文章目录
- IO
-
- [1. 文件与 IO 核心本质](#1. 文件与 IO 核心本质)
- [2. 进程与文件关联](#2. 进程与文件关联)
- [3. Linux 一切皆文件 与 标准流](#3. Linux 一切皆文件 与 标准流)
- [4. 文件打开模式细节](#4. 文件打开模式细节)
- [5. 文件描述符的分配规则](#5. 文件描述符的分配规则)
- [6. 文件权限与 umask](#6. 文件权限与 umask)
-
- [1. open ,close](#1. open ,close)
- [2. write](#2. write)
- [3. read](#3. read)
- [7. 内核文件管理与描述符表](#7. 内核文件管理与描述符表)
- 重定向
- 缓冲区
IO
1. 文件与 IO 核心本质
文件=文件内容+文件属性。一个文件,就算没有内容,它也占内存,因为文件属性也占内存。所以对文件操作,本质是文件内容操作和文件属性操作
- 文件在磁盘上 【内存和磁盘不同,内存上的数据,如果关闭程序/拔掉电源也就消失了。但磁盘是永久性存储介质,因此文件在磁盘上的存储是永久性的】
磁盘是外设。
所以访问文件 也就是访问磁盘,本质就是(对外设的输入输出):在系统和外设之间进行IO(也就是输入输出)
- 硬件被谁管理?被操作系统。而磁盘是硬件,所以磁盘被操作系统管理
- 访问文件的本质,最终都是访问磁盘硬件,而操作系统管理硬件资源(磁盘)。因此只有操作系统能直接管理文件,这就要求(操作系统)必须(在底层)提供(文件操作专属的系统调用接口)。
我们日常使用的fopen、fread、fprintf等是C/C++ 库函数,只是封装好的上层工具,并不是真正的文件操作底层实现。
因为操作系统不信任用户进程,不会允许用户程序直接操作硬件与文件资源。所有文件读写、打开关闭等操作,最终都会层层下沉,由标准库函数调用操作系统内核的文件系统调用来完成(在用户层,fopen的返回值是FILE*,FILE是一个结构体,里面封装了fd)(在OS接口层面,只认文件描述符fd)
(访问文件,访问硬件,必须通过操作系统)
- 语言是不可能直接去访问硬件的,必须通过操作系统才能够访问磁盘/文件------->我们用到的C语言接口就是封装了操作系统底层的系统调用【在C语言代码实现fopen函数的时候,它封装了open,fopen根据(w,r,a)来选择调用底层不同的open函数,给它传递不同的mode选项】
2. 进程与文件关联
-
可执行程序加载到内存 ,正式运行形成进程 后,成功调用 open 系统调用,这个这个进程才算是在内存中打开文件
【程序载入内存并创建进程实例,执行 open 系统调用完成文件描述符绑定后,即为进程在内存层面正式打开文件。】
-
我们对文件的操作(打开、读写、关闭等),本质是进程对文件的操作
因为:文件无法独立主动被访问,所有 IO 操作都必须依托运行中的进程发起(只有程序加载入内存成为进程,通过调用open/read/write/close等系统调用,才能向操作系统内核申请文件资源、建立文件关联、完成数据交互,静态文件本身不具备执行操作的能力)

-
一个进程能打开n个文件,那100个进程打开的就更多了,(如何读取文件呢?必须由OS将文件内容从磁盘读到内存中,所以系统中一定存在大量被打开的文件)。那操作系统如何管理在磁盘的文件呢?
