本文记录了我从 GitHub 找到 YOLOv5 仓库、克隆代码、配置 Conda 环境、解决国内 pip 安装 SSL 报错、准备数据集,到最终跑通训练 的完整过程。包含所有踩坑点和可直接复制的命令,适合新手一步步跟着操作。
📌 软硬件环境
| 项目 | 配置 |
|---|---|
| 操作系统 | Windows 10 / 11 |
| Python 版本 | 3.8(Conda 虚拟环境) |
| PyTorch 版本 | 2.4.1(CPU 版,可换 GPU) |
| YOLOv5 版本 | master(最新版) |
| 数据集 | 自己标注的口罩检测数据集(2 类:mask / no-mask) |
1️⃣ 第一步:在 GitHub 上找到 YOLOv5 仓库并克隆到本地
1.1 访问 YOLOv5 官方仓库
打开浏览器,进入 GitHub 官网(https://github.com),在搜索框输入 ultralytics/yolov5 或直接访问:
https://github.com/ultralytics/yolov5你会看到 YOLOv5 的官方主页,上面有代码文件、README 说明、以及最新的发布版本。
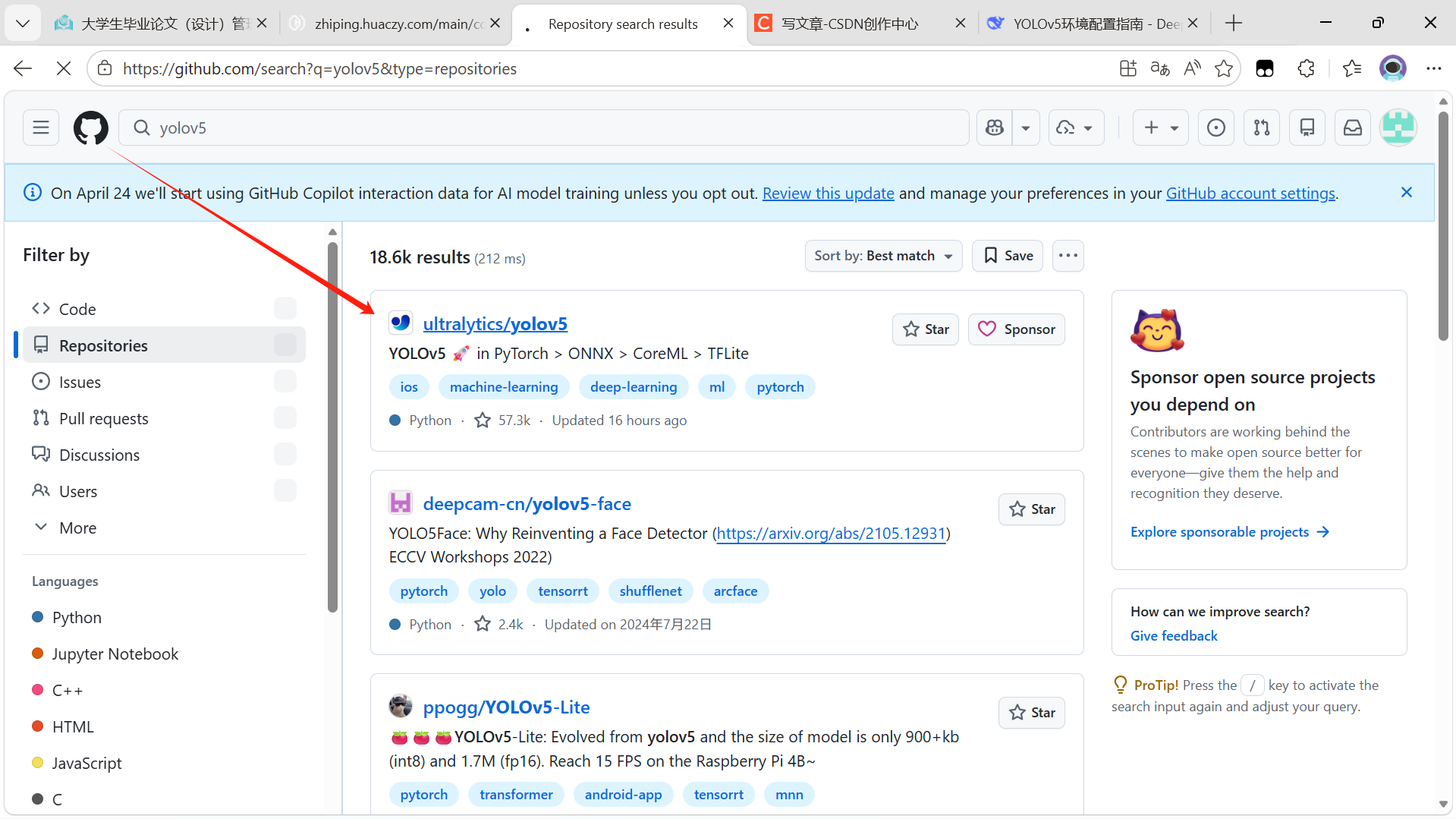
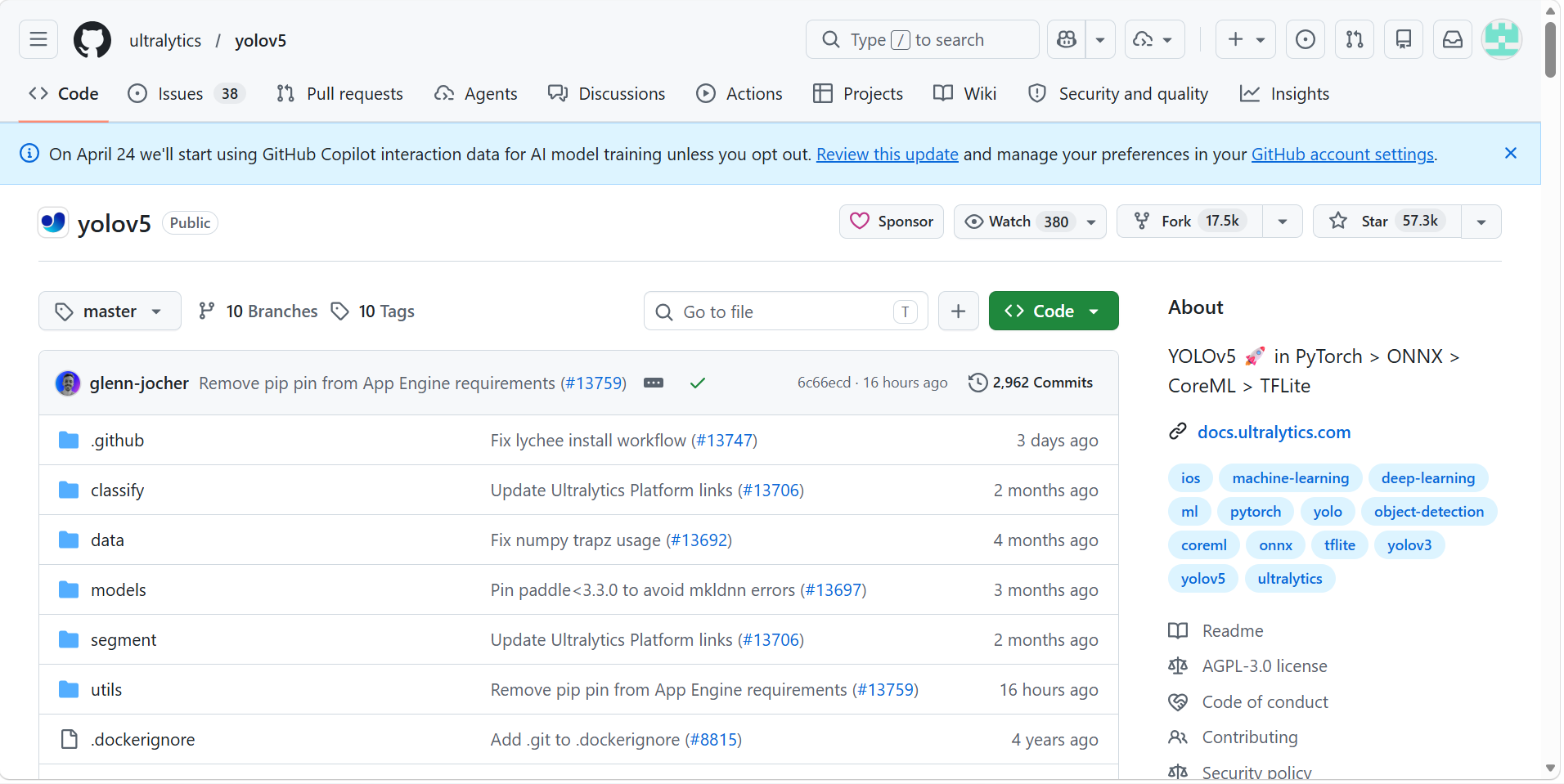
1.2 复制仓库的克隆地址
点击页面右侧绿色的 "Code" 按钮,会弹出一个下拉框。
选择 "HTTPS" 标签,然后点击复制图标,得到仓库地址:
https://github.com/ultralytics/yolov5.git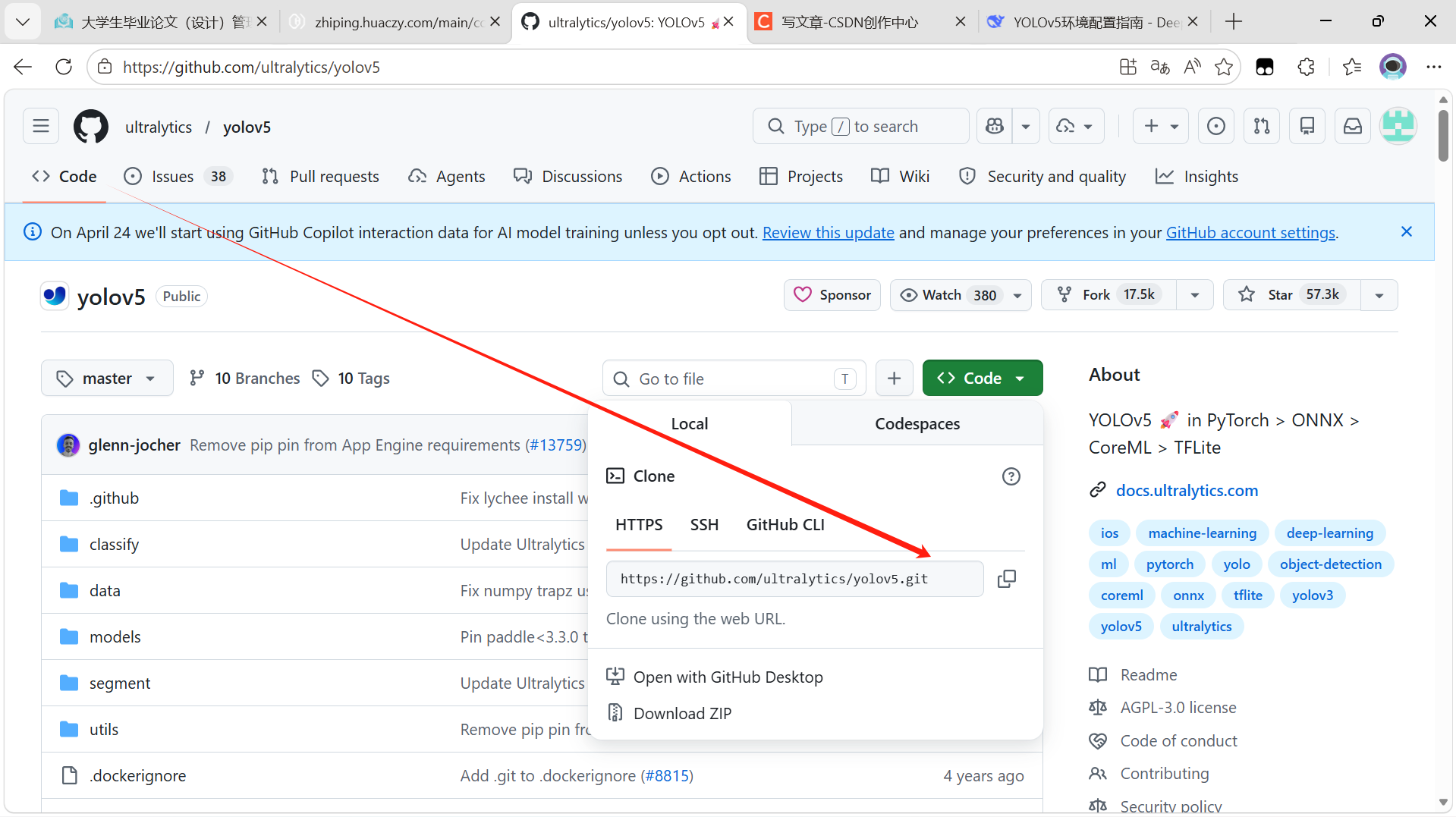
💡 如果你配置了 SSH 密钥,也可以选择 SSH 方式,但 HTTPS 最通用。
1.3 在本地打开命令行并克隆代码
在你的电脑上选择一个存放项目的目录,例如 D:\Yolov5。
在该目录下打开命令提示符(或 Git Bash、PowerShell),执行:
git clone https://github.com/ultralytics/yolov5.git等待下载完成,你会看到类似输出:
Cloning into 'yolov5'...
remote: Enumerating objects: 17898, done.
remote: Counting objects: 100% (83/83), done.
Receiving objects: 100% (17898/17898), 17.03 MiB | 5.00 MiB/s, done.
Resolving deltas: 100% (12192/12192), done.克隆完成后,当前目录下会出现一个名为 yolov5 的文件夹。
1.4 进入项目目录并查看内容
cd yolov5
dir # Windows 下查看文件列表你应该能看到 train.py、detect.py、requirements.txt、models/、data/ 等重要文件。
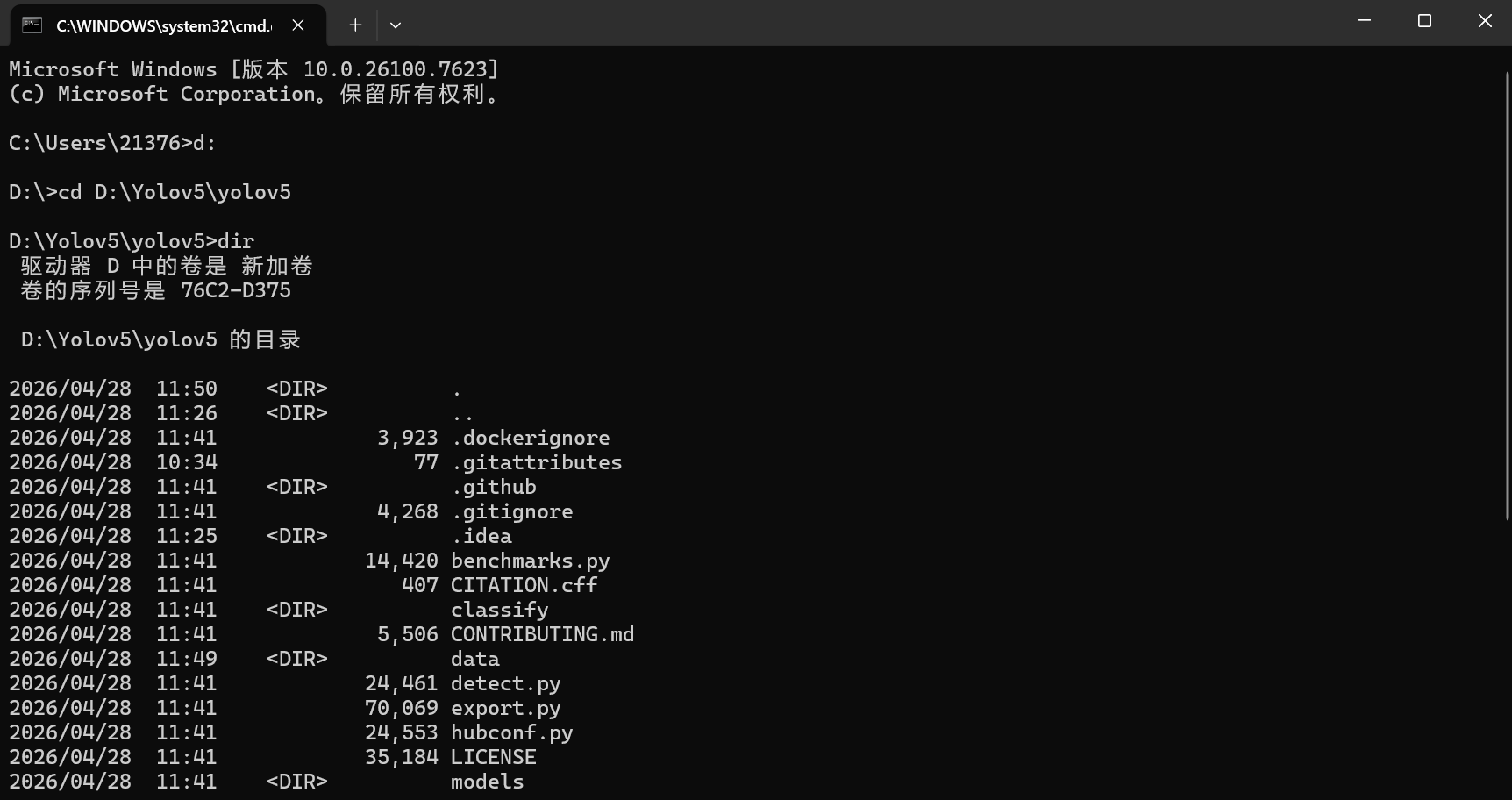
至此,代码已经准备就绪。
2️⃣ 使用 Conda 创建独立环境(避免污染全局 Python)
