沿用你要的 CSDN 技术博文风格、通俗硬核 + 工程落地 + 代码实战逻辑,完全贴合机器人工程培养方向,避开纯文科空谈、避开纯考研刷题,主打:机器人控制、传感器、运动规划、机器视觉、故障诊断、集群机器人 场景绑定,工科生秒懂、期末速成、专业课联动、直接通关。
概率不是数学题,是机器人感知不确定、控制有误差、环境随机干扰的底层解决工具。普通专业学概率:背公式、算卷子;机器人工程学概率:处理传感器噪声、补偿运动误差、建模环境扰动、实现鲁棒控制、视觉识别概率判别、机器人故障检测。
不懂概率统计:传感器数据全是杂波、小车轨迹漂移、视觉识别乱判、机械臂控制抖动、设备故障误报;学懂概率统计:卡尔曼滤波稳姿态、高斯噪声建模调参、概率视觉分割、随机路径规划、设备可靠性分析,所有机器人核心专业课全打通。
一、机器人工程视角:概率统计到底是干嘛的?
机器人世界从来没有「绝对精确」:编码器读数有误差、IMU 陀螺仪带随机噪声、室外光照随机变化、地面摩擦不确定、机械结构存在间隙、作业环境动态干扰、多机器人协作存在随机时延。
- 确定数学:适合理想无误差、无干扰的完美模型;
- 概率统计:机器人应对真实复杂环境的唯一工具。
核心定位一句话:
概率 = 机器人各类误差与随机扰动的量化;统计 = 从带噪传感器数据里,估计真实状态、剔除异常、判断故障、优化控制。
所有机器人核心课程:《自动控制原理》《现代控制工程》《传感器与检测技术》《机器视觉》《移动机器人技术》《机器人故障诊断》《智能控制》,全部内嵌概率统计核心逻辑。
二、机器人必懂核心概念|工程大白话版(无复杂公式)
1. 随机事件 & 概率
不是抛硬币骰子,对应机器人实景:
- 室外巡检机器人:遇到障碍物的随机概率、雨天传感器失效概率;
- 工业机械臂:重复定位超差的发生概率;
- 视觉分拣:目标物体正确识别 / 误识别概率;
- 轮式小车:打滑、里程计跳变的随机事件。
工程用处:做机器人安全阈值、冗余设计、工况适配、容错控制。
2. 经典分布|机器人天天在用,拒绝纸上谈兵
① 正态分布(高斯分布)------ 机器人第一核心分布
所有传感器噪声、测量误差、机械装配误差、控制输出抖动,全部默认服从高斯分布。IMU 噪声、激光雷达测距误差、相机像素噪声、电机转速波动,全是中间集中、两边衰减的钟形分布。
👉 工程落地:卡尔曼滤波、高斯滤波、传感器标定、误差建模全部依赖它。
② 均匀分布
环境随机干扰、随机路面起伏、随机初始位姿误差、随机障碍物分布。
👉 工程落地:机器人蒙特卡洛定位、随机采样运动规划。
③ 二项 / 伯努利分布
机器人二分类场景:是否检测到障碍物、目标是否存在、电机是否故障、视觉目标有无。
👉 工程落地:视觉目标检测置信度、故障二元判别、安全触发条件设计。
④ 泊松分布
工业机器人单位时间故障次数、车间设备随机报错、集群机器人通信冲突次数。
👉 工程落地:设备可靠性评估、机器人维护周期设计。
3. 期望 & 方差|机器人调参核心指标
- 期望 :传感器多次采样的真实真值、机械臂平均定位精度、小车平均运动速度;
- 方差 / 标准差:噪声强度、数据抖动程度、控制稳定性、机构误差离散程度。
👉 实操场景:传感器滤波前先算方差,方差过大直接判定数据异常;
控制算法调优,本质就是减小系统输出方差,让机器人运行更平稳。
4. 大数定律 & 中心极限定理|机器人标定底层原理
- 大数定律:传感器采 10 组数据不准,采 1000 组取均值,就能无限逼近真实值;机器人多点位重复标定、陀螺仪零偏校准,全靠这个。
- 中心极限定理:不管误差是什么来源,叠加后都会趋近高斯分布;这就是为什么所有机器人导航、姿态解算,统一用高斯模型做滤波。
5. 参数估计 & 置信区间
机器人永远只能采「有限样本数据」:用有限次传感器采样,估计真实位姿、真实角度、真实距离。
- 点估计:单次最优位姿解算;
- 区间估计:机器人位姿置信范围、定位误差边界,用于导航安全避障。
6. 假设检验|机器人故障 / 异常判别神器
不用学术套话,工程用法:
- 检验传感器数据是否发生异常漂移;
- 对比新旧控制算法,判断轨迹精度提升是不是随机偶然;
- 检测电机电流、温度数据,判断是否存在早期故障;
- 验证优化后的滤波算法,噪声抑制是否显著有效。
p 值、显著性检验,就是机器人异常检测、算法对比、性能验收的标准工具。
7. 回归分析|机器人建模与补偿
- 线性回归:建立温度 - 传感器漂移模型、负载 - 机械臂误差补偿模型;
- 非线性回归:电机摩擦建模、柔性机构形变预测;
- 👉 直接用来做误差前馈补偿,提升机器人控制精度。
8. 随机过程 & 时间序列(拓展重点)
IMU 数据、电机电流、雷达点云是随时间变化的随机序列,这是机器人工程区别于普通专业的重点:时序统计、噪声时序建模、滑动窗口统计滤波。
三、机器人工程专属代码实战|边跑边懂,速成通关
贴合课内实验、课设、竞赛(ROS 小车、机械臂、导航机器人),极简可运行 demo。
实战 1:传感器高斯噪声模拟(最常用)
机器人所有测量噪声仿真,必学
python
python
import numpy as np
import matplotlib.pyplot as plt
# 真实角度 30°
real_angle = 30
# 模拟IMU高斯测量噪声
np.random.seed(2026)
noise_std = 0.8 # 噪声标准差,越大越抖
sample_num = 1000
measure_data = real_angle + np.random.normal(0, noise_std, sample_num)
