大家好,我是直奔標杆!专注Java开发者AI转型干货分享,和大家一起从零基础吃透Spring AI,一步步实现从传统Java开发到AI工程化的跨越~
欢迎来到《Spring AI 零基础到实战》专栏的第二十二课!相信跟着专栏一路走来的小伙伴,已经掌握了Spring AI的核心基础:大模型流转的ChatClient、支撑上下文记忆的Memory/Advisors、打通私有知识壁垒的RAG/VectorStore,还有能让AI操控外部系统的MCP协议。
但咱们做技术的都懂,零散的技术组件就像散落在桌面的硬件,只有合理组装、规范架构,才能搭建出高可用、易维护的系统。今天这节课,咱们就用面向接口、高内聚的设计思路,把这些Spring AI底层组件整合起来,从零搭建一个入门级个人知识库系统,手把手教大家落地工程化实践,话不多说,直接上干货!
本节学习目标(建议收藏,打卡完成)
咱们学习不盲目,明确3个核心目标,学完就能上手搭建基础架构:
-
极简架构落地:基于MVC模式从零构建AI应用,彻底隔离HTTP网络层与AI核心调度层,避免代码耦合混乱;
-
核心契约沉淀:剥离复杂底层细节,面向前端定义简洁、标准的REST API交互协议,降低前后端联调成本;
-
系统防线构建:用AOP切面思想实现全局异常拦截,就算外部API熔断、网络异常,系统也能优雅响应,不暴露底层错误。
分层架构图:先定骨架,再写代码
做Java开发,架构先行!传统MVC分层结合大模型、Redis向量库等组件后,流转链路需要重新梳理,做到清晰、克制,避免后期维护踩坑。咱们先看架构分层(建议保存截图,对照代码理解):

架构分层详解(通俗易懂,新手也能懂)
-
Web接入层(controller):相当于系统的"前台接待",只做参数解析、文件流提取,不写任何AI推理、文件解析代码,负责把任务下发给业务层,职责单一清晰;
-
业务逻辑层(service):系统的"组装车间",核心工作就是把Spring AI各种组件像搭积木一样串联,编排成ETL(提取-转换-加载)流水线或RAG对话流,实现业务逻辑的高内聚;
-
核心引擎与设施层(Config & Beans):负责统一管理配置,剥离易变参数------比如大模型的API Key、连接池,还有Redis向量引擎、MCP客户端的单例对象初始化,后续修改配置不用动业务代码。
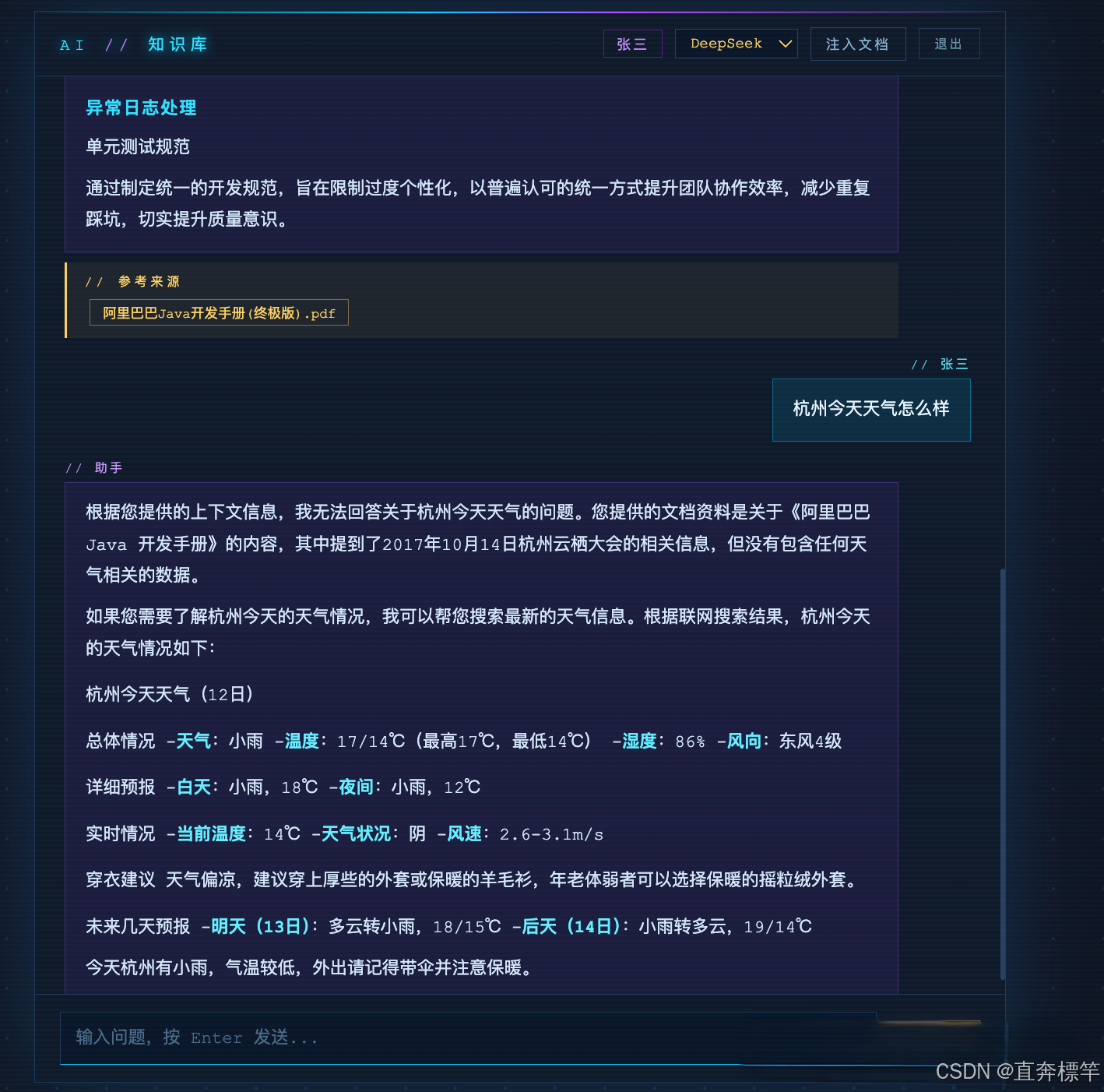
知识库效果预览(提前感受成果)
咱们搭建的个人知识库,核心功能如下(实际开发后可对照调试):
-
用户登录:简单易用的登录入口,保障知识库隐私;

-
知识库对话:基于本地私有知识问答,不依赖外部知识库,响应更快更精准;
