1. 什么是 Function Calling ?原理是什么?
Function Calling 我的理解是这样一套机制:开发者用 JSON schema 把工具描述好传给模型,模型判断需要调工具的时候不输出自然语言,而是直接输出一段结构化的 tool_calls JSON,告诉你「我要调哪个函数、参数是什么」,你的代码拿到这段 JSON 去真正执行,把结果塞回对话,模型再生成最终答案。
整个流程本质上是两轮对话:第一轮模型说「我需要调这个工具」,你去执行,第二轮模型拿到执行结果说「答案是这个」。
我觉得最核心的设计是,模型全程只做决策,
背景,Function Calling 解决了什么问题
LLM 在没有 Function Calling 之前,想让模型帮你调工具,完全靠解析自然语言。模型输出「我需要查一下北京的天气」,你再写 if/else 判断它「说」的是要查天气,然后手动去调 API。这个做法极其脆弱,模型换个说法,你的 if/else 就失配了,也根本没办法标准化。
执行的事情一律由宿主代码完成,职责分得很清楚。
Function Calling 的出现把这件事固定下来了:模型不再「说」要调工具,而是直接输出一段结构化的 JSON,开发者按格式解析就行,准确率大幅提升,也有了统一标准可以对接。这套机制由 OpenAI 在 2023 年推出,现在 Claude、Gemini、Qwen 等主流模型都支持。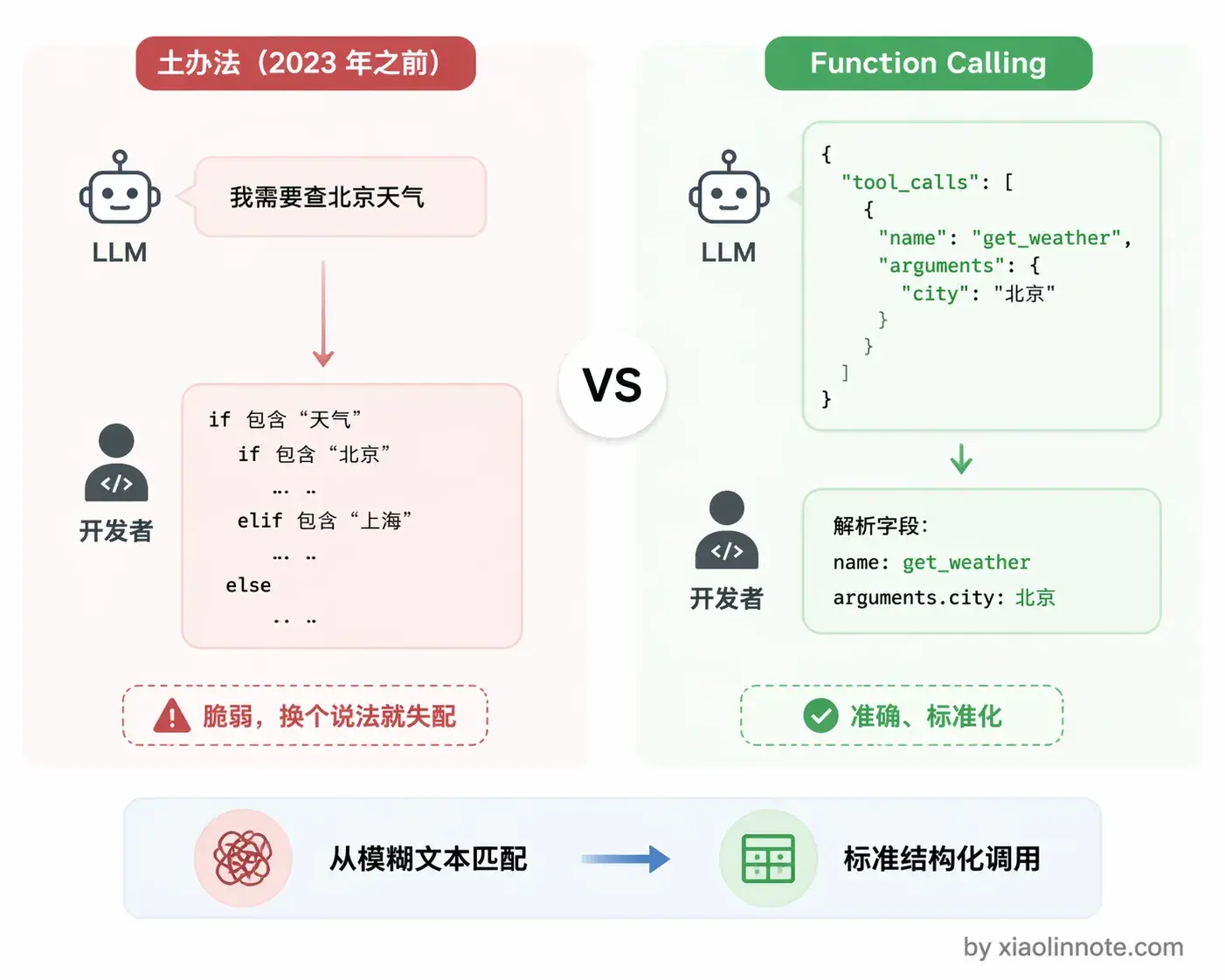
三个角色,把 Function Calling 理解成一场任务委托
理解 Function Calling 的关键是搞清楚谁做什么。可以把这套流程理解成一场「任务委托」: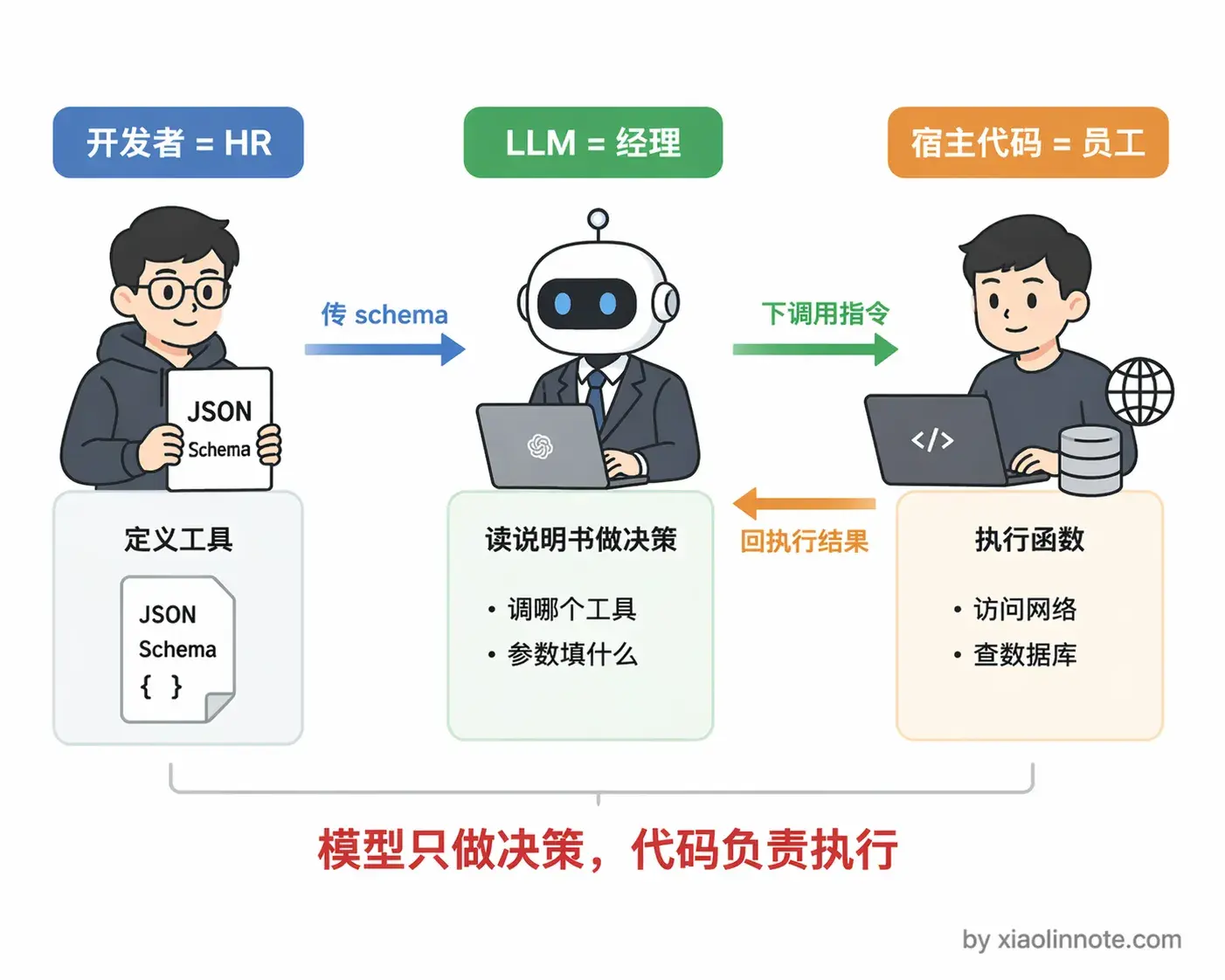
开发者是 HR,负责给每个工具写「职位说明书」,就是 JSON schema,告诉模型「我们有哪些工具、每个工具能做什么、需要哪些参数」。模型是经理,读完说明书之后决定「这个任务需要调哪个工具、参数填什么」,然后把指令下达出来。你写的代码是员工,真正去跑函数、访问网络、查数据库,把结果汇报回来。
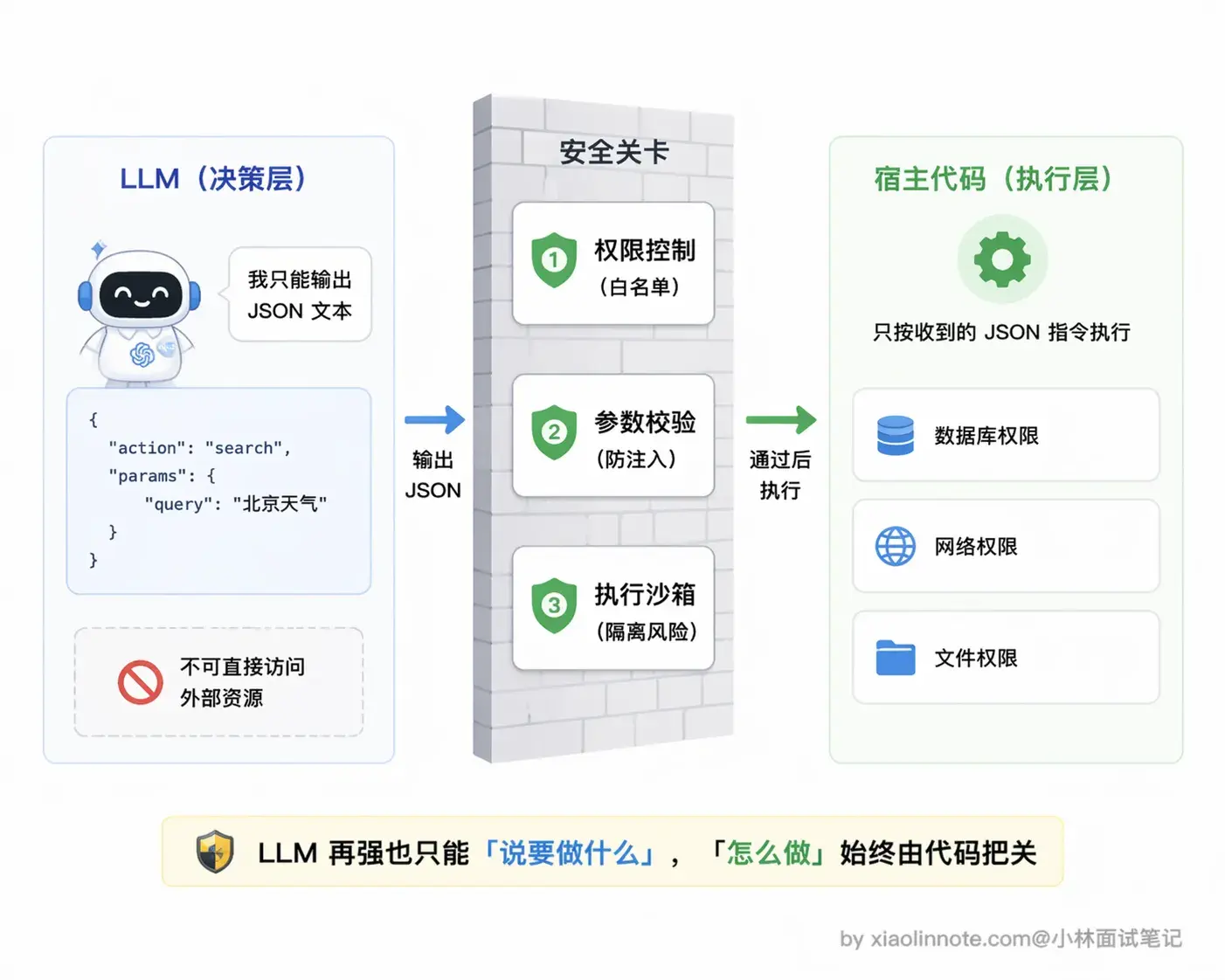
关键点:模型全程只是在「下指令」,它不亲自执行任何代码,也没有直接访问网络的权限。执行的事一律由宿主程序代码完成,这个分工要想清楚。
