前提
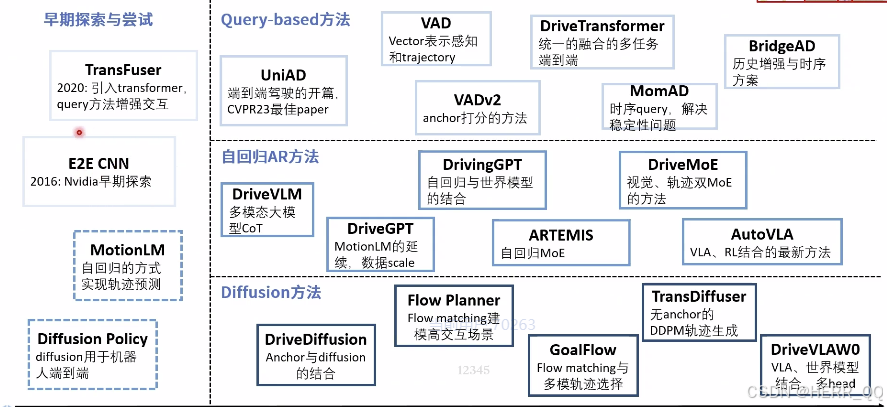
- 重点需要关注的方法
简介
-
encoder 给到BEV特征 decoder去解码
-
设计思路
-
具体方法
-
训练目标是什么
-
和传统规划控制的对比
-
技术路线: 端到端plan query based 回归 多模轨迹困难, 打分 用anchor 先验,天生就是多模 只一个分类打分问题
-
自回归 一步一步 也可以多模态
-
diffusion 给噪声 然后学习去噪解码
-
老师的总结

AI解读
- 回归的方式(Regression)
原理:类似于"填空"。模型(通常是 MLP)接收场景特征和"自车 Query",直接输出一条轨迹坐标。
优点:架构简单,与感知模块(如 DETR)统一,灵活性强。
致命缺点:难以输出多模态轨迹。因为 MLP 通常只能输出一个确定的结果,很难同时生成"左转"和"右转"两条路径。 - 打分的方式(Score-based / Anchor-based)
原理:引入了 Vocabulary(词表/Anchor) 概念。先有一组预定义的轨迹模板(Anchors),模型负责给这些模板打分(Scoring),最后选分数最高的。
优点:
天然多模:可以通过设计不同的 Anchors 来覆盖多种驾驶模式。
学习稳定:因为有先验的 Anchors 引导,模型不需要从零开始"画"轨迹,学习难度降低,收敛更快。
端到端规划 Query based 方案
- 本质是轨迹的decoder 重点关注 qkv如何设计 如何交互
- 不同的范式
代表: b uniad c bevformer d drivetransformer pert maptr
自车状态 导航信息 都可以作为 Q
老师列出的不同的设计思路
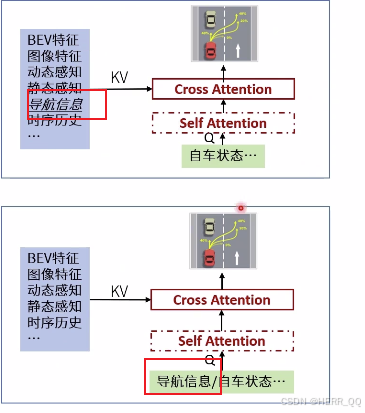
辅助任务是什么
在端到端(End-to-End)自动驾驶架构中,"辅助任务"指的是除了最终规划/控制输出之外,模型额外计算并用于辅助训练的中间监督信号。你提到的"BEV 直出规划,没有其他辅助 Task"属于**纯端到端(Pure E2E)**范式,它追求极简但面临独特的挑战。
一、什么是辅助任务?
在端到端模型中,辅助任务并非最终输出,而是训练阶段的"拐杖",用于约束中间特征的学习。常见形式包括:
- 几何/感知类:BEV 特征图上的语义分割、3D 检测、深度估计、光流预测。
- 解释性类:可驾驶区域分割、车道线检测、占用预测。
- 物理类:速度/加速度预测、轨迹预测。
关键区别:在推理(Inference)时,这些任务会被丢弃,只有规划/控制头(Planning Head)的输出被用于控制车辆。它们存在的意义是让训练更稳定。
二、"BEV 直出规划,无辅助 Task"的含义
你描述的这种范式,即输入传感器数据 → BEV 空间特征提取 → 直接输出规划轨迹/控制信号(如转向、油门),且中间不计算任何分割、检测等损失 ,就是典型的无辅助任务端到端。
- 架构逻辑:模型是一个"黑箱",BEV 特征层之后直接接规划头,训练损失仅由最终的规划误差(如 L2 轨迹损失、模仿学习损失)反向传播。
- 代表案例:类似 NVIDIA 的早期 PilotNet 思想,或一些基于 Transformer 的纯 E2E 方法(如 UniAD 去掉所有辅助头后的简化版)。
三、无辅助任务的优缺点分析
优点(为什么有人追求它)
-
极致的简约与效率
- 省去了大量中间头的计算,参数量小,推理速度通常更快。
- 工程栈极简,无需维护复杂的多任务训练 pipeline。
-
避免归纳偏置(Inductive Bias)
- 不强制模型先"看懂"世界(分割/检测),再规划。理论上模型可以自由学习**"感知-决策"的联合表示**,可能发现人类未定义的抽象特征。
-
减少误差累积
- 传统流水线中,检测框的轻微抖动会导致规划剧烈震荡。纯 E2E 直接从像素映射到控制,理论上能平滑这种噪声。
缺点(为什么通常要加辅助任务)
-
训练极不稳定(致命伤)
- 规划信号(最终 Loss)距离输入像素太远,梯度回传路径长且稀疏,模型极易陷入局部最优或发散。
- 没有中间监督,BEV 特征可能学不到对物理世界(如障碍物轮廓、道路结构)的清晰表征。
-
可解释性差(Debug 地狱)
- 车辆出现急刹或画龙,你无法通过查看"检测框"或"分割图"来定位是感知错了还是决策错了,只能对着黑箱干瞪眼。
-
数据效率低
- 需要海量的高质量规划标签(人类驾驶轨迹)才能收敛。相比之下,分割/检测标签更容易大规模获取(半自动标注)。
-
长尾风险高
- 对于罕见场景(如路上有气球),没有显式的物体概念,模型可能无法像"检测+规则"系统那样保守处理。
四、业界折衷实践
目前主流方案(如 Tesla 的 HydraNet、Wayve 等)并非完全放弃辅助任务,而是采用**"训练时多任务,推理时单任务"**的策略:
- 训练:BEV + 分割(辅助) + 检测(辅助) + 规划(主输出)。
- 推理:只保留 BEV → 规划,丢弃分割和检测头。
这既利用了辅助任务的训练稳定性 ,又保留了端到端的推理效率。
UniAD