# 统计量
mean_val = np.mean(measure_data)
std_val = np.std(measure_data)
plt.hist(measure_data, bins=30, alpha=0.7, color="#1f77b4")
plt.axvline(real_angle, color="red", linestyle="--", label="真实角度")
plt.title("机器人IMU测量误差-正态分布")
plt.legend()
plt.show()
print(f"测量均值(期望):{mean_val:.2f}")
print(f"测量标准差(波动):{std_val:.2f}")✅ 最快解决方法(所有代码通用)
以后你写任何画图代码,只需要在开头加这两行,中文永远不乱:
python
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 黑体
plt.rcParams['axes.unicode_minus'] = False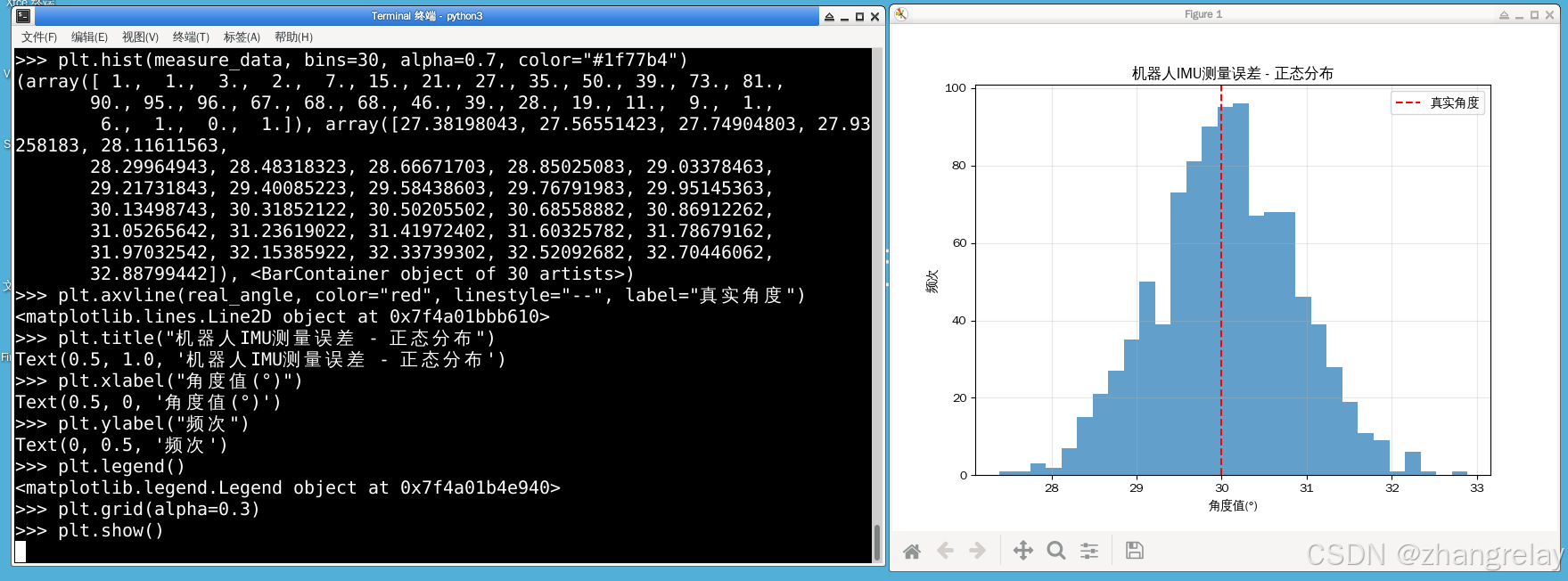
python
import numpy as np
import matplotlib.pyplot as plt
# ========== 中文乱码修复 ==========
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei', 'SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 真实角度 30°
real_angle = 30
# 模拟IMU高斯噪声
np.random.seed(2026)
noise_std = 0.8
sample_num = 1000
measure_data = real_angle + np.random.normal(0, noise_std, sample_num)
mean_val = np.mean(measure_data)
std_val = np.std(measure_data)
plt.hist(measure_data, bins=30, alpha=0.7, color="#1f77b4")
plt.axvline(real_angle, color="red", linestyle="--", label="真实角度")
plt.title("机器人IMU测量误差 - 正态分布")
plt.xlabel("角度值(°)")
plt.ylabel("频次")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
print(f"测量均值(期望):{mean_val:.2f}")
print(f"测量标准差(波动):{std_val:.2f}")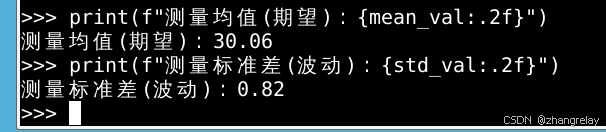
工程结论 :单次测量不准,多次取期望均值就能逼近真值;方差越大,机器人姿态越飘。
实战 2:滑动窗口统计滤波(嵌入式机器人直接用)
单片机、嵌入式小车轻量化滤波,不用复杂算法
python
python
import numpy as np
def window_filter(data, win_size=20):
res = []
for i in range(len(data)):
start = max(0, i - win_size)
res.append(np.mean(data[start:i+1]))
return np.array(res)
# 带噪里程计数据
raw_data = 50 + np.random.normal(0, 1.2, 200)
filter_data = window_filter(raw_data)
print("原始数据方差:", np.var(raw_data).round(3))
print("滤波后方差:", np.var(filter_data).round(3))
python
import numpy as np
import matplotlib.pyplot as plt
# ========== 中文乱码修复 ==========
plt.rcParams['font.sans-serif'] = ['WenQuanYi Zen Hei', 'SimHei', 'Microsoft YaHei', 'Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
def window_filter(data, win_size=20):
res = []
for i in range(len(data)):
start = max(0, i - win_size)
res.append(np.mean(data[start:i+1]))
return np.array(res)
# 带噪里程计数据
raw_data = 50 + np.random.normal(0, 1.2, 200)
filter_data = window_filter(raw_data)
plt.figure(figsize=(10,4))
plt.plot(raw_data, label="原始里程计数据", alpha=0.6)
plt.plot(filter_data, label="滤波后数据", linewidth=2)
