引言
在前两篇系列文章中,我们完成了 Kafka 的 Docker Compose 基本部署,并解决了监听器(Listener)配置与客户端连接的问题。然而,当你准备将这套环境用于日常开发时,会发现一个致命缺陷:执行 docker-compose down && docker-compose up -d 后,Kafka 之前创建的所有 Topic 和消息全部丢失。 更严重的是,即使只是添加了数据卷映射、让数据目录持久化到宿主机,Kafka 也会陷入无限重启,日志中反复出现如下错误:
kafka.common.InconsistentClusterIdException: The Cluster ID RiPfzOmmTlea-o55SnHXlQ doesn't match stored clusterId Some(Q852tjOAQjScYLGc61jECA) in meta.properties. The broker is trying to join the wrong cluster.这个问题在 Kafka 2.4 及以上版本中更为常见,因为该版本强化了启动时的 Cluster ID 一致性校验。本文将从问题现象出发,逐步剖析根因,给出完整的持久化配置方案。如果您在 docker-compose down; docker-compose up -d 后遇到 Kafka 无限重启持续报错 kafka.common.InconsistentClusterIdException,或已挂载了数据卷却发现 Topic 数据依然丢失,本文正适合您。
一、问题复现:看似配置了持久化,实则无效
1.1 初次尝试:只持久化 Kafka 数据目录
按照直觉,我们首先想到的当然是持久化 Kafka 的数据目录。于是在 docker-compose.yml 中加入:
yaml
# Kafka 服务片段
environment:
KAFKA_BROKER_ID: 1
KAFKA_LOG_DIRS: /kafka/data # 指定数据目录
volumes:
- ./kafka-data:/kafka/data # 挂载到宿主机执行 docker-compose up -d 后,宿主机 ./kafka-data 目录下确实出现了 Kafka 的日志文件(如 meta.properties、__consumer_offsets 等),看起来一切正常。
1.2 灾难降临:重启后 Kafka 无限崩溃
但当我们执行 docker-compose down && docker-compose up -d 之后,Kafka 陷入无限重启。查看日志,赫然出现前文所述的 InconsistentClusterIdException。
表象上,Kafka 的数据确实持久化了,但它"不认识"自己持久化下来的数据了。
二、根因剖析:为什么 Kafka 会"翻脸不认人"?
2.1 Cluster ID 的生成与存储机制
Kafka 集群有一个全局唯一的 Cluster ID,它存储在 ZooKeeper 的 /cluster/id 节点中。当第一个 Broker 启动时,如果 ZooKeeper 中没有该节点,Kafka 就会生成一个新的 Cluster ID 并写入 ZooKeeper;后续的 Broker 启动时,会从 ZooKeeper 读取该 ID 并与之对齐。
同时,每个 Broker 的本地数据目录下(log.dirs 指定)会生成一个 meta.properties 文件,其中也会记录 cluster.id。
2.2 问题的真正原因
当仅持久化了 Kafka 数据目录而 未持久化 ZooKeeper 数据目录 时:
- 首次启动 :ZooKeeper 生成 Cluster ID(例如
Q852tjOAQjScYLGc61jECA),Kafka 将其写入本地meta.properties。 - 执行
docker-compose down:ZooKeeper 容器被销毁,其数据(保存在容器内部临时目录中)全部丢失。 - 再次
docker-compose up -d:ZooKeeper 作为"全新"实例启动,重新生成了一个新的 Cluster ID(例如RiPfzOmmTlea-o55SnHXlQ)。 - Kafka 启动时校验 :从 ZooKeeper 读到新 ID(
RiPfz...),但本地meta.properties中记录的是旧 ID(Q852...),两者不匹配,于是抛出InconsistentClusterIdException并拒绝启动。
一句话总结:只持久化了 Kafka 的数据,却忘了 Kafka 的"大脑"------ZooKeeper 的元数据也需要持久化。
三、解决方案:同时持久化 ZooKeeper 与 Kafka
3.1 关键:找到 ZooKeeper 的正确数据目录
解决方案的原理很简单------为 ZooKeeper 的数据目录也挂载宿主机卷。但执行时有一个致命陷阱:不同镜像的 ZooKeeper 数据目录路径可能不同,直接复制网上教程里的路径大概率会踩坑。
以 wurstmeister/zookeeper 镜像为例,网上很多教程会告诉你挂载 /data 或 /var/lib/zookeeper/data,但这些路径在 wurstmeister/zookeeper 容器中并不存在。正确的路径需要通过实际进入容器查看才能确定。
查看方法(以 Docker Desktop 为例):
在 Docker Desktop 的 Containers 面板中,进入 ZooKeeper 容器的 Files 标签页,浏览到 /opt/zookeeper-3.4.13/ 目录,你会看到其中有一个 data 文件夹,该文件夹下还包含 version-2 等 ZooKeeper 运行时数据(如下图)。
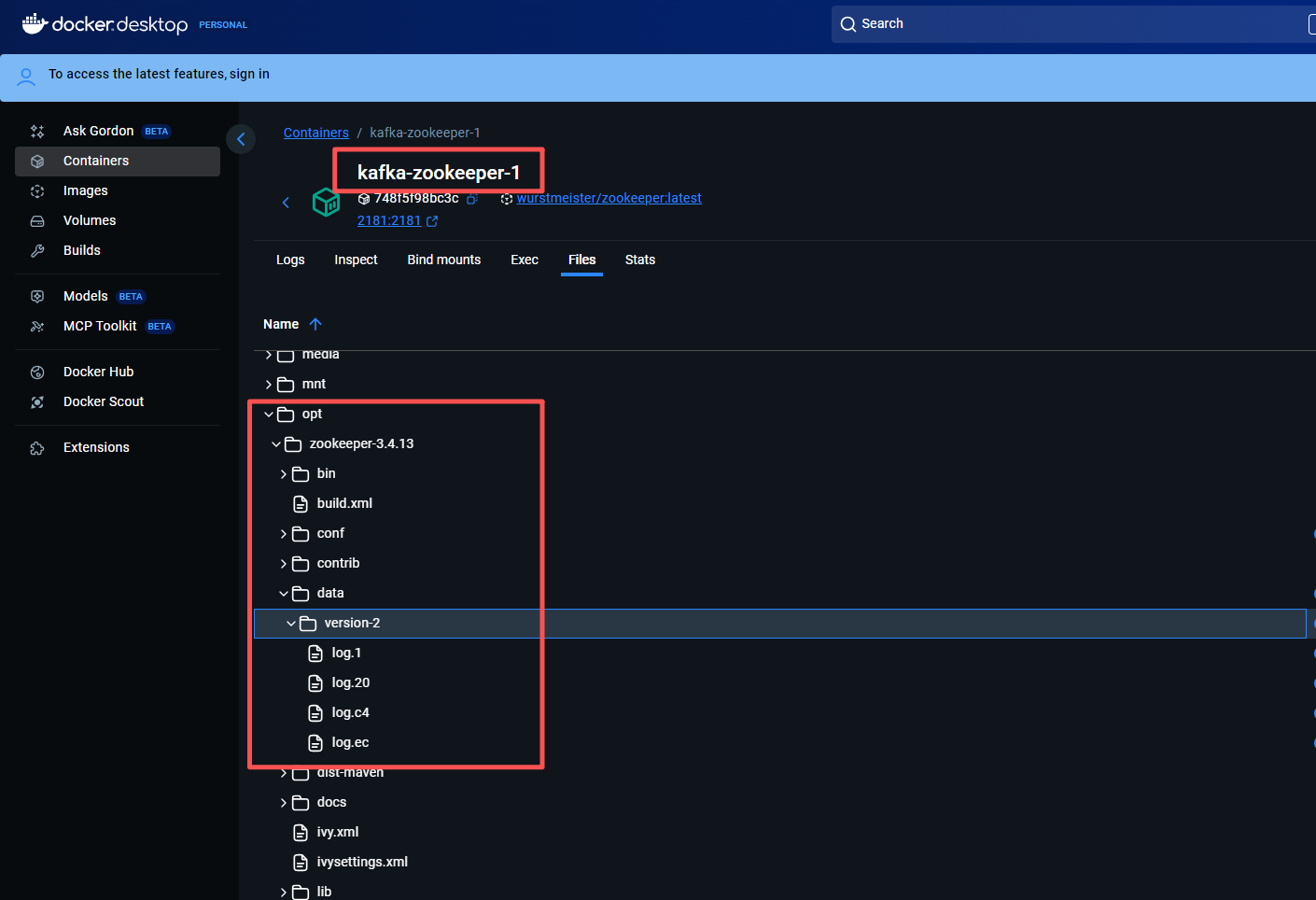
这就说明:wurstmeister/zookeeper 镜像的真实数据目录是 /opt/zookeeper-3.4.13/data,我们需要挂载的正是这个路径。
3.2 修改 docker-compose.yml
在 zookeeper 服务中添加正确的挂载配置:
yaml
services:
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181"
networks:
- kafka-network
restart: always
volumes:
# 关键修改:将宿主机 ./zookeeper/data 挂载到容器内的真实数据目录
- ./zookeeper/data:/opt/zookeeper-3.4.13/data3.3 清理残留的旧集群 ID(首次修复必须执行)
由于之前的 Kafka 数据目录中还残留着与新 ZooKeeper 不匹配的 cluster.id,需要先清理:
bash
# 清理 Kafka 本地残留的 meta.properties
# 在生产环境中,建议只在故障节点上执行,切勿同时删除所有 Broker
rm ./kafka-data/meta.properties⚠️ 重要运营提示 :在生产环境的多 Broker 集群中,绝对不要同时删除所有 Broker 的
