目录
[二、top - k 问题](#二、top - k 问题)
一、向下调整算法
1、向上调整算法建堆
排升序 - 建大堆
排降序 - 建小堆
vodi HeapSort(int * arr, int n) { //建大堆 - 向上调整算法建堆 for(int i = 0;i < n;i++) { AdjustUp(arr,i); } //堆排序 int end = n-1; while(end>0) { Swap(&arr[0],&arr[end]) AdjustDown(arr,0,end); end-- } }
2、向上向下调整算法的对比
向上调整算法:将新数据插⼊到数组的尾上,再进⾏向上调整算法,直到满⾜堆。
• 先将元素插⼊到堆的末尾,即最后⼀个孩⼦之后
• 插⼊之后如果堆的性质遭到破坏,将新插⼊结点顺着其双双亲往上调整到合适位置即可
第1层, 2 0 个结点,需要向上移动0层
第2层, 2 1 个结点,需要向上移动1层
第3层, 2 2 个结点,需要向上移动2层
第4层, 2 3 个结点,需要向上移动3层
......
第h层, 2 h−1 个结点,需要向上移动h-1层
则需要移动结点总的移动步数为:每层结点个数 * 向上调整次数(第⼀层调整次数为0)
T (h) = 2 ^ 1 ∗ 1 + 2 ^ 2 ∗ 2 + 2 ^ 3 * 3 + .. + 2 ^ h-2 ∗ (h − 2) + 2 ^ h-1 ∗ (h − 1)
2 ∗ T (h) = 2 ^ 2 ∗ 1 + 2 ^ 3 ∗ 2 + 2 ^ 4 ∗ 3 + .. + 2 ^ h-1 ∗ (h − 2) + 2 ^ h ∗ (h − 1)
② ⼀ ① 错位相减:
T (h) = −2 ^ 1 * 1 − (2 ^ 2 + 2 ^ 3 + .. + 2 ^ h-2 + 2 ^ h-1 ) + 2 ^ h ∗ (h − 1)
T (h) = −2 ^ 0 - 2 ^ 1 − (2 ^ 2 + 2 ^ 3 .. + 2 ^ h−2 + 2 ^ h-1) + 2 ^ h-1 ∗ (h − 1) + 2 ^ 0
T (h) = −(2 ^ 0 + 2 ∗ 1 + 2 ^ 2 + 2 ^ 3 + .. + 2 ^ h−2 + 2 ^ h-1 ) + 2 ^ h ∗ (h − 1) + 2 ^ 0
T (h) = −(2 ^ h - 1) + 2 ^ h ∗ (h − 1) + 2 ^ 0
T (h) = −(2 ^ h − 1) + 2 ^ h * (h − 1) + 2 ^ 0
根据⼆叉树的性质: n = 2 ^ h - 1 和 h = log2 (n + 1)
T (n) = −N + 2 ^ h * (h − 1) + 2 ^ 0
F (h) = 2 ^ h * (h − 2) + 2
F (n) = (n + 1)(log2 (n + 1) − 2) + 2
向上调整算法建堆时间复杂度为: O(n ∗ log n)
向下调整算法:删除堆是删除堆顶的数据,将堆顶的数据根最后⼀个数据⼀换,然后删除数组最后⼀个数据,再进⾏ 向下调整算法。
• 将堆顶元素与堆中最后⼀个元素进⾏交换
• 删除堆中最后⼀个元素
• 将堆顶元素向下调整到满⾜堆特性为止
第1层, 2 0 个结点,需要向下移动h-1层
第2层, 2 1 个结点,需要向下移动h-2层
第3层, 2 2 个结点,需要向下移动h-3层
第4层, 2 3 个结点,需要向下移动h-4层
......