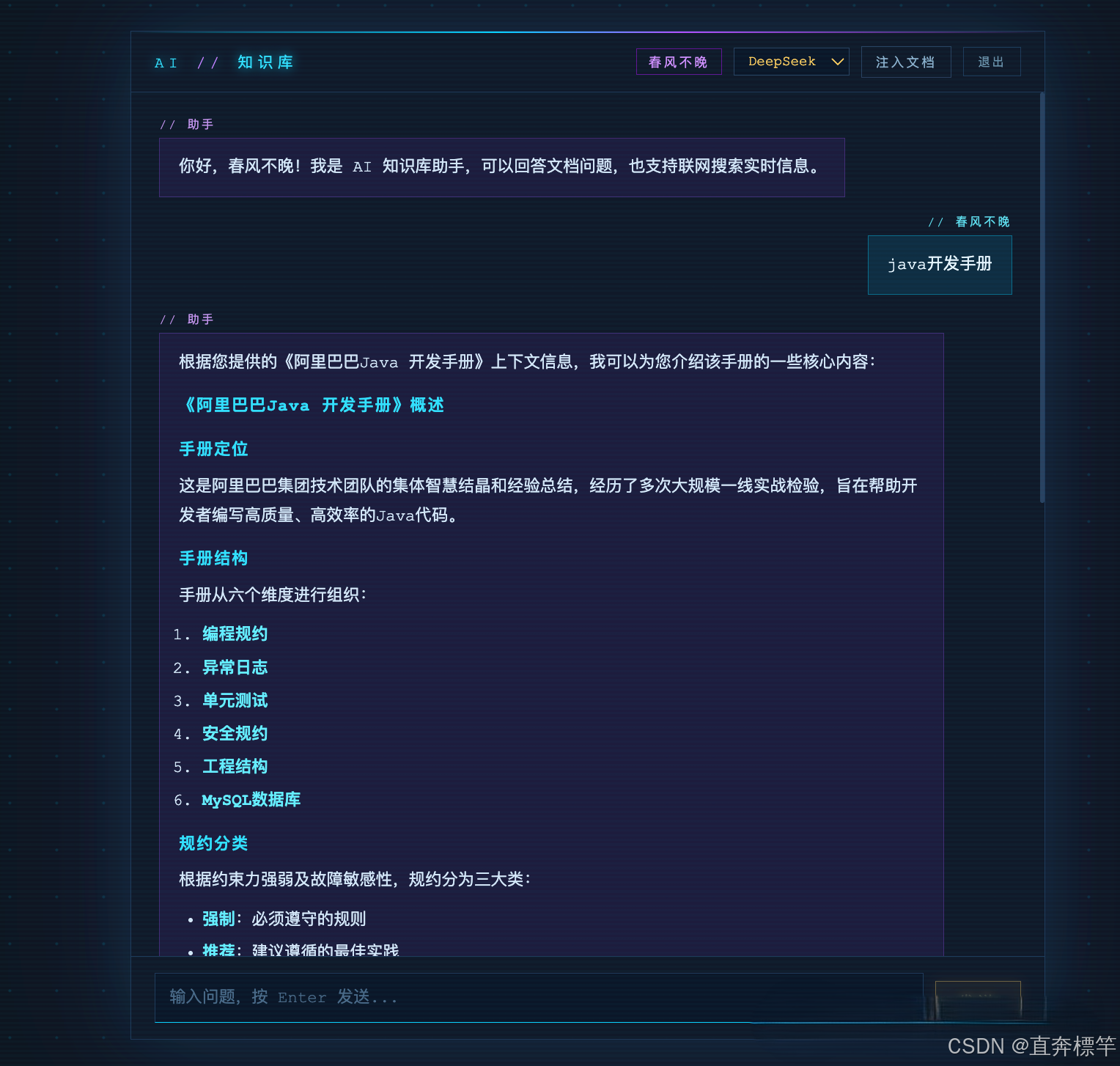
-
自动联网查询:当本地知识库无法满足用户提问时,自动触发联网检索,补充最新、最全的信息,解决大模型"知识过时"的痛点。
-
项目包结构与核心依赖(直接复制可用)
架构定好后,咱们先划分包结构,再引入核心依赖,避免后期频繁调整。建议大家跟着一步步搭建,加深记忆~
项目包结构
src/main/java/com/uka/springai/kg
-
config // 全局配置与Bean初始化(统一管理配置,解耦业务)
-
controller // REST API接入层,只做参数校验与流量转发
-
service // 高内聚的AI业务逻辑(ETL管道、对话编排)
-
└── impl // Service实现类(具体业务逻辑落地)
-
splitter // 自定义分割策略(文档切片用,适配不同格式文档)
-
strategy // 多模型策略模式(接口+OpenAI/DeepSeek实现+工厂)
-
dto // 请求/响应数据传输对象(ApiResponse、UploadResponse、ChatRequest)
-
exception // 全局异常处理(GlobalExceptionHandler)
-
SpringaiKgApplication.java // 项目启动类
核心依赖(pom.xml)
以下依赖直接复制到pom.xml即可,注释清晰,新手也能看懂每一个依赖的作用:
XML
<!-- OpenAI 模型依赖,对接OpenAI大模型 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<!-- DeepSeek 模型依赖,多模型切换备用 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<!-- Redis 向量库依赖(需配合Redis Stack使用,存储文档向量) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-redis</artifactId>
</dependency>
<!-- 非结构化文档解析依赖(基于Apache Tika,支持PDF/Word/Excel解析) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>关键配置(application.yaml)
核心配置如下,注意替换自己的API Key和中转服务地址,注释已标注关键说明,避免踩坑:
bash
spring:
ai:
# 禁用自动装配的ChatClient Bean,所有ChatClient由策略类手动构建,便于多模型切换
chat:
client:
enabled: false
openai:
api-key: ${OPENAI_API_KEY} # 建议用环境变量配置,避免硬编码泄露
base-url: 请填写中转服务地址 # 替换为自己的中转地址,解决网络访问问题
chat:
options:
model: gpt-4o # 选用gpt-4o模型,兼顾效果与速度
# DeepSeek 原生配置(spring-ai-starter-model-deepseek标准路径)
deepseek:
api-key: ${DEEPSEEK_API_KEY} # 同样用环境变量配置
chat:
options:
model: deepseek-chat # DeepSeek对话模型多模型策略设计(重点!多模型切换必备)
实际开发中,我们可能需要切换OpenAI、DeepSeek等不同模型,这里用策略模式+工厂模式实现,解耦模型调用逻辑,后续新增模型只需新增策略类,不用修改原有代码,符合开闭原则。直接上代码,可直接复制使用:
java
// 模型类型枚举,定义支持的模型
public enum ModelType {
OPENAI("openai"),
DEEPSEEK("deepseek");
// 此处可补充fromValue方法,用于前端参数转换,新手可先复制,后续理解
private final String value;
ModelType(String value) {
this.value = value;
}
public String getValue() {
return value;
}
public static ModelType fromValue(String value) {
for (ModelType type : ModelType.values()) {
if (type.getValue().equals(value)) {
return type;
}
}
throw new IllegalArgumentException("不支持的模型类型:" + value);
}
}
// OpenAI策略实现类,实现ChatModelStrategy接口
@Component
public class OpenAiChatStrategy implements ChatModelStrategy {
private final ChatClient chatClient;
// 构造方法注入ChatClient,无需手动创建
