1. 整体架构
2. Mluti-Head Attention
它允许模型同时关注来自不同位置的信息。通过分割原始的输入向量到多个头(head),每个头能独立地学习不同的注意力权重 ,从而增强模型对输入序列中不同部分的关注能力。
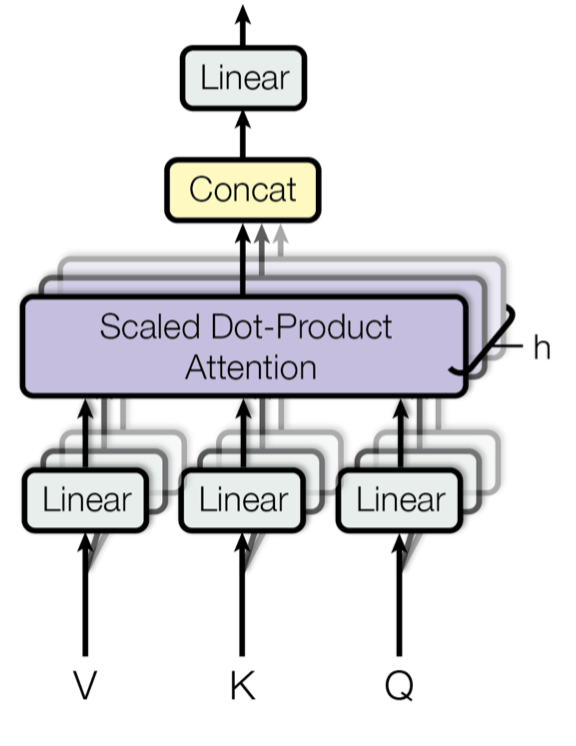
Multi-Head Attention(多头自注意力)
(1)输入线性变换
对于输入的Query(查询)、key(键)和 Value(值)向量,首先通过线性变换将它们映射到不同的子空间。这些线性变换的参数是模型需要学习的。
(2)分割多头
经过线性变换后,Query,Key和Value向量被分割成多头 。每个头都会独立地进行注意力计算。
(3)缩放点积注意力
在每个头内部,使用缩放点积注意力来计算Query 和 Key之间的注意力分数。这个分数决定了在生成输出时,模型应该关注Value向量的部分。
(4)注意力权重应用
将计算出的注意力权重应用于Value向量,得到加权的中间输出。这个过程可以理解为根据注意力权重对输入信息进行筛选和聚焦。
(5)拼接和线性变换
将所有头的加权输出拼接在一起,然后通过一个线性变换得到最终的Multi-Head Attention输出。
3. Scaled Dot-Product Attention(缩放点积注意力)
它是Transformer模型中的多头注意力机制的一个关键组成部分。
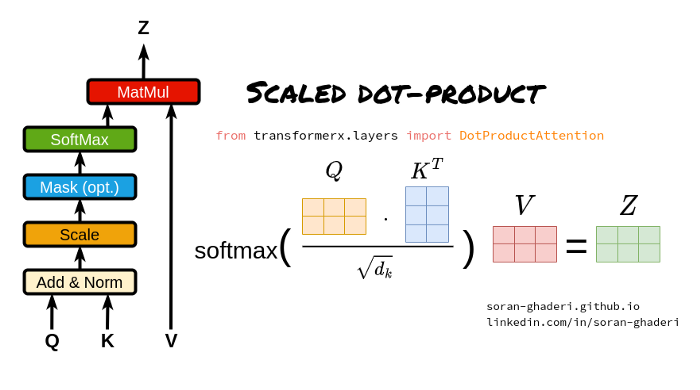
Scaled Dot-Product Attention(缩放点积注意力)
(1)Query,Key 和 Value矩阵
Query矩阵(Q):表示当前的关注点或信息需求,用于与Key矩阵进行匹配。
