一:向量数据库简介
将数据(如文本、图像、音频等)通过嵌入模型(Embedding Model) 转换为向量形式存储到向量数据库中,并通过高效的索引和搜索算法实现快速检索。
嵌入模型会将各种数据 (例如文本、图像、图表和视频) 转换为数值向量,以便捕捉其在多维向量空间中的含义和细微差别。嵌入技术的选择取决于应用需求,同时要兼顾语义深度、计算效率、要编码的数据的类型、维度等因素。
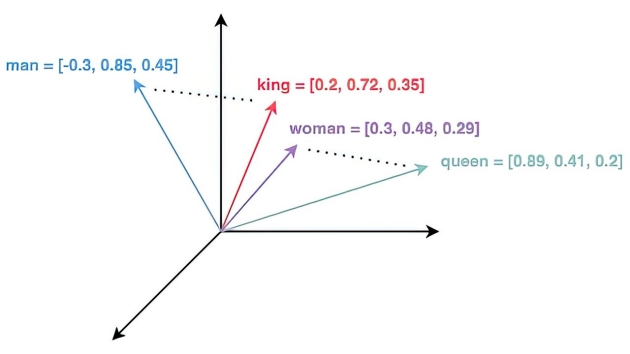
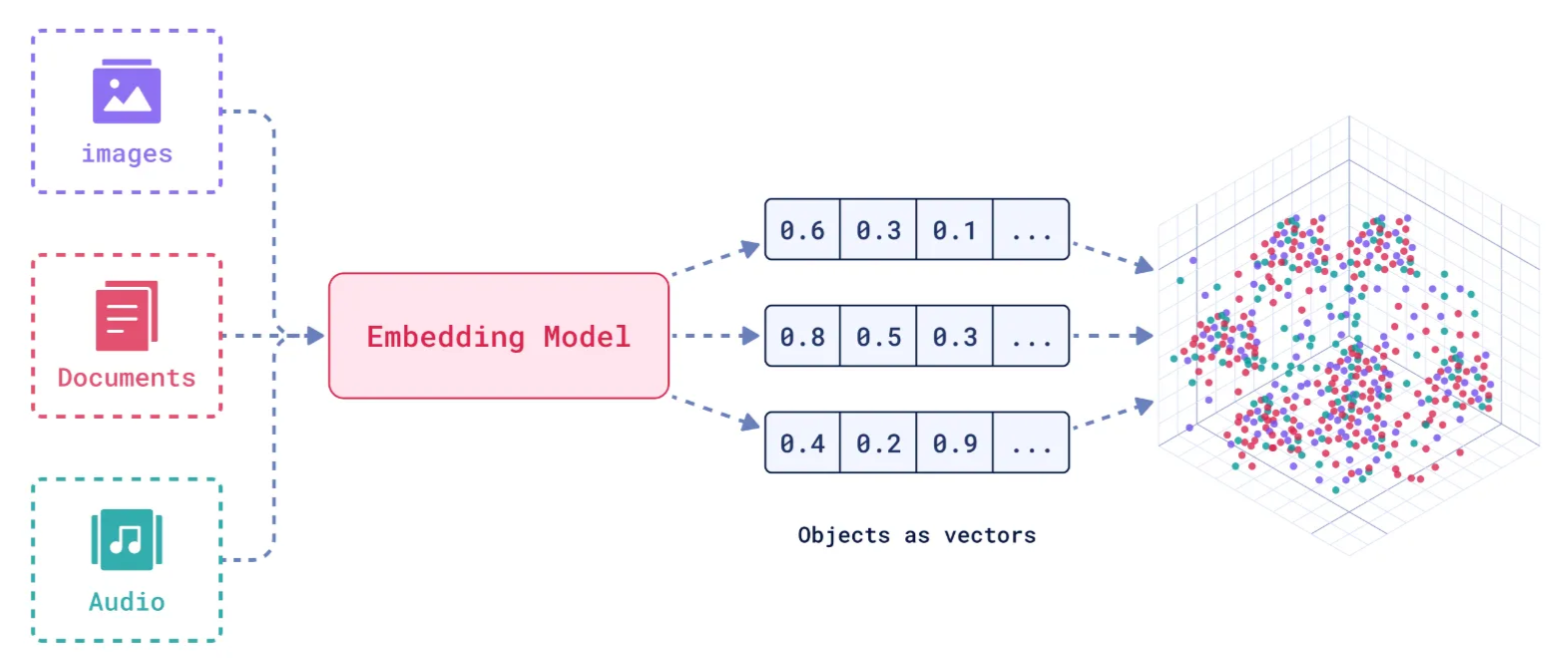
向量数据库用于相似性搜索:即通过计算向量之间的距离(如欧几里得距离、余弦相似度等)来找到与目标向量最相似的其他向量。它特别适合处理非结构化数据,支持语义搜索、内容推荐等场景。
数据不同,使用的嵌入模型不同,文本数据使用处理文本的嵌入模型,图片数据使用处理图片的嵌入模型。
存储
向量数据库将嵌入向量存储为高维空间中的点,并为每个向量分配唯一标识符(ID),同时支持存储元数据。
检索
通过近似最近邻(ANN)算法(如PQ等)对向量进行索引和快速搜索。
二、Chorma简介
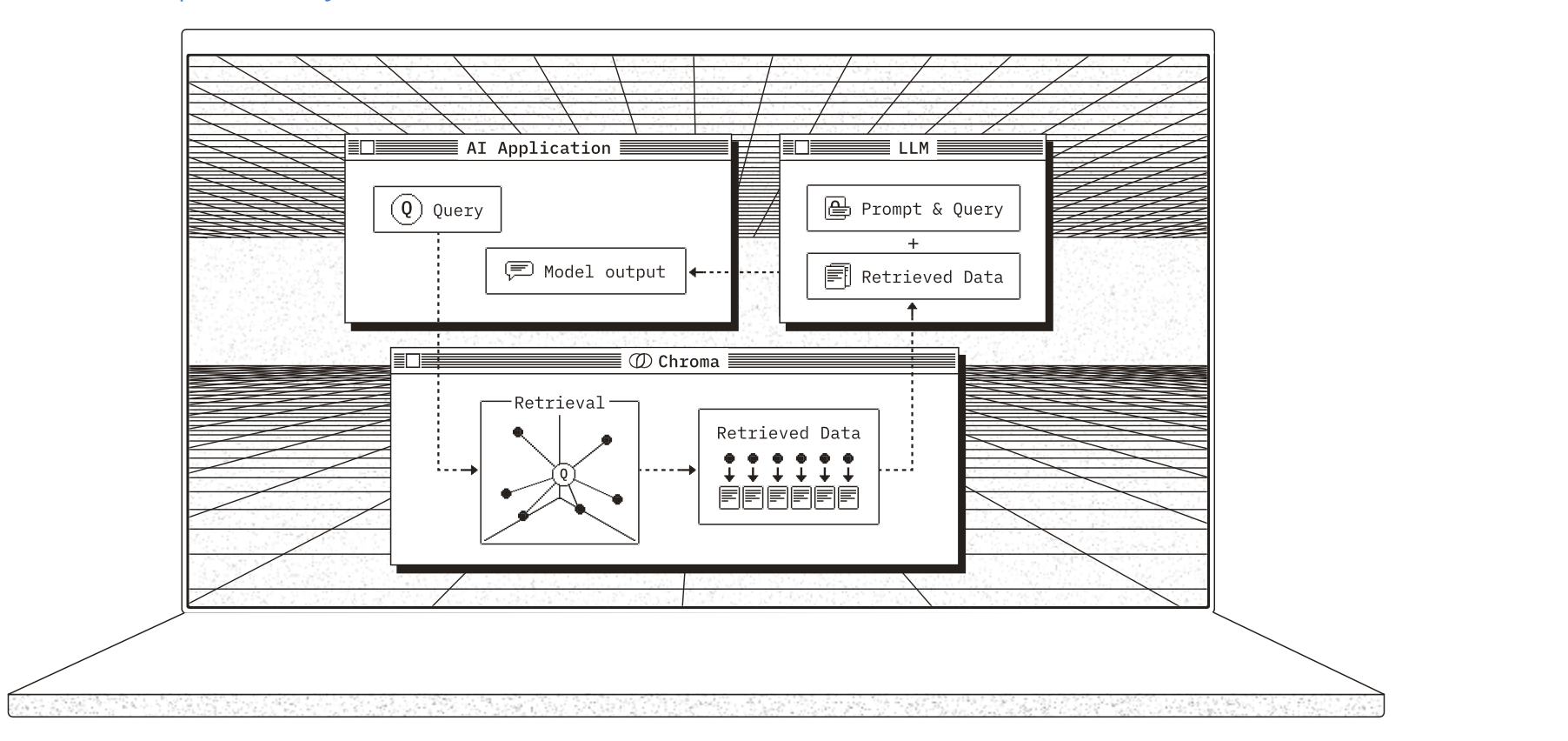
Chroma(https://docs.trychroma.com/docs/overview/introduction) 是一款开源的向量数据库,专为高效存储和检索高维向量数据设计。其核心能力在于语义相似性搜索,支持文本、图像等嵌入向量的快速匹配,广泛应用于大模型上下文增强(RAG)、推荐系统、多模态检索等场景。与传统数据库不同,Chroma 基于向量距离(如余弦相似度、欧氏距离)衡量数据关联性,而非关键词匹配。
核心优势:
-
轻量易用:以 Python/JS 包形式嵌入代码,无需独立部署,适合快速原型开发。
-
灵活集成:支持自定义嵌入模型(如 OpenAI、HuggingFace),兼容 LangChain 等框架。