在操作系统内部,每打开一个文件,内核就会在内存中创建一个 struct file 对象,用于描述该文件的各类属性与状态;操作系统会以链表的形式管理所有 struct file 对象,因此对已打开文件的管理,本质就是对这条链表进行增删查改。
- 简述:进程和文件均是:内核维护的独立数据结构。内核打开文件时会创建文件管理结构体,进程通过自身结构体与文件结构体建立关联,从而实现进程对文件的访问与操控。
详述:在内核层面,操作系统要管理文件,就必须先打开文件,在内核中创建文件对应的数据结构对象(记录文件位置、权限、读写偏移、状态等核心信息)
进程本身是内核维护的一套进程结构体对象,文件同样是内核维护的文件结构体对象。简言之:进程、文件,本质都是操作系统内核管理的两类独立数据结构。
进程想要操作文件,本质就是进程结构体 与 文件结构体 在内核中建立关联绑定,通过这种数据结构的映射关系,让进程可以合法访问、读写对应文件。
- 文件:未被打开的磁盘级文件 ,已经打开的内存级文件
本节针对磁盘级文件
3. Linux 一切皆文件 与 标准流
-
向显示器打印,本质就是:向显示器文件写入(因为Linux下,一切皆文件)
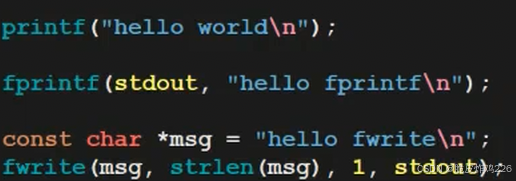
第一个不解释
第二个:将格式化字符串写入到第一个参数(这里stdout是:输出文件流)
第三个:将这段字符串的地址传给msg,fwrite 是 C 标准库提供的无格式二进制文件写入函数,用于将数据块直接写入指定的文件流(这里是stdout)。
-
系统在默认启动时,会打开三个文件流,标准输入流/输出流/错误流,类型是FILE*
stdin (入) 键盘文件 文件操作符是0
stdout (出) 显示器文件 1
stderr (错) 显示器文件 2
在写 C/C++ 代码时,不用手动打开 stdin(标准输入)、stdout(标准输出)、stderr(标准错误)这三个文件,就能直接用 printf、scanf、cout 做 IO的原因:程序编译后,编译器在你的代码前加了一段代码,启动代码会自动打开三个标准文件,并封装为全局指针供程序直接使用
程序打开标准输入/出,就是为了给我们的程序提供默认的数据源和数据结果
4. 文件打开模式细节
-
以w的形式写:想写入首先要打开文件,在以w方式打开文件,文件里就已经清空了;以a的方式(追加写)它不需要清空文件
-
fwrite将字符串写进文件里,是否需要在strlen(字符串)+1,给"\0"留位置?不需要,它是不可显字符,打开文件会乱码。
\0是C语言的规定,和文件无关
5. 文件描述符的分配规则
底层的open函数:
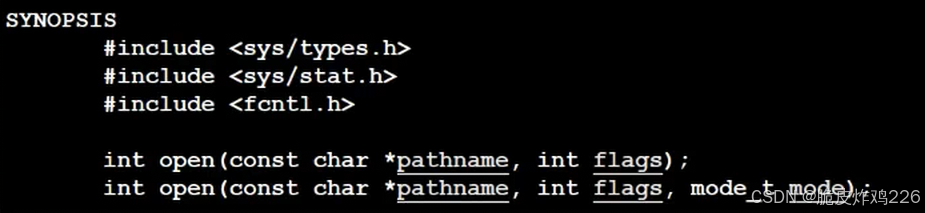
第三个参数mode,主要是为了对文件进行操作时指定权限:
- O_CREAT:没有文件就创建
- O_TRUNC:写入时清空
- O_APPEND:追加写入
- O_RDONLY:rdonly只读
- O_WRONLY:wronly只写
在语言层:w是清空写,w+是追加写等等,其实c语言做的封装,在源代码实现的时候,里面封装了open,传递不同的mode选项
6. 文件权限与 umask
- 为什么设置666,最后权限是664?