Key矩阵(K):包含输入序列中各个位置的标识信息,用于被Query与某个Key匹配时,相应的Value将被用来计算输出。
Value矩阵(V):存储了与Key矩阵相对应的实际值或信息内容,当Query与某个Key匹配时,相应的Value被用来计算输出。
(2)点积计算
通过计算Query矩阵和Key矩阵之间的点积(即对应元素相乘后求和),来衡量Query与每个Key之间的相似度或匹配程度。
(3)缩放因子
由于点积操作的结果可能非常大,尤其是在输入维度较高的情况下,这可能导致softmax函数在计算注意力权重时进入饱和区。为了避免这个问题,缩放点积注意力引入了一个缩放因子,通常是输入维度的平方根。点积结果除以这个缩放因子,可以使得softmax函数的输入保持在一个合理的范围内。
(4)Softmax函数
将缩放后的点积结果输入到softmax函数中,计算每个Key相对于Query的注意力权重。Softmax函数将原始得分转换为概率分布,使得所有Key的注意力权重和为1。
(5)加权求和
使用计算出的注意力权重对Value矩阵进行加权求和,得到最终的输出。这个过程根据注意力权重的大小,将更多的关注放在与Query更匹配的Value上。
| 对比维度 | 原始 Attention(普通注意力) | Self-Attention 自注意力 | 缩放点积注意力 Scaled Dot-Product Attention |
|---|---|---|---|
| 整体类型 | 注意力结构 | 注意力结构 | 打分计算公式(非独立结构) |
| 是否QKV结构 | 是,标准QKV | 是,完全相同QKV结构 | 共用QKV结构,仅优化打分公式 |
| QKV来源 | Q、K、V不同源 Q来自序列A,K/V来自序列B | Q、K、V同源 全部来自同一输入序列 | 不限制同源/不同源,两者通用 |
