去年底第一次接触 Claude Code 时,我只是把它当成一个 "能在终端写代码的工具"。直到某次深夜调试一个 500 行的接口报错,我看着它自动读文件、定位问题、修改代码、跑测试,全程没让我敲一行命令,甚至连文件路径都没问我要,那种震撼感让我意识到:这不是简单的代码生成器,而是一套真正在 "思考" 的智能体系统。
后来我花了几周时间,对着日志和源码,把它从输入需求到代码落地的每一步都拆解了一遍。今天这篇文章,就用我踩过的坑和调试的细节,带你看懂 Claude Code 背后的 Agent Loop,以及它为什么能在复杂项目里稳定跑起来。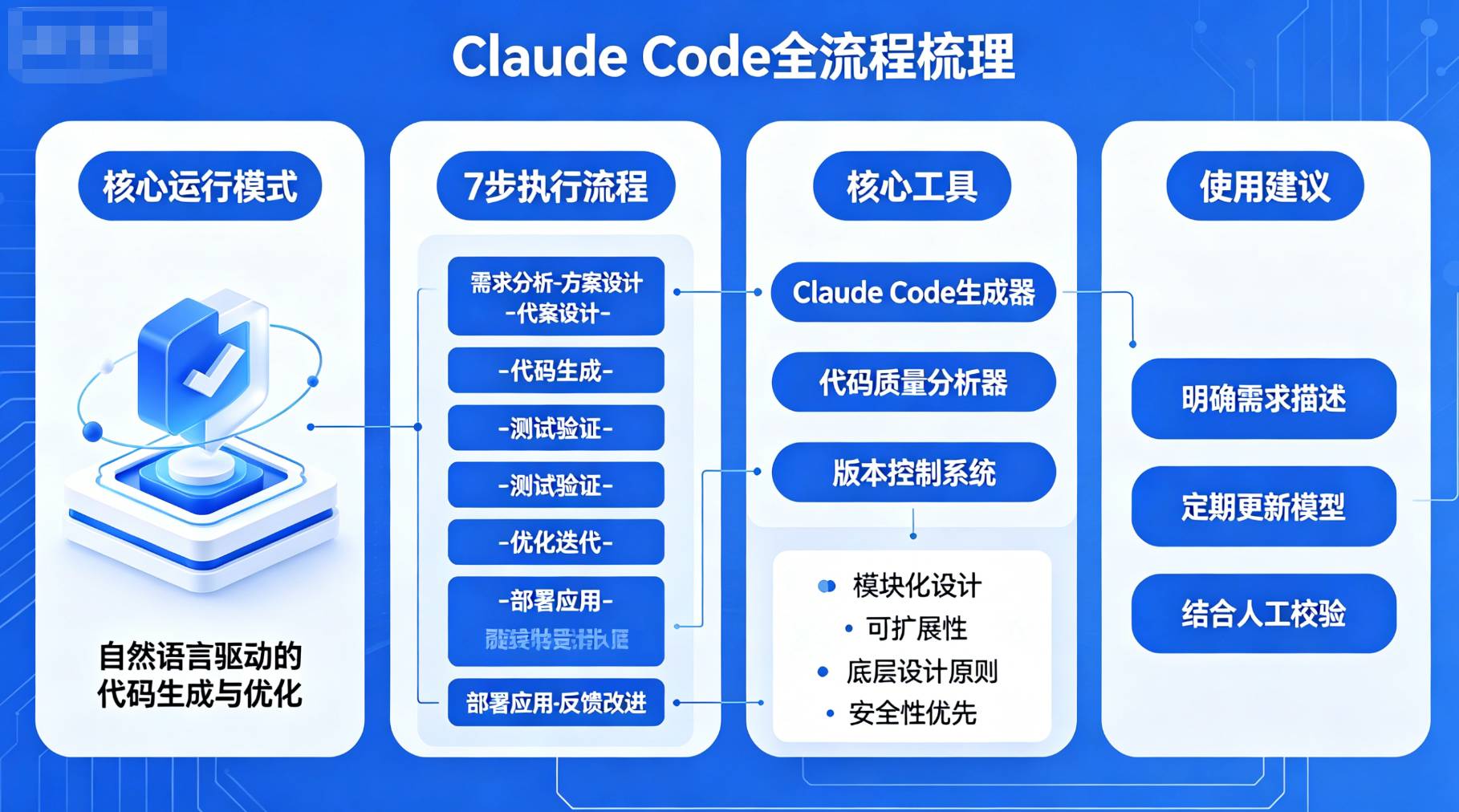
一、Claude Code 的核心运行模式
Claude Code 提供了三级权限控制模式,平衡开发效率与安全边界,这也是它能适配从本地开发到生产环境等不同场景的关键:
ask模式:默认模式,每一步工具调用都需要用户手动确认,适合初次使用或敏感项目;auto模式:带有服务端安全审查,高危操作会自动回退到手动确认,兼顾效率与安全;bypass模式:权限绕过模式,除了.git/、.claude/等受保护路径外,所有文件读写、命令执行无需用户确认直接生效,是实现"全自动编程"的基础,仅建议在本地可控项目中使用。
同时,Claude Code 支持通过 MCP(Model Control Protocol)接入外部服务,如数据库连接、云服务 API 或 IDE 插件,突破本地文件限制,处理更复杂的业务场景。
二、用户输入后的完整执行流程(Agent Loop)
当用户在终端输入需求并回车后,Claude Code 会启动循环执行的 Agent Loop(智能体循环),核心分为 7 个步骤,环环相扣、闭环运行,确保需求精准落地。
步骤 1:输入分流与预处理
需求输入后,首先经过本地预处理,避免无效模型调用,提升响应效率,具体分为 3 个环节:
-
命令判断:优先检查输入内容是否为「斜杠命令」(如 /help 查看帮助、/exit 退出会话、/clear 清空上下文),此类命令直接在本地处理,不发送至大模型,减少不必要的 API 调用。
-
消息标准化:若为普通需求(非斜杠命令),会将输入内容包装成统一格式的消息对象,附加时间戳、上下文 ID 等元数据,确保后续上下文拼接规范,便于模型理解。
-
权限模式检查:读取当前系统配置的权限模式(此处为 bypass 模式),明确后续工具调用的执行策略(如是否需要用户确认)。
步骤 2:上下文构建与压缩
Claude Code 会自动收集当前项目的所有相关上下文,为模型推理提供完整支撑;若上下文超出模型 Token 限制,会自动触发压缩逻辑,确保推理高效进行。
1. 上下文收集范围
-