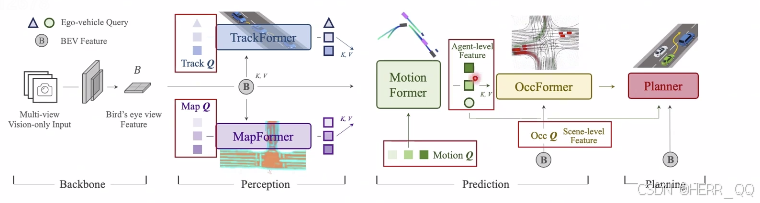
-都是从BEV feature 里面拿到 track Q 动态障碍物感知, mapQ 静态, motion 预测物体运动 以及 occ ,都拿到之后做一个planner
-backbone 是从图像拿bev 特征 类似bevformer
-trackformer 和sparse4D PETR比较像 工业界用后两者比较多
-mapformer 不需要关注节 maptr是主流 
-motionformer
把前序的动静态感知结果作为kv

是 Q
目标是预测物体运动轨迹
- occ former
做了动态静态occ的感知 - planner
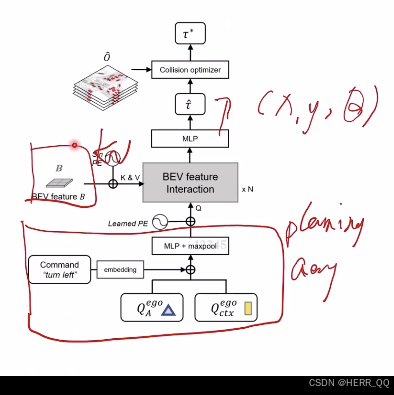
kv 是bev的feature
q 是导航ego信息
occ 优化碰撞

以下是对该 Planner 模块的详细拆解:
- 规划查询的构建
在 Planner 中,首先需要构建一个名为 Planning Query(规划查询) 的输入条件,它由两部分融合而成:
- 先验特征 :结合了
TrackFormer(目标跟踪)和MotionFormer(轨迹预测)输出的 Ego Query。这相当于让自车携带了当前对全局环境的感知与多模态意图信息。 - 导航指令:将具体的驾驶意图(如左转、直行、右转)编码为可学习的嵌入向量(Command encoding)。
- 这两部分通过 MLP 和多层感知机结合,加上位置编码,形成了最终指导自车运动的"规划查询"。
- 特征交互与轨迹解码
构建好的规划查询会与全局的 BEV 特征图 进行深度的注意力交互(BEV feature Interaction)。
- 作用:这使得规划查询能够"看清"周围的道路结构、车道线以及其他动态障碍物。
- 输出 :经过多层 Transformer 解码器(×N)的交互后,模型会初步解码出一个未来的轨迹点序列 τ ^ \hat{\tau} τ^(即图中手写标注的 x , y , θ x, y, \theta x,y,θ)。
- 碰撞优化与损失函数
这是该模块最核心的安全保障环节。为了防止神经网络直接输出的轨迹导致车辆发生碰撞,UniAD 引入了一个显式的后处理优化层:
- 占用图输入 :引入了
OccFormer(占用预测模块)预测的未来时空占用栅格图 O ^ \hat{O} O^,它代表了未来哪些区域可能被障碍物占据。 - 优化目标 :通过最小化一个带有约束的代价函数 f f f,对初步轨迹 τ ^ \hat{\tau} τ^ 进行微调,得到最终的安全轨迹 τ ∗ \tau^* τ∗:
f ( τ t , τ ^ , O ^ ) = λ c o n ∣ ∣ τ t − τ ^ ∣ ∣ 2 + λ o b s ∑ t D ( τ t , O ^ t ) f(\tau_t, \hat{\tau}, \hat{O}) = \lambda_{con}||\tau_t - \hat{\tau}||2 + \lambda{obs}\sum_{t} D(\tau_t, \hat{O}^t) f(τt,τ^,O^)=λcon∣∣τt−τ^∣∣2+λobst∑D(τt,O^t) - 两项约束的物理意义 :
- 轨迹一致性项 ( ∣ ∣ τ t − τ ^ ∣ ∣ 2 ||\tau_t - \hat{\tau}||_2 ∣∣τt−τ^∣∣2) :这一项对应手写标注的 λ c o n \lambda_{con} λcon。它要求优化后的轨迹 τ t \tau_t τt 不能偏离神经网络初步预测的轨迹 τ ^ \hat{\tau} τ^ 太远,保证了车辆行驶的平顺性和惯性。
- 碰撞避免项 ( D ( τ t , O ^ t ) D(\tau_t, \hat{O}^t) D(τt,O^t)) :这一项对应手写标注的 λ o b s \lambda_{obs} λobs。它计算轨迹点 τ t \tau_t τt 与占用区域 O ^ t \hat{O}^t O^t 之间的代价(通常基于高斯分布的距离惩罚),强制规划的轨迹必须远离任何可能被占用的网格区域。
- 问 Query是怎么得到的
。
在 UniAD 的 Planner 模块中,这个最终的 Planning Query(规划查询) 是整个端到端系统的"大脑指令"。它不是凭空生成的,而是通过**融合"对环境的感知记忆"和"人类的驾驶意图"**精心构建的。
以下是结合架构图和 UniAD 底层逻辑的详细拆解:
- 组成部分一:Ego Query 及其先验特征
这部分代表了模型"看到了什么"以及"学到了什么交互规律"。
- 来源 :在 UniAD 的整体架构中,首先通过
TrackFormer提取了代表周围车辆、行人等的 Agent Queries,以及代表自车的 Ego Query。 - 交互与演进 :随后,
MotionFormer登场,让自车的 Ego Query 与周围的 Agent Queries、Map Queries 以及 BEV 特征图进行了深度的交叉注意力(Cross-Attention)交互。 - 输出特征 :经过这一系列的"交流",Ego Query 不再只是一个孤立的向量,而是变成了一个富含上下文信息的特征向量(即图中手写标注的 Q c t x e g o Q_{ctx}^{ego} Qctxego 或 Q A e g o Q_A^{ego} QAego),它隐式地包含了自车当前的状态以及与周围环境的交互历史。
