统计量与抽样分布
某地区居民收入情况、某公司生产的某规格的净水器使用寿命等都是相关研究中的统计总体,每个人的收入状况是不同的,每件产品的使用寿命也是不同的,这些数据所形成的分布就是总体分布。由于总体中的观察值是有差别的,可以视为随机变量,如果我们用X表示,那么X的分布就是总体分布。
但现实生活中我们往往观察不到总体的全部数据,如研究者没有足够经费调查该地区的所有居民150万人,净水器生产厂家也不允许将全部产品都用来进行实验。事实上,我们研究问题的目的也并不是为了获取这些总体的全部具体数据本身,而是为了得到这些数据的特征和规律即我们关心的是关于总体的均值、某种比例等。这里"该地区居民的人均收入""该地区高收人人群占总人口的比例"等就是所关心的总体参数,它是对总体特征的某个概括性的度量。
参数通常是不知道的,但又是我们想要了解的总体的某种特征值。如果只研究一个总体,人们所关心的参数通常有总体均值( μ \mu μ)、总体方差( σ 2 \sigma^2 σ2)、总体比例( π \pi π)等,如果研究两个总体,人们则关心两个总体均值之差( μ 1 − μ 2 \mu_1-\mu_2 μ1−μ2),两个总体比例之差( π 1 − π 2 \pi_1-\pi_2 π1−π2)等。
人们可以用样本统计量的某个实际取值作为相应的上述这些总体参数的估计值,这个过程叫作点估计。常用的点估计是用样本均值 x ˉ \bar{x} xˉ估计总体均值 μ \mu μ,用样本比例 p p p估计总体比例 π \pi π,用样本方差 s 2 s^2 s2估计总体方差 σ \sigma σ。
在通常情况下,你花510元请客吃饭,聊天时你说花了500元请客,没有人说你错了,这就是你对你此次花费的一个大致估计。当然了,吃完饭结账时你要按500元结账,恐怕饭店不允许,因为付钱时必须是准确的。
总体参数虽然是未知的,但可以利用样本信息来推断。
如,我们从上述研究地区随机抽取400人组成一个样本,根据这400人的平均收入推断该地区所有人口的平均收入。这里400人的平均收入就是一个统计量,它是根据样本数据计算的用于推断总体的某些量,是对样本特征的某个概括性度量。因此,统计量是不含任何未知参数的样本的函数。由于样本是从总体中随机抽取的,样本具有随机性,由样本数据计算出的统计量也是随机的。所以理论上在抽样中,统计量是一个随机变量。
由样本统计量这个随机变量所形成的概率分布就是抽样分布,即抽样分布就是统计量的分布,如样本均值的分布,样本比例的分布等。但当样本抽取出来以后,样本值就是已经观察到的值,这个样本的统计量就是已知的某个确定的值,是随机变量的一次实现值。
样本统计量可以看做是样本的函数,并且构成样本统计量的函数中不能包含未知参数。就一个样本而言,我们关心的统计量通常有样本均值( x ˉ \bar{x} xˉ)、样本方差( s 2 s^2 s2)、样本比例( p p p)等。
例题
【单选题】参数估计就是用样本统计量去估计总体的参数。总体参数是一个(C)。
A.统计量
B.随机变量
C.未知的量
D.己知的量
知识点一、统计量的抽样分布
(一)样本均值的抽样分布
设总体共有N个元素,从中随机抽取一个容量为n的样本:
在重复抽样(指在抽取样本单位的时候每次只抽取一个样本单位,观察记录之后再放回到总体中参加下一次的抽样)过程中总体单位总数始终不变时,共有 N n N^n Nn种抽法可以组成 N n N^n Nn个不同的样本;
在不重复抽样(是指在抽取样本单位的时候每次只抽取一个样本单位,观察记录之后不再放回到总体中参加下一次的抽样)过程中总体单位总数始终在减少时,
共有 C N n = N ! n ! ( N − n ) ! C^n_N=\frac{N!}{n!(N-n)!} CNn=n!(N−n)!N!个可能的样本。
每一个样本都可以计算出一个均值,这些所有可能的样本均值形成的分布就是样本均值的分布。
例题
【单选题】欲从1000家小微企业中随机抽取3%的企业调査其融资情况,如果采用不重复抽样,可能的样本有(B)。

总体为均匀分布,即 x i x_i xi取每一个值的概率都相同。总体的均值和方差分别为:
μ = 1 N Σ i = 1 N x i = 2.5 \mu=\frac{1}{N}\Sigma^N_{i=1}x_i=2.5 μ=N1Σi=1Nxi=2.5