| 建模关系 | 跨序列互相关注(A关注B) | 序列内部自己关注自己 | 通用相似度打分方式 |
| 打分公式 | 普通点积:QK⊤\boldsymbol{QK^\top}QK⊤ 无缩放 | 普通点积:QK⊤\boldsymbol{QK^\top}QK⊤ 原生无缩放 | 缩放点积:QK⊤dk\boldsymbol{\dfrac{QK^\top}{\sqrt{d_k}}}dk QK⊤ 带缩放÷√d |
| 是否缩放 | ❌ 无缩放 | ❌ 原生无 | ✅ 强制缩放,防止softmax梯度消失 |
| 关系总结 | 基础注意力原型 | 原始Attention的同源特例 | 原始Attention/Self-Attention的计算优化版 |
4. Masked Multi-Head Attention
其实Maked MHA的核心还是scaled dot-production attention,还是从制备Q、K和V开始。
XW=QXW = QXW=Q
(XW)T=WTXT=QT(XW)^T = W^T X^T = Q^T(XW)T=WTXT=QT
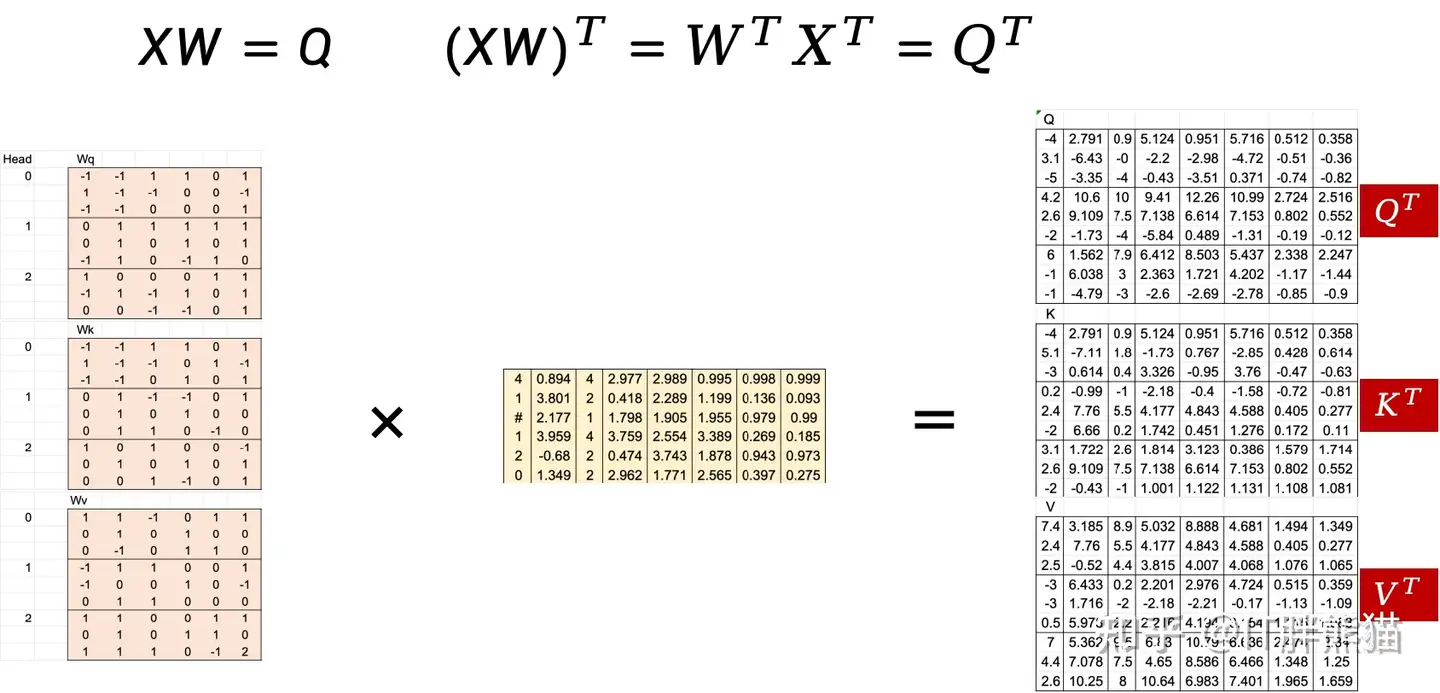
得到了Q、K、V之后,进行Masked MHA计算,数学上只要做个矩阵加法,即增加一个极大负值(这里需要注意转置的问题)
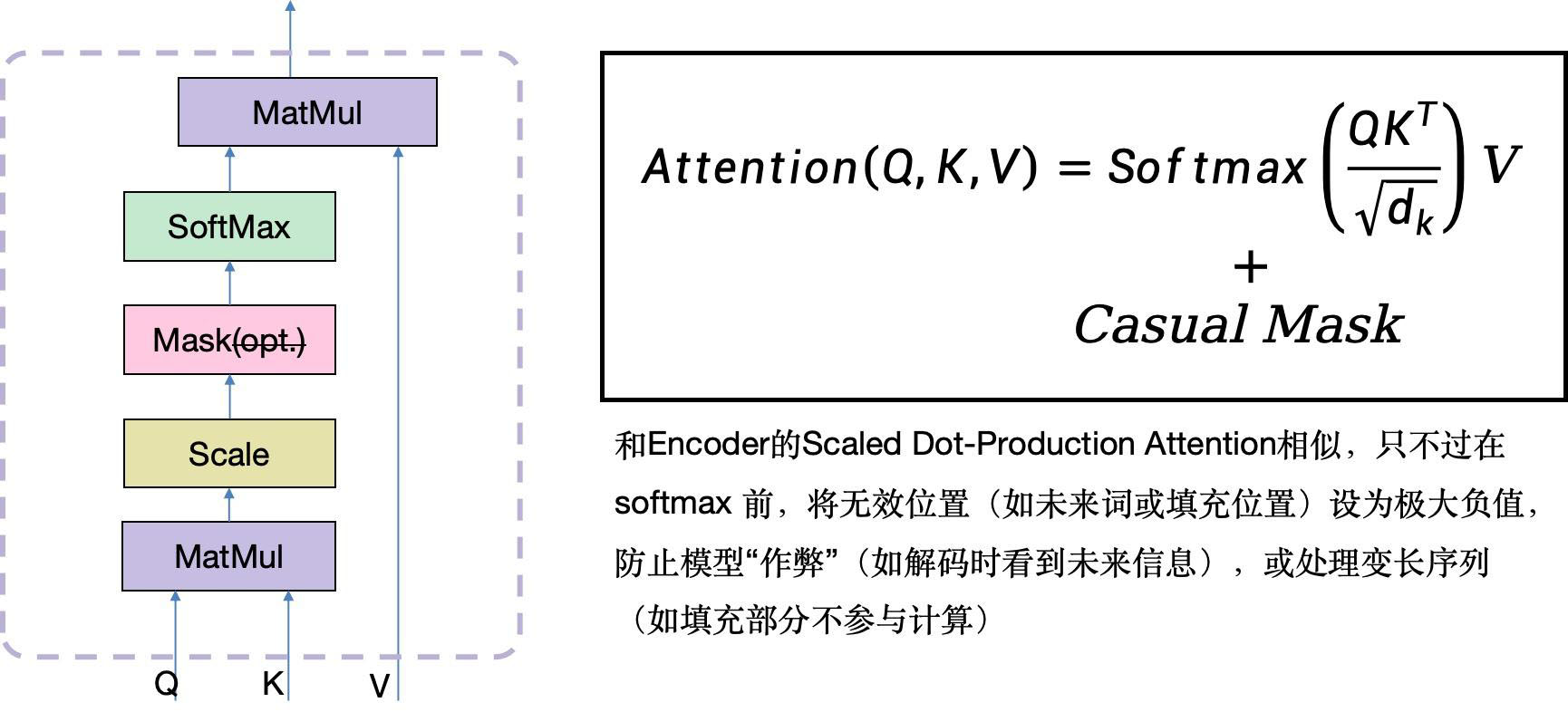
看下实际计算,依然是以Head 0为例,注意Casual Mask也做了转置。需要注意的是这里使用了3个注意力头,后面还会切换成2个注意力头,非常灵活。
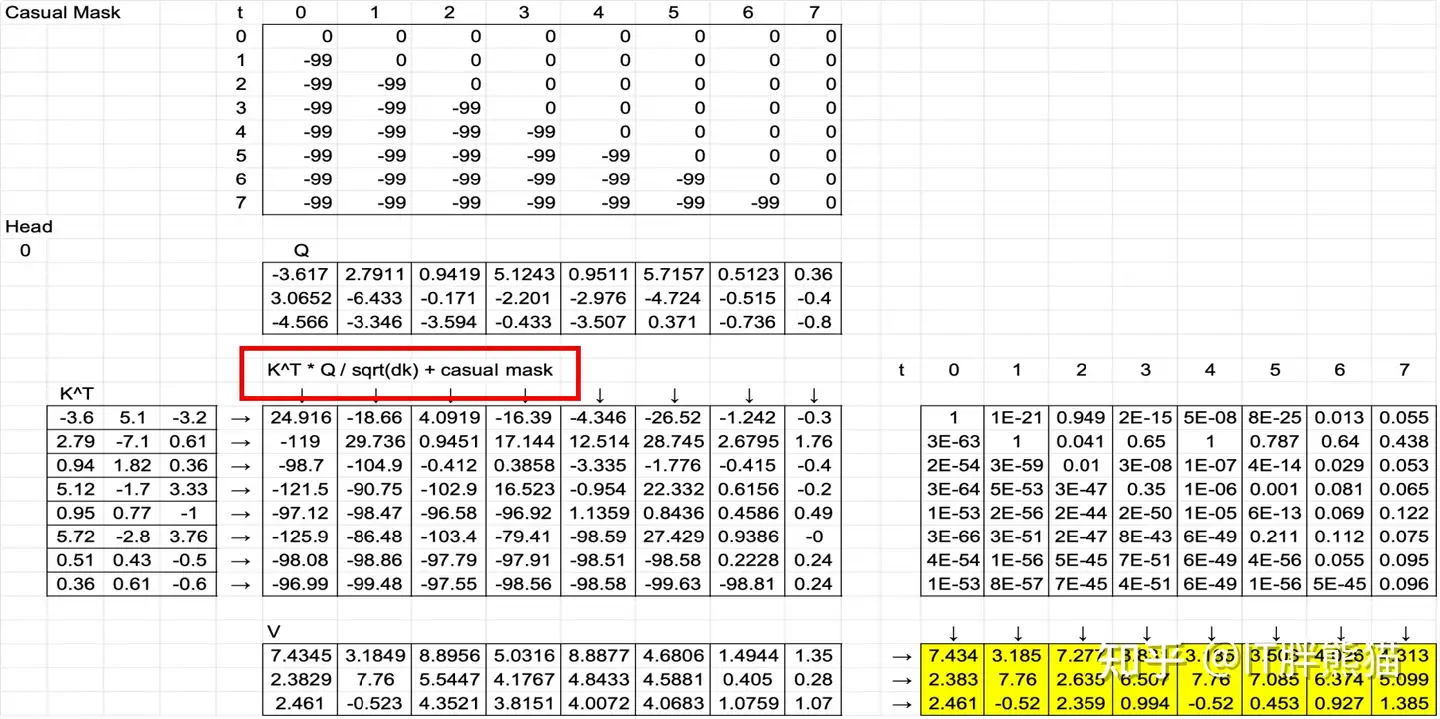