工具定义,schema 的每个字段都有含义
工具 schema 就是一份结构化的「工具说明书」,用 JSON 格式写,告诉模型这个工具叫什么、能做什么、需要哪些参数。
tools = [
{
"type": "function",
"function": {
"name": "get_weather", # 工具的唯一标识,模型输出 tool_calls 时会用这个名字
"description": "查询指定城市的实时天气,包含气温、天气状况、风向风速,仅支持中国大陆城市",
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如「北京」「上海」,不要带省份前缀"
},
"unit": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "温度单位,默认用摄氏度"
}
},
"required": ["city"]
}
}
}
]其中最关键的字段是 description。这里停一下,你想一个问题:如果 description 写得含糊,模型会怎么表现?答案是它会「瞎猜」,比如你只写「获取天气」,模型可能拿到一个带英文名的城市也照样调,拿到「这周天气如何」这种时间跨度不对的问题也硬往里塞,调完之后发现返回的数据根本对不上。模型在决定「要不要调这个工具、参数怎么填」的时候,能依赖的唯一依据就是这段描述。
你可以对比一下:「获取天气」和「查询指定城市的实时天气,包含气温、天气状况、风向风速,仅支持中国大陆城市」,对模型判断准确率的影响差距是很明显的。写得越清晰,模型的选择越准确。参数的 description 同理,格式要求、示例值、限制条件都要写进去,模型才能正确填写参数。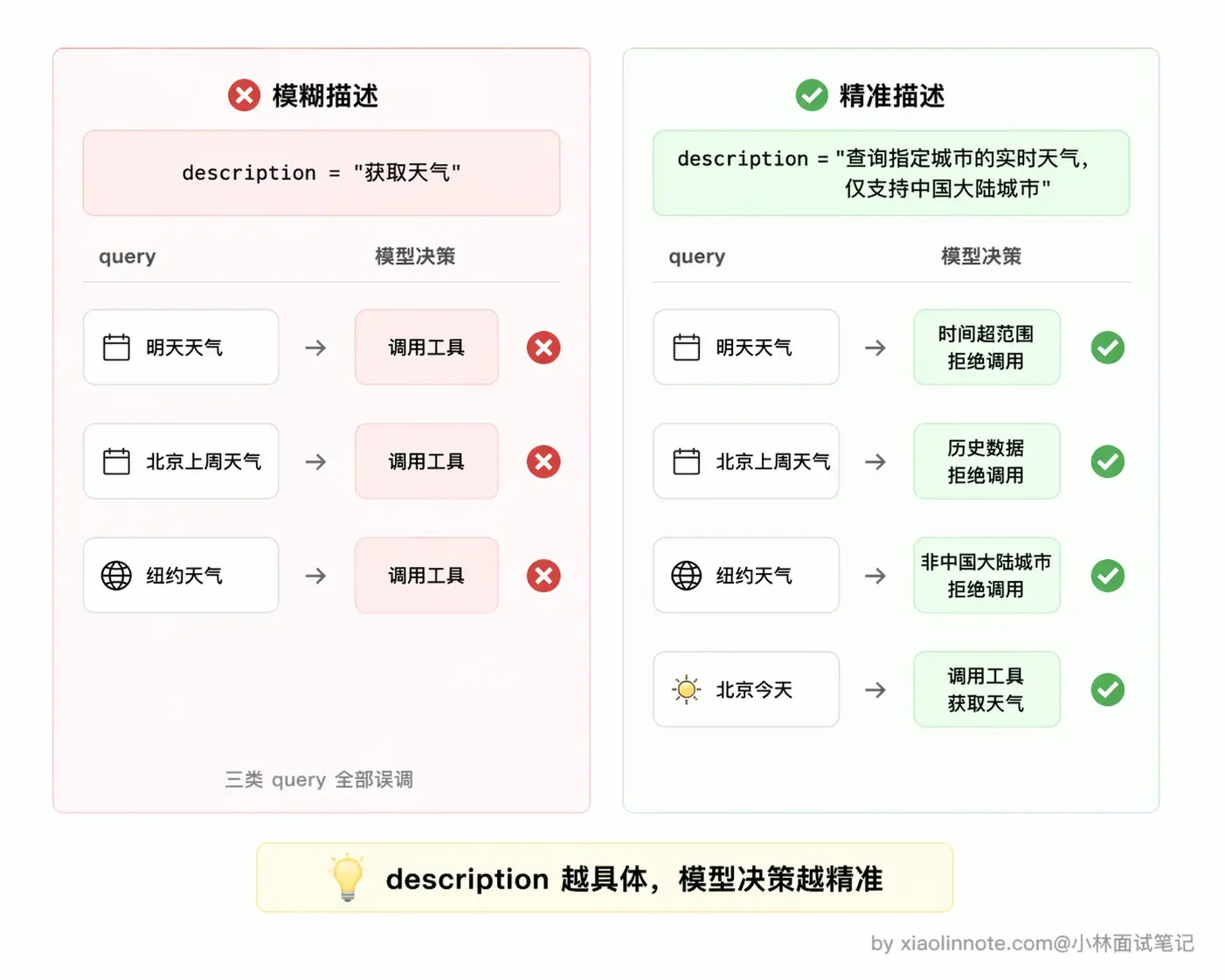
完整的调用流程,两轮对话加中间执行
Function Calling 的运行时本质上是「两轮对话 + 中间执行」的闭环。
第一轮,你把工具列表和用户的问题一起传给模型。模型读完之后,如果判断需要调工具,就不直接输出最终答案,而是输出一个 finish_reason 为 "tool_calls" 的响应,里面包含要调用的工具名和参数,这是个明确信号,告诉你「我需要工具帮助,还没准备好给答案」。
拿到这个信号之后,中间环节就交给你的代码了。你的代码解析 tool_calls 拿到函数名和参数,找到对应的函数跑一下,拿到执行结果。