σ 2 = 1 N Σ i = 1 N ( x i − μ ) 2 = 1.25 \sigma^2=\frac{1}{N}\Sigma^N_{i=1}(x_i-\mu)^2=1.25 σ2=N1Σi=1N(xi−μ)2=1.25
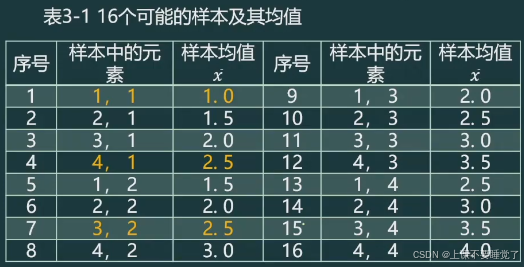
从总体中采取重复抽样方法抽取样本量为 n = 2 n=2 n=2的随机样本,共有 4 2 = 16 4^2=16 42=16个可能的样本。计算出每一个样本的均值,结果如表3-1所示。
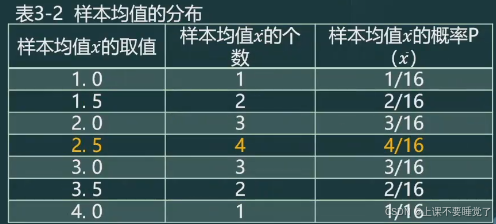
每个样本被抽中的概率相同,均为1/16。将样本均值整理后如表3-2所示。
将样本均值的分布绘成图,如图3-2所示。通过比较总体分布和样本均值的概率分布,不难看出它们的区别。尽管总体为均匀分布,但样本均值的概率分布在形状上却是对称的。
图3-2 样本均值的概率分布:
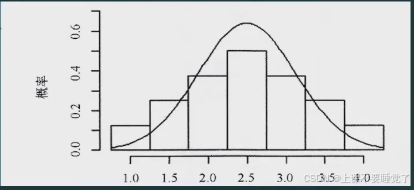
上图可以清晰地看出,样本均值的抽样分布就是指所有可能抽出来的样本的分布。数理统计学的相关定理已经证明:样本均值的均值就是总体均值,即:
E ( x ˉ ) = μ E(\bar{x})=\mu E(xˉ)=μ
在重复抽样时,样本均值的方差为总体方差 σ 2 \sigma^2 σ2的1/n即:
σ x ˉ 2 = σ 2 n \sigma^2_{\bar{x}}=\frac{\sigma^2}{n} σxˉ2=nσ2
在不重复抽样时,样本均值的方差略小于重复抽样的方差,即:
σ 2 n ⋅ N − n N − 1 , N − n N − 1 为修正系数 \frac{\sigma^2}{n}\cdot\frac{N-n}{N-1}\quad,\quad \frac{N-n}{N-1}为修正系数 nσ2⋅N−1N−n,N−1N−n为修正系数
例题
【单选题】采用不重复抽样的方法,从全校1000名学生中抽取100名学生调查其平均生活费用支出情况。根据以往调查可知总体方差 σ 2 \sigma^2 σ2为100,则样本均值的方差为(D)。
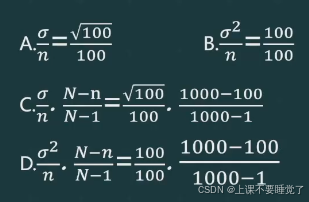
当总体为有限总体, N N N比较大而 n / N > 5 % n/N>5\% n/N>5%时,修正系数可以简化为 1 − n / N 1-n/N 1−n/N,当N比较大而 n / N < 5 % n/N<5\% n/N<5%时,修正系数可以近似为1,即可以按重复抽样计算。
并且我们可以证明当总体服从正态分布时,样本均值一定服从正态分布,即有:
x ∼ N ( μ , σ 2 ) 时, x ˉ ∼ ( μ , σ 2 / n ) x\sim{N(\mu,\sigma^2)}时,\bar{x}\sim{(\mu,\sigma^2/n)} x∼N(μ,σ2)时,xˉ∼(μ,σ2/n)
或 U = X ˉ − μ σ / n ⋅ ∼ N ( 0 , 1 ) , U 为标准化样本均值 或U=\frac{\bar{X}-\mu}{\sigma/ \sqrt{n}}\cdot{\sim{N(0,1)}}\quad,\quad U为标准化样本均值 或U=σ/n Xˉ−μ⋅∼N(0,1),U为标准化样本均值
若总体为未知的非正态分布,只要样本容量n足够大(通常要求n>30),样本均值仍会接近正态分布,其分布的期望值为总体均值,方差为总体方差的1/n。这就是统计上著名的中心极限定理。
这一定理可以表述为:从均值为 μ \mu μ、方差为 σ 2 \sigma^2 σ2的总体中,抽取样本量为n的随机样本,当n充分大时(通常要求n≥30)样本均值的分布近似服从均值为 μ \mu μ、方差为 σ 2 / n \sigma^2/n σ2/n的正态分布。
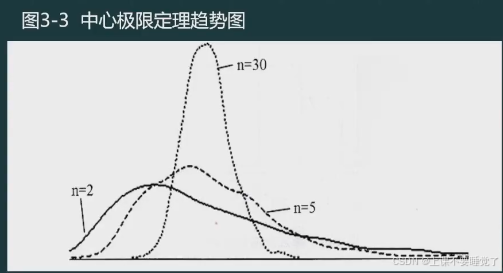
如果总体不是正态分布,且n为小样本时(通常n<30),样本均值的分布则不服从正态分布。
一般统计学中的n≥30为大样本,n<30为小样本只是一种经验说法。
例题
【单选题】下列关于样本量错误的说法是(C)。
A.它表明一个样本所包含的单位数
B.样本量的大小会影响抽样效果
C.样本量不少于25个样本称为大样本
D.样本量的大小与抽样方法有关