对话历史:用户之前的提问、Claude Code 的回复记录,确保模型能衔接历史交互,避免重复操作。
-
项目文件:自动读取用户当前打开的文件、最近修改的文件,快速掌握项目实时状态。
-
项目配置:读取 package.json、tsconfig.json 等关键配置文件,理解项目技术栈、依赖关系。
-
系统环境:获取当前终端目录、操作系统信息、已安装的命令行工具,避免生成无法执行的命令。
2. 上下文压缩逻辑
-
保留核心内容:优先保留关键对话、与当前需求相关的文件片段,剔除无关信息。
-
压缩冗余信息:对重复的交互记录、非关键日志进行精简,减少 Token 占用。
-
裁剪长文件:对超过一定长度的文件,自动裁剪为与需求相关的核心代码片段,避免上下文过载。
步骤 3:系统提示词 + 用户需求组装(核心环节)
这是 Claude Code 实现精准推理的核心步骤,会将工具内置的「系统规则」与用户输入的「具体需求」合并,组装成完整的 API 请求 Prompt,传递给大模型。其中,系统提示词是 Claude Code 的「行为准则」,结构固定,分为 7 个核心模块,具体如下表所示:
| 模块 | 核心内容 | 作用 |
|---|---|---|
| 身份锚定 | 定义角色:You are Claude Code, an expert AI coding assistant | 消除歧义,明确模型的定位的是 AI 编程助手,避免偏离任务方向 |
| 任务边界 | 明确禁止行为:不编造不存在的文件、不添加额外功能 | 防止模型产生幻觉(如虚构文件)、过度修改代码,确保操作贴合需求 |
| 工具定义 | 列出所有可用工具(Read/Edit/Bash/AskUserQuestion 等),明确每个工具的参数、用途、限制 | 让模型清楚"能调用什么工具""如何调用工具",确保工具调用规范 |
| 编码规范 | 代码风格要求:三行原则、最小修改、不引入安全漏洞 | 保证生成代码的质量和一致性,避免引入新的 Bug |
| 权限规则 | 说明当前权限模式(此处为 bypass,即无需确认直接执行) | 指导模型的工具调用策略,避免出现权限不符的操作 |
| 输出格式 | 规定回复格式:工具调用用特定标签包裹、自然语言回复清晰分点 | 确保模型输出的内容可被 Claude Code 解析,实现工具调用的自动化 |
| 错误处理 | 失败重试规则:if an approach fails, diagnose why before retrying | 避免模型盲目重试无效操作,提升任务执行成功率 |
以下是简化版的系统提示词示例,可直观理解其结构:
text
You are Claude Code, an expert AI coding assistant.