meta.properties文件 。应逐台操作:停止故障节点 → 删除该节点的meta.properties→ 重启 → 验证状态恢复正常,再处理下一台。本文是针对单机开发环境,且 ZooKeeper 元数据已全部丢失的场景,一次性清理是安全的。
3.4 重新启动并验证
bash
docker-compose down
docker-compose up -d启动后检查 ZooKeeper 数据目录是否有内容:
bash
ls -l ./zookeeper/data正常情况下,你会看到 version-2 文件夹和日志等文件,说明 ZooKeeper 的数据已成功持久化到宿主机。
(在我的案例中,是在windows环境下测试,最终结果如下图所示。)
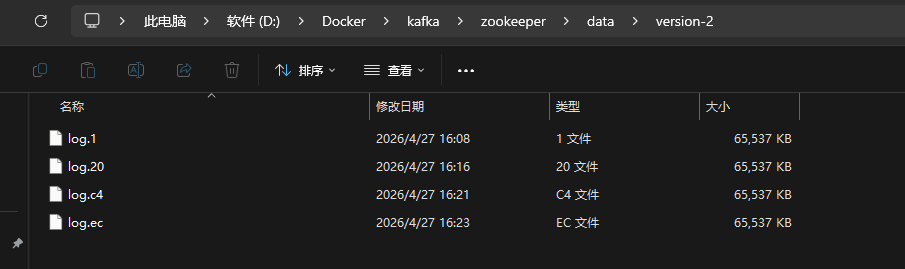
此后执行 docker-compose down && docker-compose up -d,Kafka 将正常启动,之前创建的 Topic 和数据都得以保留。
四、完整 docker-compose.yml(优化版)
以下是修复后的完整配置文件,可以直接用于本地开发环境。注意 KAFKA_ADVERTISED_LISTENERS 中的 IP 地址需要替换为你宿主机的实际 IP:
yaml
version: '2'
# 自定义网络:所有服务加入同一网络,通过服务名直接通信
networks:
kafka-network:
driver: bridge
services:
# Zookeeper:Kafka 的协调服务
zookeeper:
image: wurstmeister/zookeeper
ports:
- "2181:2181" # 映射 Zookeeper 客户端端口到宿主机
networks:
- kafka-network
restart: always # 容器退出时自动重启
# 关键修改 1:为 Zookeeper 添加持久化卷
volumes:
- ./zookeeper/data:/opt/zookeeper-3.4.13/data
# Kafka Broker:消息队列核心
kafka:
image: wurstmeister/kafka:latest
ports:
- "9092:9092" # 映射容器内 PLAINTEXT_HOST 监听器端口(9092)到宿主机,供外部客户端使用
environment:
# 监听器定义:Kafka 在容器内监听的地址和端口
# PLAINTEXT 监听器(内部通信)绑定到 9093 端口,PLAINTEXT_HOST 监听器(外部访问)绑定到 9092 端口
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9093,PLAINTEXT_HOST://0.0.0.0:9092
# 公布地址:Kafka 注册到 Zookeeper 并向客户端公布的连接信息
# 内部客户端(如同网络的 Kafdrop)应使用 PLAINTEXT://kafka:9093
# 外部客户端(宿主机)应使用 PLAINTEXT_HOST://localhost:9092
# 使用了内网穿透工具,外部客户端需要使用穿透后的地址
#KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9093,PLAINTEXT_HOST://xxxxxx
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9093,PLAINTEXT_HOST://{{your_ip}}:9092
