一. 前言:
二叉树遍历可以分为 "递归遍历" (DFS), "层序遍历" (BFS)
递归遍历分为三个位置 : 前序遍历,中序遍历,后序遍历
层序遍历则 有三种写法-----对应三种不同的场景
具体内容且听我娓娓道来。
二.递归遍历:
以下是简单的递归遍历二叉树的代码:
cpp
#include<iostream>
using namespace std;
class TreeNode{
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int val) : left(nullptr),right(nullptr) , val(val){}
};//用结构体也是一样的
void traverse(TreeNode* root){
if (root == nullptr){
return;
}
traverse(root->left);
traverse(root->right);
}//就是一个游走的指针这个遍历是从左到右来遍历子节点
正常来说二叉树遍历都是先左后右来遍历子节点,少见的先右后左来遍历子节点
可以看以下图:
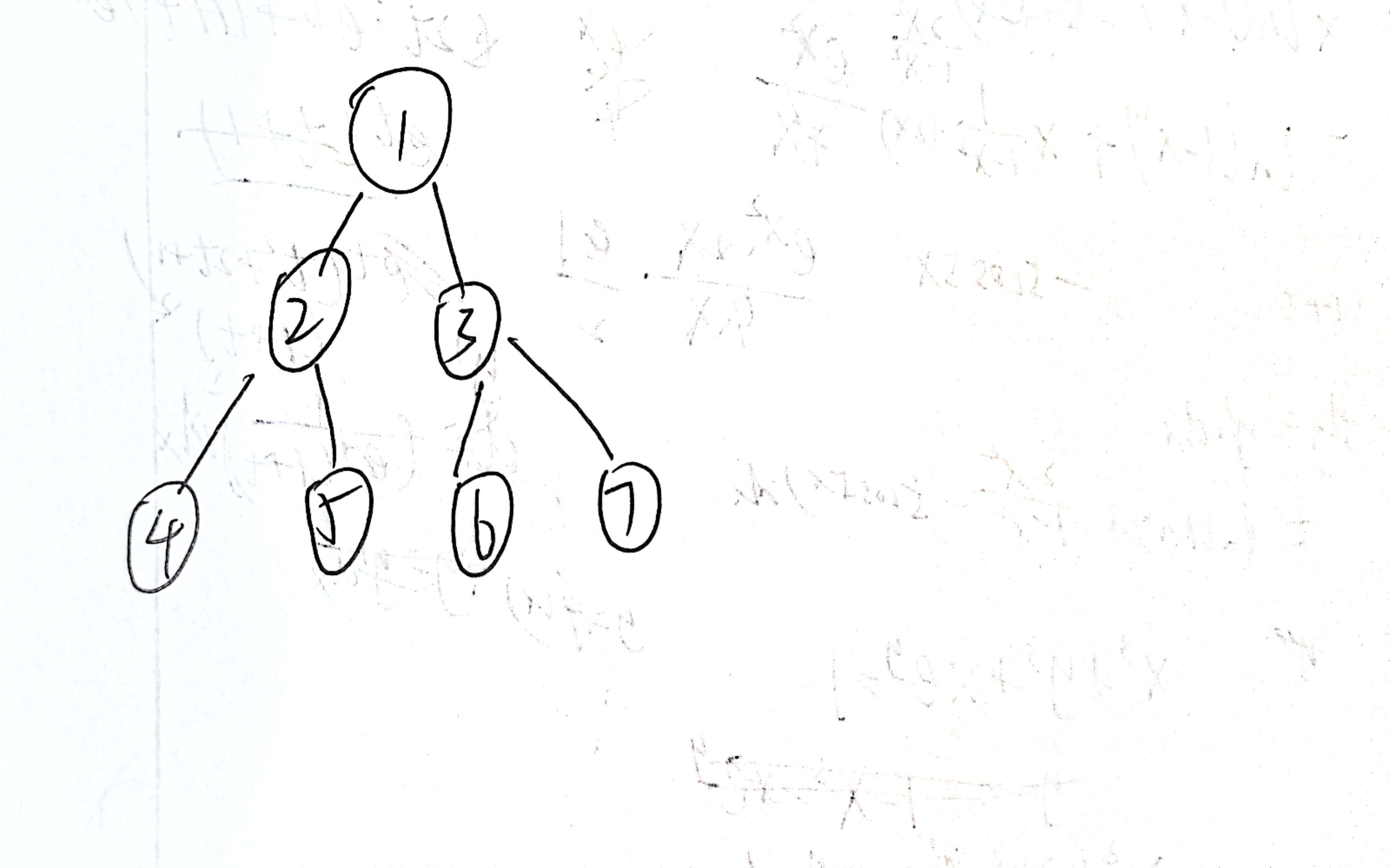
假设二叉树中储存了这些节点,
那么我上面遍历的代码的遍历顺序就是 : 1 - 》 2 - 》 4 -》 5 -》 3 -》 6 ---》 7
先走完左边,当root等于nullptr的时候,就返回上一个节点然后接着走右边
• 前 / 中 / 后序遍历:
区分前、中、后序遍历的关键在于根节点被访问(输出/处理)的时机,相对于左子树和右子树的遍历顺序。
前序遍历 :先访问根节点,再遍历左子树,最后遍历右子树。
顺序:根 → 左 → 右
中序遍历 :先遍历左子树,再访问根节点,最后遍历右子树。
顺序:左 → 根 → 右
后序遍历 :先遍历左子树,再遍历右子树,最后访问根节点。
顺序:左 → 右 → 根
++前序位置的代码会在进入节点时立即执行;中序位置的代码会在左子树遍历完成后,遍历右子树之前执行;后序位置的代码会在左右子树遍历完成后执行:++
按我个人的理解:
通过不同序列的遍历: 之后返回的节点就可以得到对应的信息。
前序: 子节点可以知道负节点的信息
中序: "根"(子树的根也算)节点可以知道 返回后左子树的信息
后序: "根" 节点 知晓左右子树的所有信息
那么我们应该如何实现呢?
cpp
// 二叉树的遍历框架
void traverse(TreeNode* root) {
if (root == nullptr) {
return;
}
// 前序位置
traverse(root->left);
// 中序位置
traverse(root->right);
// 后序位置
}左子节点递归函数前: 前序
左,右节节递归函数中: 中序
右子节点递归函数后 : 后序
补充: BST二叉遍历树的中序是有序的:
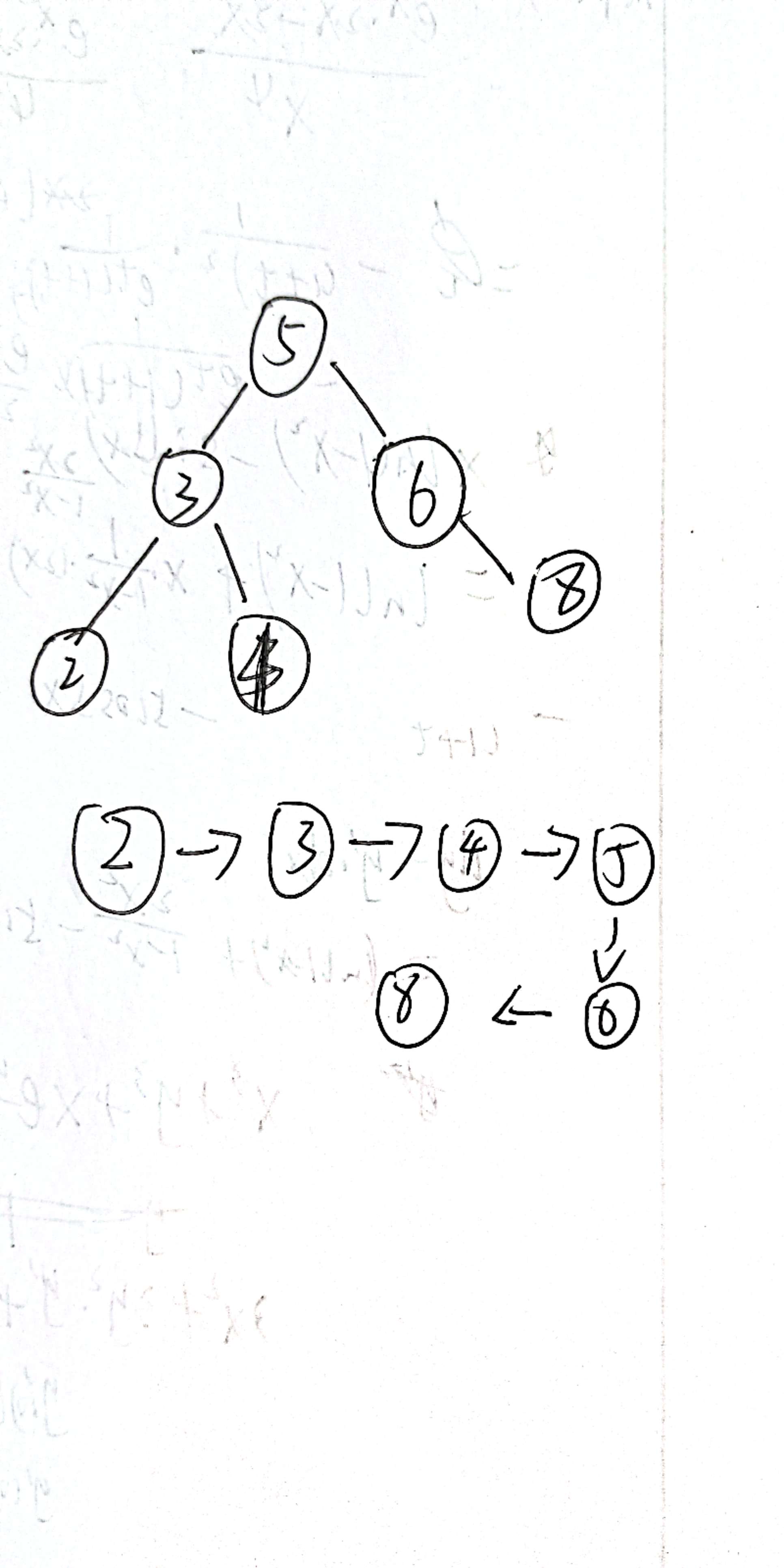
如图上所示,会按"从小到大"开始排列
小总结: 递归遍历是靠程序的"堆和栈"实现的,而层序遍历则是靠 "队列"来协助遍历