为了不影响其他 Python 项目,强烈建议使用虚拟环境。
如果你还没有安装 Conda,推荐安装 Miniconda(轻量级)或 Anaconda。
打开 Anaconda Prompt 或普通的命令提示符(确保 conda 命令可用),执行:
# 创建名为 yolov5_env 的环境,指定 Python 3.8
conda create -n yolov5_env python=3.8
# 激活环境
conda activate yolov5_env激活成功后,命令行前面会出现 (yolov5_env),表示现在处于虚拟环境中。
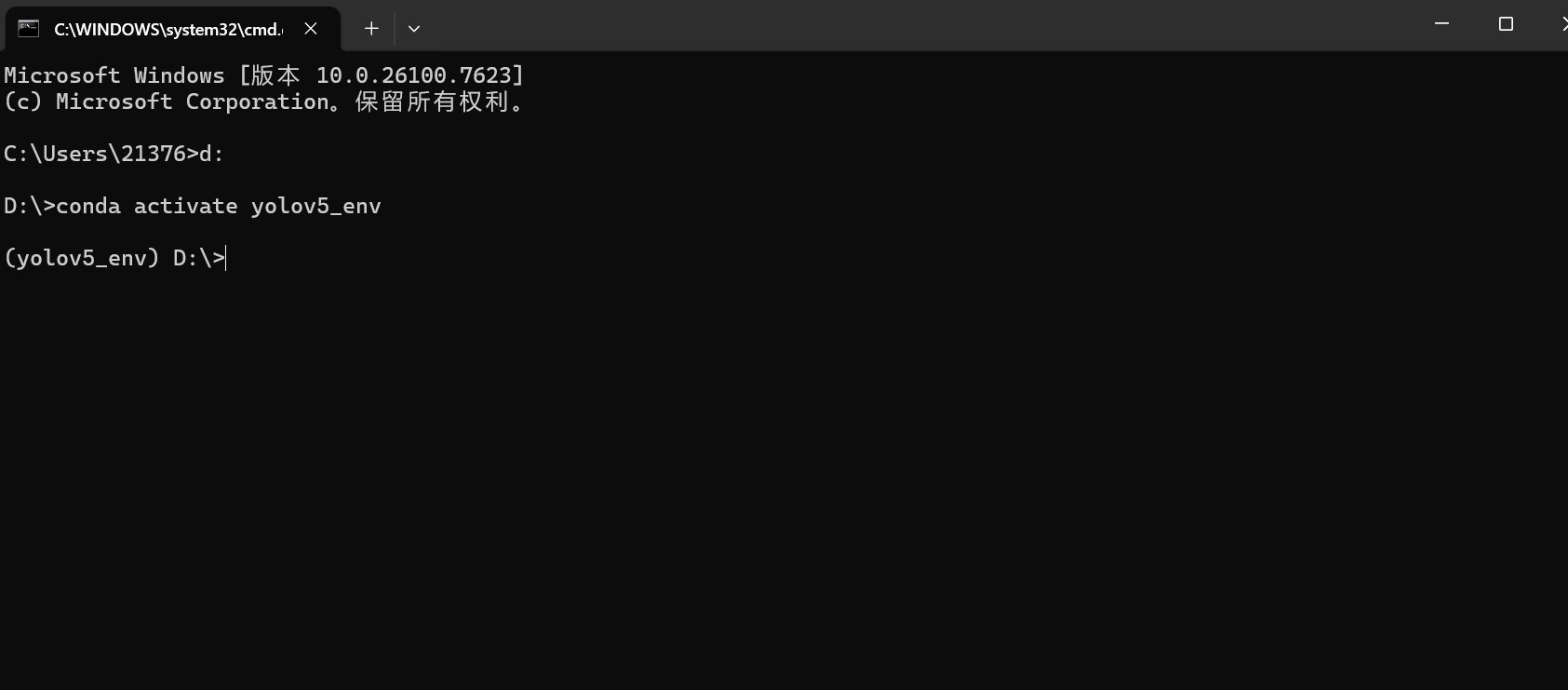
3️⃣ 安装项目依赖(解决国内 SSL 报错)
在激活的环境下,进入项目目录(如果还在外面就 cd D:\Yolov5\yolov5),然后安装依赖。
直接运行 pip install -r requirements.txt 可能因 SSL 证书问题而失败(尤其在国内网络环境下)。
我们可以换用国内 HTTP 镜像源 绕过该问题。
推荐使用阿里云镜像:
pip install -r requirements.txt -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com如果依然慢,可换清华源:
pip install -r requirements.txt -i http://pypi.tuna.tsinghua.edu.cn/simple --trusted-host pypi.tuna.tsinghua.edu.cn如果后期训练时提示缺少某个包(例如