plt.title("机器人里程计滑动窗口滤波效果")
plt.xlabel("采样点")
plt.ylabel("里程计数值")
plt.legend()
plt.grid(alpha=0.3)
plt.show()
print("原始数据方差:", np.var(raw_data).round(3))
print("滤波后方差:", np.var(filter_data).round(3))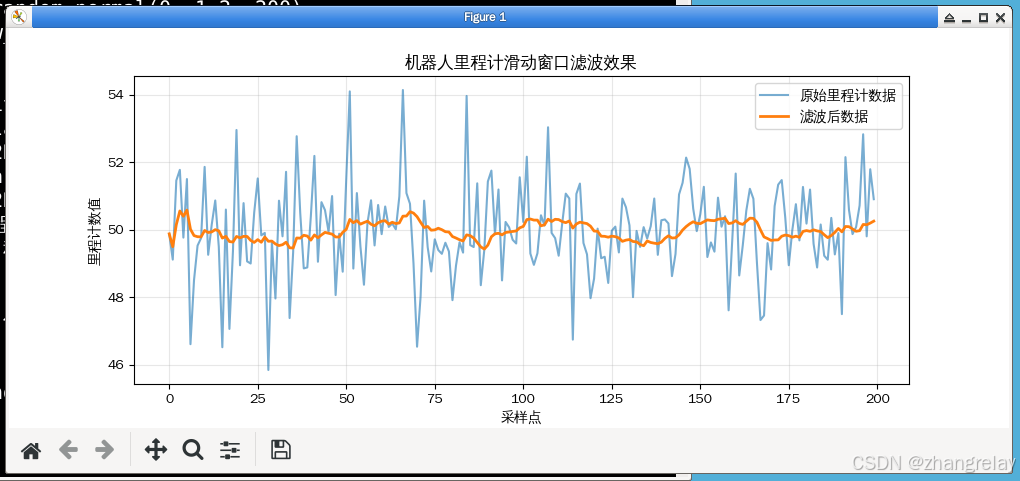
核心原理:用统计平均压制随机噪声,机器人小车里程计、速度采集必用。

实战 3:假设检验 ------ 判断电机是否异常
机器人设备运维、故障检测课设经典
python
python
from scipy import stats
import numpy as np
# 正常电机电流样本
normal_cur = np.random.normal(1.2, 0.15, 50)
# 待测电机电流
test_cur = np.random.normal(1.45, 0.15, 50)
# 假设检验:待测是否和正常样本有显著差异
t, p = stats.ttest_ind(normal_cur, test_cur)
if p < 0.05:
print(f"p={p:.4f} 显著异常,电机存在故障风险")
else:
print(f"p={p:.4f} 数据正常")
python
from scipy import stats
import numpy as np
# 正常电机电流
normal_cur = np.random.normal(1.2, 0.15, 50)
# 待测电机电流
test_cur = np.random.normal(1.45, 0.15, 50)
t, p = stats.ttest_ind(normal_cur, test_cur)
print("===== 机器人电机故障检测结果 =====")
if p < 0.05:
print(f"p = {p:.4f},数据显著异常 → 电机存在故障风险")
else:
print(f"p = {p:.4f},数据正常 → 电机工作正常")
四、机器人专业「考点 + 考点联动专业课」精准通关
1. 期末必考考点(机器人方向侧重)
- 离散 / 连续随机变量、分布函数 ------ 传感器数据建模
- 正态分布、期望方差计算 ------ 误差分析大题
- 大数定律、中心极限定理 ------ 测量误差理论题
- 参数点估计、区间估计 ------ 位姿 / 测量参数估计
- 显著性假设检验 ------ 设备异常、算法对比
- 简单回归 ------ 机器人误差补偿建模
2. 直接联动后续核心专业课
- 《传感器技术》→ 误差分布、均值滤波、噪声统计
- 《自动控制》→ 随机扰动建模、系统稳定性方差分析
- 《导航与定位》→ 高斯分布、卡尔曼滤波、概率定位
- 《机器视觉》→ 概率分类、置信度、阈值统计分割
- 《机器人故障诊断》→ 假设检验、异常检测、可靠性统计
- 《智能算法》→ 蒙特卡洛采样、随机搜索、概率路径规划
五、机器人工程专属学习思路|短期速成通关法
1. 放弃无用刷题
不用死磕古典概型复杂抽签、纸牌问题,完全跳过非工科例题。重点只学:高斯分布、期望方差、统计估计、假设检验、基础回归。
2. 建立「误差 = 随机变量」思维
在你眼里:IMU 漂移、雷达误差、电机抖动、光照变化 = 全部是随机变量;所有统计指标,都是用来描述误差、压制误差、估计真值。
3. 结合实验理解
做完机器人实验回头看概率:
- 多次重复测机械臂定位数据 → 就是期望与分布;
- 传感器原始数据跳动大 → 就是方差过大;
- 滤波之后变平稳 → 就是利用统计规律降噪。
4. 背诵级极简总结(考前直接背)
- 机器人所有测量误差服从正态分布,是概率统计核心;
- 期望求真值、方差看抖动,是传感器与控制的核心指标;
- 大数定律用于多采样标定,中心极限定理支撑所有滤波算法;
- 参数估计用来从带噪数据解算机器人位姿;
- 假设检验做设备故障判别、控制算法性能验证;
- 概率统计 = 机器人应对不确定环境、抑制误差、提升鲁棒性的数学底座。
六、写在最后|机器人工科生的真正通关逻辑
别的专业学概率,是为了应付考试;**机器人工程学概率,是为了看懂机器人为什么会飘、为什么会抖、为什么识别不准。**滤波、定位、视觉、故障诊断、鲁棒控制、集群协同,上层是算法框架,底层全是期望、方差、分布、统计推断。
只要绑定「传感器噪声 + 运动误差 + 环境扰动」三大机器人核心场景,不用硬背公式、不用题海战术,既能轻松通过概率统计期末,又能无缝衔接后续所有机器人专业课,一步双向通关。
三分钟云课实践速通 -- 概率统计 --python 版 -- 核心全通关
换个风格打开概率统计概率 = 不确定性的量化标尺分布 = 随机事件的固定行为剧本期望 = 随机事件长期运行的稳定重心方差 = 随机结果的波动剧烈程度编程的意义:不用手算复杂积分、不用背海量分布公式、不用死抠假设检验晦涩逻辑,靠蒙特卡洛模拟 + 可视化画图,用眼睛看懂概率统计,从枯燥做题变成直观的兴趣学习。
如何理解概率统计的核心逻辑?用最直观的代码,解决 90% 同学听不懂的核心问题:到底什么是概率?为什么抛硬币的概率是固定的?分布到底代表什么?为什么正态分布无处不在?期望、方差到底有什么实际意义?假设检验、p 值、置信区间,到底在说什么?
