本篇一些文本处理的基础内容 适合初学者
一、分词器
python
import jieba
python
content = "今天天气不错,我们一起出去露营烧烤吧!!"
"""
content:要分词的内容
cut_all:是否使用全词模式。默认是False
"""
words_0 = jieba.cut(content, cut_all=True)
words_1 = jieba.lcut(content,cut_all=False)
words_2 = jieba.lcut(content,cut_all=True)
print(words_0)
print(words_1)
print(words_2)cut 是得到一个Tokenizer.cut 对象
通常用lcut 分词得到数组
cut_all = 是否全词模式

自定义词典
python
jieba.load_userdict("./自定义的字典.tex")分词的时候 根据词典分词。
二、词性标注
python
import jieba
import jieba.posseg as pseg
python
content = "我爱自然语言处理"
result = pseg.lcut(sentence=content)
# [pair('我', 'r'), pair('爱', 'v'), pair('自然语言', 'l'), pair('处理', 'v')]
print(result)
for work,pos in result:
print(f'我的词->{work},词性->{pos}')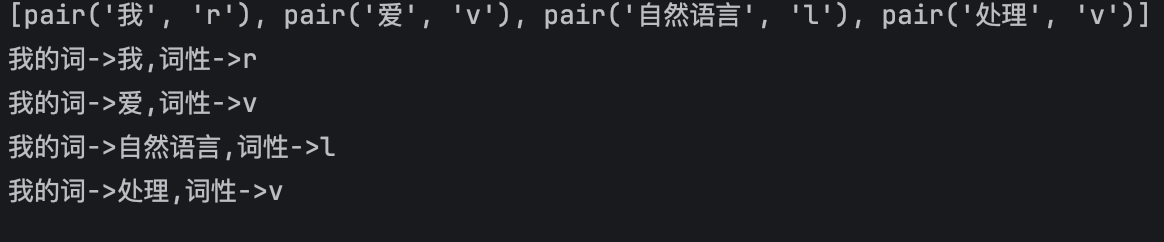
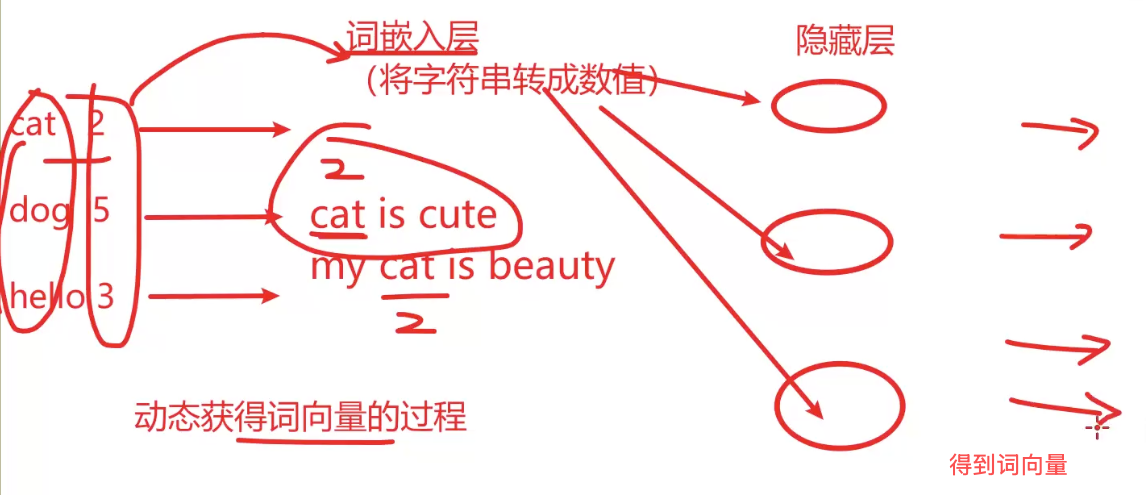
三、词的向量化 词->张量
比如:"cat", "dog", "fish"。我们将每个单词用一个固定长度的向量表示
"cat" → 1, 0, 0
"dog" → 0, 1, 0
"fish" → 0, 0, 1
词汇映射器
python
from keras.src.legacy.preprocessing.text import Tokenizer
python