tensorboard),单独安装即可:
pip install tensorboard -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com
4️⃣ 准备自己的数据集
YOLOv5 要求数据集按以下结构放置:
你的数据集根目录/
├── train/
│ ├── images/ (训练图片)
│ └── labels/ (与图片同名的 txt 标签文件)
└── valid/
│ ├── images/ (验证图片)
│ └── labels/ (标签文件)以我的口罩检测数据集为例
我的数据集存放在 D:\Yolov5\dataset\MaskDataSet\,结构如下:
MaskDataSet/
├── train/
│ ├── images/ (例如 img_001.jpg, img_002.jpg ...)
│ └── labels/ (img_001.txt, img_002.txt ...)
└── valid/
├── images/
└── labels/
创建数据集配置文件 data.yaml
在 YOLOv5 项目根目录下的 data/ 文件夹中,新建一个文件,例如 mask_data.yaml(你也可以叫 data.yaml)。
内容如下(路径务必写对):
# 绝对路径写法(最推荐,避免相对路径错误)
train: D:/Yolov5/dataset/MaskDataSet/train/images
val: D:/Yolov5/dataset/MaskDataSet/valid/images
# 类别数量
nc: 2
# 类别名称(顺序需要与标签文件中的类别 id 对应)
names: ['mask', 'no-mask']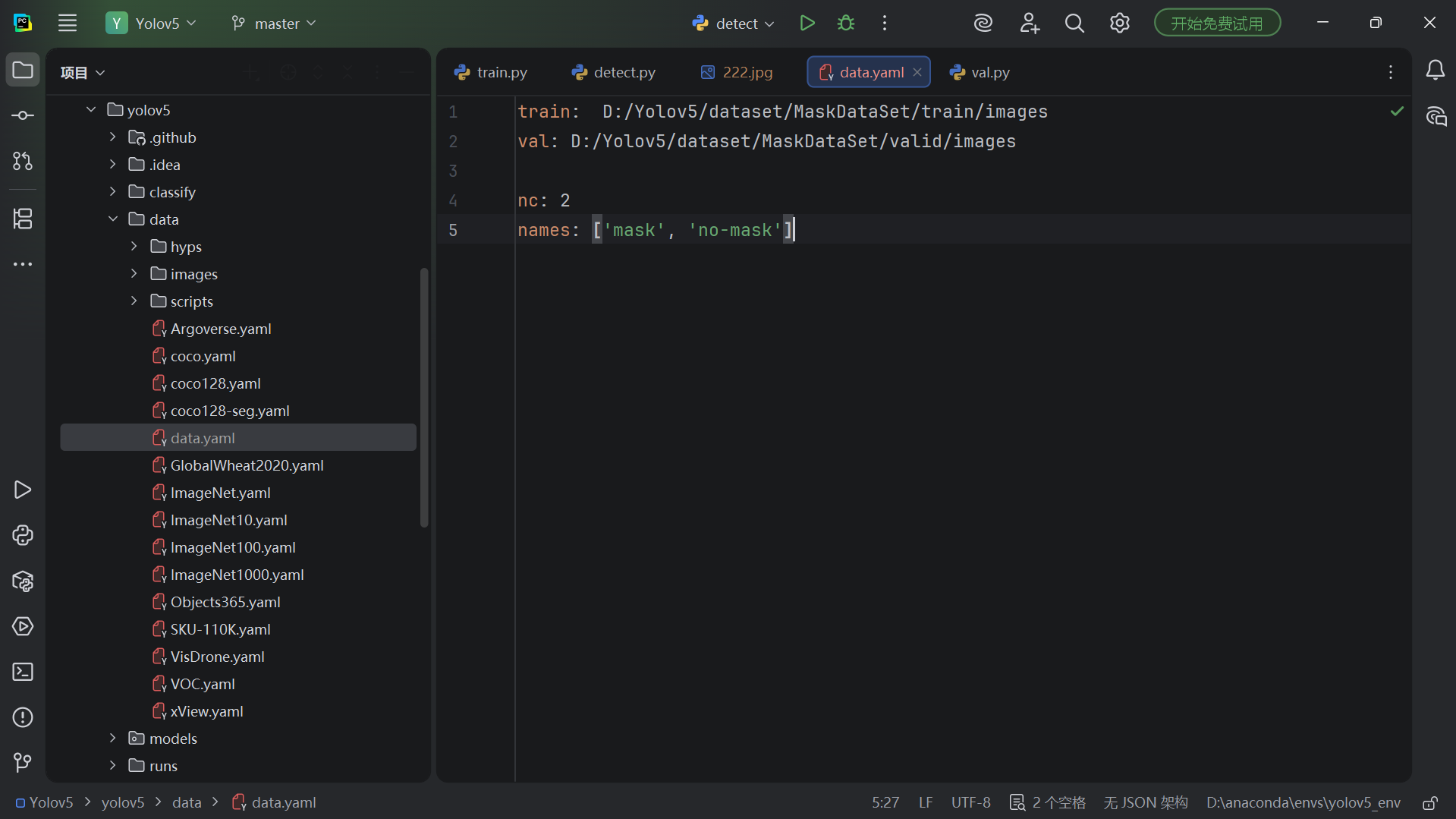
⚠️ 注意:
train和val路径指向 images 文件夹即可,YOLO 会自动在同一级目录寻找对应的labels文件夹(将images替换为labels)。
5️⃣ 修改训练参数并启动训练
在项目目录下,确保虚拟环境已激活(提示符前有 (yolov5_env)),然后执行:
python train.py --data data/mask_data.yaml --epochs 100 --batch-size 16 --device cpu参数说明:
-
--data:你创建的数据集配置文件路径 -
--epochs:训练轮数(根据数据量调整,一般 50~300) -
--batch-size:批次大小(CPU 推荐 8~16,GPU 可更大如 32) -
--device:cpu表示用 CPU;如果有 NVIDIA 显卡,可填0使用 GPU
6️⃣ 常见警告及解决方法
训练过程中可能会看到一些警告,大部分不影响最终结果,但如果你有强迫症,可以按照下面的方法消除。
📌 警告一:缓存生成时的 WinError 183
WARNING Cache directory ... is not writeable: [WinError 183] : ... labels.cache.npy -> labels.cache原因 :旧的缓存文件冲突。
解决 :删除数据集目录下的 .cache 和 .cache.npy 文件。
