Warp/Wavefront 层面的深度优化与 Profiling 实战
引言:为什么 GPU 优化至关重要
在现代游戏和实时图形应用中,GPU 是性能的关键战场。与 CPU 不同,GPU 采用大规模并行架构------一次处理成千上万个像素。这种架构既是我们优化收益最大的地方,也是最容易踩坑的地方。
理解 GPU 的并行特性,是写出高性能 Shader 的第一步。本篇文章将从 Warp/Wavefront 层面入手,探讨:
- 如何识别和定位 ALU 瓶颈与带宽瓶颈
- 如何使用 RenderDoc 和 Snapdragon Profiler 进行 Profiling
- 如何避免分支分化(Warp Divergence)导致的并行度损失
- 如何在移动端善用 half 精度与指令合并
- 如何通过 Early-Z 最大化 GPU 填充效率
GPU 性能瓶颈的四大类型
GPU 性能瓶颈通常分为四类:ALU 瓶颈、带宽瓶颈、延迟瓶颈和控制流瓶颈。正确区分它们,是制定优化策略的前提。
2.1 ALU 瓶颈(Compute-Bound)
当 Shader 包含大量数学运算(矩阵乘法、三角函数、指数运算等)时,ALU(算术逻辑单元)成为瓶颈。ALU 瓶颈的特征是 GPU Compute 占用率高,但内存访问较少。

2.2 带宽瓶颈(Memory-Bound)
当 Shader 频繁访问纹理或 Buffer 数据,但计算量较少时,带宽成为瓶颈。常见于采样次数过多、纹理未正确使用 Mipmap、或大量使用 texelFetch 的场景。

2.3 延迟瓶颈(Latency-Bound)
GPU 内存延迟远高于 ALU 延迟。当 Shader 因数据依赖导致长时间等待时,即使计算密度不高,性能也会受限。典型场景是大规模纹理采样链。
2.4 控制流瓶颈(Control-Flow Bound)
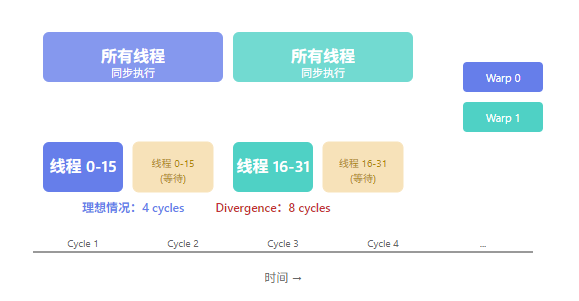
过多的分支语句导致同一 Warp 内线程执行不同代码路径,产生 Warp Divergence。这会导致有效并行度大幅下降,是 Shader 优化中最容易被忽视的问题。
| 瓶颈类型 | 主要特征 | 优化方向 |
|---|---|---|
| ALU 瓶颈 | Compute 占用率高、数学运算密集 | 降低精度、使用查找表、避免三角函数 |
| 带宽瓶颈 | Memory 占用率高、频繁纹理采样 | Mipmap、纹理压缩、延迟着色 |
| 延迟瓶颈 | 大量 Memory Stalling | 预取、缓存优化、异步调度 |
| 控制流瓶颈 | 分支密度高、Warp Divergence | 分支合并、predication、代码重排 |
Warp/Wavefront 编程模型基础
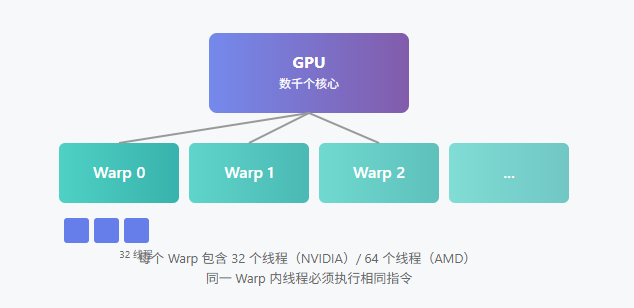
理解 Warp/Wavefront 是 GPU 优化的核心。NVIDIA 称其为 Warp,AMD 称其为 Wavefront,本质是同一概念:GPU 调度和执行的基本单元。
💡 核心概念
一个 Warp 包含 32 个线程(NVIDIA Maxwell/Pascal 及之后)或 64 个线程(AMD、Intel)。同一 Warp 内的所有线程必须同时执行同一条指令。这是理解 Warp Divergence 的关键。
3.1 Warp 执行模型
3.2 GPU 的 SIMT 架构
GPU 采用 SIMT(Single Instruction, Multiple Threads)架构。与 SIMD 不同,SIMT 允许独立线程拥有独立的执行路径,但同 Warp 线程共享取指和调度。
cs
// 场景:一个 Warp 处理 32 个像素
// 其中 16 个像素深度 > 5.0,另 16 个像素深度 <= 5.0
float depth = texelFetch(_DepthTex, uv, 0).r;
// ❌ 问题代码:导致 Warp Divergence
if (depth > 5.0)
{
// Warp 中只有部分线程执行这里
albedo = texture(_FarTex, uv).rgb;
metallic = 0.8;
}
else
{
// Warp 中另一部分线程执行这里
// 需要等待第一部分线程完成
albedo = texture(_NearTex, uv).rgb;
metallic = 0.2;
}⚠️ 性能警告