然后进入第二轮,把工具执行结果以 role: "tool" 的消息塞回对话历史,再次调用模型。这次模型有了工具结果,有了充分信息,才给出最终的自然语言答案。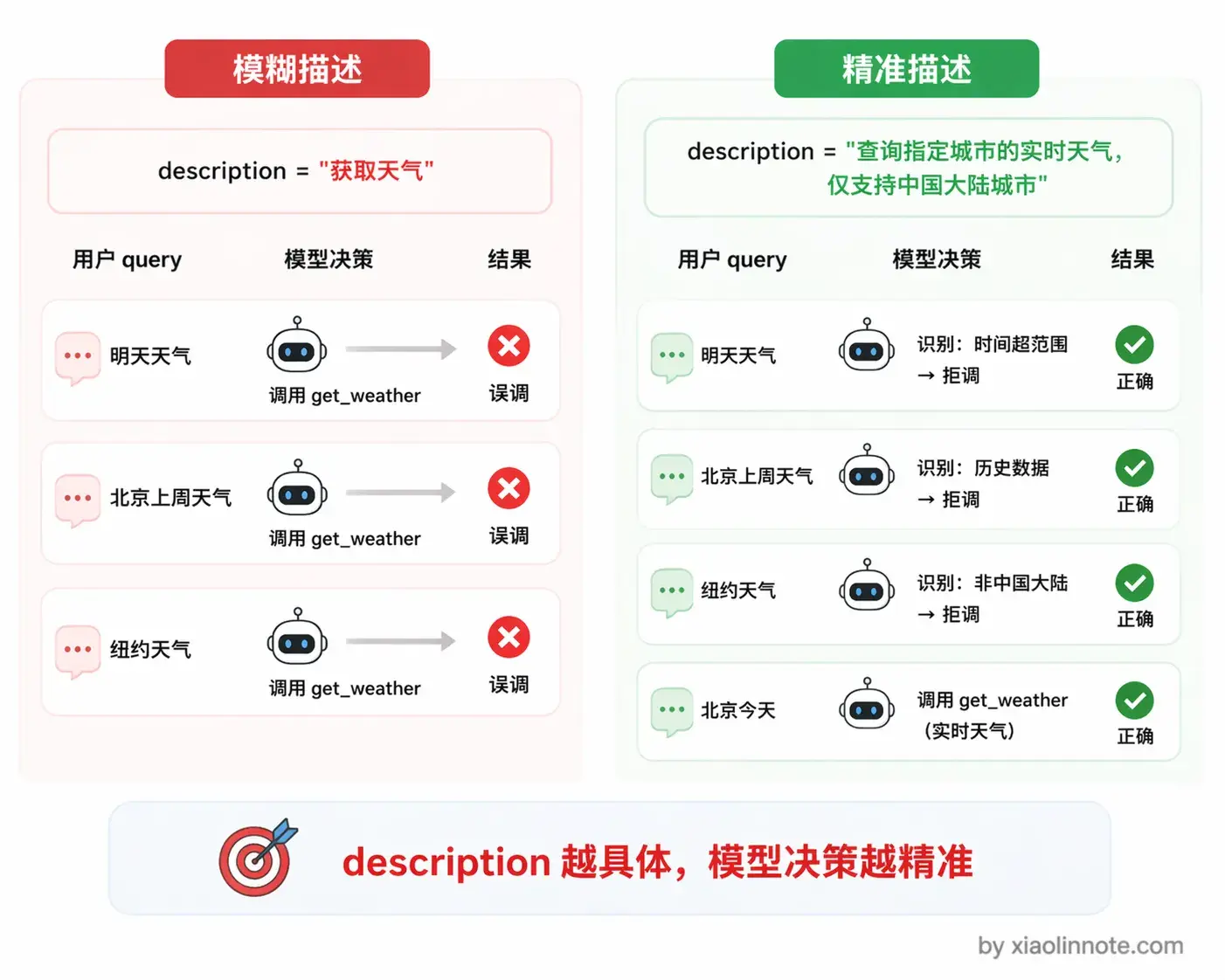
import openai, json
client = openai.OpenAI()
messages = [{"role": "user", "content": "北京今天天气怎么样?"}]
# 第一轮:把工具定义和问题一起传给模型
response = client.chat.completions.create(
model="gpt-4o",
messages=messages,
tools=tools,
tool_choice="auto" # auto 让模型自己判断要不要调,也可以设 required 强制调
)
msg = response.choices[0].message
if msg.finish_reason == "tool_calls": # 模型要调工具,还没给最终答案
tool_call = msg.tool_calls[0]
func_args = json.loads(tool_call.function.arguments) # {"city": "北京"}
# 中间执行:你的代码真正去跑函数
result = f"{func_args['city']}今天晴,15°C,东北风 3 级"
# 第二轮:把工具结果塞回对话,再问一次模型
messages.append(msg)
messages.append({
"role": "tool",
"tool_call_id": tool_call.id, # 和 tool_calls 里的 id 对应
"content": result
})
final = client.chat.completions.create(model="gpt-4o", messages=messages, tools=tools)
print(final.choices[0].message.content)
# 输出:北京今天天气晴朗,气温 15°C,东北风 3 级,适合外出。并行工具调用
看完单个工具的流程,再来想一个问题:如果用户一口气问了好几件事,比如「帮我查北京、上海、广州三个城市的天气」,模型一次该调一个工具,还是可以同时调多个?这就要说到 Function Calling 的并行调用设计。