public OpenAiChatStrategy(ChatClient.Builder chatClientBuilder) {
this.chatClient = chatClientBuilder.build();
}
@Override
public ModelType getModelType() {
return ModelType.OPENAI;
}
@Override
public ChatClient getChatClient() {
return chatClient;
}
}
// 策略工厂,用于获取对应模型的策略,入口供Controller调用
@Component
public class ChatModelStrategyFactory {
private final Map<ModelType, ChatModelStrategy> strategyMap;
// 构造方法注入所有ChatModelStrategy实现类,自动存入map
public ChatModelStrategyFactory(List<ChatModelStrategy> strategies) {
strategyMap = new EnumMap<>(ModelType.class);
for (ChatModelStrategy s : strategies) {
strategyMap.put(s.getModelType(), s);
}
}
// 前端传入字符串,转换为枚举,获取对应策略(供Controller调用)
public ChatModelStrategy getStrategy(String modelValue) {
return strategyMap.get(ModelType.fromValue(modelValue));
}
// 内部业务调用,直接传入枚举,更高效
public ChatModelStrategy getStrategy(ModelType type) {
return strategyMap.get(type);
}
}这里补充一个小知识点:策略模式的核心是"封装变化",把不同模型的调用逻辑封装成独立策略类,工厂类负责统一分发,这样后续切换模型时,只需前端传入不同的模型标识,无需修改业务层代码,非常灵活,新手建议多理解几遍,实际敲一遍代码~
核心REST API契约规划(前后端联调必备)
优秀的后端架构,对外暴露的API必须简洁、语义清晰,避免冗余。咱们这个入门级个人知识库,只需要两个核心API,就能实现"知识入库"和"智能对话",前后端联调直接对照这个契约来,高效不踩坑!