同理得到Head1、Head2的结果,通过线性变换搬回到系统维度d_model。
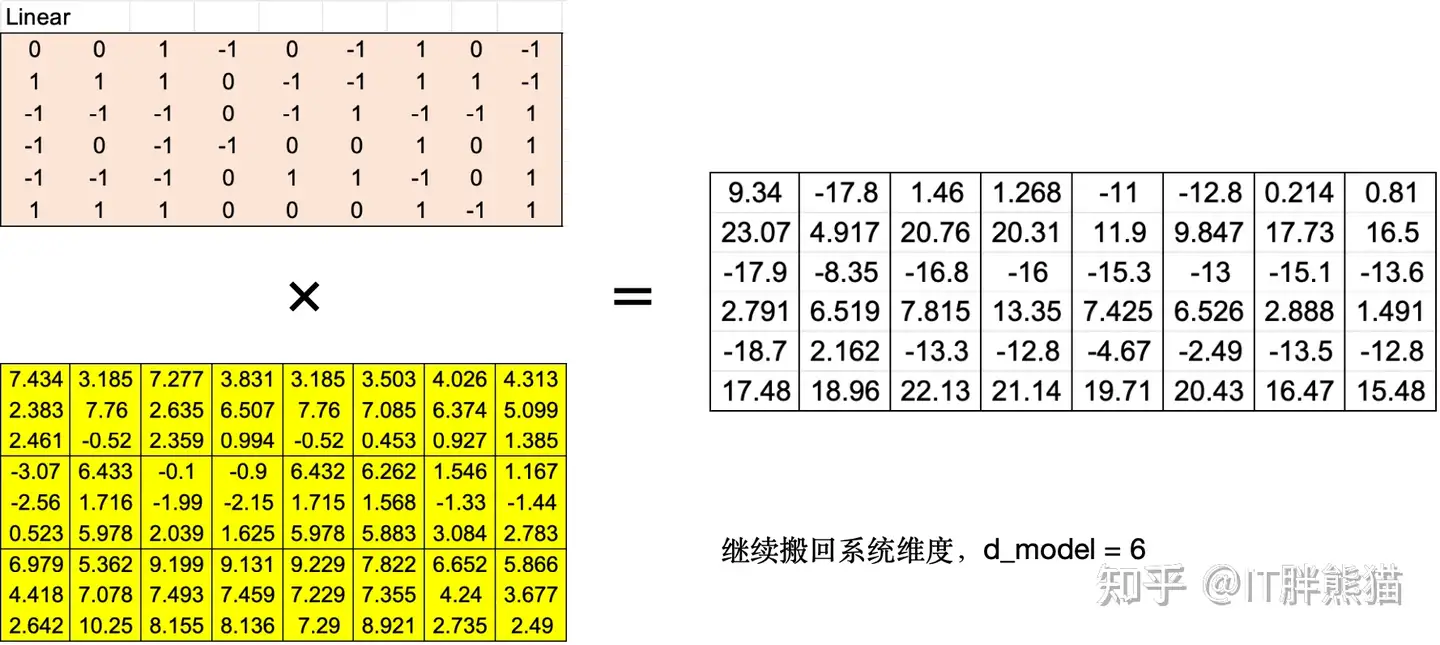
3个注意力头切换到系统维度dmodel=63个注意力头切换到系统维度 d_model = 63个注意力头切换到系统维度dmodel=6
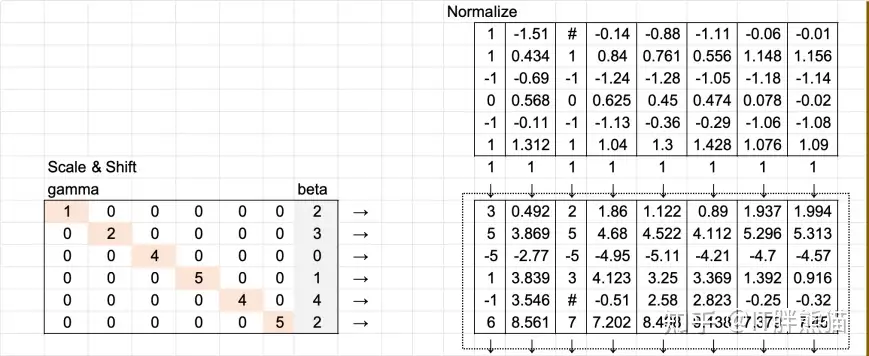
Add
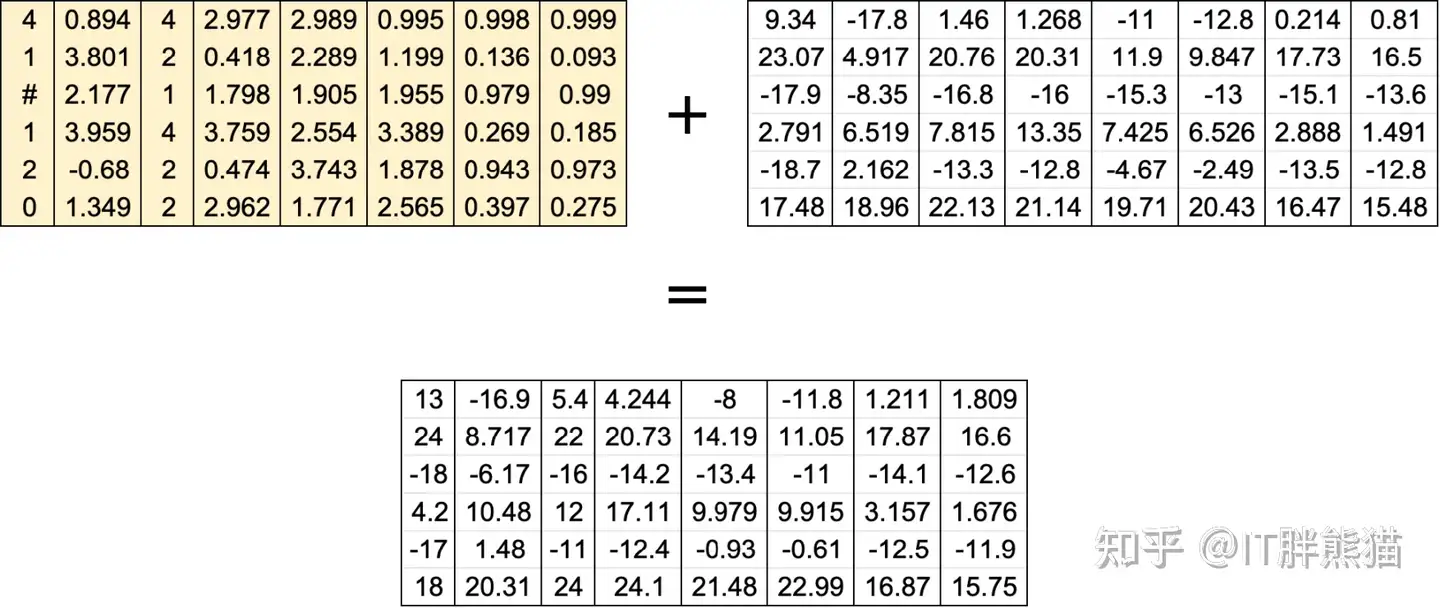
Normal ,Scale & shift
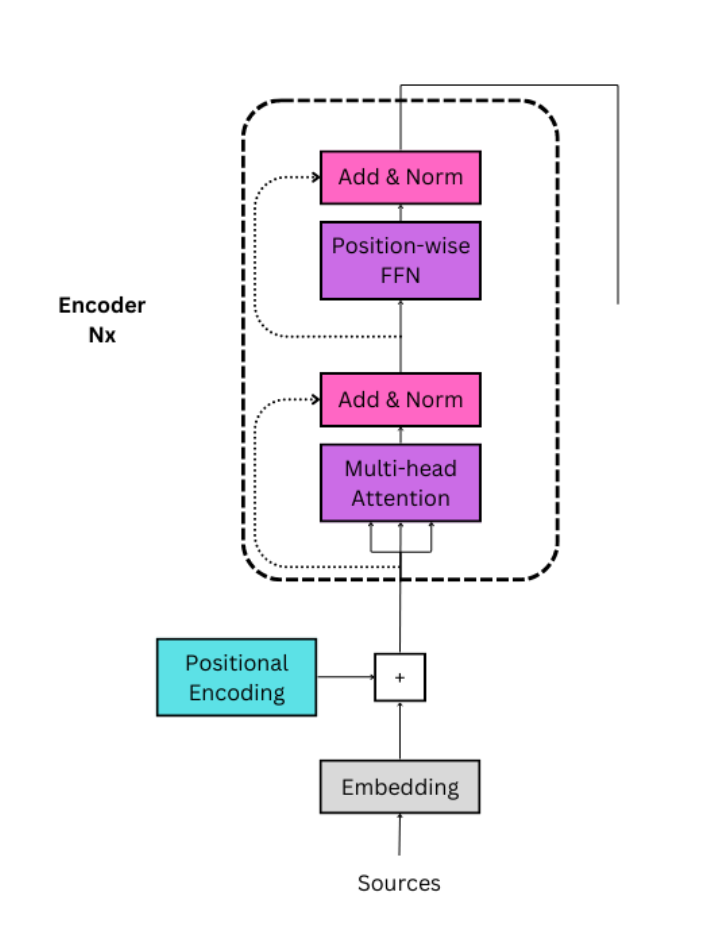
5. Position-wise Feed Forward Network(逐位置前馈网络 FFN)
基于位置的前馈神经网络(FFN)由两个全连接层或多层感知机(MLP)组成。隐藏层(称为d_ffn)的维度一般设定为d_model的四倍左右。因此,它有时被称为扩展收缩网络。
FNN第一层的权重维度为(d_model, d_ffn), 这意味着在张量乘法中,必须对每个序列进行广播。着意味着每个序列都乘以相同的权重。如果输入相同的序列,输出也将相同。这一逻辑同样适用于大小为(d_ffn,d_model)的第二个全连接层,它将张量返回到原始大小。
各层之间使用Relu激活函数max(0,X)。任何大于0的值都保持不变,任何小于或等于0的值都变为0.它引入了非线性,有助于防止梯度消失。
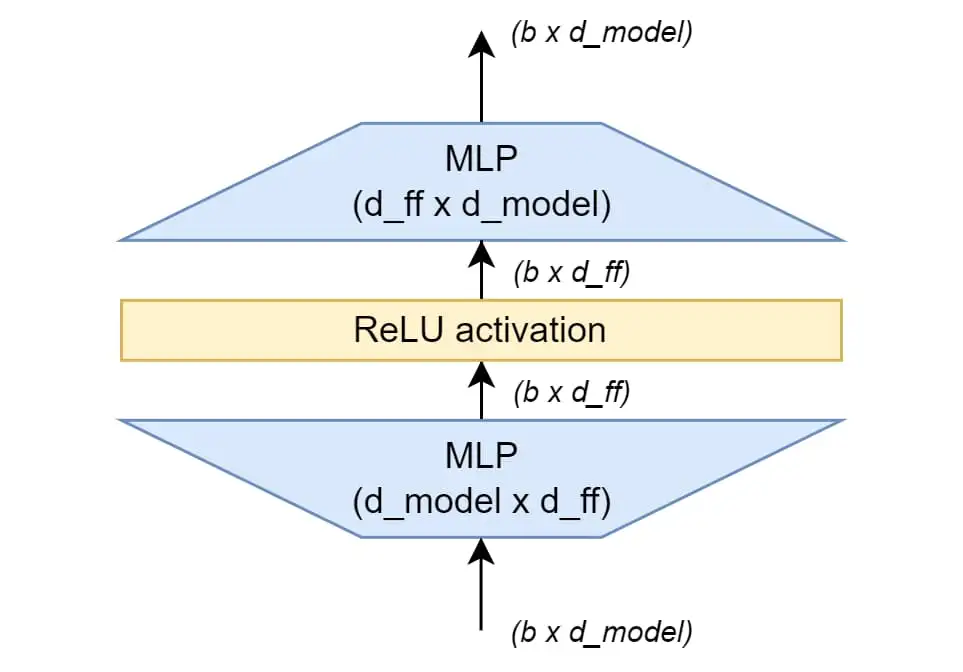
2017年结构
在2017年的原始Transformer中,前馈网络很简单:输入经过一个线性层放大维度 (通常放大4倍),经过ReLU激活函数(把负数全变成0),然后再经过一个线性层缩小回原维度 。这种设计虽然有效,但ReLU在零点处不可导(不平滑),且负半轴完全为零(会导致神经元"死亡"现象。)
