题号2033
- [🌟 LeetCode 2033 题解:Minimum Operations to Make a Uni-Value Grid](#🌟 LeetCode 2033 题解:Minimum Operations to Make a Uni-Value Grid)
-
- [1. 题目分析(先讲人话版)](#1. 题目分析(先讲人话版))
- [2. 贪心结论:选中位数最优](#2. 贪心结论:选中位数最优)
-
- [2.1 为什么是中位数?(直观证明)](#2.1 为什么是中位数?(直观证明))
- [2.2 稍微严格一点的证明](#2.2 稍微严格一点的证明)
- [3. 可行性判断(非常关键)](#3. 可行性判断(非常关键))
- [4. 算法流程](#4. 算法流程)
- [5. 我的排序递进过程:从"能分区"到"能找第 k 个"](#5. 我的排序递进过程:从“能分区”到“能找第 k 个”)
- [5.1 第一阶段:中间值分区法(我最初的写法)](#5.1 第一阶段:中间值分区法(我最初的写法))
-
- 排序部分代码
- [🌈 示意图(只分区,不归位)](#🌈 示意图(只分区,不归位))
- [✅ 优点](#✅ 优点)
- [⚠️ 缺点](#⚠️ 缺点)
- [5.2 第二阶段:首元素基准 + 填坑法(可定位)](#5.2 第二阶段:首元素基准 + 填坑法(可定位))
-
- 排序部分代码
- [🌈 示意图(填坑)](#🌈 示意图(填坑))
- [✅ 优点](#✅ 优点)
- [⚠️ 缺点](#⚠️ 缺点)
- [5.3 第三阶段:中位基准 + 填坑法(我最后采用)](#5.3 第三阶段:中位基准 + 填坑法(我最后采用))
-
- 排序部分代码
- [🌈 图解流程](#🌈 图解流程)
- [✅ 优点](#✅ 优点)
- [⚠️ 缺点](#⚠️ 缺点)
- [6. 最简单方案:直接用 STL `nth_element`](#6. 最简单方案:直接用 STL
nth_element) - [7. 三种手写分区方法对比](#7. 三种手写分区方法对比)
- [8. 一句总结](#8. 一句总结)
🌟 LeetCode 2033 题解:Minimum Operations to Make a Uni-Value Grid
1. 题目分析(先讲人话版)
我们每次操作可以对某个数 +x 或 -x,目标是让整个二维网格都变成同一个值,问最少操作次数。
核心观察有两步:
- 先把二维数组拉平成一维数组,问题不变。
- 如果最终都要变成同一个目标值
t,总代价就是:sum(|a[i] - t| / x)(前提是每个a[i]都能通过 ±x 到达t)
于是题目变成:
- 能不能到达同一个值?
- 如果能,选哪个目标值
t让总代价最小?
