大家好,我是直奔標杆,专注Java开发者AI转型实战分享,和各位同行一起从0到1吃透Spring AI,深耕技术、互相交流、共同成长,一起直奔技术标杆!
欢迎来到《Spring AI 零基础到实战》专栏的第二十三课!在上一节(Java开发者AI转型第二十二课)中,我们站在架构师视角,完成了AI个人知识库的MVC分层架构设计,搭好了整个知识库的基础骨架。
相信很多同行在实操中会发现一个关键问题:传统Web容器(比如我们常用的Tomcat),天生是为高并发短连接设计的,核心理念就是"快速处理、绝不恋战"。但AI个人知识库中的文档解析、向量运算以及大模型推理,全是极度消耗CPU和I/O资源的耗时操作------如果我们让HTTP工作线程直接同步等待AI算力返回,哪怕只是几份几十兆的PDF,都能瞬间榨干整个Web线程池,直接导致系统全面瘫痪,这也是很多新手入门时最容易踩的坑!
所以本节课,我们就切入系统核心,运用并发解耦的思想,手把手搭建一条高效、稳定的异步ETL(提取-转换-加载)流水线,让Spring Boot像一台精密的收割机,实现前台秒级响应、后台从容吞吐,真正落地生产级可用的个人知识库。
前置知识(必看)
本节课的实战需要依赖前面的核心知识点,建议大家先回顾以下内容,避免跟不上实操节奏,一起扎实进阶:
-
Java开发者AI转型第八课!避开Token陷阱!Spring AI记忆裁剪源码解析与Token级防溢出核心技巧
-