Linux 创建文件时,最终权限 = 设定权限 & ~umask;默认umask为0022,代码指定0666创建文件时,掩码会屏蔽组、其他用户的写权限,最终权限变为664;
而调用umask(0)可清空权限掩码,不再屏蔽任何权限位,文件就能严格按照代码设置的0666权限创建。
1. open ,close
关文件时需要使用open的返回值:文件描述符,当其中一个参数
bash
umask(0);
int fd = open("log.txt",O_CREAT | O_WRONLY, 0666);
close(fd);2. write
bash
ssize_t write(int fd,const void *buf,size_t count);参数:文件描述符,数据缓冲区(你要写入的数据放在这里),写入的数据长度。
这里是const void* 表明:字符串写入(文本写入) / 二进制写入都可以
返回值:实际写入的数据数
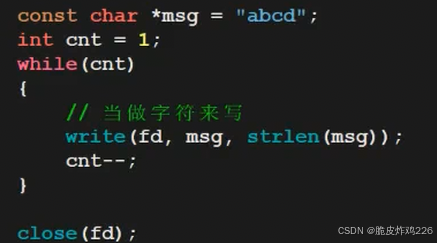
想将12345写入,不能按类型int直接写入,需要将它当作字符一样写入
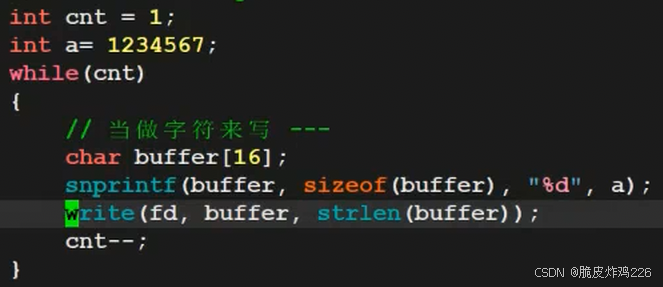
3. read
从文件描述符中读
bash
ssize_t read(int fd,const void *buf,size_t count);在之前打开文件时,只需要传RDOLY即可
7. 内核文件管理与描述符表
- 在操作系统接口层面,只认文件描述符。用户层的 FILE* 只是标准库封装的结构体,真正发起文件操作时,最终都会下沉为基于 fd 的系统调用。