- 组成部分二:导航指令编码
这部分代表了人类驾驶员输入的"主观意愿"。
- 来源:在实际的自动驾驶系统中,必须有明确的导航信号(如左转、直行、右转)来指导车辆。
- 处理 :UniAD 将这些离散的驾驶命令转换为机器可理解的连续向量,即图中的 Command encoding。具体来说,是将"左转"、"直行"、"右转"这三个选项分别映射为三个不同的可学习嵌入向量(Learned embeddings),并根据当前实际接收到的导航指令选取对应的向量。
- 融合过程:如何得到最终的 Planning Query
将上述两部分结合,就得到了图左下角红框内的融合公式:
Planning Query = MLP ( maxpool ( Q c t x e g o + Command encoding ) ) + Positional Encoding \text{Planning Query} = \text{MLP} \Big( \text{maxpool}(Q_{ctx}^{ego} + \text{Command encoding}) \Big) + \text{Positional Encoding} Planning Query=MLP(maxpool(Qctxego+Command encoding))+Positional Encoding
具体步骤如下:
- 特征相加 :将代表客观环境的上下文特征 Q c t x e g o Q_{ctx}^{ego} Qctxego 与代表主观意图的导航指令编码
Command encoding进行逐元素相加。这一步非常巧妙,相当于让自车"带着特定的目的地"去审视当前路况。 - 通道压缩 :相加后的特征维度较高,通过
maxpool(最大池化)操作对其进行降维和特征筛选,保留最显著的交互特征。 - 维度变换:将池化后的特征输入到一个 MLP(多层感知机)中,进一步调整向量的维度,使其适配后续 Transformer 解码层的标准输入要求。
- 注入位置信息 :最后,加上 Positional Encoding(位置编码)。因为纯粹的 Transformer 结构本身不具备感知顺序的能力,加入位置编码是为了让 Planner 明确自车在当前 BEV 空间中的绝对坐标和朝向,确保规划出的轨迹是符合物理空间的。
随后,它会被送入右侧的 BEV Feature Interaction 模块,与全局的 BEV 特征图进行深度交互,从而精准解码出未来的轨迹点序列。
VAD 12
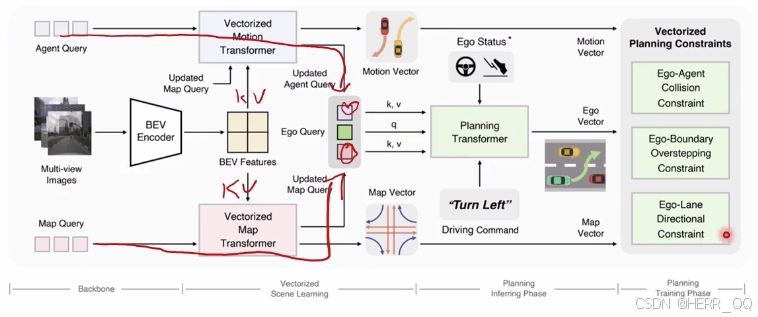
ego的query 与动态静态障碍物的kv去做交互
一、 Ego Query(自车查询机制)
在 VAD 模型中,自车同样被抽象为一个特殊的 Query。为了应对复杂的驾驶环境,模型设计了两套并行的特征交互机制来让自车了解周围情况:
- 动态交互(感知其他参与者):自车 Query 会与周围其他动态交通参与者(Agent)的 Query 进行交叉注意力(cross-attn)交互。这样自车就能"感知"到其他车辆的相对位置和运动状态,获取动态环境信息。
- 静态交互(感知道路环境):自车 Query 会与地图元素(Map)的 Query 进行交叉注意力交互。这样自车就能"感知"到车道线、道路边界等静态环境信息。
- 轨迹解码(Head) :在完成上述信息交互后,模型会将自车 Query 提取到的特征与自车当前的状态(如速度、位置等)拼接,并输入到 MLP(多层感知机)网络中,最终解码输出自车未来的预测轨迹 V ^ e g o \hat{V}_{ego} V^ego。
二、 Constraint(环境约束)
为了让自车开得安全且不违反交通规则,模型将上述感知到的环境信息转化为了三个明确的数学约束条件:
- Agent 碰撞约束:确保自车在未来的轨迹上,与其他车辆或行人保持足够的安全距离。如果距离太近,就会产生惩罚。
- 道路边界碰撞约束:确保自车不会压线、逆行或开出马路。即计算自车预测轨迹到最近道路边界的距离,要求必须大于设定的安全距离。
- 车道方向一致性约束:确保自车的行驶方向与所在车道的走向保持一致,避免出现危险的无意义转向或压线行为。
三、 Loss(损失函数)
这是模型在训练阶段用来"指导"模型优化的指标。总的损失函数由三部分加权组成:
- 感知损失:衡量模型对动态物体(motion)和地图(map)的预测准不准。
- 模仿学习损失:衡量模型预测的自车轨迹与真实人类驾驶员的轨迹有多接近(使用 L1 loss,即绝对误差)。
- 环境约束损失:衡量模型生成的轨迹是否违反了上述的碰撞和车道方向规则。
通过将这些损失结合起来反向传播,模型就能学会在满足各种交通规则和安全约束的前提下,像人类司机一样规划出合理、安全的行驶轨迹。
v2
回归变分类 有了anchor 概率建模