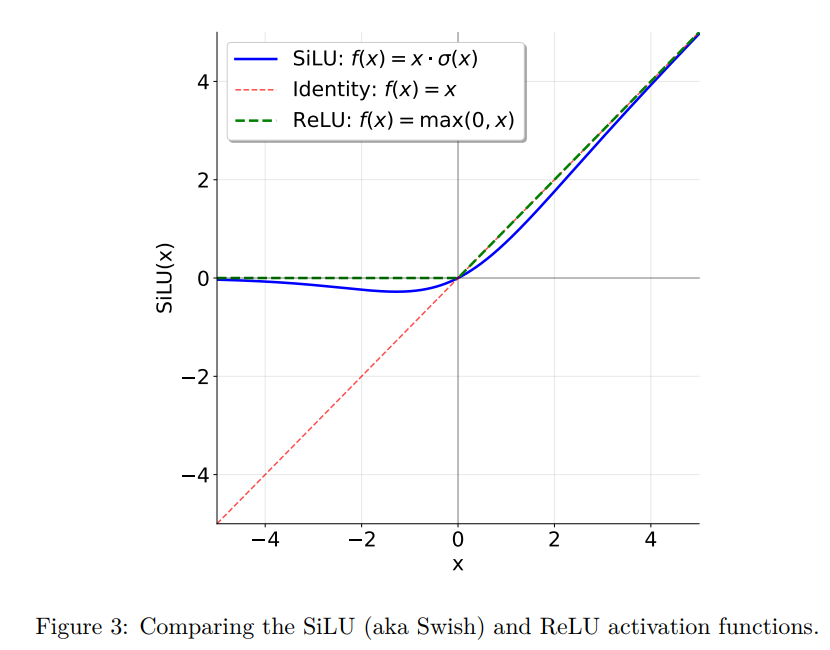
改进一: 使用SiLU(Swish)激活函数
为了解决ReLU的问题,现代模型引入了SiLU(也叫Swish)激活函数。
公式: x ×\times× Sigmoid(x)
特点: 它整体形状像ReLU,但有两个关键不同:一是在零点附近非常平滑(处处可导,有利于优化);二是在负半轴允许有微小的负值输出,保留了少量负向信息,这被证明对深层网络的训练更有利。
改进二: 引入门控机制(GLU)
门控线性单元 (GLU) 是一种特殊的结构。它不只是对输入做一次线性变换,而是做两次。
终极形态: SwiGLU
激活函数:
在最初的Transformer论文中,Transformer的前馈网络由两个带有Relu激活函数(ReLU(x)=max(0,x))介入其间的线性变换组成。内部前馈层的维度通常是输入维度的4倍。
然而,与这种原始设计相比,现代语言模型往往包含两个主要变换:它们使用另一种激活函数,并采用门控机制.具体来说,我们将实现如LLama 3 和Qwen2.5 等LLM中采用"WwiGLU"激活函数,该函数将SiLU激活与称为门控线性单元(GLU)的门控机制结合起来.遵循自PaLM以来的大多数现代LLM的做法,我们有时也会省略线性层中使用的偏置项。
siLU或Swish激活函数定义如下:
SiLU(x)=x.δ(x)=x1+e−xSiLU(x) = x.\delta(x) = \frac{x}{1+e^{-x}}SiLU(x)=x.δ(x)=1+e−xx
SiLU激活函数与ReLU激活函数相似,但其在零点处是平滑的。