Your task is to help the user complete coding tasks using the available tools.
Rules:
1. Always read files before editing them.
2. Do not modify code you haven't read.
3. Use the Read tool to explore the codebase when you don't understand something.
4. Use the Bash tool to run tests or commands only when necessary.
Available Tools:
- Read(file_path: string): Read the content of a file.
- Edit(file_path: string, content: string): Edit a file with new content.
- Bash(command: string): Run a bash command in the current directory.
Permission Mode: bypassPermissions (no user confirmation required for tool calls).
Output Format:
- When you need to use a tool, wrap the call in <tool_call> tags.
- Explain your reasoning clearly before taking action.步骤 4:模型推理与决策(需求拆解)
大模型收到完整的 Prompt 后,会对用户需求进行结构化拆解,形成可执行的操作步骤,核心分为 4 个层次,确保需求落地的精准性:
-
意图识别:首先判断用户需求的类型,明确核心目标,常见类型包括代码修改、Bug 调试、代码重构、功能解释、创建文件等。示例:用户输入"帮我修复登录接口的报错",模型会识别为「调试 + 代码修改」类需求。
-
依赖分析:梳理完成需求所需的前置信息和核心步骤,明确任务依赖。示例:修复登录接口报错,需分析依赖的文件(routes/login.ts、services/auth.ts、db/user.ts),以及报错可能的原因(数据库连接异常、参数校验缺失、权限配置错误等)。
-
子任务拆解:将用户的大需求拆分为多个可执行的小步骤,每个步骤对应一个工具调用,确保操作可落地。示例:修复登录接口报错的子任务拆分:
-
子任务 1:读取登录接口文件(调用 Read 工具);
-
子任务 2:读取数据库配置文件(调用 Read 工具);
-
子任务 3:运行接口测试,复现报错(调用 Bash 工具);
-
子任务 4:修改代码修复报错(调用 Edit 工具);
-
子任务 5:再次运行测试,验证修复效果(调用 Bash 工具)。
-
-
工具选择:为每个子任务匹配合适的工具,遵循"按需调用"原则:读文件用 Read 工具,修改文件用 Edit 工具,运行终端命令用 Bash 工具,遇到不确定的信息(如文件路径、需求细节)时,用 AskUserQuestion 工具向用户提问确认。
步骤 5:工具调用与权限校验
模型输出工具调用指令后,Claude Code 不会直接执行,而是先进行严格的权限校验,确保操作安全,再执行工具,最后将结果回传,具体分为 3 个环节:
-
权限检查(核心安全保障):
-
先检查 deny 规则(用户自定义的禁止操作列表),如禁止 rm -rf /、sudo 等高危命令,命中规则则直接拒绝执行;
-
再检查系统保护路径(.git/、.claude/ 等),即使是 bypass 模式,也会拦截对这些路径的操作,避免误删系统文件;
-
当前为 bypass 模式,经过上述校验后,大部分操作无需用户确认,直接执行。
-
-
工具执行:根据工具类型,执行对应操作,生成操作结果:
-
执行 Read 工具:读取目标文件的内容,将内容返回给大模型,为后续推理提供依据;
-
执行 Edit 工具:按照模型指令修改文件内容,生成 Diff 变更记录(清晰展示修改前后的差异);
-
执行 Bash 工具:运行终端命令,捕获命令的输出结果和错误日志,回传给模型。
-
-
结果回传:将工具执行的结果(成功/失败/输出内容)包装成新的消息,注入到对话历史中,作为下一轮模型推理的上下文,继续推进 Agent 循环。
步骤 6:循环迭代(Agent Loop)
Claude Code 会重复「模型决策 → 工具调用 → 结果回传」的循环流程,直至满足以下任一条件,循环终止:
-
需求完全完成,模型判断无需再调用任何工具;
-
遇到无法解决的问题(如缺失关键信息、权限不足),主动通过 AskUserQuestion 工具向用户提问,获取必要信息;
-
超过系统设定的最大循环次数,主动终止循环,并向用户说明当前进度和未完成原因。
步骤 7:生成最终回复
当模型判断需求完成、循环终止后,会生成清晰的自然语言回复,向用户反馈操作结果,核心包含 3 部分内容:
-
操作变更:详细说明修改了哪些文件、具体修改内容,附上 Diff 变更说明,让用户清晰了解操作细节;
-
验证结果:说明是否运行了测试、功能是否正常、报错是否修复,确保操作有效;
-
后续建议:给出针对性建议,如提交代码、补充文档、进行边界测试等,帮助用户完善后续操作。
三、Claude Code 核心工具与技能体系
Claude Code 的所有功能均依赖其内置的工具和技能(Skill),工具按功能分类,覆盖开发全场景,常见工具如下表所示,可根据需求灵活调用:
| 工具类型 | 核心工具 | 用途 |
|---|---|---|
| 读操作 | Read / Grep / Find | 读取文件内容、搜索关键词、查找目标文件,获取项目上下文信息 |
| 写操作 | Edit / Write / Rename / Delete | 修改文件内容、创建新文件、重命名文件、删除文件,实现代码变更 |
| 命令执行 | Bash / BackgroundBash | 运行终端命令、后台执行长时间任务(如测试、依赖安装) |
| 项目管理 | GitStatus / GitDiff / GitCommit | 查看 Git 仓库状态、查看代码变更差异、提交代码,适配版本管理需求 |
| 交互工具 | AskUserQuestion / Confirm | 向用户提问获取关键信息、请求用户确认操作,确保需求理解准确 |
| 扩展工具 | MCP(Model Control Protocol) | 调用外部服务(如数据库、第三方 API、IDE 插件),扩展工具能力边界 |
补充说明:若界面显示"1 MCPs",说明当前实例已配置 1 个外部扩展工具,可实现更复杂的业务场景(如直接连接数据库、调用云服务 API 等)。
四、关键细节:Claude Code 稳定完成复杂任务的核心原因
与普通代码生成工具相比,Claude Code 能稳定处理复杂工程任务,核心在于其4个底层设计原则,从根源上提升操作的准确性和安全性:
-
「先读再改」的强制规则:系统提示词明确要求"Do not modify code you haven't read",强制模型先通过 Read 工具读取相关文件、理解上下文后,再进行修改操作,从根本上避免模型"瞎改代码""凭空修改"的问题,降低引入新 Bug 的概率。
-
科学的错误诊断机制:当工具调用失败(如命令报错、文件不存在、权限不足)时,模型不会盲目重试,而是先分析错误原因,针对性调整策略(如修正文件路径、安装缺失依赖),再进行下一次尝试,避免无效循环,提升任务成功率。
-
最小修改原则:系统提示词明确要求"Don't add features or refactor beyond what was asked",模型仅修改与用户需求相关的代码,不添加额外功能、不进行不必要的代码重构,减少对原有项目的侵入性,降低后续维护成本。
-
灵活的权限分级:通过 ask/auto/bypass 三种权限模式,让用户可根据使用场景灵活选择,平衡操作效率与安全:ask 模式保障安全,auto 模式兼顾效率与安全,bypass 模式提升本地开发效率,适配不同开发场景的需求。
五、实用使用建议(结合 bypass 模式)
针对当前使用的 bypass 模式,结合实际开发场景,给出 3 条实用建议,帮助高效、安全地使用 Claude Code:
-
严格控制 bypass 模式的使用场景:bypass 模式效率极高,但仅建议在本地开发、完全可控的项目中开启,切勿在生产环境、多人协作项目中使用,避免因模型误操作导致不可逆的损失(如误删核心文件、修改公共配置)。
-
配置自定义安全规则:在项目根目录创建 .claude/settings.json 文件,配置 deny 规则,禁止高危操作,为 bypass 模式添加安全兜底,示例配置如下:
{
"permissions": {
"defaultMode": "bypassPermissions",
"deny": ["bash(rm*)", "bash(sudo*)", "read(.env*)"]
}
}
上述配置可禁止执行 rm 开头的删除命令、sudo 高危命令,以及读取 .env 敏感配置文件,避免泄露密钥或误删文件。
- 创建项目规范文件:在项目根目录创建 CLAUDE.md 文件,写入项目的编码规范、架构说明、常见问题等内容,Claude Code 会自动读取并遵守这些规则,生成的代码会更贴合项目风格,减少后续代码调整的工作量。
六、结语
Claude Code 之所以能成为终端 AI 编程助手的标杆,核心不在于它调用了多强的大模型,而在于它构建了一套严谨、高效、可落地的 Agent 执行逻辑。从上下文构建到提示词组装,从需求拆解到工具调用,再到循环迭代和安全兜底,每一步都有明确的规则约束和目标导向,让大模型的能力真正落地到工程开发场景中。
对开发者来说,理解它的执行逻辑,不仅能帮你更高效地使用 Claude Code,更能让你看懂 AI 编程助手的底层设计思路,为后续使用其他 Agent 工具打下基础。毕竟,只有看懂了"黑盒"里的运转逻辑,才能真正驾驭这个工具,让它成为你开发路上的得力助手。