List
我们当前学习的主要是带头双向循环链表。其中一个原因是循环链表可以实现时间复杂度为O(1)的插入、删除等操作。
1、基本用法
无参构造:
cpp
list<int> l1;initializer_list构造:
cpp
list<int> l2 = { 1,2,3,4 };我们就可以用迭代器和范围for的方式,打印list序列:
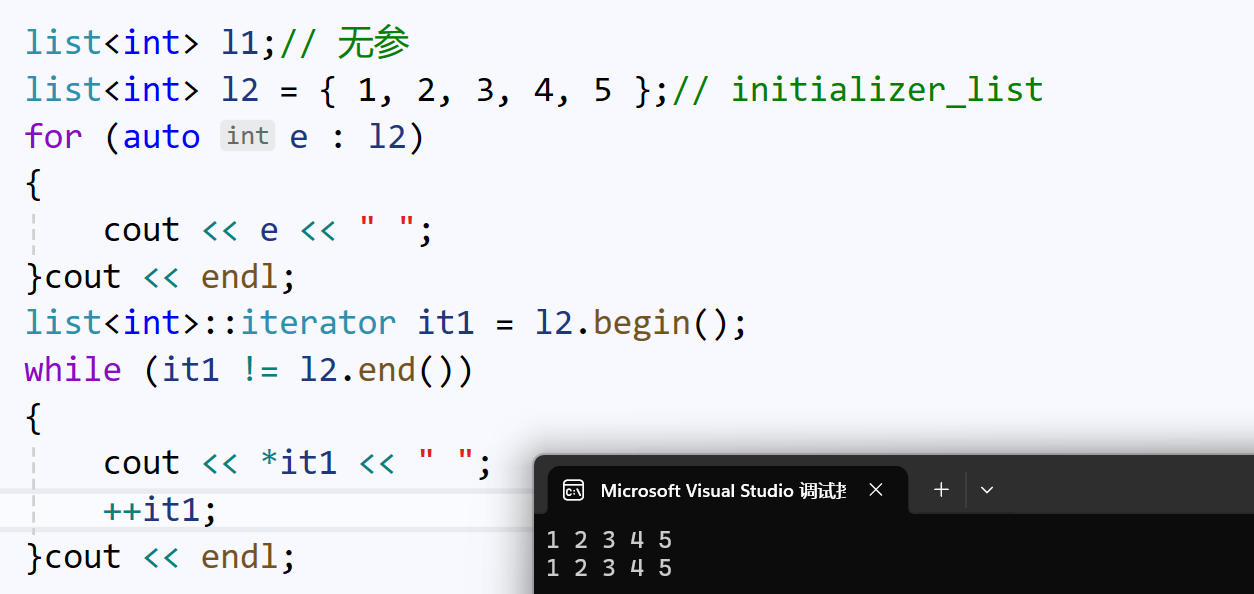
2、插入、删除
由于list没有规定find()查找方法,我们就借用算法库的find()。
cpp
