📖标题:Analysis of Optimality of Large Language Models on Planning Problems
🌐来源:arXiv, 2604.02910v1
🛎️文章简介
🔸研究问题:前沿大语言模型在解决复杂规划问题时,是依赖简单的启发式策略,还是能像经典算法一样进行真正的全局最优推理?
🔸主要贡献:揭示了推理增强型大模型在复杂组合爆炸场景下,不仅能求解,还能严格保持理论最优解,性能超越了因搜索空间爆炸而失效的传统规划器。
📝重点思路
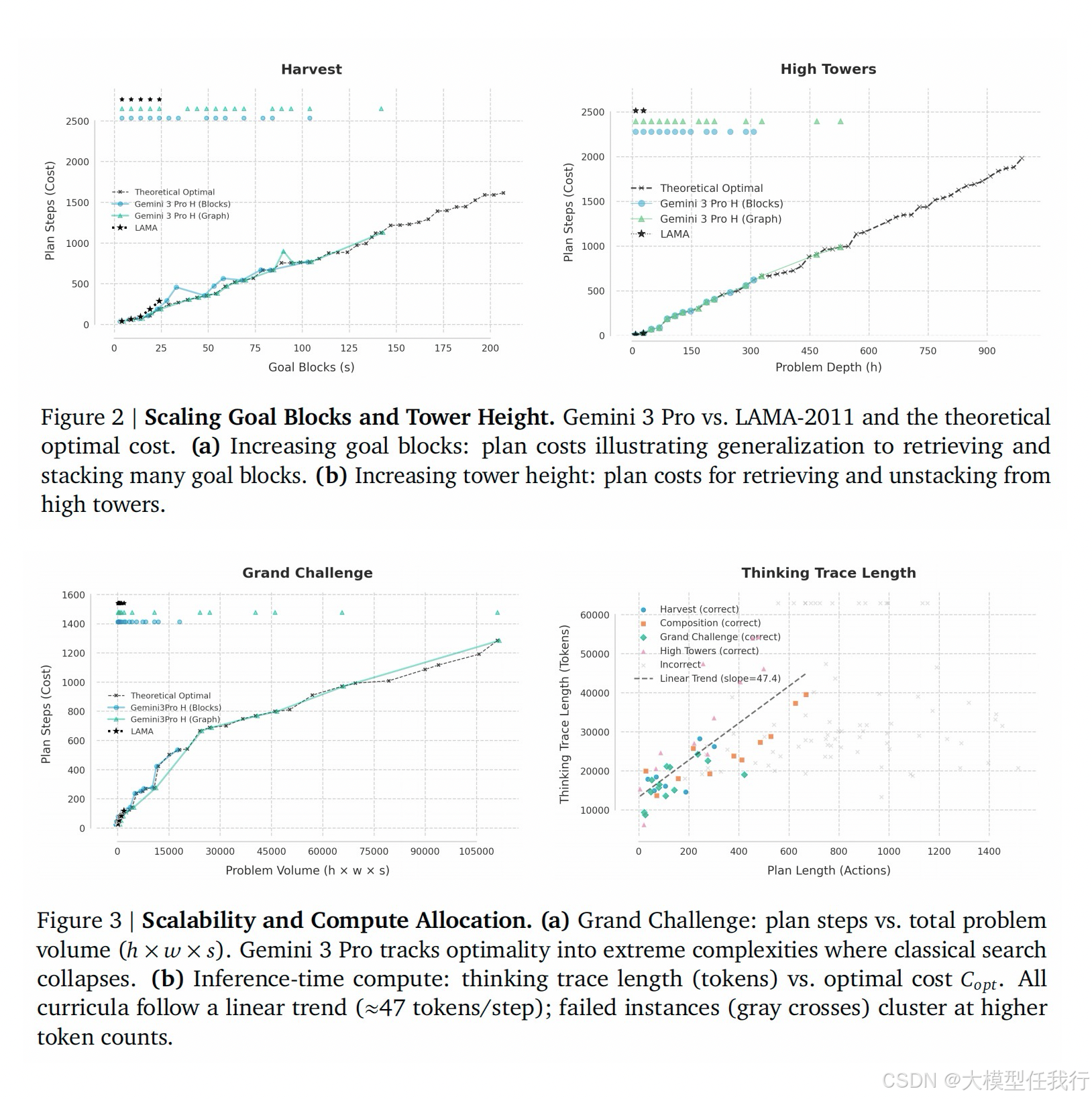
🔸构建基于广义 Path-Star 拓扑的问题空间,将积木世界映射为图结构,通过系统调节塔的高度(深度)、数量(宽度)和目标块密度(组合性)来隔离真正的拓扑推理能力。
🔸设计抽象图重写任务以剥离物理语义先验,强制模型仅依靠提供的算子和拓扑结构进行推理,排除对训练数据中特定领域启发式的记忆依赖。
🔸采用极简的少样本提示策略,仅提供领域定义和单个示例,利用具备思维链能力的推理增强模型,通过分析推理令牌消耗量来量化测试时的计算投入。
🔸提出并验证两种假设机制:一是通过推理令牌执行的主动算法模拟,二是允许模型将拓扑表示为可导航全局几何的几何记忆,以此解释模型如何绕过指数级复杂度。
🔎分析总结
🔸实验显示经典满意解规划器(如 LAMA)在目标块数量增加时迅速遭遇计算硬墙,被迫牺牲方案最优性或直接失败,而大模型能追踪理论最优界限直至极高复杂度。
🔸在去除语义提示的抽象图任务中,大模型依然能生成最优路径,证明其具备 genuine 的结构化拓扑推理能力,而非仅仅利用"堆叠"等物理常识捷径。
🔸成功生成的计划所需推理令牌数与最优计划步长呈严格的线性关系(约每步 47 个令牌),表明模型执行的是串行算法模拟,且失败模式是从完美最优直接跳变为完全失败,不存在中间的低质解。
🔸在处理塔内目标块交错依赖的复杂变体时,虽然模型最优率有所下降,但仍能解决大量传统规划器完全无法处理的实例,显示出其对分解策略的灵活适应性。
💡个人观点
论文打破了"大模型只能做近似推理"的刻板印象,证明了在特定拓扑结构下,大模型通过测试时计算(推理令牌)可以实现比传统搜索算法更优的可扩展性和严格最优性。