# 1 数据
vocabs = {'周杰伦',"陈奕迅"," 王力宏","李宗盛","吴亦凡","鹿晗"}
# 2. 训练词汇映射器
my_tokenizer = Tokenizer()
my_tokenizer.fit_on_texts(vocabs)
# 都是字段 key - vlues
# 索引从 1开始 无序的
word_dic = my_tokenizer.word_index
index_dic = my_tokenizer.index_word
print(word_dic)
print(index_dic)
# 3 获取每个词的one-hot 词向量
for word in word_dic:
# 创建 全0 列表
word_one_hot = [0] * len(vocabs)
# 获取词的索引
index = word_dic[word] - 1
# 将指定位置的值设置为1
word_one_hot[index] = 1
print(f'{word}: 词向量:{word_one_hot}')
joblib 加载器的使用保存/使用
python
# 保存训练好的词汇映射器
joblib.dump(my_tokenizer, filename='../model/my_tokenizer.pkl')
# 使用训练好的词汇映射器
my_tokenizer = joblib.load(filename='../model/my_tokenizer.pkl')词向量的三种方式有哪些
1.One-hot 编码
- 优点:简单好理解
- 缺点 :① 大量的0,只有一个地方是1,是一个稀疏向量,会浪费存储和计算资源
② 对一词多义的情况,无法解决。如:小龙女 想 过过 过过 过过的生活
2.Word2vec
- 优点:能够生成稠密的词向量,捕捉词与词之间的语义关系,计算效率高。
- 缺点:需要大量的语料来训练,且可能不适用于某些特定任务(例如:词语的多义性)。
① CBOW模式
给定一段用于训练的上下文词汇(周围词汇),预测目标词汇。
简单来说 -> 左右两边推出中
例:the quick brown fox jumps over the lazy dog
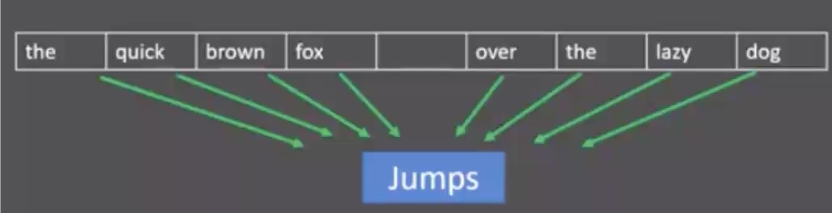