当用户的问题需要多个工具才能回答时,模型可以在一次响应里同时输出多个 tool_calls,tool_calls 是个列表,不只有一条。比如用户问「帮我查北京和上海的天气」,模型会一次返回两个调用请求,分别对应两个城市。
为什么要这么设计?你想一下,如果没有并行调用,模型先说「我要查北京天气」,你执行完喂回去,模型再说「我要查上海天气」,又一轮对话,这样两个工具串行要跑两轮,每一轮都有一次模型推理和一次工具执行的延迟,总耗时很长。有了并行调用,模型一次把两个调用请求都输出来,你的代码可以同时执行这两个工具(比如用 Python 的 asyncio.gather 或者多线程),拿到所有结果后一次性塞回对话,再调一次模型就拿到综合了多个工具结果的最终答案。整个过程从「两轮对话」压缩成了「一轮对话 + 并行执行」,总耗时大幅降低。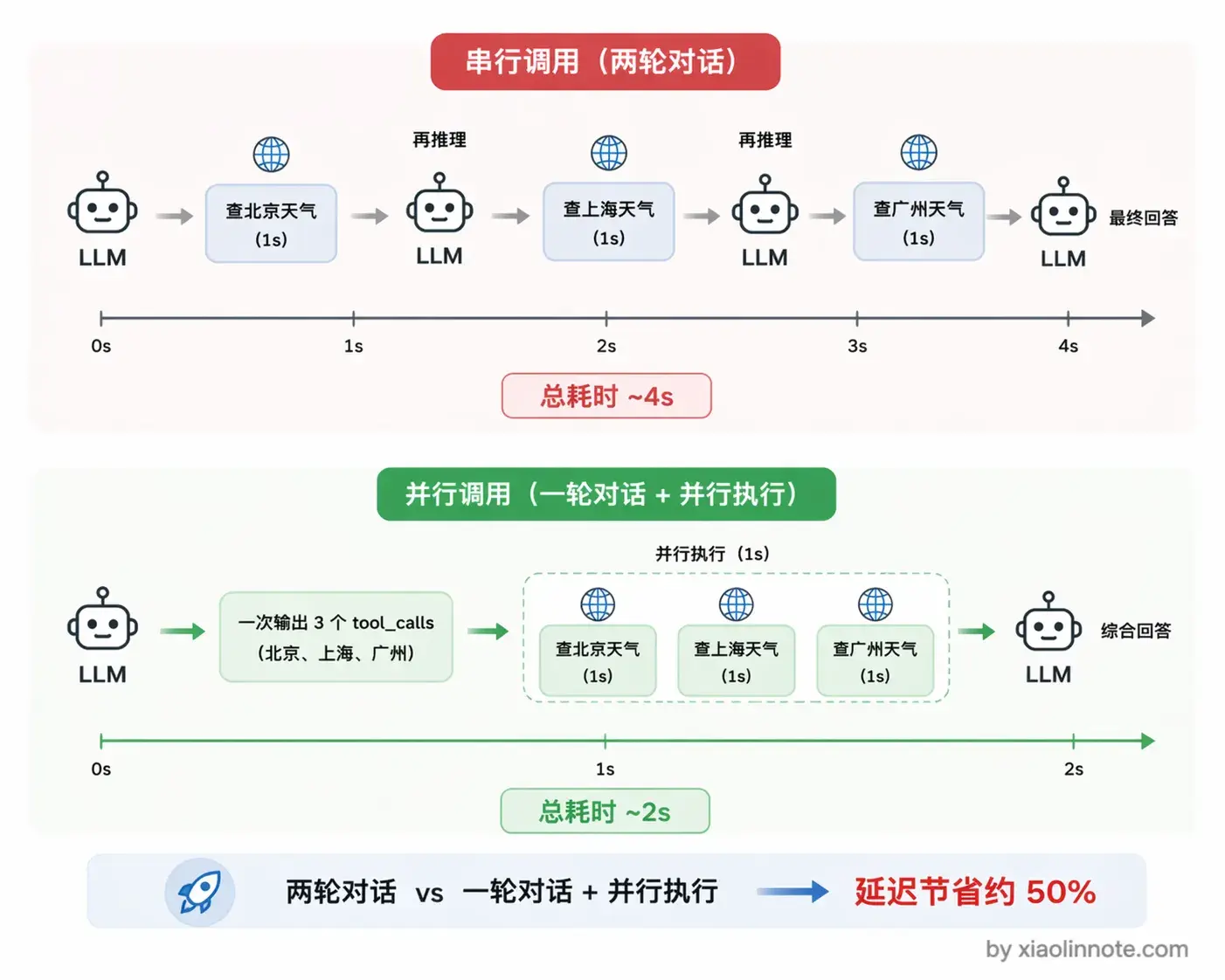
不过要注意一点,并行调用的前提是这几个工具之间没有依赖关系。
查北京天气和查上海天气互不影响,可以并行;但如果是「先查用户的订单号,再用订单号去查物流」,第二个调用依赖第一个的结果,这种就只能串行,模型也会正确地分两轮来输出。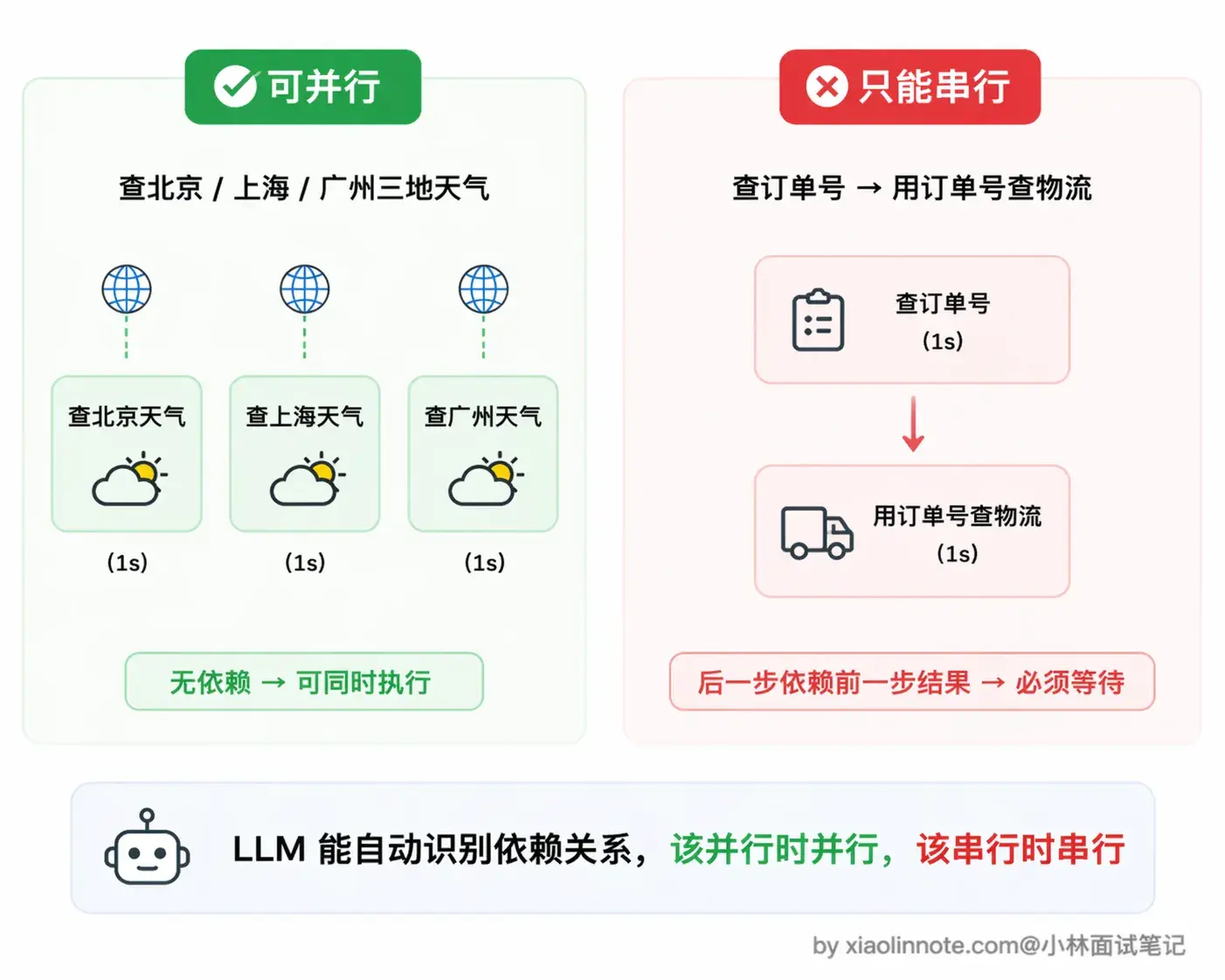
第一个误区是以为模型能「自己」去访问网络、执行代码,这是对 Function Calling 最常见的误解。面试时一定要强调:模型全程只负责决策,输出结构化的 JSON 调用请求,真正执行工具的是你的宿主程序代码,这个职责分工是整个机制的核心设计。
第二个误区是把 Function Calling 和之前靠解析自然语言调工具的「土办法」搞混了,Function Calling 的关键改进就是模型直接输出结构化 JSON 而非自然语言,让工具调用有了统一标准。
面试回答这道题,有几个点必须说到:工具定义用 JSON schema 描述,description 字段是模型判断是否调用的核心依据;运行时是「两轮对话 + 中间执行」的闭环流程;模型通过 finish_reason 为 tool_calls 来明确告知需要工具帮助;以及模型支持一次返回多个 tool_calls 实现并行调用。