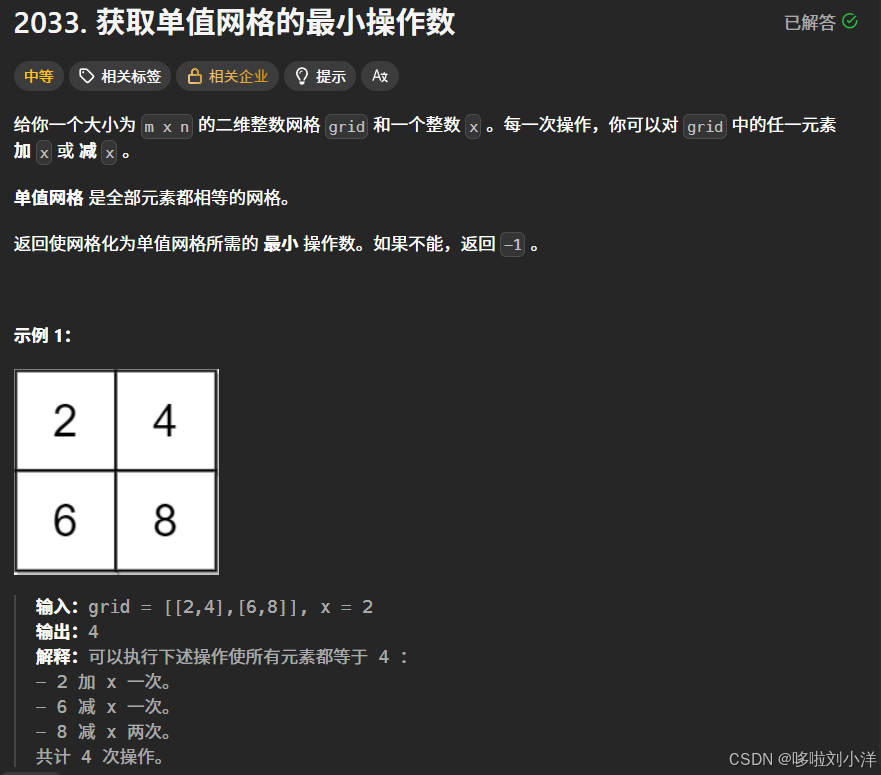
2. 贪心结论:选中位数最优
把数组记作 a,并按升序排好(或者只找中位数,不一定全排)。
我们要最小化:
F(t) = Σ |a[i] - t|
这是经典结论:绝对值距离和在中位数处最小。
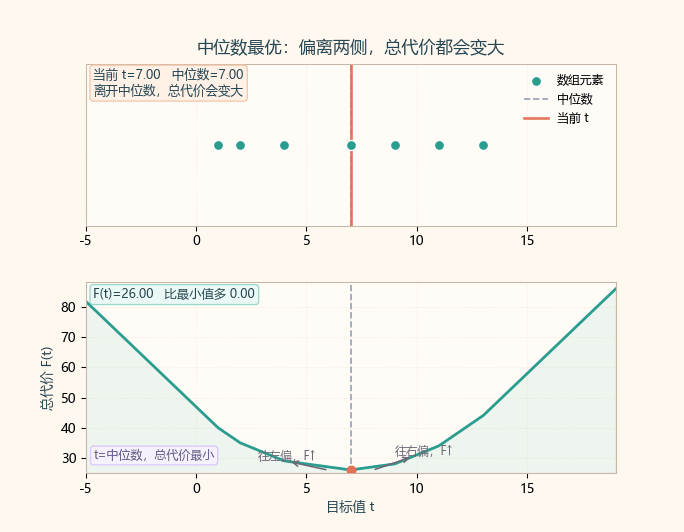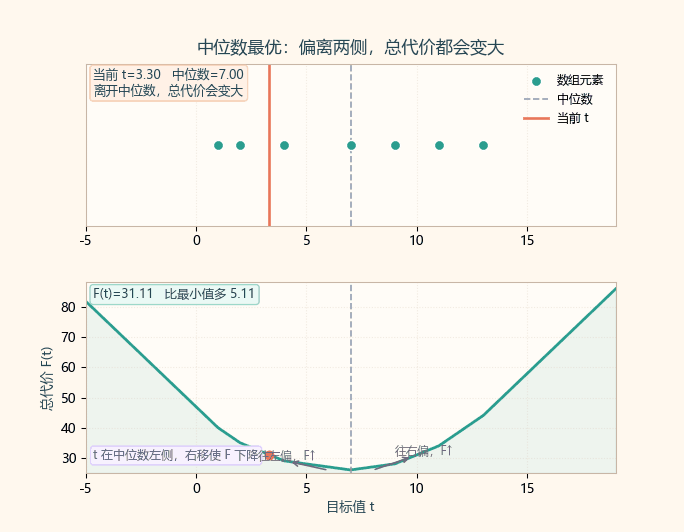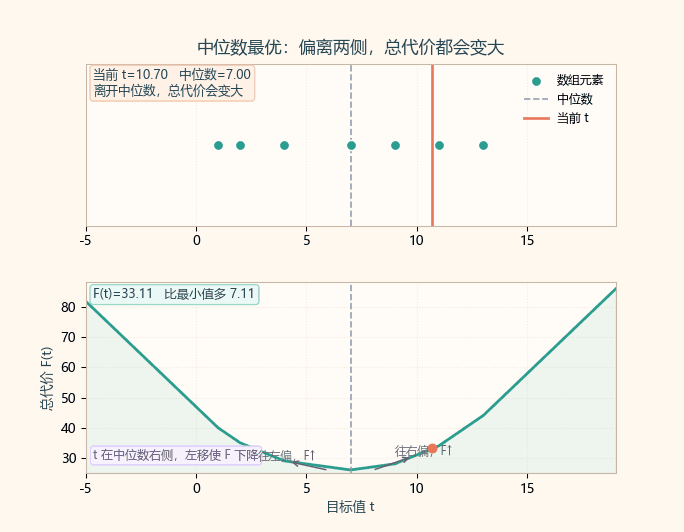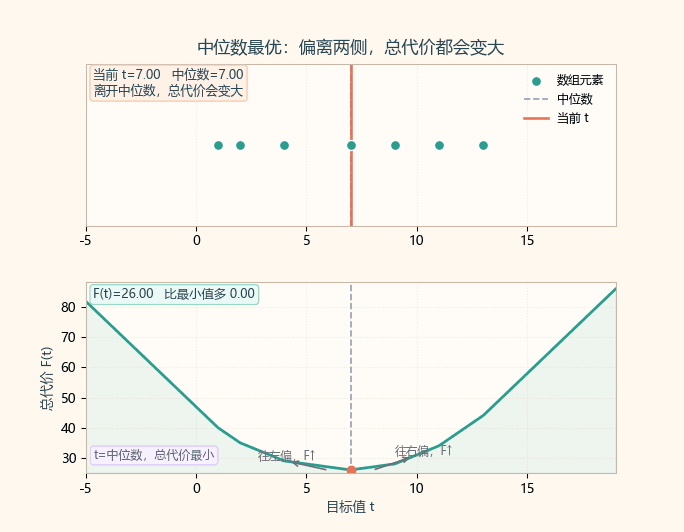
2.1 为什么是中位数?(直观证明)
- 当
t往右移动一点:- 左边元素到
t的距离变大 - 右边元素到
t的距离变小
- 左边元素到
- 只有当"左边个数"和"右边个数"尽量平衡时,总代价最小。
- 这个平衡点正是中位数位置。
2.2 稍微严格一点的证明
设数组升序后为 b[0..n-1]。考虑 t 每增加 1 时 F(t) 的变化量:
- 对每个
b[i] <= t,贡献+1 - 对每个
b[i] > t,贡献-1
所以"斜率"大致是:
count_left - count_right
当 t 在中位数左边,右侧更多,斜率负,F(t) 还在下降;
当 t 在中位数右边,左侧更多,斜率正,F(t) 开始上升;
因此最小值出现在中位数处(偶数长度时是中间区间,取任一中位数都行)。
3. 可行性判断(非常关键)
因为每次只能加减 x,一个数的模 x 余数不会变。
所以要想最终全相等,所有元素必须满足:
a[i] % x 都相同。
只要有一个不同,直接返回 -1。
4. 算法流程
- 拉平二维数组到
nums。 - 同时检查所有元素
% x是否一致,不一致返回-1。 - 找
nums的中位数med(nth_element或 quickselect)。 - 答案是
sum(|v - med|) / x。
时间复杂度:
nth_element平均O(N),N = n*m- 总体平均
O(N)
空间复杂度:
O(N)(存拉平数组)
5. 我的排序递进过程:从"能分区"到"能找第 k 个"
同样是"取中间值",为什么有的分区只能分两边,有的却能直接定位第
k小?