比如 根据Hope set 推 can,基于One - hot来推的
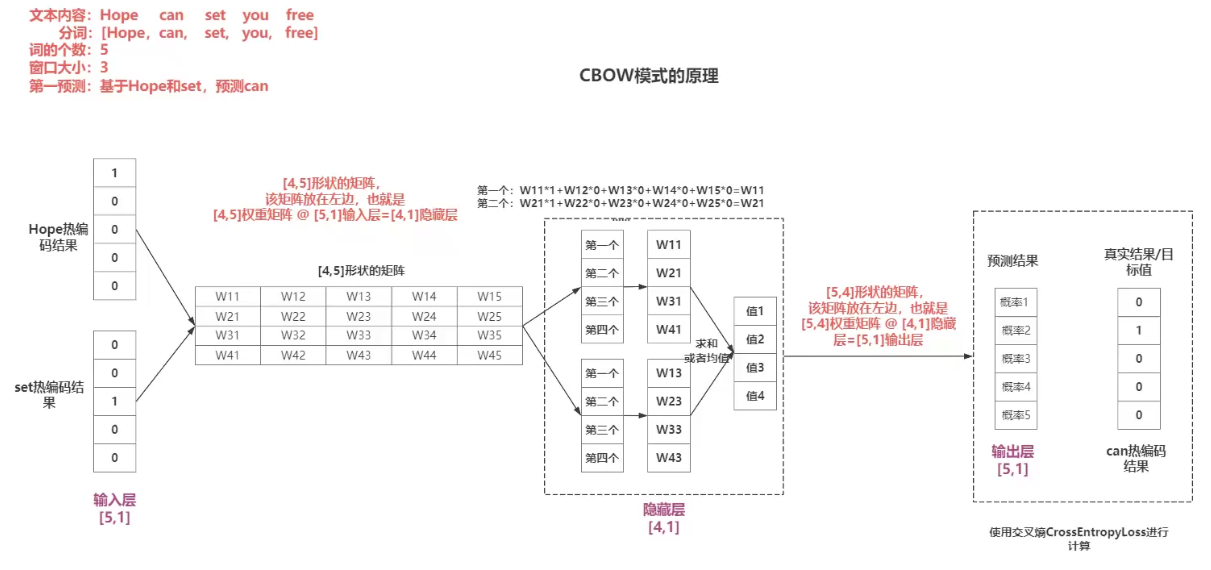
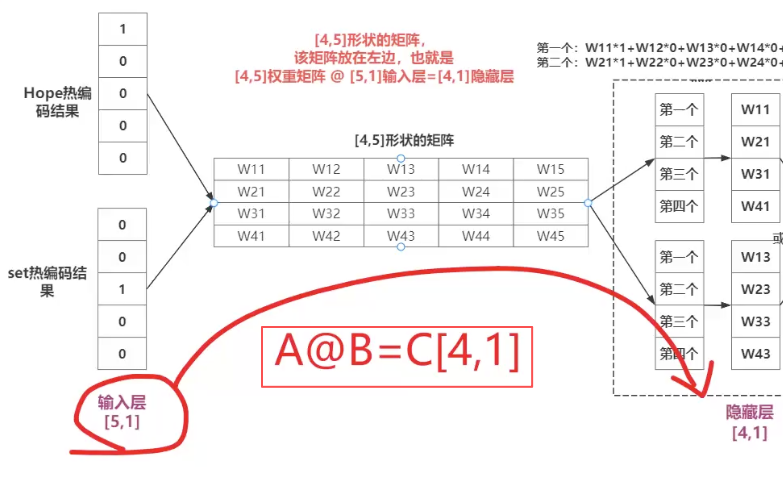
② skipgram模式
给定一个目标词,预测其上下文词汇。
简单来说 -> 中间推两边
比如:窗口大小3. 那就是 根据 Can 推 Hope 和 set
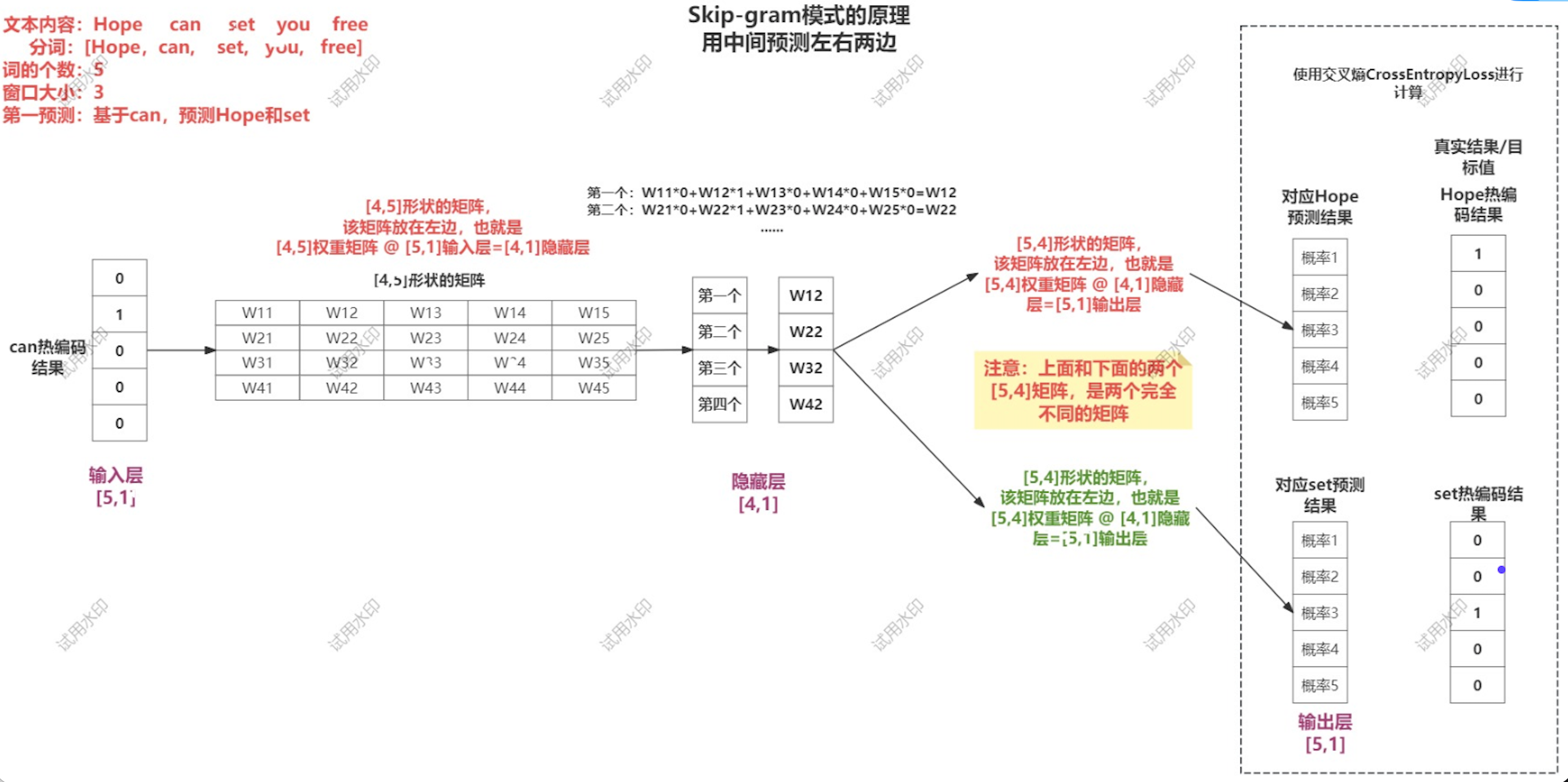
代码:
python
import fasttext使用 fasttext
pip install fasttext
这里使用fasttext工具来实现静态词向量训练,包括 CBOW 和 skip-gram
fasttext工具训练快速,只支持CPU训练,不支持GPU加速
facebook开发的 fasttext包 就是一个开源的 词向量和文本分类工具
示例1:
使用fasttext训练静态词向量,并++保存模型++
python
# 1.采用无监督模式训练
model = fasttext.train_unsupervised(input=r"./data/sz04aa")
# 2.保存训练好的模型
os.makedirs(r"./model",exist_ok=True)
# 保存为二进制文件
model.save_model(r"./model/sz04aa.bin")示例2:
使用fasttext++加载模型++,并使用模型查看词向量
python
# 1.加载模型
model = fasttext.load_model(r"./model/sz04aa.bin")
# 2.获取token对应的词向量
word = "下雨"
word_vec = model.get_word_vector(word)
print(f"{word}:{word_vec}")
print(f"shape:{word_vec.shape}")
# 3.查看语义相近的词
words_near = model.get_nearest_neighbors(word)
print(words_near)示例3:
手动设定无监督学习来训练词向量的超参数
python
start_time = time.time()