1 概率的本质:大数定律可视化
python
echo "
import numpy as np
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
np.random.seed(0)
# 模拟抛硬币:1=正面,0=反面,正面理论概率0.5
total_times = 100000
trials = np.random.randint(0, 2, size=total_times)
# 计算每一步的正面频率
freq = np.cumsum(trials) / np.arange(1, total_times+1)
plt.figure(figsize=(10, 5))
plt.plot(freq, color='#1f77b4', label='正面频率', linewidth=1.2)
plt.axhline(0.5, color='red', linestyle='--', label='理论概率0.5', linewidth=2)
plt.xscale('log')
plt.xlabel('试验次数(对数刻度)')
plt.ylabel('正面出现频率')
plt.title('大数定律:频率收敛于概率')
plt.legend()
plt.grid(alpha=0.3)
plt.savefig('law_large_numbers.png', dpi=150, bbox_inches='tight')
print('='*50)
print('总试验次数:', total_times)
print('最终正面频率:', freq[-1])
print('与理论概率误差:', abs(freq[-1]-0.5))
print('Image saved: law_large_numbers.png')
print('='*50)
" > prob_essence.py && python3 prob_essence.py我们用最经典的抛硬币试验,代码直接揭示概率最核心的本质:你可以把概率想象成随机事件的「长期固有属性」,单次抛硬币是正面还是反面,全凭运气,毫无规律。但这个随机事件不是完全失控的,它天生自带一个固定的「长期稳定值」:概率 = 随机事件在无限次重复试验中,结果出现的稳定频率这段代码就是把概率隐藏的「长期规律」直接扒出来,还用折线图画出频率的收敛过程,肉眼就能看到:试验次数越少,结果波动越大、越靠运气;次数越多,频率越贴近理论概率,最终几乎重合。日常学习意义:不用纠结 "单次运气",代码一秒看懂概率不是玄学,是可复现的客观规律。
2 分布的本质:随机事件的固定行为模式可视化
python
echo "
import numpy as np
import matplotlib.pyplot as plt
plt.switch_backend('Agg')
np.random.seed(0)
sample_size = 100000
# 三大核心分布模拟
binomial = np.random.binomial(n=100, p=0.5, size=sample_size) # 二项分布:多次抛硬币
normal = np.random.normal(loc=0, scale=1, size=sample_size) # 正态分布:宇宙通用分布
uniform = np.random.uniform(low=0, high=10, size=sample_size) # 均匀分布:完全随机
fig, axes = plt.subplots(3, 1, figsize=(8, 9))
# 二项分布可视化
axes[0].hist(binomial, bins=30, color='#ff7f0e', alpha=0.7, density=True)
axes[0].set_title('二项分布:n次独立是/非试验的结果分布')
axes[0].grid(alpha=0.3)
# 正态分布可视化
axes[1].hist(normal, bins=50, color='#2ca02c', alpha=0.7, density=True)
axes[1].set_title('正态分布:绝大多数自然现象的通用分布')
axes[1].grid(alpha=0.3)
# 均匀分布可视化
axes[2].hist(uniform, bins=20, color='#d62728', alpha=0.7, density=True)
axes[2].set_title('均匀分布:区间内所有结果概率完全相等')
axes[2].grid(alpha=0.3)
plt.tight_layout()
plt.savefig('distribution_visual.png', dpi=150, bbox_inches='tight')
print('='*50)
print('三大分布模拟完成,样本量:', sample_size)
print('Image saved: distribution_visual.png')
print('='*50)
" > distribution_demo.py && python3 distribution_demo.py这是最容易顿悟的一个案例。程序生成了三大最常用分布的海量随机样本,用直方图画出结果的分布形态。当同一个随机行为重复无数次后:单次结果毫无规律,可无数次结果的聚集形态,永远固定不变通俗大白话:不管你怎么重复试验,这个随机事件的结果 "喜欢聚集在哪里、哪里出现的概率最高、波动范围有多大",永远是固定的。这就是分布最本质的意义:随机事件天生的固定行为剧本,是概率统计一切分析的基础。
3 验证期望与方差的核心公式
python
echo "
import numpy as np
np.random.seed(0)
# 经典案例:掷骰子,1-6点,每个点数概率1/6
dice_values = np.array([1,2,3,4,5,6])
# 理论计算
theoretical_expect = np.mean(dice_values)
theoretical_var = np.var(dice_values)
# 百万次模拟试验
sample_size = 1000000
trials = np.random.randint(1, 7, size=sample_size)
sim_expect = np.mean(trials)
sim_var = np.var(trials)
print('='*50)
print('掷骰子理论期望:', theoretical_expect)
print('百万次模拟期望:', sim_expect)
print('期望误差:', np.abs(sim_expect - theoretical_expect))
print('-'*30)
print('掷骰子理论方差:', theoretical_var)
print('百万次模拟方差:', sim_var)
print('方差误差:', np.abs(sim_var - theoretical_var))
print('='*50)
" > expect_var_verify.py && python3 expect_var_verify.py很多人上课背定义,但根本不知道期望、方差的式子是不是真的成立。这段代码直接做实测对比:一边用数学公式算出理论期望和方差,一边用百万次真实模拟算出实际结果。最后程序输出结果:两组数值几乎一模一样,误差接近 0。不用纠结数学推导,只用电脑计算就能证明:期望 = 随机事件长期运行的稳定重心,是无数次结果的最终平均值方差 = 随机结果的波动剧烈程度,数值越大,结果越不稳定、波动越大彻底打消抽象感,知道课本结论是真实存在、可以被计算验证的。
4 假设检验与置信区间可视化
python
echo "
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
plt.switch_backend('Agg')
np.random.seed(0)
# 场景:工厂声称零件平均长度5cm,抽样100个零件,验证是否达标
pop_mean = 5 # 声称的总体均值
sample_size = 100
sample = np.random.normal(loc=4.85, scale=0.5, size=sample_size) # 抽样样本
