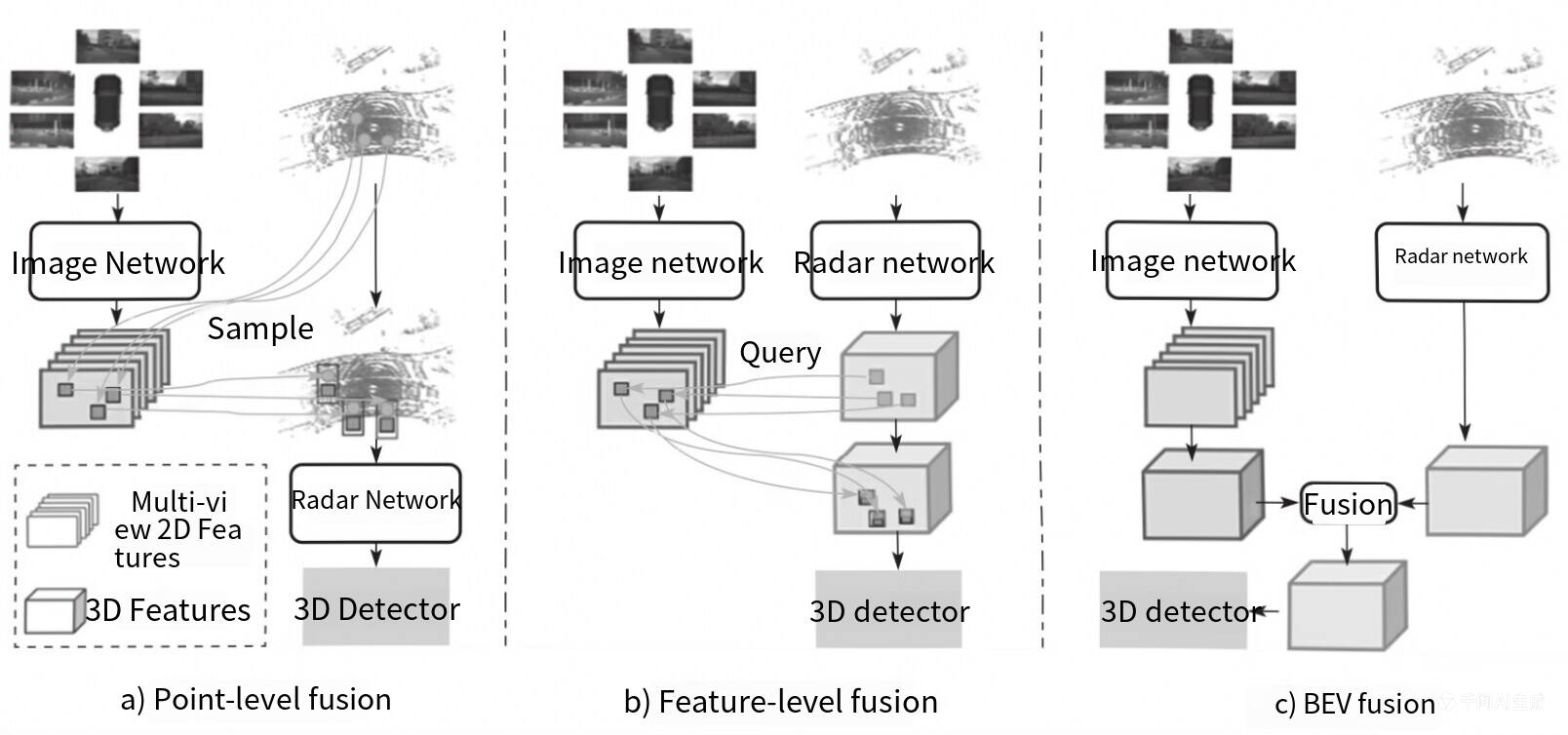
这张图非常清晰地展示了自动驾驶感知领域中三种主流的多传感器融合策略。根据图中内容以及BEVFusion的相关原理,这三类融合方式(a、b、c)的详细解读如下:
1. 点级融合
- 位置:图 a)
- 核心逻辑 :"投影与拼接"。这是最直观的融合方式,通常发生在数据处理的早期阶段。
- 工作流程:
图像网络提取图像的二维特征。
利用传感器的标定参数,将雷达点云 直接投影到图像平面上。
Sample:根据投影坐标,从图像的二维特征图上"采样"对应的像素特征。
将采样到的图像特征与原始的雷达点云特征(如深度、反射强度)拼接在一起,形成增强后的点云特征。
最后输入到雷达网络 和3D检测器中进行处理。
- 优缺点 :
- 优点 :计算量相对较小,保留了点云的几何精度。
- 缺点 :高度依赖标定的准确性。如果车在颠簸或标定有误差,投影就会错位("鬼影")。此外,图像特征是稀疏采样的,容易丢失上下文信息。
2. 特征级融合
- 位置:图 b)
- 核心逻辑 :" 跨模态查询******"******。这种方式通常是在特征提取的中间层进行交互。
- 工作流程:
图像网络 和雷达网络分别独立提取各自的特征。
Query :利用一种模态的特征(例如雷达特征)作为"查询",去另一种模态(例如图像特征)中寻找相关的信息。这通常通过交叉注意力机制实现。
通过这种"查询"机制,雷达特征被图像特征"增强"或"修正"。
融合后的特征被送入3D检测器。
- 优缺点 :
- 优点 :比点级融合更灵活,能捕捉到更深层的语义关联。
- 缺点 :依然面临视角转换的问题。雷达是在3D空间,图像是在2D平面,直接在各自视角下进行特征交互,容易出现特征对齐困难的问题。
3. BEV融合
- 位置:图 c)
- 核心逻辑 :" 统一空间,后期融合******"******。这是BEVFusion的核心创新点,也是目前最主流、效果最好的方案。
- 工作流程:
图像网络 将多视角的2D图像特征通过视图变换,提升到鸟瞰图空间。
雷达网络 将雷达点云特征也通过体素化等处理,转换到鸟瞰图空间。
Fusion :此时,图像和雷达的数据都在同一个统一的坐标系(鸟瞰图)下。直接将两者的鸟瞰图特征图在通道维度上进行拼接或融合。
融合后的鸟瞰图特征包含了丰富的语义(来自相机)和精确的几何信息(来自雷达),最后送入3D检测器。
- 优缺点 :
- 优点 :
- 鲁棒性强 :解决了视角不一致的问题,特征对齐更自然。
- 容错率高 :即使某一种传感器(如相机)失效,鸟瞰图空间的另一种特征(如雷达)依然能维持基本的检测能力。
- 信息互补:在统一空间下,两种传感器的优势互补效果最好。
- 缺点 :视图变换(从2D图像到鸟瞰图)计算量较大,对算法设计要求高。
- 优点 :
总结
这张图实际上展示了融合技术从"粗糙"到"精细"的进化过程:
- 点级融合 是在原始数据层面"硬拼"。
- 特征级融合 是在特征提取过程中"互相打听"。
- BEV融合 则是大家先"翻译"成同一种语言(鸟瞰图),然后再"坐下来深谈",因此效果通常也是最好的