这页 PPT 展示的是一种基于"离散化动作空间"的端到端自动驾驶规划模型架构(通常对应 VADv2 等相关方案)。与上一轮展示的直接回归连续轨迹的方案不同,这个方案借鉴了大语言模型中"词汇表"的概念来进行轨迹规划。
整个流程可以拆解为以下几个核心步骤:
- 动作空间的离散化与"Token"化
- 传统难题:在自动驾驶中,车辆未来的运动轨迹是一个连续的二维空间,直接去拟合和计算这种连续空间在数学上非常困难且不稳定。
- 解决方案 :为了解决这个难题,模型首先定义了一个"动作空间",并通过一个 Planning Vocabulary(规划词汇表) 将其离散化为一系列具有代表性的、典型的轨迹。
- Token化 :这些典型的轨迹被编码成了类似语言模型中的基本单位------Planning Tokens(规划令牌)。这使得模型可以用处理自然语言的方式来理解和生成驾驶动作。
- 场景信息的 Token 化编码
左下角的多视角图像序列(传感器输入)被送入场景编码器,提取出当前环境的矢量化特征,并将其转化为不同类型的 Scene Tokens(场景令牌):
- M (Map Tokens):地图令牌,代表车道线、道路边界等静态道路信息。
- A (Agent Tokens):智能体令牌,代表周围其他车辆、行人等动态交通参与者的信息。
- I (Image Tokens):图像令牌,保留原始的视觉特征细节。
- T (Traffic Element Tokens):交通元素令牌,代表红绿灯、斑马线等交通标志信息。
- Planning Transformer 的核心推理
这是整个模型的"大脑"。它将两路信息汇聚在一起进行深度交互与推理:
- 输入:环境场景 Tokens(M, A, I, T)、导航信息(Navigation Info.)以及自车当前的状态(Ego State)。
- 交互机制 :自车通过特殊的查询向量 Q Q Q 与上述所有场景 Tokens 进行注意力机制( K , V K, V K,V)交互。这使得自车能够"读懂"周围环境,并结合导航指令(如左转、直行)来评估词汇表中的每一条候选轨迹在当前环境下的合理性。
- 概率分布生成与双重约束监督
经过 Transformer 的推理,模型会输出 Predicted Action Distribution(预测的动作分布),即评估出在当前场景下,词汇表中的哪几条轨迹是最可能、最合理的选择。为了确保输出的轨迹既符合人类驾驶习惯又保证安全,模型在训练时受到了双重监督:
- 模仿学习监督(KL Divergence) :
- 模型会将预测的动作分布与海量人类真实驾驶数据(Large-Scale Driving Demonstrations)中的动作分布进行对比。
- 通过 KL 散度损失,强迫模型模仿人类优秀驾驶员在特定场景下的实际驾驶轨迹。
- 安全约束监督(Conflict Check) :
- 模型会将预测的动作分布输入到 Scene Constraints(场景约束) 模块中进行碰撞检查。
- 这会过滤掉那些会导致碰撞(如撞到其他车辆、压到道路边界)的危险候选轨迹,确保最终输出的动作分布是100%安全的。
通过这种方式,模型将复杂的连续轨迹规划问题,巧妙地转化为了一个类似"语言生成与选择"的概率问题,既保证了规划的高效性,又极大提升了驾驶的安全性和与人类驾驶习惯的一致性。
- 词表是怎么生成的
在VAD这类端到端自动驾驶模型中,"词表"并不是像自然语言那样由人类专家人工编写的,而是纯粹从海量真实的驾驶数据中自动学习并离线构建的。
这个过程可以分为以下几个核心步骤来理解:
-
收集海量的人类驾驶数据
首先,系统会收集大量真实的"Large-Scale Driving Demonstrations"(大规模驾驶演示数据),或者高质量的闭环仿真数据。这些数据包含了人类驾驶员在各种复杂路况下的真实行驶记录,特别是车辆在未来一段时间内连续的经纬度坐标和航向角变化,这些就是原始的真实轨迹数据。
-
核心步骤:最远轨迹采样
由于真实驾驶场景千变万化,人类司机会做出各种各样的操作(比如直行、左右变道、刹车、绕行等)。如果直接用所有的真实轨迹作为词表,数据量会极其庞大且存在大量冗余。因此,通常会采用一种叫做最远轨迹采样的算法来提取最具代表性的轨迹:
- 原理:这个算法的目的是让选出来的轨迹尽可能"多样化"。
- 过程:首先从所有真实轨迹中随机挑选一条作为起点;然后在剩下的轨迹中,挑选一条与已有轨迹"距离最远"(差异最大)的轨迹加入词表;接着不断重复这个过程,直到选出预设数量的轨迹(例如在VADv2中通常是4096条)。
- 目的:通过这种方式,确保最终的词表能够全面覆盖日常驾驶中可能出现的各种典型动作模式。
- 动作空间离散化
真实的车辆运动是连续的,而Transformer模型在处理离散的"Token"时效率最高。因此,需要将高维的连续动作空间离散化:
- 将选出的这几千条代表性轨迹,视为一个个独立的"动作原子"。
- 将它们编码成固定维度的向量,这就形成了架构图中的 Planning Tokens。
- 为什么这样做?(词表的核心优势)
- 自带物理常识(运动学约束):因为这些轨迹直接来源于真实人类的驾驶数据,所以它们天然符合真实车辆的运动学和动力学约束(比如方向盘不能瞬间打死,急加速后会有惯性)。这避免了模型凭空捏造出不切实际的轨迹。