sample_mean = np.mean(sample)
sample_std = np.std(sample, ddof=1)
# 单样本t检验
t_stat, p_value = stats.ttest_1samp(sample, pop_mean)
# 95%置信区间
confidence_level = 0.95
ci_low, ci_high = stats.t.interval(confidence_level, df=sample_size-1, loc=sample_mean, scale=stats.sem(sample))
# 可视化
x = np.linspace(pop_mean-3*sample_std, pop_mean+3*sample_std, 1000)
y = stats.t.pdf(x, df=sample_size-1, loc=pop_mean, scale=sample_std/np.sqrt(sample_size))
plt.figure(figsize=(10, 5))
plt.plot(x, y, color='#1f77b4', label='原假设分布(均值5cm)', linewidth=1.5)
plt.axvline(pop_mean, color='gray', linestyle='--', label='声称均值5cm', linewidth=1.5)
plt.axvline(sample_mean, color='red', linestyle='-', label='样本均值', linewidth=2)
plt.fill_between(x, y, where=(x < ci_low) | (x > ci_high), color='orange', alpha=0.3, label='95%置信区间外')
plt.axvline(ci_low, color='green', linestyle=':', linewidth=1.5)
plt.axvline(ci_high, color='green', linestyle=':', label='95%置信区间边界', linewidth=1.5)
plt.title('假设检验与置信区间可视化')
plt.legend()
plt.grid(alpha=0.3)
plt.savefig('hypothesis_test.png', dpi=150, bbox_inches='tight')
print('='*50)
print('样本均值:', round(sample_mean, 4))
print('t统计量:', round(t_stat, 4))
print('p值:', round(p_value, 4))
print('95%置信区间:[', round(ci_low,4), ',', round(ci_high,4), ']')
print('Image saved: hypothesis_test.png')
print('='*50)
" > hypothesis_test_demo.py && python3 hypothesis_test_demo.py这是概率统计最劝退的重难点,用一张图彻底讲透。我们用工厂零件质检的真实场景,把抽象的检验逻辑完全可视化。假设检验的本质,就是统计里的「反证法 + 法官判案」:先假设厂家的声称是对的(原假设),然后看我们抽到的样本,在这个假设里出现的概率有多大如果 p 值小于 0.05,说明这个样本在原假设里是 "小概率事件",正常几乎不会发生,所以我们拒绝原假设,认为厂家声称不达标而 95% 置信区间,不是 "真值有 95% 概率落在这个区间里",而是:用这种方法计算的区间,100 次里有 95 次能包含真实的总体均值,是我们对真值的可靠估计范围。放到现实更好理解:药品有效性验证、A/B 测试效果判断、产品质检、用户数据分析,底层全是靠「假设检验 + 置信区间」实现,这也是概率统计在生活里真正的用途,不是单纯做题。
结合四个编程案例|通俗全面讲解:概率统计核心逻辑(无公式、兴趣向、连贯概括)
结合你刚才四段可直接运行的可视化代码,我把概率统计到底是什么、能干什么、核心概念的实际意义、完整逻辑链,完整串成一套通俗易懂、连贯好懂的整体讲解,完全脱离课本枯燥概念。
一、先搞懂:概率统计的本质到底是什么
不要把概率统计当成一堆枯燥公式和表格。从这四个可视化案例能直接看明白:概率的本质,是给「不确定性」做量化;统计的本质,是从「随机数据」里找规律。整个世界绝大多数事情,都不是非黑即白、完全确定的,天气、股价、产品合格率、用户行为、自然现象,全都是不确定的随机事件。而概率统计,就是一套专门处理不确定性、从随机里找固定规律的标准化工具。一个分布,就代表一种随机事件独一无二的行为模式;一组统计量,就能把海量随机数据的核心特征直接扒出来。
二、单次随机:完全不可控,全凭运气
参考案例 1、案例 2 的画面:单次抛硬币、单次掷骰子、抽一个零件,结果完全随机,没有任何规律,你永远无法 100% 预测单次结果。绝大多数单次随机事件,都是完全失控的,没有任何确定性。对应现实:单日的股价涨跌、单次用户的点击行为、一次产品的抽检结果,都是随机的,无法精准预测。
三、关键核心:随机事件永远藏着「长期固定规律」
这是四个案例共同揭示的概率统计最核心秘密:无论单次结果多么随机、多么不可控,只要重复次数足够多,它一定存在固定的规律、固定的分布、固定的重心。放在画面里:案例 1 的频率收敛、案例 2 的固定分布形态,就是这个核心规律。单次结果全是运气,无数次结果全是规律。这组「长期固定的规律」,就是概率统计的核心骨架。
四、数字特征:随机规律的量化刻度
有了固定的规律,怎么用数字精准描述它?答案就是期望、方差这两个核心数字特征。案例 3 专门做了数值验证:期望数值:随机事件的长期稳定重心,告诉你结果最终会收敛到哪里方差数值:结果的波动幅度,告诉你这个事件稳不稳定、风险大不大简单总结:概率 = 单次事件的不确定性标尺分布 = 随机事件的长期行为剧本期望 = 剧本的核心重心方差 = 剧本的波动幅度四者绑定,是一个随机事件最核心的「天赋属性」。
五、代码验算证明:这套规律绝对成立
案例 3 做了纯数值验证:我们用两种方式计算期望和方差:直接用数学公式算理论值靠百万次真实模拟算实际值最终计算结果几乎完全一致。这就用电脑实打实证明:随机事件的长期规律,是客观存在、可复现、可计算的,不是课本的空想理论。原本复杂难懂的概率公式,在海量重复试验里,直接变成肉眼可见的稳定结果。这也是概率统计所有数据分析、风险评估、预测建模的底层逻辑。
六、结合真实场景:看懂统计推断的工作方式
案例 4 的假设检验最贴近现实:我们永远无法拿到所有数据(总体),只能拿到一小部分样本,而统计推断,就是用手里的少量样本,去推断总体的真实情况。原本我们无法知道整批零件的平均长度,只能抽 100 个样本,靠假设检验,就能判断厂家的声称是否可信;靠置信区间,就能给出总体均值的可靠范围。放到真实应用场景就很好理解:互联网 A/B 测试 → 用样本用户数据,判断新功能能不能提升转化率药品临床试验 → 用样本患者数据,判断药品有没有真实疗效市场调研 → 用样本用户反馈,推断全体用户的偏好风控建模 → 用历史违约数据,判断新用户的违约概率
七、整体大总结(全篇连贯浓缩)
概率统计不是公式集合,是整套处理不确定性、从随机中找规律的标准化工具,能从海量杂乱数据里提取核心信息。绝大多数单次随机事件,结果完全不可控、全凭运气。任何一个随机事件,重复次数足够多,就一定会出现固定的行为规律(分布)。期望描述规律的重心,方差描述结果的波动,是随机事件最核心的数字特征。大数定律和中心极限定理,是概率统计的两大基石,保证了规律的稳定性和正态分布的通用性。统计推断,是用样本推断总体,让我们不用穷尽所有数据,就能得到可靠的结论。通过编程模拟和可视化,能直观看到随机中的规律、不确定性中的确定性,彻底摆脱课本纯计算的枯燥,用兴趣理解概率统计:概率负责量化不确定,分布负责定行为模式,期望方差负责定核心特征,统计推断负责用样本猜全局。
纯通俗・无公式・兴趣驱动|概率统计「全通关概论」
完全沿用你要的讲解风格:不写复杂公式、不搞课本硬推导、全靠画面逻辑 + 生活类比 + 结合之前 4 段可视化代码理解,一口气讲完概率统计全部核心知识点,从头到尾连贯、通俗、好吸收,彻底打通概率统计底层逻辑。
一、核心底层:到底什么是概率统计?