把这几个点讲清楚,再强调「模型决策、代码执行」的分工原则,这道题就稳了。
2. LLM 是如何学会调用外部工具的?
这道题我分两块来讲:模型怎么被训练出工具调用能力,以及训练好之后运行时是怎么工作的。
训练层面靠两个阶段:
- SFT(监督微调,Supervised Fine-Tuning):给模型喂大量「工具调用示范对话」,让它通过模仿学会「看到工具描述 -> 判断要不要调 -> 输出结构化 JSON 请求」这整套流程;
- RLHF(基于人类反馈的强化学习,Reinforcement Learning from Human Feedback):收集人类对「哪种回答更好」的判断,训练一个打分器,再用这个分数反复调整模型,让它学会什么时候不应该调工具。
运行层面,每次请求时,你的应用代码把工具描述(叫 schema,可以理解为工具的说明书)传给模型,模型如果判断需要工具,就输出一段结构化的 tool_calls JSON;你的代码拿到这段 JSON 去真正执行,把结果塞回对话,模型再给出最终答案。
有一点非常关键:模型全程只是在「下指令」,真正执行工具的是你的代码,不是模型本身。这套「模型决策、代码执行」的运行时机制,就是我们常说的 Function Calling。
原始 LLM 的世界,为什么不会调工具
想象一个人从出生到成年,只生活在文字的世界里,读过几乎所有的书,却从没接触过任何工具,没用过锤子、没开过车、也没见过 API 是什么。你突然跟他说「去帮我查一下天气 API」,他最多只会用语言描述「我需要查天气 API 来获取数据......」,绝对不会真的去操作工具。
大语言模型在预训练阶段经历的就是这样一个过程,学的是给定前面的文字预测下一个 token(token 可以理解为模型处理文字的最小单位,大致对应一个字或半个词),整个训练过程完全是在文本空间里进行的,模型从未见过「工具调用」这件事。所以哪怕你在 prompt 里写「你可以调用天气 API」,没经过专门训练的模型也只会生成一段自然语言描述,比如「我需要调用天气 API 来回答你」,而不是输出一段可以被程序解析的 JSON 调用请求。