list<int> l3 = { 1,2,3,4 };
auto it2 = find(l3.begin(), l3.end(), 3);插入:
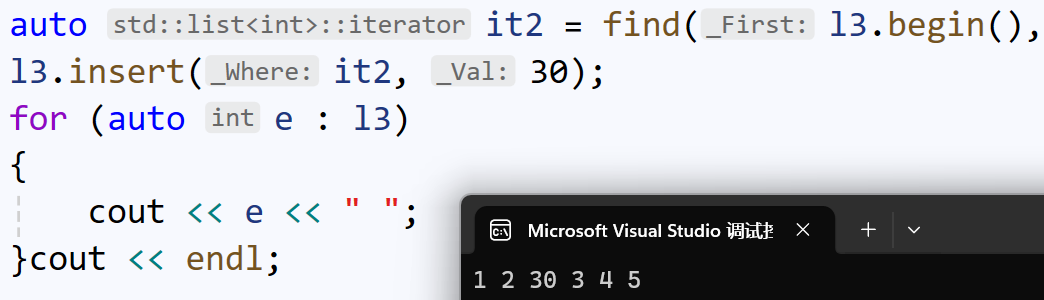
插入后,迭代器it2没有失效,因为list不存在扩容。
删除:
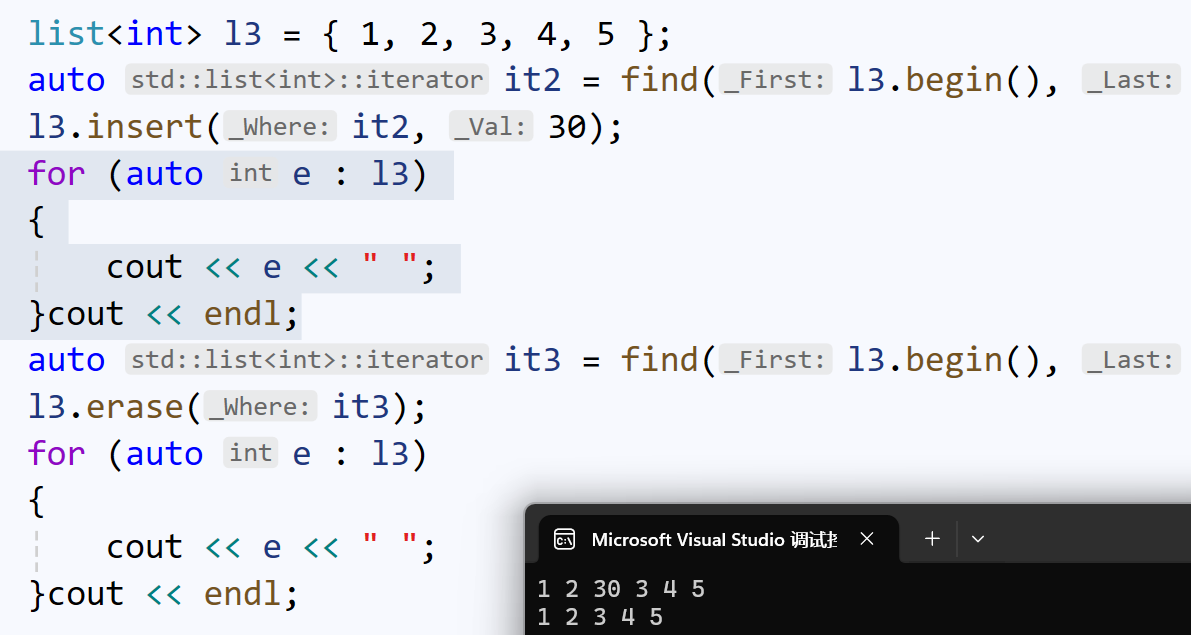
但是删除后,迭代器it2失效了,因为erase()删除的本质,是释放指定节点的空间。此时vs2022环境下会报警告:
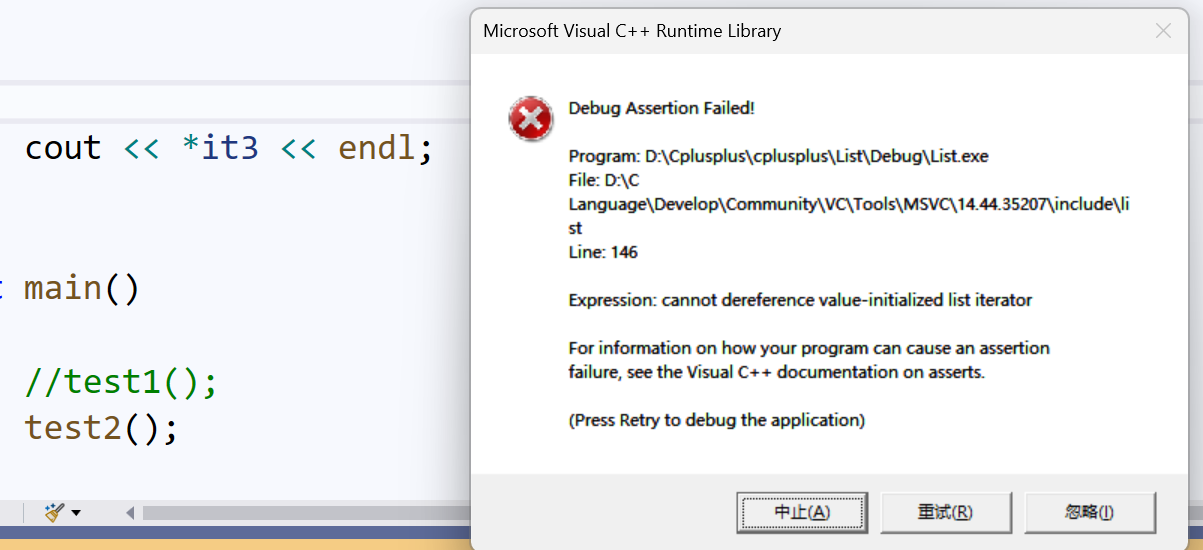
