为什么你的 Agent 读了文件,却好像什么都没读到?
两个让人抓狂的现象,同一个根因。扒了 Claude Code 源码之后,我终于搞清楚了。
先说两个场景,你可能都踩过
场景一:幽灵型(更隐蔽,更多人踩)
我让 Agent 分析一份服务器日志,找出最近一周的报错规律。
Agent 很快回复:「已读取日志文件,以下是分析结果......」
然后给了我一份看起来很像样的分析。
但我越看越不对------它提到的报错时间全在文件开头,后半段完全没提。我翻了一下原始日志,后半段才是问题最集中的地方。
Agent 没有报错,没有警告,语气笃定得像读完了整个文件。
它根本没读完。
场景二:崩溃型(更直接,更让人血压升高)
另一次,让 Agent 读一个依赖分析报告------一个 8 万行的 JSON 文件。
工具调用成功,然后下一步直接报错:
javascript
Error: context length exceeded. Maximum input tokens: 200000任务中断。Agent 一脸无辜。
两个场景,一个静默截断,一个直接崩溃,感觉像两个完全不同的问题。
但扒了 Claude Code 源码之后,我发现它们指向的是同一个机制。
根因:applyToolResultBudget,query loop 的第一道闸门
在 Claude Code 的 query.ts 里,每次 query 开始时,第一步执行的就是这个函数:
scss
// query.ts:379(第1步,最先执行)
messagesForQuery = applyToolResultBudget(messagesForQuery)它的职责只有一件事:在消息送进模型之前,确保工具结果不超出上限。
具体上限是三条硬编码的数字,源码在 src/constants/toolLimits.ts:
arduino
export const DEFAULT_MAX_RESULT_SIZE_CHARS = 50_000 // 单个工具结果:5 万字符
export const MAX_TOOL_RESULTS_PER_MESSAGE_CHARS = 200_000 // 单条消息所有工具结果总和:20 万字符
export const MAX_TOOL_RESULT_TOKENS = 100_000 // 单个工具结果 token 上限:10 万三条上限,任何一条触发,都会介入处理。
触发之后,不是丢弃,是「写磁盘 + 路径预览」
这里有个关键细节,很多人会猜错:
超出上限的内容,不是直接截断丢弃。
实际的处理流程是:
- 把完整内容写入磁盘临时文件
- 模型收到的
tool_result被替换成一段固定格式的文本 - 模型可以根据需要,再次
Read该文件的特定部分
模型实际看到的内容长这样(源码 buildLargeToolResultMessage):
lua
<persisted-output>
Output too large (2.3 MB). Full output saved to: /path/to/session/tool-results/xxx.txt
Preview (first 2.0 KB):
[文件前 2000 字节的内容]
...
</persisted-output>注意:这里没有「请用 Read 精准定位」之类的引导提示。Claude Code 只告诉模型「太大了,完整内容存在这里,给你看前 2KB」,剩下怎么处理,完全交给模型自己判断。
问题就出在这里。模型看到预览,往往不会意识到自己只拿到了冰山一角------它会把这 2KB 当成完整内容,继续往下走,给出一个看起来完整、实际上残缺的答案。这就是「幽灵型」场景的根因:Agent 说「已读取」,是真的,工具确实执行了,文件确实被读了。但模型在用残缺的信息自信作答,自己却不知道。
「崩溃型」场景则是在这个机制介入之前就出问题了------文件太大,连写磁盘 + 预览的流程都来不及救,上下文直接撑爆。
处理流程一图看懂
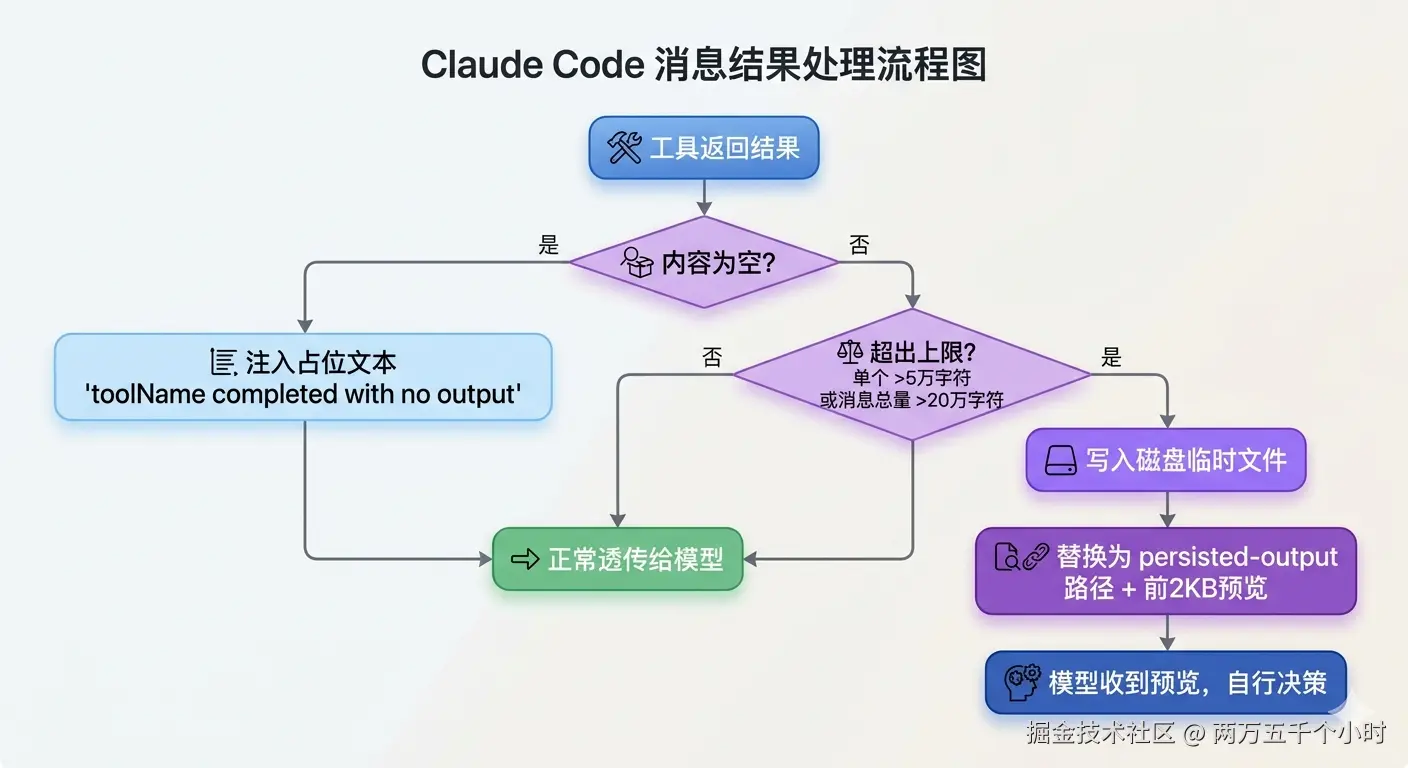
为什么要这样设计?