task_struct 是进程创建时才会生成的内核数据结构,每个进程对应一个,和文件创建操作无关;而在创建 / 打开文件时,内核会为文件创建对应的 struct file 对象,进程通过自身的文件描述符表,将 fd 与 struct file 建立关联,从而实现文件操作。
- 语言层为什么要做封装:为了语言的可移植性
语言层对系统调用进行封装,核心目的是为了实现跨平台可移植性。不同操作系统提供的原生系统调用接口存在差异,如果直接使用系统调用编写代码,程序将与平台强绑定,无法在不同操作系统间直接运行。
- OS 打开文件,本质就是在内核中创建一个 struct file 对象,其中包含文件模式(mode)、读写位置、读写选项、文件缓冲区,以及链表指针(struct file *next)等信息;操作系统会以链表的形式,将所有已打开文件的 struct file 对象统一管理起来。
- 进程通过 task_struct 中的文件描述符表 struct files_struct,通过 fd_array\[\] 数组索引到对应的 struct file 对象;对已打开文件的管理,本质就是对这条链表进行增删查改。
- 文件读写的本质,是用户空间与内核文件缓冲区之间的数据拷贝。
这些底层内核细节,被 C 标准库的 fopen/fread/write 等函数完全封装屏蔽,用户只需调用通用接口即可完成文件操作,无需关心不同平台的系统调用差异,从而实现跨平台可移植性。
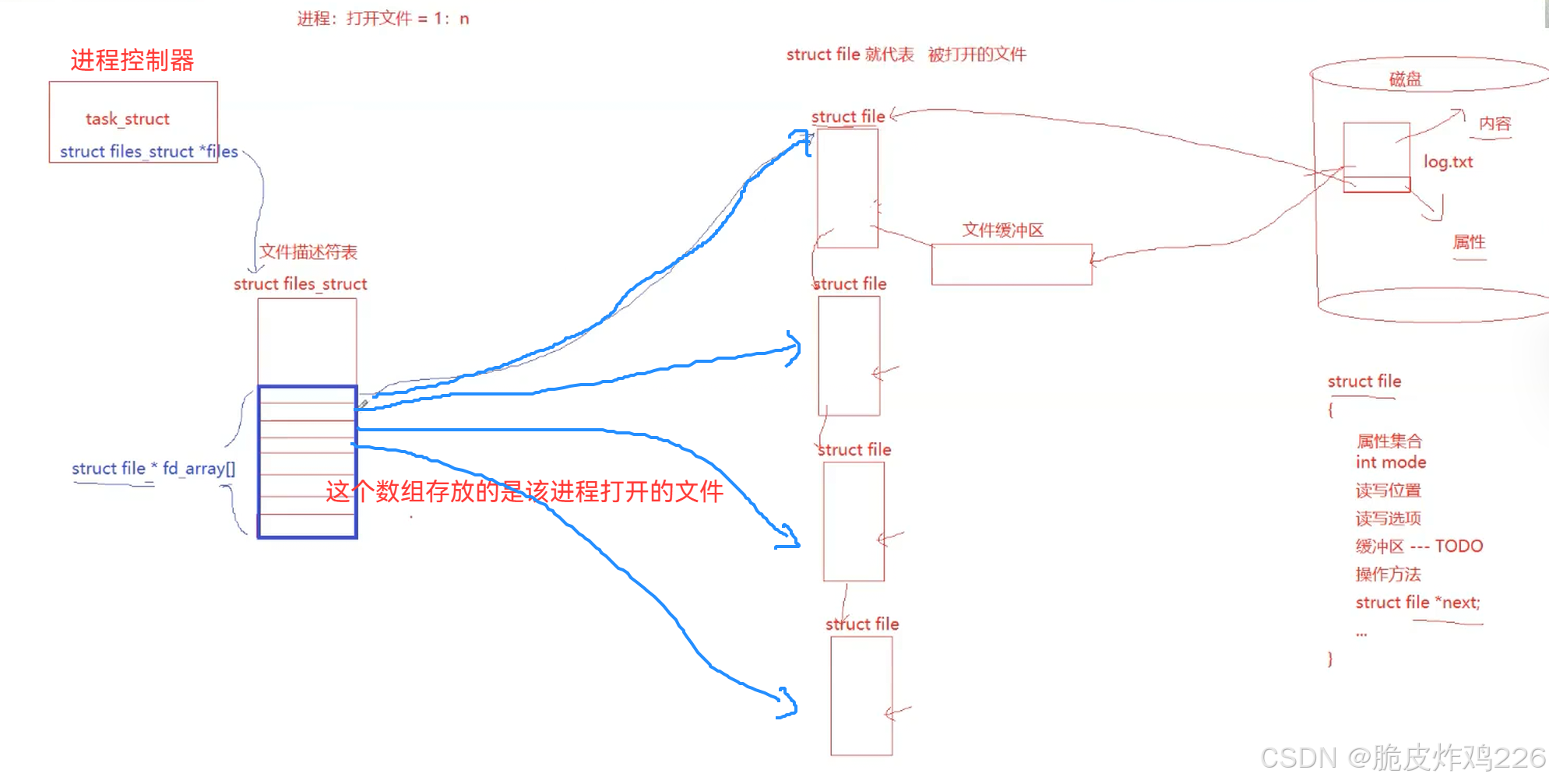
- 一个进程打开n个文件,怎么知道哪些文件和该进程相关?