1. 知识入库接口(POST /api/document/upload)
职责:接收前端上传的PDF等文件,交给Service层完成解析、切片、向量化,最终存入Redis向量库,相当于给知识库"喂知识"。
-
Content-Type:multipart/form-data(文件上传格式)
-
必填参数:file(文件对象,支持PDF/Word/Excel等格式)
-
响应契约(JSON格式,前端直接解析):
bash
{
"code": 200,
"message": "文件解析并入库成功",
"data": {
"fileName": "架构实战指南.pdf",
"chunksInserted": 150 // 插入的文本切片数量,可用于校验入库效果
}
}2. 智能对话接口(GET /api/chat/stream)
职责:提供带上下文记忆、本地知识库支持的对话功能,通过SSE长连接流式返回结果,提升用户体验,避免等待。
-
Content-Type:application/x-www-form-urlencoded 或 application/json
-
必填参数: - message:用户的自然语言提问 - chatId:会话标识(用于绑定用户上下文,并发场景下精准定位会话记忆)
-
响应契约(SSE长连接流):
bash
Content-Type: text/event-stream
data: 根据
data: 内部知识库
data: 记载,该架构的设计核心是...全局异常控制(必做!提升系统健壮性)
做AI应用,比传统CRUD更脆弱------依赖外部网络、第三方API(比如OpenAI)、Redis向量库,很容易出现API限流、网络中断、文件损坏等问题。如果不做异常处理,前端会收到杂乱的500错误和堆栈信息,体验极差。
这里咱们用Spring AOP思想,通过@RestControllerAdvice实现全局异常拦截,无侵入式兜底,让系统遇到异常时也能优雅响应,给前端清晰的错误提示。直接上代码,复制到exception包下即可:
java
/**
* 全局异常拦截器,统一处理系统所有异常,避免底层错误暴露给前端
*/
@RestControllerAdvice
@Slf4j // 记得导入lombok依赖,或手动创建log对象
public class GlobalExceptionHandler {
/**
* 拦截大模型API不可恢复异常
* 场景:API Key无效、账户欠费、模型不存在等无法重试的错误
*/
@ExceptionHandler(NonTransientAiException.class)
public ResponseEntity<ApiResponse<Void>> handleNonTransientAiException(Exception e) {
log.error("[AI异常] 大模型通信不可恢复错误: {}", e.getMessage(), e);
// 返回503状态码,给前端清晰的错误提示,便于排查问题
return ResponseEntity.status(HttpStatus.SERVICE_UNAVAILABLE)
.body(ApiResponse.error(503, "AI 服务暂时不可用,请检查 API Key 配置或网络连接"));
}
// 可补充其他异常拦截,比如文件解析异常、Redis连接异常等
@ExceptionHandler(FileParseException.class)
public ResponseEntity<ApiResponse<Void>> handleFileParseException(Exception e) {
log.error("[文件异常] 文档解析失败: {}", e.getMessage(), e);
return ResponseEntity.status(HttpStatus.BAD_REQUEST)
.body(ApiResponse.error(400, "文件解析失败,请检查文件格式是否正确、文件是否损坏"));
}
}补充说明:@RestControllerAdvice会拦截所有Controller的异常,通过@ExceptionHandler指定具体异常类型,将异常转换为前端可解析的JSON格式,既方便排查问题,又提升用户体验,新手一定要加上,这是企业开发的规范~
本节总结(重点回顾,加深记忆)
这一节课,咱们重点搭建了个人知识库的"骨架",从软件工程的角度,做好了系统的基础设计,核心要点总结如下,建议大家对照回顾:
-
架构分层:用MVC模式隔离HTTP层与AI核心层,避免代码耦合,为后续维护打下基础;
-
契约设计:定义两个核心REST API,简洁清晰,降低前后端联调成本;
-
异常兜底:用AOP实现全局异常拦截,解决AI应用脆弱的问题,提升系统健壮性;
-
多模型支持:用策略模式+工厂模式,实现多模型灵活切换,符合开闭原则。
其实做AI应用,和咱们传统Java开发一样,核心还是"架构先行、规范落地",把基础打扎实,后续添加功能才会更轻松。相信大家跟着敲一遍代码,就能掌握这些核心知识点~
下期预告(提前预热,敬请期待)
【Java开发者AI转型第二十三课!Spring AI 个人知识库实战(二)------文档解析与向量入库】
架构蓝图已经绘制完毕,下一节课,咱们就直奔主题,按照POST /api/document/upload接口契约,深入DocumentService内部,手把手实现文档解析(Tika)、段落切片(Splitter),并将文本写入Redis向量库。
另外,针对超大文档解析耗时过长的问题,咱们还会引入Spring异步任务(@Async)机制,避免漫长的运算耗尽HTTP线程池,真正落地高可用的业务逻辑!
精彩继续,咱们下节课见~ 大家如果有疑问,欢迎在评论区留言讨论,一起学习、一起进步,直奔技术标杆!
往期内容回顾(错过的小伙伴可以补卡)
-
Java开发者AI转型第十九课!MCP协议揭秘与无边界插件生态实战
-
Java开发者AI转型第二十课!Spring AI MCP 双向实战:客户端与服务端手把手落地
-
Java开发者AI转型第二十一课!吃透Spring AI MCP底层源码,彻底告别黑盒调用
我是直奔標杆,专注Java开发者AI转型干货分享,每一节课都力求通俗易懂、实战落地,跟着我一步步学,轻松实现从传统Java开发到AI工程化的跨越~ 记得点赞、收藏,关注不迷路!