3、一些方法
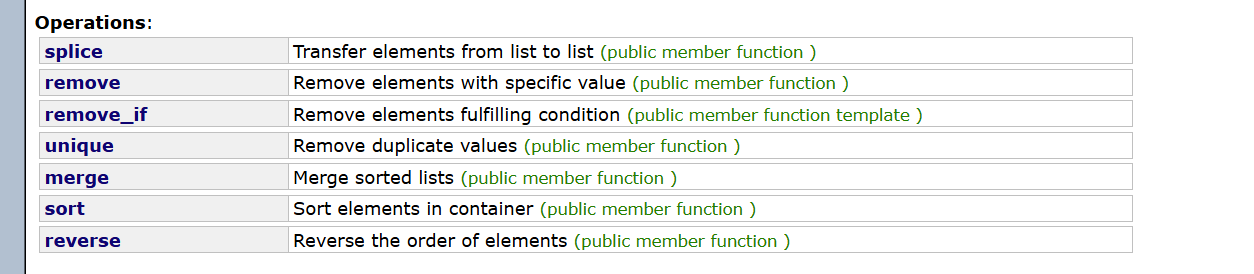
reverse():逆置
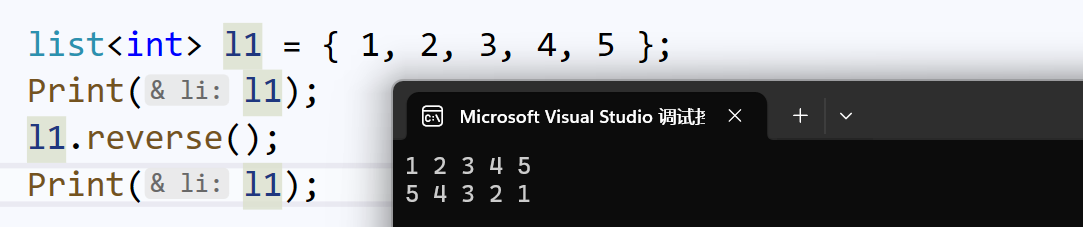
merge():合并
合并算法,类似于我们在数据结构算法中,将两个有序序列,合成一个有序序列的算法题。
只不过这里给出的序列,不一定是有序的,需要先排序:
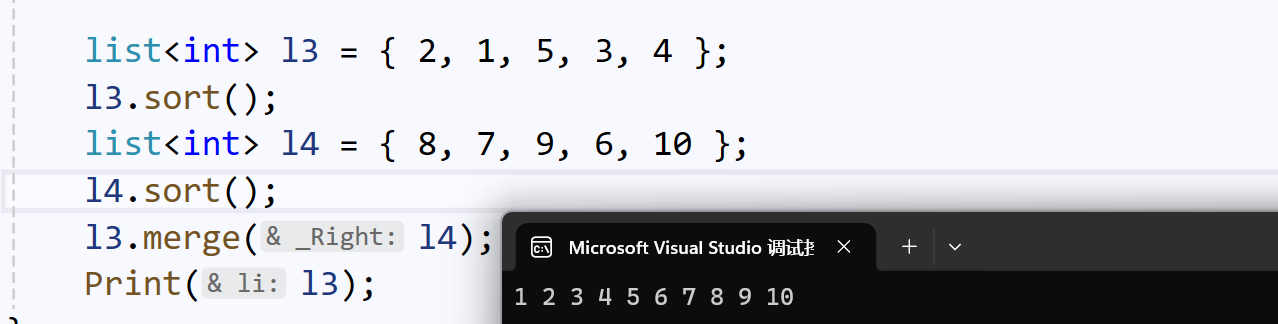
unique():去重
去重算法,也要排序:
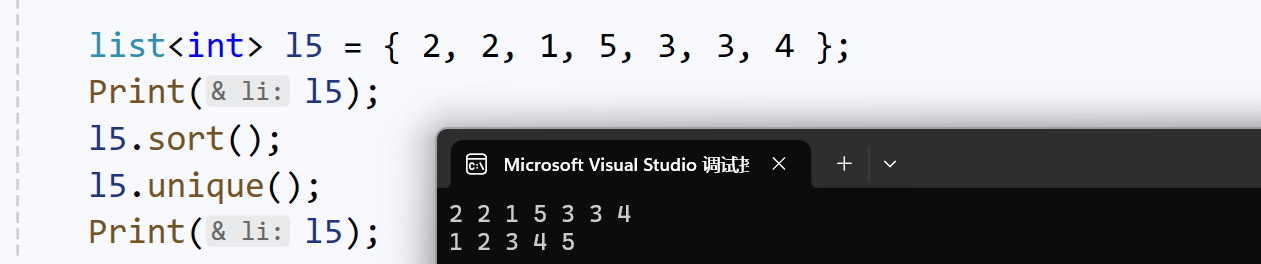
remove():删除指定数

splice():转移
splice()可以不同序列之间进行转移:
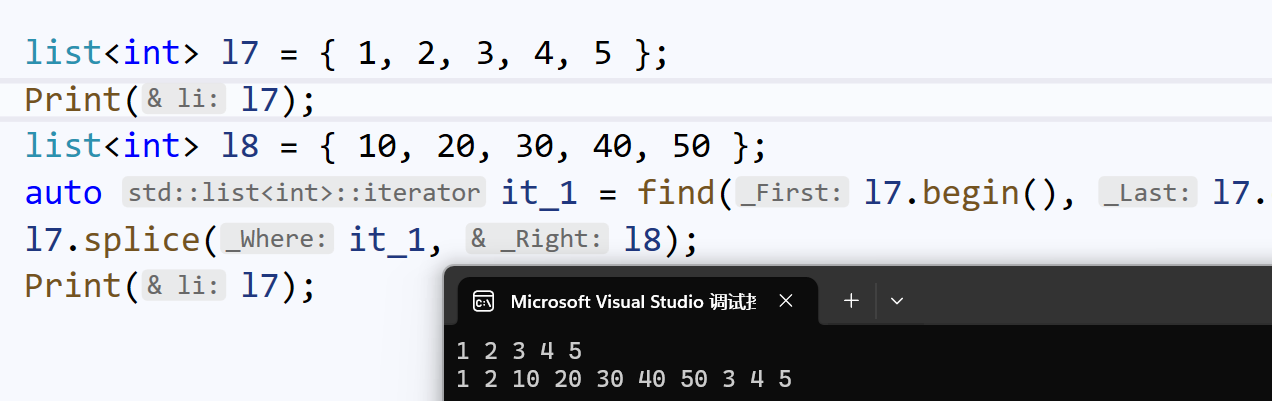
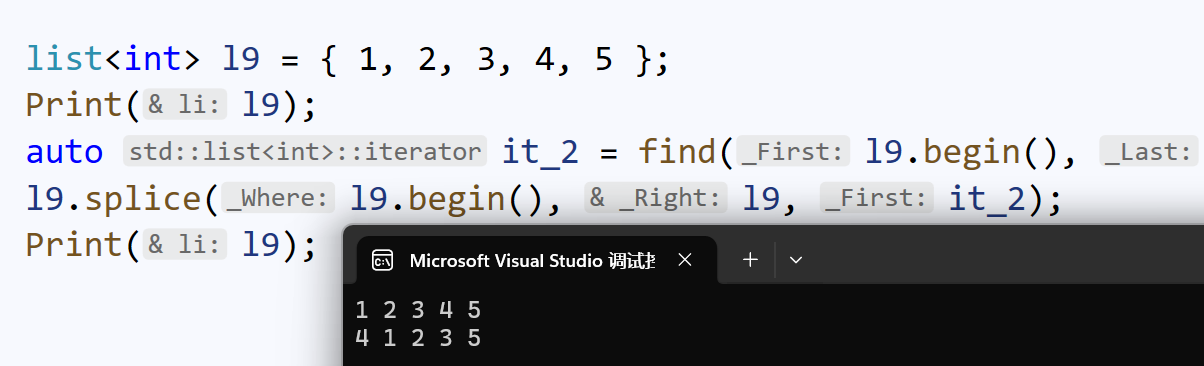
也可以同一序列内进行转移:
sort():排序
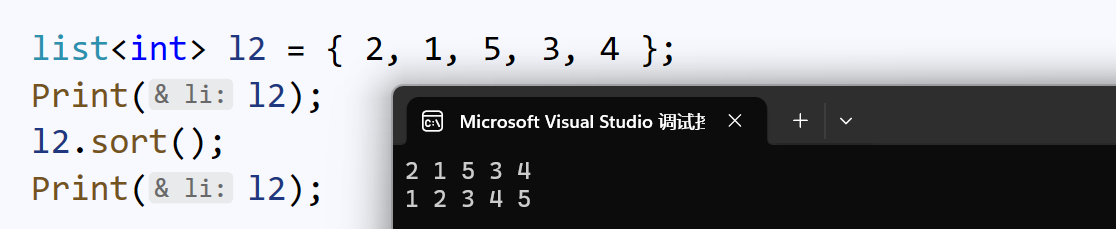
这里就有人要问了:为什么不用算法库的sort()?