第h-1层, 2 h−2 个结点,需要向下移动1层
则需要移动结点总的移动步数为:每层结点个数 * 向下调整次数
① T (h) = 2 ^ 0 * (h − 1) + 2 ^ 1 * (h − 2) + 2 ^ 2 * (h − 3) + 2 ^ 3 * (h − 4) + .. + 2 ^ h-3 * 2 + 2 ^ h-2 * 1
② 2 ∗ T (h) = 2 ^ 1 ∗ (h − 1) + 2 ^ 2 ∗ (h − 2) + 2 ^ 3 ∗ (h − 3) + 2 ^ 4 ∗ (h − 4) + ... + 2 ^ h-2 ∗ 2 + 2 ^ h-1 ∗ 1
② ⼀ ① 错位相减: T (h) = 1 − h + 2 ^ 1 + 2 ^ 2 + 2 ^ 3 + 2 ^ 4 + .. + 2 ^ h-2 + 2 ^ h-1
T (h) = 2 ^ 0 + 2 ^ 1 + 2 ^ 2 + 2 ^ 3 + 2 ^ 4 + . + 2 ^ h-2 + 2 ^ h-1 − h
T (h) = 2 ^ h − 1 − h
根据⼆叉树的性质: n = 2 ^ h − 1 和 h = log2 (n + 1) T (n) = n − log2 (n + 1) ≈ n
向下调整算法建堆时间复杂度为: O(n)
向下调整时:结点由少到多
向上调整时:结点由多到少
二、top - k 问题
TOP-K问题:即求数据结合中前K个最⼤的元素或者最⼩的元素,⼀般情况下数据量都⽐较⼤。
⽐如:专业前10名、世界500强、富豪榜、游戏中前100的活跃玩家等。
对于Top-K问题,能想到的最简单直接的⽅式就是排序,但是:如果数据量⾮常⼤,排序就不太可取了 (可能数据都不能⼀下⼦全部加载到内存中)。最佳的⽅式就是⽤堆来解决,基本思路如下:
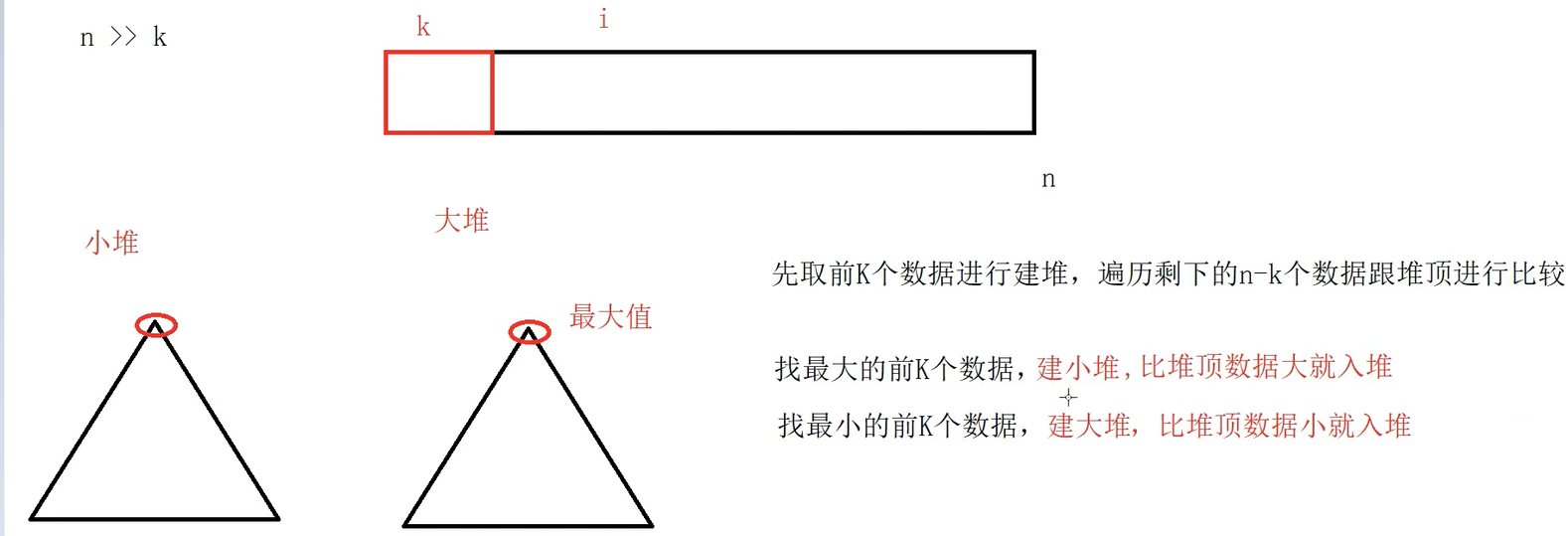
1)⽤数据集合中前K个元素来建堆
前k个最⼤的元素,则建⼩堆
前k个最⼩的元素,则建⼤堆
2)⽤剩余的N-K个元素依次与堆顶元素来⽐较,不满⾜则替换堆顶元素
将剩余N-K个元素依次与堆顶元素⽐完之后,堆中剩余的K个元素就是所求的前K个最⼩或者最⼤的元 素