工具调用能力不是天生的,是后天「教」出来的。怎么教?靠两个阶段:SFT 教会怎么调,RLHF 教会什么时候调 。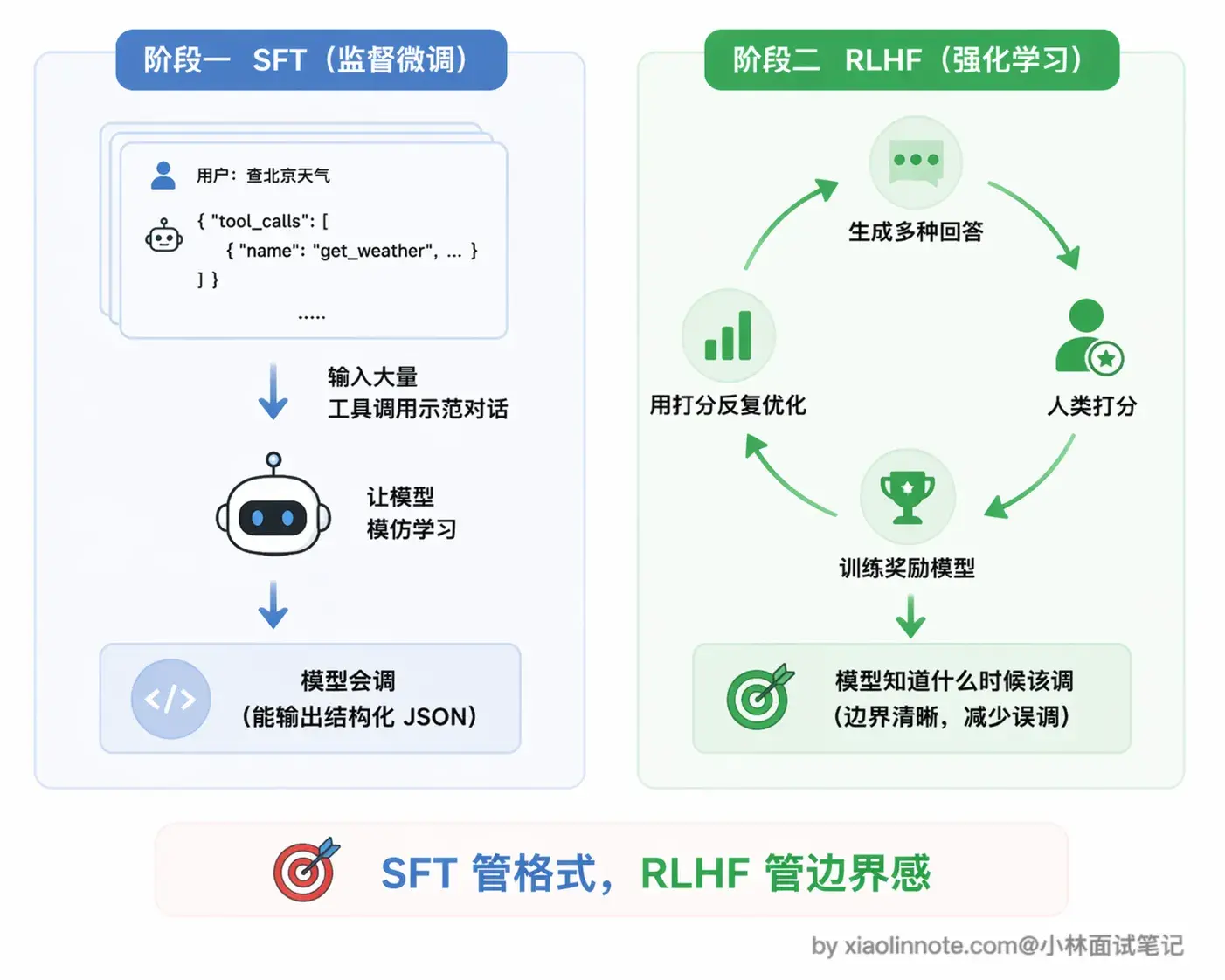
第一阶段:SFT,让模型「见过」工具调用
SFT 是 Supervised Fine-Tuning(监督微调)的缩写,核心思路非常直接:给模型看大量正确的示例,让它学会模仿。就像培养一名新员工,前期让他看几百份填好的工单,他自然就学会了「遇到这类问题该怎么写工单、该走哪个流程」。
要让模型学会工具调用,就要构造专门的训练数据。一条完整的训练样本长这样:
首先是 System 消息 ,也就是工具说明书,列出模型现在有哪些工具可用,每个工具叫什么名、能做什么事、需要什么参数,模型从这里「认识」工具。接着是 User 消息,就是用户的提问,比如「北京今天天气怎么样?」。
然后到了最关键的部分:Assistant 的调用请求 。注意,这里的「正确答案」不是自然语言回答,而是结构化 JSON,类似 {"tool_calls": [{"name": "get_weather", "arguments": {"city": "北京"}}]}。这就是模型需要学会输出的东西。为什么是 JSON 而不是自然语言?因为 JSON 格式固定、机器好解析,你的代码才能准确读到「调哪个工具、参数是什么」。
再往后是 Tool 消息 ,模拟工具返回的数据,比如「晴,15°C,东北风3级」。最后是 Assistant 的最终回答 ,模型看到工具结果后,给出自然语言答案:「北京今天天气晴朗,气温15°C......」。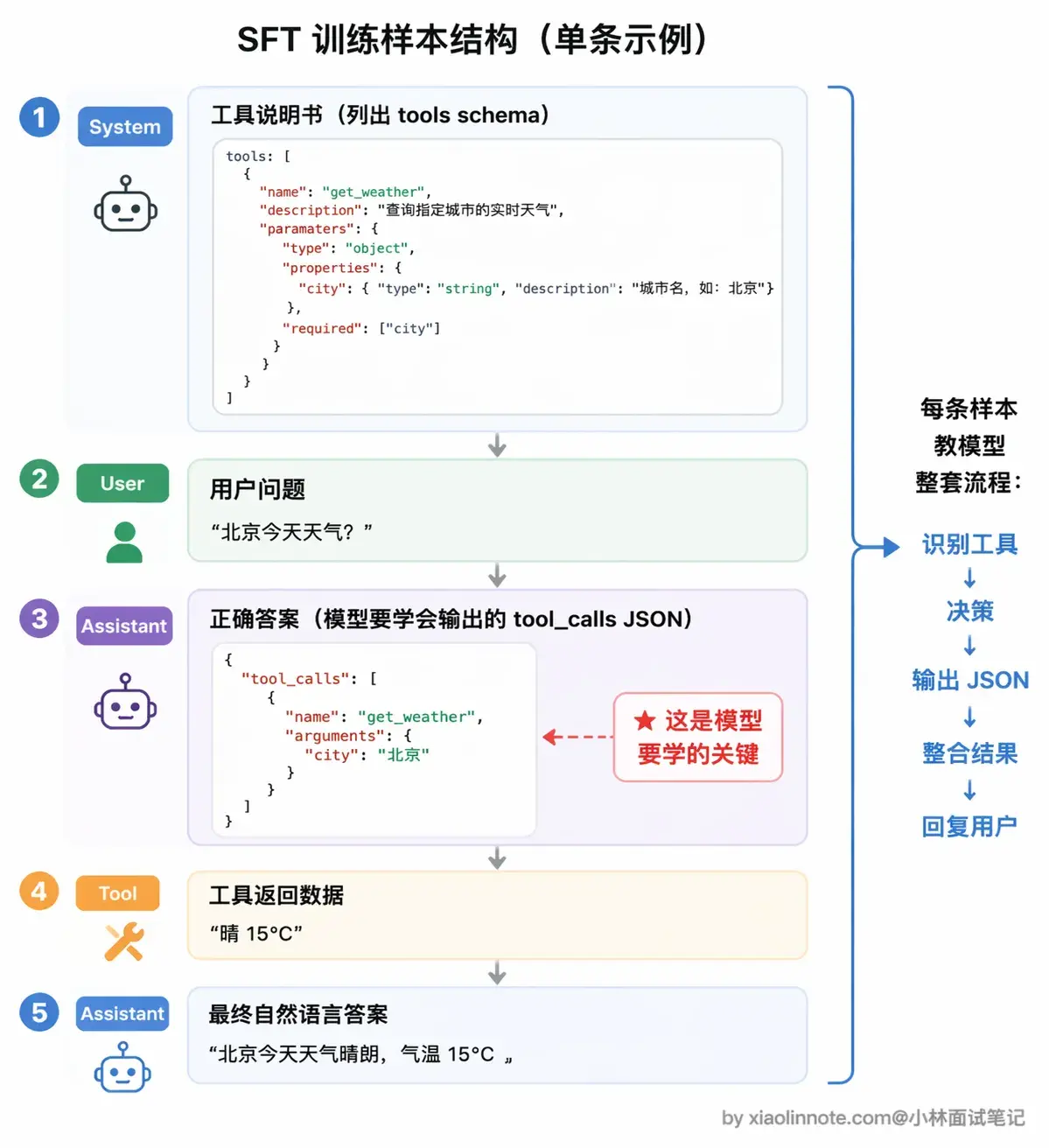
模型在几十万甚至上百万条这样的样本上反复训练,就学会了整套流程:识别工具定义、判断要不要调、输出格式规范的 JSON 请求。
训练数据的来源通常有两种:人工标注,成本高但质量好,一般用于构造核心的种子数据;用更强的模型(比如 GPT-4)自动批量生成,再人工抽查,成本低、量大,是业界现在的主流做法。
SFT 的短板,会了,但不知道「该不该调」
SFT 让模型学会了「调工具」这个动作,但它不知道什么时候该调、什么时候不该调。你可以想象一个刚培训完的新员工,过于热情,每件事都想走流程,有人问他「1+1 等于几」,他也要去查手册,这明显多此一举,直接回答就行。