# 监听器名称到安全协议的映射,这里均使用 PLAINTEXT(无加密)
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
# 指定 broker 之间内部通信使用的监听器,这里使用 PLAINTEXT(即 9093 端口)
KAFKA_INTER_BROKER_LISTENER_NAME: PLAINTEXT
# Zookeeper 连接地址,使用服务名
KAFKA_ZOOKEEPER_CONNECT: zookeeper:2181
# Topic 默认配置:副本因子 1(单副本),分区数 3
KAFKA_DEFAULT_REPLICATION_FACTOR: 1
KAFKA_NUM_PARTITIONS: 3
KAFKA_BROKER_ID: 1
# 新增:指定数据目录
KAFKA_LOG_DIRS: /kafka/data
networks:
- kafka-network
depends_on:
- zookeeper # 确保 Zookeeper 先启动
restart: always
# 新增:挂载数据卷
volumes:
- ./kafka-data:/kafka/data
# Kafdrop:Kafka Web UI 管理工具
kafdrop:
image: obsidiandynamics/kafdrop
ports:
- "9000:9000" # 映射 Web 端口到宿主机,访问 http://localhost:9000
environment:
# 连接 Kafka 的 broker 地址:必须使用内部公布的 PLAINTEXT 地址(kafka:9093)
KAFKA_BROKERCONNECT: kafka:9093
SERVER_SERVLET_CONTEXTPATH: "/"
networks:
- kafka-network
depends_on:
- kafka # 确保 Kafka 先启动
restart: always五、经验总结与避坑备忘
5.1 踩坑教训
| 坑点 | 现象 | 正确做法 |
|---|---|---|
| 只持久化 Kafka 而忽略 ZooKeeper | 重启后 InconsistentClusterIdException |
Kafka 和 ZooKeeper 两者都必须持久化 |
| 照搬网上教程中的挂载路径 | ZooKeeper 宿主机目录始终为空,问题得不到解决 | 进入容器查看实际目录结构后再配置挂载路径 |
修复后忘记清理 meta.properties |
配置正确但仍报 Cluster ID 不匹配 | 首次修复时删除旧的 meta.properties,让 Kafka 从 ZooKeeper 重新获取 Cluster ID |
5.2 排查方法论
当你遇到类似的 Docker 容器数据持久化问题时,可以按以下顺序排查:
- 确认目标目录 :进入容器内部(
docker exec -it <容器名> /bin/bash或通过 Docker Desktop 的 Files 面板),找到实际的数据存储路径。 - 验证挂载是否生效:重启容器后,检查宿主机对应目录是否有新文件生成。
- 检查权限问题 :如果挂载路径正确但宿主机目录仍为空,可能是权限不足。可以临时执行
chmod 777 <目录>快速验证,确认有效后再收紧权限。
5.3 衍生思考
本文解决了 Zookeeper 模式下的持久化问题。如果你在使用 KRaft 模式 (即 Kafka 去 Zookeeper 化部署),持久化策略又有所不同:需要通过 KAFKA_KRAFT_CLUSTER_ID 环境变量固定指定一个 UUID,避免自动生成导致的不一致。这种部署方式的持久化方案将在后续文章中展开。