进程在内核中除了 PCB(task_struct)、地址空间、页表外,还维护着一个文件描述符表 struct files_struct。这个表内部包含一个指针数组 fd_array\[\],数组里存放的是该进程所有打开文件对应的 struct file 对象的地址。
文件描述符(fd)本质上就是这个数组的下标 :
----下标 0、1、2 固定被标准输入、标准输出、标准错误占用;
----普通文件的描述符从 3 开始分配。
进程通过文件描述符(数组下标),就能快速索引到对应的 struct file 对象,从而关联和管理自己打开的所有文件。
想读取文件,当前进程调read(),需要传参数文件描述符fd,接着操作系统拿着fd索引文件描述符表fd_array\[\],由下标找对应的文件。每个文件都有文件缓冲区,假如我们想要读文件,OS将磁盘中的文件内容预加载到缓冲区,然后把缓冲区的内容拷贝到(用户层)read对应的缓冲区。所以read函数的本质是内核到用户空间的拷贝函数。
如果想对文件做修改(CPU是不和外设打交道的),所以先将文件内容读到缓冲区,在内存里修改,修改之后再写回到磁盘
对文件内容做任何操作,都必须先将内容加载到内核相对应的缓冲区【加载的本质:从磁盘到内存的拷贝】
重定向
重定向就是:修改程序原来的输入/输出文件(这里的输入/输出并不单指标准输入/标准输出)
输出重定向:原本要输出到显示器文件中的数据,我们让它输出到指定文件中
文件描述符的分配原则:从0开始去找一个最小且没有被使用的文件描述符,进行分配,0、1、2已经被三个标准流占用
">"是清空写入,">>"是追加写入
-
重定向原理:在内核层面 ,狸猫换太子(原本1代表着xxx,现在偷换,代表着yyy)
(上层不变,永远用0、1、2...数组下标;重定向改的是文件描述符表的指针的指向)
-
进行重定向的系统调用:打开文件的方式+
dup2重定向修改的是内核级的数据结构,用户没有权限,只能系统调用
 原本的1指向:标准输出。3指向log.txt的file*
原本的1指向:标准输出。3指向log.txt的file*现在想让1指向log.txt的file*,那就需要将file*拷贝给1。dup2的作用就是使用oldfd位置的值去覆盖newfd位置的值 ,把3的拷贝将1的覆盖,所以是dup2(旧,新),
dup2(3,1);

-
"ls -a -l > log.txt中,"ls -a -l"是需要分析的执行命令,"log.txt"是执行的文件 -
进程替换不会影响重定向的结果。进程替换是替换进程的代码和数据,而重定向操作系统内核的数据结构,并没有创建新进程,整套数据结构不变。所以'打开文件不影响',重定向后的文件也是我打开的文件。所以不影响
-
指令变成字符串被shell命令行给解释了,在解释时遇到了>符号来做判断:把命令,文件,重定向方式分出来,在程序替换之前先做重定向,然后子进程执行。就可以在子进程内部输入输出时,从指定的文件里读写
-
./a.out > log.txt

一会儿printf输出错误,一会儿又可以perror输出错误,不都是向显示器上打吗?
- printf:走标准输出(stdout),打普通消息
- perror:走标准错误(stderr),打错误消息
printf 与 perror 虽然都输出到终端,但分别对应标准输出和标准错误两个独立的文件流。
将标准输出与标准错误分离,目的是利用操作系统的重定向能力,实现常规消息与错误消息的分离存储 / 输出,让日志逻辑更清晰,便于问题排查与日志管理。
缓冲区
-
缓冲区(保存数据)
1.1缓冲区是什么:缓冲区是内存空间的一部分 ;简单来说就是在内存中预留一定的存储空间,这些存储空间用来缓存输入/输出数据。
1.2最大的功能:提高程序运行的效率({为什么要存在缓冲区呢,我们直接通过系统调用进行读写操作不行吗?如果没有缓冲区,每次读写时都要通过系统调用,但系统调用也是有成本的。}可以在语言层提供缓冲区,一兆的缓冲区满了(保存了10次),调用一次系统调用即可;若没有缓冲区则需要调用10次系统调用。频繁系统调用会导致程序效率低下)

-
write是系统调用,使用write系统调用,就算显示器文件被关闭了,内容还是可以写到显示器文件中。
17.1 标准输出是行缓冲,遇到换行就会调用系统调用,将缓冲区内容写入到显示器文件的缓冲区中。printf输出带\n时,内容就会刷新到文件缓冲区当中
-
全缓冲 区:整个缓冲区被写满时,会进行I/O系统调用操作。磁盘文件,普通文件
行缓冲 :当输入输出中遇到了换行符,就会执行系统调用操作。
无缓冲:立即刷新【不对字符进行缓存,直接调用系统调用】(标准错误stderr通过就是无缓冲的,这样错误信息能够立即刷新出来) -
语言层的缓冲区内容什么时候被写入到文件缓冲区中呢:fflush;当刷新条件满足(全缓冲、行缓冲、无缓冲);进程退出