为什么会这样?因为 SFT 的训练样本里,「该调的场景」占了绝大多数(毕竟我们就是要教它调工具),模型在模仿的过程中会过拟合这种「积极调用」的倾向,没看过足够多的「不该调」反例。再加上训练信号只告诉它「这是正确答案」,没有告诉它「为什么不该调也是一种正确」,所以它的边界感天然就弱。
SFT 之后的模型也有类似的毛病:可能对简单问题也尝试调工具,或者遇到工具调用失败时不知道该怎么处理,行为边界感很弱。
这个问题,需要第二阶段的 RLHF 来解决。
第二阶段:RLHF,用反馈建立边界感
RLHF 是 Reinforcement Learning from Human Feedback(人类反馈强化学习)的缩写。如果说 SFT 是让新员工看示例学规范,那 RLHF 就是老板持续给他的工作表现打分,帮他建立判断力。
它的流程分四步: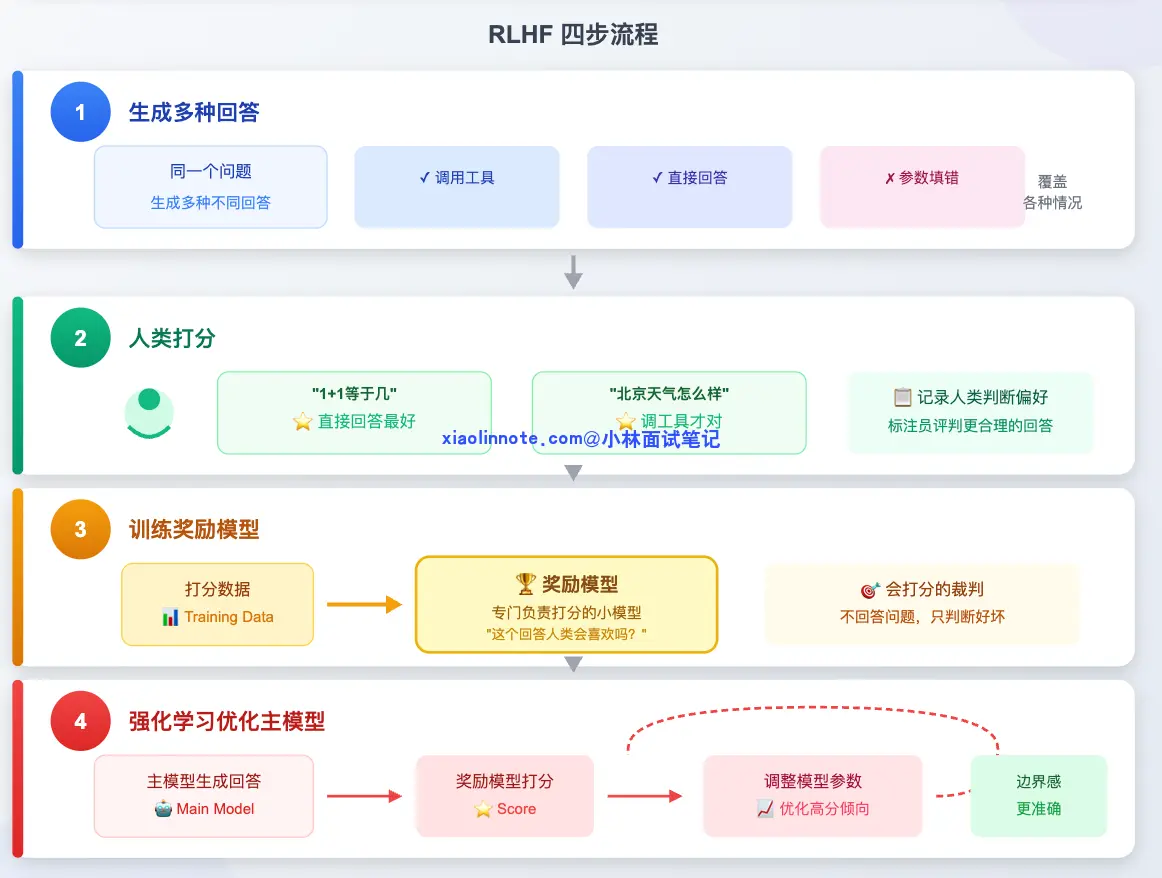
第一步是生成多样回答。对同一个问题,让模型生成几种不同的处理方式,有的调了工具,有的直接回答,有的参数填错了,故意覆盖各种情况。
第二步是人类打分。标注员评判哪种回答更合理,比如「1+1 等于几」直接回答最好,「北京天气怎么样」调工具才对。这批打分数据就记录了人类的判断偏好。
第三步是训练奖励模型。用这批打分数据,单独训练一个小模型,专门负责打分,它不回答问题,只判断「这个回答人类会喜欢吗」。你可以把它理解成一个「会打分的裁判」。
这一步很关键,也容易被忽略:奖励模型的打分能力本身就是从人类标注员的偏好数据里学出来的,换句话说,人类的判断被「蒸馏」进了这个裁判。所以如果人类标注员自己水平不稳定、标准不一致,奖励模型就会学到一个歪的打分标准,后面主模型再怎么被它优化,方向也是歪的。
第四步是用强化学习优化主模型。拿奖励模型的打分不断调整主模型的参数,让主模型越来越倾向于产出「高分回答」,也就是边界感更准确的工具调用行为。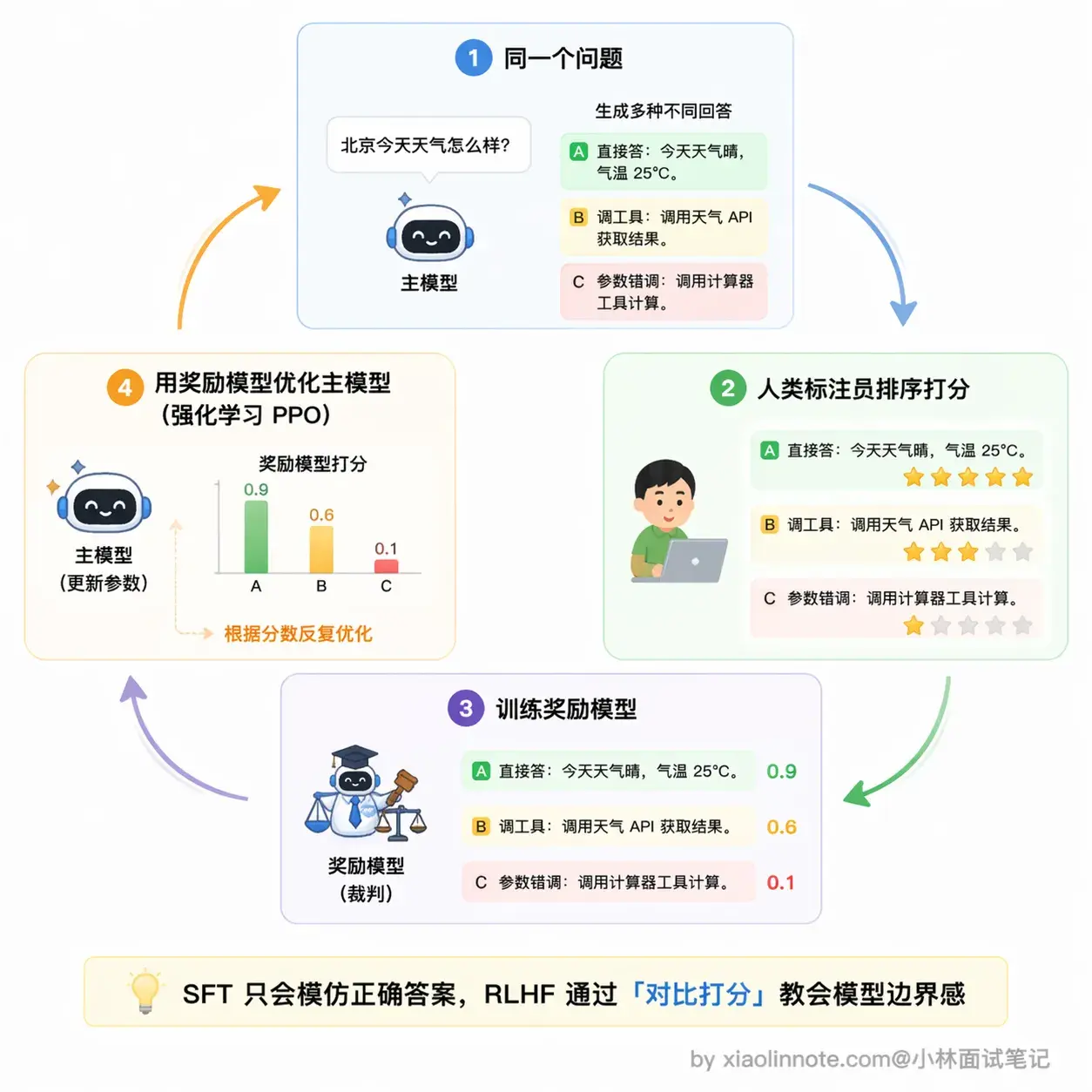
经过这个过程,模型逐渐学会了更微妙的判断:能直接回答的就直接回答,不要多此一举调工具;需要实时数据、需要执行操作的,才去调。这个边界感是 SFT 给不了的,必须靠反馈信号来塑造。