三.层序遍历:
假设二叉树存储了如上图的元素,那么遍历代码如下:
• 写法一: 最简单,不在乎树的层数
cpp
#include<iostream>
#include<queue>
using namespace std;
class TreeNode{
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int val) : val(val), left(nullptr) , right(nullptr){}
};
void levelorderTraverse(TreeNode* root){
if (root == nullptr) return;
queue<TreeNode*> q;
q.push(root);
while(!q.empty()){
TreeNode* cur = q.front();
q.pop();
cout << cur->val << endl;//模仿遍历之后的操作
if (cur->left != nullptr){
q.push(cur->left);
}
if (cur->right != nullptr){
q.push(cur->right);
}
}
}利用队列q,储存遍历的节点 "左右子节点",然后一层层遍历下去
利用队列的 "先进先出"性质,我们便能够实现层层遍历
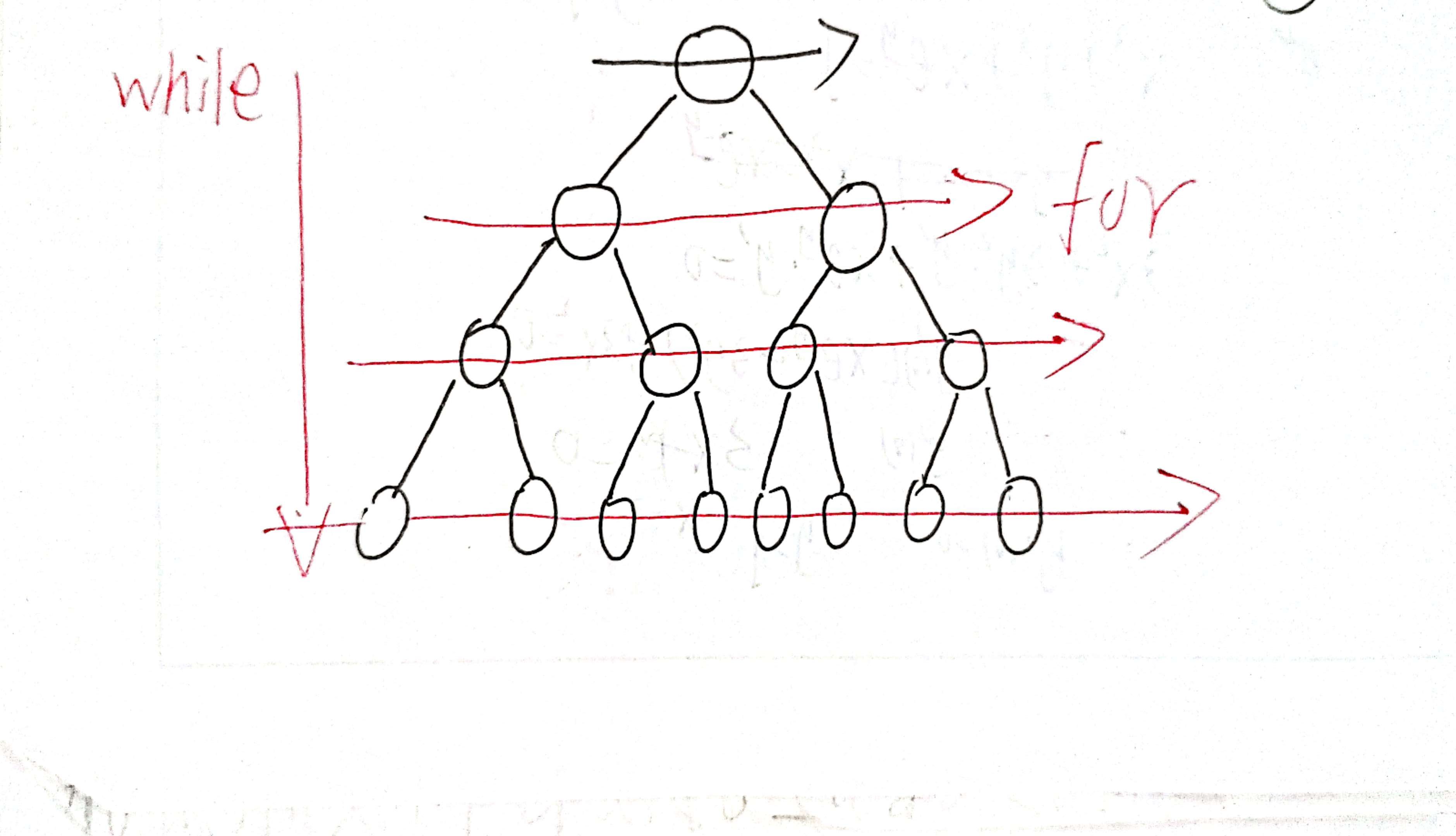
• 写法二: 最常用,可以记录树的深度
cpp
#include<iostream>
#include<vector>
#include<queue>
using namespace std;
class TreeNode{
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x), left(nullptr) , right(nullptr) {}
};
vector<int> levelOrderTraverse(TreeNode* root){
if (root == nullptr) return{};
vector<int> res; //answer数组
queue<TreeNode*> q;
q.push(root);
int depth = 1;//树的深度,根节点是一
while(!q.empty()){
int size = q.size(); //这一层的个数
for (int i = 0; i < size; i++){
TreeNode* cur = q.front();
q.pop();
res.push_back(cur->val);
if (cur->left){
q.push(cur->left);
}
if (cur->right){
q.push(cur->right);
}
}
depth++;
}
return res;
}for循环是遍历每一层的节点,当然可以用while改写
cpp
int size = q.size();
while(size--){
// ......