5.1 第一阶段:中间值分区法(我最初的写法)
排序部分代码
cpp
auto _sort=[&](int left,int right)->int
{
if(left >= right) return left;
int l = left;
int r = right;
int base = nums[(l + r) / 2];
while(l < r)
{
while(l < r && nums[r] >= base) r--;
while(l < r && nums[l] <= base) l++;
if(l < r)
{
swap(nums[l], nums[r]);
}
}
return l;
};🌈 示意图(只分区,不归位)
text
初始: [ 9, 1, 8, 3, 7, 2, 6 ]
base = 中间值 3
过程后可能变成:
[ 2, 1, 3, 8, 7, 9, 6 ]
^
l/r 相遇点✅ 优点
- 代码短
- 做"粗分区"很快
⚠️ 缺点
- 返回下标不保证是基准最终位置
- 只能分区间,不能稳定定位第
k小
5.2 第二阶段:首元素基准 + 填坑法(可定位)
排序部分代码
cpp
auto _sort=[&](int left,int right)->int
{
int base = nums[left];
int l = left, r = right;
while (l < r)
{
while (l < r && nums[r] >= base) r--;
nums[l] = nums[r];
while (l < r && nums[l] <= base) l++;
nums[r] = nums[l];
}
nums[l] = base;
return l;
};🌈 示意图(填坑)
text
base 挖坑:
[ (base), 5, 2, 9, 1, 7 ]
^ left 坑
从右找 < base 的数填左坑,再从左找 > base 的数填右坑...
最终:
[ 1, 2, (base), 9, 5, 7 ]
^
base 最终位置✅ 优点
- 返回下标就是基准最终位置
- 能稳定用于 quickselect
⚠️ 缺点
- 如果始终取首元素,遇到坏序列时退化风险高
5.3 第三阶段:中位基准 + 填坑法(我最后采用)
排序部分代码
cpp
auto _sort=[&](int left,int right)->int
{
int mid = (left + right) / 2;
int base = nums[mid];
swap(nums[left], nums[mid]);
int l = left, r = right;
while (l < r)
{
while (l < r && nums[r] >= base) r--;
nums[l] = nums[r];
while (l < r && nums[l] <= base) l++;
nums[r] = nums[l];
}
nums[l] = base;
return l;
};🌈 图解流程
text
步骤A:选中位基准
[ 9, 4, 7, 3, 8, 2, 6 ]
^ mid, base=3
步骤B:换到 left,开始挖坑
[ 3, 4, 7, 9, 8, 2, 6 ]
^ left 坑
步骤C:填坑循环后
[ 2, 3, 7, 9, 8, 4, 6 ]
^ base 归位(可用于 quickselect)✅ 优点
- 比固定首元素更不容易退化
- 比只交换不归位更适合找第
k小
⚠️ 缺点
- 代码复杂度高于直接用 STL
6. 最简单方案:直接用 STL nth_element
如果只是为了拿中位数,工程上最推荐直接用 STL。
cpp
int k = nums.size() / 2;
nth_element(nums.begin(), nums.begin() + k, nums.end());
int med = nums[k];它的含义是:
nums[k]会是"如果整体排序后"第k个元素- 左边都
<= nums[k],右边都>= nums[k] - 但左右两边内部不保证有序
这正好满足本题需求。
7. 三种手写分区方法对比
| 方法 | 能否把基准放到最终位置 | 能否直接用于找第k小 | 实现复杂度 | 退化风险 |
|---|---|---|---|---|
| 中间值交换分区(第一版) | ❌ 不能保证 | ⚠️ 不稳 | 🙂 简单 | 中等 |
| 首元素基准填坑(第二版) | ✅ 可以 | ✅ 稳定 | 😐 中等 | 偏高 |
| 中位基准 + 填坑(第三版) | ✅ 可以 | ✅ 稳定 | 😐 中等 | 较低 |
8. 一句总结
这题本质是"同余可达性 + 中位数最小绝对偏差"。
排序/快选只是为了高效拿到中位数;想省心就直接
nth_element。