发生了编译错误。
我们转向文件algorithm的第8403行,可以发现一点点问题产生的原因:
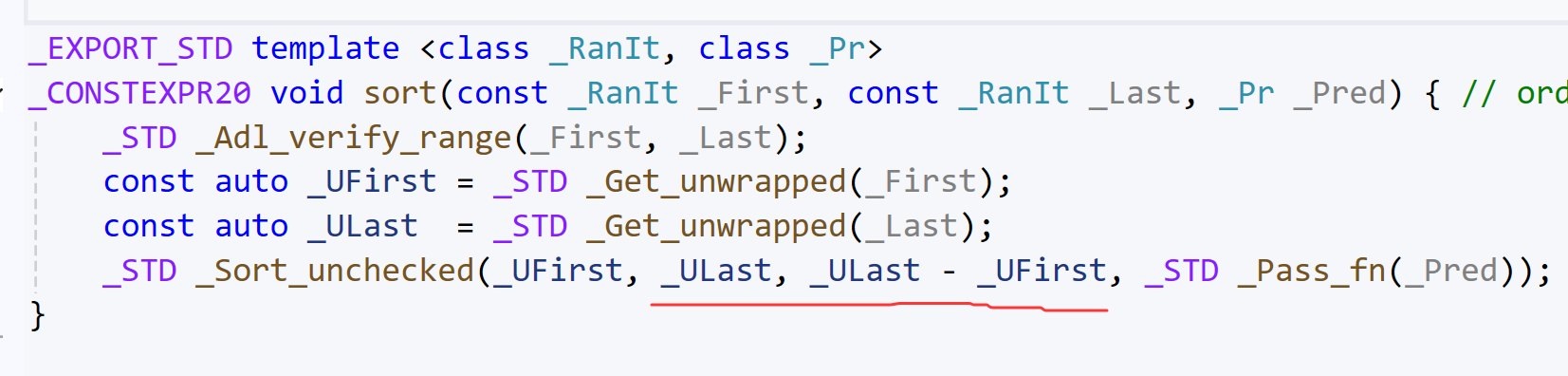
我们发现,算法库sort(),其底层使用的迭代器,支持减操作。
要认识这个问题,我们就要简单了解迭代器按照功能的分类。
3.1、迭代器分类的简单了解
迭代器按照功能,可以分为三类:
- 单向:只能向后走一步(++)
- 双向:可以向前、向后,但是只能一步(++、--)
- 随机:可以向前、向后多步(++、--、+、-)
迭代器的种类,是由所属容器决定的:
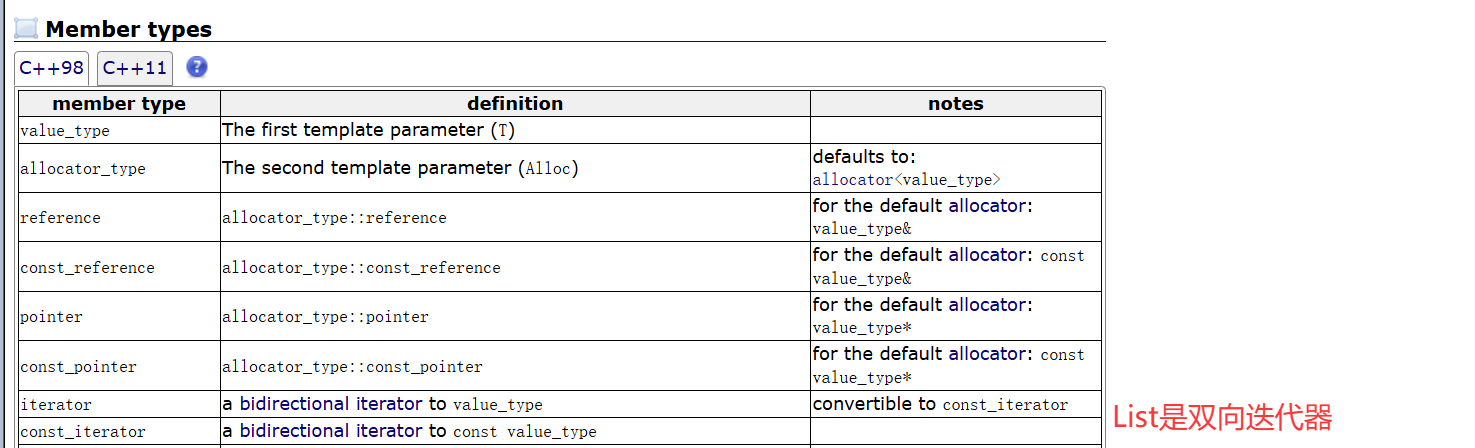
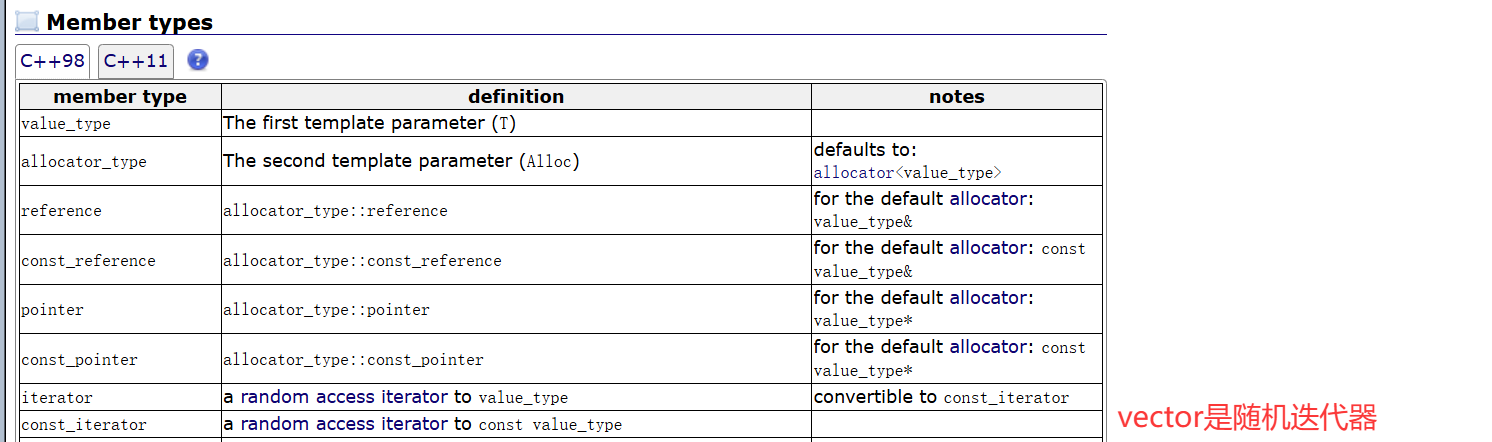
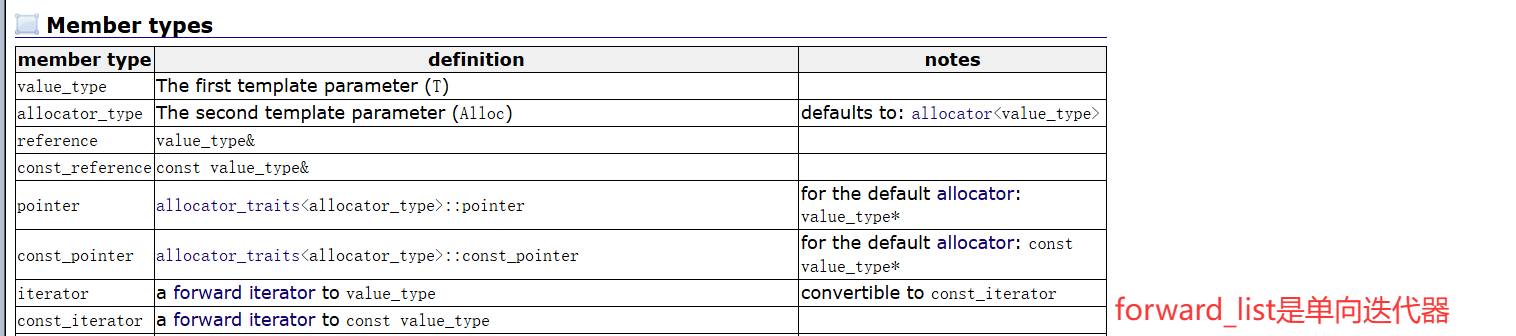
我们可以理解为:List的迭代器,如果实现成随机迭代器,由于链表节点的空间不是连续的,那么需要遍历,代价变大。
而诸如vector之类容器的迭代器,由于顺序表空间是连续的,所以支持随机迭代器,代价就不那么大。
所以List的迭代器,实现成了代价更小的双向迭代器。
算法库里的方法,对传入的迭代器也有要求:


按照不同功能迭代器的说明,我们不难理解:双向迭代器可以被当作单向迭代器使用、随机迭代器可以被当作单向迭代器和双向迭代器使用。
而单向迭代器不可以被当作双向迭代器和随机迭代器使用,双向迭代器也不可以被当作随机迭代器使用。
也就是说,算法库的sort()不支持List的双向迭代器,所以开发者实现了支持双向迭代器的List成员sort()。