}depth用于记录当前的层数,根节点当作第一层
• 写法三: 适用于每个节点权重不同的复杂场景
++深度 就是 路径权重值 ,++ 后面这个概念会在图的时候详细讲述
每一个节点的权重都可以是任意值,不再是同写法二中每一个路径权重都是1,那么每一层的路径权重都是相同的
为了实现写法三权重不同的情况,聪明的读者已经想到用类或者结构体来封装这个权重了
cpp
#include<iostream>
#include<queue>
using namespace std;
class TreeNode{
public:
int val;
TreeNode* left;
TreeNode* right;
TreeNode(int x): val(x),left(nullptr) , right(nullptr) {}
};
class state{
public:
TreeNode* node;
int depth;//权重
state(TreeNode* node,int depth) : node(node), depth(depth){}
};
void levelOrderTraverse(TreeNode* root){
if (root == nullptr) return;
queue<state> q; //如果在堆区的话,就会是 state*
//假设根节点路径权重是1
q.push(state(root,1));
while(!q.empty()){
state cur = q.front();
q.pop();
cout << "depth = " << cur.depth << endl;//模仿遍历后要做的操作
if (cur.node->left){
q.push(state(cur.node->left,cur.depth+1));
}
if (cur.node->right){
q.push(state(cur.node->right,cur.depth+1));
}
}
}总结:
1. 写法一:最简单,但功能受限
代码特征 :直接
while(!q.empty()),每次取出队头节点。 适用场景:
- 只需要按顺序访问所有节点,不需要知道节点所在的层数(深度)。
- 例如:简单的二叉树节点值打印、查找某个值是否存在(且不关心深度)。 缺点:无法区分哪些节点属于同一层,因此无法解决与"层"或"深度"相关的问题。
2. 写法二:最常用,可记录深度
代码特征 :在
while循环内部增加一个for循环,利用int sz = q.size()一次性处理完当前层的所有节点。 适用场景:
- 需要知道节点在第几层。
- 需要按层处理数据。
- 典型题目:
- 102. 二叉树的层序遍历(返回每一层的节点列表)。
- 111. 二叉树的最小深度。
- 104. 二叉树的最大深度。 优点:逻辑清晰,能明确感知"层"的概念,是解决大多数二叉树层级问题的标准模板。
3. 写法三:最灵活,适用于复杂权重场景
代码特征 :定义一个
State结构体/类,将节点指针和附加信息(如depth、路径权重和等)绑定在一起存入队列。 适用场景:
- 树枝带有权重,且同一层节点的路径权重和不同。
- 需要维护每个节点的独立状态,而不仅仅是全局的层数。
- 典型场景:
- 图的 BFS 遍历。
- BFS 暴力穷举算法框架 中的复杂状态搜索(如迷宫最短路径、滑动谜题等,状态可能包含坐标、步数、当前局面等)。
- Dijkstra 算法 等最短路径算法的基础思想。 优点:解耦了节点和其附属状态,能够处理非均匀权重的遍历问题,是通用 BFS 算法的核心写法。
结语:
二叉遍历本质上就这两种写法,递归遍历和层序遍历,其他写法的本质也是这两种,希望我和大家能够灵活运用,respect。
喜欢我的文章,不妨点一个免费的赞或者收藏,如果想要持续看我最新的文章,可以点个关注不迷路。
下期再见!