//求size int HPSize(HP * php) { assert(php); return php->size; } void CreateNDate() { // 造数据 int n = 100000; srand(time(0)); const char* file = "data.txt"; FILE* fin = fopen(file, "w"); if (fin == NULL) { perror("fopen error"); return; } for (int i = 0; i < n; ++i) { int x = (rand()+i) % 1000000; fprintf(fin, "%d\n", x); } fclose(fin); } void topk() { printf("请输⼊k:>"); int k = 0; scanf("%d", &k); const char* file = "data.txt"; FILE* fout = fopen(file, "r"); if (fout == NULL) { perror("fopen error"); exit(1); } int val = 0; int* minheap = (int*)malloc(sizeof(int) * k); if (minheap == NULL) { perror("malloc error"); ecit(2); } for (int i = 0; i < k; i++) { fscanf(fout, "%d", &minheap[i]); } // 建k个数据的⼩堆 for (int i = (k - 1 - 1) / 2; i >= 0; i--) { AdjustDown(minheap, k, i); } int x = 0; while (fscanf(fout, "%d", &x) != EOF) { //遍历剩下的n-k个数据,根堆顶比较,堆顶小替换堆顶元素 if (x > minheap[0]) { minheap[0] = x; AdjustDown(minheap, k, 0); } } for (int i = 0; i < k; i++) { printf("%d ", minheap[i]); } fclose(fout); }时间复杂度: O(n) = k + (n − k)log2 k