Warp Divergence 会导致有效并行度减半。在深度复杂的场景中,频繁的分支分化可能使性能下降 2-4 倍。
Profiling 工具详解
优化之前,先测量。正确使用 Profiling 工具能让你事半功倍,避免优化方向错误。以下是两大主流工具的使用指南。
4.1 RenderDoc
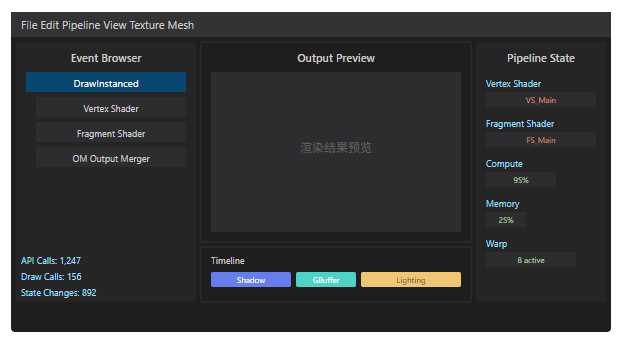
RenderDoc 是 Windows 平台最强大的 GPU 调试和 Profiling 工具,支持 DirectX、Vulkan、OpenGL。它可以逐帧分析 GPU 工作负载,精确到每个 Draw Call。
主要功能
- Frame Debugging:逐 Draw Call 分析 GPU 操作
- Pipeline State:查看当前渲染状态的完整配置
- Shader Debugging:GLSL/HLSL 源码级调试
- Texture Viewer:查看所有中间纹理内容
- Event Browser:按时间顺序查看所有 GPU 事件
关键指标解读
| 指标 | 含义 | 优化方向 |
|---|---|---|
Compute |
ALU 计算占用率 | 降低运算复杂度、使用查找表 |
Memory |
显存带宽占用 | Mipmap、纹理压缩、减少采样 |
Active Warps |
每 SM 活跃 Warp 数 | 增加并行度、避免长时间等待 |
Branch Divergence |
分支分化程度 | 重排分支、使用 predication |
4.2 Snapdragon Profiler
Snapdragon Profiler 是高通为 Adreno GPU 提供的 Profiling 工具,是移动端优化的首选。它可以连接真机或模拟器,实时追踪 GPU 性能数据。

移动端特有的优化指标
⚠️ 移动端限制
移动 GPU(如 Adreno、Mali)与桌面 GPU 有显著差异:寄存器数量更少、Shared Memory 更小、Warp 切换成本更高。桌面端的高性能 Shader 在移动端可能表现糟糕。
- URP Target Feature Level:确保 Shader 使用合适的特性级别(Android: GLES 3.1+,iOS: Metal)
- Half Precision :移动端强烈推荐使用
half而非float - Register Pressure:监控寄存器使用量,避免溢出到 Local Memory
- Texture Heatmap:可视化高频采样区域,定位带宽热点
避免 Warp Divergence
Warp Divergence 是 GPU 性能杀手之一。当同一 Warp 内线程执行不同分支时,未执行的分支会被"禁用",造成计算资源浪费。
5.1 分支合并(Branch Merging)
将可合并的分支合并为单一表达式,利用 GPU 的条件执行特性:
cs
// ❌ 低效:产生 Warp Divergence
float3 GetAlbedo(float depth, float2 uv)
{
if (depth > 10.0)
{
return texture(_FarTex, uv).rgb;
}
else if (depth > 5.0)
{
return texture(_MidTex, uv).rgb;
}
else
{
return texture(_NearTex, uv).rgb;
}
}
// ✅ 高效:使用 mix 合并分支,无 Divergence
float3 GetAlbedoOptimized(float depth, float2 uv)
{
float3 far = texture(_FarTex, uv).rgb;
float3 mid = texture(_MidTex, uv).rgb;
float3 near = texture(_NearTex, uv).rgb;
// 三重 lerp 替代 if-else 分支
float3 result = mix(near, mid, smoothstep(0.0, 5.0, depth));
result = mix(result, far, smoothstep(5.0, 10.0, depth));
return result;
}5.2 Predication(谓词执行)
GPU 硬件支持 Predication 机制:所有分支都执行,但结果根据条件选择。这比分支分化更高效,尤其是分支内操作简单时。
cs