-
高性能检索:采用 HNSW 算法优化索引,支持百万级向量毫秒级响应。
-
多模式存储:内存模式用于开发调试,持久化模式支持生产环境数据落地。
python
# 安装chromadb
pip install chromadb
# 导入
import chromadb
三、增删改查
3.0 初始化客户端
python
# 内存模式,一般不推荐使用
client = chromadb.Client()
# 持久化模式(常用)
client = chromadb.PersistentClient(path="./data/chromadb")3.1 创建集合Collection
集合(Collection)是 Chroma 中管理数据的基本单元,类似关系数据库的表。在创建集合的时候需要指定嵌入函数。
python
import os
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
# 持久化模式
client = chromadb.PersistentClient(path="../db/chroma")
# 创建一个集合,这里的集合名字必须在Chromadb中唯一
# get_or_create_collection
my_collection = client.create_collection(
name="my_collection",
embedding_function=OpenAIEmbeddingFunction(
api_key=os.getenv("OPENAI_API_KEY"),
api_base="https://xxx",
model_name="text-embedding-3-small"
)
)
python
# 删除集合
client.delete_collection(name='my_collection')3.2 获取集合
python
my_collection = client.get_collection(name="my_collection")3.3 添加数据
方式一:使用Chroma指定的嵌入函数将文本生成向量。
python
my_collection.add(
documents=["RAG是一种检索增强生成技术", "向量数据库存储文档的嵌入表示",
"在机器学习领域,智能体(Agent)通常指能够感知环境、做出决策并采取行动以实现特定目标的实体"],
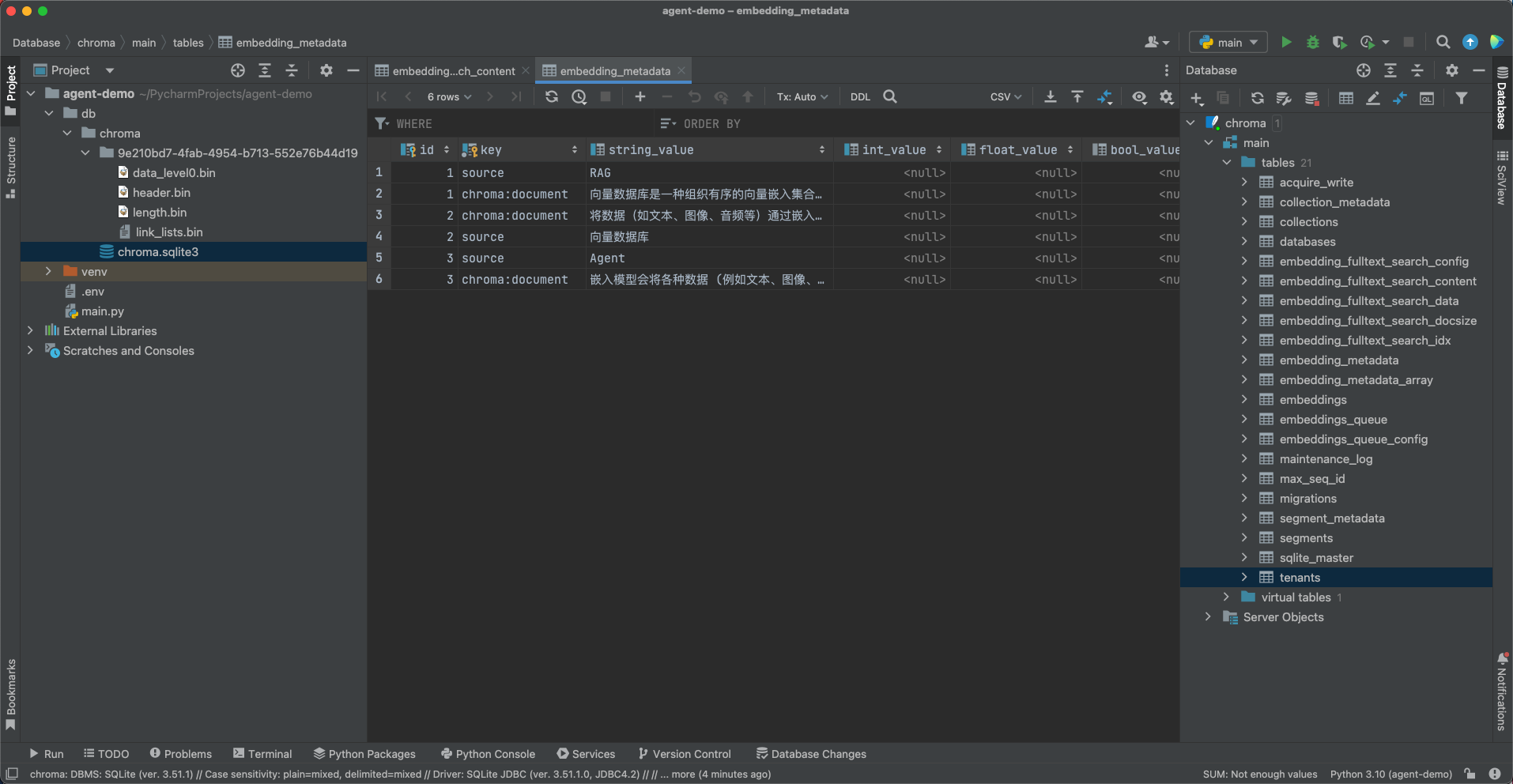
metadatas=[{"source": "RAG"}, {"source": "向量数据库"}, {"source": "Agent"}],
ids=["id1", "id2", "id3"]
)
print('添加数据后peek ==>', knowledge_collection.peek())
print('添加数据后count ==>', knowledge_collection.count())
# 获取所有文档
result = knowledge_collection.get()
print('所有文档:', result)方式二:自己去调用模型获取向量然后再存储
python
# 方式二:手动传入预计算向量,
knowledge_collection.add(
embeddings=[[1.2, 2.3, 4.5], [6.7, 8.2, 9.2]],
documents=["This is a document", "This is another document"],
metadatas=[{"source": "my_source"}, {"source": "my_source"}],
ids=["id1", "id2"]
)3.4 查询
根据条件查询
python
r = my_collection.get(
where={"source": 'Agent'}, # 通过metadatas 中的字段来查询记录