门控线性单元(GLUs)最初由Dauphin等人定义为经过sigmoid函数的线性变换 与 另一个线性变换之间的逐元素乘积:
GLU(x,W1,W2)=δ(w1x)⊙W2xGLU(x,W_1,W_2)=\delta(w_1x)\odot W_2xGLU(x,W1,W2)=δ(w1x)⊙W2x
其中⊙\odot⊙表示逐元素乘法。门控线性单元被建议用于"减少深层架构的梯度消失问题,通过为梯度提供线性路径,同时保留非线性能力。"
将SiLU/Swish 和 GLU结合在一起,我们得到了SwiGLU,我们将把它用于我们的前馈网络:
FFN(x)=SwiGLU(x,W1,W2,W3)=W2(SiLU(W1x)⊙W3x)FFN(x) = SwiGLU(x,W_1,W_2,W_3) = W_2(SiLU(W_1x) \odot W_3x)FFN(x)=SwiGLU(x,W1,W2,W3)=W2(SiLU(W1x)⊙W3x)
其中 x∈Rdmodelx\in R^{d_{model}}x∈Rdmodel, W1,W3∈Rdff×dmodelW_1,W_3\in R^{d_{ff}\times d_{model}}W1,W3∈Rdff×dmodel, W2∈Rdmodel×dffW_2 \in R^{d_{model} \times d_{ff}}W2∈Rdmodel×dff, 并且按照惯例,dff=83dmodeld_ff = \frac{8}{3}d_{model}dff=38dmodel
Shazeer 首次提出将SiLU /Swish 激活与GLUs结合,并进行了实验,表明在语言建模任务上,SwiGLU优于ReLU 和 SiLU(无门控)等基线。
6. Positional Encoding