- 天然的先验知识:在推理阶段,模型不需要从零开始"画"一条轨迹,而是只需要在这几千个"标准动作"中挑出当前环境下最合适的一个,这大大降低了规划和优化的难度。
简单来说,构建这个词表的过程,就像是让机器学习了成千上万个人类老司机的驾驶录像,从中提炼出了几千种最常用的"标准开车动作",并存放在一个"字典"里备用。
- 问:这有一点像是lattice采样对吗? 然后举一些实际的例子 谢谢
是的,你的直觉非常准确!在概念上,VAD 的"轨迹词表(Planning Vocabulary)"的生成过程,确实与传统的 Lattice(网格/晶格)轨迹采样有着异曲同工之妙。
为了让你更直观地理解,我们可以把这两种方法进行深度的对比,并举几个实际的驾驶例子。
一、 两者的相似之处与核心区别
| 对比维度 | 传统 Lattice 采样(基于规则的规划器) | VAD 的词表生成(基于学习的规划器) |
|---|---|---|
| 核心理念 | 暴力穷举与筛选:在多维空间(横纵向)预设终点,生成大量候选轨迹,然后剔除违规的。 | 数据驱动与提炼:从海量真实人类驾驶数据中,提取出最具代表性的轨迹。 |
| 采样方式 | 在 Frenet 坐标系下,对横向偏移量(如 -0.5m, 0m, 0.5m)和纵向位移(如 10m, 20m, 40m)进行双层循环遍历,生成组合轨迹。 | 对真实轨迹进行最远轨迹采样,确保选出的轨迹在空间中尽可能分散、多样化。 |
| 轨迹质量 | 物理约束完美(平滑、符合运动学),但可能缺乏"人性化"(如遇到加塞只会机械减速,不懂加速抢行)。 | 自带人类驾驶的"肌肉记忆"和习惯(舒适、拟人),但需要依赖神经网络来保证物理可行性。 |
简单来说,Lattice 是"工程师手搓的规则",而 VAD 的词表是"AI 从历史经验中总结的套路"。
二、 实际场景例子
假设一辆自动驾驶汽车正在一个十字路口,导航提示它需要直行通过,但正前方有一辆慢速行驶的黑色轿车挡住了去路。
在传统 Lattice 算法中,规划器会在终点状态空间里均匀"撒点",生成类似下面这样的候选轨迹:
- 紧贴左侧超车(横向偏移 -0.5m,纵向穿过前车)
- 紧贴右侧超车(横向偏移 +0.5m,纵向穿过前车)
- 原地急刹停下(纵向位移 0m,横向偏移 0m)
- 向左变道绕行(横向偏移 -1.0m,绕过前车路口)
规划器会从这些预设好的几何轨迹中,挑选出一条既不与障碍物碰撞、又最符合当前速度要求的轨迹。
而在 VAD 的"词表"中,它不会自己去画图,而是去历史大数据中寻找人类司机在遇到这种情况时真实走过的轨迹。通过"最远轨迹采样",词表里可能会收录以下几种极具代表性的"动作 Token":
- 激进超越 Token:一条略微向左切入、迅速加速超过前车并迅速回到原车道的平滑轨迹。
- 保守避让 Token:一条明显减速、拉开与前车距离的平缓轨迹。
- 借道绕行 Token:一条大角度向左打方向,直接从左侧空旷车道绕过去的轨迹。
当 VAD 模型遇到上述十字路口场景时,它的 Planning Transformer 就会在脑海中搜索这两个 Token,评估哪一个在当前环境下(比如左侧车道是否真的空旷)的代价最低,最终直接输出选择的那条轨迹。这样既保留了人类驾驶的灵活性,又极大地简化了神经网络的决策难度。
driver transformer
论文详读
https://blog.csdn.net/weixin_46479223/article/details/160479380?spm=1011.2415.3001.5331
课程
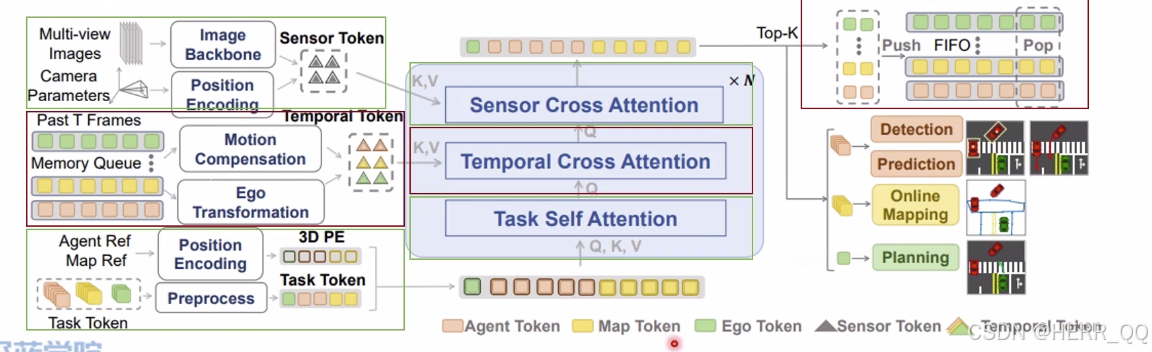
agent 动态障碍物 包括预测轨迹等
map 地图 静态障碍物
ego 自车规划轨迹
task SA 让让任务间彼此相关
sensor CA 提取输入信息特征
Temproal CA 融合历史特征
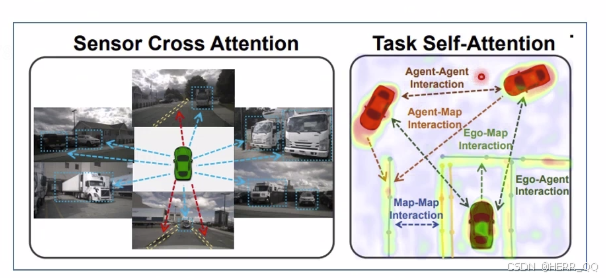
-
时序特征融合
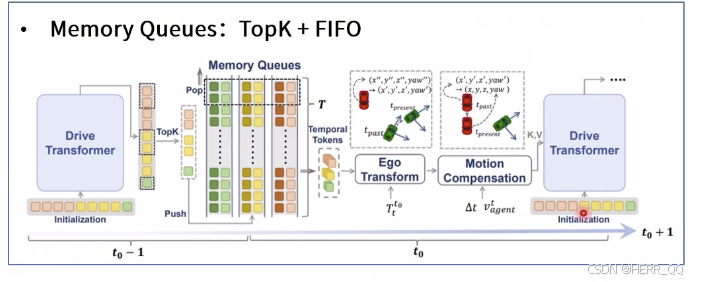
上一帧 取topk 进入队列 然后再筛选去除一些,之后做时间对齐 然后做一次因为时间差距的运动补偿 最后作为kv参与当前帧的计算
-
任务 head
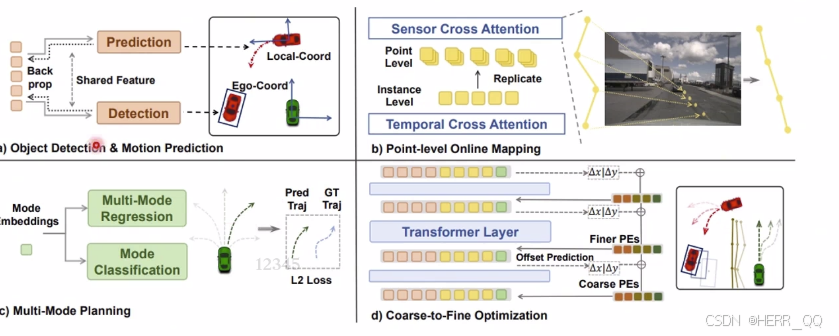
DETR style 指的不是模型 而是取代了anchor 使用稀疏query 的查询
-
问 什么是 point level 什么是 instance level
在 Driving Transformer 这类端到端架构中,Point Level 和 Instance Level 代表两种不同粒度的数据抽象层级。结合你提到的 Cross Attention 机制,它们分别对应"原始信号"与"语义对象"。
概念定义:点 vs 实例
- Point Level(点级) :指最底层的原始感知单元 。在视觉中是像素(pixel),在激光雷达中是 3D 点云中的单个点(point)。它只包含坐标、反射强度等低层物理信息,没有"是什么"的语义概念。