// GPU 先执行 A 分支,再执行 B 分支
// 最后根据条件选择结果(无 Divergence)
float4 main(float2 uv : TEXCOORD) : SV_Target
{
float depth = texelFetch(_DepthTex, uv, 0).r;
float mask = step(0.5, depth); // 0 或 1
// 两分支都执行,GPU 无需切换
float4 branchA = tex2D(_TexA, uv);
float4 branchB = tex2D(_TexB, uv);
// 根据 mask 选择结果
return lerp(branchA, branchB, mask);
}5.3 均匀分支分布
如果分支不可避免,尽量让分支条件均匀分布,减少同一 Warp 内分化线程数量:

精度优化:half 与 mad()
6.1 half 精度 vs float 精度
移动端 GPU 对 half(16-bit float)有原生支持,ALU 吞吐量是 float(32-bit)的 2 倍。在保证视觉效果的前提下,优先使用 half。
| 类型 | 位数 | 范围 | 精度 | 适用场景 |
|---|---|---|---|---|
float |
32-bit | ±3.4e38 | 24 位尾数 | 世界坐标、深度、 HDR 颜色 |
half |
16-bit | ±60000 | 11 位尾数 | 法线、UV、颜色(通常够用) |
fixed |
11-bit | ±2.0 | 低精度 | 仅用于常量,URP 中已废弃 |
cs
// ❌ 过度使用 float
float4 main(float2 uv : TEXCOORD) : SV_Target
{
float3 normal = normalize(float3(uv.x, uv.y, 1.0));
float3 viewDir = normalize(float3(0.5, 0.5, 1.0));
float NdotV = dot(normal, viewDir);
float roughness = tex2D(_RoughnessMap, uv).r;
float metallic = tex2D(_MetallicMap, uv).r;
// ... 更多 float 计算
}
// ✅ 正确使用 half
half4 main(half2 uv : TEXCOORD) : SV_Target
{
half3 normal = normalize(half3(uv.x, uv.y, 1.0));
half3 viewDir = normalize(half3(0.5h, 0.5h, 1.0h));
half NdotV = dot(normal, viewDir);
half roughness = tex2D(_RoughnessMap, uv).r;
half metallic = tex2D(_MetallicMap, uv).r;
// ... 更多 half 计算
}
// ⚠️ 必须使用 float 的场景
float4 worldPos; // 世界坐标,可能超出 half 范围
float depth = texelFetch(_DepthTex, screenCoord, 0).r; // 深度值需要精确
float3 hdrColor; // HDR 光照,值可能超过 600006.2 mad() 指令合并
mad(a, b, c) = a * b + c。GPU 硬件通常将 mad 作为单指令实现,比分离的 mul + add 更快。
cs
// ❌ 低效:生成两条指令 MUL + ADD
float result = x * 2.0 + 1.0;
// ✅ 高效:生成一条 MAD 指令
float result = mad(x, 2.0, 1.0);
// 典型应用:矩阵变换
// ❌ 低效
float3 worldPos = mul UNITY_MATRIX_MVP, float4(position, 1.0);
worldPos = worldPos.xyz / worldPos.w;
worldPos = worldPos * _Scale + _Offset;
// ✅ 优化:尽量合并为 mad
float4 clipPos = mul(UNITY_MATRIX_MVP, float4(position, 1.0));
