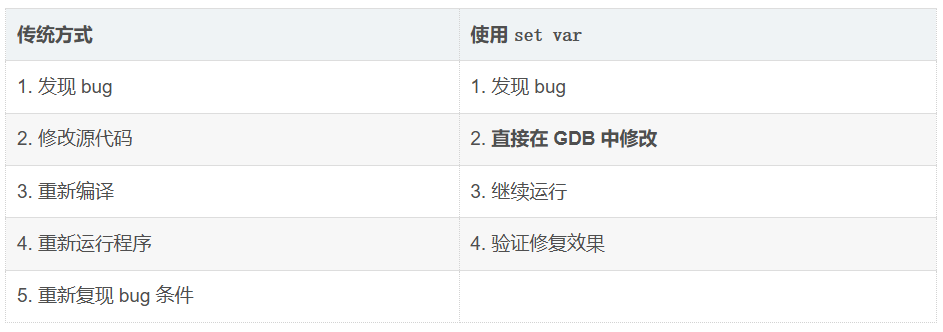
条件断点
条件断点是 GDB/CGDB 中非常实用的功能,可以在特定条件满足时才暂停程序,避免在无关的迭代中反复中断。
bash
b <行号> if <条件表达式>添加条件断点:比如我想在i==10时停下来就可以使用 b 7 if i == 10
bash
(gdb) b 7 if i == 10
Breakpoint 1 at 0x1186: file code.c, line 7.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000001186 in Sum at code.c:7
stop only if i == 10
(gdb) r
Starting program: /home/xqq/linux/three/gdb_cgdb/code.exe
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
I will begin
Breakpoint 1, Sum (s=1, e=100) at code.c:7
7 result += i;
(gdb) p i
$1 = 10也可以直接在已经存在的断点加条件:
bash
(gdb) b 7
Breakpoint 1 at 0x1186: file code.c, line 7.
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000001186 in Sum at code.c:7
(gdb) condition 1 i == 10
(gdb) info b
Num Type Disp Enb Address What
1 breakpoint keep y 0x0000000000001186 in Sum at code.c:7
stop only if i == 10
(gdb) r
Starting program: /home/xqq/linux/three/gdb_cgdb/code.exe
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
I will begin
Breakpoint 1, Sum (s=1, e=100) at code.c:7
7 result += i;
(gdb) p i
$1 = 10
qa:如果CGDB卡死怎么办:
Ctrl + L:这会强制刷新整个屏幕,解决大部分显示异常问题Ctrl + C:这会发送中断信号给正在运行的程序,强行让 GDB 暂停下来。如果是因为程序进入死循环导致的假死,这招最管用。