# 在数据集的 train 和 valid 目录下分别执行
del D:\Yolov5\dataset\MaskDataSet\train\labels.cache*
del D:\Yolov5\dataset\MaskDataSet\valid\labels.cache*重新运行训练,警告消失,且启动速度正常。
📌 警告二:AMP 混合精度 API 弃用
FutureWarning: `torch.cuda.amp.autocast(args...)` is deprecated. Please use `torch.amp.autocast('cuda', args...)` instead.原因 :PyTorch 2.x 更改了混合精度的 API。
解决 :编辑 train.py,找到类似代码(大约在第 414 行):
with torch.cuda.amp.autocast(amp):改为:
with torch.amp.autocast('cuda' if torch.cuda.is_available() else 'cpu', enabled=amp):如果不介意,也可以忽略该警告,完全不影响训练结果。
7️⃣ 训练过程监控与结果
训练过程中,你会看到类似这样的输出:
Epoch 0/99: 43%|████▎ | 3/7 [00:35<00:42, 10.74s/it]
box_loss obj_loss cls_loss
0.1223 0.05673 0.02936-
box_loss:边界框损失(定位准确度) -
obj_loss:目标是否存在置信度损失 -
cls_loss:分类损失
随着 epoch 增加,这三个损失值会逐渐下降,说明模型在学习。
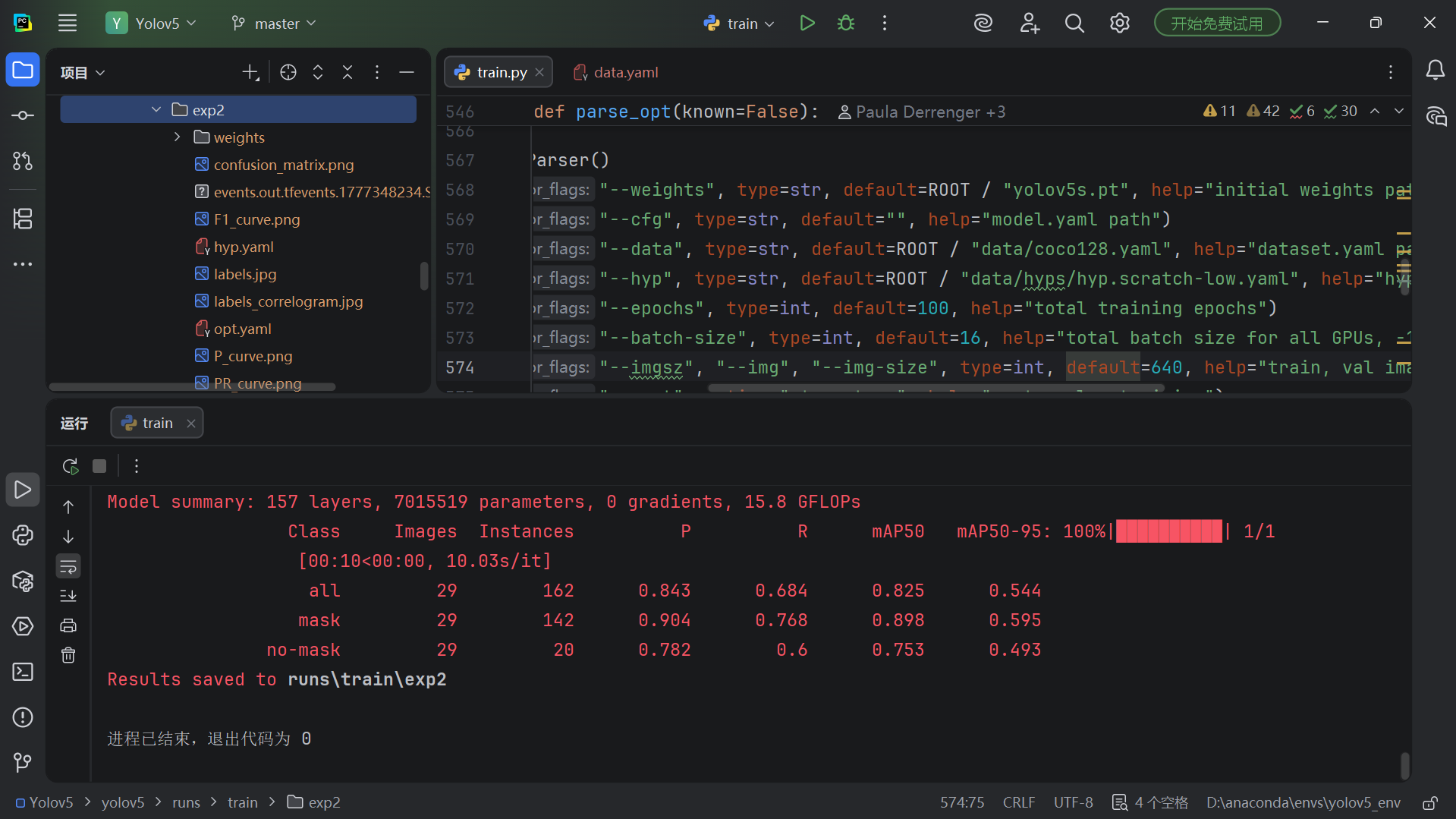
训练完成后,最优权重保存在:
runs/train/exp/weights/best.pt你也可以使用 TensorBoard 可视化训练曲线:
tensorboard --logdir runs/train8️⃣ 使用训练好的模型进行目标检测
训练完成后,我们得到了一个最优权重文件 best.pt(位于 runs/train/exp2/weights/best.pt)。接下来就可以用它来检测自己的图片或视频了。
8.1 运行 detect.py 检测单张图片
在项目根目录下,确保虚拟环境已激活,执行以下命令:
python detect.py --weights runs/train/exp2/weights/best.pt --source 你自己的图片路径参数说明:
-
--weights:指定训练好的权重文件路径 -
--source:需要检测的图片路径(也可以是视频文件、摄像头ID、或一个目录)
按下回车后,YOLOv5 会加载模型,对图片进行推理,并输出结果。
8.2 终端输出示例
你会看到类似下面的信息:
detect: weights=runs/train/exp2/weights/best.pt, source=C:\Users\21376\Desktop\222.jpg, ...
YOLOv5 v7.0-... Python-3.8.20 torch-2.4.1+cpu CPU
Fusing layers...