Positional Encoding 就是将token的位置信息体现在输入中,因为多头注意力(MHA)中没有考虑位置信息,所以作为Encoder/Decoder的输入来考虑。
在Transformer架构中,在Encoder和Decoder的输入中只计算一次 ,就是token的Embedding结果和PE相加 。 所以PE的矩阵形状和token的Embedding结果一致。
在Transformer中采用了后者,位置向量有多种表达方式。其中一种常见的是正弦-余弦位置编码(sinusoidal Position Encoding)
PEpos,2i=sin(pos/100002i/dmodelPE_{pos,2i} = sin(pos/10000^{2i/d_{model}}PEpos,2i=sin(pos/100002i/dmodel
PEpos,2i+1=cos(pos/100002i/dmodelPE_{pos,2i+1} = cos(pos/10000^{2i/d_{model}}PEpos,2i+1=cos(pos/100002i/dmodel
单词Embedding(TE):Token Embedding可以采用Word2Vec,Glove等算法训练得到,也可以在Transformer中训练得到。
位置Embedding(PE):因为Transformer有全局视野,位置也是要考虑的,PE的维度与单词Embedding也是一样的。

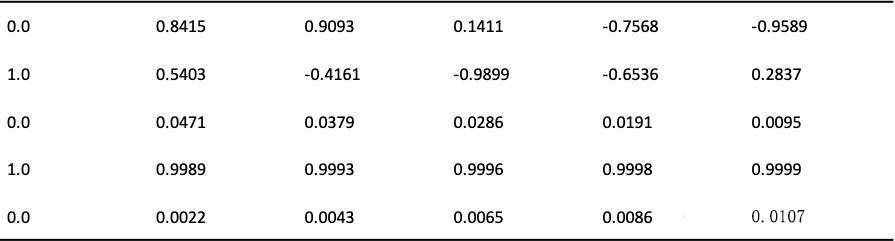
假设d_model=5,即token的embedding的维度是5;token的个数是6。使用正弦-余弦位置编码 结果如下:
流程说明
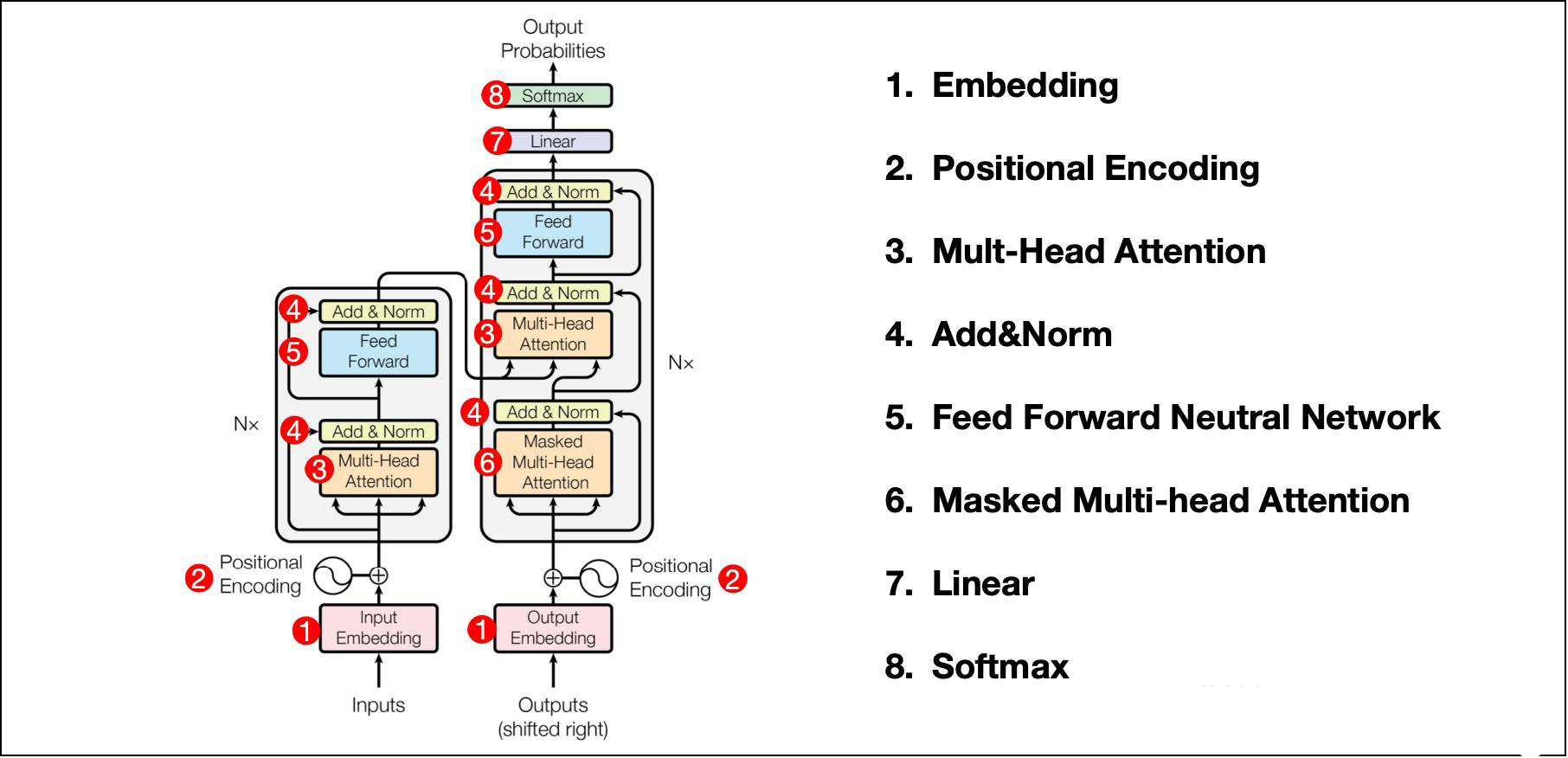