# 1.采用无监督模式训练
# 参数1:训练数据,
# 参数2:训练模式,默认skip-gram, 也可以选cbow,
# 参数3:词向量维度,
# 参数4: 训练轮数
# 参数5: 学习率
# 参数6: 训练的线程个数
model = fasttext.train_unsupervised(
input=r"./data/sz04aa",
model="skipgram", #"cbow"
dim=100,
epoch=10,
lr=0.02,
thread=10
)
# 2.保存训练好的模型
os.makedirs(r"./model", exist_ok=True)
# 保存为二进制文件
model.save_model(r"./model/sz04aa03.bin")
end_time = time.time()
print(f"skipgram训练时间:{end_time - start_time}s")3.Word Embedding
- 优点:能够有效捕捉词的语义和句法信息,且训练出来的词向量可以在多个任务中使用。
- 缺点:对于一些低频词和未见过的词处理可能较差
句子 -> 分词 -> 去重得到词汇表 -> 得到词索引 -> Embedding -> 词向量代码流程:
① 定义文本
② 构建词表,分词处理
③ 创建词汇映射器
④ 创建词嵌入层
⑤ 遍历获得每个词的词向量
python
import torch.nn as nn
import torch
import jieba
from keras.src.legacy.preprocessing.text import Tokenizer
python
# 1.定义文本,两个句子
sentence1 = "从前有一段真挚的爱情放在我的面前,可惜我当时正在疯狂的打游戏"
sentence2 = "不问你为何学不会,只问你心里还有谁,就让我给你安慰,不论结局是喜是悲"
text = [sentence1, sentence2]
# 2.构建词表,分词处理
word_list = []
for word in text:
word_list.append(jieba.lcut(word))
# 3.创建词汇映射器
my_tokenizer = Tokenizer()
