note
- 基于Qwen3-VL-32B-Thinking做的面向数学、物理、化学、天文、地理、生物六大学科的科学多模态推理模型,主要特点是Python 沙箱执行图像裁剪、缩放、标注等代码,多轮迭代推理
- 数据源整合【开源轨迹Thyme/V-Thinker+内部高分辨率图表/几何推理数据,Thyme(hinkBeyondImages,让模型自己写Python代码裁剪、放大、旋转、调对比度、做计算,在沙箱里执行,再继续推理,开源了大量代码驱动的图像交互轨迹)/V-Thinker(Interactive Thinking with Images,通过裁剪、画辅助线、标注关键点等交互,一步步看图推理,开源了V-Interaction-400K等高质量视觉交互数据集,专门教模型"边画边想")
文章目录
一、S1-VL多模态推理
【多模态推理大模型进展】基于Qwen3-VL-32B-Thinking做的面向数学、物理、化学、天文、地理、生物六大学科的科学多模态推理模型,主要特点是Python 沙箱执行图像裁剪、缩放、标注等代码,多轮迭代推理。S1-VL: Scientific Multimodal Reasoning Model with Thinking-with-Images,https://arxiv.org/pdf/2604.21409,https://huggingface.co/ScienceOne-AI,https://modelscope.cn/organization/ScienceOne-AI。
1)科学推理数据构造方式:
step1.种子数据采集【覆盖数/理/化/天文/地理/生物六学科,融合开源数据集、教科书、竞赛题】
->
step2.初始模型训练【在种子数据上初步训练】
->
step3.推理轨迹自蒸馏【生成完整思维链推理轨迹,混合通用多模态数据,得到68.5万SFT数据】
->
step4.课程难度分层【10次采样pass_rate<0.4为困难样本,构建20KRL数据、60K课程学习SFT数据】
->
step5.多维度轨迹过滤【剔除无意义token、重复短语、格式异常、数值重复、格式不合规、语义冗余样本】。
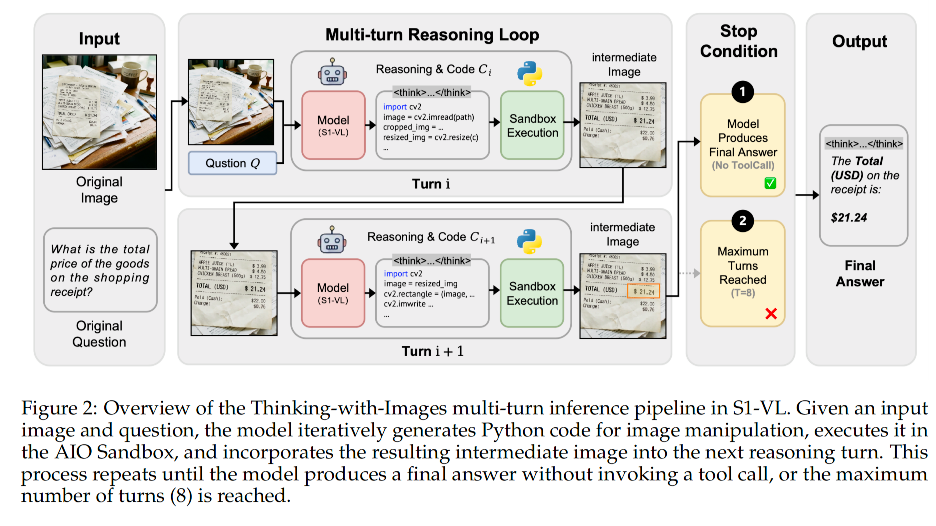
2)以图思辨数据:
step1.数据源整合【开源轨迹Thyme/V-Thinker+内部高分辨率图表/几何推理数据,Thyme(hinkBeyondImages,让模型自己写Python代码裁剪、放大、旋转、调对比度、做计算,在沙箱里执行,再继续推理,开源了大量代码驱动的图像交互轨迹)/V-Thinker(Interactive Thinking with Images,通过裁剪、画辅助线、标注关键点等交互,一步步看图推理,开源了V-Interaction-400K等高质量视觉交互数据集,专门教模型"边画边想"),都是专门做边看图片、边写Python代码操作图片、边推理的思考模型】
->
step2.结构化适配【统一为多轮对话、标准思维链+工具调用格式】
->
step3.六维度质量过滤【格式合规→推理答案一致→中间图像有效→图文语义对齐→关键信息完整→跨回合无冗余】
->
step4.自适应数据路由【视觉信息增益低的样本转为纯科学推理数据,避免无意义图像操作】
->
step5.滚动采样与下采样【每个样本16次滚动,剔除全错样本,下采样得到10KRL数据】->step6.最终数据产出【72K以图思辨SFT数据、10K以图思辨RL数据】;
3)训练过程。基座模型使用Qwen3-VL-32B-Thinking,分别做68.5K科学推理SFT数据微调、60K科学难题正确轨迹+72K以图思辨SFT数据微调、20K科学困难RL样本SAPO强化学习。