Model summary: 224 layers, 7069184 parameters, 0 gradients
image 1/1 C:\Users\21376\Desktop\222.jpg: 640x640 1 mask, 2 no-masks, Done. (0.523s)
Speed: 2.5ms pre-process, 523.0ms inference, 2.0ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp-
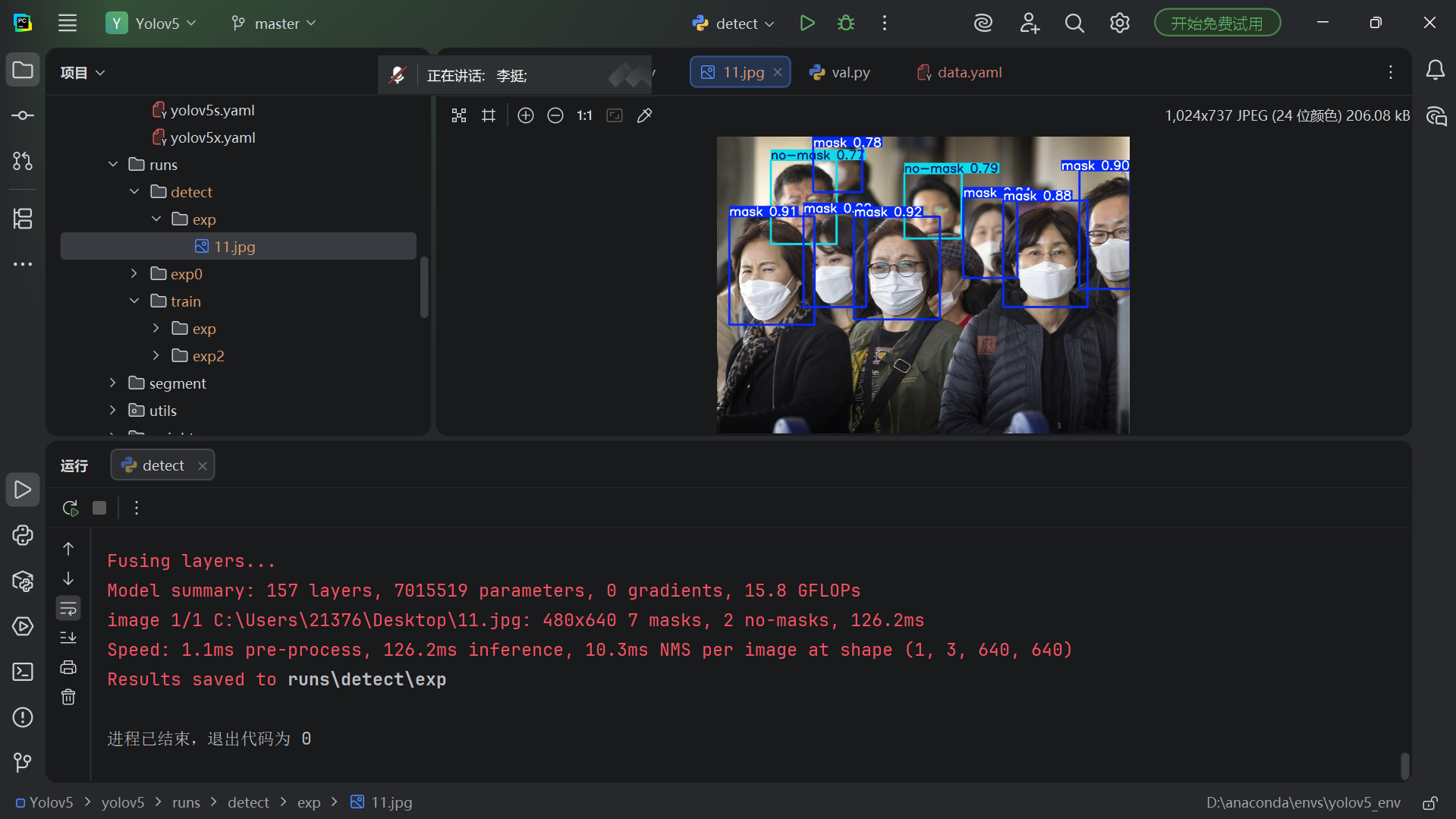
从输出可以看到:检测到了一张图片,其中有 1 个"mask"和 2 个"no-mask"目标。
-
推理时间约 0.5 秒(CPU 环境下),速度尚可。
8.3 查看检测结果图片
检测完成后,结果图片保存在:
runs\detect\exp\222.jpg打开这张图片,你会看到原图上被标注了带置信度的检测框,框上显示类别名称(mask / no-mask)和概率。
8.4 批量检测与视频检测
-
检测整个文件夹 :
--source 图片文件夹路径 -
检测视频 :
--source 视频文件.mp4 -
打开摄像头实时检测 :
--source 0
检测结果默认都会保存到 runs/detect/exp 系列文件夹中,每运行一次会生成新的 expN 目录,避免覆盖。
📌 后续扩展
如果你对检测结果满意,可以进一步:
-
导出模型为 ONNX / TensorRT 格式,加速推理;
-
使用
--save-txt参数同时保存坐标文本; -
调整
--conf-thres和--iou-thres改变置信度和 NMS 阈值。
现在,你已经完成了从环境配置到模型训练、再到目标检测的完整闭环!🎉