预览
先说结论
做了一个完全本地运行的私人知识库应用,特点是:
- 不上传、不外传 --- 所有文档和对话都在本地处理
- 支持多种格式 --- PDF、Word、Excel、Markdown、TXT
- RAG 对话 --- 能和文档"聊天",回答附带参考来源
- 开箱即用 --- 自带模型管理,无需折腾配置
解决的问题
你有没有遇到过这些情况:
- 📎 把机密文档上传到在线 AI 服务,担心数据泄露
- 📚 有一堆文档,想快速找到某个知识点
- 🔍 需要从 Excel/Word 报告里提取信息,但懒得逐个打开
- 🤯 问 AI 关于自己文档的问题,结果它一本正经地胡说八道
PrivRAG 就是为了解决这些问题:把文档扔进去,然后像跟人聊天一样问问题。它会从你的文档里找答案,不会瞎编。
什么是 RAG?
RAG = Retrieval Augmented Generation(检索增强生成)
简单说就是:先把文档"喂给"AI 让它读懂,再回答问题。
传统方式:
- 把文档内容直接塞进 prompt
- 问题多了 prompt 装不下,而且 AI 容易"遗忘"前面的内容
RAG 方式:
markdown
1. 文档 → 分块 → 向量化 → 存入向量数据库
2. 用户提问 → 向量化 → 在数据库里找"最像"的几个片段
3. 把这些片段 + 问题一起喂给 LLM → 生成答案好处是:不管文档多大,都能找到最相关的内容,而不是把整篇都塞进去。
功能展示
文档导入
支持拖拽或点击上传,一次性处理多个文件:
- 📄 PDF(论文、合同、手册)
- 📝 Word(报告、方案、文档)
- 📊 Excel(表格、数据、报表)
- 📖 Markdown(笔记、教程)
- 📃 TXT(纯文本)
导入后自动分块、向量化,存进本地数据库。整个过程在本地完成,不需要联网。
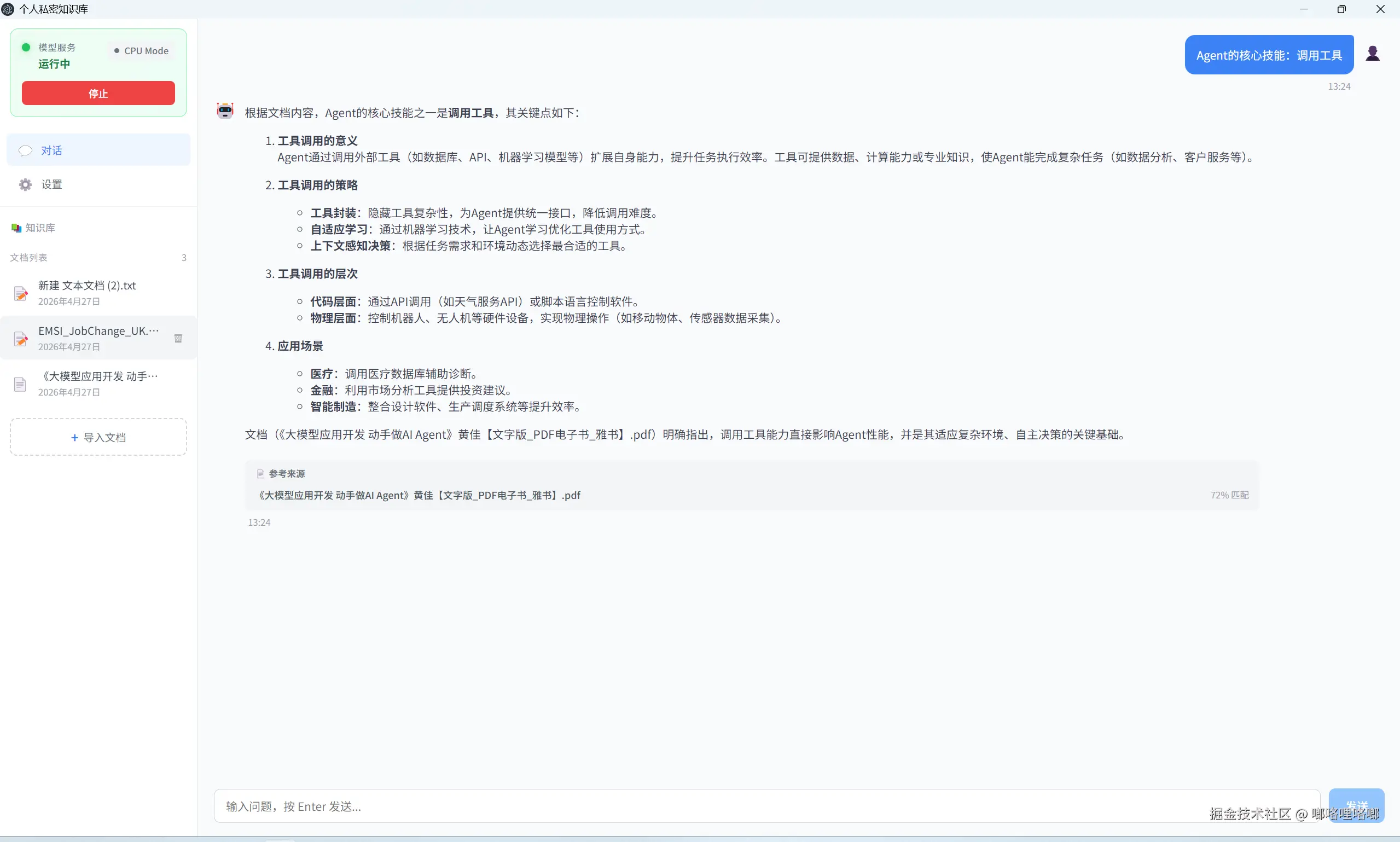
智能问答
问问题的方式很自然,比如:
- "这份合同的关键条款有哪些?"