float3 ndcPos = clipPos.xyz / clipPos.w;
float3 worldPos = mad(ndcPos, _Scale, _Offset); // 合并最后一次变换
// ⚠️ 注意:当心精度溢出
// mad(x, y, z) 可能比 x*y + z 在极端值下更精确
// 因为 GPU 内部可能有更高精度中间值💡 URP 中的建议
在 URP 的 Lit Shader 中:Position 使用 float,Normal 使用 half,TexCoord 使用 half2,颜色空间转换中间变量使用 half。
Overdraw 与 Early-Z 优化
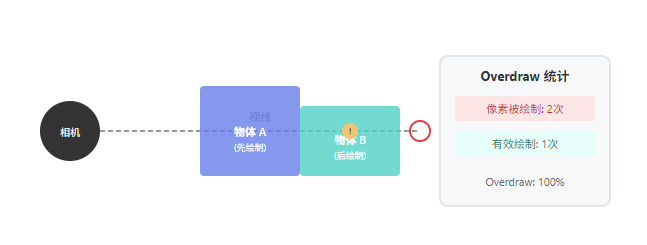
7.1 Overdraw 的成因
Overdraw 指同一个像素被多次绘制。透明的 UI、不透明物体间的遮挡关系处理不当、多遍渲染都会产生 Overdraw。
7.2 Early-Z 的工作原理
Early-Z 是 GPU 硬件优化:在 Fragment Shader 执行前,先进行深度测试,跳过被遮挡的像素,避免昂贵的着色计算。
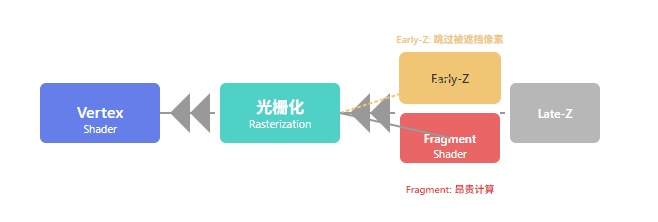
7.3 Pre-Z Pass 优化策略
对于复杂场景,Pre-Z Pass(也称 Z-Prepass)是一个有效的优化策略:先渲染一遍只输出深度的 Pass,然后主渲染 Pass 启用 Early-Z 跳过被遮挡像素。
cs
// 方案一:使用 Render Objects 特性
// 在 URP Asset 中添加 Render Objects 特性
// 1. 创建一个 Custom Render Pass
public class PreZPass : ScriptableRenderPass
{
public override void Execute(ScriptableRenderContext context,
ref RenderingData renderingData)
{
// 绘制不透明物体到深度缓冲
var drawSettings = CreateDrawingSettings(
new ShaderTagId("DepthOnly"),
ref renderingData,
SortingCriteria.CommonOpaque);
// 只写入深度,不写入颜色
drawSettings.enableDynamicBatching = true;
drawSettings.enableInstancing = true;
drawSettings.perObjectData = PerObjectData.None;
context.DrawRenderers(renderingData.cullResults,
ref drawSettings, out _);
}
}
// 2. 在 Renderer 中插入 Pass
// PreZPass 在不透明 Pass 之前执行
// 这会自动填充深度缓冲Pre-Z Pass 适用场景
💡 何时使用 Pre-Z Pass
适合:场景中不透明物体多、深度复杂度高、Fragment Shader 昂贵的场景(如复杂光照、PBR)。
不适合:透明物体多、场景简单、GPU 瓶颈在别处的情况。Pre-Z Pass 本身也有成本。
7.4 减少 Overdraw 的最佳实践
- 合理排序:从前往后绘制不透明物体,充分利用深度测试
- 视锥剔除:使用 URP 的 Frustum Plana Culling,不渲染相机外的物体
- 遮挡剔除:使用 Occlusion Culling,跳过被遮挡物体
- LOD 系统:远处物体使用低多边形模型,减少 Overdraw
- 避免过度透明:半透明物体无法使用深度测试,会产生大量 Overdraw
discard/clip() 的代价
discard 和 clip() 会立即终止当前像素的执行,看起来是"跳过"计算,但实际上会严重破坏 Early-Z 优化。
8.1 discard 对 Early-Z 的破坏
当 GPU 检测到 Shader 中存在 discard 调用时,必须延迟深度测试到 Fragment Shader 之后(Late-Z),因为无法预知哪些像素会被 discard。
🚫 性能警告
discard 会强制关闭 Early-Z,导致 GPU 必须完整执行所有被遮挡像素的 Fragment Shader,然后才能丢弃它们。这是巨大的浪费!

