建议:这道题目基本把 刚刚做过的字符串操作 都覆盖了,不过就算知道解题思路,本题代码并不容易写,要多练一练。 题目链接:https://leetcode.cn/problems/reverse-words-in-a-string/ 视频讲解:https://www.bilibili.com/video/BV1uT41177fX
一、看到题目的第一想法
- 题目要求理解 :给定一个字符串
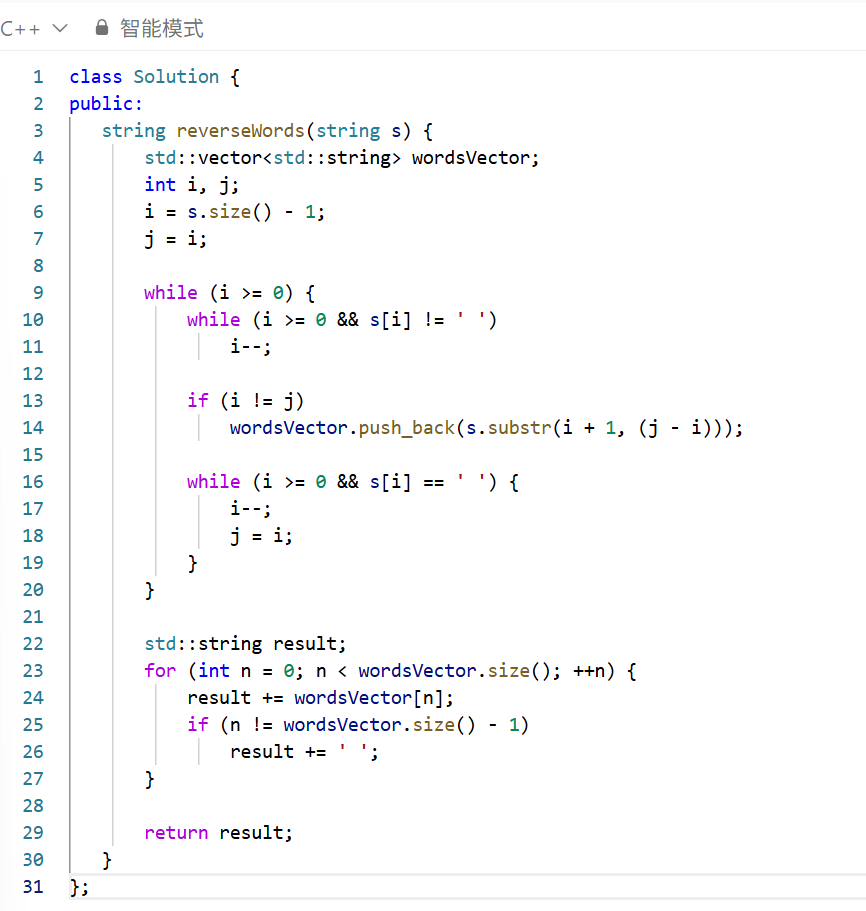
s,反转字符串中单词的顺序,同时要去除首尾和中间多余的空格,保证单词之间只有一个空格分隔。比如" hello world! "要变成"world! hello"。 - 核心思路:从字符串的末尾向前遍历,先跳过空格,找到单词的末尾位置;再继续向前遍历,找到单词的开头位置;把这个单词截取出来存入容器;再跳过中间的空格,重复这个过程,直到遍历完整个字符串。最后把容器里的单词按顺序拼接起来,中间用一个空格隔开。
- 初步实现念头 :
- 用双指针
i和j,j标记单词的末尾,i标记单词的开头,从后往前遍历。 - 遇到非空格字符就移动
i继续向前,遇到空格就把[i+1, j]这个区间的单词截取出来,存入vector<string>。 - 最后遍历容器,把单词拼接成结果字符串,中间加上空格。
- 用双指针
二、实现过程中遇到的困难
- 边界条件的处理
- 一开始没有考虑字符串开头 / 结尾的连续空格,比如
" a b c ",导致截取单词时出现空字符串,拼接后出现多余空格。后来才想到用while循环先跳过所有空格,再标记单词的起始和结束位置。 - 循环条件容易越界:比如
while (i >= 0 && s[i] != ' '),一开始忘记加i >= 0,当遍历到字符串开头时,i变成负数,访问s[i]会报错。
- 一开始没有考虑字符串开头 / 结尾的连续空格,比如
- 截取子串
substr的参数理解错误- 一开始搞混了
substr(pos, len)的参数含义,错误地写成s.substr(i, j - i + 1),导致截取的单词长度不对。后来才纠正过来:substr第一个参数是起始下标,第二个参数是长度,所以从i+1开始,长度是j - i才正确。
- 一开始搞混了
- 拼接时多余空格的问题
- 一开始直接在每个单词后面都加一个空格,导致结果字符串末尾多出一个空格。后来才改成 "不是最后一个单词才加空格",用
if (n != wordsVector.size() - 1)来控制。
- 一开始直接在每个单词后面都加一个空格,导致结果字符串末尾多出一个空格。后来才改成 "不是最后一个单词才加空格",用
- 单词连续空格的处理
- 一开始没有处理单词之间的多个空格,导致截取时把多个空格也当成了分隔符,产生空字符串。后来才在截取完一个单词后,用
while (i >= 0 && s[i] == ' ')把中间的所有空格都跳过,保证每次只处理一个单词。
- 一开始没有处理单词之间的多个空格,导致截取时把多个空格也当成了分隔符,产生空字符串。后来才在截取完一个单词后,用
三、今日收获心得
- 从后往前遍历的技巧这道题让我学会了 "反向遍历" 的思路:从字符串末尾开始找单词,天然就实现了单词顺序的反转,不需要再额外反转整个单词列表,简化了逻辑。这种思路在处理反转类、分隔类字符串问题时非常实用。
substr与区间操作的巩固 彻底搞懂了substr(pos, len)的用法,以及如何用两个指针来确定子串的区间。同时也加深了对 "左闭右开" 区间的理解,避免了截取子串时的长度错误。- 边界与特殊情况的鲁棒性处理 这道题包含了很多特殊情况:空字符串、全是空格的字符串、首尾有空格、单词间多个空格、单个单词的字符串等。通过这次实现,我学会了用
while循环来过滤掉所有无关的空格,而不是依赖固定的分隔符,让代码能处理所有边界情况。 - 代码结构的优化意识 原来以为要写很多
if-else来判断各种情况,后来发现用双指针 + 循环过滤的方式,能把所有空格和单词的处理统一起来,代码更简洁、更健壮,也更容易维护。 - 空间复杂度的思考 这道题的解法用了一个
vector<string>来存储单词,空间复杂度是 \(O(n)\)。虽然能通过题目,但也让我意识到可以尝试 "原地修改字符串" 的优化思路(比如先反转整个字符串,再反转每个单词,最后去除多余空格),来把空间复杂度降到 \(O(1)\),这对后续的进阶学习很有启发。