- "对比一下这两个报告的营收数据"
- "关于 XXX 问题的解决方案是什么?"
回答会附带引用来源,标注这段话来自哪个文档、匹配度多少。方便你核实,也方便溯源。
流畅体验
- ⚡ 流式输出 --- 打字机效果,边生成边显示
- 🛑 随时中断 --- 回答不满意可以提前停止
- 📝 Markdown 渲染 --- 代码、表格、列表都能正常显示
- 🎨 原生体验 --- Electron 桌面应用,Windows/macOS/Linux 都能用
技术架构
技术栈
| 组件 | 技术 | 说明 |
|---|---|---|
| 桌面框架 | Electron 33 | 跨平台桌面应用框架 |
| 前端 | Vue 3 + TypeScript | 组合式 API 开发 |
| 构建工具 | electron-vite | 高速开发体验 |
| 状态管理 | Pinia | 轻量响应式状态 |
| LLM 推理 | llama.cpp (llama-server) | Qwen3-4B GGUF 量化模型 |
| Embedding | bge-small-zh-v1.5-gguf | 中文向量化,384 维 |
| 向量数据库 | LanceDB | 单文件、嵌入型,无需额外部署 |
| 文档解析 | pdf-parse / mammoth / xlsx | PDF/Word/Excel 支持 |
为什么选这些技术?
Qwen3-4B GGUF --- 4B 参数模型,量化后约 2.5GB,普通的 4GB 显存就能跑起来。没有 GPU?用 CPU 也能跑,只是慢一点。
LanceDB --- 嵌入式向量数据库,数据存在单个文件里,程序关闭再打开数据还在。不需要像 Milvus/Pinecone 那样单独部署服务。
llama.cpp --- C++ 实现的 LLM 推理,高效、跨平台、支持 GPU 加速。llama-server 把它包装成 HTTP 服务,前端直接调 API。
bge-small-zh-v1.5 --- 专门针对中文的 Embedding 模型,体积小(几十 MB)、速度快、效果不错。
工作流程
bash
┌─────────────────────────────────────────────────────────────┐
│ 文档导入流程 │
└─────────────────────────────────────────────────────────────┘
📄 PDF/DOCX/XLSX/MD/TXT
│
▼
┌──────────────────┐
│ 文档解析 │ 提取纯文本内容
│ DocumentProcessor │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ 文本分块 │ 512 字符/chunk
│ Chunking │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ Embedding 向量化 │ bge-small-zh-v1.5 (384维)
│ 本地 llama-server │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ LanceDB 存储 │ 向量数据库(本地文件)
└──────────────────┘
┌─────────────────────────────────────────────────────────────┐
│ 查询流程 │
└─────────────────────────────────────────────────────────────┘
用户提问:"这份合同的关键条款有哪些?"
│
▼
┌──────────────────┐
│ 问题向量化 │ bge-small-zh-v1.5
└────────┬─────────┘
│
▼
┌──────────────────┐
│ 向量相似度检索 │ Top-K 最相关 chunk
│ LanceDB IVF_PQ │
└────────┬─────────┘
│
▼
┌──────────────────┐
│ LLM 生成回答 │ Qwen3-4B GGUF
│ 拼接上下文 │
└────────┬─────────┘
│
▼
💬 回答 + 📄 引用来源安装即用
下载安装包(推荐)
前往 Releases 页面 下载最新版本,双击安装即可。
从源码运行
bash
# 克隆项目
git clone https://github.com/SpanManX/private-RAG.git
cd private-RAG
# 安装依赖
npm install
# 构建项目(初次必须先运行)
npm run build
# 启动开发模式
npm run dev
# 构建 Windows 安装包
npm run build:win环境要求
| 项目 | 最低要求 | 推荐配置 |
|---|---|---|
| 操作系统 | Windows 10 (64位) | Windows 11 |
| 内存 | 4 GB | 8 GB+ |
| 显存 | - | 4 GB+ (GPU 推理) |
| 磁盘 | 5 GB 可用空间 | 10 GB+ |
使用流程
1. 首次启动
首次启动会提示下载模型文件(约 3GB)。点击下载,等待完成。
注意:模型文件需要放在非中文路径下,建议使用默认路径。
2. 导入文档
点击侧边栏的"上传文件"按钮,或者直接拖拽文件到窗口。
支持多选,一次性导入多个文档。
3. 启动服务
点击侧边栏的"启动"按钮,启动本地 LLM 服务。
- 有 NVIDIA 显卡?会自动启用 GPU 加速
- 没有显卡?自动回退到 CPU 模式
4. 开始对话
在对话框输入问题,AI 会从你导入的文档里找答案。
回答完成后会显示引用来源,点击可以跳转到原文。
为什么做这个
市面上的 RAG 产品要么要联网、要么要付费、要么数据要上传到云端。
对于处理敏感文档(合同、报告、内部资料)的场景,本地运行是刚需。
我不想让我的文档被上传到任何地方,也不想每个月交订阅费。
所以干脆自己写了一个:完全免费、代码开源、数据不上传、一键启动。
项目地址
GitHub: github.com/SpanManX/pr...
觉得有用的话,给个 ⭐ 吧~
常见问题
Q: 需要联网吗? A: 不需要。模型文件下载一次后就离线可用了。
Q: 没有显卡能用吗? A: 可以用 CPU 模式,只是推理速度会慢一些。
Q: 文档安全吗? A: 所有处理都在本地完成,没有任何数据会上传到服务器。
Q: 支持 Mac/Linux 吗? A: 代码层面支持,但目前 Release 只有 Windows 版本。需要的话可以自己编译。