where_document={'$contains': 'Agent'} # 在集合中的文档中去检索包含Agent字符串的记录 可选
)
print(r)根据条件分页查询,通过limit限制每页条数,offset表示开始下标
python
r = my_collection.get(
ids=['id1', 'id2', 'id3'],
limit=1,
offset=2
)
print(r)传入的query_texts 会使用集合的embedding function来转化为向量,然后通过余弦相似度与集合中的文档来检索相似关系
python
r = my_collection.query(
query_texts='Agent是什么',
n_results=1 # 返回的结果个数
)
print(r)
python
r = my_collection.query(
query_embeddings=[[0.5, 0.6, ...]],
n_results=2
)3.5 更新
python
# 修改文档
knowledge_collection.update(
ids=['id3'],
documents=['在机器学习领域,Agent通常指能够感知环境、做出决策并采取行动以实现特定目标的实体,只需给出目标,然后自动执行任务达成目标']
)3.5 删除
python
knowledge_collection.delete(ids=["id3"])四、示例
python
import os
import json
from dotenv import load_dotenv; load_dotenv()
import chromadb
from chromadb.utils.embedding_functions import OpenAIEmbeddingFunction
# 初始化客户端
client = chromadb.PersistentClient(path="./db/chroma")
my_collection = client.get_or_create_collection(
name="my_collection",
embedding_function=OpenAIEmbeddingFunction(
api_key=os.getenv("OPENAI_API_KEY"),
api_base=os.getenv("OPENAI_BASE_URL"),
model_name="azure_openai/text-embedding-3-small"
)
)
# 获取集合
my_collection = client.get_collection(name="my_collection")
# 添加向量
my_collection.add(
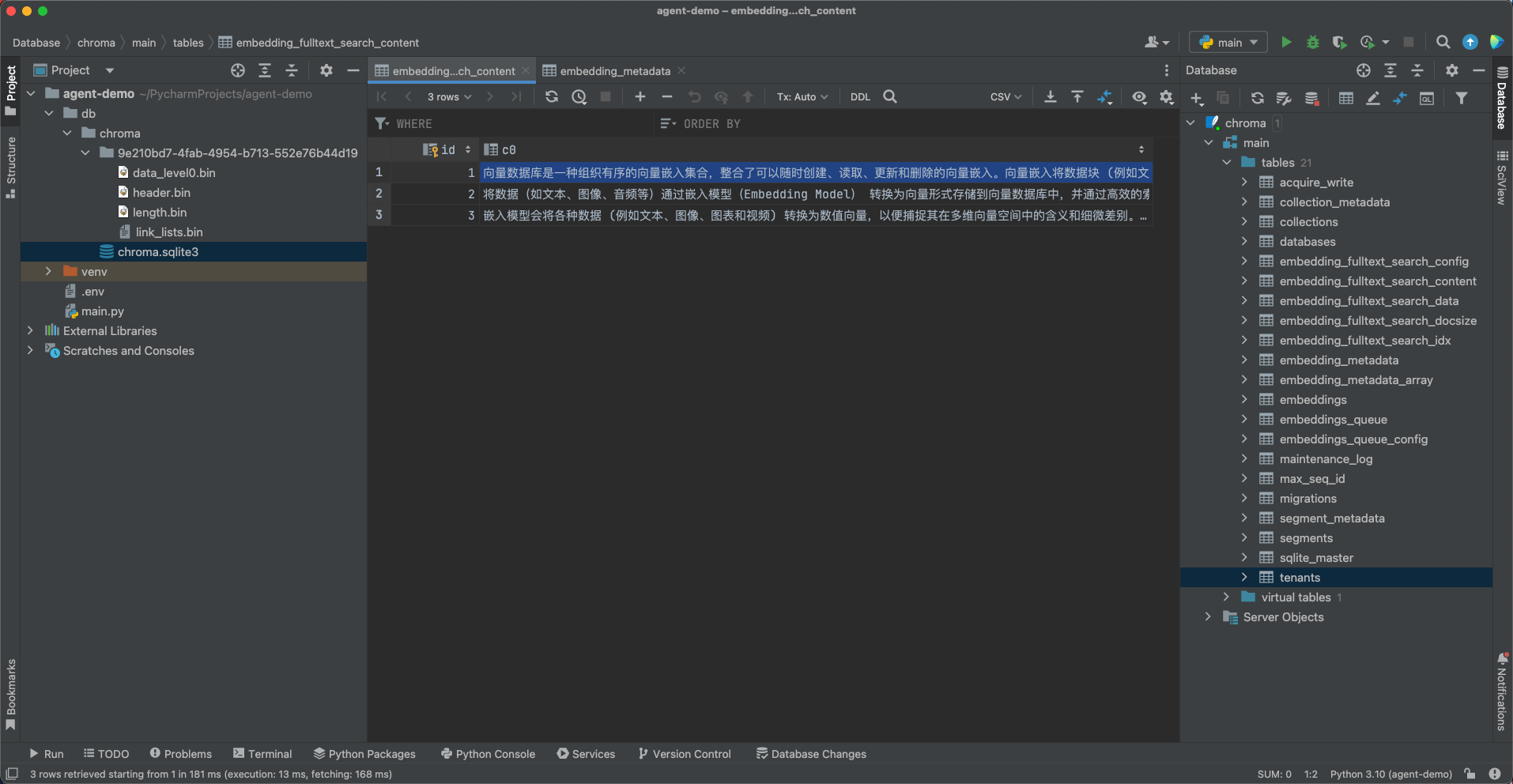
documents=["向量数据库是一种组织有序的向量嵌入集合,整合了可以随时创建、读取、更新和删除的向量嵌入。向量嵌入将数据块 (例如文本或图像) 表示为数值。",
"将数据(如文本、图像、音频等)通过嵌入模型(Embedding Model) 转换为向量形式存储到向量数据库中,并通过高效的索引和搜索算法实现快速检索",
"嵌入模型会将各种数据 (例如文本、图像、图表和视频) 转换为数值向量,以便捕捉其在多维向量空间中的含义和细微差别。嵌入技术的选择取决于应用需求,同时要兼顾语义深度、计算效率、要编码的数据的类型、维度等因素。"
],
metadatas=[{"source": "RAG"}, {"source": "向量数据库"}, {"source": "Agent"}],
ids=["id1", "id2", "id3"]
)
# 查询
results = my_collection.query(
query_texts='向量数据库是什么?',