RLAIF(AI Feedback)是 RLHF 的变体,用另一个 AI 代替人类标注员打分,成本更低、速度更快,现在业界也很常用,效果和人工反馈相差不大。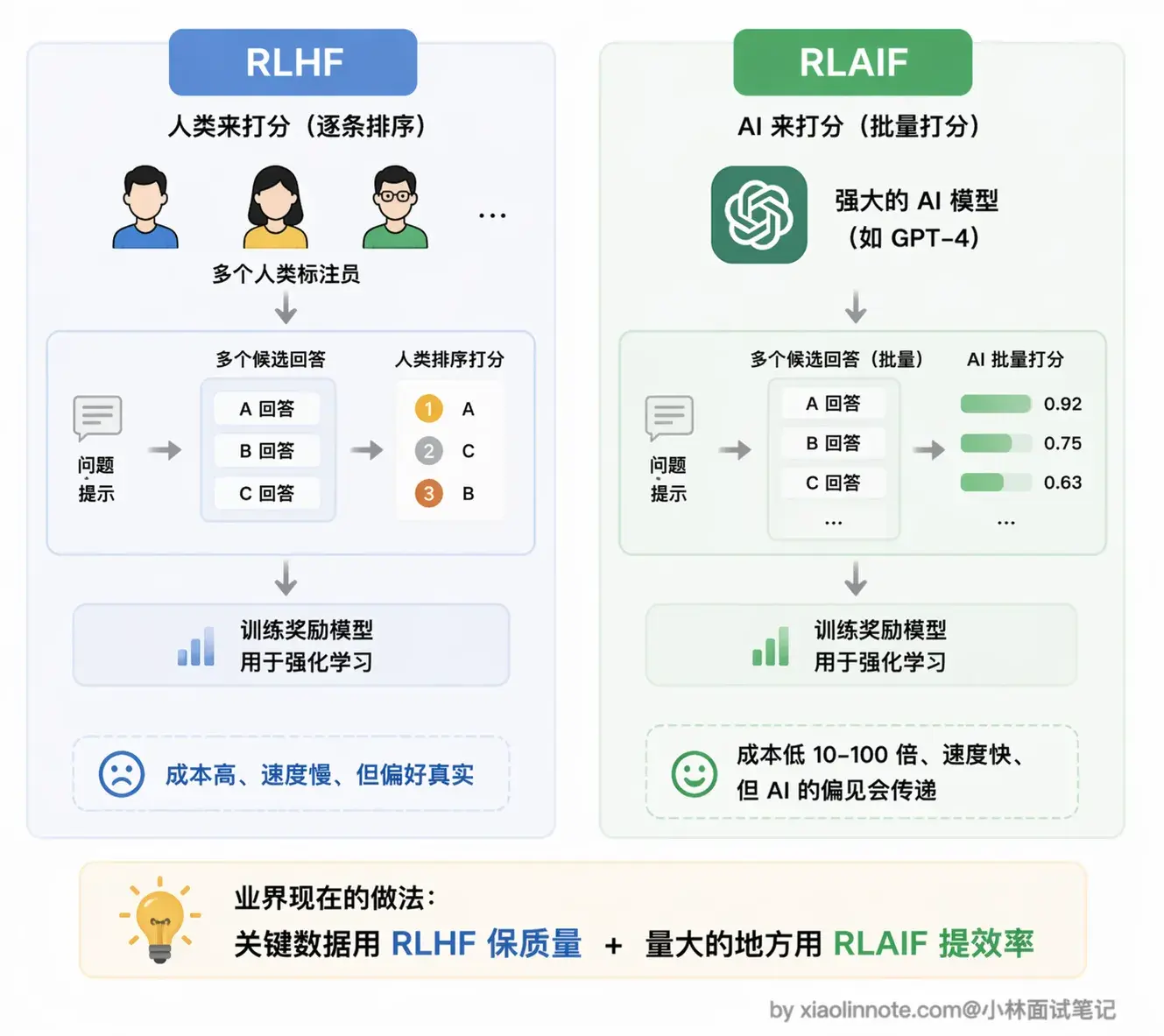
运行时,训练好之后怎么用
训练阶段结束,模型上线了。每次你的应用调用模型时,流程是这样的: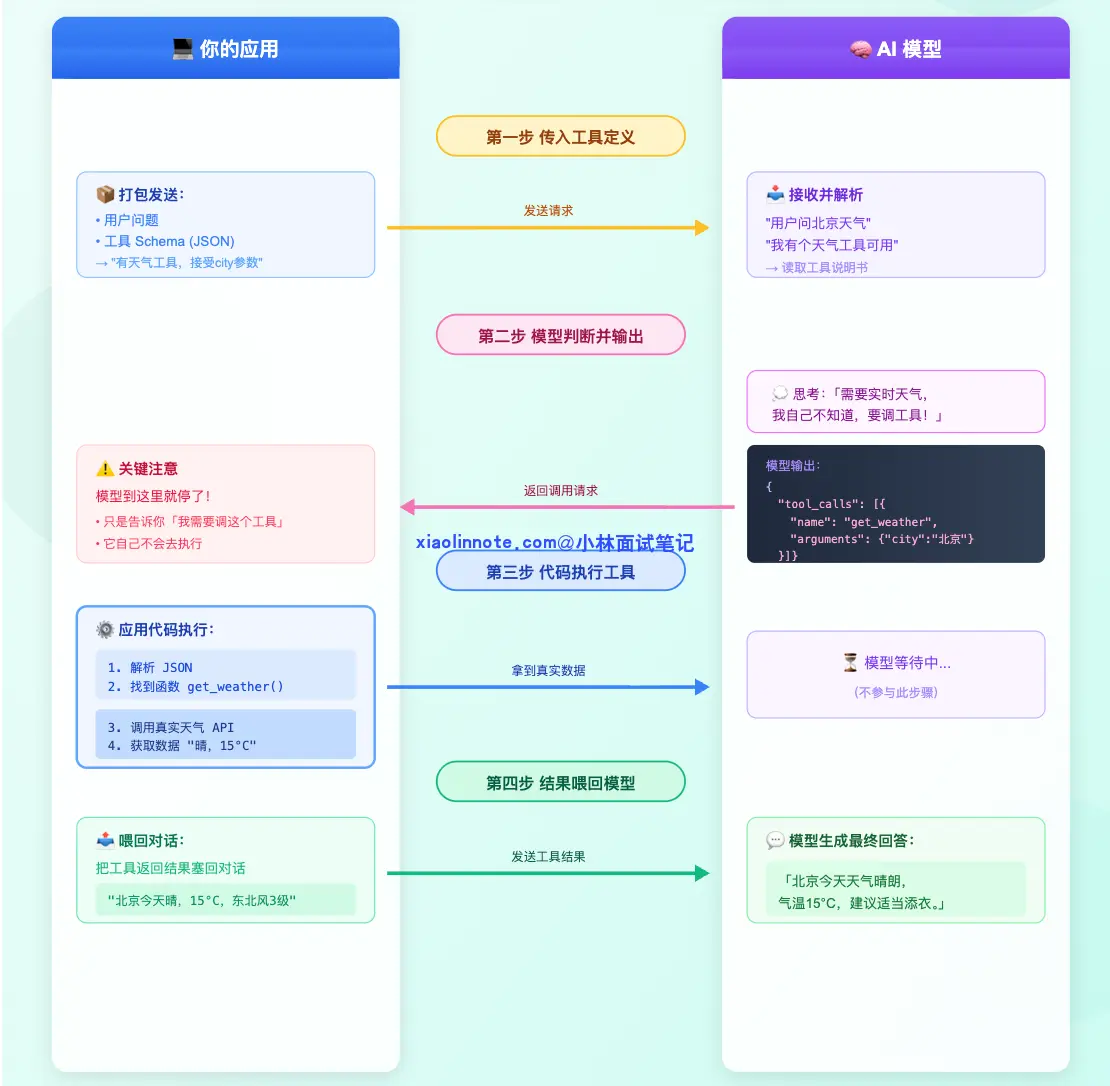
首先,你的应用代码把「有哪些工具可用」打包成 JSON 格式(叫做 schema,也就是工具的说明书),连同用户的问题一起发给模型。比如告诉模型:「你现在有一个天气查询工具,接受 city 参数,返回该城市的实时天气。」
模型读完工具定义和用户问题后,做了一个判断:这个问题需要查实时天气,我自己不知道,需要工具帮忙。于是它不直接回答,而是输出一段结构化的 JSON:
{
"tool_calls": [{
"name": "get_weather",
"arguments": {"city": "北京"}
}]
}模型到这里就停了,它只是告诉你「我需要调这个工具,参数是这个」,它自己不会去执行。
接下来就轮到你的代码上场了。你的应用代码解析这段 JSON,找到对应的函数,真正去调天气 API,拿到实际数据。
拿到结果之后,你把工具返回的结果(比如「北京今天晴,15°C,东北风3级」)塞回对话历史,再次调用模型,模型这才组织成一句话回答用户。
这套「模型输出结构化调用请求 -> 代码执行 -> 结果喂回」的机制,有一个专有名词:Function Calling。换句话说,Function Calling 就是大模型工具调用能力在运行时的具体实现形式。
一个关键认知:模型只负责「决策」,不负责「执行」
这是理解工具调用最重要的一点。
模型在整个过程中只做了一件事:判断要调哪个工具、参数填什么,然后把这个决策用 JSON 格式输出出来。真正去跑函数、访问网络、查数据库的,是你写的宿主程序代码。
这个分工设计得很合理:LLM 擅长理解意图和推理,但不应该有直接操作系统资源的权限;宿主程序负责执行,可以做权限控制、参数校验、执行沙箱等安全措施。这样的设计让工具调用既灵活又安全,是目前主流工具调用框架的核心设计原则。