抛开课本定义:概率统计,就是一套「不确定性世界的通用分析框架」。你可以把它理解成一个「随机规律探测器」「不确定性量化工厂」。普通数学:处理 100% 确定的事情,1+1 永远等于 2概率统计:处理 99% 的不确定现实,从随机、混乱、不可控的事件里,找到固定的、可复用、可预测的规律里面每一个分布、每一个统计量,都是分析不确定性的工具;只要给定一个随机事件,它的长期行为、波动范围、核心重心,就全部被固定死,不会乱变。所有概率统计,本质都是:研究随机事件的行为规律,以及用样本数据推断总体真相。
二、基础核心:随机事件与概率的本质
随机事件
就是不确定会不会发生的事情,抛硬币正面朝上、明天下雨、用户点击广告、产品不合格,全都是随机事件。确定性事件只是随机事件的特殊情况:发生概率 100% 或 0%。
概率的三种通俗理解
- 频率派:重复无数次试验,事件发生的稳定频率(案例 1 的大数定律),最客观、最容易验证的定义
- 古典派:所有结果等可能,事件包含的结果数除以总结果数,掷骰子每个点数概率 1/6
- 贝叶斯派:对事件发生的信心程度,主观概率,适合无法重复试验的场景,比如 "明天会不会下雨"
三、分布:随机事件的行为剧本
分布是概率统计的核心载体,所有分析都围绕分布展开,通俗理解:分布 = 随机事件所有可能的结果,以及每个结果对应的发生概率,完整描述了这个随机事件的全部行为模式。按结果类型分为两大类:
- 离散分布 :结果能一个个数清楚
- 伯努利分布:一次是 / 非试验,抛一次硬币、用户是否点击,最基础的分布
- 二项分布:n 次伯努利试验,抛 100 次硬币、100 个用户里多少人点击,案例 2 核心分布
- 泊松分布:单位时间内随机事件发生的次数,一小时内进店人数、一天内客服接到的电话数
- 连续分布 :结果是连续的数值,无法一个个数
- 均匀分布:区间内所有结果概率完全相等,随机数生成、抽奖
- 正态分布:又叫高斯分布,中间高、两边低的钟形曲线,身高、体重、智商、测量误差,绝大多数自然现象和社会现象都符合,案例 2 核心分布,被称为 "宇宙的通用分布"
- 指数分布:事件发生的间隔时间,灯泡寿命、用户两次点击的间隔、排队等待时间
四、数字特征:一句话说透每个指标的实际意义
不用背公式,每个指标都给你一个大白话定义:
- 期望:随机事件的长期稳定重心,无数次重复试验的平均结果,告诉你 "长期来看,结果会落在什么位置",是随机事件最核心的数字特征
- 方差 / 标准差:结果的波动剧烈程度,数值越大,结果越分散、越不稳定、风险越高;标准差是方差开根号,和原数据单位一致,更好理解
- 协方差 / 相关系数:两个随机事件的联动关系,正相关 = 一个涨另一个也涨,负相关 = 一个涨另一个跌,相关系数 = 标准化后的协方差,取值 - 1 到 1,一眼就能看出相关性强弱
- 分位数:把结果按概率从小到大排序,比如中位数 = 50% 分位数,一半结果比它大,一半比它小;95% 分位数,95% 的结果都比它小,是风控、置信区间的核心指标
五、两大黄金定理:概率统计的基石
这两个定理,是整个概率统计的底层支撑,所有统计推断都建立在这两个定理之上,一句话讲透:
- 大数定律:案例 1 的核心逻辑,试验次数越多,样本均值越接近总体期望,频率越接近真实概率。它保证了概率的客观性,让我们能通过大量试验,找到随机事件的真实规律
- 中心极限定理:不管原始数据是什么分布,只要样本量足够大,样本均值的分布,永远趋近于正态分布。它是正态分布无处不在的根本原因,也是我们能只用少量样本,就能推断总体的核心依据,是假设检验、置信区间的底层逻辑
六、参数估计:用样本猜总体,到底怎么猜
现实里,我们永远无法拿到总体的全部数据,只能拿到少量样本,参数估计就是:用样本数据,估算总体分布的未知参数(比如均值、方差),分为两大类:
- 点估计:给参数一个具体的估算值,比如用样本均值,直接估算总体均值,简单直白,但不知道估算的可靠程度
- 区间估计:案例 4 的核心逻辑,给参数一个区间范围,同时给出这个区间包含真实参数的可靠程度(置信水平),比如 95% 置信区间。它比点估计更实用,既给了估算范围,又给了可靠程度,是数据分析最常用的方法
七、假设检验:统计里的 "法官判案",到底在验什么
假设检验是统计推断的核心,也是最劝退的知识点,一句话讲透本质:假设检验 = 带概率的反证法,先假设一个结论成立(原假设),然后看我们手里的样本,在这个假设下出现的概率有多大。如果概率太小(p 值 < 0.05),就说明原假设很可能不成立,我们就拒绝它;反之,就没有足够的证据拒绝它。核心概念大白话:
- 原假设 H0:我们想要推翻的结论,比如 "厂家声称的零件均值 5cm""新功能没有效果"
- 备择假设 H1:我们想要证明的结论,比如 "零件均值不达标""新功能有效果"
- p 值:在原假设成立的前提下,出现当前样本甚至更极端结果的概率。p 值越小,原假设越不可信
- 显著性水平 α:判断小概率事件的标准,通常取 0.05,p 值 <α 就拒绝原假设
- 两类错误:第一类错误 = 弃真,原假设是对的,我们拒绝了;第二类错误 = 取伪,原假设是错的,我们接受了
八、相关与回归:变量之间的关系到底怎么量化
现实里,我们经常想知道两个或多个变量之间有没有关系,关系有多强,能不能用一个变量预测另一个,这就是相关与回归的核心作用:
- 相关分析:只看两个变量之间有没有线性关系,关系有多强,不区分因果,用相关系数衡量。比如身高和体重的相关性、广告投放和销售额的相关性