- Instance Level(实例级) :指已完成识别的独立物体。例如一辆具体的车、一个行人、一条车道线。它包含了身份 ID、类别、运动状态等高层语义信息。
在 Cross Attention 中的角色
你提到的 Sensual Cross Attention (应为 Sensor ,传感器交叉注意力)和 Temporal Cross Attention 分别处理空间和时间维度的信息融合,这两个 Level 在其中扮演不同角色:
- Sensor Cross Attention(空间融合)
- Point Level 作用 :进行原始数据对齐。例如,将激光雷达的某个 3D 点投影到相机图像的对应像素上,实现"点-像素"级的早期融合(Early Fusion)。
- Instance Level 作用 :进行物体级关联。例如,一个代表"车辆"的 Query(实例)去查询所有摄像头视野中属于该车辆的特征区域。
- Temporal Cross Attention(时间融合)
- Point Level 作用:通常较少直接使用,除非是做极低层的信号跟踪。
- Instance Level 作用 :核心应用层。利用前一帧的 Instance(如车 A 的轨迹点)作为 Key/Value,让当前帧的 Instance Query 去查询,从而建立"这辆车还是那辆车"的时间关联,实现多目标跟踪(MOT)。
直观类比
把自动驾驶感知比作看交通监控:
- Point Level :相当于监控画面的原始像素流。你看到的是颜色和光点,但不知道哪堆像素是车。
- Instance Level :相当于画好的检测框。你明确知道"框 1 是卡车,框 2 是轿车",并能跟踪框 1 的运动。
在 Driving Transformer 中,模型通过 Attention 机制,从 Point Level 的 raw data 中提炼出 Instance Level 的抽象概念,最终输出给规划模块使用的是实例级的轨迹和状态。
query based 的不同范式的比较
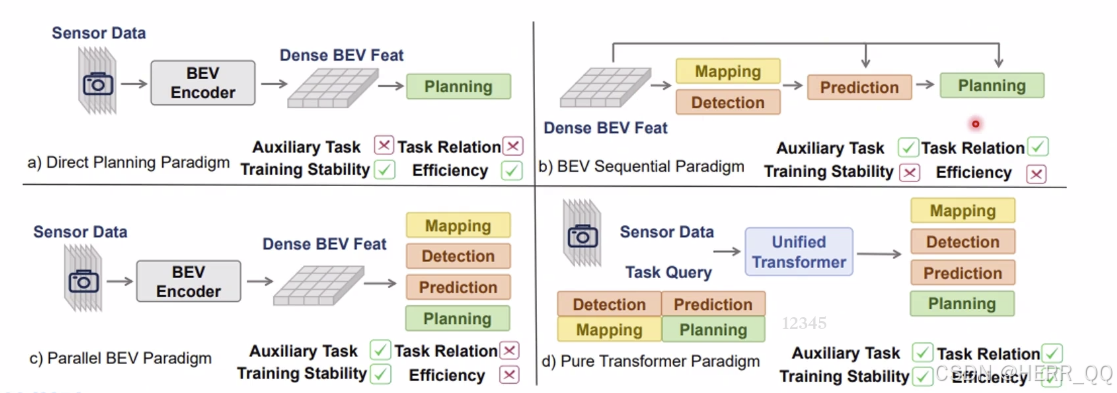
- AI 解读
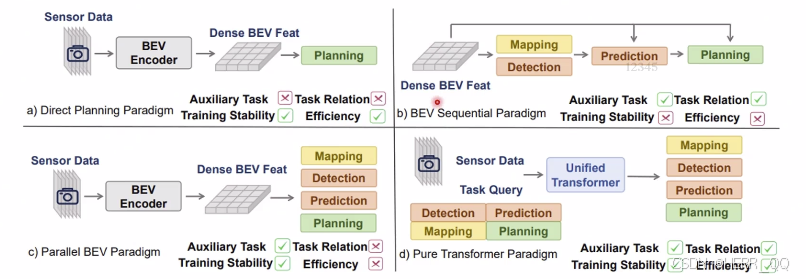
这四种范式代表了端到端自动驾驶架构从"单打独斗"到"多任务协同"的演进过程。它们都依赖于同一个起点:将多摄像头的图像通过 BEV Encoder 转换成稠密的鸟瞰图特征(Dense BEV Feat),但在**如何利用这些特征生成最终结果(规划)**上,走了四条截然不同的路。
一、 四种范式的深度解析
- (a) Direct Planning Paradigm(直接规划范式)------ "一步到位"
- 逻辑:这是最激进的端到端路线。拿到 BEV 特征后,不经过任何中间步骤,直接输入给 Planning 模块,输出车辆的控制信号。
- 特点:极简、延迟极低。它试图让网络自己"悟"出如何驾驶。
- 痛点:由于缺乏显式的监督(比如不知道中间过程是否准确识别了障碍物),模型训练难度极大,容易学歪。
- (b) BEV Sequential Paradigm(BEV 顺序范式)------ "按部就班"
- 逻辑:这是传统模块化思想的延续,但用 BEV 统一了表示。感知任务(Mapping 建图、Detection 检测、Prediction 预测)按顺序串行执行,最后才到 Planning。
- 特点:逻辑清晰,各司其职,训练相对容易(因为每一步都有明确的标签监督)。
- 痛点:效率极低,且存在严重的"信息孤岛"。前面的感知误差会直接传给后面的规划,缺乏全局最优考虑。
- © Parallel BEV Paradigm(BEV 并行范式)------ "各干各的"
- 逻辑 :为了解决顺序执行的低效问题,感知任务(建图、检测、预测)不再排队,而是并行地从 BEV 特征中提取信息,最后汇总给规划模块。
- 特点:多任务学习(Multi-task Learning),能同时优化多个子任务,整体训练稳定性尚可。
- 痛点:虽然快了,但各任务之间依然是"零沟通"。检测任务和规划任务在算各自的东西,没有针对"最终怎么开"这个目标进行联合优化。
- (d) Pure Transformer Paradigm(纯 Transformer 范式)------ "终极大一统"
- 逻辑 :这是目前最前沿的架构。它引入了一个统一的 Unified Transformer 。不再是感知任务输出给规划,而是所有任务(感知、预测、规划)都由一组统一的 Task Queries 驱动。
- 特点:感知、预测、规划在同一个空间内进行交互。例如,规划在决定往哪开时,可以直接"询问"代表障碍物的 Query:"你挡路吗?"。
- 优势:真正的"以终为始",所有任务为了共同的规划目标服务,实现了全局最优。
二、 四大范式对比总结表
| 范式名称 | 核心逻辑与流程 | 辅助任务 (Auxiliary Task) | 任务关系 (Task Relation) | 训练稳定性 (Training Stability) | 效率 (Efficiency) | 适用场景与代表 |