# 训练
my_tokenizer.fit_on_texts(word_list)
index_word = my_tokenizer.index_word
# word_index = my_tokenizer.word_index
print(index_word)
#{1: ',', 2: '的', 3: '我', 4: '你', 5: '是', 6: '从前', 7: '有', 8: '一段', 9: '真挚', 10: '爱情', 11: '放在', 12: '面前', 13: '可惜', 14: '当时', 15: '正在', 16: '疯狂', 17: '打游戏', 18: '不问', 19: '为何', 20: '学', 21: '不会', 22: '只', 23: '问', 24: '心里', 25: '还有', 26: '谁', 27: '就让', 28: '给', 29: '安慰', 30: '不论', 31: '结局', 32: '喜', 33: '悲'}
# 4.创建词嵌入层
word_nums = len(index_word)
"""
参数1: num_embeddings: 词汇表中词的个数
参数2: embedding_dim: 词向量维度
"""
ebd = nn.Embedding(num_embeddings=word_nums, embedding_dim=8)
print(f"embedding: {ebd}")
print(f"embedding.weight.shape: {ebd.weight.shape}")
# 5.遍历获得每个词的词向量
for key,value in index_word.items():
# key 词索引 映射是1开始的。所以-1
word_vec = ebd(torch.tensor(key-1))
print(f"词:{value}, 词向量:{word_vec}")打印

embedding_dim=8
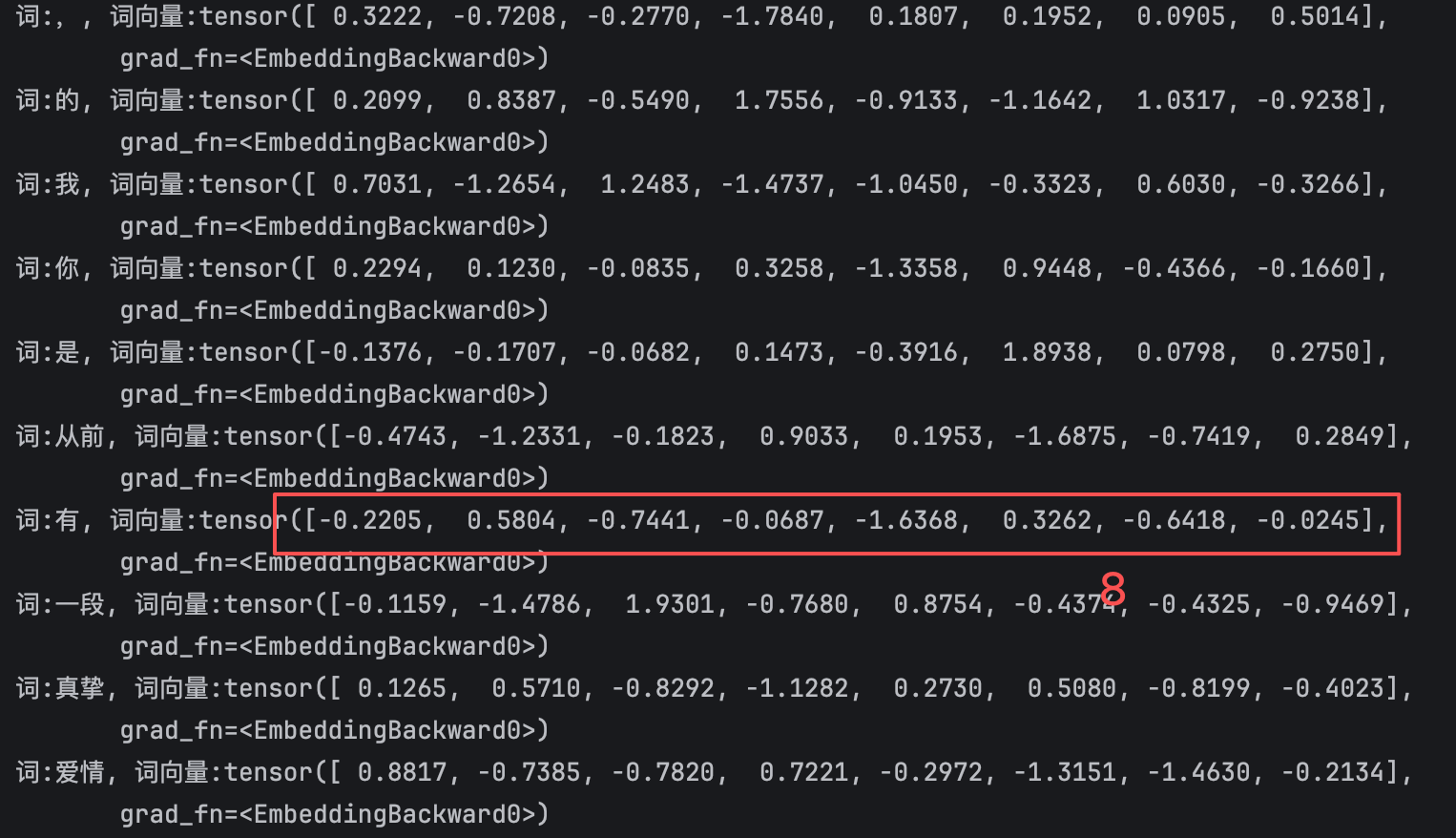
ebd = nn.Embedding(num_embeddings=word_nums, embedding_dim=8)大概原理