- 线性回归:给变量之间的关系,拟合一个线性方程,用自变量预测因变量。比如用广告投放金额,预测销售额;用用户的年龄、消费习惯,预测用户的生命周期价值。本质就是找到一条最贴合所有数据的直线,让预测误差最小
- 回归的核心意义:把变量之间的相关关系,变成可量化、可预测的公式,是数据分析、AI 建模最基础、最常用的工具
九、方差分析:多组数据的差异到底有没有意义
我们经常会遇到多组数据对比的场景,比如三个不同版本的 APP,用户留存率有没有差异;四种不同的肥料,农作物产量有没有差异,这就是方差分析的核心作用:方差分析,又叫 ANOVA,本质是检验多组数据的均值,有没有显著差异。它把数据的波动,分成组内波动(随机误差)和组间波动(不同处理带来的差异),如果组间波动远大于组内波动,就说明不同组之间的差异,不是随机误差导致的,是真实存在的。对应现实:A/B 测试里多组方案对比、多组临床试验效果对比、不同运营策略的效果对比,全靠方差分析判断差异有没有统计学意义。
十、全部知识串联:概率统计完整逻辑链
随机事件 = 我们要研究的不确定对象概率 = 给不确定性做量化分布 = 随机事件的固定行为剧本数字特征 = 描述剧本的核心刻度大数定律 + 中心极限定理 = 保证规律的稳定性,是统计推断的基石参数估计 = 用样本数据,估算总体的真实参数假设检验 = 验证我们对总体的判断是否成立相关与回归 = 量化变量之间的关系,做预测方差分析 = 对比多组数据的差异是否真实存在
十一、现实落地:学概率统计到底能干什么
完全脱离做题,讲真实用途:
- 数据分析:用户行为分析、业务指标分析、A/B 测试,全靠概率统计做支撑
- 人工智能:机器学习、深度学习的底层,全是概率统计,贝叶斯模型、逻辑回归、聚类算法,本质都是统计建模
- 金融风控:信贷违约预测、投资风险评估、股价预测,核心是用概率量化风险
- 生物医药:药品临床试验、疾病发病率分析、药效验证,全靠假设检验做判断
- 工业生产:产品质检、良品率控制、设备故障预测,用统计方法保证产品质量
- 市场调研:用户偏好分析、问卷数据处理、市场规模预测,用样本推断总体
十二、最终极简总括(背诵级)
概率是不确定性的量化标尺,统计是随机数据的规律探测器;分布是随机事件的行为剧本,期望方差是剧本的核心特征;大数定律保证频率收敛于概率,中心极限定理撑起正态分布的通用性;参数估计用样本猜总体,假设检验用数据验结论;相关回归量化变量关系,方差分析判断组间差异;整个概率统计,就是:研究不确定世界的固定规律,用少量样本推断全局真相。
概率统计|结合 AI / 数据分析专业 全通俗通关讲解
(全程无公式、纯大白话、连贯逻辑、结合你之前 4 个可视化案例,把概率统计每一个核心知识点,直接绑定到 AI / 数据分析的实际干活场景)
先定总基调:AI / 数据分析 = 从头到尾全是概率统计数据分析不是做表格、画图表,AI 不是调库、堆模型,它们是「从海量随机数据里提取规律、做预测决策的工具」。只要涉及:用户画像、A/B 测试、特征工程、模型训练、效果评估、风控建模、推荐算法,底层全部是:概率做不确定性量化、分布做数据建模、统计量做特征提取、统计推断做效果验证、回归分析做预测建模不学概率统计,你只会拉取数据、做可视化、调别人写好的模型;学懂概率统计这套逻辑,你能自己设计分析方案、自己做特征工程、自己优化模型、自己解释模型结果、自己设计 A/B 测试并验证效果,真正从 "取数工具人" 变成 "业务决策人"。
1. 概率到底是什么(AI / 数据分析版理解)
普通理解:事件发生的可能性AI / 数据分析理解:概率 = 用户行为 / 业务数据的不确定性量化标尺用户会不会点击广告、会不会下单、会不会流失、会不会违约,全都是不确定的随机事件,我们做的所有分析、所有建模,本质都是在计算这些事件的发生概率,用概率给业务做决策。比如推荐系统,核心就是计算 "用户点击这个商品的概率",把概率最高的商品推给用户;风控模型,核心就是计算 "用户违约的概率",概率高的直接拒绝。
2. 分布|AI / 数据分析天天在用
普通理解:一堆公式AI / 数据分析理解:分布 = 数据的天生行为模式,是数据分析和建模的前提我们拿到的所有业务数据,用户消费金额、用户生命周期、访问时长、订单量,全都是有固定分布的。
- 正态分布:用户身高、体重、访问时长、模型的预测误差,做特征工程时,经常要把数据转换成正态分布,提升模型效果
- 伯努利 / 二项分布:用户是否点击、是否下单、是否流失,分类模型的预测目标,全都是二项分布
- 泊松分布:用户一天内的访问次数、商品的日订单量,用来做销量预测、流量预测
- 幂律分布:用户消费金额、粉丝数量,20% 的用户贡献 80% 的收入,就是幂律分布的核心特征,做用户分层、精细化运营的核心依据做数据分析的第一步,就是看数据的分布,不看分布的分析,全是瞎分析。
3. 数字特征|数据分析的核心指标
之前讲的期望、方差、分位数、相关系数,就是我们做数据分析时,天天在用的核心指标:
- 期望:就是我们常说的均值,平均客单价、平均访问时长、平均转化率,业务最核心的基础指标
- 方差 / 标准差:衡量数据的波动,比如客单价的波动、日订单量的波动,波动大说明业务不稳定,需要定位原因
- 分位数:中位数、90 分位、95 分位,比均值更抗异常值,比如用户消费金额,少数土豪用户会把均值拉高,中位数更能代表普通用户的真实消费水平
- 相关系数:分析两个业务指标的相关性,比如广告投放和销售额的相关性、用户访问时长和转化率的相关性,快速找到影响业务的核心因素
4. 大数定律与中心极限定理|A/B 测试的底层基石
很多人做 A/B 测试,只看两组数据的均值差异,却不知道这两个定理才是 A/B 测试能成立的根本:
- 大数定律:保证了试验样本量足够大时,样本均值才能代表真实的用户群体均值。样本量太小,结果全是随机波动,根本不可信,这就是为什么 A/B 测试必须要凑够样本量,不能看一天的数据就下结论
- 中心极限定理:保证了不管用户原始数据是什么分布,只要样本量足够大,样本均值的分布就是正态分布,我们才能用假设检验,判断 A、B 两组的差异,到底是真实的效果差异,还是随机误差导致的。所有 A/B 测试平台、所有效果验证,底层全靠这两个定理撑着。
5. 参数估计与置信区间|业务指标的可靠估算
我们做数据分析时,永远只能拿到历史样本数据,估算的转化率、客单价、留存率,都是样本统计量,而置信区间,就是给这些指标一个可靠的范围。比如你算出来新功能的用户转化率是 5%,95% 置信区间是 4.6%, 5.4%,这就比单独一个 5% 靠谱得多,你能清楚地知道,真实的转化率大概率在这个区间里,做业务决策时,不会被单一的数值误导。在 AI 建模里,模型的预测结果,也可以给出置信区间,告诉业务方,这个预测结果的可靠程度有多少,比如预测用户的生命周期价值,同时给出 95% 置信区间,业务方可以根据可靠程度,制定不同的运营策略。
6. 假设检验|A/B 测试效果判断的核心工具
这是数据分析最核心的技能,不会假设检验,你根本没法判断 A/B 测试的结果到底有没有效。比如你做了一个新功能,上线后实验组的转化率比对照组高 2%,你怎么判断这个提升,是新功能带来的,还是随机波动导致的?答案就是假设检验:
- 原假设:新功能没有效果,两组转化率没有差异
- 备择假设:新功能有效果,两组转化率有显著差异
- p 值 < 0.05:说明这个差异,只有不到 5% 的概率是随机波动导致的,我们就可以认为新功能真的有效,全量上线
- p 值 > 0.05:说明没有足够的证据证明新功能有效,不能全量上线所有互联网公司的 A/B 测试、功能迭代、运营策略优化,全靠假设检验做最终的效果判断。
7. 相关与回归|预测建模的基础
线性回归是机器学习最基础、最常用的模型,也是所有复杂模型的底层逻辑:
- 相关分析:做特征工程的第一步,筛选和目标变量相关性高的特征,去掉冗余、无关的特征,提升模型效果
- 线性回归:最简单的预测模型,用多个业务特征,预测目标指标,比如用用户的年龄、性别、访问时长、历史消费金额,预测用户未来的消费金额
- 逻辑回归:分类问题的核心模型,本质是用线性回归计算事件发生的概率,是风控建模、点击率预测、流失预警的首选模型,互联网公司的风控系统,绝大多数都是用逻辑回归搭建的,因为它可解释性强,结果就是概率,非常贴合业务需求。
8. 方差分析|多组 A/B 测试的效果对比
当你的 A/B 测试,不是两组,而是三组、四组甚至更多方案时,比如你想测试 5 个不同的商品详情页,哪个转化率最高,这时候就需要用方差分析。它能一次性判断,这多组方案的转化率,到底有没有显著差异;如果有,再进一步做两两对比,找到最优的方案。如果不用方差分析,直接两两做假设检验,会大大提升犯错的概率,得出错误的结论,这就是方差分析在多组对比里的核心价值。
9. 贝叶斯统计|AI 建模的核心流派
传统的频率派概率,是固定的、客观的;而贝叶斯统计,是先有一个先验概率,然后根据新的数据,不断更新后验概率,非常贴合现实里的决策逻辑。在 AI 领域,贝叶斯统计的应用无处不在:
- 朴素贝叶斯模型:文本分类、垃圾邮件识别的经典模型,计算速度快,效果好
- 贝叶斯优化:超参数优化的核心方法,比网格搜索、随机搜索效率高得多,能快速找到模型的最优超参数
- 贝叶斯神经网络:能给出预测结果的不确定性,在自动驾驶、医疗诊断等高风险场景,非常重要
- 推荐系统:用贝叶斯方法,不断根据用户的新行为,更新用户的偏好概率,实现个性化推荐
10. AI / 数据分析完整串联(终极打通)
所有用户行为、业务数据、指标波动 → 都是随机事件,用概率做量化所有数据的分布、行为模式 → 靠分布来描述,是分析和建模的前提所有业务核心指标、特征提取 → 全是数字特征的计算所有 A/B 测试、效果验证 → 靠大数定律 + 中心极限定理做支撑,用假设检验做判断所有业务预测、用户分层 → 靠相关与回归、分类模型实现所有多组方案对比、策略优化 → 靠方差分析判断差异是否真实所有模型优化、不确定性评估 → 靠贝叶斯统计实现
11 给 AI / 数据分析从业者一句大实话
为什么数据分析、人工智能的必修课,强制学概率统计?不学概率统计:你只会拉取数据、做可视化、调别人写好的模型,做一个 "取数工具人""调参侠",根本没法解释数据、解释模型,更没法给业务提供有价值的决策建议学懂概率统计这套逻辑:你能自己设计分析方案、自己设计 A/B 测试、自己做特征工程、自己搭建和优化模型、自己解释模型结果、自己给业务提供可落地的决策建议,真正成为业务的核心驱动者Excel、SQL、Python 是数据分析的工具可视化是数据分析的呈现方式概率统计,是数据分析和 AI 的灵魂与底层逻辑
概率统计是机器人应对真实不确定性的核心工具:传感器噪声服从高斯分布,运动误差用期望/方差量化,故障诊断依赖假设检验。本文用工程视角重构知识点:①抛弃古典概型,聚焦机器人四大分布(高斯/均匀/二项/泊松);②代码实战三场景:IMU噪声模拟(正态分布)、滑动窗口滤波(大数定律)、电机故障检测(p值检验);③联动控制/导航/视觉等专业课------卡尔曼滤波=期望迭代,路径规划=随机采样,视觉识别=概率分割。附可直接运行的Python仿真代码,解决"学完不会用"痛点,实现"概率统计→机器人误差补偿→算法优化"全链路打通。