|---|---|---|---|---|---|---|
| (a) Direct Planning*(直接规划)* | 图像 → \rightarrow → BEV特征 → \rightarrow → 直接输出规划极简路线,无任何中间显式任务。 | ❌ 无*(纯端到端,无中间监督)* | ❌ 无*(无中间交互)* | ✅ 高*(结构简单,不易梯度爆炸)* | ✅ 极高*(跳过所有中间解码)* | 轻量级部署追求极致低延迟,但对复杂路况泛化能力较弱。 |
| (b) BEV Sequential*(BEV 顺序)* | 图像 → \rightarrow → BEV特征 → \rightarrow → Mapping → \rightarrow → Detection → \rightarrow → Prediction → \rightarrow → Planning传统流水线,串行处理。 | ✅ 有*(显式监督每一步)* | ❌ 弱*(信息单向传递,误差累积)* | ❌ 低*(多阶段梯度回传困难)* | ❌ 低*(必须等上一步算完)* | 早期探索逻辑清晰,但效率低,难以应对动态复杂场景。 |
| © Parallel BEV*(BEV 并行)* | 图像 → \rightarrow → BEV特征 → \rightarrow → Mapping, Detection, Prediction 并行 → \rightarrow → Planning多任务并行解码。 | ✅ 有*(多任务联合监督)* | ❌ 弱*(任务间无直接交互)* | ✅ 高*(多任务稳定优化)* | ❌ 低*(仍需分别解码所有任务)* | 主流过渡方案如 UniAD 等,兼顾了性能与稳定性,但计算开销大。 |
| (d) Pure Transformer*(纯 Transformer)* | 图像 → \rightarrow → BEV特征 → \rightarrow → Unified Transformer + Task Queries → \rightarrow → 所有任务交互融合 → \rightarrow → Planning大一统架构。 | ✅ 有*(统一监督)* | ✅ 强*(Query间直接交互)* | ✅ 高*(端到端可微分)* | ✅ 极高*(全局优化,避免冗余)* | 未来主流代表架构如 VAD、DriveTransformer 等,实现全局最优决策。 |
| 三、 决策建议 |
- 如果你追求极致的上车部署速度 且不差钱,可以研究 (a),但它目前还很难处理复杂的极端路况。
- 如果你是研究人员或算法工程师 ,追求性能上限和逻辑严谨 ,目前学术界和产业界最推崇的是 (d) Pure Transformer 范式。它打破了感知与规划的壁垒,让 AI 真正像人一样,在理解环境的同时,综合考虑各种因素做出最佳决策。
训练目标 模仿学习和约束条件
单模态 只有一个 输出 对应一个GT 做loss
多模态 有很多输出 需要找出与GT对应的那个 做loss
目的是 loss 最小 同时 满足安全约束
- 问transformer 结构里 这个loss可以人为设定吗 适合 二次规划的cost function 设计一样吗
端到端(End-to-End)Transformer 结构(如 VAD、UniAD 等)。关于 Loss 是否可以人为设定,以及它与二次规划(QP)中 Cost Function 的设计是否一样,答案是:形式上相似(都是优化目标),但本质上是完全不同的两件事。
✅ 一、端到端 Transformer 的 Loss 可以人为设定吗?
✅ 完全可以,而且是必须的。
在端到端自动驾驶中,Loss 是指导模型训练的"指挥棒"。你不能只靠"让模型自己学",必须人为设计 Loss 函数,告诉模型"什么是好,什么是坏"。
从你提供的图中可以看到,Loss 分为两大类:
- 模仿学习 Loss(Imitation Learning Loss)
- 目的:让模型模仿人类驾驶员的轨迹。
- 形式 :
- 单模态:L2 Loss(预测轨迹 vs 真实轨迹 的欧氏距离)
- 多模态:正负样本匹配 + L2 Loss(鼓励模型输出多种合理轨迹,并区分好坏)
- 人为设定点 :
- 选择用 L2 还是 L1?
- 是否加权(比如对转弯处加大权重)?
- 是否加入多模态分支?
- 辅助约束 Loss(Auxiliary Constraint Loss)
- 目的:让模型不仅"像人",还要"安全、合规、舒适、高效"。
- 形式 :
- 安全:动态/静态碰撞惩罚
- 交规:闯红灯、逆行、压线惩罚
- 舒适:加减速平滑、横向稳定性惩罚
- 效率:到达时间、车速惩罚
- 人为设定点 :
- 每个约束的权重是多少?(比如"碰撞"权重 > "压线"权重)
- 约束的数学形式(是 0/1 惩罚?还是连续函数?)
- 是否引入"软约束"(如 Sigmoid 平滑)?
📌 结论 :端到端 Transformer 的 Loss 是高度可定制、强依赖人工设计的,设计的好坏直接决定模型性能。
✅ 二、和"二次规划(QP)的 Cost Function"设计一样吗?