这是我扒完源码之后最想聊的部分。
applyToolResultBudget 有三种可能的设计选择:
选择一:直接截断 超出上限,把内容砍掉,只保留前 N 个字符。 问题:模型不知道内容被截断了,会用残缺信息自信作答------这正是「幽灵型」场景最糟糕的版本。
选择二:直接报错 超出上限,抛异常,任务中断。 问题:用户体验差,而且很多时候模型其实不需要完整内容,只需要文件的某个部分------报错让它连尝试的机会都没有。
选择三:写磁盘 + 路径预览(Claude Code 的选择) 超出上限,把完整内容存下来,给模型一个「我知道这个文件在哪,我可以按需读取」的能力。
这个选择背后的设计哲学是:把决策权还给模型,而不是替它做决定。
模型拿到路径预览之后,可以选择:
- 读文件的特定行(
Read+ 行号参数) - 先搜索关键词再定位(
Grep+ 精准范围) - 告诉用户「文件太大,请告诉我你最关心哪部分」
这比「直接截断」聪明,也比「直接报错」优雅。代价最低(纯截断,不调 LLM,不修改历史),但给了后续流程最大的灵活性。
这是所有压缩机制里最前置、代价最低的一道闸门------在 query loop 第一步执行,在其他任何压缩机制介入之前。
其他框架怎么处理大文件?
横向对比一下,更能看出 Claude Code 这个设计的独特之处。
LangChain FileLoader:在调用模型之前就把文件切成固定大小的 chunk,每个 chunk 单独送进去。决策权在框架层,模型只能看到被切好的片段,不知道完整文件长什么样。
AutoGPT:遇到大文件通常直接报错或截断,把「处理不了」的问题抛回给用户。
Claude Code :文件完整保存,模型拿到路径和预览,自己决定要不要继续读、读哪一段。
核心差异在于谁来做决策。LangChain 是框架决策,AutoGPT 是放弃决策,Claude Code 是把决策权交给模型------代价是模型必须足够聪明才能用好这个能力,这也是为什么「反直觉补丁」那一节的系统提示词那么重要。
对照检查:你的 Agent 有没有踩这些坑?
| 检查项 | 做了吗? |
|---|---|
| 让 Agent 读大文件时,有没有先确认文件大小? | ☐ |
| Agent「已读取」之后,有没有验证它拿到的是完整内容? | ☐ |
| 遇到「context length exceeded」时,知道是哪一层触发的吗? | ☐ |
| 系统提示词里有没有引导模型「按需读取」而非「一次读完」? | ☐ |
最关键的一条:当 Agent 说「已读取文件」,不要默认它拿到了完整内容。超过 5 万字符的文件,它拿到的很可能只是一个路径和前几行预览。
关于「系统提示词引导」那一条 ,由于 Claude Code 的 <persisted-output> 里没有任何引导提示,模型能不能聪明地按需读取,完全取决于它自己的判断。如果你发现模型拿到预览后仍然直接作答、不去精准定位,可以在系统提示词里加一段明确的行为约束:
markdown
当你看到 <persisted-output> 标签时,说明文件内容超出了单次读取上限,
你拿到的只是前 2KB 的预览,不是完整内容。
在此情况下,你必须:
1. 先用 Grep 搜索关键词,定位到相关行号
2. 再用 Read 加行号参数精准读取目标片段
禁止直接基于预览内容作答。这样模型就有了明确的行为规范,不再靠「自己判断」。
写在最后
扒完这段源码,我对 Claude Code 的设计有了新的理解:
它不信任「一次读完」,它相信「按需获取」。
applyToolResultBudget 不是一个限制,而是一个引导------引导模型从「把所有信息塞进上下文」的思维,转向「知道信息在哪、需要时再取」的思维。
这个设计哲学,其实也值得我们在构建自己的 Agent 时借鉴:上下文窗口是稀缺资源,不是垃圾桶。
你在让 Agent 处理大文件时,遇到过哪些奇怪的现象?欢迎留言,说不定我们踩的是同一个坑。
如果这篇文章对你有帮助,点个赞收藏一下~这是「Claude Code 上下文管理」系列的第①篇,后续还会继续拆其他机制。