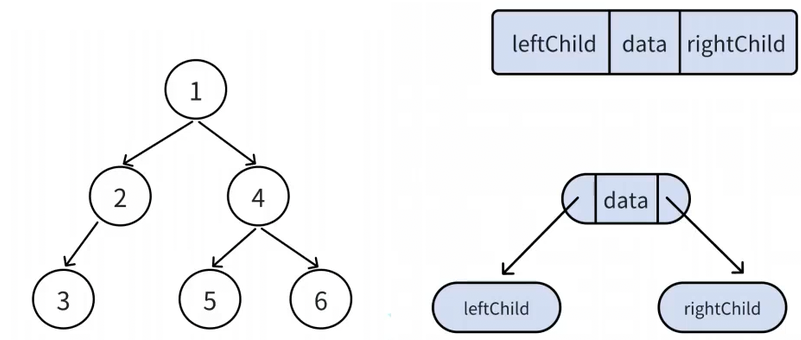
三、实现链式结构二叉树
⽤链表来表⽰⼀棵⼆叉树,即⽤链来指⽰元素的逻辑关系。 通常的⽅法是链表中每个结点由三个域组 成,数据域和左右指针域,左右指针分别⽤来给出该结点左孩⼦和右孩⼦所在的链结点的存储地址 , 其结构如下:
typedef int BTDataType; // 定义链式结构的二叉树 typedef struct BinaryTreeNode { struct BinTreeNode* left; // 指向当前结点左孩⼦ struct BinTreeNode* right; // 指向当前结点右孩⼦ BTDataType val; // 当前结点值域 }BTNode; BTNode* BuyBTNode(int val) { BTNode* newnode = (BTNode*)malloc(sizeof(BTNode)); if (newnode == NULL) { perror("malloc fail"); return NULL; } newnode->val = val; newnode->left = NULL; newnode->right = NULL; return newnode; } BTNode* CreateTree() { BTNode* n1 = BuyBTNode(1); BTNode* n2 = BuyBTNode(2); BTNode* n3 = BuyBTNode(3); BTNode* n4 = BuyBTNode(4); BTNode* n5 = BuyBTNode(5); BTNode* n6 = BuyBTNode(6); BTNode* n7 = BuyBTNode(7); n1->left = n2; n1->right = n4; n2->left = n3; n4->left = n5; n4->right = n6; n5->left = n7; return n1; }根结点的左⼦树和右⼦树分别⼜是由⼦树结点、⼦树结点的左⼦树、⼦树结点的右⼦树组成的,因此 ⼆叉树定义是递归式的,后序链式⼆叉树的操作中基本都是按照该概念实现的。
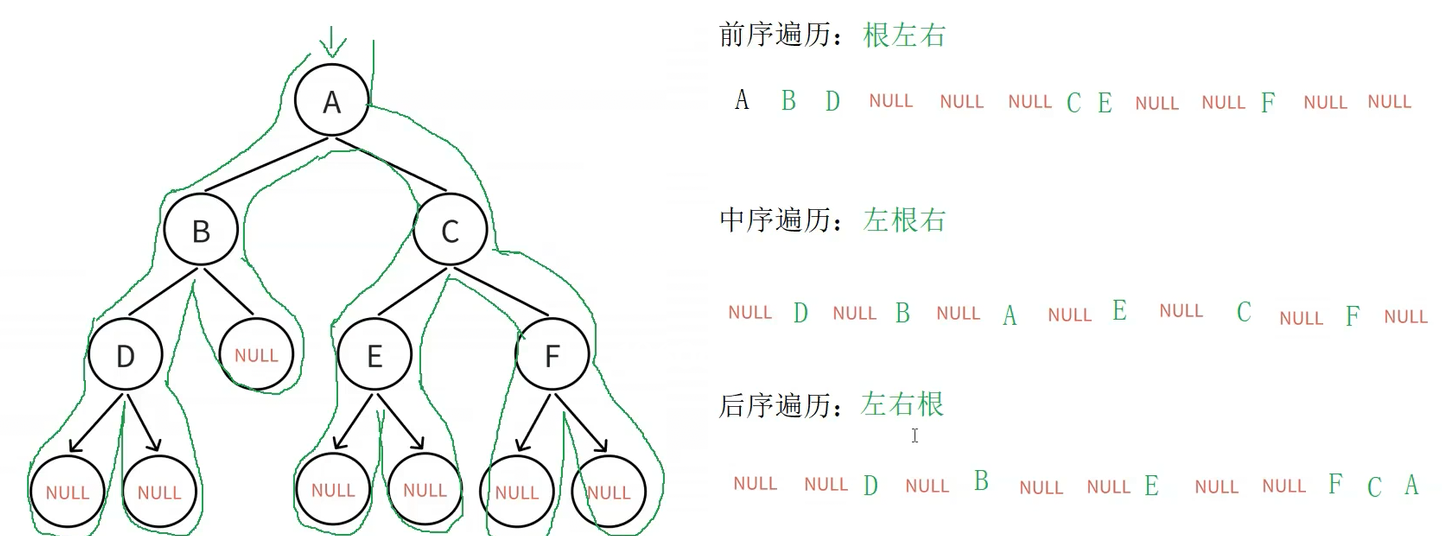
四、前中后序遍历
按照规则,⼆叉树的遍历有:前序/中序/后序的递归结构遍历:
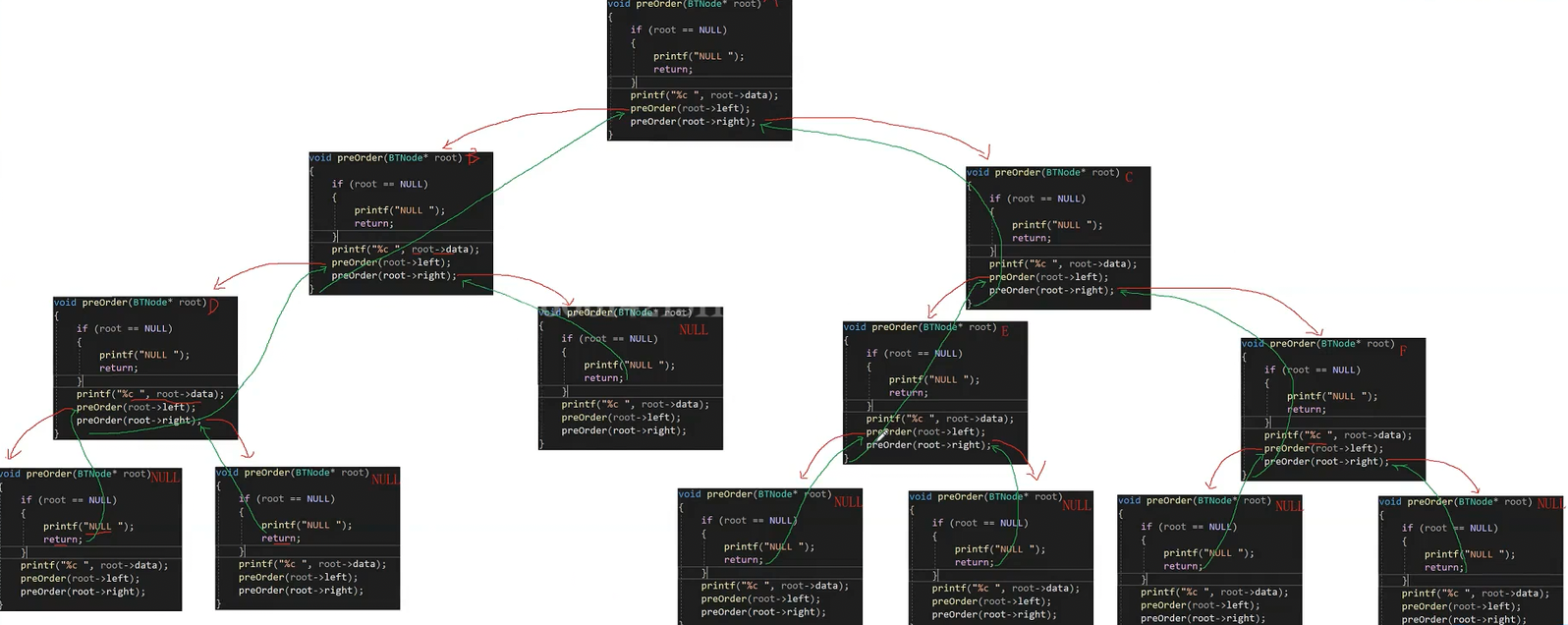
1)前序遍历(Preorder Traversal 亦称先序遍历):访问根结点的操作发⽣在遍历其左右⼦树之前
访问顺序为:根结点、左⼦树、右⼦树
2)中序遍历(Inorder Traversal):访问根结点的操作发⽣在遍历其左右⼦树之中(间)
访问顺序为:左⼦树、根结点、右⼦树
3)后序遍历(Postorder Traversal):访问根结点的操作发⽣在遍历其左右⼦树之后
访问顺序为:左⼦树、右⼦树、根结点
//前序遍历 void PreOrder(BTNode* root) { if (root == NULL) { printf("N "); return; } printf("%d ", root->val); PreOrder(root->left); PreOrder(root->right); } //中序遍历 void InOrder(BTNode* root) { if (root == NULL) { printf("N "); return; } InOrder(root->left); printf("%d ", root->val); InOrder(root->right); } //后序遍历 void PostOrder(BTNode* root) { if (root == NULL) { printf("N "); return; } InOrder(root->left); InOrder(root->right); printf("%d ", root->val); }