Java开发者AI转型第九课!突破知识边界!企业级 RAG (检索增强生成) 核心架构与 ETL 管道初探
-
Java开发者AI转型第十课!化繁为简!Spring AI 全能文档解析器 (Document Readers) 与元数据提取实操
-
Java开发者AI转型第十一课!文本切分避坑指南:Spring AI 智能分块与Overlap语义防割裂实战
-
Java开发者AI转型第十二课!吃透Embeddings向量化:让Java代码读懂文本语义
-
Java开发者AI转型第十三课!知识库终局方案:Spring AI Vector Store架构演进与ETL全链路入库实战
-
Java开发者AI转型第十四课!Spring AI向量数据库实操:检索召回与相似度检索实战详解
本节章节目标(明确方向,高效学习)
结合实战需求,本节课我们重点掌握3个核心目标,学完就能上手搭建异步ETL流水线,避开关键坑点:
-
认知重塑:搞懂同步HTTP请求与异步AI算力之间的核心矛盾,理解异步解耦的必要性,避免踩线程阻塞的坑;
-
底层透视:解密MultipartFile在Tomcat容器中的生命周期陷阱,掌握文件流安全交接的核心方法;
-
极简实战:串联Tika(提取)、Splitter(转换)与VectorStore(加载)三大组件,搭建高内聚、可复用的文档解析与入库管道。
知识库功能预览(提前感知实战成果)
先给大家展示下我们最终要落地的知识库核心功能,跟着实操走,你也能快速实现:
-
