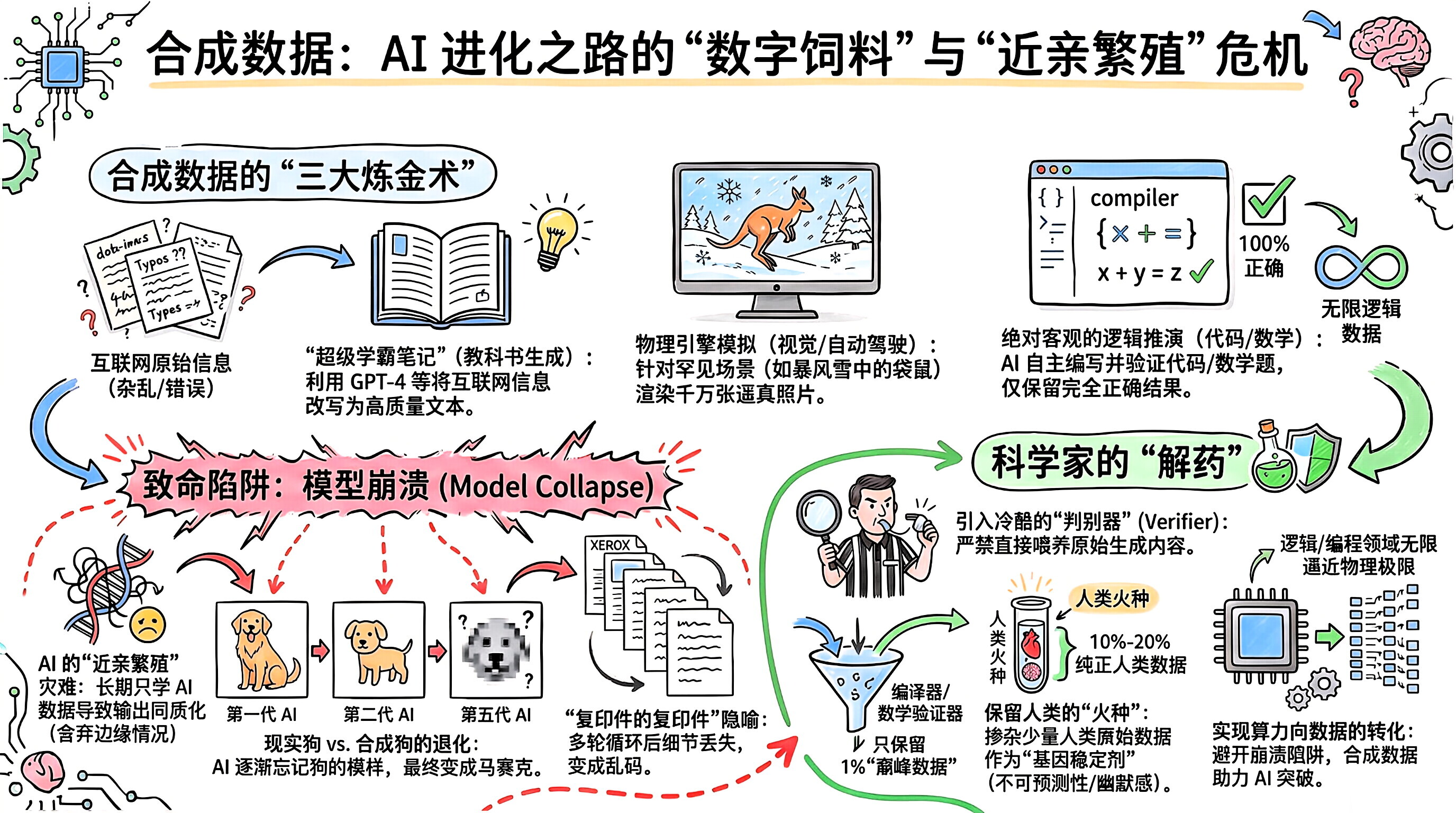
合成数据 ( Synthetic Data ) 是 AI 时代的**"人造人造肉"** 或者**"实验室大棚蔬菜"** 。
如果说过去十几年,训练 AI 用的是从互联网大自然里"野生采摘"的数据(人类写的文章、拍的照片); 那么现在,为了应对我们上一条聊过的"数据墙危机",科学家们开始让 AI 自己生成极其海量的、专门用来训练下一代 AI 的数据。
这既是 AI 突破智力天花板的最后一张底牌,也是一个极具风险的疯狂实验。
1.🧪 什么是"高质量的"合成数据?