Transformer架构图是分左右两列的,左边的叫Encoder,右边的叫Decoder,数据流分布都是从下到上,每个Encoder/Decoder Block都可以是多层堆叠的,甚至可以选择同时实现两者或其中之一。
Encoder部分的输入是一次性输入的,即模型瞬间就看到了所有的输入,并同时并行计算完成了。随后,Encoder最后的输出也会分别进入Decoder的每一层。
Decoder部分和Encoder类似,但它是自回归模型,它的输入就是它的输出,你可能好奇,那第一个字符是啥?--当然是空的了,是个空的TokenS(输出是来源自然来自Encoder部分的输入),你得等Decoder的第一个字符输出了,才能灌回Decoder的输入,可以看到Transformer框架图里的Decoder输入注释成(shifted right),非常形象。
Decoder的输出其实就是基于Encoder的输入,和它每一个token的输出共同决定的,也就是要一个token一个token的输出。
什么是自回归模型? 目前使用的哪些模型是自回归模型
Transformer的decoder部分是自回归,会将输出逐个的作为decoder的输入返回给Transformer,它是不需要考虑Tokenization的(严谨吧?)。
自回归模型指利用历史已知序列预测下一时刻内容,单向生成、屏蔽未来信息;
代表模型包括:LSTM/GRU、GPT 全系、Llama 等 Decoder-only 大模型,以及 Transformer 解码器;
而 BERT、Transformer 编码器为双向非自回归模型。参考:
https://www.zhihu.com/question/596771388/answer/119375053579
https://cloud.tencent.com/developer/article/2400095