登录页面:基础身份验证,保障知识库数据安全;

-
RAG对话:基于向量库检索,实现精准问答,告别大模型幻觉;
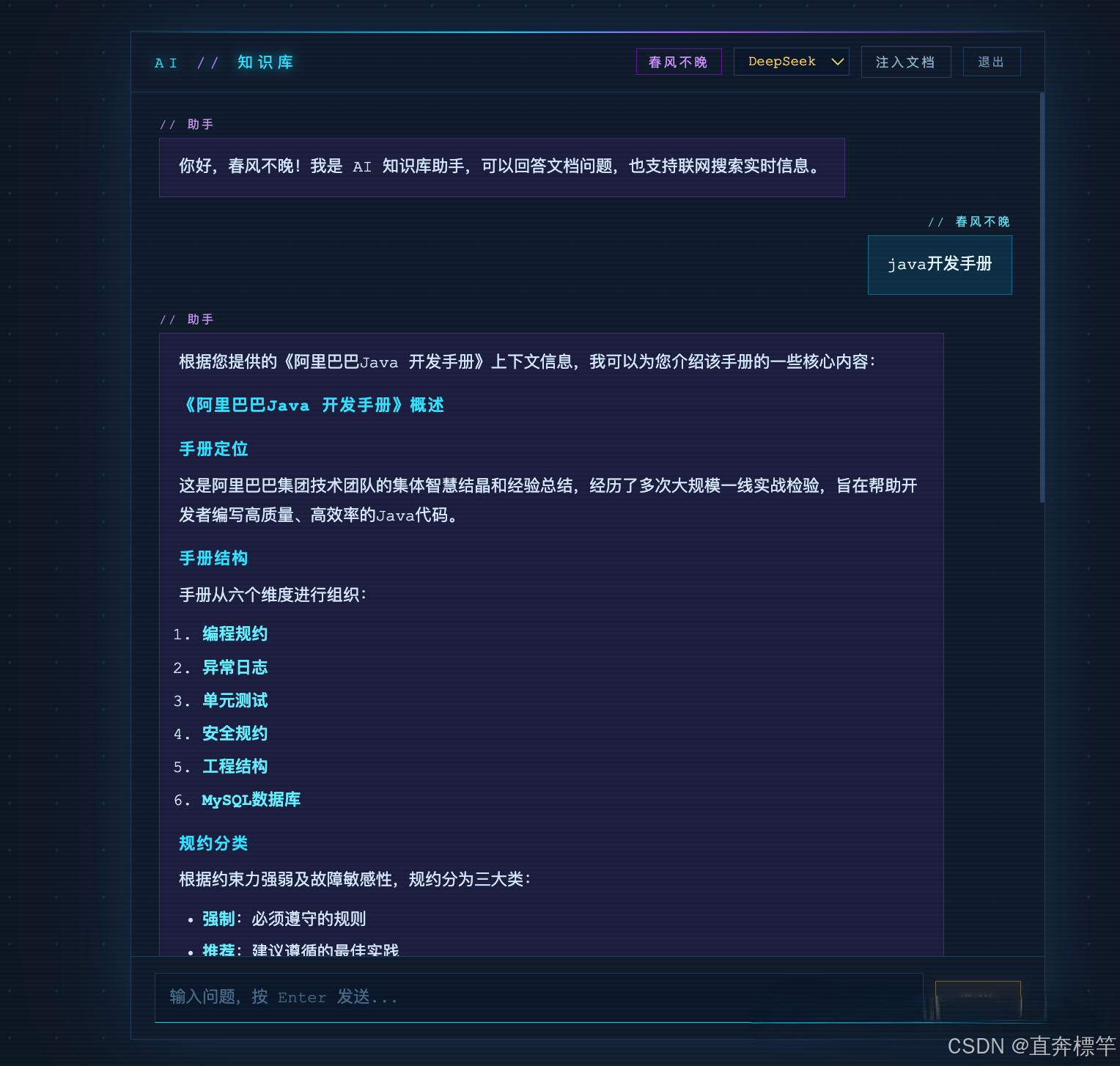
-
联网对话:结合网络资源,突破本地知识库边界,提升问答实用性。
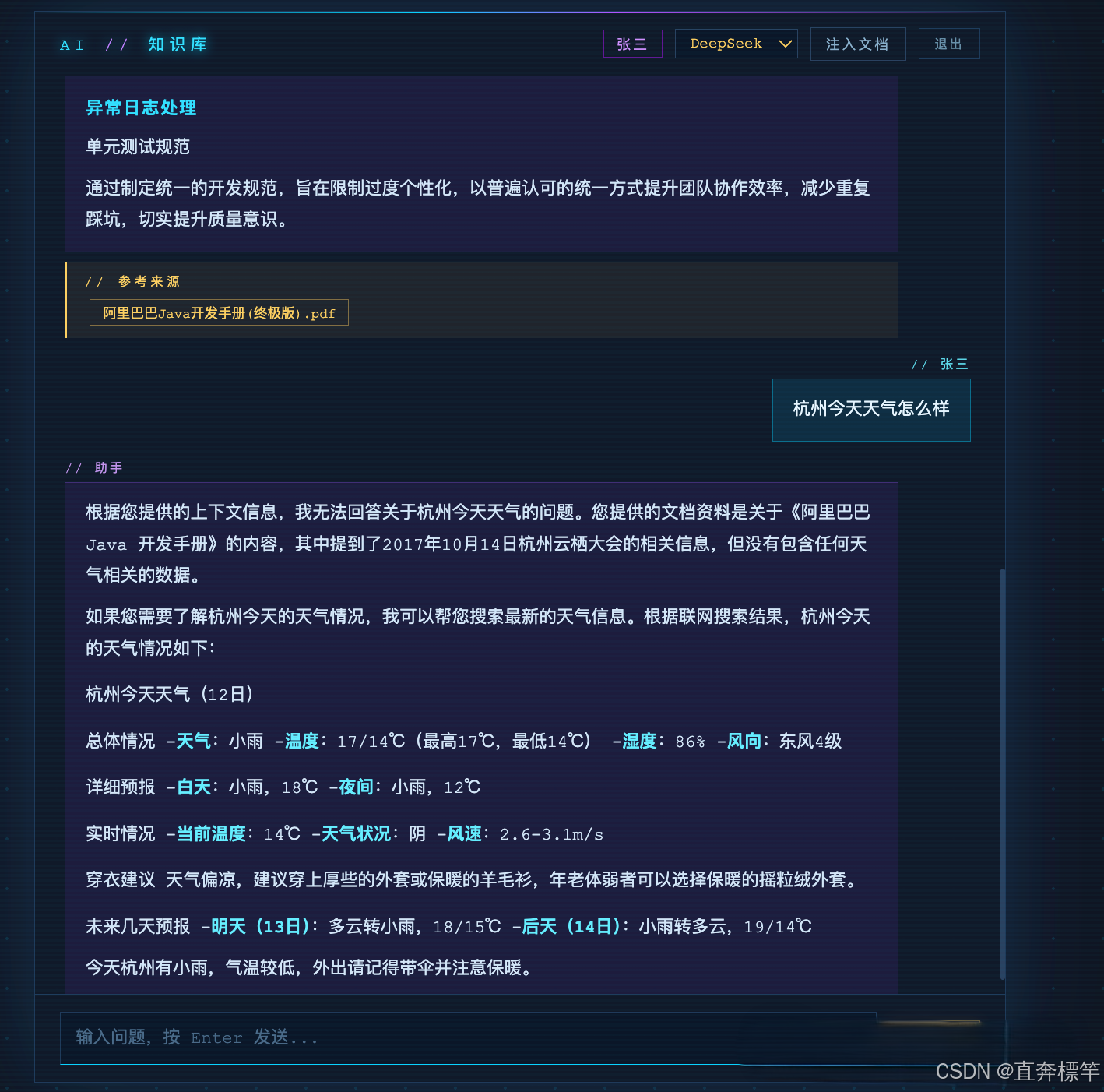
异步ETL管道全链路解析(核心重点)
在敲下第一行代码前,我们先看懂底层流转逻辑------这张流转图清晰展示了Tomcat请求线程与Spring异步任务池之间,如何通过"本地磁盘"这座桥梁,完成任务的平滑交接,从根源上避免线程阻塞问题:
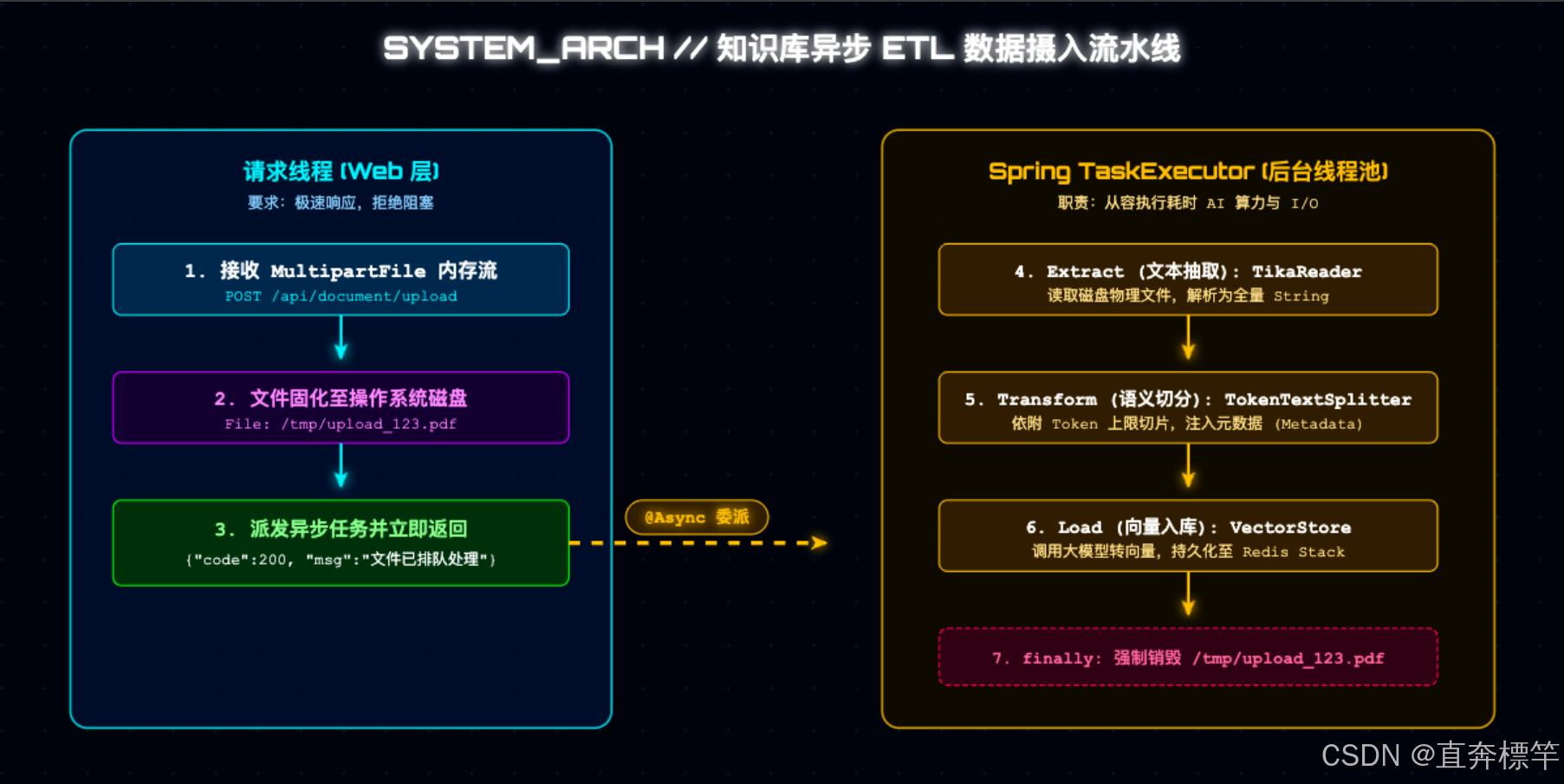
Web接入层:规避MultipartFile生命周期陷阱(新手必看避坑)
在Controller层,我们的职责要克制且高效,就像一个专业的"前台接待"------只负责接收请求、完成文件的安全交接,不参与任何耗时的AI操作,避免占用HTTP线程。
java
@RestController
@RequestMapping("/api/document")
publicclass DocumentController {
@PostMapping("/upload")
public ResponseEntity<ApiResponse<UploadResponse>> upload(
@RequestParam("file") MultipartFile file) throws IOException {
// 1. 获取原始文件名,并生成 UUID 避免并发覆盖
String originalFilename = file.getOriginalFilename();
String tempFilename = UUID.randomUUID() + "_" + originalFilename;
// 2. 在操作系统的临时目录中创建一个物理文件存根
File tempFile = new File(System.getProperty("java.io.tmpdir"), tempFilename);
// 3. 核心动作:将 Tomcat 内存流固化到物理磁盘!
file.transferTo(tempFile);
// 4. 委派给后台异步线程执行 AI 解析,主线程立即释放返回
documentService.processAndStoreAsync(tempFile, originalFilename);
return ResponseEntity.ok(
ApiResponse.success("文件已接收,后台正在进行知识库解析")
);
}
}避坑指南与底层剖析(90%新手踩过的坑)
很多同行会问:为什么一定要用file.transferTo(tempFile)将文件写入磁盘?直接把MultipartFile传给后面的@Async异步方法不行吗?