❌ 不一样,但有形式上的相似性。
| 维度 | 端到端 Transformer Loss | 二次规划(QP)Cost Function |
|---|---|---|
| 本质 | 监督学习信号,用于训练神经网络 | 优化问题目标函数,用于实时求解控制量 |
| 输入 | 模型预测的轨迹/动作 | 系统状态、约束条件、参考轨迹 |
| 输出 | 梯度(用于更新网络参数) | 最优控制量(如方向盘角、加速度) |
| 设计目标 | 让模型"学得像人 + 安全合规" | 让系统在物理约束下"代价最小" |
| 数学形式 | 通常是可微分的(如 L2、交叉熵、自定义惩罚) | 通常是二次型(如 xᵀQx + uᵀRu) |
| 是否可微 | ✅ 必须是可微的(才能反向传播) | ❌ 不一定需要可微(QP 是数值优化) |
| 实时性 | 训练时用,推理时不参与 | 推理时实时计算,每帧都要解一次 |
🧩 形式相似性举例:
-
两者都可以写成:
Total Cost = w₁ * Safety + w₂ * Comfort + w₃ * Efficiency -
在 QP 中,Safety 可能是"碰撞距离"的二次函数;
-
在 Loss 中,Safety 可能是"碰撞惩罚项"的 L2 或 Huber Loss。
📌 关键区别:
- Loss 是"教模型怎么学"(训练阶段)
- Cost Function 是"教控制器怎么算"(部署阶段)
✅ 四、总结表格
| 项目 | 端到端 Transformer Loss | 二次规划 Cost Function |
|---|---|---|
| 是否人为设定 | ✅ 是,且必须 | ✅ 是,且必须 |
| 是否可微 | ✅ 必须是 | ❌ 否(QP 求解器不依赖梯度) |
| 作用阶段 | 训练阶段 | 推理/部署阶段 |
| 优化对象 | 网络参数 | 控制量(u) |
| 设计复杂度 | 高(需平衡多目标) | 中(需设计 Q, R 矩阵) |
| 与物理世界关系 | 间接(通过数据学习) | 直接(基于动力学模型) |
✅ 五、延伸思考:未来趋势
现在很多工作(如 VAD、ST-P3、PnPNet)都在尝试:
- 将 QP 的 Cost Function 思想融入 Loss 设计(比如用"可微 QP layer"做辅助监督)
- 让端到端模型学会"隐式地"做 QP 优化(即模型内部自动权衡安全、舒适、效率)
- 用强化学习(RL)替代模仿学习 Loss,让模型自己探索最优策略
所以,虽然现在两者不一样,但边界正在模糊,未来的端到端系统可能会"既像 Loss 又像 Cost Function"。
✅ 最后一句话总结:
端到端 Transformer 的 Loss 是人为设计的"训练评分标准",二次规划的 Cost Function 是实时求解的"控制优化目标"------前者教模型"怎么学",后者教控制器"怎么算",形式相似,本质不同,但都在追求"安全、舒适、高效"的驾驶目标。
- 问 loss设计的不好是不是模型学习就废了
是的,Loss 设计不好,模型基本就废了。在端到端自动驾驶中,Loss 不仅是"评分标准",更是模型唯一的"生存法则"。如果法则定错了,模型要么学不会,要么学出一身坏毛病。
为什么 Loss 是"生死线"?
端到端模型(尤其是 Transformer)没有"常识",它完全依赖 Loss 的反向传播来调整参数。Loss 设计决定了模型"价值观":
- Loss 只关注"像人" → 模型可能学会人类的坏习惯(如加塞、压线)。
- Loss 忽略"安全" → 模型可能为了效率而冒险。
- Loss 权重失衡 → 模型可能为了不撞车而直接"死机"停在路中间。
常见的"废掉模型"的 Loss 设计雷区
| 雷区类型 | 错误表现 | 导致的模型"废"态 |
|---|---|---|
| 1. 只做模仿(Imitation Only) | 只计算轨迹的 L2 误差,没有安全约束。 | "马路杀手":完美复现人类司机的激进驾驶,包括违章和危险动作。 |
| 2. 约束冲突(Constraint War) | 安全 Loss 权重过大,且形式过于粗暴(如硬碰撞惩罚)。 | "僵尸车":极度保守,遇到复杂路况直接刹停或龟速蠕动,无法完成导航。 |
| 3. 模态坍塌(Mode Collapse) | 多模态预测 Loss 设计不当(如仅用 Winner-Takes-All)。 | "赌徒":只输出一种最保守的轨迹,失去应对突发状况的灵活性。 |
| 4. 不可微/非平滑 | 使用了类似 if-else 的逻辑判断做 Loss。 | "学不动":梯度消失或爆炸,训练直接卡住,Loss 不下降。 |
Loss 与二次规划(QP)Cost 的"失效"差异
你之前问到 QP Cost,这里有一个关键区别:Loss 设计错了是"根坏了",QP Cost 设计错了是"工具坏了"。
| 维度 | 端到端 Loss(训练阶段) | QP Cost Function(部署阶段) |
|---|---|---|
| 失效后果 | 毁灭性:模型参数被污染,需从头训练,且可能永远学不到正确策略。 | 可修复性:只是当前帧算得不好,下一帧调整权重或约束即可实时修正。 |
| 调试难度 | 极难:训练周期长(天/周级),现象滞后,难以定位是数据问题还是 Loss 问题。 | 较易:实时调试,参数(Q, R 矩阵)调整立竿见影。 |
| 本质原因 | Loss 定义了模型的长期行为策略(Policy)。 | Cost 定义了单步的优化目标(Objective)。 |
如何设计"不废"的 Loss?------ 端到端自动驾驶的 Loss 设计原则
-
多目标协同(Imitation + Safety + Comfort):
- 必须引入辅助约束:即使没有真实标签,也要通过可微的物理模拟(如碰撞检测)加入安全 Loss。
- 公式示例 :
Total Loss = L_imitation + λ₁ * L_collision + λ₂ * L_comfort + λ₃ * L_rule
-
可微性(Differentiability):
- 所有惩罚项必须平滑。例如,用
SmoothL1代替L2,用Sigmoid近似硬碰撞边界,确保梯度能流回去。
- 所有惩罚项必须平滑。例如,用
-
Curriculum Learning(课程学习):
- 先让模型学会"像人"(Imitation Loss 主导),再逐步加大安全约束的权重,防止初期训练崩溃。
-
引入 RL(强化学习):
- 在后期用 RL 的 Reward(可视为另一种 Loss)替代纯模仿,让模型学会"做决策"而非"抄作业"。
总结
Loss 设计是端到端自动驾驶的"宪法" 。QP Cost 设计不好,车开得别扭;Loss 设计不好,模型从根本上就不是一辆车。在端到端架构中,没有规则模块(Rule-based)兜底,Loss 就是唯一的"上帝之手"。