8.2 替代方案
尽量避免使用 discard,用其他方式实现相同效果:
cs
// ❌ 低效:使用 discard 实现 Alpha Test
float4 main(float2 uv : TEXCOORD) : SV_Target
{
float alpha = texture(_AlphaMap, uv).a;
if (alpha < _Cutoff) // GPU 必须在执行后才知道
{
discard; // ❌ 关闭 Early-Z
}
// 即使像素被遮挡,Fragment Shader 也会完整执行
return tex2D(_MainTex, uv);
}
// ✅ 高效方案 1:Alpha To Coverage(MSAA)
// 使用硬件 MSAA 采样遮罩代替 discard
// 设置 Render Queue 为 AlphaTest
// 在 Shader 中使用 _AlphaCutoffEnable
// ✅ 高效方案 2:Stencil Mask
// 第一 Pass:Stencil = 0,Alpha Test,只写 Stencil
// 第二 Pass:Stencil = 1,正常渲染,不透明 Pass 跳过
// ✅ 高效方案 3:Depth offset 配合不透明排序
// 让透明物体在正确顺序绘制,利用深度测试8.3 无法避免 discard 时
如果必须使用 discard,尽量减少其影响:
cs
// ✅ 技巧 1:尽早 discard
// 在 Fragment Shader 开头进行 discard 检查
// 减少已执行但被 discard 的计算
float4 main(half2 uv : TEXCOORD) : SV_Target
{
// 最早检查最廉价的条件
float4 col = tex2D(_MainTex, uv);
if (col.a < _Cutoff) discard; // 检查 alpha
// 其他昂贵计算在 discard 之后
half3 normal = DecodeNormal(tex2D(_NormalMap, uv));
half3 lighting = CalculateExpensiveLighting(normal);
return col * lighting;
}
// ✅ 技巧 2:使用 alpha 混合代替 discard
// clip(x-0.001) 可以用 smoothstep 近似
// 但要注意渲染排序
// ✅ 技巧 3:将 discard 区域烘焙到纹理中
// 使用预计算的 alpha mask
// 避免在运行时计算 discard 条件⚠️ URP Alpha Test 注意事项
URP 默认使用 _ALPHATEST_ON 关键字实现 Alpha Test,但它本质上仍是 discard。如果场景中大量使用 Alpha Cutoff 材质,考虑使用 Render Objects 特性进行 Pass 排序优化。
总结:优化清单
🎯 GPU Shader 优化速查表
- ✅ 优先识别瓶颈类型(ALU vs 带宽 vs 控制流)
- ✅ 使用 RenderDoc/Snapdragon Profiler 测量后再优化
- ✅ 避免 Warp Divergence,使用分支合并或 Predication
- ✅ 移动端使用 half 精度,计算密集处使用 float
- ✅ 使用 mad() 合并乘加运算
- ✅ 合理使用 Early-Z,从前往后渲染不透明物体
- ✅ 考虑 Pre-Z Pass 优化复杂场景
- ✅ 避免 discard,关闭 Early-Z 得不偿失
性能优化的黄金法则
"先测量,后优化;优化一个不存在的瓶颈是浪费时间。"
GPU 优化是一个迭代过程:Profiling → 分析 → 修改 → Profiling。建议每次只修改一个点,记录优化前后的性能数据,确保改动真正有效。