这里给大家讲透底层逻辑:MultipartFile是Tomcat容器维护的HTTP请求级资源,它的生命周期极其短暂,就像前台给访客发的"临时访客牌"------一旦Controller方法执行完毕、返回响应,Tomcat的垃圾回收机制会立刻介入,关闭底层的内存流,销毁可能存在的网络临时文件。
如果此时你把MultipartFile直接交给后台异步线程,几秒钟后异步线程苏醒,调用file.getInputStream()进行文档解析时,系统一定会抛出java.io.FileNotFoundException(文件找不到)或流已关闭异常,这也是很多人实操中卡壳的核心原因!
因此,将网络内存流固化为操作系统级别的物理磁盘文件,是跨越HTTP线程与后台Worker线程边界的最安全、最稳妥的方式,没有之一。
异步ETL管道实战:手把手组装流水线(核心实操)
解决了线程边界的坑之后,我们就进入真正的"组装车间"------DocumentService。在这里,我们将Tika(提取)、Splitter(转换)、VectorStore(加载)三大组件严丝合缝地串联起来,搭建完整的ETL流水线,直接上代码、讲细节,新手也能跟着敲!
java
public class DocumentServiceImpl implements DocumentService {
private final VectorStore vectorStore;
// 构造器注入 VectorStore 略(实际开发中记得完善注入逻辑,避免空指针)
@Async // 核心注解:将方法交给Spring异步任务池执行,脱离HTTP线程
@Override
public void processAndStoreAsync(File tempFile, String originalFilename) {
long startTime = System.currentTimeMillis();
try {
// ========== 1. Extract:提取阶段,根据文件类型选择对应读取策略 ==========
List<Document> rawDocuments = extractDocuments(tempFile, originalFilename);
log.info("[ETL] Extract 完成,原始段落数: {}", rawDocuments.size());
// ========== 2. Transform:转换阶段,语义感知切分,保留句子完整性 ==========
SemanticTokenTextSplitter splitter = SemanticTokenTextSplitter.builder().build();
List<Document> chunks = splitter.apply(rawDocuments);
log.info("[ETL] Transform 完成,切分块数: {}", chunks.size());
// 注入Metadata:添加文件来源和导入时间,供后续RAG溯源过滤(实用技巧)
long importTime = System.currentTimeMillis();
for (Document chunk : chunks) {
chunk.getMetadata().put("source_filename", originalFilename);
chunk.getMetadata().put("import_time", importTime);
}
// ========== 3. Load:加载阶段,触发Embedding计算,写入Redis向量库 ==========
vectorStore.add(chunks);
log.info("[ETL] Load 完成,文件 [{}] 已入库,总耗时: {}ms",
originalFilename, System.currentTimeMillis() - startTime);
} catch (Exception e) {
log.error("[ETL] 管道执行异常,文件: {},异常原因: {}", originalFilename, e.getMessage(), e);
} finally {
// 关键操作:强制清理临时文件,防止磁盘空间泄漏(生产级必加)
if (tempFile.exists() && !tempFile.delete()) {
log.warn("[ETL] 临时文件清理失败,请及时排查磁盘占用: {}", tempFile.getAbsolutePath());
}
}
}
}底层细节剖析(深化理解,避免只会敲代码)
在上面的Transform(转换)阶段,大家会发现:我们没有用Spring AI默认的TokenTextSplitter,而是选择了自定义的SemanticTokenTextSplitter------这不是多此一举,而是为了避免文本切分的核心痛点,提升RAG检索的准确性,这里给大家详细拆解两者的区别,一起吃透底层逻辑。