n_results=2 # 返回的结果个数
)
print(json.dumps(results))
json
{
"ids": [["id1","id2"]],
"embeddings": null,
"documents": [
[
"向量数据库是一种组织有序的向量嵌入集合,整合了可以随时创建、读取、更新和删除的向量嵌入。向量嵌入将数据块 (例如文本或图像) 表示为数值。",
"将数据(如文本、图像、音频等)通过嵌入模型(Embedding Model) 转换为向量形式存储到向量数据库中,并通过高效的索引和搜索算法实现快速检索"
]
],
"uris": null,
"included": ["metadatas","documents","distances"],
"data": null,
"metadatas": [
[{"source": "RAG"},{"source": "向量数据库"}]
],
"distances": [
[
0.15911930799484253,
0.42112505435943604
]
]
}
四、Client-Server Mode
4.1 服务端
在生产环境中也可以使用Client-Server Mode,类似我们使用关系型数据库,在服务器上部署一个mysql Server,然后通过Client进行链接使用。
shell
# uv安装
uv tool install chromadb
# pip安装
python3 -m pip install --upgrade chromadb
shell
# --path:表示存储数据的文件目录
# --port:表示监听的端口号,默认端口:8000
chroma run [--port 8000] --path /db_path
4.2 客户端
python
import chromadb
chroma_client = chromadb.HttpClient(host='localhost', port=8000)