并不是随便让 ChatGPT 写两篇水文就能拿去当训练数据的。真正能让模型变聪明的合成数据,通常有极高的门槛。
目前业界制造合成数据,主要有三大流派:
-
"超级学霸笔记" (Textbook Generation):
-
直接去网上抓取的维基百科或论坛帖子,里面经常有错别字、逻辑断层或毫无意义的争吵。
-
科学家会让目前最聪明的模型(如 GPT-4),把这些杂乱的知识重新改写成极其详尽、毫无废话、循序渐进的"教科书级别"文本。然后把这些"提纯后的浓缩营养丸"喂给小模型吃。
-
-
物理引擎 模拟 (Simulation for Vision/Robotics):
-
自动驾驶公司(如特斯拉)很难在现实中收集到"汽车在暴风雪天遇到一只横穿马路的袋鼠"这种罕见数据。
-
于是,他们用类似于《GTA 5》或虚幻引擎 (Unreal Engine) 的 3D 游戏引擎,直接无中生有地渲染出几千万张极其逼真的合成照片来训练视觉 AI。
-
-
绝对客观的逻辑推演 (Math/Code Verification):
- 这是目前最核心的手段。让 AI 自己写几万道数学题和代码,然后扔进编译器里运行。跑通了的,就是 100% 正确的合成数据;报错的直接扔掉。这样就凭空创造出了无限的高质量逻辑训练集。
2.💀 致命陷阱:模型崩溃 (Model Collapse)
如果合成数据这么好用,那我们是不是只要让 AI 不停地自己生成数据、自己训练自己,就能实现无限进化了?
绝对不行。 2023 年,牛津大学和剑桥大学的科学家联合发布了一篇震动 AI 界的论文,提出了一个名为 "模型崩溃 (Model Collapse)" 的赛博绝症。
这个现象可以简单概括为**"AI 的近亲繁殖灾难"** :
-
第一代 AI (吃人类数据长大) :能画出极其生动、多姿多彩的狗,有的长毛、有的短毛、有在跑的、有在睡觉的。(保留了人类数据的多样性和边缘情况)。
-
第二代 AI (吃第一代 AI 画的狗长大):它发现第一代画的狗大多数都是金毛,于是它为了省事,生成的狗几乎全变成了金毛。
-
第五代 AI (吃前几代 AI 的数据长大):经过几轮"近亲繁殖",模型彻底忘记了真实世界的狗长什么样。它生成的图片变成了一堆模糊的色块,或者不断重复毫无意义的乱码。
隐喻:这就像是你用手机拍下一张照片,然后打印出来;接着再用手机拍这张打印的照片,再打印......重复 10 次之后,照片上的细节将彻底丢失,变成一团马赛克。
3.🛡️ 科学家的解药:如何打破魔咒?
为了防止"近亲繁殖"导致的智力退化,顶尖 AI 实验室(如 OpenAI、Google、DeepMind)摸索出了一套极其严格的防线:
-
引入"判别器" (Verifier) :绝对不能把大模型生成的文本直接喂给下一代。正如我们在 自我蒸馏 (Self-Distillation) 里提到的,必须有一个冷酷无情的"裁判"(比如代码编译器、数学验证器),把 AI 生成的平庸内容全部杀掉,只保留那 1% 极其惊艳的巅峰数据。
-
保留人类的火种 :科学家发现,即使大规模使用合成数据,训练集里也必须掺杂哪怕 10% 到 20% 纯正的人类原始高质量数据。人类的不可预测性、幽默感和偶尔的疯狂,是防止 AI 陷入死板逻辑循环的"基因稳定剂"。
总结
合成数据 ( Synthetic Data ) 是 AI 摆脱人类"喂饭"依赖、实现算力向数据转化的伟大壮举。
只要科学家能够小心翼翼地避开"模型崩溃"的陷阱,利用严酷的验证机制过滤出高质量的合成数据,AI 就拥有了在逻辑、数学和编程领域无限逼近物理极限的门票。