TokenTextSplitter切分的3大痛点(避坑重点)
-
数组暴力截断:底层核心逻辑是直接执行tokens.subList(0, chunkSize),一旦触碰Token容量上限,会硬生生把一句话从主谓宾中间截断,比如把"Java开发者AI转型很有必要"截成"Java开发者AI转型很";
-
上下文撕裂:没有平滑的过渡机制,前一个Chunk可能以"根据业务报表显示,由于"结尾,后一个Chunk直接以"核心业务萎缩导致利润下滑"开头,语义断层严重;
-
诱发大模型幻觉:RAG检索时,如果大模型只命中了半截残缺的句子,会因为上下文不完整,产生严重的胡编乱造(幻觉),这也是很多知识库问答不准确的核心原因之一。
SemanticTokenTextSplitter的3大优势(推荐使用)
-
语义断句:利用正则"正向后瞻"技术,根据句号、问号、换行等标点符号,将长文本精准切分为完整的句子,绝不吞没标点,保证句子语义完整;
-
智能组装:将完整句子作为不可分割的单元,不断向当前文本块累加,直到总Token数量逼近设定的chunkSize安全红线,避免暴力截断;
-
句子级重叠(Semantic Overlap):触发切分边界时,不会拆分超载句子,而是从当前块末尾提取完整句子,作为下一个块的开头,确保相邻切片有平滑的语义锚点,让RAG检索更顺滑、更准确。
这里再给大家提个醒:finally块中的tempFile.delete()绝对不能省!做架构、写代码,既要懂资源分配,也要懂资源回收,否则长期运行会导致磁盘空间泄漏,最终拖垮系统------这也是生产级开发的核心素养,一起共勉。
Redis向量库常用操作(实操必备,收藏备用)
实操中,我们常用Redis作为向量库,难免会遇到索引无法命中、索引创建错误等问题,这里整理了4个高频操作命令,大家可以直接复制使用,高效排查问题,节省调试时间:
bash
# 1. 查询索引内容,判断数据是否命中索引
# 核心:通过结果中"Number of docs: "的值判断,无值则需重建索引(删除索引后重启项目即可自动重建)
FT.INFO '索引名称'
# 2. 删除索引(索引创建错误时使用,否则会导致向量查询失效)
FT.DROPINDEX '索引名称'
# 3. Docker部署Redis时,删除kg分组下的所有数据(批量清理常用)
docker exec -e REDISCLI_AUTH=密码 -i redis-stack sh -c 'redis-cli --scan --pattern "kg:*" | xargs -r redis-cli DEL'
# 4. 获取指定数据(排查数据是否成功入库)
# 示例:JSON.GET kg:0376472b-73fa-4669-824b-e1afd47986f7
JSON.GET key名称补充说明:使用Redis向量库时,若遇到索引无法命中、需要增减索引字段的情况,可通过上述命令排查、删除索引,重启项目后系统会自动重建索引,快速恢复正常。
本节总结(梳理重点,巩固提升)
本节课,我们跳出了单纯的API调用层面,从系统架构和操作系统资源管理的角度,重新审视AI应用的开发思路------这也是Java开发者转型AI的核心能力之一:不仅要会敲代码,还要懂架构、避坑点。
我们通过@Async注解实现了HTTP网络协议与AI算力的隔离,用物理文件跨越了Tomcat的生命周期陷阱,从接收内存流、落盘固化,到Tika提取、语义Splitter切分,再到VectorStore加载、临时文件回收,完整搭建了一条高内聚、可复用的ETL数据摄入流水线,为后续RAG对话功能打下了坚实基础。
希望大家课后多动手实操,把本节课的代码敲一遍,吃透异步解耦的逻辑和文本切分的避坑点,遇到问题可以在评论区交流,我们一起探讨、共同进步!
下期预告(提前预热,敬请期待)
【第二十四课:Spring AI 个人知识库实战(三)】
目前,我们的数据已经成功存入Redis向量库,但整个系统还缺少一个"大脑中枢"。下一节课,我们将重点实现:拦截前端用户问题,通过RAG向量检索召唤出我们存入的文本切片,再将切片与用户聊天历史打包,传递给大模型;同时,针对大模型推理的漫长等待,我们将引入SSE(Server-Sent Events)长连接技术,实现打字机式流式推送,提升用户体验!
精彩继续,我们下节见!
往期内容(连贯学习,查漏补缺)
-
Java开发者AI转型第二十课!Spring AI MCP 双向实战:客户端与服务端手把手落地
-
Java开发者AI转型第二十一课!吃透Spring AI MCP底层源码,彻底告别黑盒调用
-
Java开发者AI转型第二十二课!Spring AI 个人知识库实战(一)------架构搭建与核心契约落地
我是直奔標杆,专注Java开发者AI转型实战分享,专栏《Spring AI 零基础到实战》持续更新,每一节课都贴合实操、避坑导向,和大家一起从0到1吃透Spring AI,早日实现技术转型、直奔标杆!