有时,我们也会看到这样的迭代器类型:

其实,迭代器还可以分为:
- 只读(OutputIterator)
- 只写(InputIterator)
现阶段我们只需要认为,只写迭代器,包括了单向、双向、随机迭代器。
3.2、List下的成员sort的性能讨论
首先我们要明白:
- List下的成员sort,使用的是处理后的归并排序
- 算法库中的sort,使用的是快速排序
这两个排序的时间复杂度,都是O(NlogN),但是有差异。
我们简单设计程序,印证这一点。
分别在List、vector中放入1000000个数据,然后记录、比较排序的用时:
cpp
void test_op1()
{
vector<int> v;
list<int> l;
const int n = 1000000;
for (int i = 0; i < n; ++i)
{
int x = rand() % 100 + 1;
v.push_back(x);
l.push_back(x);
}
int begin1 = clock();
sort(v.begin(), v.end());
int end1 = clock();
int begin2 = clock();
l.sort();
int end2 = clock();
printf("vector:>%d\n", end1 - begin1);
printf("list:>%d\n", end2 - begin2);
}
我们当前是在x64的release版本下进行测试,而不是debug版本。因为debug版本编译、链接时要做很多处理,而release不需要。
我们可以发现,同样时间复杂度的排序方式,List的sort明显比算法库的sort慢了十几倍。
我们再进行一个测试:创建两个List,放入1000000个数据,其中一个List的数据被vector拷贝,vector经算法库sort排序,再拷贝回List;另一个List直接排序。
cpp
void test_op2()
{
list<int> l1;
list<int> l2;
const int n = 1000000;
for (int i = 0; i < n; ++i)
{
int x = rand() % 100 + 1;
l1.push_back(x);
l2.push_back(x);
}
int begin1 = clock();
vector<int> copy(l1.begin(), l1.end());
sort(copy.begin(), copy.end());
l2.assign(copy.begin(), copy.end());
int end1 = clock();
int begin2 = clock();
l2.sort();
int end2 = clock();
printf("list1:>%d\n", end1 - begin1);
printf("list2:>%d\n", end2 - begin2);
}
可以看到,两种排序方式的用时几乎一致,有时拷贝并使用算法库的sort,还优于List的sort。
所以,List的sort,在大量访问数据的情况下,效率普遍低于算法库的sort。所以我们在大量访问数据的情况下,尽可能使用算法库的sort,其实就是借助vector等内存空间连续的容器。这可能是因为连续空间的访问效率比不连续空间的要快。